![How Hotstar.com dealt with 25 million concurrent viewers which became the world record #reinvent [CMY302]](https://devio2023-media.developers.io/wp-content/uploads/2019/12/reinvent2019_report_eyecatch.jpg)
How Hotstar.com dealt with 25 million concurrent viewers which became the world record #reinvent [CMY302]
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
This post is the session report about CMY302: Scaling Hotstar.com for 25 million concurrent viewers at AWS re:Invent 2019.
日本語版はこちらです。
Abstract
This session focuses on why traditional autoscaling doesn't work for Hotstar (Disney's OTT streaming service), who recently created a global record for live streaming to 25.3 million concurrent viewers. We talk about challenges in scaling infrastructure for millions and how to overcome them, how Hotstar runs gamedays before facing live games, how it uses a load-testing monster called Hulk to prepare its platform for 50M peak. We also learn how the company uses chaos engineering to overcome real-world problems and achieve this scale.
Speaker
- Gaurav Kamboj
- Cloud Architect, Hotstar
Hotstar is the Indian over-the-top (OTT) platform and currently offers over 100,000 hours of TV content and movies across 9 languages, and every major sport covered live. On 10th July, 2019, the number of concurrent viewers reached 25.3 million which broke its own previous world record of 18.6 million. How did Hotstar deal with that huge number of concurrency accesses?

Contents
About Hotstar
- Disney-owened #1 OTT platform in India
- Over 350 million downloads
- 1 day, more than 100 million unique users, which is during the weekend, India vs. New Zealand
- Available in more than 15 languages
- Variety of content
- Live/on-demand
- Sports/news/TV/movies
- Regional catalogues
Concurrency pattern
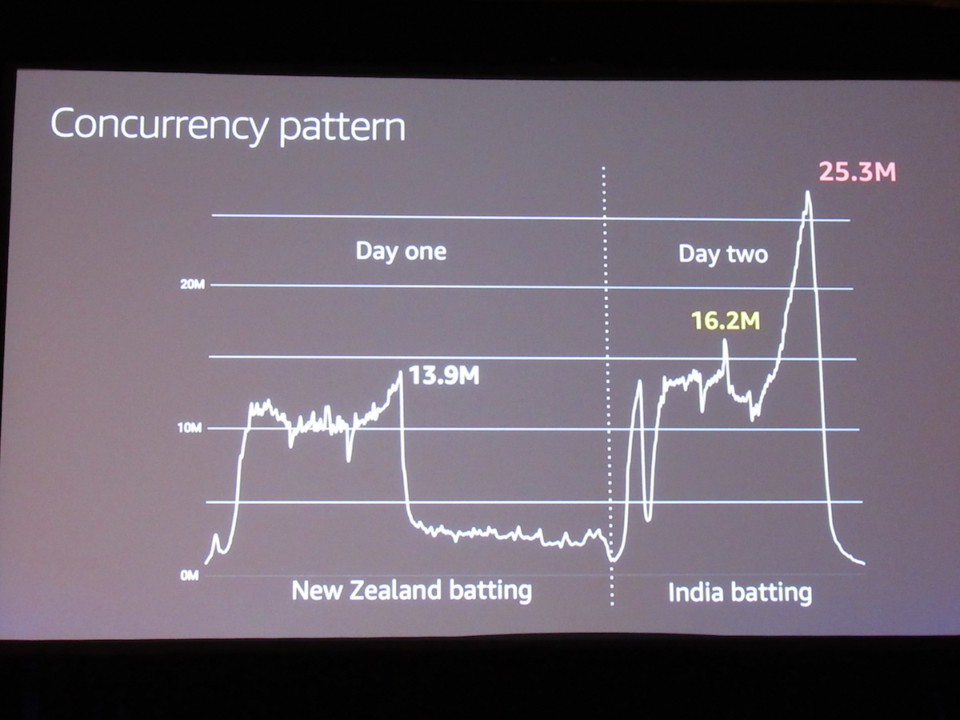
- India vs. New Zealand
- The 13.9 million number is the first peak before it started raining, and the game was postponed to tehe next day
- Finally, the number of concurrent viewers reached to 25.3 million, which updated the glocal record
Let’s talk about scale
- 25M+: Peak concurrency Ind vs NZ - World Cup 2019
- 1M+: Peak R\requests per second
- 10Tbps+: Peak bandwidth consumption
- Consume 70-75% of India's Internet bandwidth and 70% of Internet bandwidth
- 10B+: Clickstram messages
Why is that big number?
