[新機能]入力テキスト内の個人を特定できる情報 (PII) をプレースホルダー値に置き換える「AI_REDACT関数」がパブリックプレビューとなったので試してみた
かわばたです。
2025年11月7日にAISQLのAI_REDACT関数がプレビュー版として利用可能になりました。
今回はAI_REDACT関数を実際に試してみるとともに、活用できるユースケースを考えていきます。
【公式ドキュメント】
対象読者
- AI_REDACT関数について確認したい方
検証環境
- SnowflakeトライアルアカウントEnterprise版
概要
AI_REDACT関数は、氏名、住所、電話番号、メールアドレス、納税者番号などのPIIデータをSnowflakeがホストする大規模言語モデル(LLM)を使用してPIIを識別し、プレースホルダー値に置き換えて匿名化する機能となります。
具体的には下記内容が該当となります。
| カテゴリ | 補足事項 |
|---|---|
| 名前 | 名前の一部であるFIRST_NAME、MIDDLE_NAME、LAST_NAMEも識別します |
| メール | |
| 電話番号 | |
| 生年月日 | |
| 性別 | 男性、女性、ノンバイナリーの価値観を認識する |
| 年 | |
| 住所 | アドレス部分も識別します |
| 国民ID | 米国の社会保障番号を識別します |
| パスポート | 米国、英国、カナダのパスポート番号を識別します |
| 税識別子 | 個人納税者番号(ITN)を識別します |
| 支払いカードデータ | 支払いカードの部分であるPAYMENT_CARD_NUMBER、PAYMENT_CARD_EXPIRATION_DATE、PAYMENT_CARD_CVVも識別します |
| 運転免許証 | 米国、英国、カナダの運転免許証番号を識別します |
| IPアドレス |
実際に試してみた
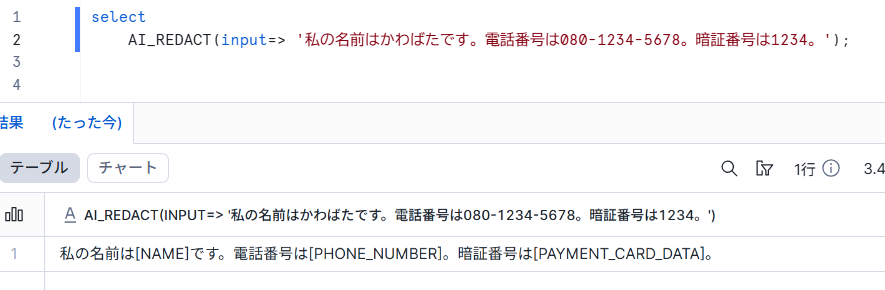
select
AI_REDACT(input=> '私の名前はかわばたです。電話番号は080-1234-5678。暗証番号は1234。');
結果は下記のとおりで、しっかりと日本語でもマスクできていますね!
考えられるユースケースとして下記が考えられます。
- 顧客サポートのチャットログ
- 通話の文字起こし
- アンケートの自由回答欄
上記ケースに対して、分析を行いたいときにAI_REDACT関数は活用できそうです。
非構造化データに対するアプローチ
AI_TRANSCRIBE関数を使用して、音声・動画ファイルを文字起こしを行ってからAI_REDACT関数を使用する組み合わせはよくありそうなので試していきます。
AI_TRANSCRIBE関数について詳細は、下記ドキュメントを参照してください。
【公式ドキュメント】
【分かりやすい記事】
使用するデータ
kaggleのCall Center Transcripts Datasetを活用していきます。
実際に試してみた
データベースとスキーマを指定し、ステージを作成します。
-- データベースとスキーマを適切に指定してください
USE DATABASE KAWABATA_MART_DB;
USE SCHEMA AI_REDACT;
-- 音声ファイル専用の内部ステージを作成
