
Amazon Redshift Serverless 簡単分析セルフハンズオンやってみた
2026.02.04
今回は、こちらのワークショップを実施しました。
ざっくりまとめ
- 所要時間:30 - 40分
- 使用するサービス:Amazon Redshift Serverless、AWS CloudShell、Amazon S3
- 必要な作業:Redshift Serverless の作成、S3 バケットの作成、IAM ロールの作成
事前準備
サンプルデータファイルの準備
-
AWS マネジメントコンソールのナビゲーションバーで、CloudShell アイコンを選択し、CloudShell を起動します。
-
以下のコマンドを実行し、サンプルデータファイル を S3 にアップロードするためのスクリプトをダウンロードします。
curl -O "https://ws-assets-prod-iad-r-iad-ed304a55c2ca1aee.s3.us-east-1.amazonaws.com/566245ec-486c-4b2c-9e94-d431f67316c1/script/setup_workshop_data.py"
- 以下のコマンドを実行し、テーブル定義ファイル と サンプルデータファイル を S3 へアップロードします。
python3 ./setup_workshop_data.py --region ${AWS_REGION}
- S3 バケット(例:20260101-redshift-serverless-qs-{アカウントID}-ap-northeast-1)が作成され、ファイルがアップロードされていることを確認します。
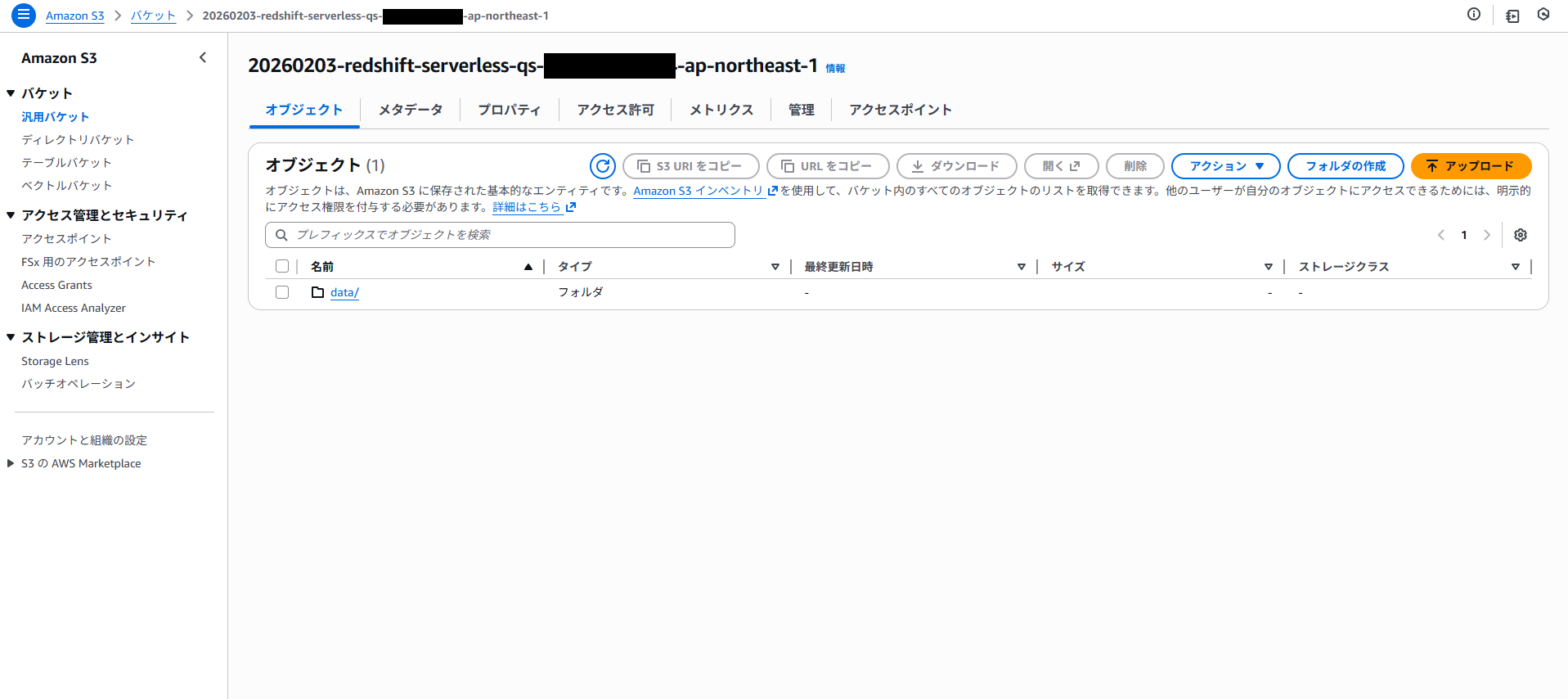
テーブル定義ファイルのダウンロード
テーブル定義ファイル(definition_profit_and_loss.csv)をダウンロードします。
ステップ 1:Amazon Redshift Serverless の作成
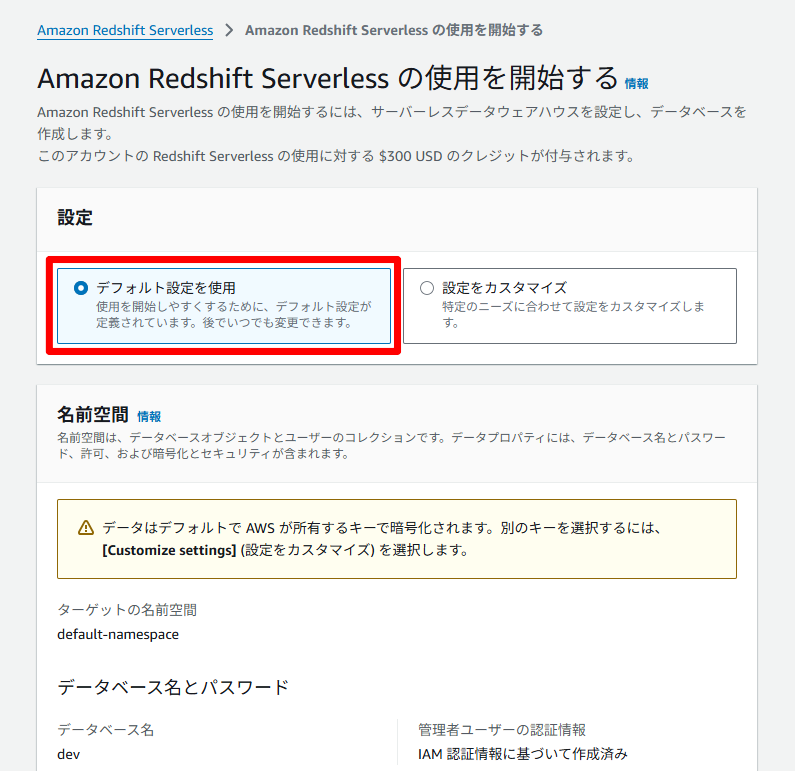
- 設定 で [デフォルト設定を使用] を選択します。
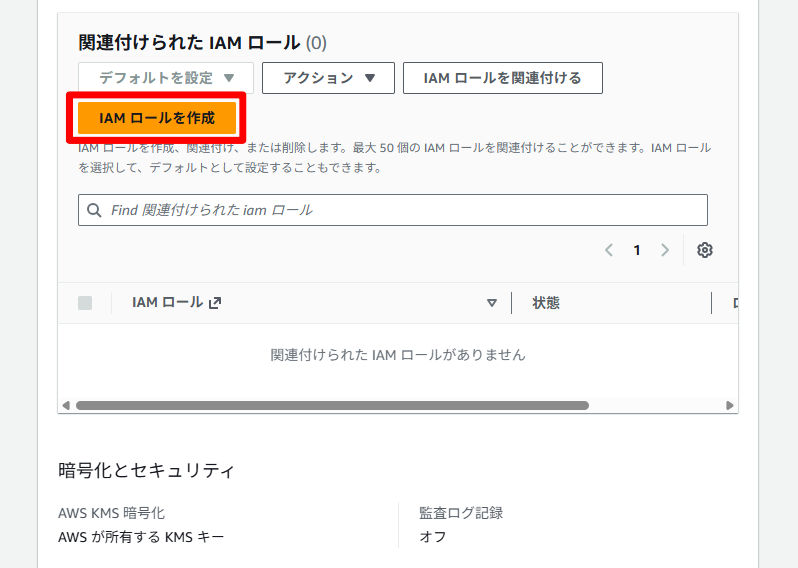
- [IAM ロールを作成] をクリックします。
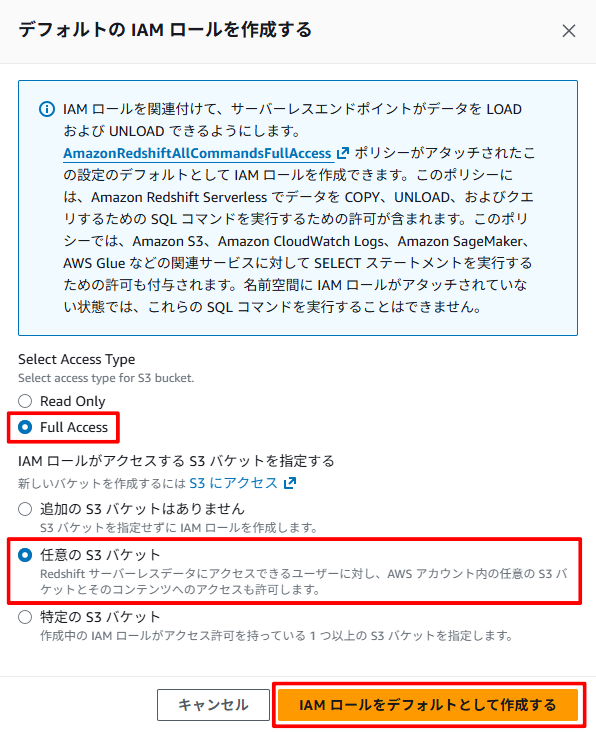
