![[レポート] NLPを説明可能にする最先端の技術についてBreakout Sessionを聴講しました! #reinvent #BOA401](https://devio2023-media.developers.io/wp-content/uploads/2022/11/eyecatch_reinvent2022_session-report.png)
[レポート] NLPを説明可能にする最先端の技術についてBreakout Sessionを聴講しました! #reinvent #BOA401
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんちには。
データアナリティクス事業本部 機械学習チームの中村です。
現在、re:Invent 2022に現地で参加しており、機械学習系のセッションをメインに回っています。
本記事では「Explainable attention-based NLP using perturbation methods」というセッションに参加しましたので、そのレポートをします。
セッションについて
- タイトル
- Explainable attention-based NLP using perturbation methods
- 登壇者
- Cyrus Vahid, Principal Developer Advocate, Kourosh Moazami-Vahid
- Saousan Kaddami, Research Scientist, Amazon
- セッション情報
- 日時: 2022-11-28 (Mon) 12:15-13:15
- 形式: Breakout Session
- 番号: BOA401
- 会場: MGM Grand (Level 1, Grand 121, MGM Grand)
- レベル: 400 - Expert
内容は、TransformerベースのNLPにおける説明可能性にフォーカスし、実装のための課題を探るものとなります。
セッション概要
事前の案内としては以下の通りです。
Explainable AI has gained a lot of attention from both legislators and the scientific community. There are many advantages of being able to explain the reasoning behind the decisions a model makes, top among them are fairness, accountability, and causality. More and more, explainability is used to improve both human and machine decision-making in a mutually reinforcing loop. This session