Snowflakeの自然言語によるデータ分析機能であるCortex Analystに入門する
データ事業本部の鈴木です。
みなさんはSnowflakeのデータを自然言語で分析するための機能であるCortex Analystは使っていますでしょうか?
Snowflake Summit 2025ではCortex Analystを組み込んだ機能もいくつか発表されており、ますます盛り上がってきている機能です。
最近は私もデータ分析のために生成AIに自然言語で問い合わせて分析させる方法を調べる機会も増えており、その選択肢の一つであるCortex Analystについてもより理解が深まってきました。
簡単な使い方などは以前もご紹介しましたが、改めてまとめてみました。
Cortex Analystとは
平たく言うと、「Snowflakeに格納したデータを自然言語で分析するための機能」です。分析はテーブルまたはビューをデータソースとします。
とはいえ、この機能の実現にはさまざまな技術要素が必要となります。
Cortex Analystは、例えばSnowflakeに格納しているデータの構造を知らない、もしくはSQLを使わないビジネスユーザー向けの分析作業も効率化することができますが、ユーザーが入力したテキストと実際のデータは意味は同じでも文字列として一致するわけではないため、上手く対応づける必要があります。出力されるSQLも基本的にSnowflakeのエンジンで実行できる必要があります。また、ユーザーが適切な質問を入力できない時には質問例を提案する必要もあるかもしれません。
このように、ビジネス的にはよくあるニーズに対するツールではあるものの、実際の処理としてはかなり高度な処理が必要となります。なお、Cortex Analystはこれらの要素をセマンティックモデルやセマンティックビュー(記事執筆時点でプレビュー)に記載します。また、SQLの正確さを保つためCortex Analyst内では、以下のように複数のエージェントが動作しています。
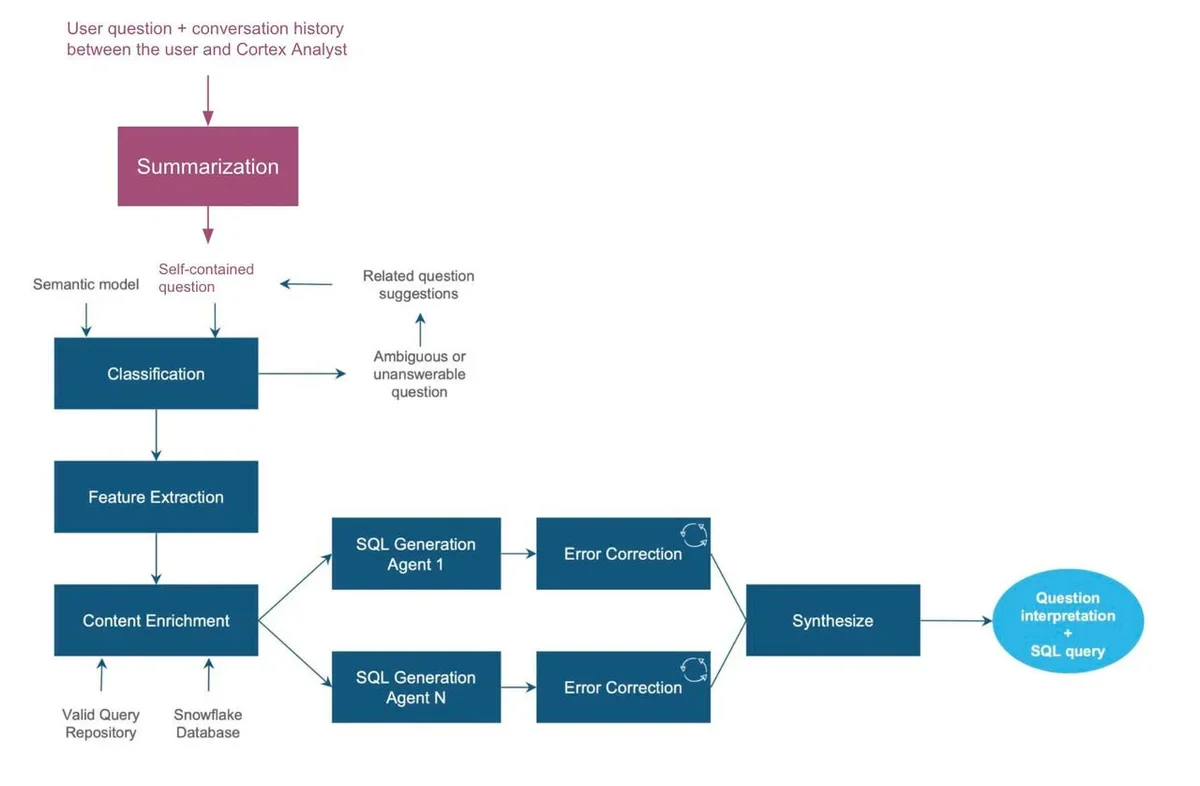
(上記ブログ記事より)
Cortex AnalystはREST APIから利用します。マルチターンの会話にも対応しています。
回答はセマンティックモデルまたはセマンティックビューの情報をもとに作成します。
勘違いしがちな点として、SQL結果が返されるわけではありません。SQL実行結果は別途実行する必要があります。
後ほど紹介するように、Snowflake Intelligenceのような自然言語→分析結果のインターフェースも登場してきており、確実にデータ分析における生成AIの活用は進んでいます。
個人的には分析作業が今すぐ完全に生成AIに置き換わるというよりは、アドホックな分析をユーザーがより自分で行いやすくなる、という発展として捉えて、重要で高い品質が求められる分析は専門家が引き続き開発を行うという考え方が良いように考えています。ダッシュボードなどの開発・保守をしたことがある方だと経験があるかもしれませんが、分析のリクエストは事業の進展によりどんどんと出てくるため、開発チームは発展が嬉しいながらも、場合によってはかなり多くの開発作業を行うことがあります。また、ユーザー側もそのリードタイムを計算して依頼をしないといけません。そのため、急ぎだけれどもダッシュボードに組み込むかは分からないアドホックな分析は依頼側が自分たちで行いやすくなった、という捉え方をするのがしっくりくるように考えています。
Cortex Analystの周辺機能
Rest APIから直接実行する以外に、Cortex Agentsから実行することも可能です。この機能はGAが予告されていますが現状はプレビューです。
以前は動作確認できていませんでしたが、ドキュメントにはエージェントが使うツールとしてdata_to_chartというチャート作成用のものも記載されており、今後使えるようになるのではと期待はしております。
Snowflake Intelligence(記事執筆時点でプライベートプレビュー)からも利用されます。
自然言語での問い合わせに対して、SQLの生成と回答、作図も行ってくれるようです。
Cortex Analystのコスト
2025年7月現在ですと、1000メッセージで67クレジットです。
ただしメッセージ当たりの文字数による課金の差はありません。
コストの考え方としては、例えばBIダッシュボードにない新しい分析を追加したいような場合に、まずはCortex Analystで分析してみることができます。ダッシュボードなどの開発チームの対応工数をセーブしつつ、分析が欲しい依頼者側もリードタイムが削減できるのであれば十分に効果があると考えられます。