- [Full Access][任意の S3 バケット] を選択し、[IAM ロールをデフォルトとして作成する] をクリックします。
- IAM ロールが作成され、[関連付けられた IAM ロール] に表示されたことを確認します。
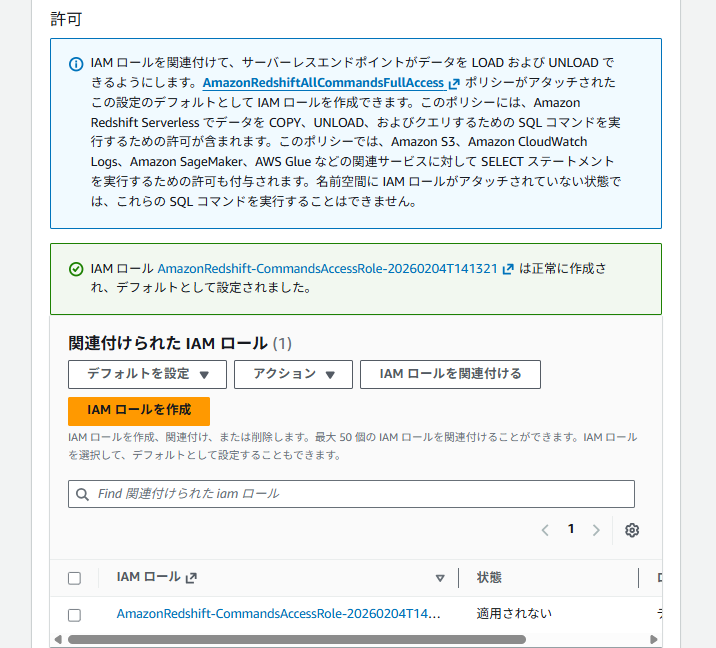
- [設定を保存] をクリックします。
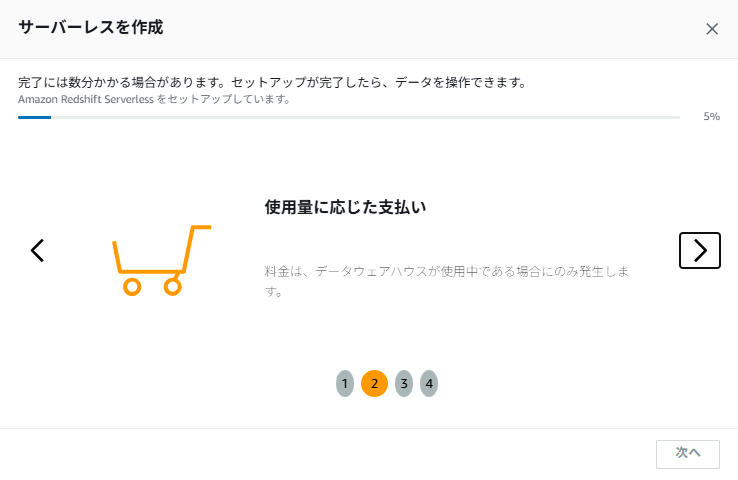
以下のような画面が表示され、セットアップが開始されます。2、3 分程で作成されました。
ステップ 2:テーブルの作成
データをロードするためのテーブルを作成していきます。
-
Amazon Redshift コンソールのナビゲーションペインで [クエリエディタ v2] を選択し、クエリエディタを起動します。
