
【Redshift】 MCP ServerとClaude Codeを利用して自然言語でデータの読み書きをしてみた
データ事業本部のueharaです。
今回は、Redshift MCP ServerとClaude Codeを利用して自然言語でデータの読み書きをしてみたいと思います。
はじめに
AWS Samplesから、RedshiftのMCP Serverのサンプル実装を発見しました。
今回はこちらのMCP ServerをClaude Codeと共に用いて、Redshiftにアクセスしてみたいと思います。
リポジトリのREADMEを確認すると、以下のような用途に使用できそうです。
- Redshiftデータベース内のスキーマとテーブルを一覧表示する
- テーブルのDDL(データ定義言語)スクリプトを取得する
- テーブルの統計情報を取得する
- SQLクエリを実行する
- 統計情報を収集するためにテーブルを分析する
- SQLクエリの実行計画を取得する
構成について
MCP Serverはローカルで動作させます。
Redshiftはプライベートサブネットで動作させたいので、AWS SSMのポートフォワーディング機能を用いてリモートホストへ安全にアクセスする形を取りたいと思います。
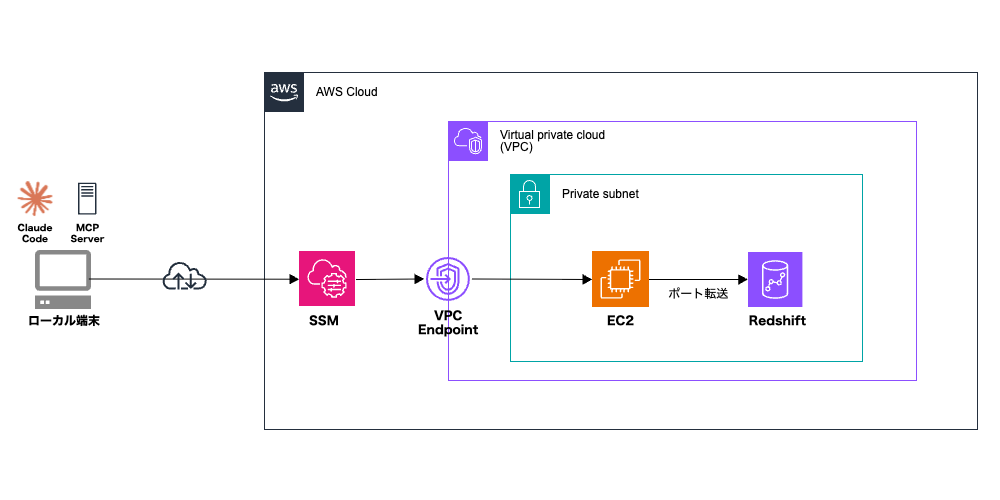
※なお、本記事ではRedshiftやEC2等の作成については割愛させて頂きます。
前提
今回、Redshiftでは以下のテーブルを用意しています。
CREATE TABLE customers (
customer_id INTEGER NOT NULL,
customer_name VARCHAR(100) NOT NULL,
email VARCHAR(100),
city VARCHAR(50),
registration_date DATE,
PRIMARY KEY (customer_id)
);
INSERT INTO customers (customer_id, customer_name, email, city, registration_date) VALUES
(1, '田中太郎', 'tanaka@example.com', '東京', '2023-01-15'),
(2, '佐藤花子', 'sato@example.com', '大阪', '2023-02-20'),
(3, '鈴木一郎', 'suzuki@example.com', '名古屋', '2023-03-10'),
(4, '高橋美咲', 'takahashi@example.com', '福岡', '2023-04-05'),
(5, '山田健太', 'yamada@example.com', '札幌', '2023-05-12');
CREATE TABLE orders (
order_id INTEGER NOT NULL,
customer_id INTEGER NOT NULL,
product_name VARCHAR(100) NOT NULL,
quantity INTEGER NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
order_date DATE NOT NULL,
PRIMARY KEY (order_id),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
INSERT INTO orders (order_id, customer_id, product_name, quantity, unit_price, order_date) VALUES
(101, 1, 'ノートパソコン', 1, 89800.00, '2023-06-01'),
(102, 1, 'マウス', 2, 2500.00, '2023-06-01'),
(103, 2, 'キーボード', 1, 8900.00, '2023-06-03'),
(104, 3, 'モニター', 1, 45000.00, '2023-06-05'),
(105, 2, 'スピーカー', 1, 12000.00, '2023-06-07'),
(106, 4, 'Webカメラ', 1, 7800.00, '2023-06-10'),
(107, 1, 'ヘッドセット', 1, 15600.00, '2023-06-12'),
(108, 5, 'タブレット', 1, 32000.00, '2023-06-15'),
(109, 3, 'プリンター', 1, 25000.00, '2023-06-18'),
(110, 2, 'USBメモリ', 3, 1200.00, '2023-06-20');
