
Google Researchの時系列予測基盤モデルTimesFMでゼロショット予測と共変量付き予測を試してみる
はじめに
データ事業本部のkobayashiです。
時系列データの予測を行う際に、従来はARIMAやProphetといった統計モデルやドメイン固有のモデルを個別にチューニングする必要がありました。近年ではLLMの成功に触発されて、時系列データに対しても事前学習済みの基盤モデル(Foundation Model)を活用するアプローチが注目されています。
今回はGoogle Researchが開発した時系列予測の基盤モデルTimesFMを試してみたのでその内容をまとめます。
TimesFMとは
TimesFM(Time-series Foundation Model)は、Google Researchが開発した事前学習済みの時系列予測モデルです。ICML 2024で発表されたデコーダーオンリーアーキテクチャを採用しており、ファインチューニングなしでゼロショット予測が可能という特徴があります。
主な特徴としては以下になります。
- ゼロショット予測: 追加の学習なしで、さまざまな時系列データに対して高精度な予測が可能
- 分位点予測(Quantile Forecast): ポイント予測に加えて、予測の不確実性を表す分位点予測をサポート
- 共変量サポート(XReg): 外部変数を組み込んだ予測が可能
- 複数系列の同時予測: 複数の時系列データを一度にまとめて予測できる
- マルチバックエンド対応: PyTorchとFlax(JAX)の両方で動作
- マルチハードウェア対応: CPU / GPU / TPU / Apple Silicon で動作
TimesFMのバージョン
TimesFMはこれまでに以下のバージョンがリリースされています。
| バージョン | パラメータ数 | 最大コンテキスト長 | 備考 |
|---|---|---|---|
| TimesFM 1.0 | 200M | 512 | 初期リリース |
| TimesFM 2.0 | 500M | 2,048 | v1.0比で最大25%精度向上 |
| TimesFM 2.5 | 200M | 16,000 | 最新版。モデルサイズ縮小かつコンテキスト長大幅拡大 |
最新のTimesFM 2.5では、パラメータ数が500Mから200Mに縮小されつつも、コンテキスト長が最大16,000まで拡大されています。また周波数インジケータが不要となりアーキテクチャが簡素化されています。
では早速試してみます。
TimesFMを使ってみる
環境
今回はTimesFM 2.5(PyTorchバックエンド)を使用します。
Python 3.13.9
timesfm 2.0.0(GitHubリポジトリからインストール、モデルはv2.5を使用)
torch 2.11.0
numpy 2.4.4
pandas 3.0.2
TimesFMはPython 3.10以上をサポートしています。なおPyPIのパッケージバージョンは2.0.0ですが、GitHubリポジトリの最新版をインストールすることでTimesFM 2.5モデルを使用できます。
インストール
TimesFM 2.5はPyPIパッケージ(v1.3.0)には含まれていないため、GitHubリポジトリからソースインストールを行います。
$ git clone https://github.com/google-research/timesfm.git
$ cd timesfm
仮想環境の作成とインストールを行います。ここではuvを使用しています。
$ uv venv
$ source .venv/bin/activate
PyTorchバックエンドでインストールする場合は以下のようにします。
$ uv pip install -e ".[torch]"
Flax(JAX)バックエンドの場合は以下になります。
$ uv pip install -e ".[flax]"
