
製造業×AI Agent。未来の技術を使いこなすための、地道で大切な第一歩
こんにちは!おおはしりきたけです。今年も製造業アドベントカレンダーの季節がやってまいりました。当エントリは クラスメソッド発 製造業 Advent Calendar 2025の12日目のエントリです。
はじめに
先日、ラスベガスで開催された AWS re:Invent 2025 に参加してきまして、現地の熱量は凄まじく、どこへ行っても聞こえてくるキーワードは「AI Agent」でした。
これまでのように人間がチャットで指示を出す生成AIから一歩進み、AI自身が自律的にタスクをこなし、判断し、ワークフローを回していく未来。そんなデモや事例を目の当たりにし、製造業の現場も大きく変わる予感にワクワクしました。
しかし、同時にある種の危機感も覚えました。 きらびやかなAI Agentの事例の裏側で、どのセッションも口を酸っぱくして語っていた「ある前提条件」があったからです。
今回は、re:Inventで見てきたセッションを振り返りつつ、日本の製造業がAIエージェントを活用していくために、今、私たちが実直に向き合うべきことについて書いてみたいと思います。
re:Invent 2025で見てきたセッション
今回、「製造業」 と 「AI Agent」という組み合わせで、私が聞いてきたのは以下の3つのセッションです。
-
IND370: Modernizing operational technology for AI-powered manufacturing
-
PEX402: Engineering intelligence: Multi-agent AI systems for industrials
-
IND305: AI agents in manufacturing: Building intelligent data workflows
OT領域のモダナイズ、エンジニアリングにおけるマルチエージェント、そしてデータワークフロー。それぞれ切り口は違いますが、これら3つのセッションで共通して言っていたのは、こういうことです。
「AI Agentを活用するためには、業務フローの整備とデータをしっかりまとめることが何より大切である」
実際に、セッションで紹介されていたロードマップのスライドをご覧ください。
