Snowflakeのデータ検索機能であるCortex Searchに入門する
データ事業本部の鈴木です。
Cortex Searchを使うと、Snowflake上で誰でも簡単にテーブルなどに対するキーワードおよびベクトルのハイブリッドな検索システムを構築・利用できます。
今回はCortex Searchと利用方法についてご紹介します。
Cortex Searchについて
Cortex SearchはSnowflakeのネイティブなデータ検索機能を簡単に構築・利用できます。
現時点では、RAGのためのテキストデータ検索の用途で使われることが多いのではないでしょうか。
この機能は昨年の夏からパブリックプレビューが開始され、同年の10月から一般提供を開始したサービスとなっています。
当時は以下のブログでも紹介しました。
SQLなどでの操作に加え、SnowsightからUIでぽちぽちと管理も可能で、誰でも非常に使いやすいです。検索対象のデータが既にテーブルに入っている場合は、ものの数分でCortex Searchサービスが作成できてしまいます。
▼ データベースからも見える
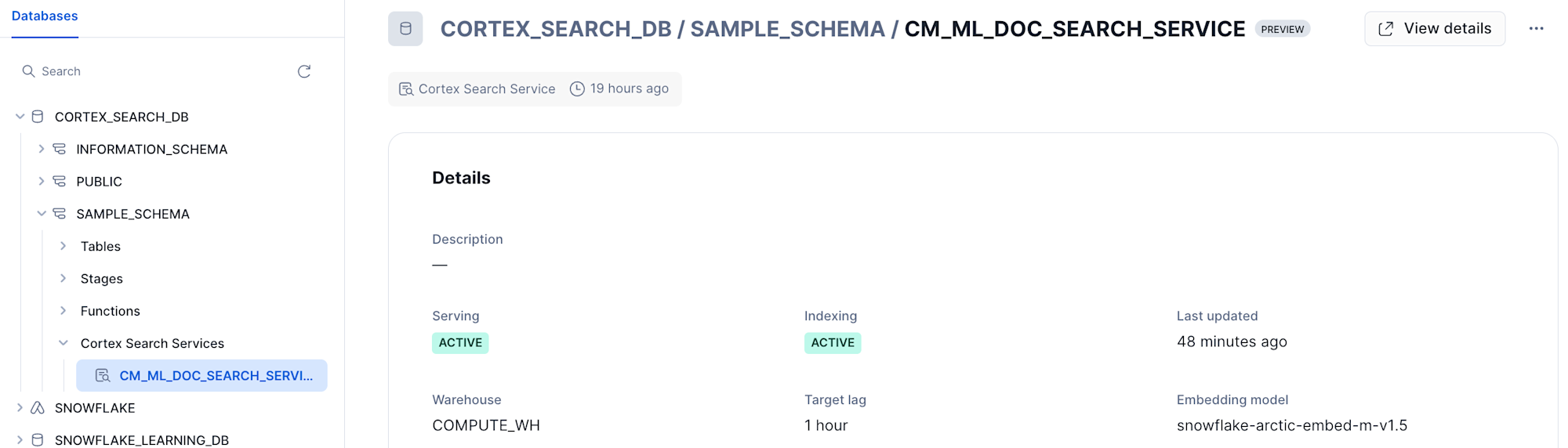
▼ Cortex Search向けのページもある
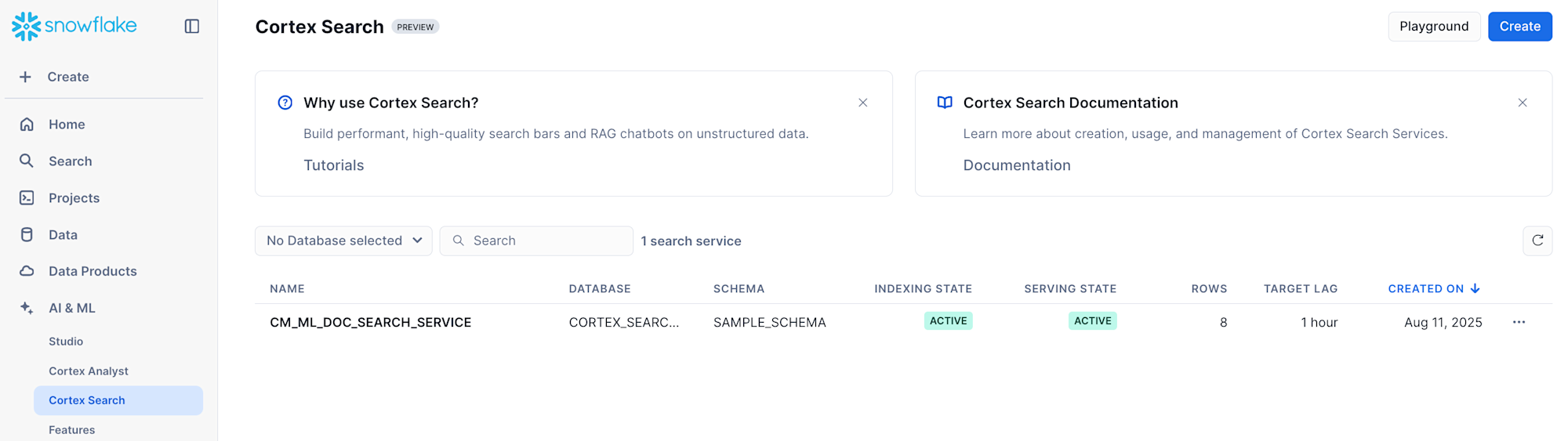
使い方が簡単なだけではなく、キーワードおよびベクトルのハイブリッドな検索とリランキングを組み合わせて、高い検索精度も実現しています。
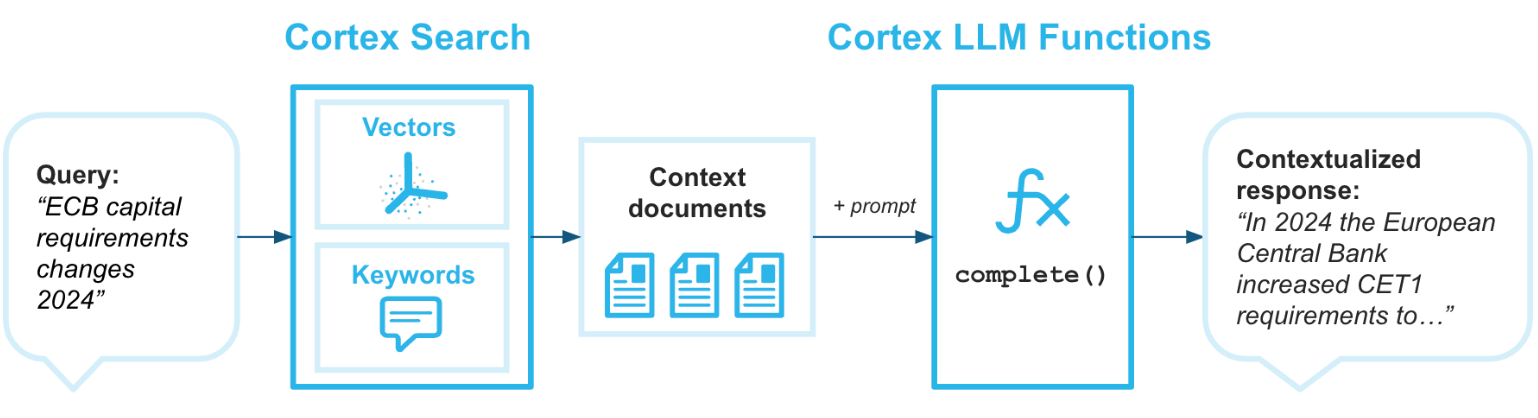
(引用元:RAG 向けのCortex Search)
この仕組みについては、パブリックプレビュー当時の以下の文書が分かりやすいです。
ユースケースとしては、やはりLLMと組み合わせてRAGでカスタマイズしたチャットアプリを作成する用途が主なものになると思います。
以下のようなイメージです。
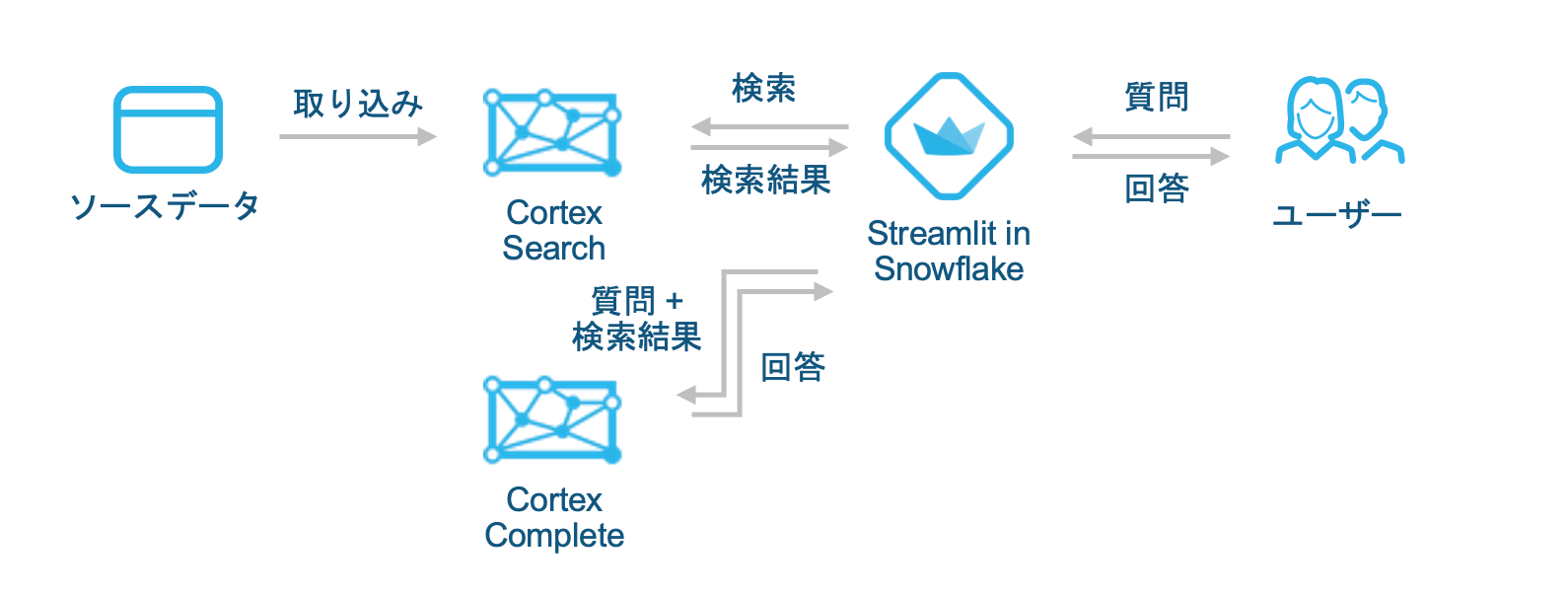
また、エンタープライズ検索のバックエンドとしても想定されています。