また以降のスクリプトでは予測結果をグラフで確認するためmatplotlibもインストールしておきます。
uv pip install matplotlib
基本的な使い方
TimesFMの基本的な使い方として、NumPy配列で時系列データを渡してゼロショット予測を行ってみます。
import torch
import numpy as np
import matplotlib.pyplot as plt
import timesfm
# 浮動小数点演算の精度設定
torch.set_float32_matmul_precision("high")
# モデルの読み込み(Hugging Faceから自動ダウンロード)
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained(
"google/timesfm-2.5-200m-pytorch"
)
# 予測設定のコンパイル
model.compile(
timesfm.ForecastConfig(
max_context=1024, # 入力コンテキストの最大長
max_horizon=256, # 予測ホライズンの最大長
normalize_inputs=True, # 入力の正規化
use_continuous_quantile_head=True, # 連続分位点ヘッドの使用
force_flip_invariance=True, # フリップ不変性の強制
infer_is_positive=True, # 正値推論
fix_quantile_crossing=True, # 分位点交差の修正
)
)
# 入力データ
linear_input = np.linspace(0, 1, 100) # 線形トレンド
sine_input = np.sin(np.linspace(0, 20, 67)) # サイン波
# 予測の実行
point_forecast, quantile_forecast = model.forecast(
horizon=12, # 12ステップ先まで予測
inputs=[linear_input, sine_input],
)
# グラフの作成(2段構成)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 8))
for ax, data, pf, qf, title in [
(ax1, linear_input, point_forecast[0], quantile_forecast[0], "Linear Trend"),
(ax2, sine_input, point_forecast[1], quantile_forecast[1], "Sine Wave"),
]:
input_x = np.arange(len(data))
forecast_x = np.arange(len(data), len(data) + 12)
ax.plot(input_x, data, color="#2563eb", linewidth=1.5, label="Actual")
ax.plot(forecast_x, pf, color="#dc2626", linewidth=1.5, label="Point forecast")
# 分位点予測の信頼区間
ax.fill_between(forecast_x, qf[:, 0], qf[:, 8],
alpha=0.15, color="#dc2626", label="10-90 percentile")
ax.fill_between(forecast_x, qf[:, 2], qf[:, 6],
alpha=0.25, color="#dc2626", label="30-70 percentile")
ax.axvline(x=len(data) - 1, color="gray", linestyle="--", alpha=0.5)
