
【レポート】 AWS DevOps Agentでクラウド運用を変革「Move beyond reactive: Transform cloud ops with AWS DevOps Agent」に参加しました!#AWSreInvent #COP362
こんにちは!クラウド事業本部のおつまみです。
今回はre:Invent2025のセッション 「[NEW LAUNCH] Move beyond reactive: Transform cloud ops with AWS DevOps Agent」 に参加してきたので、内容をご紹介します!
AWS DevOps Agent についてはAWSブログや弊社ブログでもいくつか記事が出ています。
- AWS ブログ
- 速報ブログ
- やってみたブログ
セッションの概要
タイトル
[NEW LAUNCH] Move beyond reactive: Transform cloud ops with AWS DevOps Agent
概要
Is your operations team consumed by daily firefighting? Do you lack the time to evaluate and improve your operational posture? Move from reactive firefighting to proactive operational improvement with AWS DevOps Agent, a frontier agent that resolves and proactively prevents incidents, continuously improving reliability and performance of applications in AWS, multicloud, and hybrid environments. We’ll show you how you can leverage AWS DevOps Agent to integrate with your DevOps toolset including AWS and non-AWS observability tools, code repositories, and pipelines to correlate and connect the dots across signals to surface concerning trends and provide prioritized improvements to drive operational excellence.