specifically focuses on post hoc local explainability for transformer-based NLP. This session first details the general and scientific methods for explaining BERT and then explores challenges for a real-world implementation.
(日本語訳)
説明可能なAIは、議員や科学者コミュニティの両方から注目されています。モデルが行う意思決定の背後にある理由を説明できることには多くの利点があり、その中でも特に、公平性、説明責任、因果関係が重要です。説明可能性は、人間と機械が相互に強化し合うループの中で、双方の意思決定を改善するためにますます利用されるようになってきています。このセッションでは、特に変換器ベースの自然言語処理におけるポストホックローカル説明可能性に焦点を当てます。このセッションでは、まずBERTを説明するための一般的かつ科学的な方法を詳述し、その後、実世界での実装のための課題を探ります。
セッション動画
YouTubeで公開されていました。
セッション聴講内容
前半は、説明可能なAIをNLPで実現する方法、後半はResearch Scientistによる最先端の成果について紹介がありました。
アジェンダ

アジェンダはこのようになっております。
なぜ説明可能性が必要か?

まずは説明可能性が必要な意義について、例を示しながら紹介がありました。
例えば、ローン申請が却下された場合、なぜ却下されたのかを分析すると、モデルが以下のようなバイアスのかかった情報を元に判断している場合があります。
- 名前に発音しにくい名前がある場合
- 郵便番号が特定のものである場合
こういったものを避けるために説明可能性が重要になってきます。
また欧州の貿易法では、取引に関する決定を説明できなければ、罰金を課されることがあります。 そのため、機械学習で意思決定をする場合も、その根拠が説明可能である必要があります。
説明可能性の研究
ここからは説明可能性に関する研究の歴史が振り返られていました。

まずはLIME(Local Interpretable Model-agnostic Explanation)についてでした。 画像のスーパーピクセル単位で無効化することで、どの程度推論結果に影響するかを見る手法のようです。

次にSHAPについての説明がありました。こちらは、ゲーム理論に基づいてどの特徴量が最も成果に貢献しているか、ある特徴量単体での性能と、ある特徴量を除いた場合を総合的に判断します。
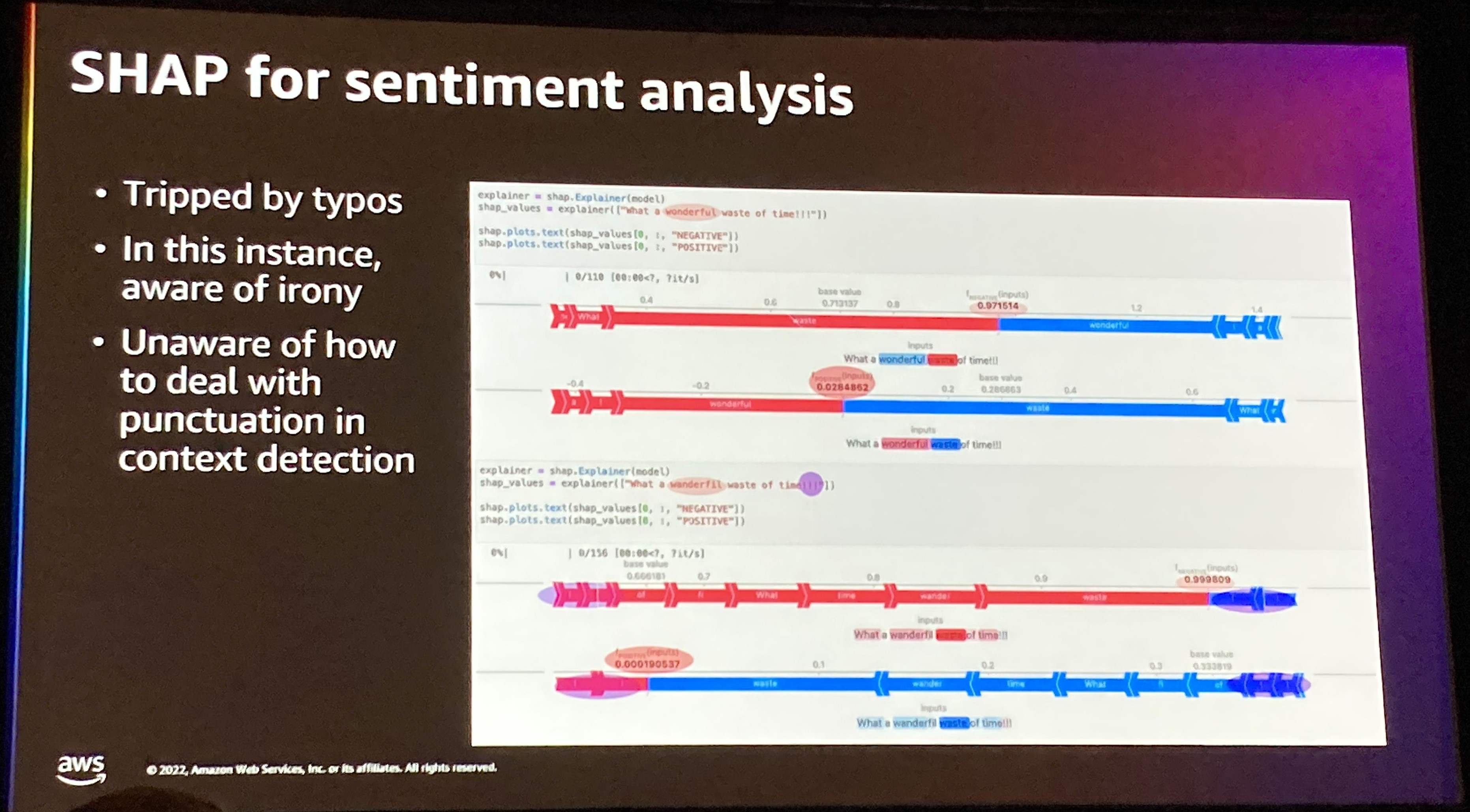
また、このSHAPをどのようにテキストの感情分類に適用するのかという話もありました。
摂動(perturbation)について
ここから、スピーカが代わり、Research Scientistからの説明となります。
