
LiteLLMとLangGraphで構築したAIエージェントをFastAPI・Streamlit・Dockerでデプロイしてみる
はじめに
データ事業本部のkobayashiです。
これまで実装してきたLangGraphエージェントを実運用環境で公開する方法を試してみます。本記事ではFastAPI(REST API)、Streamlit(チャットUI)、Dockerでのコンテナ化、そしてLangGraph Platformへの言及をまとめます。
デプロイの選択肢
| 方法 | 特徴 | 適用 |
|---|---|---|
| FastAPI + Uvicorn | 軽量・自由度高 | バックエンドAPI、社内ツール |
| Streamlit | UIをコードで書ける | プロトタイプ、社内ダッシュボード |
| LangGraph Platform | LangChain純正、永続化・スケジューリング統合 | 本番運用、エンタープライズ |
| Cloud Run / ECS Fargate | コンテナベースのマネージド実行 | 一般的なクラウド本番 |
環境
Python 3.13
litellm 1.83.14
langgraph 1.1.10
langchain 1.0.0
langchain-litellm 0.6.4
fastapi
uvicorn
streamlit
FastAPI で REST API として公開
"""FastAPI で LangGraph エージェントを REST API として公開する。
エンドポイント:
- POST /chat: 1ターンの会話
- thread_id でセッションを継続
"""
from fastapi import FastAPI
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_litellm import ChatLiteLLM
from langgraph.checkpoint.memory import InMemorySaver
from pydantic import BaseModel
@tool
def get_weather(city: str) -> str:
"""都市の天気を返します。"""
return f"{city}: 晴れ、24°C"
llm = ChatLiteLLM(model="openai/gpt-5-mini")
checkpointer = InMemorySaver()
agent = create_agent(model=llm, tools=[get_weather], checkpointer=checkpointer)
app = FastAPI(title="LiteLLM × LangGraph Agent")
class ChatRequest(BaseModel):
thread_id: str
message: str
class ChatResponse(BaseModel):
answer: str
@app.post("/chat", response_model=ChatResponse)
async def chat(req: ChatRequest) -> ChatResponse:
config = {"configurable": {"thread_id": req.thread_id}}
result = await agent.ainvoke(
{"messages": [{"role": "user", "content": req.message}]}, config=config
)
return ChatResponse(answer=str(result["messages"][-1].content))
@app.get("/health")
def health() -> dict:
return {"status": "ok"}
# 起動: uvicorn fastapi_server:app --host 0.0.0.0 --port 8000
thread_idをリクエストに含めることで、複数ユーザーのセッションを分離できます。CheckpointerをPostgresSaverに切り替えれば、複数のFastAPIインスタンスで状態を共有できます。
起動・テスト:
$ uvicorn fastapi_server:app --reload
INFO: Started server process [...]
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000
# 別ターミナルで
$ curl -s http://localhost:8000/health
{"status":"ok"}
$ curl -s -X POST http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{"thread_id":"demo-1","message":"東京の天気を教えて"}'
{"answer":"東京の天気は晴れ、気温は24°Cです。何か他に知りたいことはありますか?"}
POSTのレスポンスはエージェントが get_weather ツールを呼んだ結果を整形した1文応答です。同じ thread_id で続けて投げれば、Checkpointerが履歴を保持してくれるので「さっきの天気は?」のような追従質問が可能です。
Streamlit でチャットUI
社内ツールやプロトタイプには、Pythonだけでチャットインターフェースが組めるStreamlitが便利です。
"""Streamlit で LangGraph エージェントのチャットUIを提供する。
起動: streamlit run streamlit_app.py
"""
import streamlit as st
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_litellm import ChatLiteLLM
from langgraph.checkpoint.memory import InMemorySaver
@tool
def get_weather(city: str) -> str:
"""都市の天気を返します。"""
return f"{city}: 晴れ、24°C"
@st.cache_resource
def get_agent():
llm = ChatLiteLLM(model="openai/gpt-5-mini")
checkpointer = InMemorySaver()
return create_agent(model=llm, tools=[get_weather], checkpointer=checkpointer)