運用チームは日々の緊急対応に追われていませんか?運用状況を評価・改善する時間が足りませんか?AWS DevOps Agent は、インシデントを解決し、プロアクティブに予防する最先端のエージェントです。AWS、マルチクラウド、ハイブリッド環境におけるアプリケーションの信頼性とパフォーマンスを継続的に向上させます。AWS DevOps Agent を活用して、AWS および AWS 以外のオブザーバビリティツール、コードリポジトリ、パイプラインなどの DevOps ツールセットと統合し、シグナル間の相関関係を分析・関連付けることで、懸念される傾向を明らかにし、優先順位をつけて改善を行い、運用の卓越性を高める方法をご紹介します。
スピーカー
- Bill Fine, Product Manager, Amazon
- David Yanacek, Sr. Principal Engineer, AWS
レベル
300
Session Type
Breakout session
セッションの内容
AWS DevOps Agentとは
AWS DevOps Agentは、re:Invent 2025で発表されたばかりの新サービスです。
このエージェントは、インシデント対応を加速し、システムの信頼性を向上させることを目的としています。

従来、運用チームは日々の緊急対応(いわゆる「firefighting」)に追われ、運用態勢を評価・改善する時間が不足していました。
AWS DevOps Agentは、こうした課題を解決するために、リアクティブな対応からプロアクティブな運用改善へと移行することを可能にします。
2つの基本機能
1. インシデントの迅速な解決
AWS DevOps Agentは、トレース、ログ、メトリクスを包括的に分析し、調査結果を共有します。根本原因を特定した上で、問題解決のための具体的な緩和手順を提供することで、MTTR(平均修復時間)の短縮を支援します。エンジニアがラップトップを開く前に調査が完了していることもあり、迅速なインシデント対応を実現します。
2. インシデントの事前予防
エージェントは常にバックグラウンドで監視を続け、過去に調査・管理したインシデントを定期的にスキャンします。AWSベストプラクティスやアプリケーション環境の理解に基づいて、インシデントを引き起こす根本的な問題を検出し、運用態勢の改善機会を提案します。これにより、同じ問題が繰り返し発生することを防ぎます。
AWS DevOps Agentの4つの特徴
1. チームメンバーとして機能

AWS DevOps Agentは、フロンティアエージェントとして、チームの一員として自律的に動作します。サポートチケット、ページャー、アラームに応答し、インシデントの調査を自動的に実行します。