摂動に基づく方法により、入力が出力のどの部分と関係しているのかを理解するのに役立ちます。
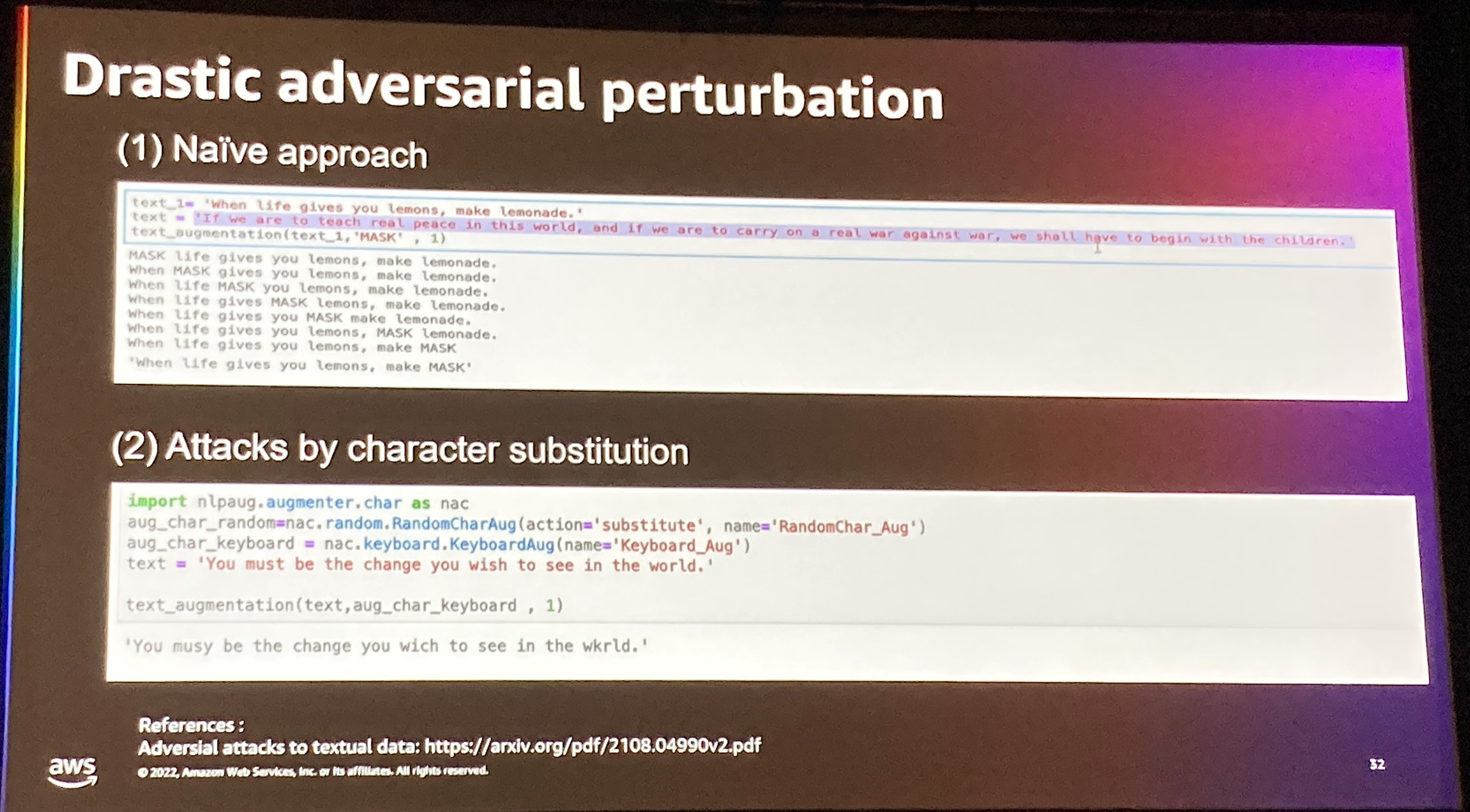
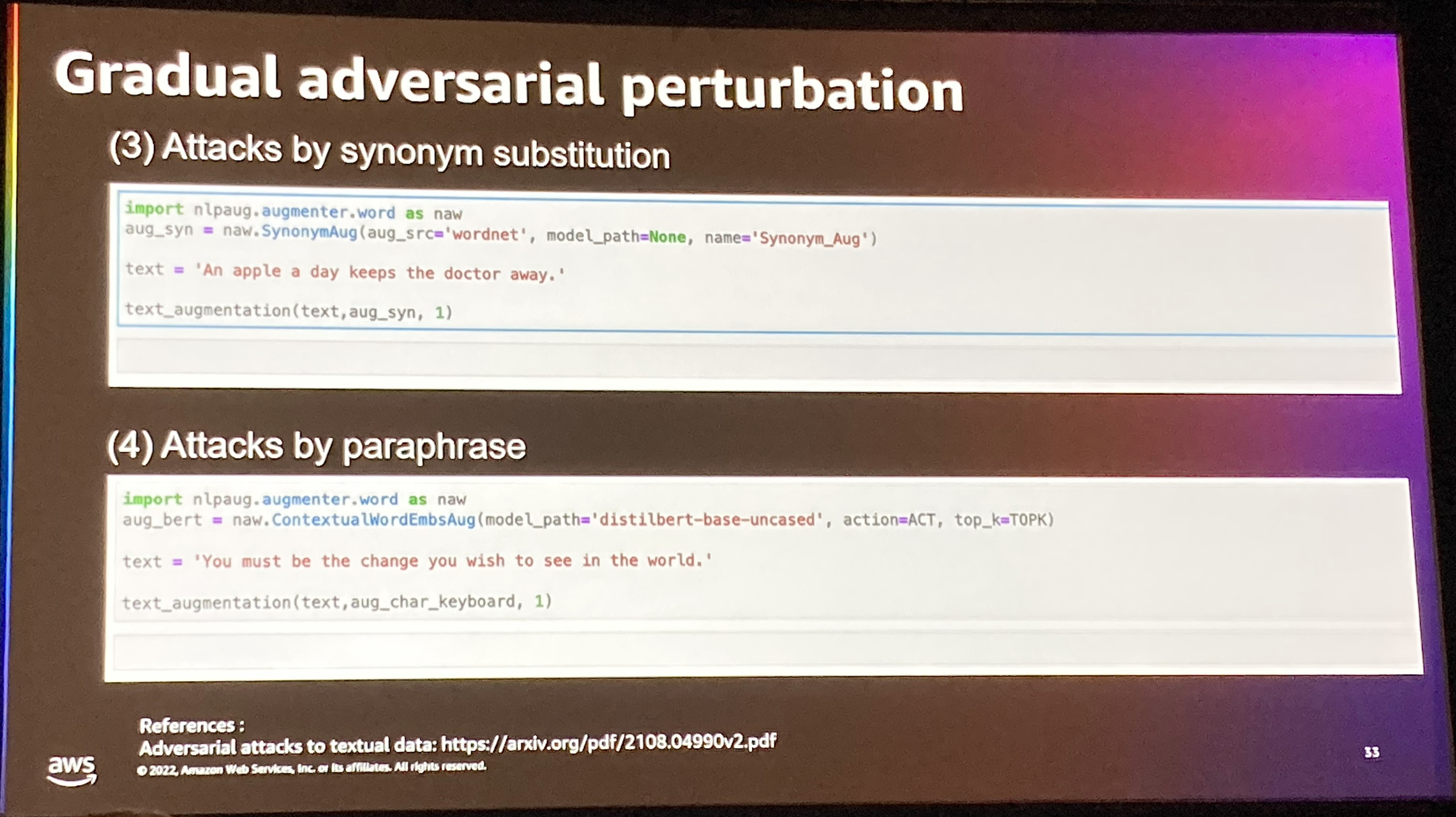
そのために基本的な例として、ある単語をマスクする方法や文字レベルのsubstitution(置換)などのいくつかの例がコードを含めて紹介されていました。これらのAugmentationをするためのモジュールも存在するようですね。

次にこれらの基本的な摂動の限界について言及がありました。 Out of Distribution(実際の分布から外れる)こと、解釈可能性というよりは、ロバスト性を目的とした摂動になってしまっていることが挙げられています。
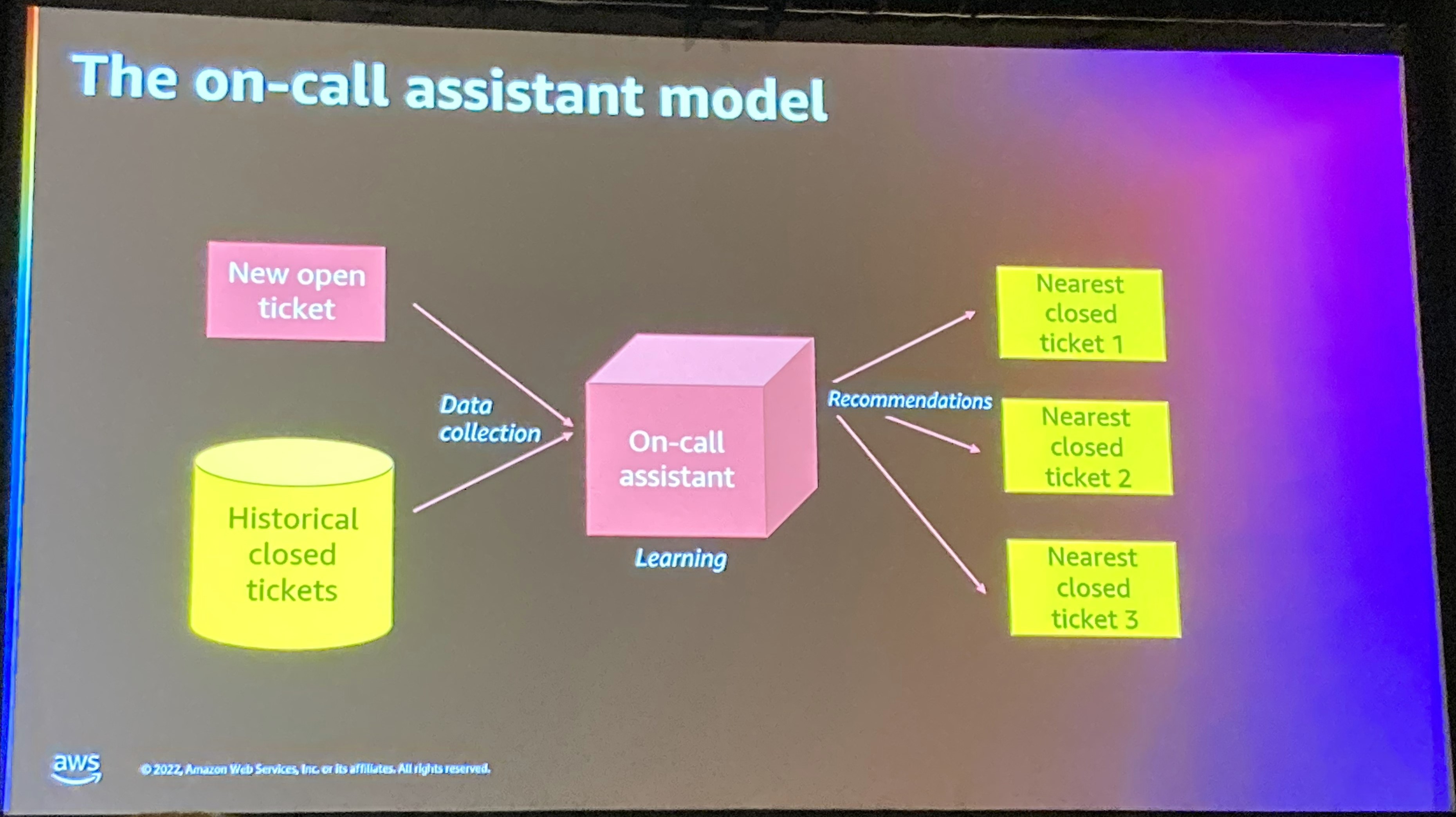
これに対する提案手法について、チケット分類を例に挙げられて説明されました。
方法としては、テキストの前処理などを実施して、BERTなどのエンコーダで処理します。これを近傍法でクラスタリングします。類似度にはコサイン類似度を使用します。
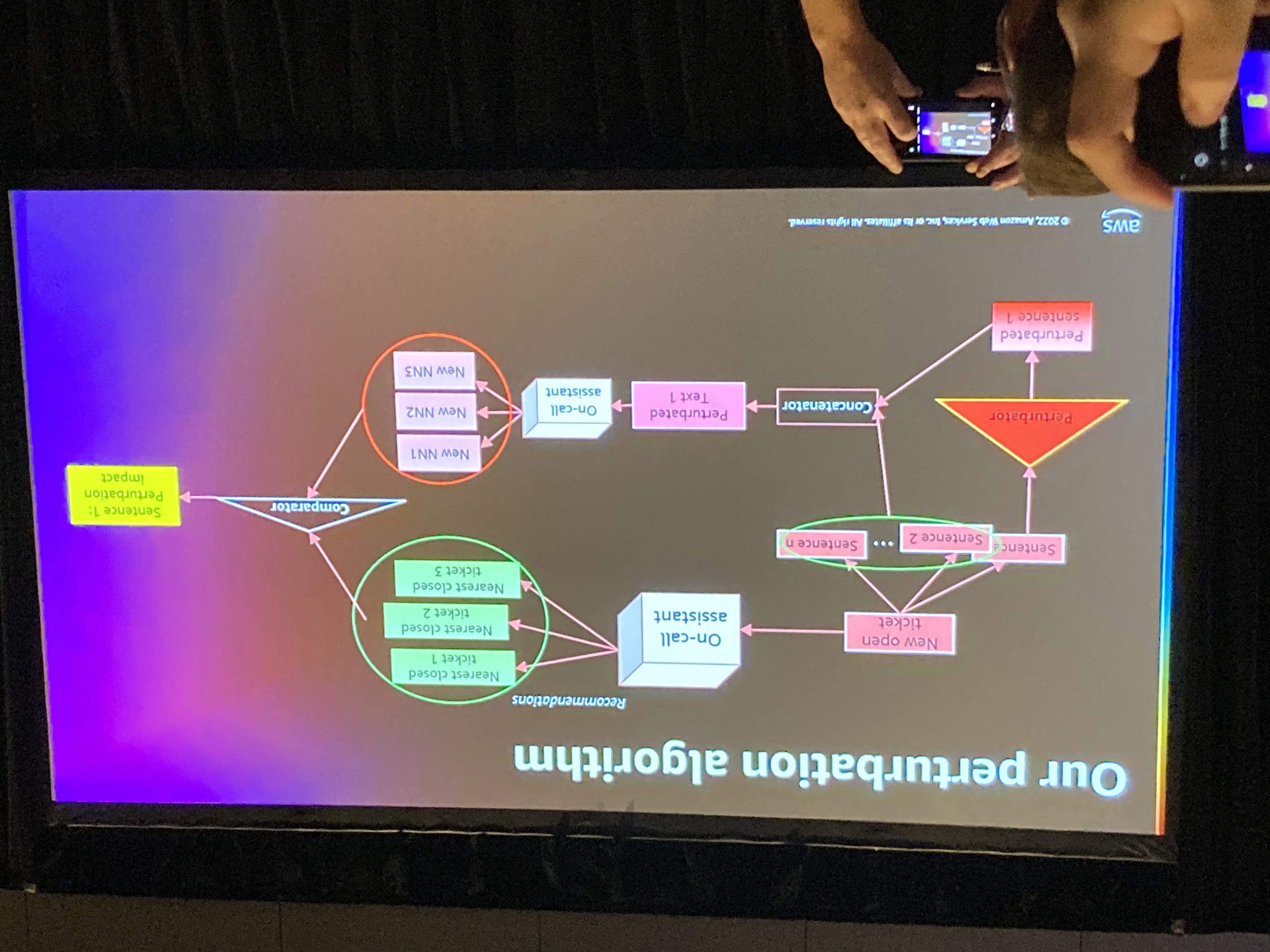
このアーキテクチャについて、摂動をどのように適用するか説明がされました。
摂動の種類としては、センテンス単位で分割して、1センテンスにのみ摂動をくわえて近傍法の結果を比較するイメージとなっています。これにより、各センテンス単位での重要度を可視化することが可能となっているようです。
Amazon SageMaker Clarifyの説明

話はSageMaker Clarifyの話に移り、ここでは現時点でのClarifyで対応している説明可能性とバイアス検出について説明がありました。
質疑応答
いくつか質問がありましたが、理解できた範囲のメモ書きとなります。
Q. 実査器に摂動を導入する場合には、どのように定量化して実施すればよいか。 A. 今回の手法を適用するには、近傍法を使用するため、距離を定義する必要がある。距離はユースケースに依存するため、地震で設計する必要がある。我々の場合も様々な距離を比較して、安定しているものを使用した。
Q. Out of Distributionを防ぐにはどのようにしたらよいか。摂動が無意味なものになってしまったりはしないのでしょうか。 A. 摂動が意味があるかどうかは確かに重要で、特定のタスクのみで適用した場合、局所最適になっているだけな可能性があります。ですので、様々なタスクに基づいてダブルチェックを行う必要があると考えています。
まとめ
いかがでしたでしょうか。説明可能なAIについて、よく使われる手法から、最先端の研究まで紹介されていた良いセッションでした。質疑応答は非常に活発に行われ、参加者の興味の高さが伺えました。
機能的にも重要な研究成果の話もあり、これらが将来的に適用されるサービスが出てくることも期待したいと思います!!









