![[レポート][新機能]Amazon SageMaker LakehouseとAmazon RedshiftへのZero-ETLレプリケーション #AWSreInvent](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1734239589/user-gen-eyecatch/fug1hxkt0dhjbirnxzqx.jpg)
[レポート][新機能]Amazon SageMaker LakehouseとAmazon RedshiftへのZero-ETLレプリケーション #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、データ事業本部の渡部です。
今回はAWS re:Invent2024 3日目のBreakoutSessionである【ANT353-NEW | [NEW LAUNCH] Zero-ETL replication to Amazon SageMaker Lakehouse & Amazon Redshift】のセッションレポートをまとめます。
3日目の17:30からという遅めのセッションでしたが、新しく発表されたAmazon SageMaker Lakehouseのセッションということもあり、多くの参加者が集まりました。
私もNEW LAUNCHセッションだった本セッションに迷うことなく参加です。
セッション概要
In today’s data-driven landscape, organizations rely on enterprise applications to manage critical business processes. However, extracting and integrating this data into data warehouses and data lakes can be complex. This session explores a new zero-ETL capability that simplifies ingesting data to Amazon SageMaker Lakehouse and Amazon Redshift via AWS Glue from enterprise applications such as Salesforce, ServiceNow, and Zendesk. See how zero-ETL automates the extract and load process, expanding your analytics and machine solutions with valuable SaaS data.