作成例
1. Cortex Searchサービスの作成
ドキュメントのチャンクとドキュメント名の2カラムがあるcm_ml_doc_chunksテーブルがあったとして、そのテーブルをもとに以下のSQLでCortex Searchサービスを作成できます。
CREATE OR REPLACE CORTEX SEARCH SERVICE cm_ml_doc_search_service
ON CHUNK
ATTRIBUTES relative_path
WAREHOUSE = compute_wh
TARGET_LAG = '1 hour'
AS (
SELECT
chunk,
relative_path
FROM cm_ml_doc_chunks
);
サービス作成時に、元のテーブルはCHANGE_TRACKINGが有効化されます。テーブルの所有権を持たないロールを使用して検索サービスを作成する場合は、別途有効化する必要があります。
ALTER TABLE cm_ml_doc_chunks SET
CHANGE_TRACKING = TRUE;
※補足
なお、cm_ml_doc_chunksテーブルは以下のUDFを定義し、
CREATE OR REPLACE FUNCTION pypdf_extract_and_chunk(file_url VARCHAR, chunk_size INTEGER, overlap INTEGER)
RETURNS TABLE (chunk VARCHAR)
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
HANDLER = 'pdf_text_chunker'
PACKAGES = ('snowflake-snowpark-python','PyPDF2', 'langchain')
AS
$$
from snowflake.snowpark.types import StringType, StructField, StructType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from snowflake.snowpark.files import SnowflakeFile