-
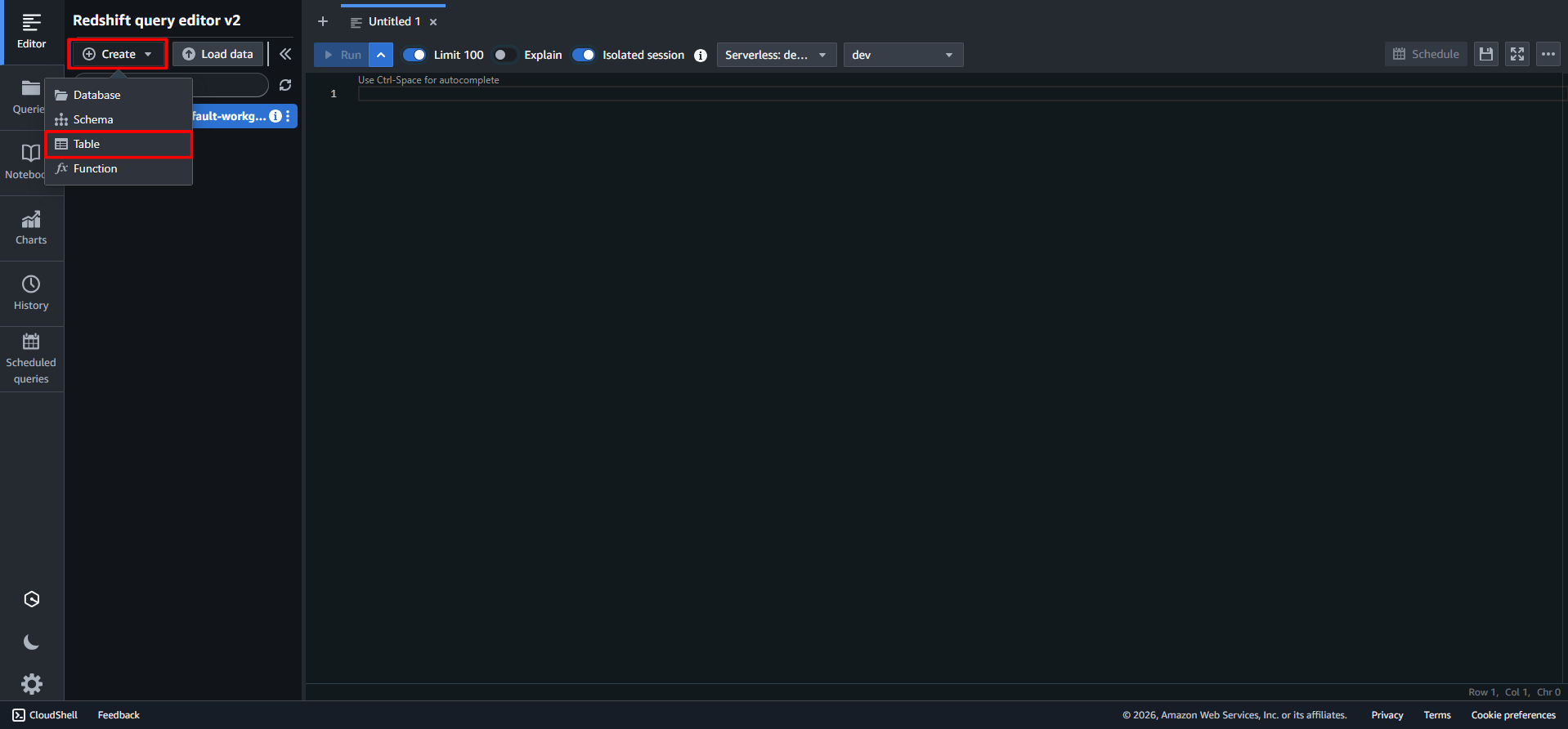
画面左上の [Create] をクリックし、ドロップダウンリストから [Table] を選択します。
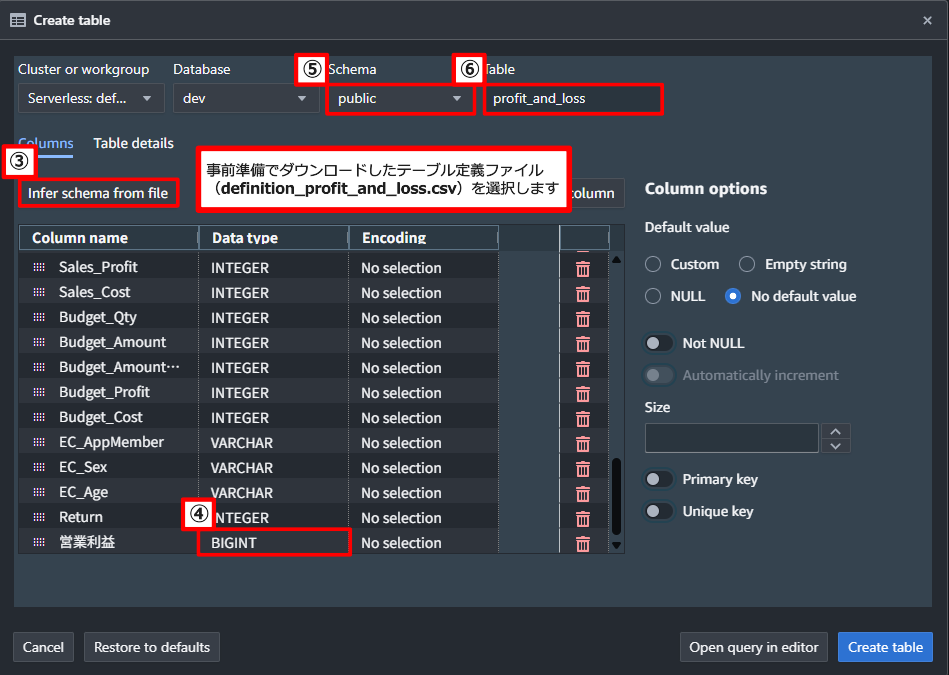
- [Infer schema from file] をクリックし、事前準備でダウンロードしたテーブル定義ファイル(definition_profit_and_loss.csv)を選択します。
- テーブル定義ファイルが読み込まれると、カラム名とデータ型が自動入力されるので、カラム名 [営業利益] のデータ型に [BIGINT] を選択します。
- Schema のドロップダウンメニューから [public] を選択します。