ax.set_title(title)
ax.set_xlabel("Step")
ax.set_ylabel("Value")
ax.legend(loc="upper left")
ax.grid(True, alpha=0.3)
fig.suptitle("Zero-shot Forecasting with TimesFM 2.5", fontsize=14, y=1.01)
fig.tight_layout()
fig.savefig("basic_forecast.png", dpi=150, bbox_inches="tight")
実行すると以下のような出力が得られます。
$ python basic_forecast.py
ポイント予測の形状: (12,)
分位点予測の形状: (12, 10)
ポイント予測(線形トレンド): [1.0127583 1.0188394 1.0272744 1.0430083 1.0479412 1.059132 1.0746955
1.0754819 1.0890975 1.1027 1.1116321 1.1225947]
ポイント予測(サイン波): [ 0.9855352 0.97798777 0.8909132 0.72856337 0.47109857 0.1975782
-0.1051054 -0.39542517 -0.6310076 -0.83595407 -0.9664636 -1.0037618 ]
線形トレンドデータに対しては値が1.0から緩やかに上昇する予測が、サイン波データに対しては波形の続きを追従する予測が得られていることがわかります。matplotlibでグラフ化すると、予測の様子がより直感的に確認できます。
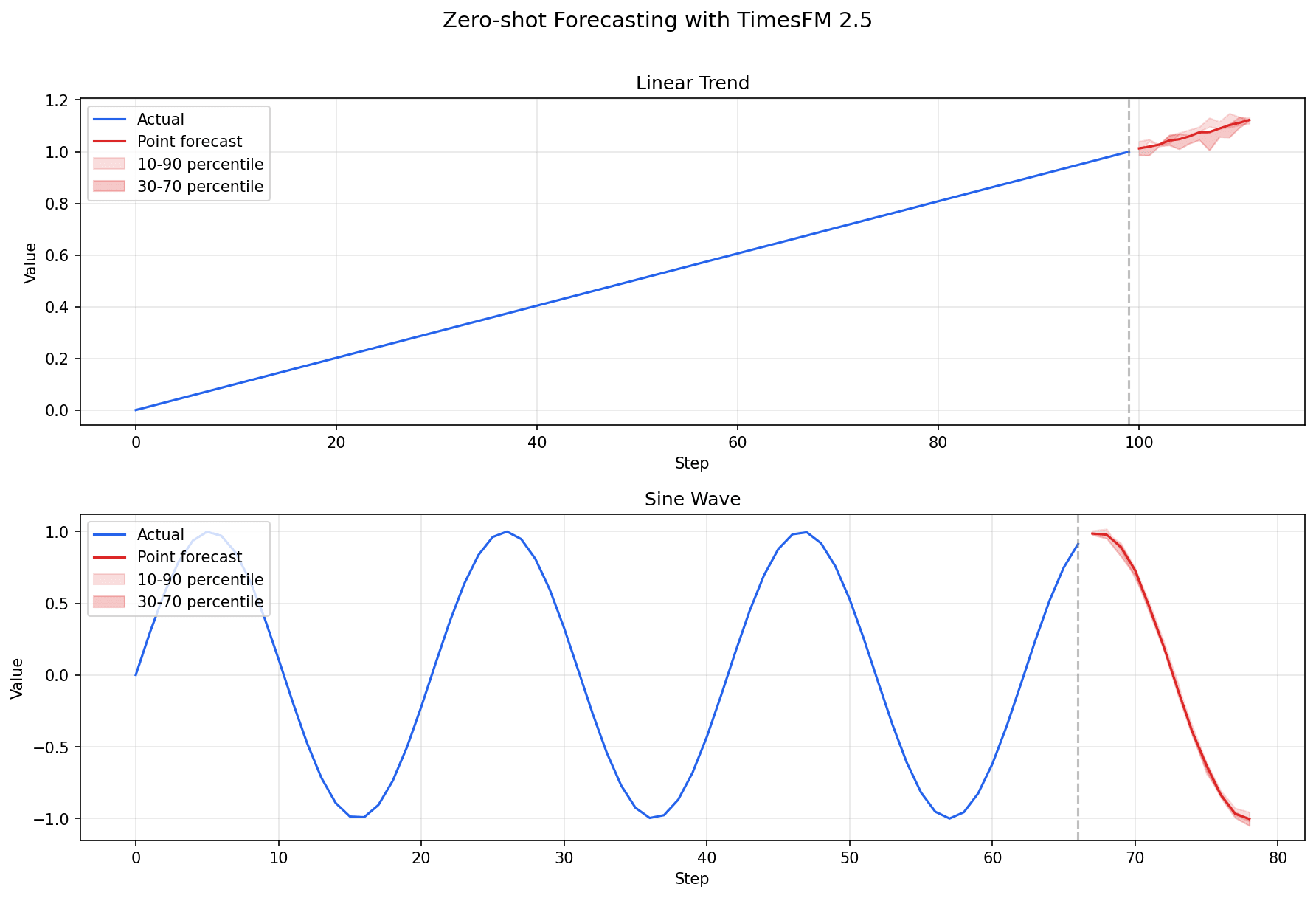
上段の線形トレンドでは上昇傾向がそのまま継続する予測が、下段のサイン波では波形パターンを正しく捉えた予測が得られていることが確認できます。また赤い帯で表示された信頼区間から、予測の不確実性も把握できます。
このコードのポイントは以下の点です。
TimesFM_2p5_200M_torch.from_pretrained()でHugging Faceからモデルを自動ダウンロードして読み込みます。初回実行時にモデルがダウンロードされ、以降はキャッシュが使用されますForecastConfigで予測時の各種設定を指定します。max_contextは入力として使用する最大の長さ、max_horizonは予測する最大のステップ数ですmodel.forecast()に予測したいステップ数horizonと入力データを渡して予測を実行します。入力はNumPy配列のリストで、複数の時系列を同時に渡すことができます- 戻り値は
point_forecast(ポイント予測)とquantile_forecast(分位点予測)のタプルです。分位点予測の形状が(12, 10)となっているのは、10〜90パーセンタイルの9つの分位点と平均値を含んでいるためです
pandasのDataFrameを使った予測
実務ではpandasのDataFrameで時系列データを扱うことが多いかと思います。model.forecast()はNumPy配列のリストを受け取るため、DataFrameから値を取り出して渡し、予測結果を再びDataFrameにまとめるという流れになります。
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import timesfm
torch.set_float32_matmul_precision("high")
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained(
"google/timesfm-2.5-200m-pytorch"
)
model.compile(