Text2SQLの自作
SQL生成の機能自体は自作も可能です。AWSのブログでは色々とアイデアが紹介されており、とても参考になります。
自作の場合、先に紹介したように、Snowflakeの文法を守らせる工夫や構文ミスの修正などさまざまな課題があります。加えてユーザーが入力するビジネス用語と分析対象のデータとのマッピングも適切に行う必要があります。
上記ブログでも参照されている論文『Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies』によると、以下のようにプロンプトを作ることで、メタデータを含めて、LLMにSQL文を考えさせることができると紹介されていました。なお、リレーションシップを考慮させる例も同様に紹介されています。
/* Given the following database schema : */
CREATE TABLE IF NOT EXISTS " department " (
" Department_ID " int , -- a unique identifier for a department
" Name " text , -- the name of the department
" Creation " text , -- the date the department was created
" Ranking " int , -- the ranking of the department within the organization
" Budget_in_Billions " real , -- the department 's budget in billions of dollars
" Num_Employees " real , -- the number of employees in the department
PRIMARY KEY ( " Department_ID " )
) ;
CREATE TABLE IF NOT EXISTS " head " (
" head_ID " int , -- a unique identifier for the head of a department
" name " text , -- the name of the head of the department
" born_state " text , -- the state where the head of the department was born
" age " real , -- the age of the head of the department
PRIMARY KEY ( " head_ID " )
) ;
CREATE TABLE IF NOT EXISTS " management " (
" department_ID " int , -- the unique identifier for the department being managed
" head_ID " int , -- the unique identifier for the head of the department
" temporary_acting " text , -- whether the head of the department is serving in a
temporary or acting capacity
PRIMARY KEY ( " Department_ID " , " head_ID " )
FOREIGN KEY ( " Department_ID " ) REFERENCES `department `( " Department_ID " )
FOREIGN KEY ( " head_ID " ) REFERENCES `head `( " head_ID " )
) ;
/* Answer the following : What are the distinct creation years of the departments
managed by a secretary born in state 'Alabama '? */
select distinct t1 . creation from department as t1 join management as t2 on t1 .
