
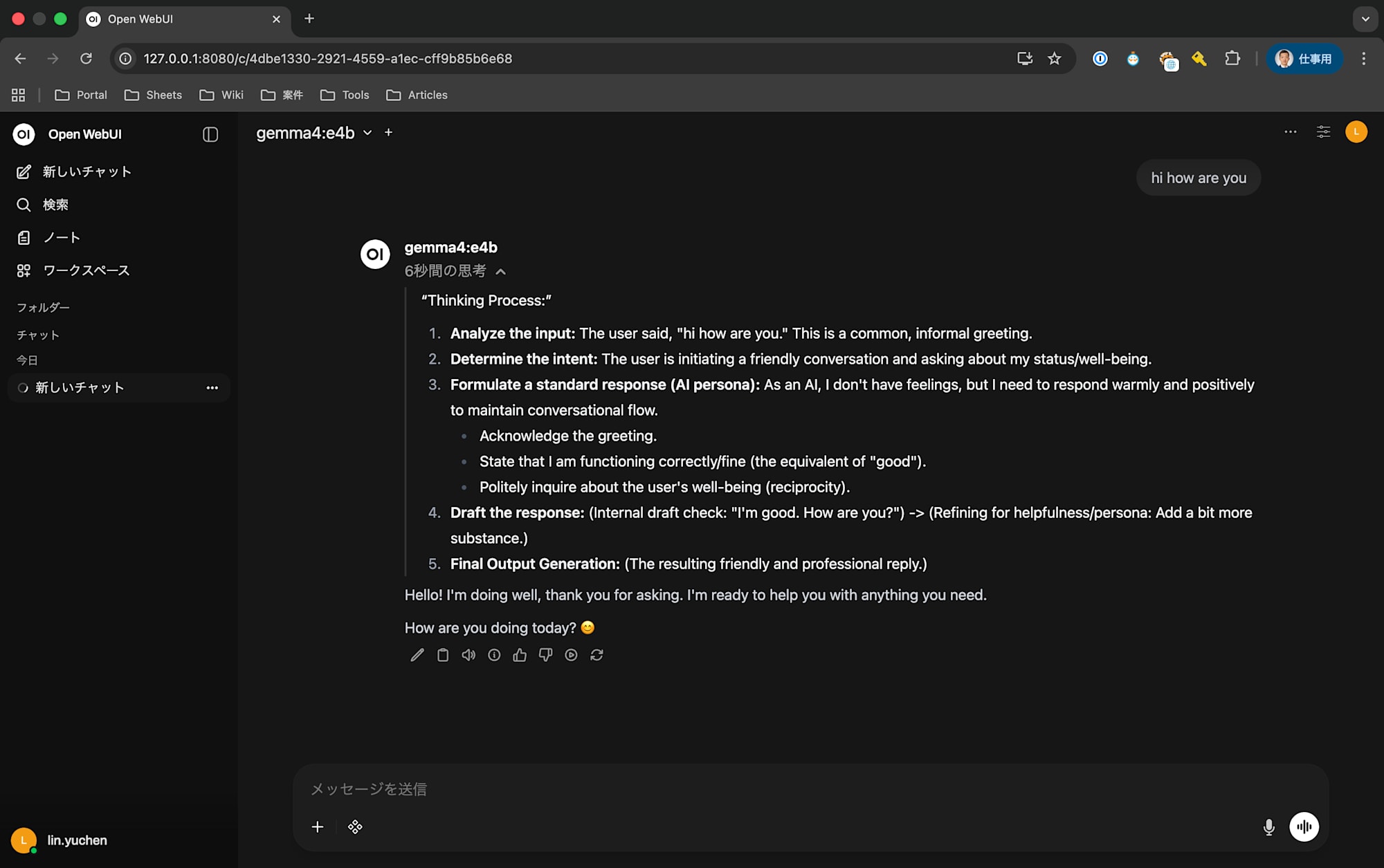
MacBook (16GB) でGemma 4をローカル実行してみた ─ Ollamaでモデル選定からUI構築、実プロジェクト活用まで
はじめに
Google が2026年にリリースした Gemma 4 は、ローカルで動かせるオープンウェイトLLMとして注目を集めています。APIコストゼロで自前のAIエンドポイントを持てるのは魅力的ですが、「自分のMacBookで動くのか?」が最初の壁です。
本記事では、16GB メモリの MacBook(Apple M5)で Gemma 4 をローカル実行するまでの過程を紹介します。最初に選んだモデルでは画面がフリーズする失敗も経験しつつ、最終的に実プロジェクトで活用できるところまでたどり着きました。
Gemma 4 ファミリーの全体像
Gemma 4 には4つのバリエーションがあります。
| モデル | パラメータ数 | アーキテクチャ | ディスク容量 (Q4) | 必要メモリ目安 | 特徴 |
|---|---|---|---|---|---|
| E2B | 2.3B | Dense | ~2 GB | ~3-4 GB | 超軽量、エッジデバイス向け |
| E4B | 4.5B | Dense | ~3 GB | ~5-6 GB | バランス型、ほとんどのMacで快適 |
| 26B (MoE) | 25.2B (Active: 3.8B) | Mixture of Experts | ~17 GB | ~18-19 GB | 高品質だがメモリ大量消費 |