timesfm.ForecastConfig(
max_context=1024,
max_horizon=256,
normalize_inputs=True,
use_continuous_quantile_head=True,
force_flip_invariance=True,
infer_is_positive=True,
fix_quantile_crossing=True,
)
)
# サンプルデータの作成(ランダムウォーク)
dates = pd.date_range(start="2024-01-01", periods=100, freq="D")
np.random.seed(42)
values = np.cumsum(np.random.randn(100)) + 50
df = pd.DataFrame({
"ds": dates,
"y": values,
})
# DataFrameからNumPy配列を取り出して予測
point_forecast, quantile_forecast = model.forecast(
horizon=12,
inputs=[df["y"].values],
)
# 予測結果をDataFrameにまとめる
last_date = df["ds"].max()
forecast_dates = pd.date_range(
start=last_date + pd.Timedelta(days=1), periods=12, freq="D"
)
# グラフの作成
fig, ax = plt.subplots(figsize=(12, 5))
# 入力データ(実績) - 直近30日分を表示
display_start = 70
ax.plot(dates[display_start:], values[display_start:],
color="#2563eb", linewidth=1.5, label="Actual")
# ポイント予測
ax.plot(forecast_dates, point_forecast[0],
color="#dc2626", linewidth=1.5, label="Point forecast")
# 分位点予測の信頼区間
q10 = quantile_forecast[0][:, 0]
q90 = quantile_forecast[0][:, 8]
q30 = quantile_forecast[0][:, 2]
q70 = quantile_forecast[0][:, 6]
ax.fill_between(forecast_dates, q10, q90,
alpha=0.15, color="#dc2626", label="10-90 percentile")
ax.fill_between(forecast_dates, q30, q70,
alpha=0.25, color="#dc2626", label="30-70 percentile")
ax.axvline(x=dates[-1], color="gray", linestyle="--", alpha=0.5)
ax.set_xlabel("Date")
ax.set_ylabel("Value")
ax.set_title("Zero-shot Time Series Forecasting with TimesFM 2.5")
ax.legend(loc="upper left")
ax.grid(True, alpha=0.3)
fig.tight_layout()
fig.savefig("pandas_forecast.png", dpi=150)
実行すると以下のようなグラフが出力されます。
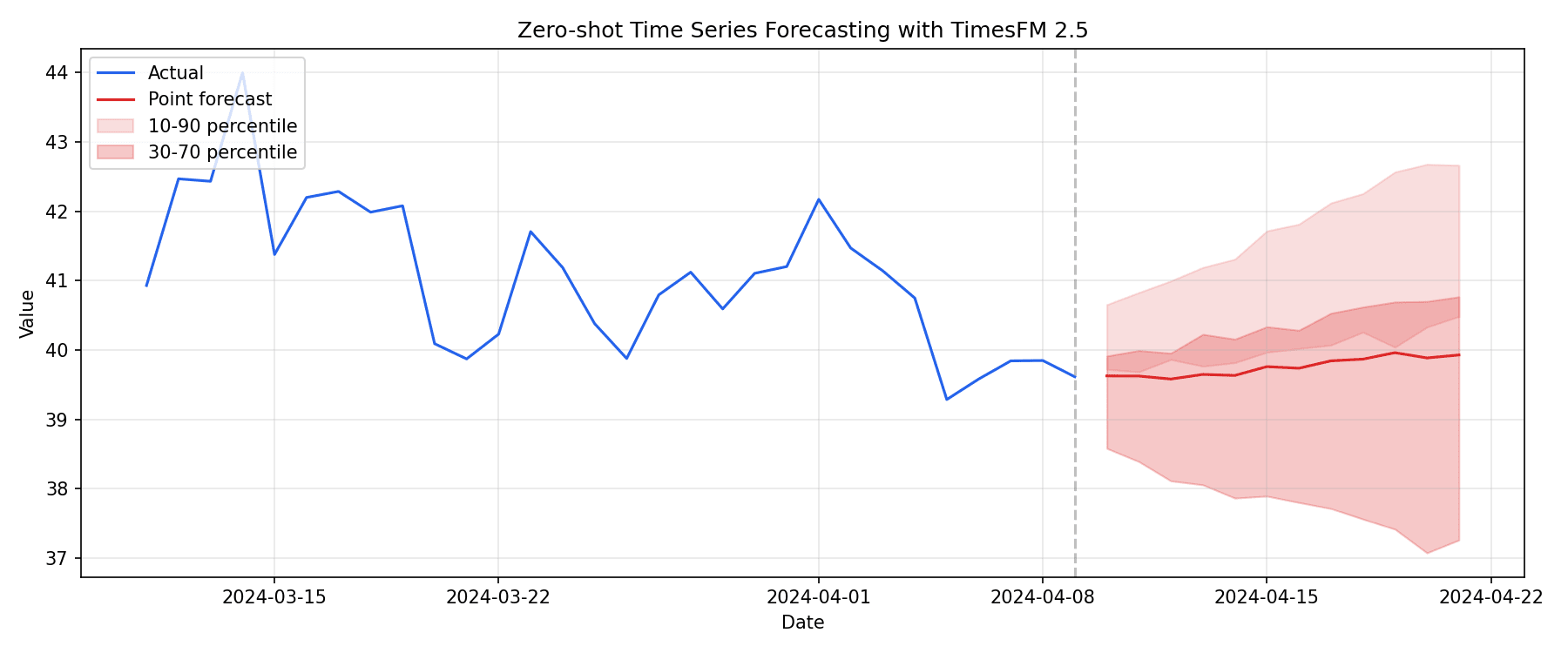