import PyPDF2, io
import logging
import pandas as pd
class pdf_text_chunker:
def read_pdf(self, file_url: str) -> str:
logger = logging.getLogger("udf_logger")
logger.info(f"Opening file {file_url}")
with SnowflakeFile.open(file_url, 'rb') as f:
buffer = io.BytesIO(f.readall())
reader = PyPDF2.PdfReader(buffer)
text = ""
for page in reader.pages:
try:
text += page.extract_text().replace('\n', ' ').replace('\0', ' ')
except:
text = "Unable to Extract"
logger.warn(f"Unable to extract from file {file_url}, page {page}")
return text
def process(self,file_url: str, chunk_size: int, chunk_overlap: int):
text = self.read_pdf(file_url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap,
length_function = len
)
chunks = text_splitter.split_text(text)
df = pd.DataFrame(chunks, columns=['CHUNK'])
yield from df.itertuples(index=False, name=None)
$$;
@CORTEX_SEARCH_DB.SAMPLE_SCHEMA.CM_MLというステージにアップロードしておいたPDFから作成しました。
CREATE OR REPLACE TABLE cm_ml_doc_chunks (
relative_path VARCHAR, -- Relative path to the PDF file
chunk VARCHAR
) AS (
SELECT
relative_path,
chunks.chunk as chunk
FROM
directory(@CORTEX_SEARCH_DB.SAMPLE_SCHEMA.CM_ML)
, TABLE(pypdf_extract_and_chunk(
build_scoped_file_url(@CM_ML, relative_path),
2000,
500
)) as chunks
);
いずれも冒頭に紹介した『[新機能]Snowflakeでテキストデータに対するRAGを簡単に実装できる「Cortex Search」を用いてRAGチャットボットを構築してみた』に記載のSQLを改変しました。
PDFの中身は、弊社の以下のサイトをブラウザでPDFにしたものになります。
テーブルの中身は以下のようになりました。
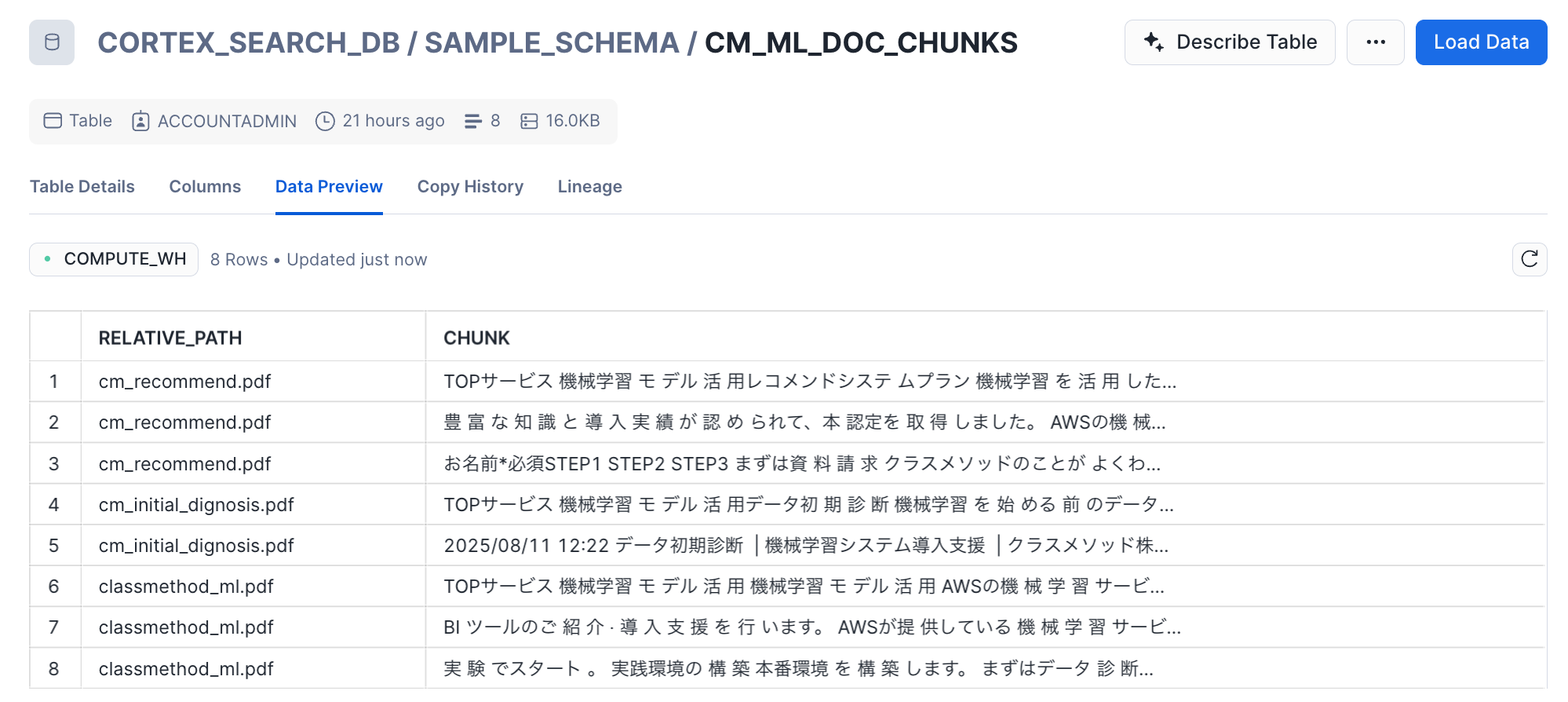
2. 検索の実行
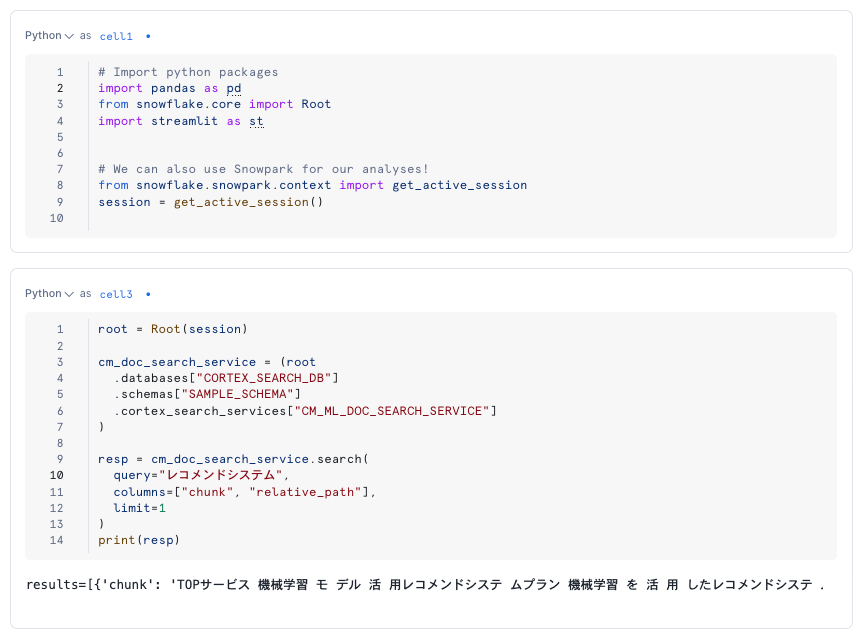
Pythonの場合、以下のようにsearchメソッドで検索することが多いと思います。特にStreamlitでUIを作って利用するケースです。
▼ searchメソッドの例
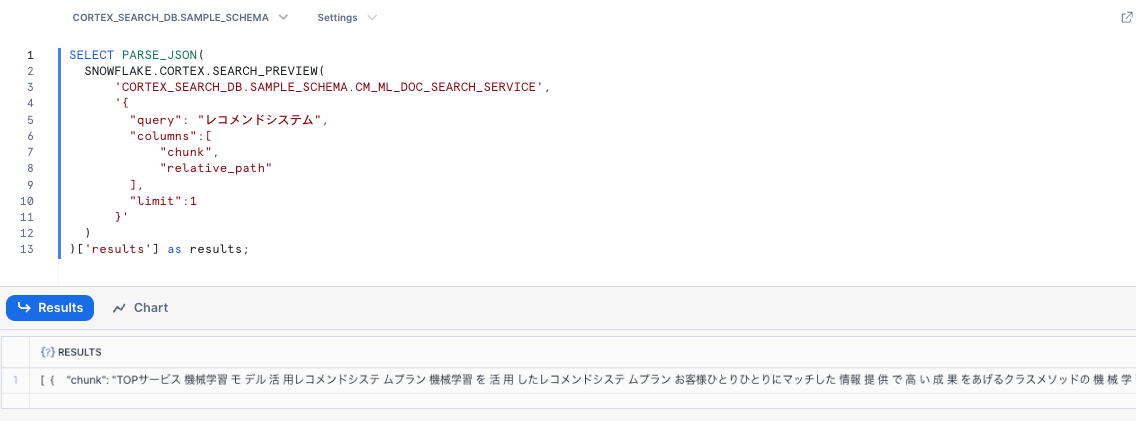
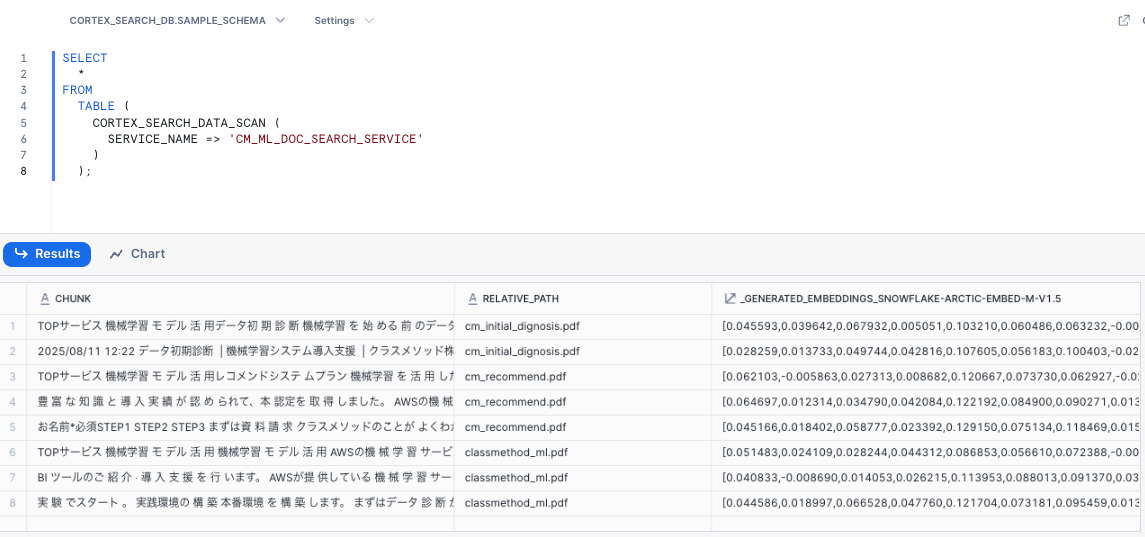
SQLの場合、SNOWFLAKE.CORTEX.SEARCH_PREVIEWクエリできるほか、CORTEX_SEARCH_DATA_SCANでサービスの中身を確認することができます。
▼ SNOWFLAKE.CORTEX.SEARCH_PREVIEWの例