AI翻訳
現代のデータ駆動型の環境において、組織は重要なビジネスプロセスを管理するために企業アプリケーションに依存しています。しかし、このデータをデータウェアハウスやデータレイクに抽出・統合することは複雑な作業となりがちです。このセッションでは、Salesforce、ServiceNow、Zendeskなどの企業アプリケーションからAWS Glueを介してAmazon SageMaker LakehouseとAmazon Redshiftにデータを取り込むプロセスを簡素化する、新しいゼロ-ETL機能について説明します。ゼロ-ETLがデータの抽出とロードのプロセスを自動化し、価値のあるSaaSデータを活用して分析や機械学習ソリューションを拡張する方法をご紹介します。
スピーカー
- Nitin Bahadur, Head of Engineering, AWS Glue & Amazon AppFlow, Amazon
- Sean Ma, Principal Product Manager, Amazon Web Services
- Kamen Sharlandjiev, Sr. WW SSA Big Data, AWS
本編動画
セッション内容
ここからはセッションでスピーカーたちが話した内容をまとめていきます。

顧客と話をする際によく聞かれることは、どうすればより多くの価値を、より速く、よりスムーズにデータから引き出せるかということとのことです。
それらを求める理由としては3つ大きく考えられるとのこと。
- AI活用の促進
- 分析の簡素化
- 市場導入時間の短縮

多国籍の製薬会社のRoche社も同じような課題を持っているとのことで、
開発したETLを確実に機能し続けるようにすることと、効果的な方法でそのデータにアクセスすることが非常にコストがかかるということを挙げていました。

アジェンダは以下の通りです。
- 01 データ統合の課題
- 02 アプリケーション統合の全体像
- 03 技術的課題の詳細
- 04 ソリューション概要
- 05 デモ
- 06 重要なポイントとメリット

本題に入る前に、解決の必要がある課題について整理をしてくれました。
- データ取り込み:ビジネスロジックを盛り込んだ変換をする
- データ品質:適切な処理とエラー処理の検討
- パイプラインやインフラ管理
- 上記に対応するスキル

データ統合処理の3種類について説明がありました。
- MSKやKinesis、Kafkaを使用したストリーム処理
- GlueやEMR、Sparkを使用したバッチ処理
- データの変更をもとにしたイベント処理

ここからスピーカーが変わりました。