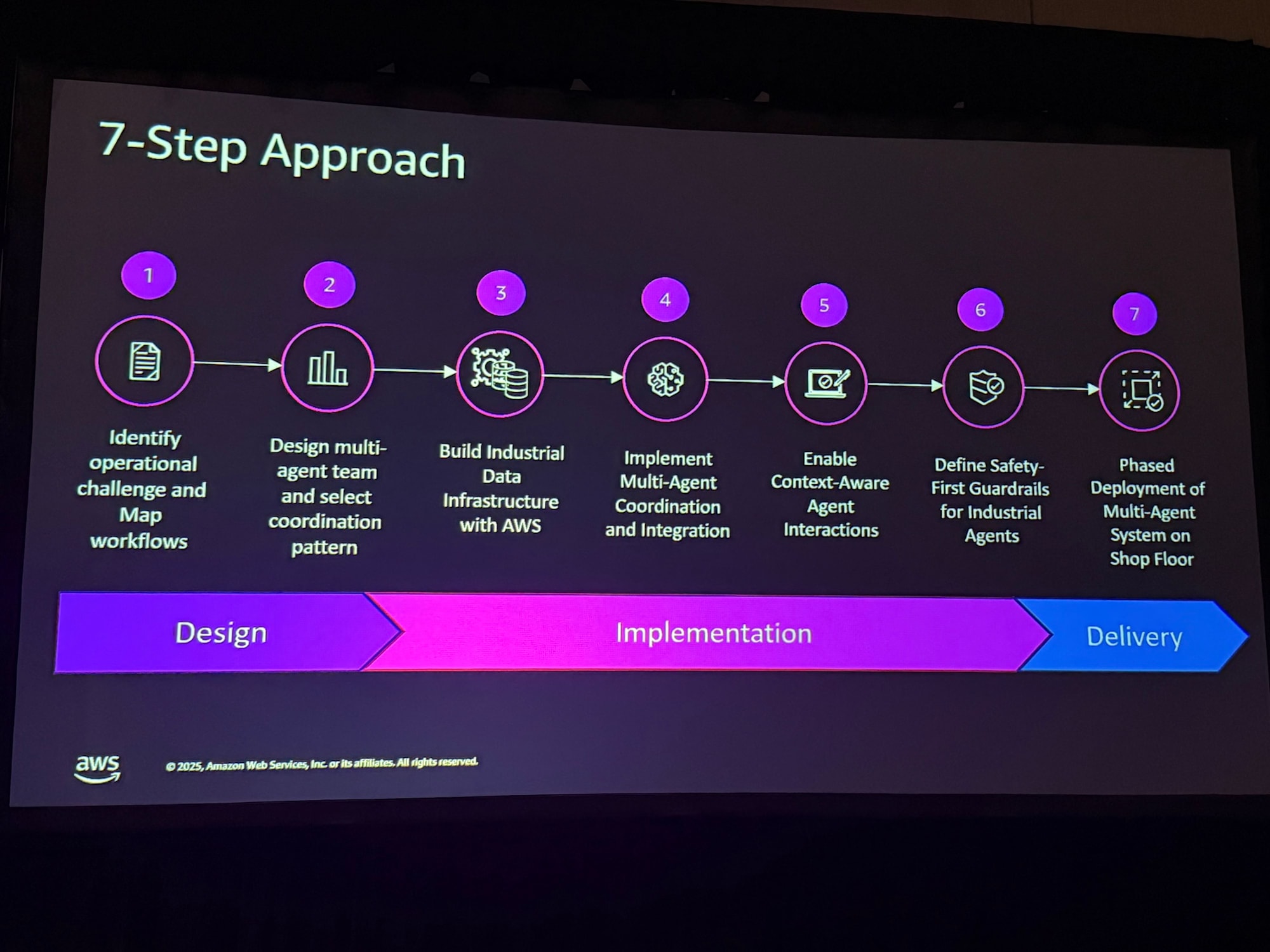
これは「7-Step Approach」として紹介されていたものですが、一番最初のステップに書かれているのは課題の特定とワークフローのマップ化です。 そして、ステップ3にはデータインフラの構築が来ています。
AI Agentは、魔法のように見えますが、その実は業務フローとデータの積み重ねです。「在庫が減ったら発注する」というタスク一つとっても、「いくつ減ったら」「どこに」「どういう形式で」発注するのかという明確な業務フローと、現在の正確な在庫データが揃っていなければ、エージェントは動くことができません。
どのセッションでも、華麗なAI Agentの動作だけでなく、その下支えとなる「泥臭い整備」の重要性が何度も強調されていました。
日本の製造業における「暗黙知」の壁
この「業務フロー」と「データ」という前提条件を、日本の製造業に当てはめてみると、乗り越えるべき課題が見えてきます。
日本のモノづくりは素晴らしいです。現場の方々の技術、そして阿吽の呼吸で回る現場力には、世界に誇れる強みがあります。しかし、AI Agent活用という文脈においては、この暗黙知がひとつのハードルになるかもしれません。
いい感じにやっておいて
人間同士なら通じるこの言葉が、AI Agentには通じません。 日本の現場では、業務フローが明文化されていないところも多いです。熟練者の頭の中にあるケースが非常に多く、いつも通りが通用しないAI Agentと働くためには、私たちが当たり前に行っている業務を一つ一つ言語化し、フローに落とし込むという地道な作業が必要になります。
現地では、このようなスライドも紹介されていました。
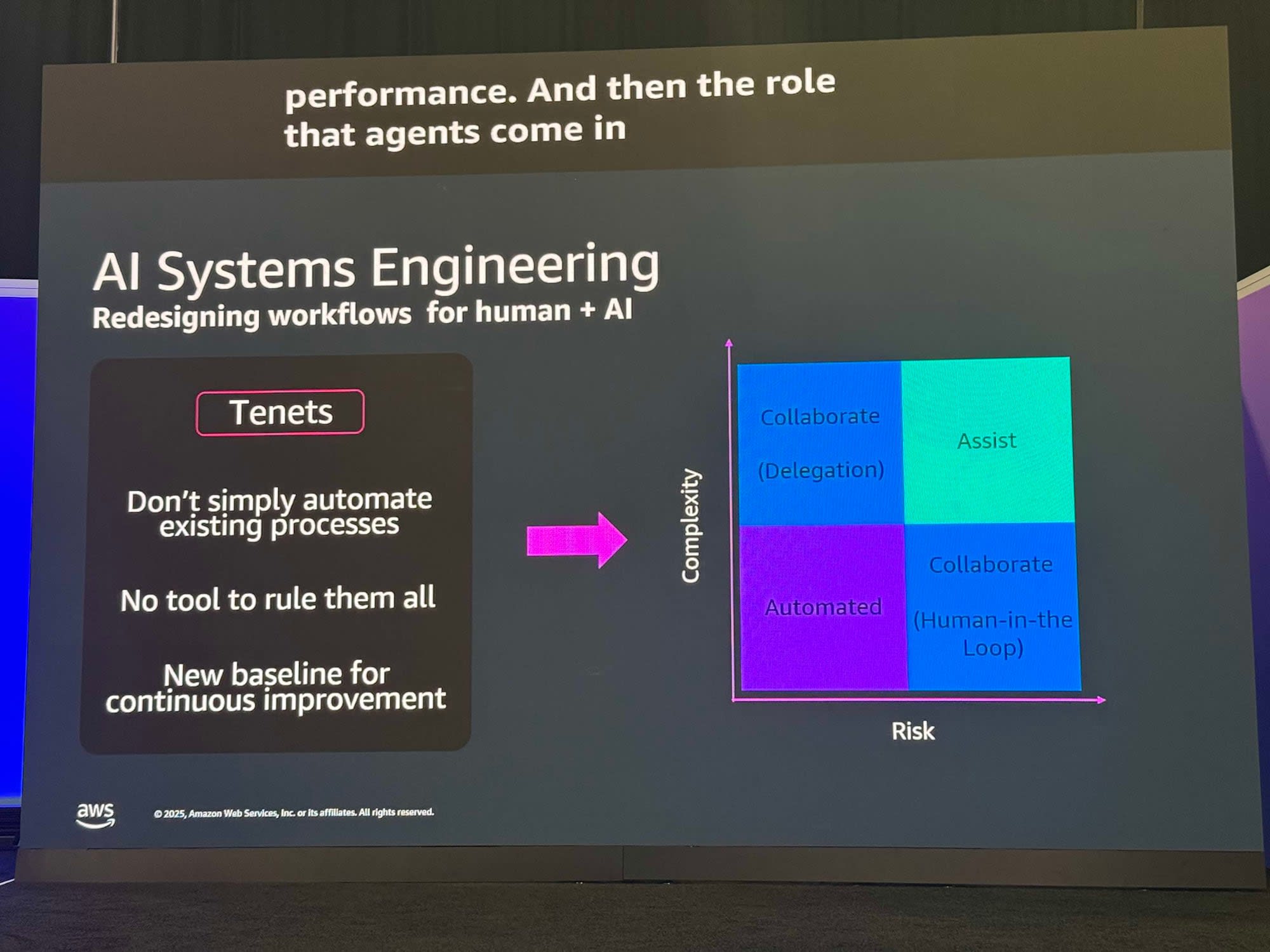
スライド左側のTenets(原則)にあるDon't simply automate existing processes(既存のプロセスを単に自動化するな)」という言葉が非常に印象的でした。
AI Agent導入は、今の「暗黙知でなんとかなっている業務」をそのまま自動化することではありません。「人間とAIのためのワークフロー再設計」とあるように、どこをAIに任せ、どこを人間が判断するのか、業務そのものを見直して再設計する必要があります。
データをクラウドへ上げるということ