▼ CORTEX_SEARCH_DATA_SCANの例
これらの検索方法については以下のドキュメントに記載があります。
3. Streamlitアプリからの利用
Pythonから上記のような方法で、Cortex Searchサービスから質問内容に類似するドキュメントを取得することで、RAGによるカスタマイズをしたチャットアプリを作成できます。
例えば以下のような例です。先にリンクを貼ったサイトの内容をしっかり回答してくれています。
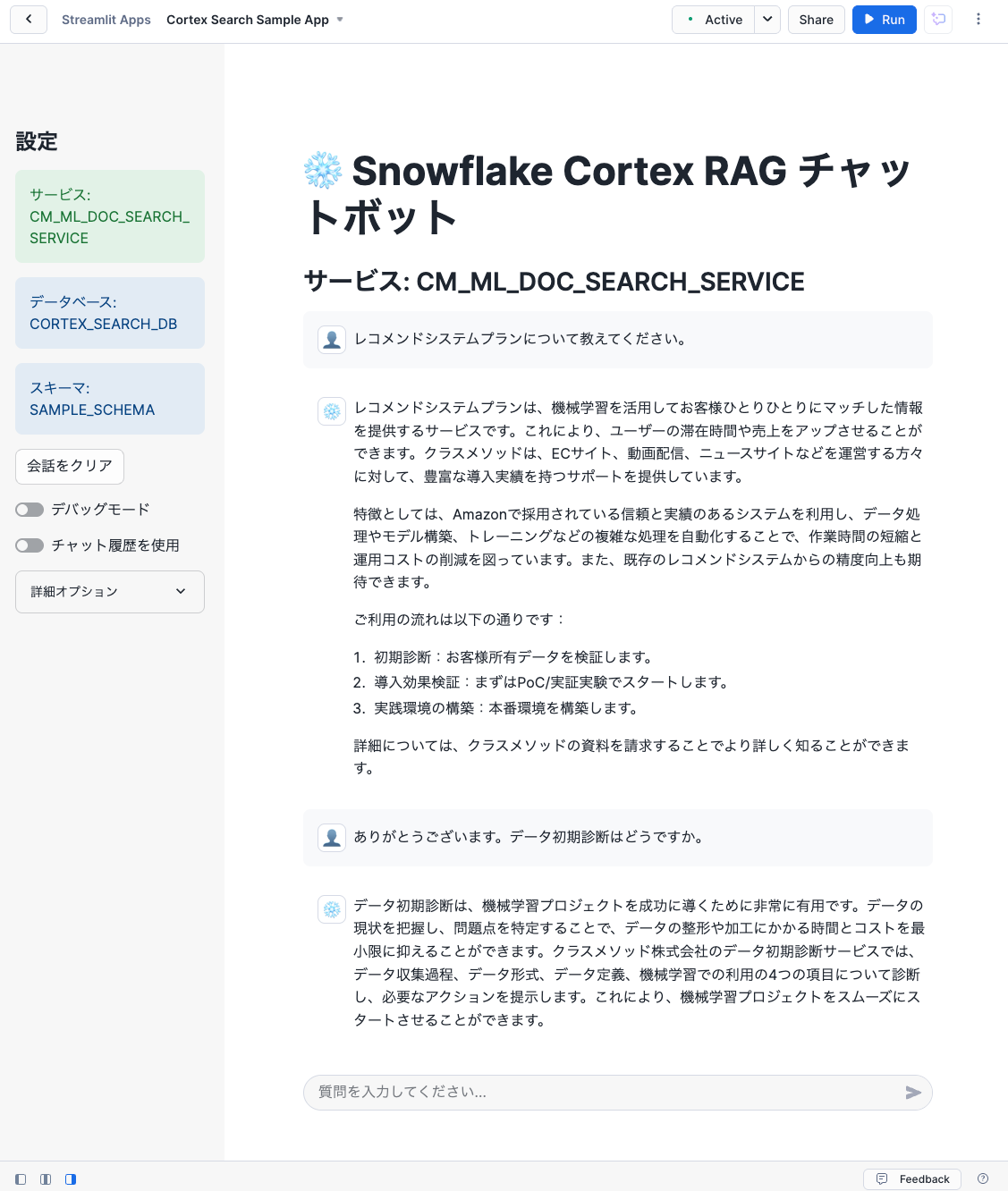
プロンプトは以下のようにしています。
[INST]
あなたはRAG機能を持つ有用なAIチャットアシスタントです。ユーザーが質問をすると、
<context>と</context>タグの間に提供されるコンテキストも与えられます。そのコンテキストを
<chat_history>と</chat_history>タグの間に提供されるユーザーのチャット履歴と組み合わせて使用し、
ユーザーの質問に対応する要約を提供してください。回答は一貫性があり、簡潔で、
ユーザーの質問に直接関連するものにしてください。
与えられたコンテキストやチャット履歴で答えられない一般的な質問をユーザーが尋ねた場合は、
「その質問に対する答えがわかりません。」と答えてください。
「提供されたコンテキストによると」のような表現は使わないでください。
<chat_history>
{chat_history}
</chat_history>
<context>
{prompt_context}
</context>
<question>
{user_question}
</question>
[/INST]
回答:
このプロンプトをCOMPLETEに与えて回答を生成し、Streamlitアプリに表示するという流れになります。
なお、プロンプトは冒頭に掲載した『[新機能]Snowflakeでテキストデータに対するRAGを簡単に実装できる「Cortex Search」を用いてRAGチャットボットを構築してみた』で紹介されている実装と同じです。