データは複数のアプリケーションで生成されて、10年間でSaaSは劇的に増加したという話から始まり、データはそれぞれの場所からRest APIやSOAP API、JDBC、RPCを用いて収集してくると説明がありました。
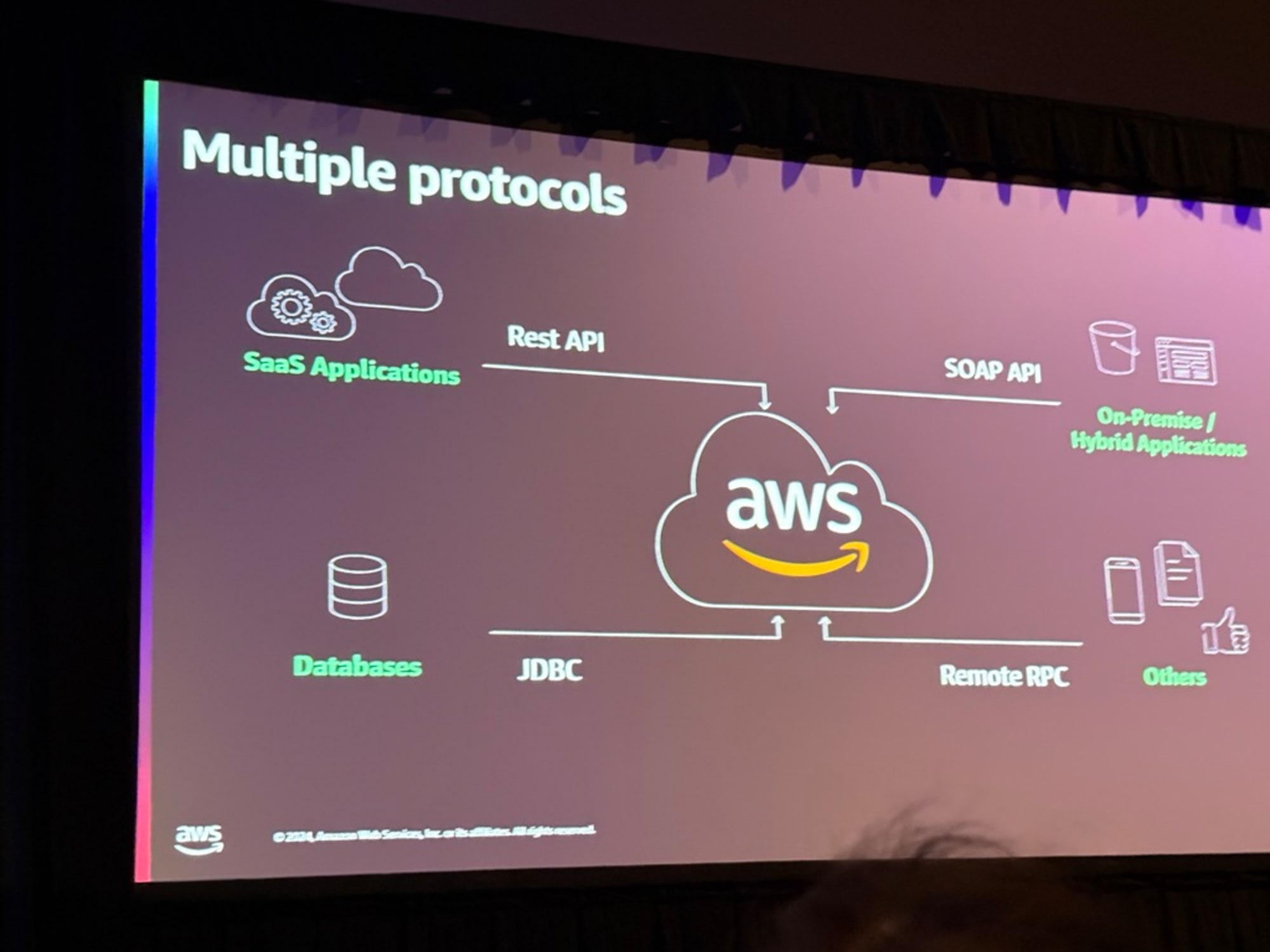
異なるアプリケーションでは提供するAPIも異なるということで、その種類についても解説されます。
- 変更されたデータを全て取得するAPI
- 特定時間から変化したデータを取得するAPI
- 挿入と更新データの取得と削除データの取得がわかれているAPI
- トークンをもとに、前回のトークン発行以降に変化があったデータを取得するAPI
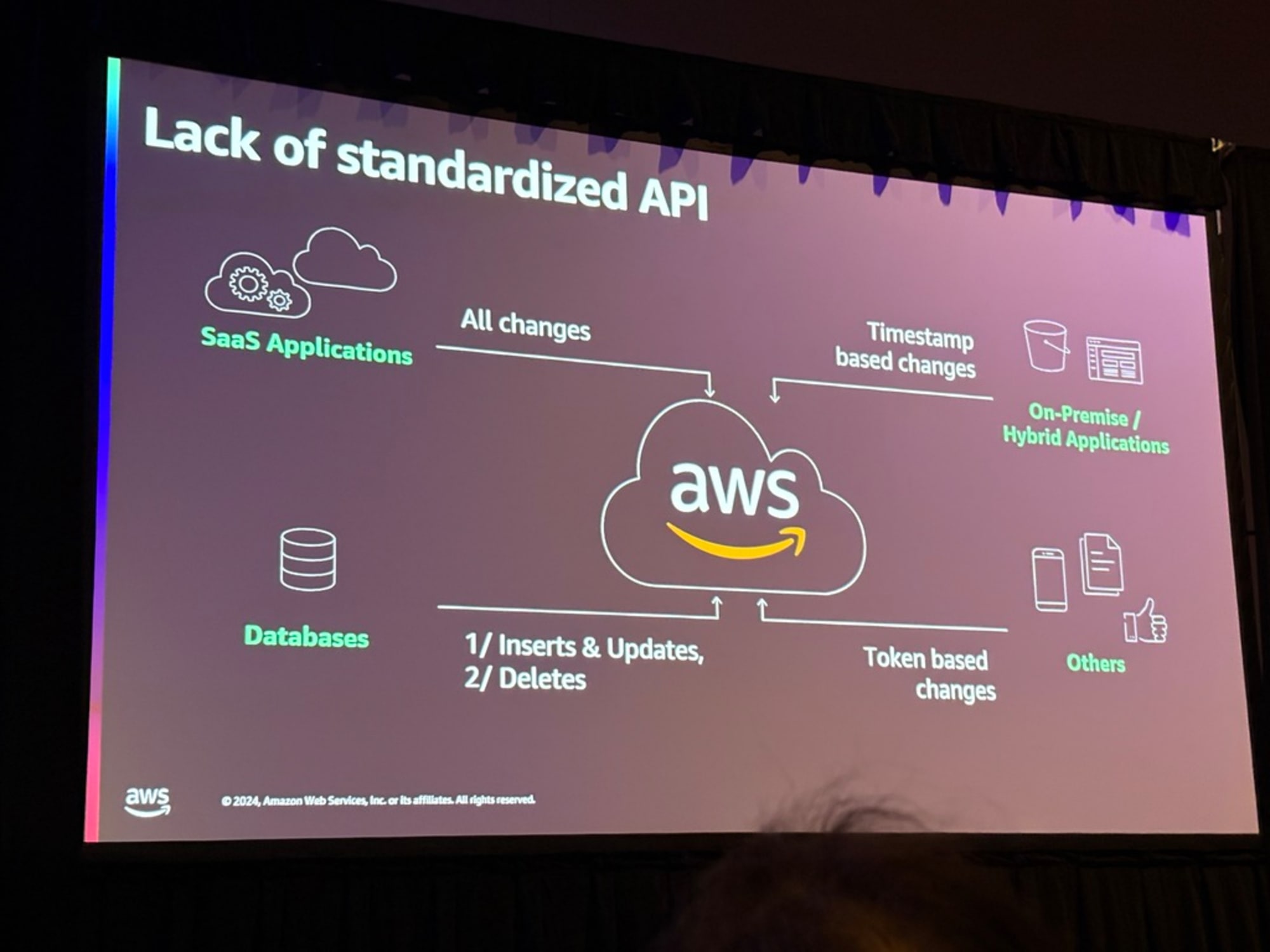
複製の難しいところはDeleteという話がありました。
上流で削除されたデータを下流に伝播させるのは、ただInsertやUpdate処理を実行させるほど簡単ではないということです。
例としては車の在庫システムがあげられ、車のレコード削除処理が伝播されていなかったため車がディーラーに届かなかったという話がありました。
またスキーマの追加は簡単でも、変更(型変更など)や削除(項目削除)が同じように下流に伝播させることは大変であるということです。