準備
MCP Serverの用意
適当な作業ディレクトリを作成し、冒頭のGitHubのリポジトリからCloneを行います。
$ git clone https://github.com/aws-samples/sample-amazon-redshift-MCP-server.git
Cloneが完了したらフォルダを移動し、 uv (Pythonのパッケージマネージャー)を用いて依存関係のインストールを行います。
$ cd sample-amazon-redshift-MCP-server
$ uv sync
以上で完了です。
Claude Codeの設定ファイルの用意
sample-amazon-redshift-MCP-server のディレクトリから1つ階層を戻り、以下のような .claude/mcp.json を作成します。
{
"mcpServers": {
"redshift": {
"command": "uv",
"args": ["--directory", "sample-amazon-redshift-MCP-server/src/redshift_mcp_server", "run", "server.py"],
"env": {
"RS_HOST": "localhost",
"RS_PORT": "5439",
"RS_USER": "your_username",
"RS_PASSWORD": "your_password",
"RS_DATABASE": "your_database",
"RS_SCHEMA": "your_schema"
}
}
}
}
環境変数を設定する env にはRedshiftの接続情報を記載します。
冒頭で述べた通り今回はSSMのポートフォワーディングを用いるため、ホスト( RS_HOST )には localhost を設定しています。
ユーザー名やパスワード等、接続情報についてはご自身の環境に合わせて設定して下さい。
リモートホストへのポートフォワーディング
以下のコマンドを実行して、SSMを利用してリモートホストへのポートフォワーディングを行います。
$ aws ssm start-session \
--profile <YOUR AWS PROFILE> \
--target <YOUR INSTANCE ID> \
--region ap-northeast-1 \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters '{"host":["<YOUR REDSHIFT HOST>"],"portNumber":["5439"], "localPortNumber":["5439"]}'
上記はローカルの 5439 番のポートを、リモートホスト(Redshift)の 5439 番のポートへフォワーディングするようなものになっています。
上記コマンド実行し、以下のように接続が待機されていれば準備完了です。
Starting session with SessionId: botocore-session-xxx
Port 5439 opened for sessionId botocore-session-xxx.
Waiting for connections...
実行してみた
以下のように、前章の「準備」で作成したMCPのconfigファイルを指定してClaude Codeを起動します。
$ claude --mcp-config=.claude/mcp.json
なお、本MCP Serverについて利用可能なtoolは以下のようでした。
Redshift (MCP)
- mcp__redshift__execute_sql - SQL実行
- mcp__redshift__analyze_table - テーブル分析
- mcp__redshift__get_execution_plan - 実行計画取得
テーブル一覧の取得
まずはテーブルの一覧を取得するよう依頼してみます。
> テーブルの一覧が知りたい
結果は以下の通りで、一覧が取得できました。
> テーブルの一覧が知りたい
⏺ redshift:execute_sql (MCP)(sql: "SELECT schemaname, tablename \nFROM pg_tables \nWHERE
schemaname NOT IN ('information_schema',
'pg_catalog')\nORDER BY schemaname, tablename;")
⎿ schemaname,tablename
pg_internal,redshift_auto_health_check_13608294