CREATE STAGE audio_stage
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
ステージに使用する音声データを格納します。
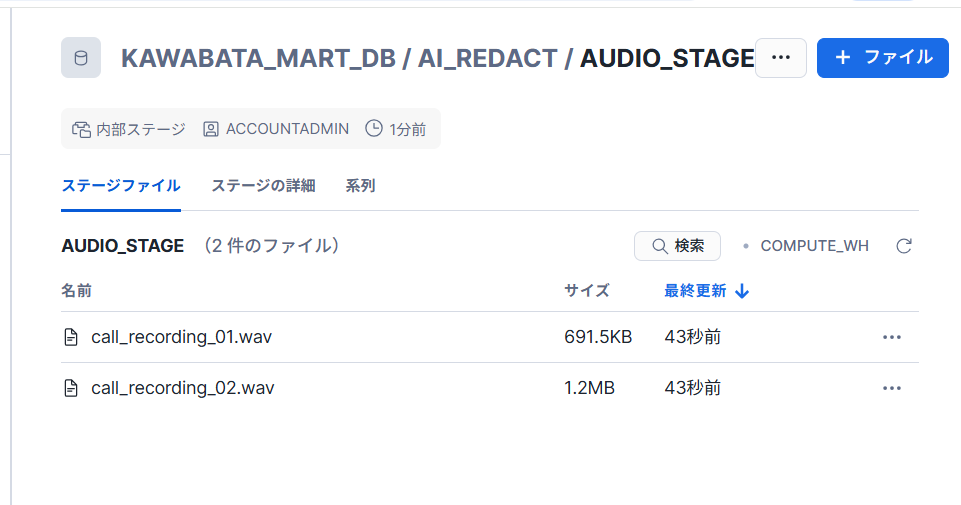
AI_TRANSCRIBE関数を使用して、音声ファイルを文字起こしします。
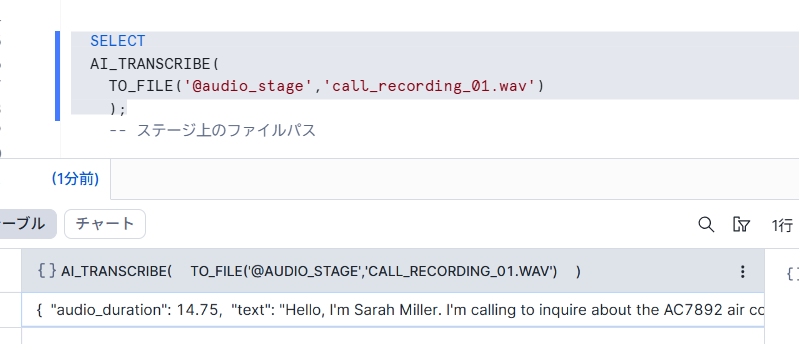
SELECT
AI_TRANSCRIBE(
TO_FILE('@audio_stage','call_recording_01.wav')
);
出力結果
{
"audio_duration": 14.75,
"text": "Hello, I'm Sarah Miller. I'm calling to inquire about the AC7892 air conditioner unit. I saw it on your website and I had a few questions. First, what's the BTU rating? And second, does it come with a remote control or is that sold separately?"
}
AI_REDACT関数を組み合わせて実行してみます。
WITH transcription AS (
SELECT AI_TRANSCRIBE(TO_FILE('@audio_stage','call_recording_01.wav')) AS result
)
SELECT
AI_REDACT(result:text::string) AS redacted_text,
result:audio_duration AS audio_duration
FROM transcription;
出力結果
Hello, I'm [NAME]. I'm calling to inquire about the AC7892 air conditioner unit. I saw it on your website and I had a few questions. First, what's the BTU rating? And second, does it come with a remote control or is that sold separately?
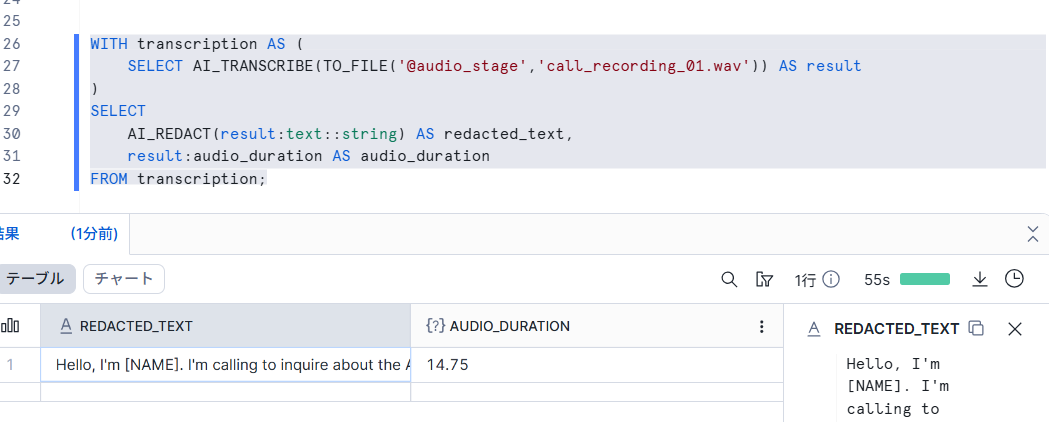
音声データを文字起こしし、そのデータに対してマスクをすることができました。
活用の用途としてはこのような形で、非構造化データに対して分析を行いたいときに個人情報をマスクしたいときに活用できそうです。
最後に
AI_REDACT関数を活用してみましたが、AIが自動で判別してくれるのは良い機能ですね。
まだ、プレビュー版かつ英語での精度が一番高いため活用のケースに悩む場面もあるかなと考えています。
私の考えとしては、顧客サポートのチャットログなどのテキストデータを分析したいときなどが一番活用できるのではないかと思います。
また、非構造化データの分析についても分析前のマスクとして活用できそうです。
この記事が何かの参考になれば幸いです!