- 8M: Felix Baumgartner’s Supersonic Jump Youtube
- 3.1M: Super Bowl NBC Sports App
- 10.3M: IPL 2018: Final Hotstar
- 18.6M: IPL 2019: Final Hotstar
- 25.3M: Worldcup Ind vs New Zealand hotstar
Game Day
- Face the real game before actual game
- Project HULK
- Load Generation
- Performance $ Tsunami tests
- Chaos Engineering
- Traffic pattern using ML
- 108,000 CPU
- 216 TB
- 200 Gbps Network out
- 8 regions Geo distributed
- Note that it is in a public cloud, network is shared among all the customer, so needed to be mindful of that
- The loads from where our traffic was flowing has caused an outage
Load Generation Arch
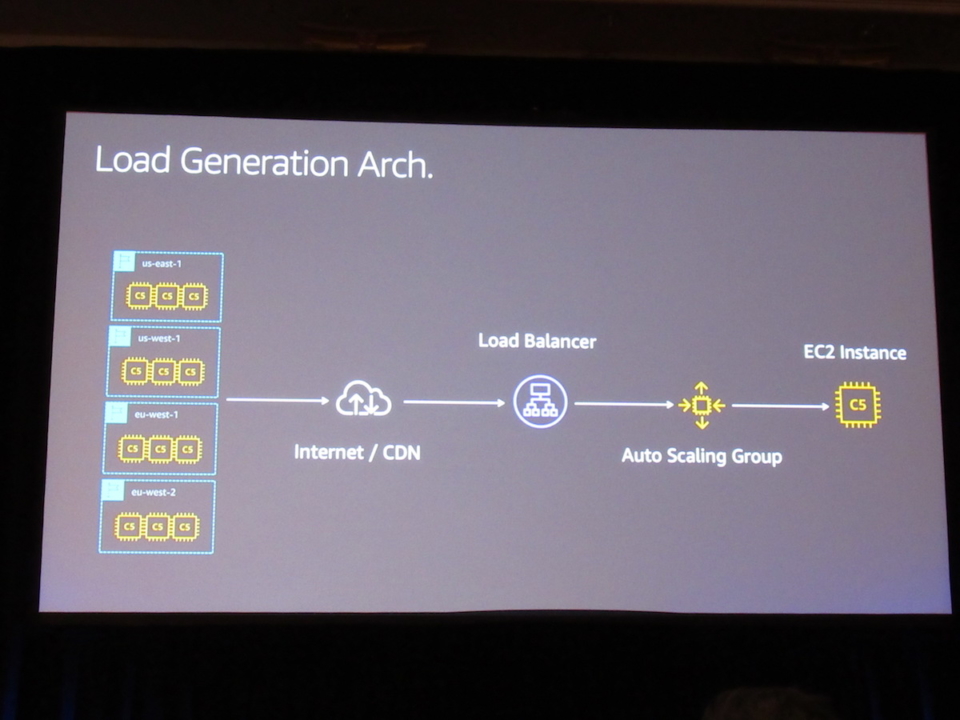
- Very simple
- Multipule load balancer to handle huge traffic
- Homepage load testing
- Everything needs to happen at that moment
Race against time
- 1M+ growth rate - per minute
- ~ minute - application boot-up time
- 90 seconds reaction time
- Push notifications
- Fully baked AMIs
Why we don’t use auto scaling
- Insufficient capacity errors
- Single instance type per auto scaling group (ASG)
- Step size of ASG
- Simply using step size to reduce the scale is not an option because it adds more complexity
- Retries and exponential backoff
- Game of (availability) zones
Battle-tested scaling strategy
- Pre-warm infra before match time
- Scale up based on request count or platform concurrency
- Proactive automated scale up based on concurrency
- EC2 spot fleet - diversified instance types
Ingredient of actual Chaos
- Push notification
- Tsunami traffic
- Delayed scale up
- Bandwidth constraints
- Increase latency
- Network failure (CDN)
What are we looking for?
- Breaking point of each system
- Death wave
- Bottlenecks and choke points
- Undiscovered issues and hidden pattern
- Failure at network, applications, etc.
Panic mode

- While the game is going on, you don't have like 15 or 20 minutes to fix the problem
- Turn off recomendations or personalization to keep critical components running; streaming video aggregation or a payment subscription
Key takeaways
- Prepare for failures
- Understand your user journey
- Okay to degrade gracefully
Q&A
- What is the other framework instead of traditional auto scaling?
- A normal Python Script
- What monitoring tools did you use for scaling?
- We monitored the metrics of containers, which is primitive
References
- http://www.sportspromedia.com/news/hotstar-global-streaming-record-india-new-zealand-semi-final