| 31B | 31B | Dense | ~20 GB | ~20+ GB | 最高品質、32GB以上推奨 |
ここで重要なのは、ディスク容量と必要メモリは別物だという点です。ディスク容量はモデルファイルの保存に必要なストレージで、必要メモリはモデルを実際にロードして推論する際にGPU/CPUが使うメモリです。
Step 1: MacBookのスペックを確認する
まず、自分のマシンで使えるメモリを確認します。
sysctl hw.memsize
hw.memsize: 17179869184
16GB の MacBook です。Apple Silicon ではCPUとGPUが同じ統合メモリ(Unified Memory)を共有しています。「VRAM」という独立した領域はなく、物理メモリの一部をGPUが使います。
Ollama を起動すると、実際に使えるメモリ量が表示されます。
inference compute id=0 library=Metal name=Metal description="Apple M5"
total="11.8 GiB" available="11.8 GiB"
16GB のうち OS やシステムが使う分を除き、モデルに割り当てられるのは約11.8GB ということがわかりました。
Step 2: Ollamaのインストール
Ollama は、ローカルLLMの実行環境です。Homebrew でインストールできます。
brew install ollama
サーバーを起動します。
ollama serve
別のターミナルタブでモデルの pull や実行を行います。
Step 3: 26B MoE を試して失敗した話