department_id = t2 . department_id join head as t3 on t2 . head_id = t3 . head_id
where t3 . born_state = 'Alabama '
実際に試してみると、案外この方法でSQL文を作成させることは可能です。ただし、先に記載した課題を解決するためには、冒頭で紹介したCortex Analystの仕組みのように、追加の工夫が必要です。また、分析したいテーブルが多岐に渡る場合にも、質問に適したテーブル定義をRAG用に取得する仕組みが必要です。
このように、単純にSQL生成ができるかどうかだけでなく、ビジネス用語を解釈する仕組み、生成したSQLの間違いを発見する仕組みや、サポート範囲を拡大させる仕組みが必要で、どこまで対応するか・どの程度の正確さを目指すかは、コンセプトをよく考える必要があります。
Cortex Analystの回答生成
以上からCortex Analystがあるとかなり楽に自然言語による分析が実現できそう、というイメージを抱いて頂けたかと思いますが、最後に少し使用感をご紹介します。
分析のためにはまずセマンティックモデルまたはセマンティックビューの作成からが必要です。
セマンティックモデルの作成
開発段階ではSnowsightのAI&MLから使うとブラウザ上で作業でき、扱いやすいです。
Create new model > Create new modelよりセマンティックモデルまたはセマンティックビューを作成することができます。
動線は同じだったので、ここではセマンティックモデルの方で例を紹介します。題材としてはクイックスタートの『Getting Started with Cortex Analyst: Augment BI with AI』を使います。
まずは作成する種別を選択し、保存先や名称を指定します。
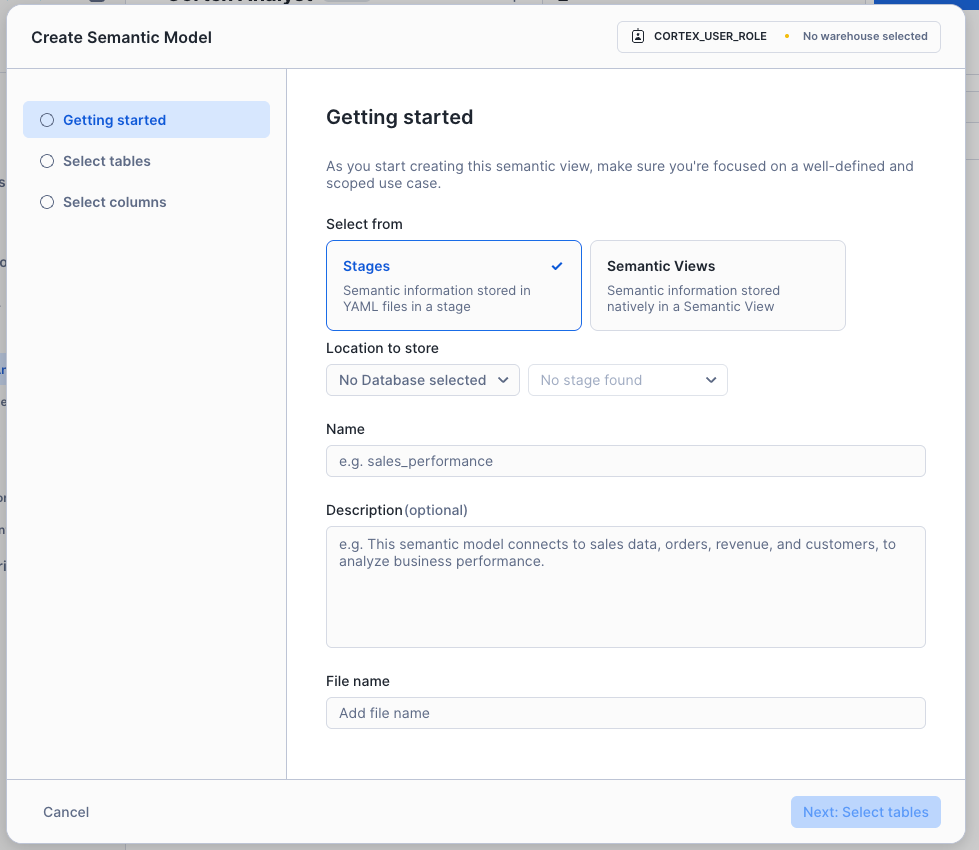
続いてどのテーブルを使うか指定します。