public,customers
… +1 line (ctrl+r to expand)
⏺ 利用可能なテーブル:
- public.customers
- public.orders
- pg_internal.redshift_auto_health_check_13608294 (内部テーブル)
テーブル定義の取得
次に、テーブル定義を聞いてみます。
> customersテーブルの定義を教えて
結果は次の通りで、こちらも問題無く結果を抽出できました。
> customersテーブルの定義を教えて
⏺ redshift:execute_sql (MCP)(sql: "SELECT \n column_name,\n data_type,\n
is_nullable,\n column_default,\n
character_maximum_length\nFROM information_schema.columns
\nWHERE table_schema = 'public' \n AND table_name =
'customers'\nORDER BY ordinal_position;")
⎿ column_name,data_type,is_nullable,column_default,character_maximum_length
customer_id,integer,NO,None,None
customer_name,character varying,NO,None,100
… +3 lines (ctrl+r to expand)
⏺ customersテーブルの定義:
- customer_id (integer, NOT NULL)
- customer_name (varchar(100), NOT NULL)
- email (varchar(100), NULL)
- city (varchar(50), NULL)
- registration_date (date, NULL)
テーブルデータの取得
次にテーブルデータの取得のためのクエリ実行が必要な内容を問い合わせてみます。
> 顧客名とそれぞれの顧客について注文の合計数が知りたい
以下の通り、適切にJOINを行い結果を抽出していることが分かります。
> 顧客名とそれぞれの顧客について注文の合計数が知りたい
⏺ redshift:execute_sql (MCP)(sql: "SELECT \n c.customer_name,\n
COALESCE(COUNT(o.order_id), 0) as total_orders\nFROM
public.customers c\nLEFT JOIN public.orders o ON
c.customer_id = o.customer_id\nGROUP BY c.customer_id,
c.customer_name\nORDER BY total_orders DESC,
c.customer_name;")
⎿ customer_name,total_orders
佐藤花子,3
田中太郎,3
… +3 lines (ctrl+r to expand)
⏺ 顧客名と注文合計数:
- 佐藤花子: 3件
- 田中太郎: 3件
- 鈴木一郎: 2件
- 山田健太: 1件
- 高橋美咲: 1件
SQLファイルの作成
テーブルデータを元に、SQLファイルそのものを作成してもらいます。
> customersテーブルとordersテーブルを結合して、ユーザー毎の注文が見れるSQLファイルを作成して。
結果、 customer_orders.sql ファイルが作成されました。
> customersテーブルとordersテーブルを結合して、ユーザー毎の注文が見れるSQLファイルを作成して。
⏺ Update Todos
⎿ ☐ ordersテーブルの構造を確認
☐ customers-ordersを結合するSQLファイルを作成
⏺ Update Todos
⎿ ☐ ordersテーブルの構造を確認
☐ customers-ordersを結合するSQLファイルを作成
⏺ redshift:execute_sql (MCP)(sql: "SELECT \n column_name,\n data_type,\n is_nullable,\n
column_default,\n character_maximum_length\nFROM
information_schema.columns \nWHERE table_schema = 'public' \n AND
table_name = 'orders'\nORDER BY ordinal_position;")