調査結果は、ServiceNowチケットのコメントに記録されたり、Slackチャネルで他のチームメンバーと同じようにコミュニケーションを取ることができます。また、他のエージェント(例:DynatraceのDavis AI)とも連携可能で、より高度な協調作業を実現します。
2. テレメトリーエキスパート

AWS DevOps Agentは、幅広いテレメトリーソースとの統合を実現しています。AWS CloudWatchとはネイティブに統合されており、ローンチパートナーであるDynatrace、Datadog、Splunkとも連携可能です。さらに、PrometheusやLoki、Grafanaなどのオープンソースツールにも対応しています。
独自のテレメトリーシステムを使用している場合でも、BYO MCP Server(Bring Your Own MCP Server)機能を使用することで、約20分程度で任意のテレメトリーシステムに対応できます。エージェントは、ログ、メトリクス、アラーム、トレースを迅速にスキャンするだけでなく、オブザーバビリティ態勢の改善提案(メトリクスの追加、アラームの調整など)も行います。
3. パイプラインのプロ

多くのインシデントは、アプリケーションコードやインフラストラクチャコードの変更によって引き起こされます。AWS DevOps Agentは、GitHub、GitLab、AWS CodePipelineなどのCI/CDパイプラインと統合し、コード変更やインフラストラクチャコードの変更を検出し、デプロイメントを追跡します。
これにより、インシデントと変更の相関関係を迅速に特定できます。また、将来のインシデントを防ぐために、パイプライン自体の改善提案(テスト追加など)も行います。
4. アプリケーションを深く理解

AWS DevOps Agentは、アプリケーショントポロジーを自動生成します。これは、アプリケーションとエンティティの関係を示す知識グラフで、調査時にどこを調べるべきかをエージェントが理解するために使用されます。
さらに、ステアリングファイル(Runbook)を提供したり、ServiceNowやConfluenceなどに保存されている既存のRunbookにアクセスすることで、組織固有のプラクティスを反映させることができます。調査中に人間のエキスパートが必要な場合は、1クリックでAWSサポートエンジニアを呼び出し、すべてのコンテキストを共有して協力することも可能です。
デモ1: インシデント対応の自動化
セッションでは、「Robots as a Service」という架空のマイクロサービスアプリケーションを使用したデモが実施されました。

