
PowerPointスライドの翻訳を自動化してみた(python-pptx)
こんにちは、AI事業本部インターンの山中です。
今回は、PowerPointスライドの日本語→英語翻訳を自動化する方法を検討・実装してみたので、その内容をまとめます。
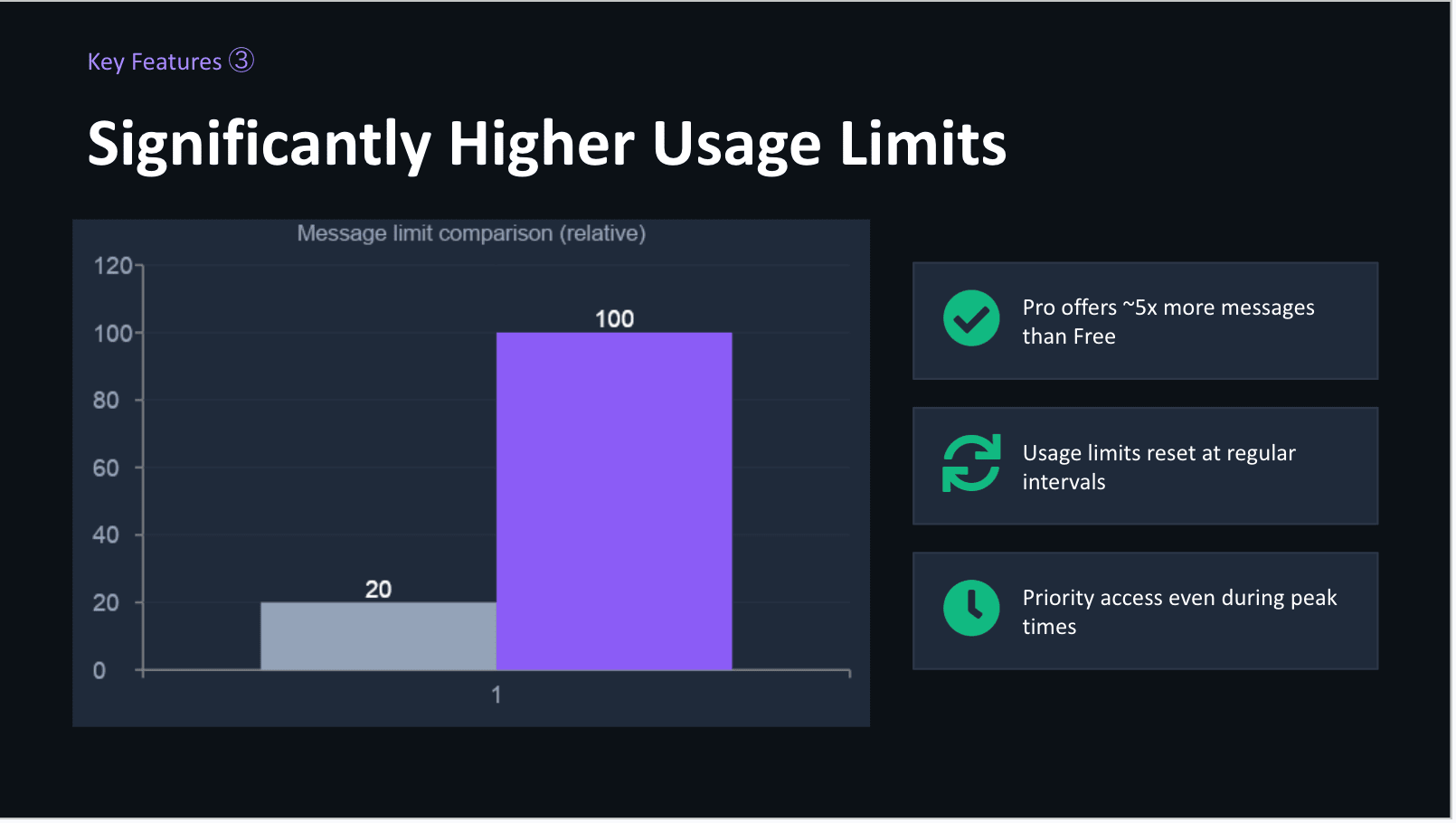
今回実装したやり方で、試しにclaudeに自身のProプランをプレゼンするスライドを作らせ翻訳して見たところ、以下のようにうまく翻訳することができました。
翻訳元
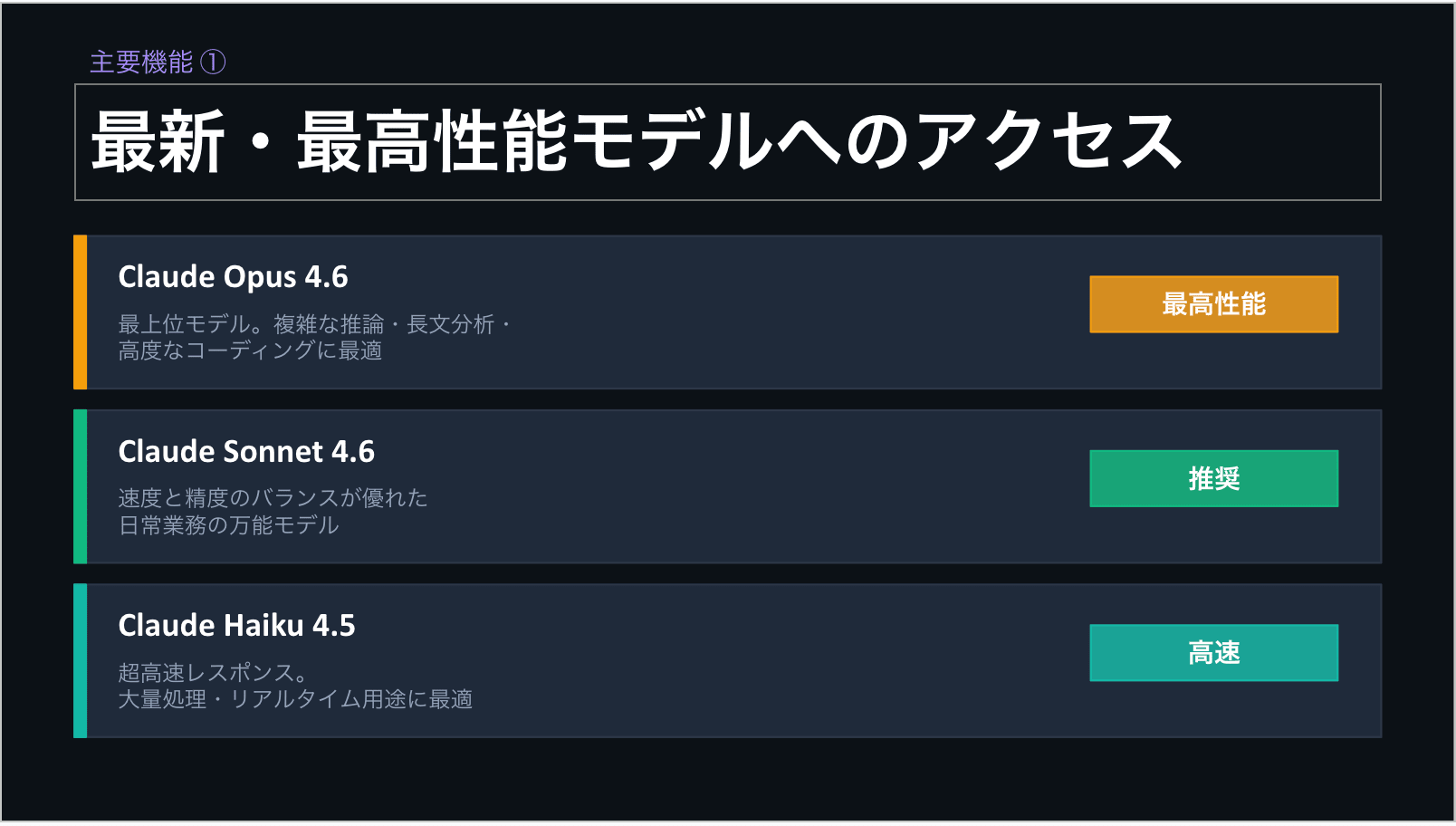
翻訳後

1. はじめに
生成AIを使えば文章の翻訳自体は簡単にできますが、PowerPointのテキストの翻訳には、レイアウトが崩れてしまうという独特の課題があります。
この課題を解決した上で自動でスライドを翻訳するため、 python-pptx というライブラリを使って、スライドのテキスト抽出とレイアウト調整(の一部)を自動化しようとしました。
2. 背景・課題
2.1 レイアウトが崩れる原因
PowerPointスライドを深く考えず自動翻訳しようとすると、以下のような問題が起きます。
- テキストの抽出漏れ:図形、グループ内のテキストが自動で取得されないことがある
- 文字数の違い:英語は日本語より文字数が増えやすいので、テキストボックスからはみ出してしまう
- フォントの問題:日本語専用フォントを英語テキストに適用すると、字体が正しく表示されない
2.2 解決したいこと
従って、解決したい課題は以下の通りとなります。
- スライドのあらゆる場所からテキストを漏れなく抽出する
- 翻訳後も文字数の変化によってレイアウトが崩れないようにする
- 日本語フォントを適切な英語フォントに置き換える
3. 前提
- 使用するライブラリ:python-pptx
.pptx形式のファイルは、XMLファイルと画像などをZIPで圧縮したものです。python-pptxは、そのXMLをPythonから操作するためのライブラリです。 - テキスト翻訳に用いた手段:claude agent sdk
今回は検証する環境の都合でサブスクのclaude codeの認証を引き継いでclaude agent sdkを使いました。
4. 全体の処理の流れ
Step 0: ファイルの読み込み
↓
Step 1: 翻訳対象テキストの抽出
↓
Step 2: Claude APIなどで翻訳
↓
Step 3: 翻訳テキストを書き戻し・保存
5. 実装の詳細
5.1 Step 0:ファイルの読み込み
まずは入力であるPPTXファイルを読み込みます。Presentation("path")でpptxファイルをオブジェクトとして扱うことができます。
from pptx import Presentation
prs = Presentation("input.pptx")
翻訳方針をClaudeに指示するmdファイルもパスを指定して読み込みます。このmdファイルには固有名詞の決まった翻訳などを書いておきます。
今回は翻訳指示ファイルは省略可能で、指定しない場合はデフォルトの方針で翻訳されるよう実装しました。
5.2 Step 1:テキストの抽出