青線が実績データ、赤線がポイント予測、薄い赤の帯が分位点予測による信頼区間です。ランダムウォークのデータに対して直近の水準を維持しつつ緩やかに推移する予測が得られていることが確認できます。予測期間が先に進むほど信頼区間の幅が広がっており、将来の不確実性が増していく様子も視覚的に把握できます。
複数の時系列を同時に予測したい場合は、inputsリストに複数のNumPy配列を渡すだけで対応できます。
共変量(XReg)を使った予測
TimesFM 2.5では、外部変数(共変量)を組み込んだ予測もサポートされています。forecast_with_covariates()メソッドを使うことで、祝日フラグやプロモーション情報などの外部要因を考慮した予測が可能です。
共変量サポートを使用するには、追加のインストールが必要です。内部でJAXとscikit-learnが使用されます。
CUDA環境の場合はそのままtimesfm[xreg]でインストールできます。
$ uv pip install -e ".[xreg]"
Mac ARM環境などCUDAが利用できない環境では、timesfm[xreg]の依存関係にjax[cuda]が含まれているため古いバージョンのjaxがインストールされ、jaxlibとのバージョン不整合が起きることがあります。その場合は以下のようにjaxとjaxlibのバージョンを揃えた上でscikit-learnをインストールしてください。
$ uv pip install "jax>=0.9" "jaxlib>=0.9" scikit-learn
ここでは実データを使って共変量の効果を確認してみます。UCI Bike Sharing Datasetは2011-2012年の自転車レンタル日次データで、曜日(weekday)や気温(temp)といった共変量が含まれています。
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import timesfm
torch.set_float32_matmul_precision("high")
# UCI Bike Sharing Dataset の取得
url = "https://raw.githubusercontent.com/danwild/bike-share-prediction/master/Bike-Sharing-Dataset/day.csv"
df = pd.read_csv(url)
df["dteday"] = pd.to_datetime(df["dteday"])
# 最後30日をテスト期間として分割
horizon = 30
train_df = df.iloc[:-horizon]
test_df = df.iloc[-horizon:]
ts_data = train_df["cnt"].values.astype(float)
actual = test_df["cnt"].values
# モデルの準備
model = timesfm.TimesFM_2p5_200M_torch.from_pretrained(
"google/timesfm-2.5-200m-pytorch"
)
model.compile(
timesfm.ForecastConfig(
max_context=1024,
max_horizon=128,
normalize_inputs=True,
use_continuous_quantile_head=True,
force_flip_invariance=True,
infer_is_positive=True,
fix_quantile_crossing=True,
return_backcast=True, # XReg使用時に必要
)
)
# 通常の予測(共変量なし)
pf_normal, _ = model.forecast(horizon=horizon, inputs=[ts_data])