もう一つの課題は「データ」です。 「工場には宝の山(データ)がある」とよく言われますが、その多くは工場内のサーバーに閉じ込められていたり、そもそも紙で管理されていたり、機械の中にログとして眠ったままだったりします。
re:Inventのセッションでも語られていた通り、AI Agentが自律的に判断するためには、判断材料となるデータがクラウド上で、かつAI Agentが理解できる形でアクセス可能である必要があります。
日本では、まだ現場のデータがクラウドに上がっていないことが多いと思います。セキュリティの懸念や古い設備の制約など、現場には現場の事情がありますが、AI Agentをパートナーとして迎え入れるためには、このデータをクラウドへつなぐパイプラインの構築を避けては通れません。
AIエージェント活用のための「下ごしらえ」
re:Inventを通して私が感じたのは、「AI Agent活用は一足飛びにはいかない」という現実です。 AI Agentという最新技術を使いこなすための第一歩は、実はとてもアナログで、基本的なことの積み重ねでした。
- 業務フローの棚卸しと標準化: 暗黙知を形式知に変え、理解できる手順にする。
- データのクラウド化: 現場の情報をデジタルに乗せ、AI Agentが触れる場所に置く。
これらは、製造DXという言葉が流行る前から言われてきたことかもしれません。しかし、AI Agentという強力なパートナーが見えた今、この「下ごしらえ」の価値は以前よりも遥かに高まっています。
おわりに
「なんだ、結局やることは地味な作業か」と思われたかもしれません。 でも、私は逆に勇気づけられました。
なぜなら、業務を丁寧に整理し、データを大切に扱うという「真面目な下準備」こそ、日本の製造業が本来得意としてきたことではないかと思うからです。
AI Agentは、私たちの仕事を奪うものではなく、整理された業務とデータを入力として、私たちの生産性を何倍にも増幅してくれるパートナーです。 そのパートナーが最大限の力を発揮できるよう、まずは私たちが現場の足元を固め、業務とデータの「翻訳」をしてあげる。
これからの製造業を楽しくするための「準備運動」として、まずは自分たちの業務フローを書き出すところから始めていく必要があると感じました。 re:Invent 2025で見た未来の景色は、そんな地道な一歩の先にあるのだと信じています。