このアプリケーションは、Gateway、Bot Service、Schedule Service、IoT Service、Forge Serviceなどの複数のマイクロサービスで構成されており、それぞれがセキュリティグループ、ロードバランサー、Auto Scalingグループなど、多数のコンポーネントを持つ複雑な構成になっています。
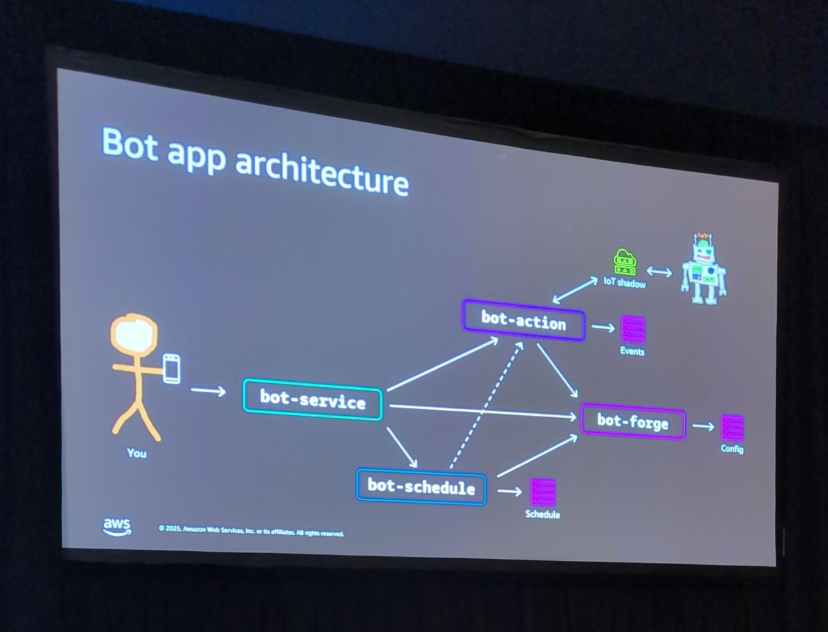
シナリオ: キャッシュバグの導入
デモでは、まずForge Serviceのキャッシュロジックに意図的にバグを導入しました。

具体的には、キャッシュレコードにタイムスタンプフィールドを追加するという、一見無害に見える変更を行いました。
しかし、この変更をデプロイした直後、Dynatraceが自動的に問題を検出し、Bot Serviceでエラー率が増加していることを報告しました。
Dynatraceは、このアラートをwebhook経由でAWS DevOps Agentに通知しました。
エージェントは即座に調査を開始し、エンジニアがラップトップを開く前に調査を完了させました。根本原因として「キャッシュシリアライゼーション形式の非互換性」を特定しました。
詳しく見ると、エージェントは新しいタイムスタンプフィールドの追加を検出し、デシリアライゼーションメソッドが新しいフィールドに対応していないことを特定しました。
さらに興味深いことに、エージェントはキャッシュミスのリクエスト(DynamoDBに直接アクセスしたリクエスト)が成功していることも観察し、これが問題の証拠として重要であることを理解しました。
最後に、エージェントはGitHub Actionsを使用したロールバック手順を含む詳細なMCM(変更ドキュメント)を生成しました。
このドキュメントには、準備、事前検証、適用、事後検証、そして万が一の場合のロールバック手順が含まれており、本番環境での変更を安全に実行できるようになっています。
さらに、長期的な解決策として、コード修正やテストの追加も提案されました。
調査プロセスの可視化
エージェントがどのように調査を進めたのか、そのプロセスを見ます。
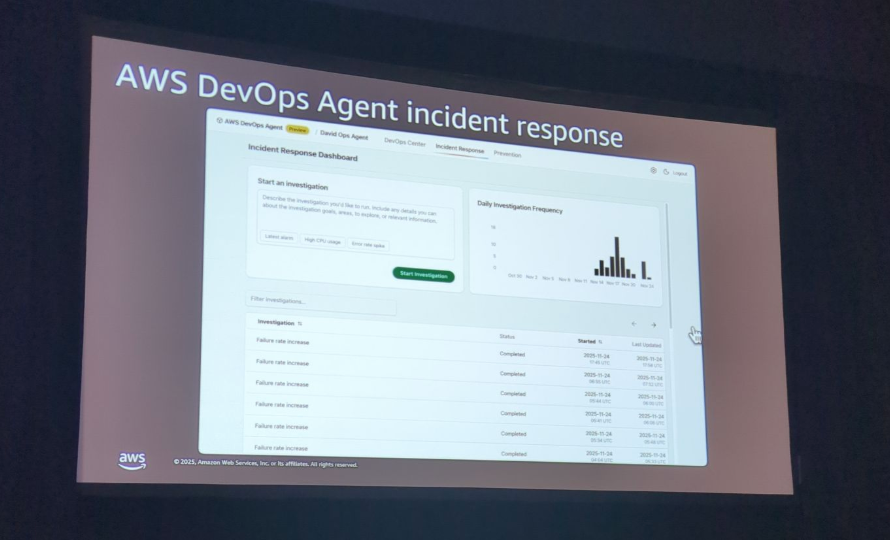
まず、エージェントはアプリケーショントポロジーを理解し、サービス間の関係を把握します。
次に、各サービスの健全性を確認するトリアージを実行し、最も依存性の高いサービス(この場合はBot Forge)に焦点を絞り込みました。
ここからが興味深い点です。エージェントは、人間のエンジニアよりも多くの「手」を持っているかのように、複数のサブエージェントを立ち上げて並行調査を実行しました。