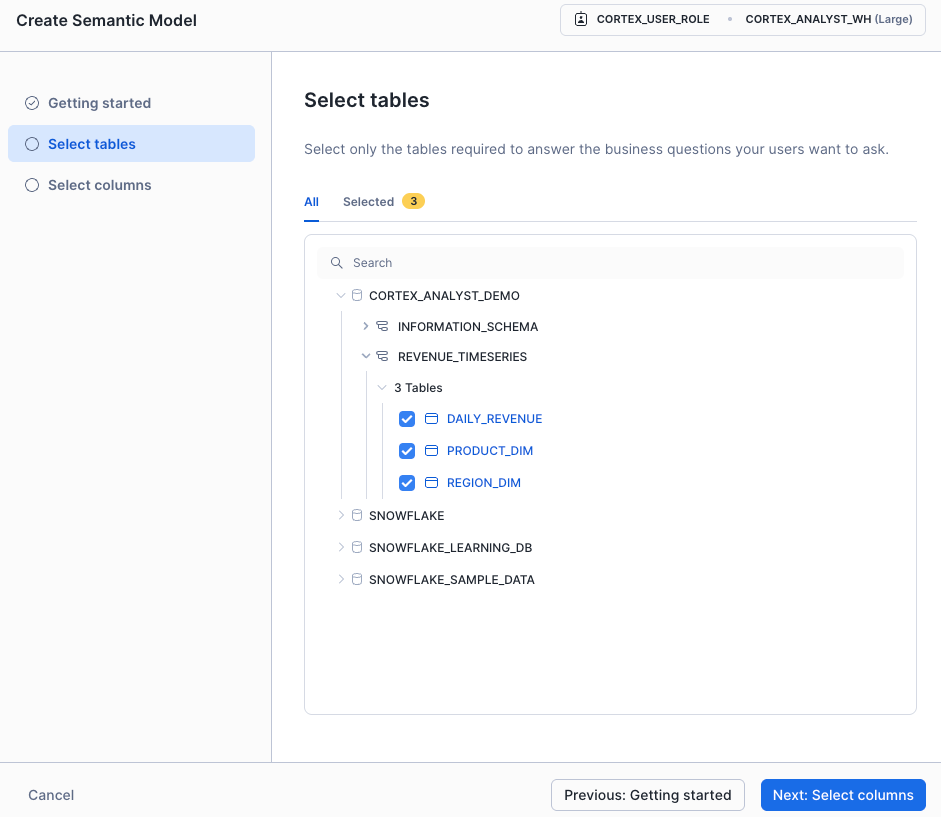
どのカラムを使うかも指定します。サンプルデータをセマンティックモデルに含めるかも指定できます。これで初期の作成は完了です。
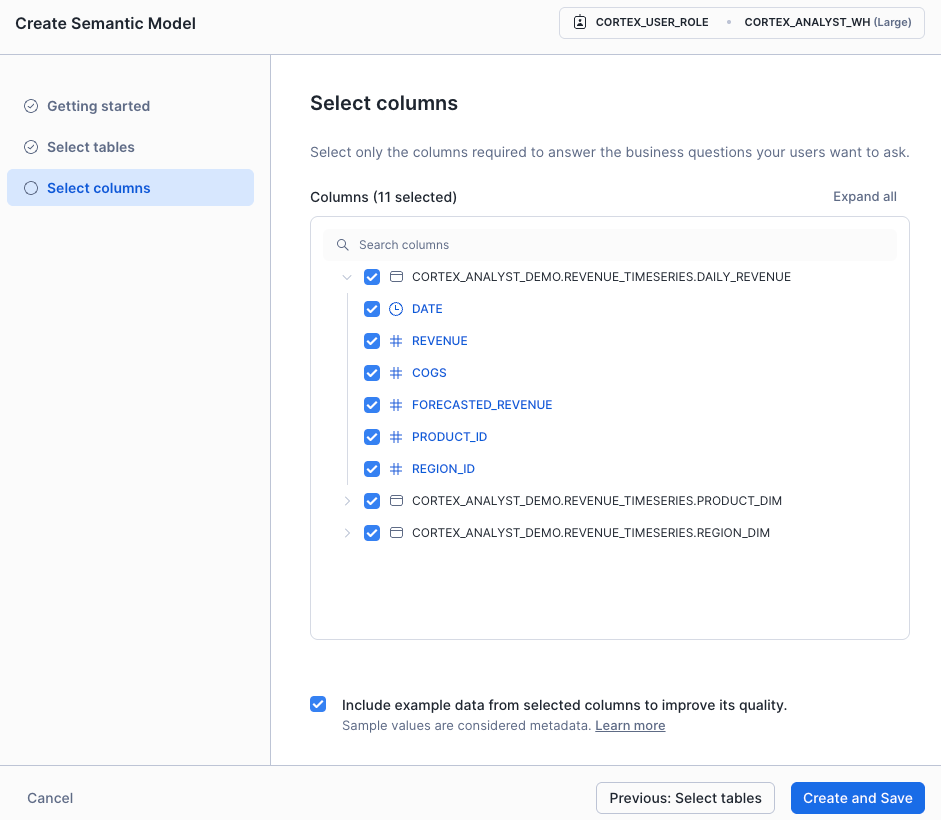
もちろん、手元のエディタなどで作りたい場合は、それでも問題ありません。Snowsightから叩き台を生成し、手元で編集するなどでも良いと思います。
質問してみる
Cortex AnalystはSnowflakeのアカウントへ接続さえできればREST APIから実行可能ですが、セマンティックモデルの作成と同じく、Snowsightから実行するとデバッグが楽です。
以下が試しに作成してみたセマンティックモデルの画面です。
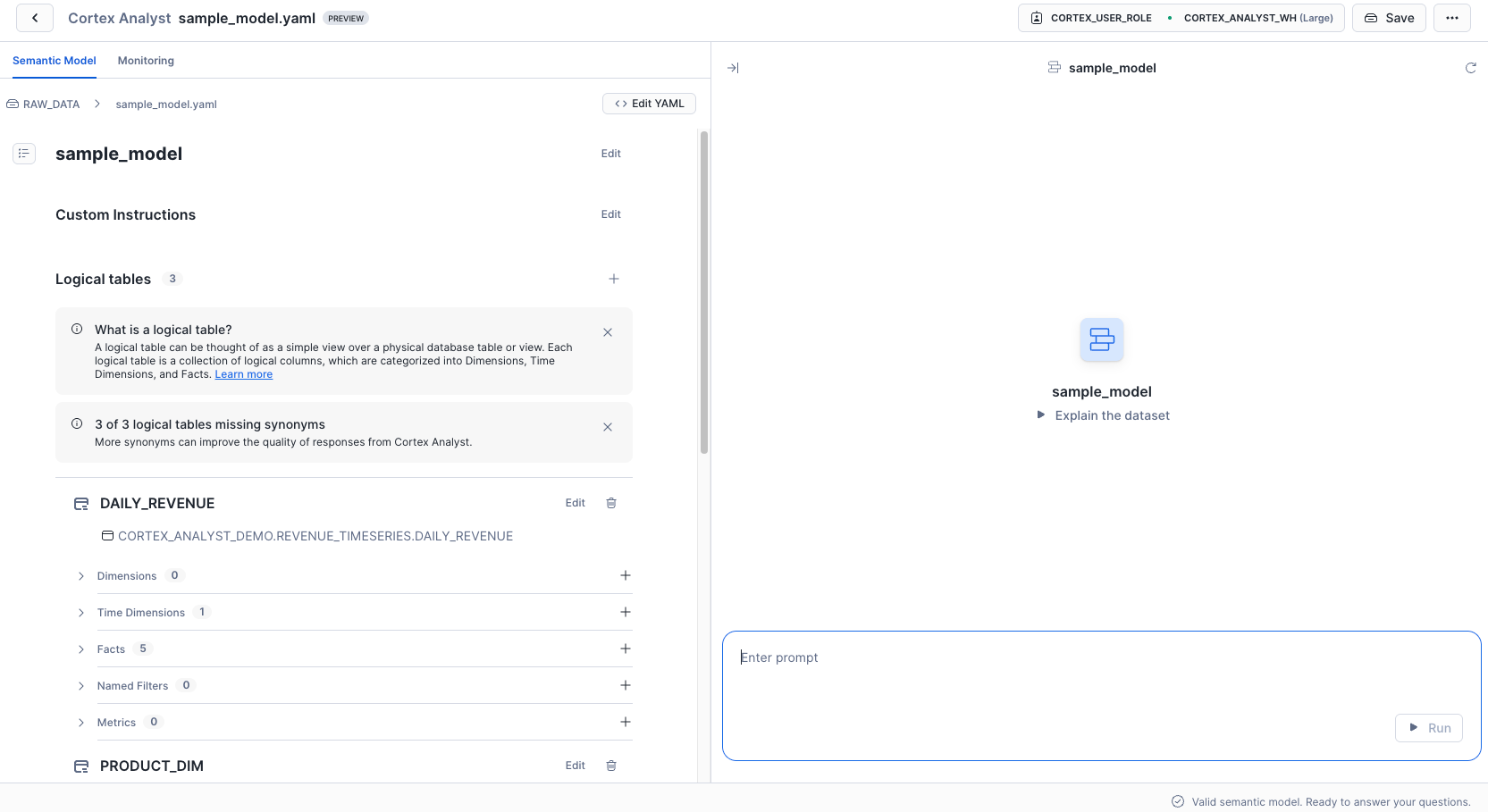
テーブルには以下の設定があります。
- Dimensions
- Time Dimensions
- Facts
- Named Filters