- Table 欄に テーブル名 [profit_and_loss] を入力します。
- [Create table] をクリックします。
ステップ 3:データのロード
先程作成したテーブルにデータをロードしていきます。
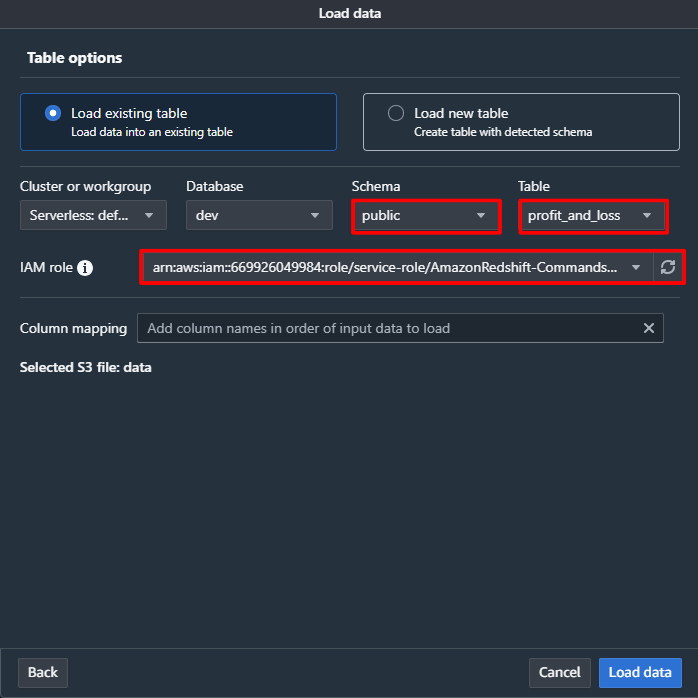
- 画面左上の [Load data] をクリックします。
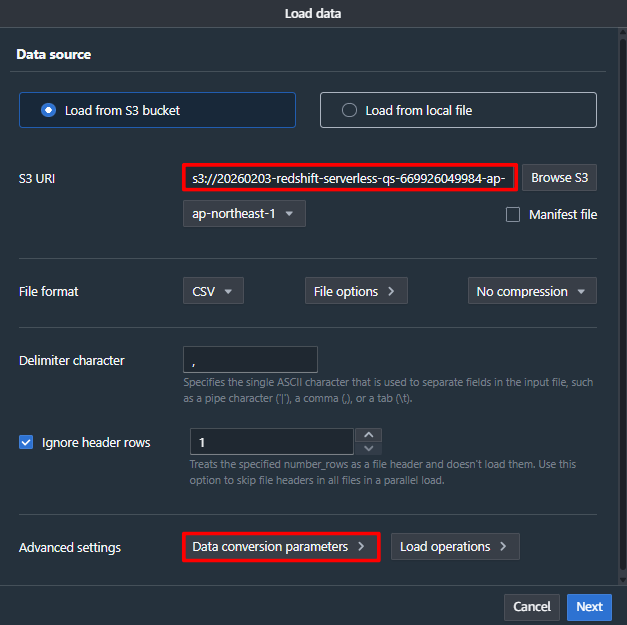
- S3 URI の [Browse S3] をクリックし、事前準備で作成された S3 バケットを選択します。
- Advanced settings の [Data conversion parameters] をクリックします。