PowerPointのスライドは、以下のような階層構造になっています。
Slide(スライド)
└─ Shape(図形)
└─ TextFrame(テキストが入る箱)
└─ Paragraph(段落)
└─ Run(書式が連続する文字の塊)
この構造を踏まえて、テキストを漏れなく取得する必要があります。
グループ図形は再帰処理する
図形はグループにまとめられていることがあります。グループの中に子図形があり、さらにその中にテキストがある、というような構造になっていると、単純にループするだけでは漏れが出るため、再帰処理をしています。
def collect_from_shape(shape, texts):
if hasattr(shape, "shapes"): # グループ図形なら中に入る
for child in shape.shapes:
collect_from_shape(child, texts)
return
if shape.has_text_frame:
collect_from_tf(shape.text_frame, texts)
if shape.has_table:
for row in shape.table.rows:
for cell in row.cells:
collect_from_tf(cell.text_frame, texts)
その他の翻訳対象
以下の項目もテキスト抽出対象にしています。それぞれXMLの属性を確認して判定し、同様に抽出します。
| 項目 | 内容 |
|---|---|
| テーブル(表) | セル内のテキスト |
| グラフ | タイトル・軸ラベル・系列名 |
| スライドマスター | 共通テンプレートのテキスト |
| セクション名 | スライドのセクション見出し |
縦書きテキストはスキップ
縦書きのテキストボックスは扱いが難しいかつあまり使われないと思うので、スキップします。XMLの属性を確認して判定します。
def is_vertical(tf) -> bool:
bodyPr = tf._txBody.find(qn("a:bodyPr"))
if bodyPr is None:
return False
return bodyPr.get("vert", "horz") not in ("horz", "eaHorz", "")
5.3 Step 2:翻訳処理
収集したテキストと翻訳指示のmdファイル内のテキストをプロンプトとしてAPIに渡します。以下のように番号付きリストを作ってAPIに送っています。
chunk = texts[i:i + BATCH_SIZE]
numbered = "\n".join(f"{j+1}. {t}" for j, t in enumerate(chunk))
返ってきたレスポンスを、元のテキストをキー、翻訳結果を値として辞書へ格納します。
for line in response_text.strip().split("\n"):
m = re.match(r"^(\d+)\.\s*(.*)", line.strip())
if m:
idx = int(m.group(1)) - 1
result[chunk[idx]] = m.group(2)