- Metrics
また、テーブル間のリレーションシップの設定や、類似した質問に答える際に使用する検証済みクエリリポジトリ(VQR)へのクエリ追加も行うことができます。
今回のデータについて質問をしてみました。回答は英語で返ってきます。REST APIから利用する場合は、レスポンス内の回答を日本語に翻訳するとよいかもしれません。
個人的に注意すべき点としては、質問が英訳されてしまっていると思われる点です。分析上、固有名詞を使う場合に性能が出ない際は、レスポンスのテキストを確認するとよさそうです。
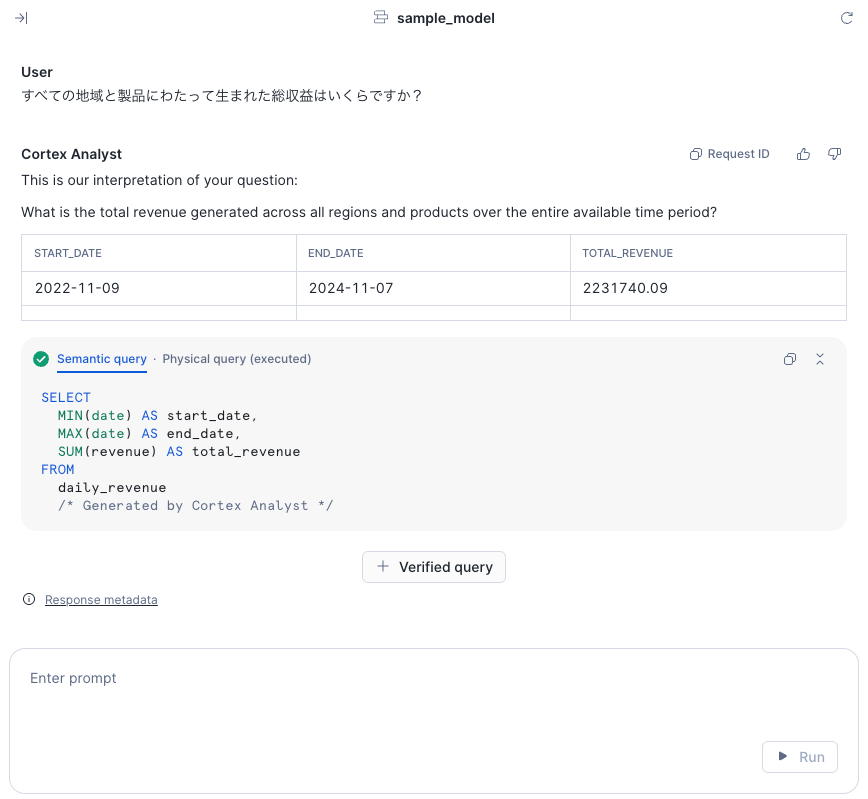
Response metadataとして、なんのモデルを使っているかも確認できました。今回はclaude-4-sonnetを使っているようでした。

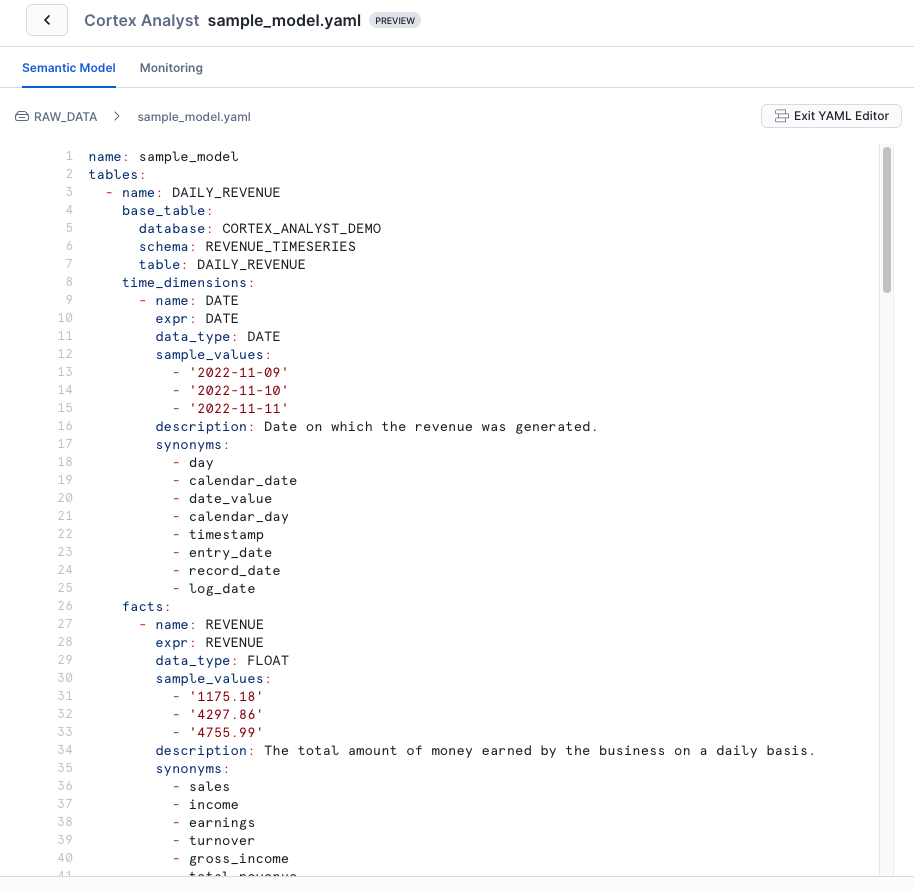