上述の問題に対応するには、データレイクとデータウェアハウスの両方に対して対応する必要があるとAWSは考えたとのことです。
まずデータレイクはオープンテーブルフォーマットApache Icebergの採用。ただし効果的なクエリを実現するためには、定期的なコンパクション、適切なパーティション化をする必要があると認識したようです。
またデータウェアハウスはクエリに最適化された独自のフォーマットがあり、クエリのSLAに影響を与えないことが重要であると考えていてようです。そのため、スキーマの変更やレコードの削除などの変更をSLAに影響を与えずに達成することが必要だと認識したそうです。

以上の経緯から、AWSはZero-ETLを使用してデータを流せる、S3とRedshiftが統合された新サービスAmazon SageMaker Lakehouseを開発したとのことです。

Zero-ETLの目的は、一般的なデータ取り込みやデータレプリケーションにおいて、詳細なデータパイプラインを構築する必要性を排除または最小化することです。上述ですが、ストリーム処理、バッチ処理、イベント処理など、様々な取り込み方法がありますが、それらとZero-ETLの違いは、AWS管理であることということです。
上述した方法を用いた自分で構築したパイプラインは、自分で管理・維持したい場合には最適。
しかし、もっとシンプルで直接的なものを探しているケースにおいてはZero-ETLの出番とのことです。