ほかの機能との連携
Cortex SearchサービスはStreamlitアプリなどから直接利用することもできますが、ほかのネイティブな機能から利用することもあります。
1. Cortex Agentsからの利用
SnowflakeのネイティブなAIエージェント機能であるCortex AgentsのツールとしてCortex Searchを利用することができます。
Cortex Agentsは記事執筆時点でパブリックプレビュー中ですが、現時点で公開されているツールの中、非構造化データを利用するためのものとして位置付けられています。
以下のブログで紹介されている例でもCortex AgentsからCortex Search Serviceを利用しています。
2. Cortex Analystからの利用
Cortex Analystから利用することもあります。
Cortex Analystは自然言語からSQLを生成する機能ですが、生成するSQLのWHERE句で指定される具体的な値を決めるためにCortex Searchを使用できます。
Text-to-SQLの仕組みを自作してみるとピンとくるのですが、例えばチャットAIを利用するユーザーが入力テキストに含んでいる単語と、Cortex Analystが生成するSQLで分析するテーブルのレコードの値が必ずしも一致するわけではなく、WHERE句でフィルタする際に入れる値をどう生成するかは頭を悩ませるポイントです。
例:「淀屋橋駅の2025/8で晴れの日は何日でしたか」を計算するSQLの集計対象になっているテーブルで、実際のレコードの地名は「淀屋橋駅」ではなく「YODOYABASHI」になっている、など
Cortex AnalystではSQLを生成する際に参考にするセマンティックモデルというファイルのsample_valuesにこの値を持たせることができますが、全国の地名など途方も無い数のある値を全て書いておけません。そのような場合にCortex Searchから取得できるようになっています。
そのたのポイント
1. Cortex Searchサービスのリフレッシュ