翻訳指示ファイルのポイント
mdファイルでは、レイアウト崩れを軽減するため、簡潔さを優先して翻訳するよう指示しました。
そのほかに、
- 翻訳は短いフレーズを優先する
- 固有名詞はローマ字表記(例:山田太郎 → Yamada Taro)
- 日付は英語圏の形式(例:2026年4月 → April 2026)
- URLや数値はそのまま保持する
といった内容を定めました。
5.4 Step 3:翻訳テキストの書き戻し
段落単位でまとめて翻訳する
1つの段落は、書式の切れ目ごとに複数の「Run」という単位に分割されています。Run単位でバラバラに翻訳・書き込みを行うと、文脈が途切れて不自然な翻訳になります。
そのため、段落内の全Runのテキストをつなげてから翻訳し、先頭のRunに書き込んでいます。
full = "".join(r.text for r in para.runs)
if has_ja(full):
translated = translate(full)
para.runs[0].text = translated
for run in para.runs[1:]:
run.text = "" # 残りのRunは空にする
フォントの置き換え
翻訳後も日本語フォントが残っていると、翻訳した時元の字体の雰囲気が失われたり、そもそも正しく表示されなくなることがあります。そのため、よく使われるフォントは字体を合わせたフォントマップを手動で作って対応させています。よく使うフォントで対応させたいものがあれば手動でマップに追加して対応します。
| 日本語フォント(例) | 対応する英語フォント |
|---|---|
| 游ゴシック(Yu Gothic) | Calibri |
| メイリオ(Meiryo) | Arial |
| 游明朝(Yu Mincho) | Cambria |
| MS明朝(MS Mincho) | Times New Roman |
テキストサイズの調整
英語は日本語よりも文字数が増えやすいため、翻訳後にテキストボックスからはみ出すことがあります。対策として、normAutofitを設定すると、図形に収まるようにテキストサイズが自動で縮小されます。
def enable_autofit(tf):
bodyPr = tf._txBody.find(qn("a:bodyPr"))
# 既存のautofit設定を削除
for tag in ("a:noAutofit", "a:spAutoFit", "a:normAutofit"):
for child in bodyPr.findall(qn(tag)):
bodyPr.remove(child)
# normAutofit を追加(フォントサイズを自動縮小)
etree.SubElement(bodyPr, qn("a:normAutofit"))
6. 対応していない項目
技術的に難しい、コストが高いといった理由で以下の項目は今回翻訳対象として対応できませんでした。
| 項目 | 理由 |
|---|---|
| 縦書きテキスト | ほぼ使われない、対応が難しい |
| 画像内のテキスト | 実装するコストが高い |