agent = get_agent()
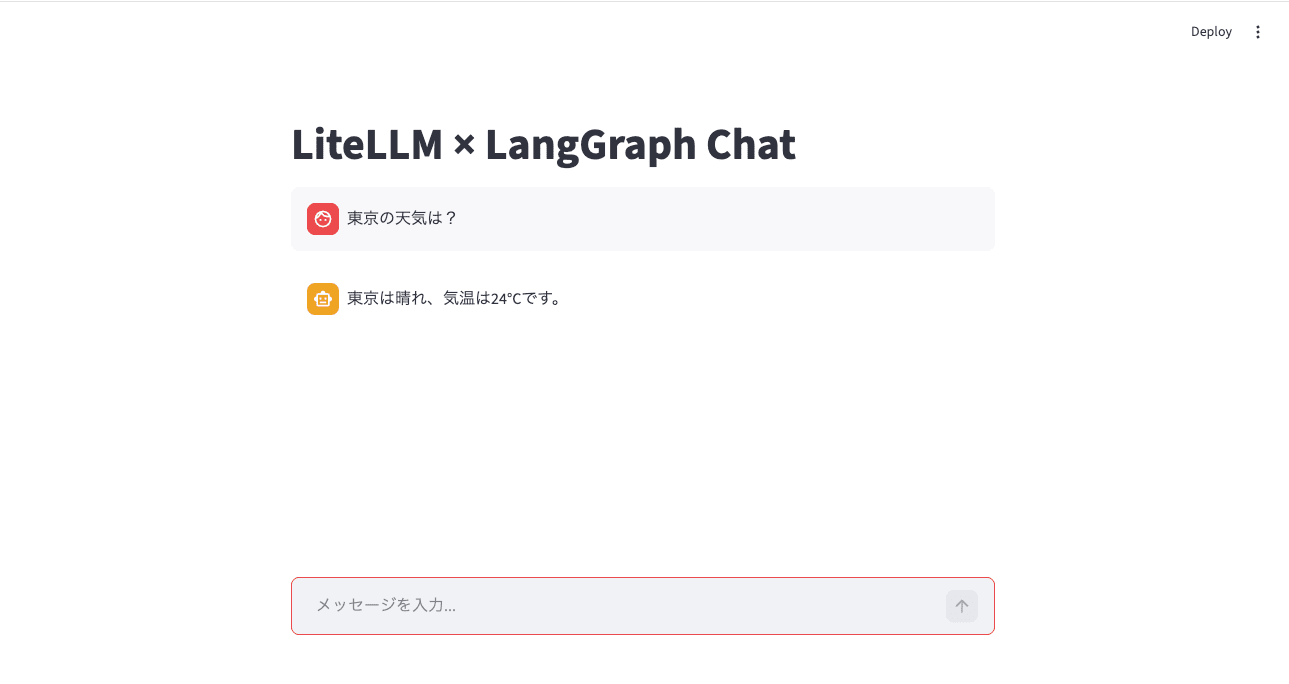
st.title("LiteLLM × LangGraph Chat")
if "thread_id" not in st.session_state:
import uuid
st.session_state.thread_id = str(uuid.uuid4())
if "messages" not in st.session_state:
st.session_state.messages = []
# 既存メッセージを表示
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
# 入力
if user_input := st.chat_input("メッセージを入力..."):
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
config = {"configurable": {"thread_id": st.session_state.thread_id}}
with st.chat_message("assistant"):
placeholder = st.empty()
full_response = ""
# ストリーミングで応答
for event in agent.stream(
{"messages": [{"role": "user", "content": user_input}]},
config=config,
stream_mode="updates",
):
for _node_name, node_state in event.items():
if "messages" in node_state:
last = node_state["messages"][-1]
if hasattr(last, "content") and isinstance(last.content, str):
full_response = last.content
placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
@st.cache_resourceでエージェントをセッション間で再利用し、st.session_state.thread_id でユーザーごとの履歴を分離します。
起動:
$ streamlit run streamlit_app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://...:8501
ブラウザで http://localhost:8501 を開くと「LiteLLM × LangGraph Chat」というタイトルのチャット画面が表示され、メッセージ入力欄からエージェントと対話できます。@st.cache_resource のおかげでエージェントは1度だけ初期化され、st.session_state.thread_id の uuid でブラウザセッションごとに会話が分離されます。
CIや headless 検証で動作確認だけ行いたい場合は --server.headless true を付けて起動すると、ブラウザを開かない状態でサーバーが立ち上がります。
Docker でコンテナ化
FROM python:3.13-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "fastapi_server:app", "--host", "0.0.0.0", "--port", "8000"]
ビルド・実行:
$ docker build -t litellm-agent .
$ docker run -p 8000:8000 \
-e ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY \
-e OPENAI_API_KEY=$OPENAI_API_KEY \
litellm-agent
このコンテナはAWS ECS Fargate / Cloud Run / Cloud Run Jobs などにそのまま乗るので手軽のクラウド環境でLLMサービスを立ち上げることができます。
LangGraph Platform
LangChainチームが提供するマネージドサービス LangGraph Platform は、以下を一括で面倒見してくれます。
- グラフのデプロイ(コンテナ化不要)
- Checkpointer・Storeの管理
- スケジューリング(cron風)
- アシスタント機能(versioning含む)
- LangSmithとの統合
langgraph deploy コマンドで langgraph.json の設定からデプロイできます。エンタープライズ要件で運用負荷を抑えたい場合に有力な選択肢です。
構成パターンの推奨
| 用途 | 推奨構成 |
|---|---|
| 社内プロトタイプ | Streamlit + InMemorySaver |
| 内製API | FastAPI + SqliteSaver / PostgresSaver + Cloud Run |
| 一般向けプロダクト | FastAPI + Postgres + Redis + Fargate / GKE |
| エンタープライズ | LangGraph Platform |
LiteLLMでモデルを切り替えられる利点は、デプロイ後のモデル変更が再ビルド不要で行える点にもあります(環境変数や Configマップの差し替えで切替可能)。
まとめ
LangGraph エージェントの主要なデプロイパターンを、FastAPI(軽量バックエンドAPI)/ Streamlit(即席チャットUI)/ Docker(コンテナ化)/ LangGraph Platform(マネージド本番)の4種類で紹介しました。
FastAPI では /chat エンドポイントで thread_id 管理を行い、Streamlit では @st.cache_resource でエージェントを永続化、Docker ではコンテナ化して FastAPI サーバーを CMD 起動、本格運用では LangGraph Platform に乗せて永続化やスケジューリングをマネージドに任せる、というように 段階的にスケール できる構成になっています。本番運用では Checkpointer に必ず プロセス横断で共有可能なバックエンド(Postgres など)を選ぶこと、API キーは シークレットマネージャー 経由で渡すことが重要で、LiteLLM を介していればモデル切替を1行で完結できる利点もそのまま生きてきます。
最後まで読んでいただきありがとうございました。