Cortex Searchサービスのデータは特定時点のクエリ結果のため、元データの更新時にはその差分を反映する必要があります。
更新は自動で行われ、その頻度はTarget lagで指定したラグよりも小さくなるように決定されます。Target lagは、例えばSQLだとサービス作成時にTARGET_LAGで指定していました。
Cortex Searchサービスのリフレッシュ状況はSnowsightから確認できます。
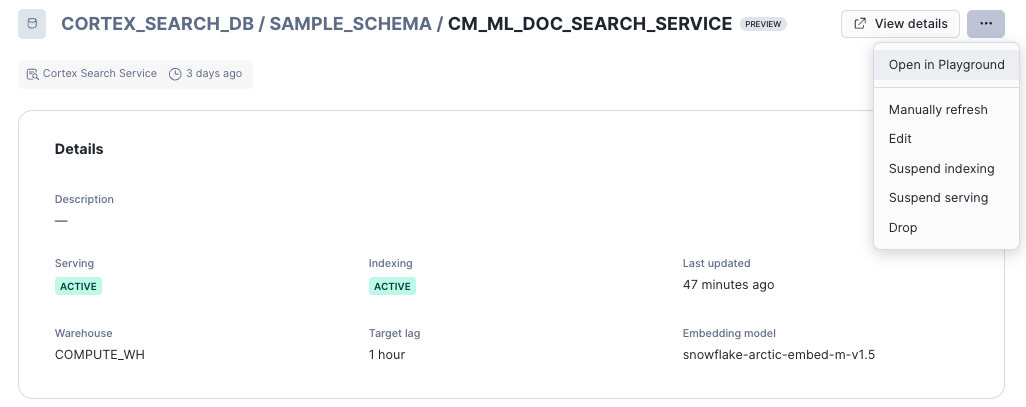
リフレッシュは同画面から手動で行うことも可能です。もちろんSQLでもできます。
例えば検証のためにCortex Searchサービスの参照する元データを更新した場合は、これらの方法でリフレッシュしないと更新したデータは反映されません。
2. Streamlitアプリを生成AIで作る
最近は生成AIによるコーディングツールが盛んに使われていますが、「Cortex Searchの仕組みはなんとなくわかったけどStreamlitアプリを作るのは初めてなんだよね」という方はコーディングツールに頼ってもよいかもしれません。
先に紹介したアプリ例もコーディングツールを使って作成してみています。今回はCursorを使いました。
以下のように参考にさせたいStreamlitアプリのコードと関連するCortex SearchのドキュメントのURLを渡して作成してもらっています。
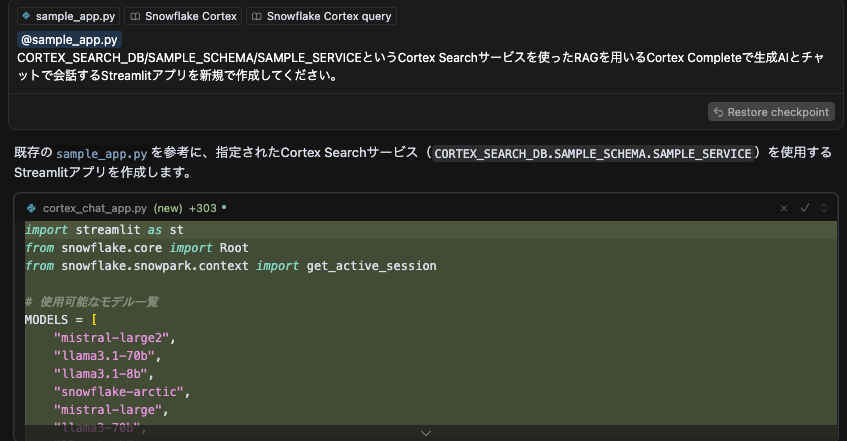
参考にさせたいStreamlitアプリのコードがない場合、割と自由にアプリが生成されてしまい、内容確認が大変になってしまうため、与えるとやりやすいです。また作成されたコードの内容はしっかり確認することをおすすめします。
3. ほかのアカウントへの共有
直近でCortex Knowledge Extensions(CKE)が一般提供開始されています。この機能を使うことで、自身のCortex Searchサービスを共有できます。
多くの場合は社内共有になると思いますので、プライベートリストもしくは組織リストでの共有になります。