| SmartArt内のテキスト | python-pptxが正式サポートしていない |
| グラフ埋め込みExcelデータ | 対応が難しい |
7. 目視で確認が必要な点
normAutofitでフォントサイズが小さくなりすぎてないか- フォントマップで変換されないフォントのテキストが正しく表示されているか
- 装飾図形がテキストに重なっていないか
特に装飾図形や挿入した画像とテキストが重なる問題は発生しやすく、python-pptxで確認する術がないので人の目で確認する必要がありそうです。
8. 使用にあたって
8.1 使い方
python translate_pptx_agent.py \
--pptx input.pptx \
--instructions pptx_translation_instructions.md
翻訳対象のスライドと翻訳指示用のmdファイルのパスを指定して実行します。出力ファイルは input_en.pptx という名前で翻訳元ファイルと同じフォルダに保存されます。
8.2 コストの概算
今回は翻訳の手段として用いるため、claude agnet sdk経由でAPIを呼び出しました。
claude agent sdkの場合、こちらの公式ドキュメントに書かれている方法で処理にかかったコストを取得することができます。これを用いて算出したコストを記載します。[1]
検証においては、平均的なPowerPointファイルとして、以下のものを用意しました。
- スライド枚数:20枚
- テキスト件数:200件
この場合の1ファイルあたりにかかるコストは以下の通りでした。
| 項目 | 数値 |
|---|---|
| 金額 | $0.32 |
| 処理時間 | 50s |
9. まとめ
PowerPointの翻訳では、テキスト抽出・フォント・レイアウトの3つが課題になりました。
2.2 解決したいことにあげた項目をそれぞれ振り返ると、
- スライドのあらゆる場所からテキストを漏れなく抽出する:
達成することができました。 - 翻訳後も文字数の変化によってレイアウトが崩れないようにする:
図形内にテキストを収めることはできましたが、通常のテキストが画像などに隠れる問題が残ってしまいました。 - 日本語フォントを適切な英語フォントに置き換える:
よく使うフォントをあらかじめ決めた対応で変換するというあまり柔軟性のない解決方法になってしまい、改善の余地があります。
python-pptxを使っておおむね課題を解決することができましたが、より高い品質で翻訳するには、もっと柔軟なフォント変換をすることに加えて画像内テキストの翻訳なども課題になるかと思います。
しかし個人的な資料、社内の資料などを翻訳する場合であれば、ある程度実用的であると言える結果になりました。
10. 補足等
コストの概算について
- 追記予定
サンプルコード
- 追記予定
11. 参考
[1] Cladue Agent SDK公式ドキュメント
英語版 :https://code.claude.com/docs/en/agent-sdk/cost-tracking
日本語版:https://code.claude.com/docs/ja/agent-sdk/cost-tracking