YAML Editorからは作成されたセマンティックモデルのYAMLファイルを確認・編集することが可能です。Snowsight上からCortex Analystの回答をみつつ、セマンティックモデルの編集ができます。
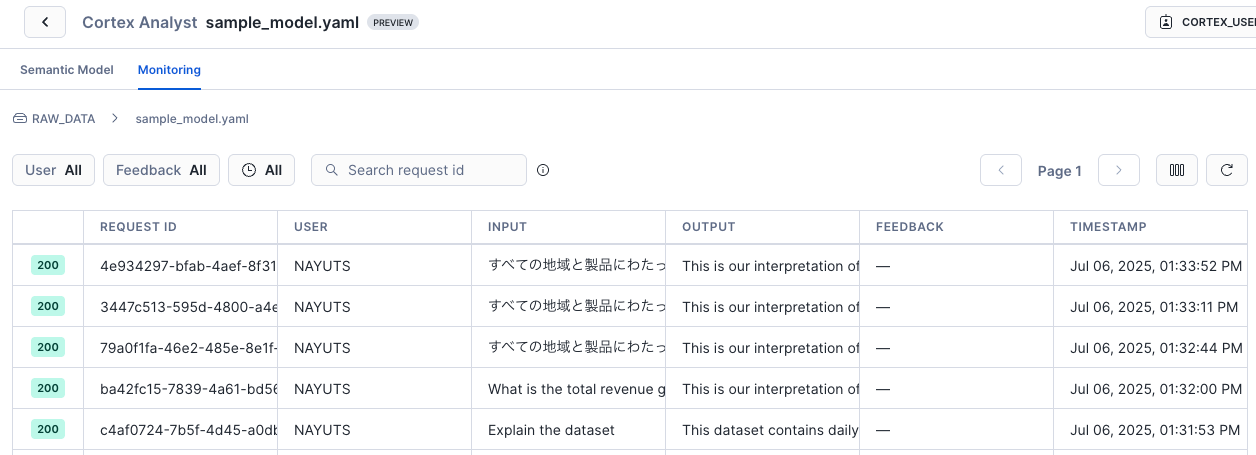
モニタリングも可能でした。
セマンティックモデルの留意点
セマンティックモデルを1つ作れば、求められるあらゆる分析に対応できるのか、というと現状はそうではないと解釈しており、適切な粒度でセマンティックモデルを分割しておくのがよいと考えています。
以下のガイドの『create-a-semantic-model-using-the-model-generator』を見ていただくと記載があるように、ハードリミットではないものの、テーブルは10、カラムは50に絞ることがおすすめされています。
また、セマンティックモデルのDimensionやFactのような記載から分かるように、最大限パフォーマンスを出すには、テーブルをCortex Analystが使いやすい形式にしておく必要があると思います。そのため、Cortex Analystを使うだけで万事うまくいくというわけではなく、データの持ち方はしっかり設計する必要があります。
個人的には、以下で紹介されているように、Tableauなどで利用するのと同様の読み取りやすい形式になるようにしておくのが良いと考えています。
こうしておくことで、生成されるSQL文やセマンティックモデルに記載する内容が簡潔になります。
最後に
Text2SQL機能の自作にも少し触れつつ、Snowflakeの自然言語によるデータ分析機能であるCortex Analystを改めてご紹介しました。
Snowflake Intelligenceなど魅力的な機能が出てきているなかで、自然言語による分析をどのように導入していくかや、そもそもその中核にあるCortex Analystってどんな機能なんだっけ?自作する場合とどう違うのかな?とさまざまな疑問が出てきていると思います。
そういった疑問解決の参考になりましたら幸いです。