# return_backcast=Trueの場合、バックキャスト+予測が返るため末尾30が予測部分
pf_normal_h = pf_normal[0][-horizon:]
# 共変量付き予測(曜日 + 気温)
# 動的共変量は過去データ+予測期間分の全データを渡す
pf_xreg, _ = model.forecast_with_covariates(
inputs=[ts_data],
dynamic_numerical_covariates={
"temp": [df["temp"].values.tolist()],
},
dynamic_categorical_covariates={
"weekday": [df["weekday"].astype(str).tolist()],
},
xreg_mode="xreg + timesfm",
)
# MAE(平均絶対誤差)の計算
mae_normal = np.mean(np.abs(actual - pf_normal_h))
mae_xreg = np.mean(np.abs(actual - np.array(pf_xreg[0])))
# グラフの作成(通常予測との比較)
dates = df["dteday"].values
test_dates = test_df["dteday"].values
display_start = len(train_df) - 60
fig, ax = plt.subplots(figsize=(14, 5))
ax.plot(dates[display_start:len(train_df)],
df["cnt"].values[display_start:len(train_df)],
color="#2563eb", linewidth=1.5, label="Actual (train)")
ax.plot(test_dates, actual, color="#2563eb", linewidth=1.5,
linestyle=":", label="Actual (test)")
ax.plot(test_dates, pf_normal_h, color="#10b981", linewidth=1.5,
linestyle="--", label=f"TimesFM only (MAE={mae_normal:.0f})")
ax.plot(test_dates, pf_xreg[0], color="#dc2626", linewidth=1.5,
label=f"TimesFM + covariates (MAE={mae_xreg:.0f})")
# 休日をハイライト
for _, row in test_df.iterrows():
if row["workingday"] == 0:
ax.axvspan(row["dteday"] - pd.Timedelta(hours=12),
row["dteday"] + pd.Timedelta(hours=12),
alpha=0.08, color="orange")
ax.axvline(x=dates[len(train_df) - 1], color="gray", linestyle="--", alpha=0.5)
ax.set_xlabel("Date")
ax.set_ylabel("Bike Rentals")
ax.set_title("Bike Sharing Daily Demand: TimesFM vs TimesFM + Covariates")
ax.legend(loc="upper left")
ax.grid(True, alpha=0.3)
fig.tight_layout()
fig.savefig("xreg_forecast.png", dpi=150)
実行すると以下のようなグラフが得られます。
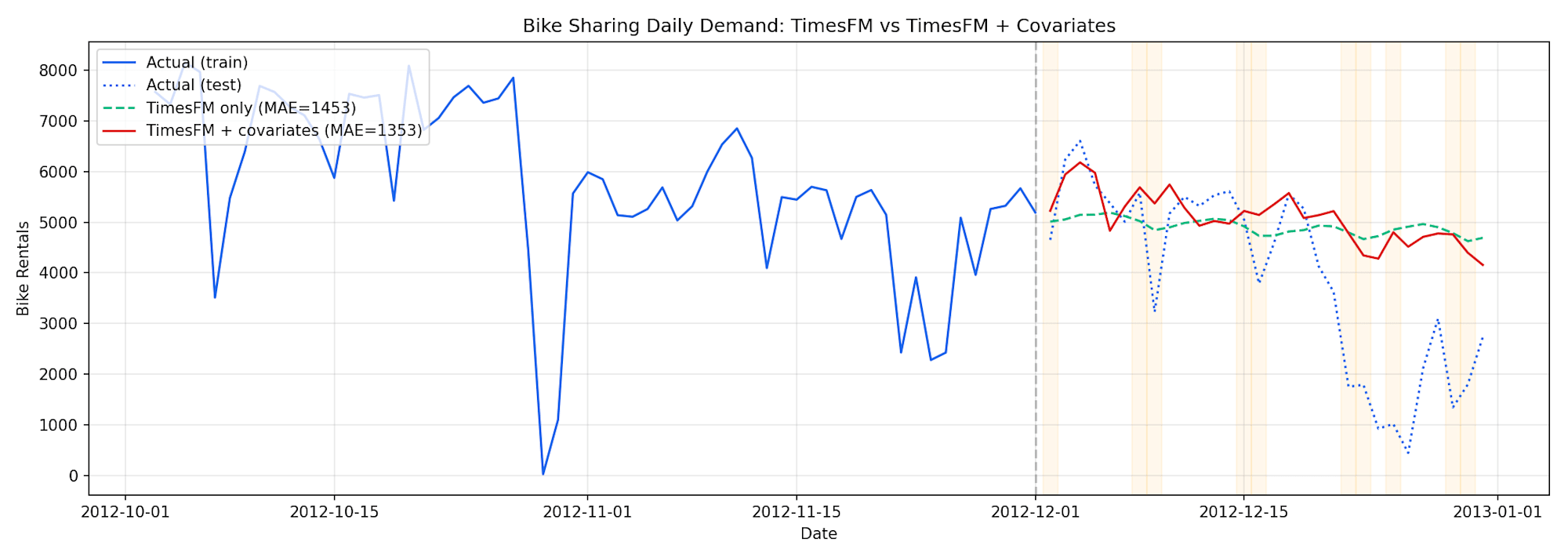