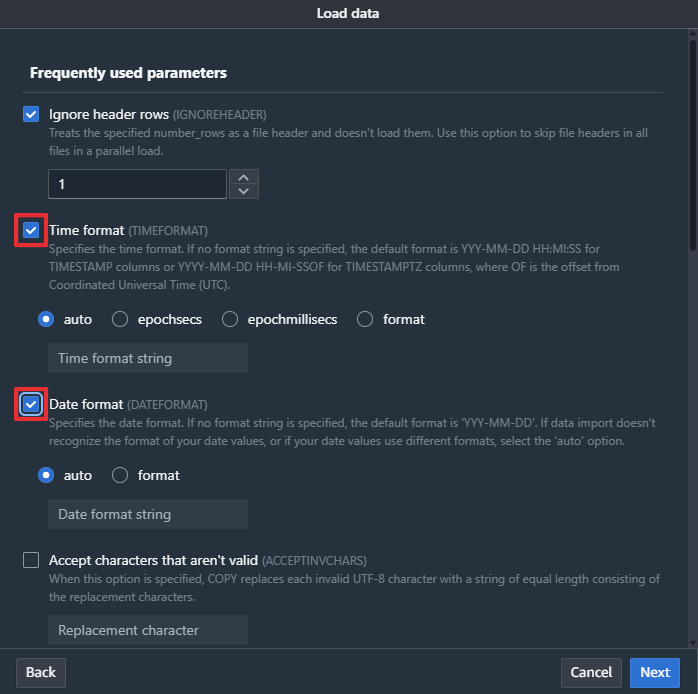
- [Time format] と [Date format] の左側のチェックボックスをチェックし、[Next] をクリックします。
- Schema のドロップダウンメニューから [public]、Table のドロップダウンメニューから [profit_and_loss] を選択します。
- IAM role の [Choose an IAM role] をクリックし、ドロップダウンメニューから選択可能なロールの ARN を選択します。
- [Load data] をクリックします。
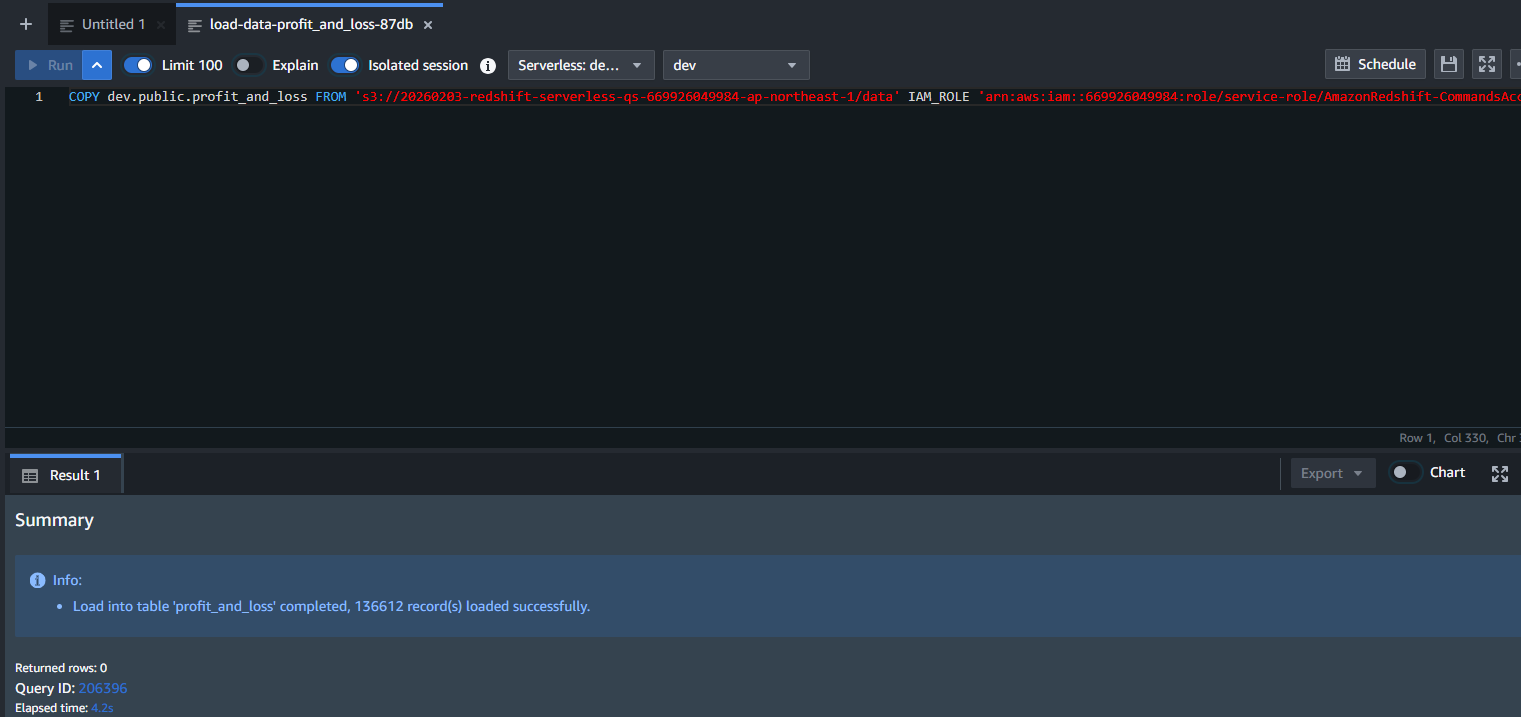
SQL 文の COPY コマンドが自動生成・実行されます。結果は以下の通りです。