⎿ column_name,data_type,is_nullable,column_default,character_maximum_length
order_id,integer,NO,None,None
customer_id,integer,NO,None,None
… +4 lines (ctrl+r to expand)
⏺ Update Todos
⎿ ☒ ordersテーブルの構造を確認
☐ customers-ordersを結合するSQLファイルを作成
⏺ Write(customer_orders.sql)
⎿ Wrote 33 lines to customer_orders.sql
-- ユーザー毎の注文詳細を表示するクエリ
-- customers テーブルと orders テーブルを結合
SELECT
c.customer_id,
c.customer_name,
c.email,
c.city,
c.registration_date,
o.order_id,
… +23 lines (ctrl+r to expand)
⏺ Update Todos
⎿ ☒ ordersテーブルの構造を確認
☒ customers-ordersを結合するSQLファイルを作成
⏺ customer_orders.sql
ファイルを作成しました。ユーザー毎の注文詳細と統計の両方のクエリが含まれています。
作成されたSQLファイルの中身は以下の通りです。
-- ユーザー毎の注文詳細を表示するクエリ
-- customers テーブルと orders テーブルを結合
SELECT
c.customer_id,
c.customer_name,
c.email,
c.city,
c.registration_date,
o.order_id,
o.product_name,
o.quantity,
o.unit_price,
(o.quantity * o.unit_price) AS total_amount,
o.order_date
FROM public.customers c
LEFT JOIN public.orders o ON c.customer_id = o.customer_id
ORDER BY c.customer_name, o.order_date DESC;
-- ユーザー毎の注文統計
-- SELECT
-- c.customer_id,
-- c.customer_name,
-- c.email,
-- c.city,
-- COUNT(o.order_id) as total_orders,
-- COALESCE(SUM(o.quantity * o.unit_price), 0) as total_spent,
-- MIN(o.order_date) as first_order_date,
-- MAX(o.order_date) as last_order_date
-- FROM public.customers c
-- LEFT JOIN public.orders o ON c.customer_id = o.customer_id
-- GROUP BY c.customer_id, c.customer_name, c.email, c.city
-- ORDER BY total_spent DESC;
テーブルの作成とデータ挿入
次にテーブルの作成とデータ挿入を依頼してみます。
> customersテーブルの定義を元に、テスト用のcustomers_testテーブルを作成して。データは50件程度用意して入れて欲しいです。
結果は長くなったので一部省略しますが、 customers_test テーブルを作成できました。
(省略)
⏺ redshift:execute_sql (MCP)(sql: "SELECT COUNT(*) as total_records FROM public.customers_test;")
⎿ total_records
50
⏺ customers_testテーブルを作成し、50件のテストデータを挿入しました。
念のためクエリエディタから確認してみましたが、以下のように期待したデータが作成されていることが確認できました。
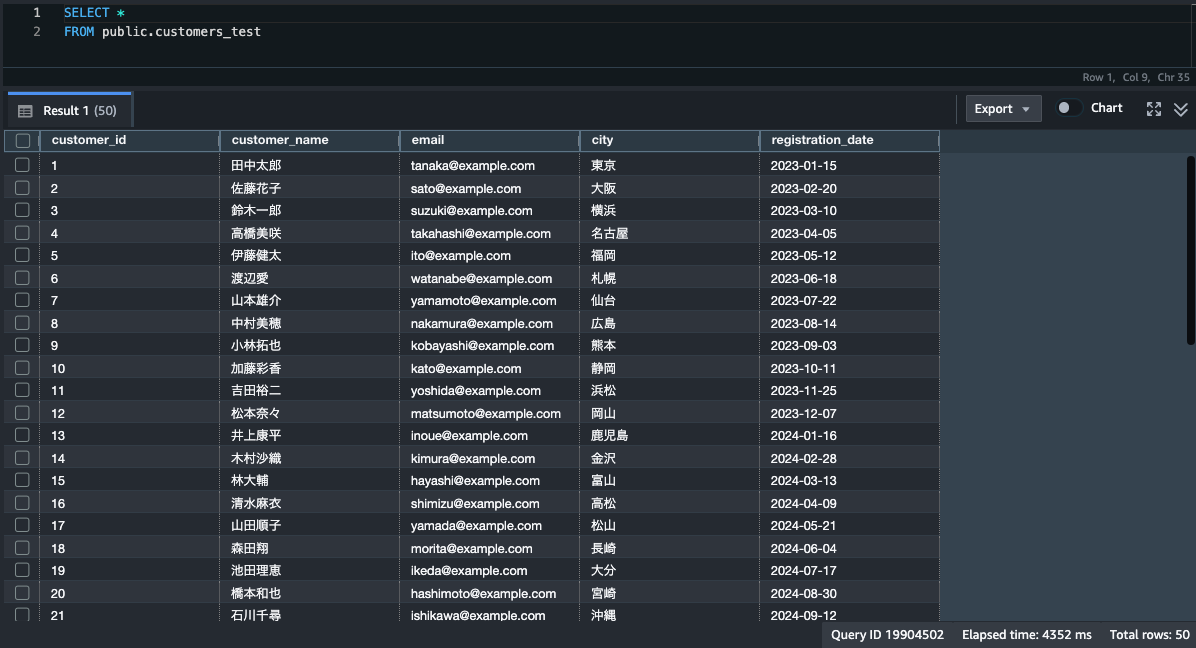
最後に
今回は、Redshift MCP ServerとClaude Codeを利用して自然言語でデータの読み書きをしてみました。
DWHとMCP Serverを利用することで、データ内容の理解/データ分析のためのSQL作成/テストデータの作成等を非常に効率良くできるようになることを実感しました。
参考になりましたら幸いです。