緑の破線がTimesFM単体の予測(MAE=1453)、赤の実線が共変量付きの予測(MAE=1353)です。共変量として曜日と気温を加えることで、MAEが約7%改善していることが確認できます。オレンジの帯は休日(週末)を示しており、共変量付きの予測では休日のレンタル数の落ち込みをより正確に捉えていることがわかります。
forecast_with_covariates()メソッドでは以下の4種類の共変量を指定できます。
| 共変量の種類 | パラメータ名 | 説明 |
|---|---|---|
| 動的数値共変量 | dynamic_numerical_covariates |
時間とともに変化する数値変数(例: 気温、価格) |
| 動的カテゴリカル共変量 | dynamic_categorical_covariates |
時間とともに変化するカテゴリ変数(例: 曜日、祝日フラグ) |
| 静的数値共変量 | static_numerical_covariates |
系列ごとに固定の数値(例: 店舗の面積) |
| 静的カテゴリカル共変量 | static_categorical_covariates |
系列ごとに固定のカテゴリ(例: 地域、店舗タイプ) |
動的共変量は過去のデータポイント分に加えて予測期間分のデータも含める必要があります。これにより将来の既知の外部要因(曜日、気温、祝日など)を予測に反映させることができます。
またxreg_modeパラメータで共変量の組み込み方を選択できます。"xreg + timesfm"は先に共変量の線形モデルをフィットしてからTimesFMで残差を予測し、"timesfm + xreg"はTimesFMの予測残差に対して線形モデルをフィットします。今回のケースでは"xreg + timesfm"の方が良い結果が得られました。
Hugging Faceで利用可能なモデル
TimesFMのモデルはHugging Face上で公開されており、用途に応じて選択できます。
| モデル | バックエンド | パラメータ数 | 用途 |
|---|---|---|---|
google/timesfm-2.5-200m-pytorch |
PyTorch | 200M | 最新版(PyTorch環境向け) |
google/timesfm-2.5-200m-flax |
Flax/JAX | 200M | 最新版(JAX環境向け) |
google/timesfm-2.0-500m-pytorch |
PyTorch | 500M | v2.0(より大きなモデル) |
google/timesfm-1.0-200m-pytorch |
PyTorch | 200M | v1.0 |
BigQueryとの統合
TimesFMはGoogle Cloud BigQueryのML機能とも統合されており、SQLから直接時系列予測を実行することも可能です。BigQuery上の大規模な時系列データに対して、データの移動なしに予測を適用できるため、本番環境でのデプロイが容易になります。
まとめ
Google Researchが開発した時系列予測の基盤モデルTimesFMを試してみました。
TimesFMの大きな魅力は、ファインチューニングなしでゼロショット予測が可能な点です。従来の時系列予測では、データセットごとにモデルの選定やハイパーパラメータのチューニングが必要でしたが、TimesFMではモデルを読み込んでデータを渡すだけで予測ができます。
また最新のv2.5ではパラメータ数が200Mに抑えられつつコンテキスト長が最大16,000まで拡大されており、より長い時系列データに対しても効率的に予測が行えるようになっています。分位点予測による不確実性の定量化や、共変量サポートによる外部要因の組み込みなど、実務で求められる機能も備わっています。
時系列予測のタスクで手軽に高精度な予測を試したい場合に、ぜひ活用してみてください。
最後まで読んでいただきありがとうございました。