デプロイメント履歴、EC2インスタンスの健全性メトリクス、DynamoDBテーブルの容量、アプリケーションログ、トラフィックパターンなど、調査すべき項目を同時に調査し、結果を集約しました。
証拠の収集段階では、CloudFormationスタックのデプロイメントを検出し、新しいインスタンスと古いインスタンスの置き換えを確認しました。
ログからはスタックトレースを発見し、GitHub Actionsからはコード変更の詳細を特定しました。これらすべての情報を統合することで、正確な根本原因分析を実現しています。

一連のインシデントフローはこちらです。
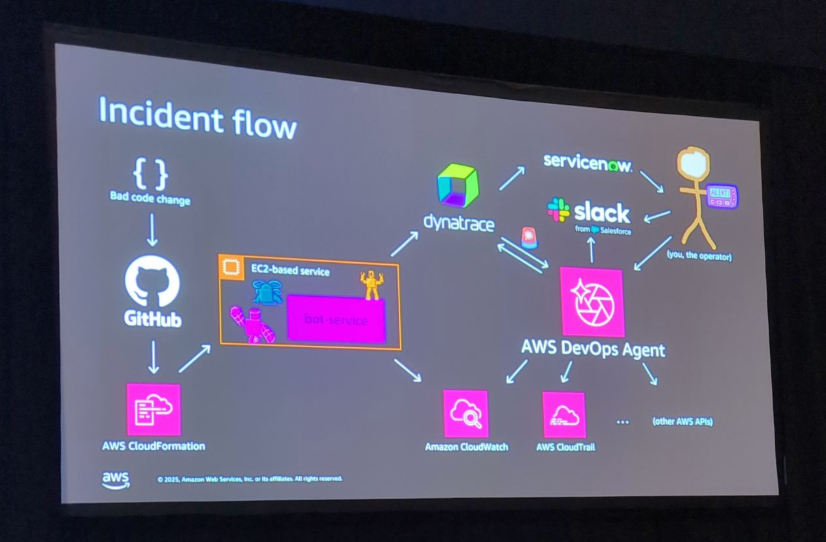
デモ2: カスタムMCPサーバーの活用
2つ目のデモでは、独自のログストアを使用している場合の統合方法が紹介されました。
多くの組織では、S3などのカスタムログストアを使用していますが、BYO MCP Server(Bring Your Own MCP Server)機能を使用することで、約20分程度で統合が可能です。
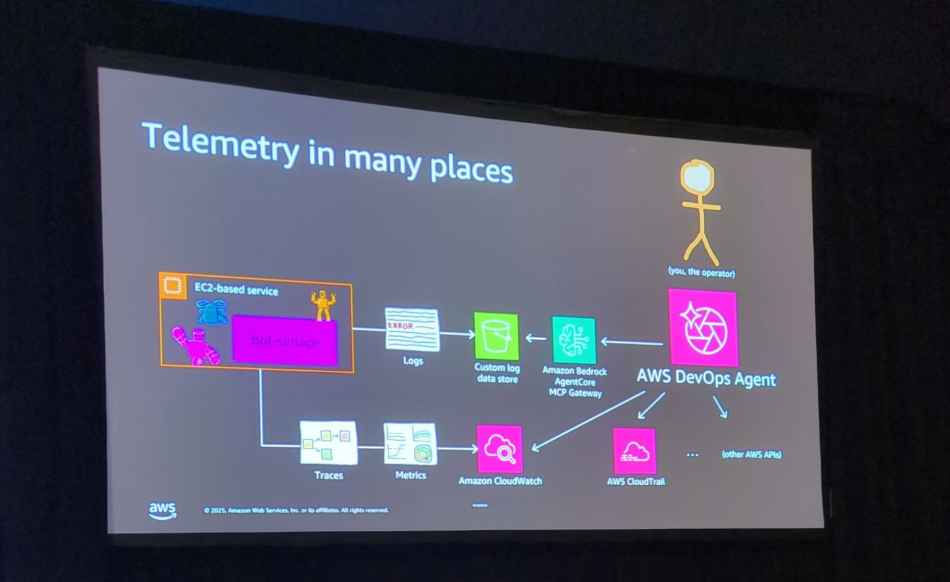
統合に必要なのは以下の要素です
- 実装時間: 約20分
- 使用ツール: Amazon Bedrock Agent Core MCP Gateway、Lambda
- 結果: エージェントがカスタムログソースから情報を取得し、調査に活用
手動オペレーションによる障害のケース
このデモでは、エンジニアがEC2インスタンスにSSM経由でログインし、キャッシュファイルを削除するという手動操作を行ったシナリオが取り上げられました。
この操作により、SQLiteキャッシュテーブルが破損し、HTTP 500エラーが発生しました。
AWS DevOps Agentは、S3に保存されているアプリケーションログから、カスタムMCPサーバー経由で問題を特定しました。
さらに、CloudTrailのログを分析することで、SSMセッションによる手動操作が根本原因であることを突き止めました。
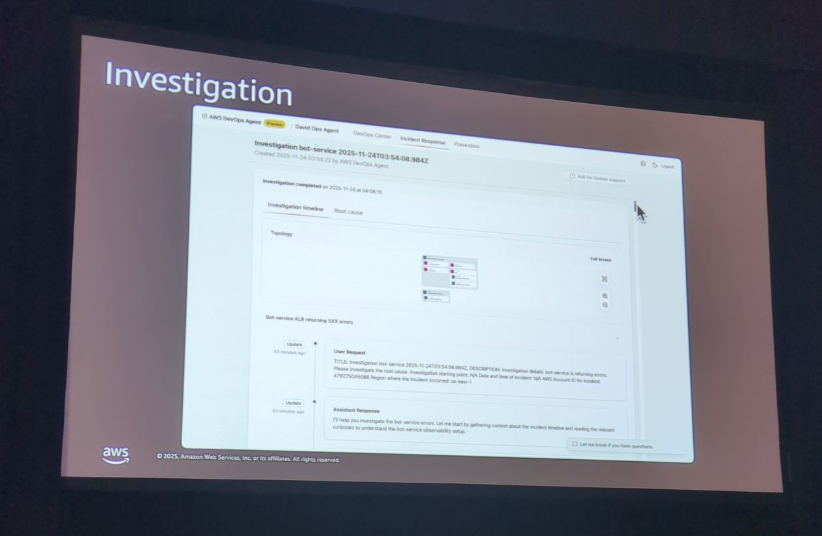
デモ3: チャットによる対話的な調査
3つ目のデモでは、AWS DevOps Agentとの対話的なやり取りが紹介されました。
エージェントは、自動調査を実行するだけでなく、チャットインターフェースを通じて人間のエンジニアと自然なコミュニケーションを取ることができます。
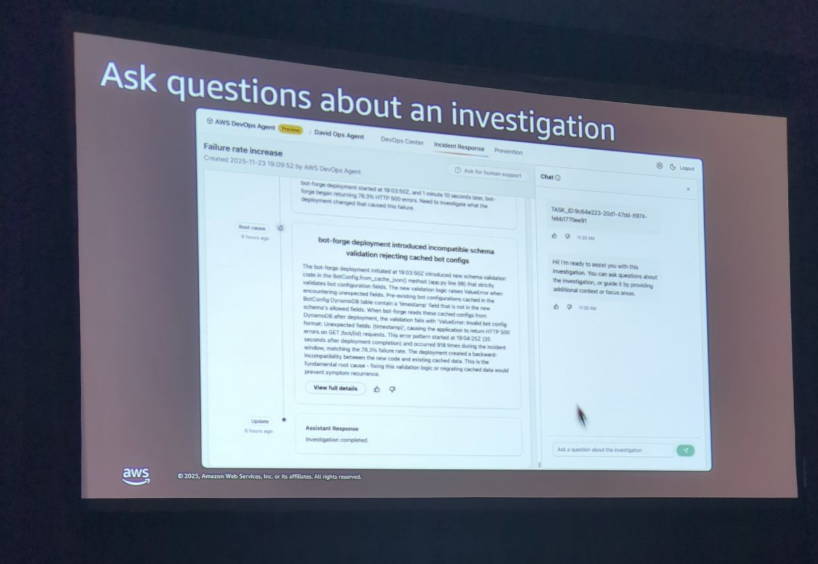
質問応答の柔軟性