そのあとは、Zero-ETLの対応ソースの話、アプリケーションのZero-ETLが発表されたことが紹介されました。

次にSageMaker Lakehouseの話へと移りました。
Zero-ETLとLakehouseを組み合わせることで、データウェアハウス、データレイク、運用データベース、そして今回新たにアプリケーションからのデータを、すべてLakehouseという単一のデータ格納場所に統合したということです。
LakehouseはRedshiftとS3の両方のメリットを得ることができ、データがすべてLake Formationとカタログを使用して管理すると。そしてその裏ではGlueデータカタログを使用していて、アクセスに関しては、オープンスタンダードであるApache Icebergを使用しているとのことです。
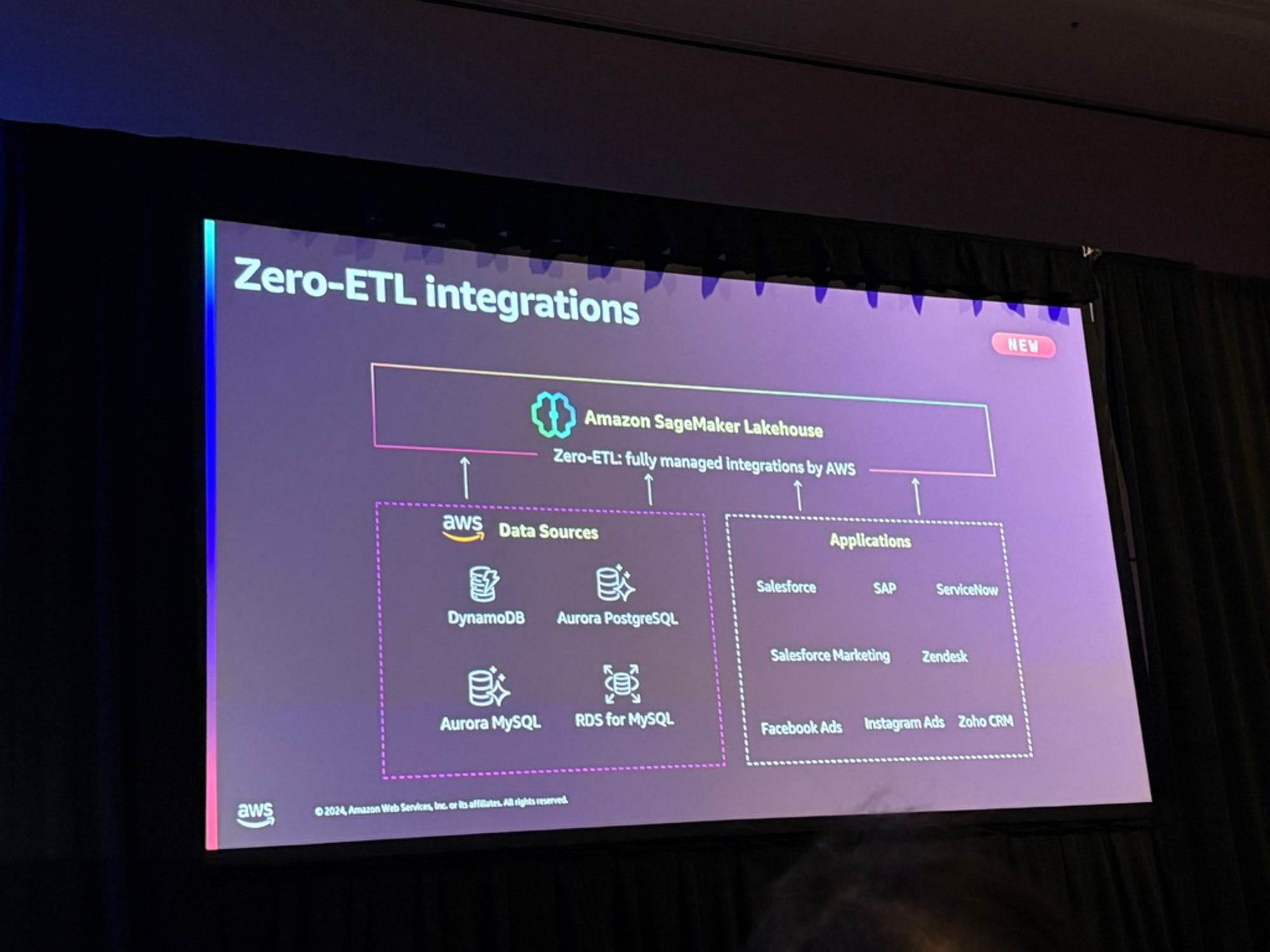
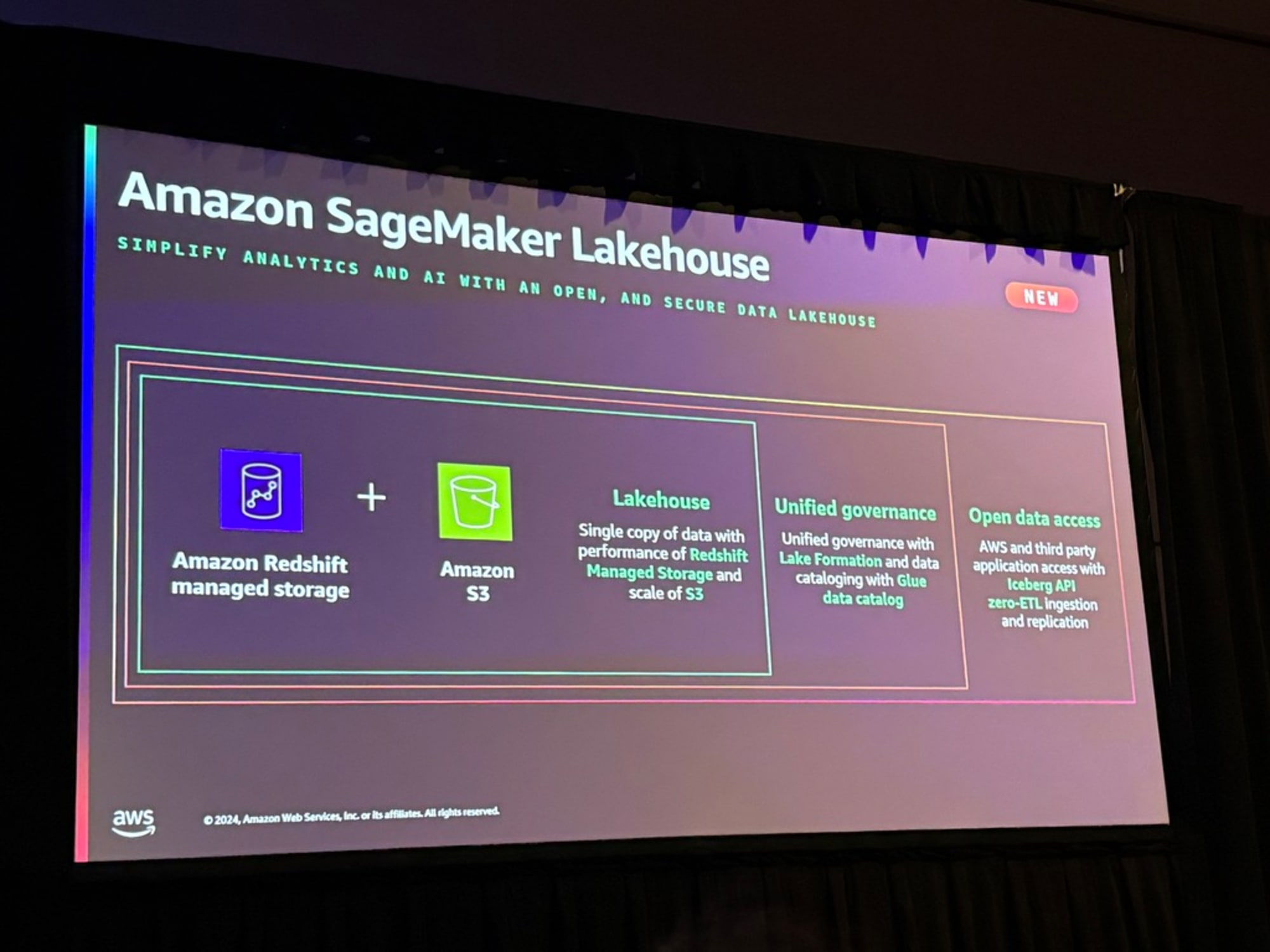
アプリケーションのZero-ETLについて再度言及がありました。
APIは都度変化するけれど、その変化に対応するのはAWSであり、何か問題が発生した際はAWSが調査・対応をすると宣言されていました。