ステップ 4:データのロード結果の確認
-
画面上部のクエリエディタのタブ [Untiteled 1] を選択し、未入力のエディタを開きます。
-
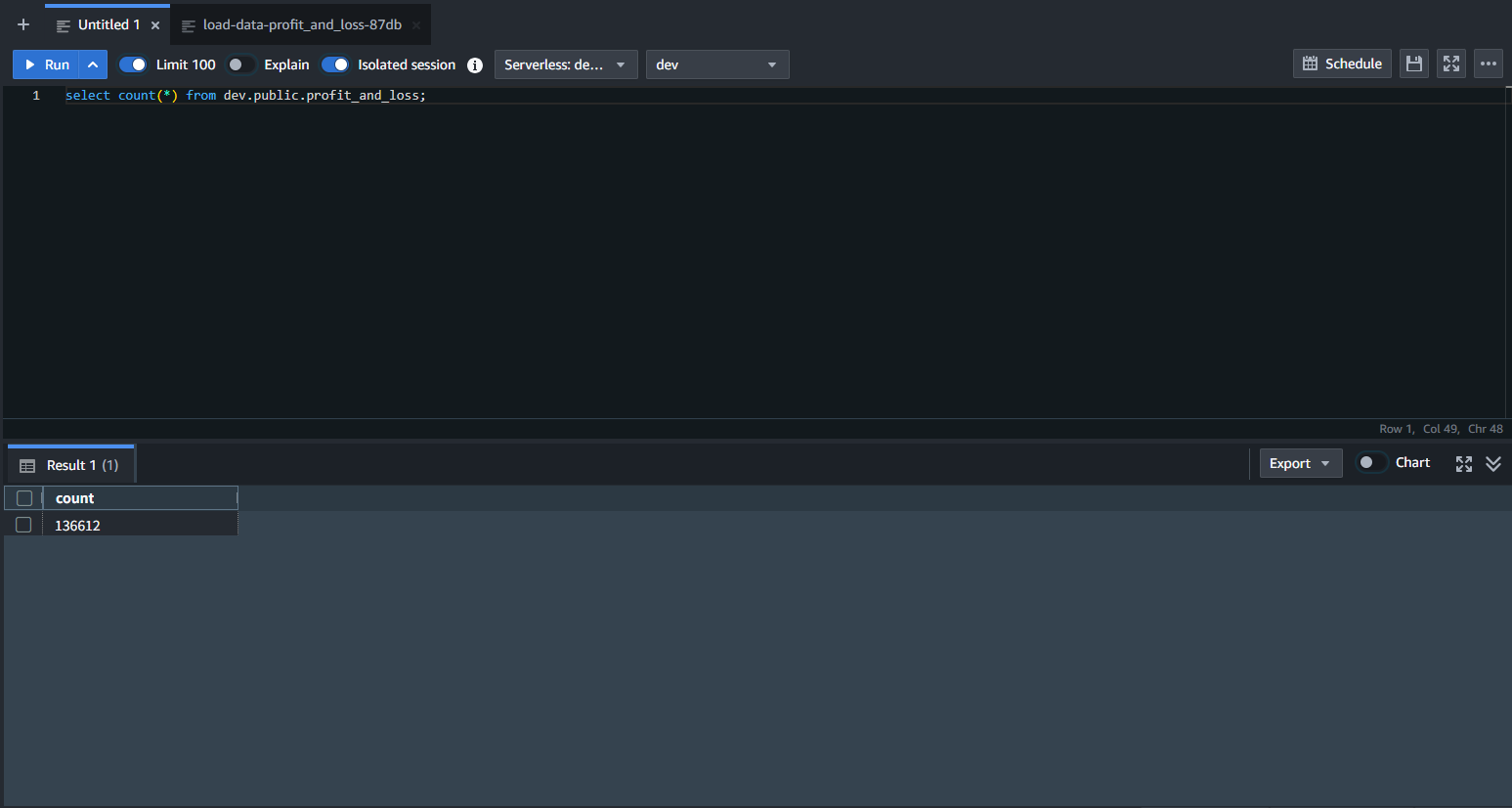
以下の SQL をコピーし、エディタに貼り付け ▶Run を選択します。
select count(*) from dev.public.profit_and_loss;
結果は以下の通りです。
最後に
30 分程度で Redshift Serverless の全体像が掴める、初心者におすすめのワークショップでした。
次回は、Amazon QuickSight と連携させてデータの可視化を試してみようと思います。