基本的な質問から高度な分析まで、幅広い質問に対応可能です
- 基本的な質問: 「開始時刻は?」「どのアラームがトリガーされた?」
- 詳細なレポート: 「顧客への影響を要約して」→ サービスごとの障害率、期間、顧客対応の影響を含むレポートを生成
- 深掘り調査: 「何台のロボットが影響を受けた?」→ スパンデータを追加で照会し、91台のユニークなロボットを特定
調査の誘導(ステアリング)
調査中にエージェントの方向性を修正することも可能です。
例えば、複数の異なる時間帯に問題が発生していた際、「最新の影響に焦点を当てて」と指示することで、エージェントは自らのプロンプトを改善し、最新のタイムスタンプに基づいて調査を絞り込みます。
環境の学習
インシデント対応以外の質問にも対応できます。例えば、「数分前に何台のEC2インスタンスが終了した?」と質問すると、エージェントは54台のインスタンスが過去30分間に終了したことを検出し、Auto Scalingグループでのインスタンスチャーンが発生していることを指摘しました。
デモ4: 将来のインシデント予防
4つ目のデモでは、AWS DevOps AgentのPrevention Investigator機能が紹介されました。
この機能は、過去のインシデントを分析し、長期的な改善を提案することで、同じ問題が再発することを防ぎます。

推奨事項は以下の3つのカテゴリに分類されます:
- ガバナンス
- インフラストラクチャ
- オブザーバビリティ
具体的な推奨例
セッションでは、4つの具体的な推奨例が紹介されました。
1. Auto Scalingの設定改善
min instances in serviceパラメータが適切に設定されていない場合、すべてのインスタンスが同時に置き換えられるリスクがあります。
エージェントは、より安全な設定に変更し、常に最低限のインスタンスを稼働させることを推奨しました。
2. DynamoDBテーブルのアクセス許可管理
10回にわたってテーブルポリシーが変更され、その度にアクセス拒否エラーが発生していたことが判明しました。
エージェントは、アクセス許可をロックダウンし、不正な変更を防止する対策を提案しました。
3. デプロイ後のヘルスチェック実装
Pingヘルスチェックにシンタックスエラーがあり、インスタンスが起動と終了を繰り返すという問題が見つかりました。
エージェントは、デプロイ後のヘルスチェック検証と自動ロールバックの実装を推奨しました。
4. CI/CDパイプラインの改善
キャッシュ破壊バグが複数回プロダクション環境に到達していたことが明らかになりました。
エージェントは、テストの追加、ステージング環境での検証強化、自動ロールバックの実装を提案しました。