データ収集を素早く、追加のコネクタ費用などのコストを払わず、運用を最低限にするサービスであるとZero-ETLについて特徴を挙げていました。
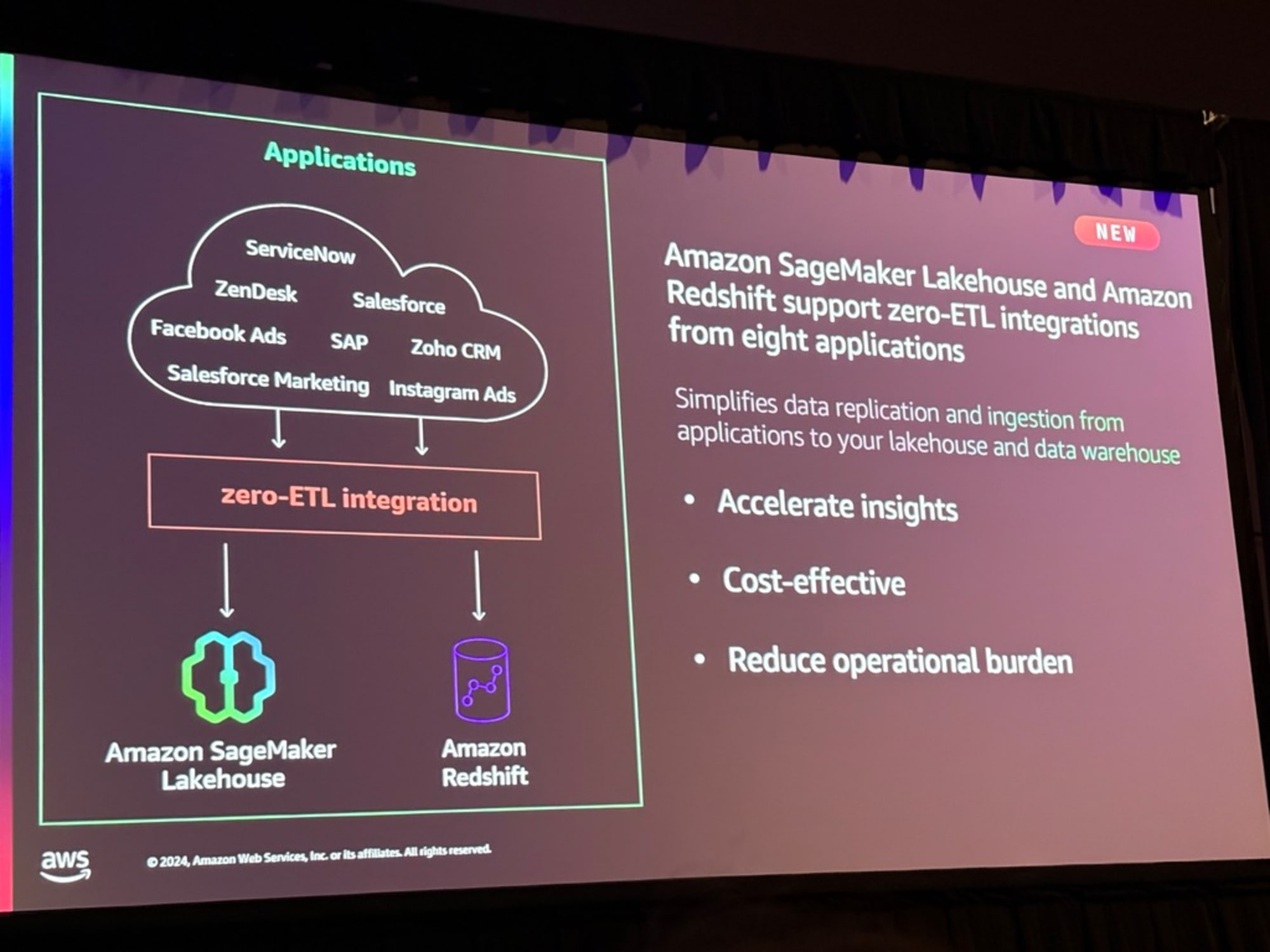
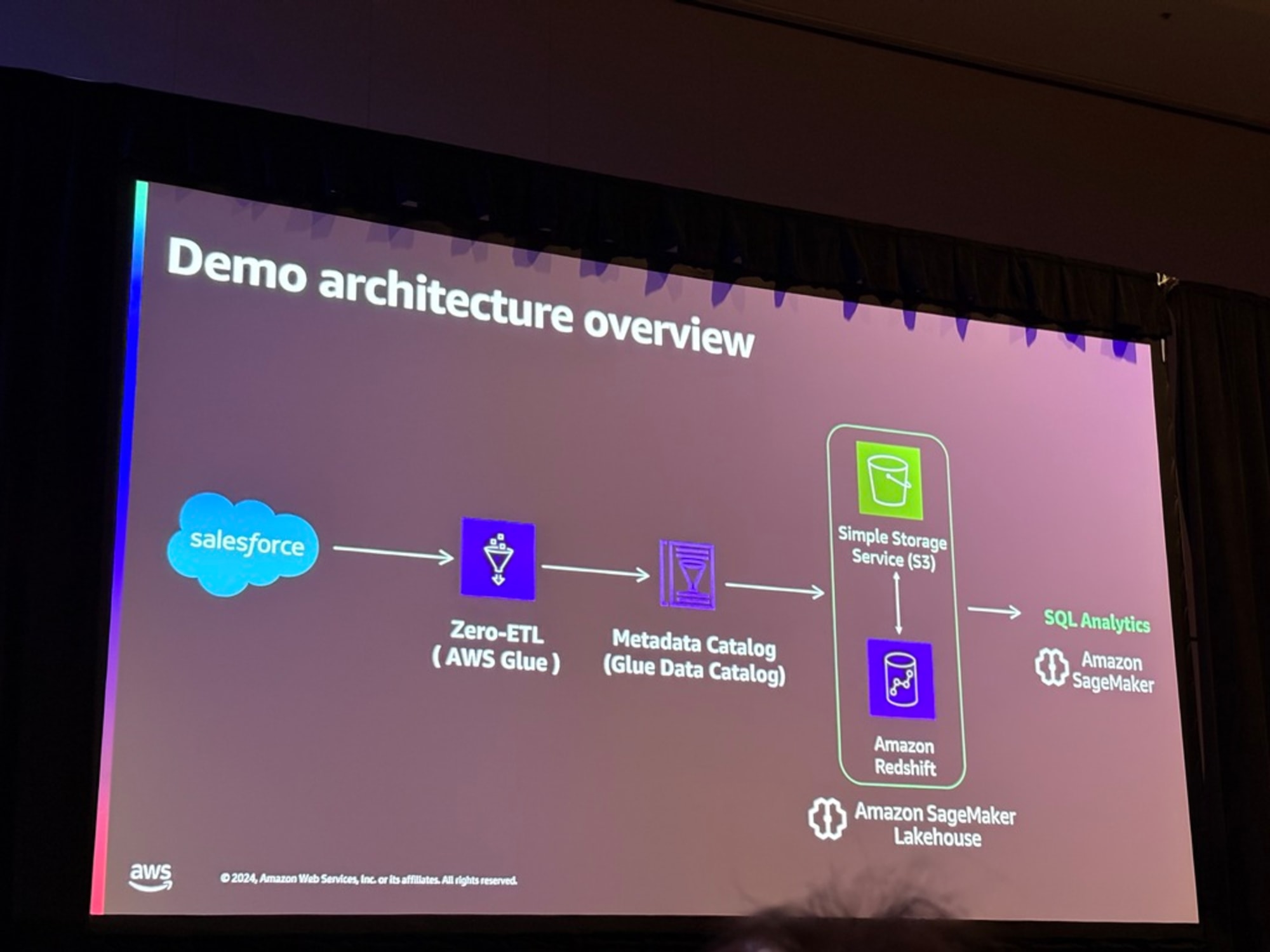
このあとはZero-ETLとLakehouseのデモが展開されました。先述したRoche社の実現したいアーキテクチャですね。
以下のアーキテクチャで実際の画面でZero-ETLを設定し、Unified Studioでデータをクエリするところまでが確認できます。
詳しくは動画が公開されているので、そちらでチェックしてみてください。
デモが終わると、Zero-ETLのまとめでセッションが締め括られました。
さいごに
Zero-ETLについてはまずは使えないか?と最初に考えるのがスタンダードになると思います。
またLakehouse、非常に面白いサービスですね。
Lakehouseの生まれた経緯を語っていただいたので、Lakehouseの使い方についてよくわかるセッションだったのかなと思います。
Iceberg REST APIを通したデータ消費で今後のデータ分析が加速されそうな印象です。
とにかくデータ分析に至るまでの道のりを短くしていくというテーマが伝わってきたセッションでした。
合わせて読みたい