以下のチュートリアルでプライベートリストによる公開の例が紹介されています。
4. REST APIからの利用
Cortex SearchはREST APIでの利用も可能です。Snowflakeアカウントにログインできればどこからでも利用可能です。
REST APIでの利用については、Cortex Analystの例ですが、同様のブログを書いていますので参考にしてください。
5. 料金
以下のドキュメントにコストの記載があります。
低レイテンシの検索クエリ実行のため、マルチテナントのサービングコンピューターを使用するほか、検索列の埋め込みベクトル作成のためのトークンベースのクレジット消費、サービス更新・リフレッシュ時のウェアハウス・クラウドサービス料金、ストレージ料金がかかります。
いろいろと課金要素がありますが、ものすごく大量のドキュメントを検索するような場合は別なものの、安価に始められるサービスと思います。
また、Cortex Searchサービスが参照するテーブルはCHANGE_TRACKINGが有効になるため課金が発生します。ただし以下にあるように現状の挙動としてはそれほど大きな影響はないと考えています。
6. 検索時のフィルタリング
今回紹介した例では使っていませんでしたが、検索時に検索列と異なるカラムでフィルタリングをすることができます。
フィルタリングのためにはサービス作成時にATTRIBUTESで対象列を指定する必要があります。
フィルタリングのマッチングには@eq・@contains・@gte・@lteの4つがあります。
最後に
Snowflake上で誰でも簡単にキーワードおよびベクトルのハイブリッドな検索システムを構築・利用できるCortex Searchについてご紹介しました。
いろいろと細かい機能や課金項目もご紹介しましたが、マネージドで誰でも非常に使いやすいサービスです。
まずはCortex Searchサービスを作ってCOMPLETEなど回答生成の機能と組み合わせて、どんなことができるか試してみて頂けると使いやすさが分かって頂けるかなと思います!