アプリケーショントポロジーの仕組み
AWS DevOps Agentの重要な機能の1つが、アプリケーショントポロジーの自動生成です。
これは、アプリケーションとエンティティの関係を示す知識グラフで、エージェントが調査時にどこを調べるべきかを理解するために使用されます。
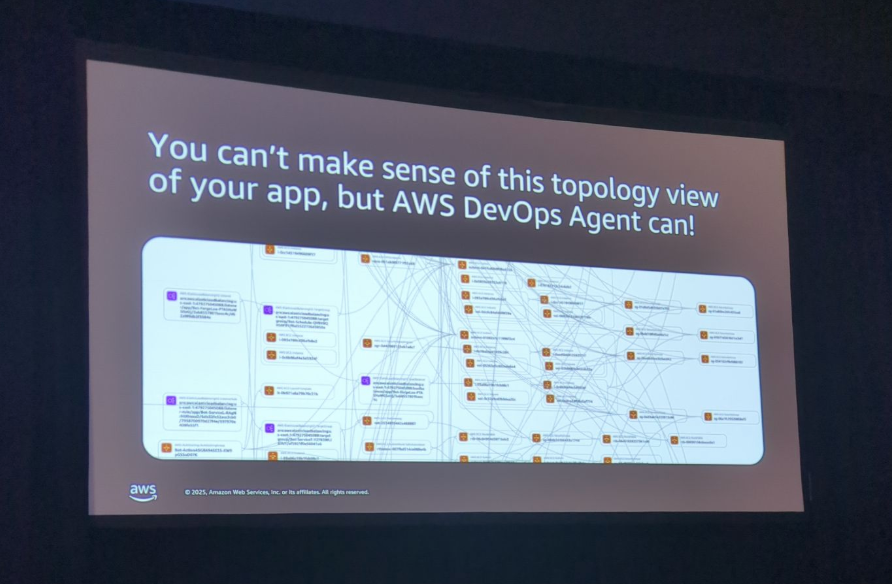
自動生成プロセス
トポロジーは以下の5つのステップで自動生成されます
- Agent Spaceの作成: 1つまたは複数のクラウドアカウントにアクセス
- リソースの発見: IAMロールを通じて許可されたリソースとその関係を発見
- サービスマップの統合: テレメトリーソースからサービスマップを取得
- エンティティのマッピング: ログ、グループ、メトリクス、アラームをエンティティにマッピング
- デプロイメントの追跡: CI/CDパイプラインからデプロイメントをエンティティにマッピング
活用方法
このトポロジーは、様々な場面で活用されます
- インシデント時: ログやメトリクスのクエリを絞り込み、効率的な調査を実現
- 予防時: AWSベストプラクティスやWell-Architectedの原則と比較し、逸脱を検出
- ステアリングファイル: 組織固有のガイドラインやポリシーとの比較により、より組織に適した調査・改善提案を実現
AWS DepOps Agentの利用開始方法
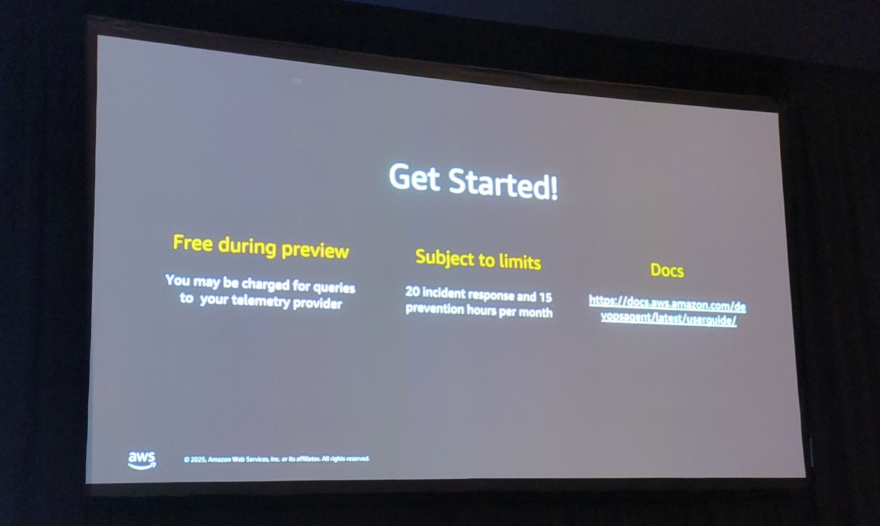
- 提供形態: AWSコンソールでパブリックプレビューとして利用可能
- 料金: プレビュー期間中は無料(エージェントが実行するアクションに伴うAWSサービスの料金のみ)
- 制限:
- アカウントあたり20エージェント
- 月あたり20時間の調査時間
- 月あたり15時間の予防時間
おわりに
今回のre:Invent 2025のセッション「Move beyond reactive: Transform cloud ops with AWS DevOps Agent」では、インシデント対応を革新する新しいアプローチを学ぶことができました。
単なる運用自動化ツールではなく、「チームメンバーとして機能する」という点が良いなと思いました。
また、過去のインシデントを分析して将来の問題を予防する提案まで行う、ということで人間よりも賢い能力を持っています。
パブリックプレビューとして無料で試せるので、ぜひこの機会に触ってみましょう!
最後までお読みいただきありがとうございました!
どなたかのお役に立てれば幸いです。
以上、おつまみ(@AWS11077)でした!