スペック表だけ見ると、26B MoE は「Active パラメータが3.8Bだけだから軽いのでは?」と思えます。Mixture of Experts は推論時に全パラメータを使うわけではなく、トークンごとに一部のエキスパートだけが活性化する仕組みです。
しかし、モデルの全パラメータはメモリにロードされる必要があります。Active パラメータが少ないのは計算量の話であって、メモリ使用量は全パラメータ分かかります。
ollama pull gemma4:26b
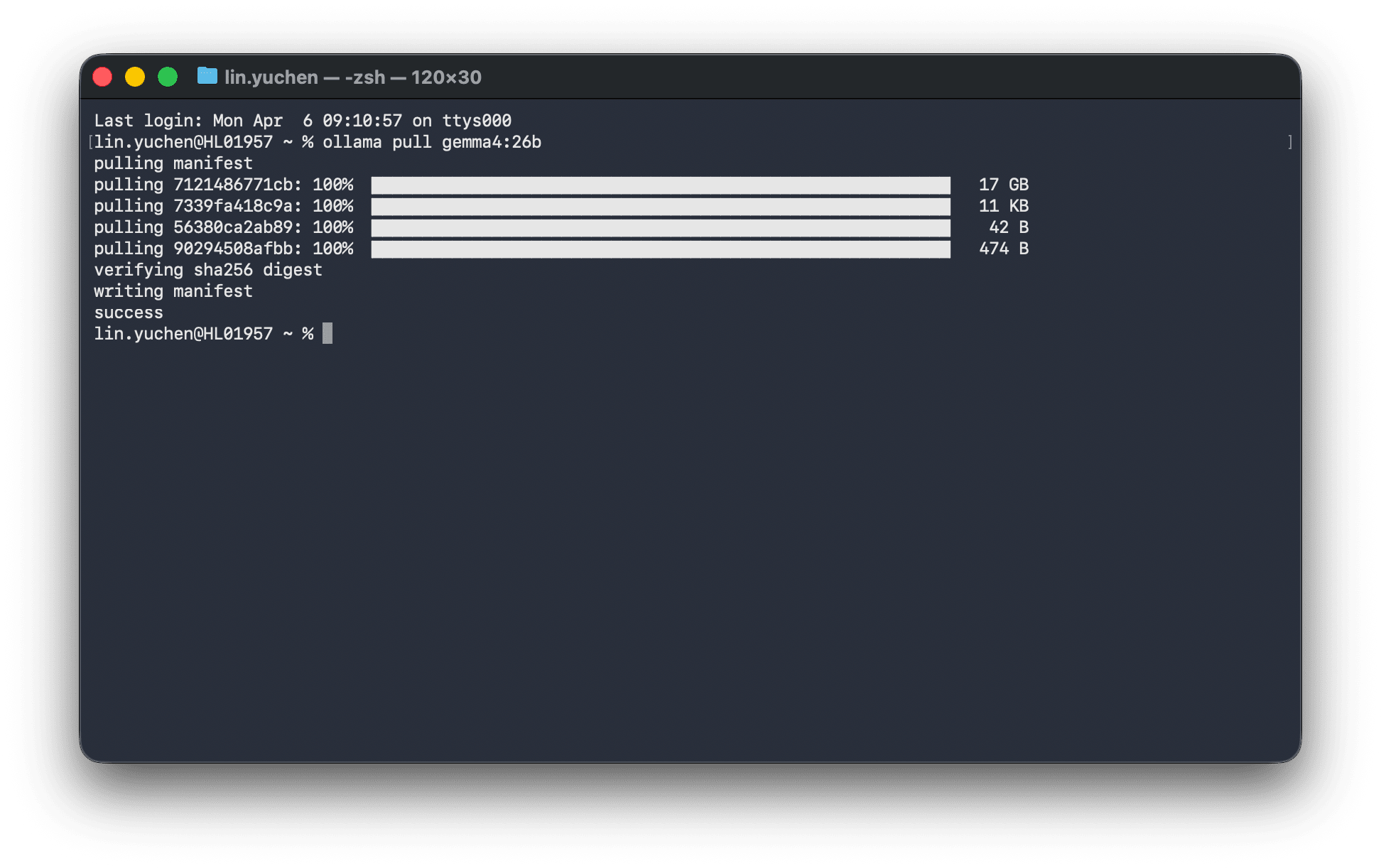
17GBのダウンロードが完了し、いざ実行すると...
model weights device=Metal size="10.0 GiB"
model weights device=CPU size="7.3 GiB" ← GPUに載りきらずCPUに溢れている
offloaded 20/31 layers to GPU ← 31層のうち20層しかGPUに載らない
total memory size="18.8 GiB" ← 必要メモリ18.8GB > 利用可能11.8GB
画面が完全にフリーズしました。13分間操作不能になった後、HTTP 500 エラーが返ってきました。
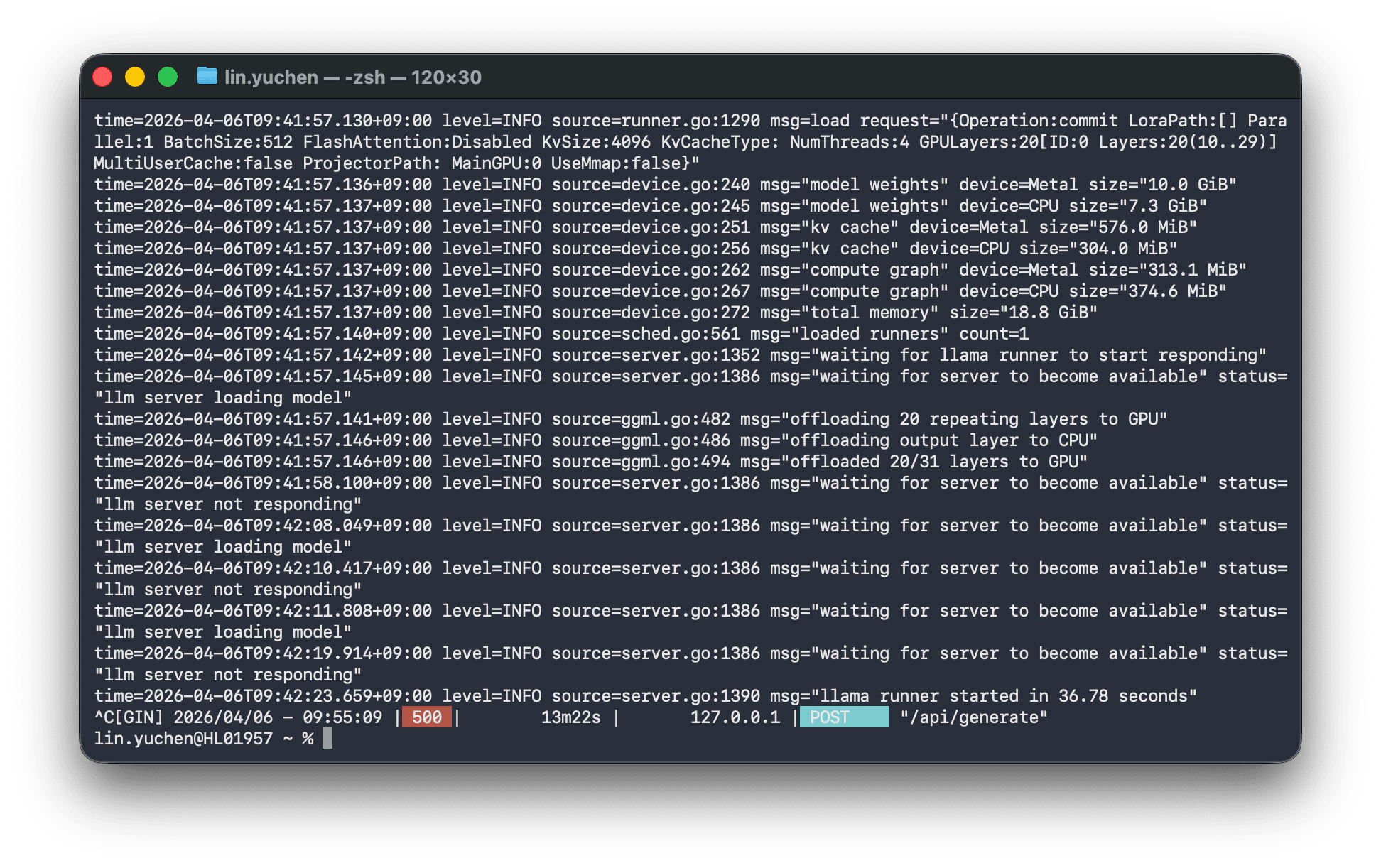
GPUメモリに載りきらない分がCPUメモリに溢れ(オフロード)、GPU↔CPU間のデータ転送がボトルネックになって、マシン全体が応答不能になったのです。
不要になったモデルはディスク容量を圧迫するので削除しておきます。
ollama rm gemma4:26b
Step 4: E4B で快適に動作
気を取り直して E4B に切り替えます。
ollama pull gemma4:e4b
ダウンロード後、テストしてみます。
curl -s http://localhost:11434/api/generate \
-d '{"model":"gemma4:e4b","prompt":"Say hello in one sentence.","stream":false}'
{
"model": "gemma4:e4b",
"response": "Hello!",
"total_duration": 12755806500,
"load_duration": 12189128000,
"eval_count": 3,
"eval_duration": 60049084
}
初回はモデルのロードに約12秒かかりますが、一度ロードされればメモリに保持されます。2回目以降の応答速度を見てみましょう。
# チャット形式でテスト
curl -s http://localhost:11434/api/chat \
-d '{
"model": "gemma4:e4b",
"messages": [{"role": "user", "content": "日本の首都は?"}],
"stream": false
}'
| テスト | 応答時間 |
|---|---|
| 短い質問(「日本の首都は?」) | 0.5秒 |
| 創作(俳句を書いて) | 0.9秒 |
| 長い回答(APIの説明を2-3文で) | 13.5秒 |
画面のフリーズもなく、快適に動作しました。 E4B は約5-6GBのメモリで収まるため、11.8GBの制約内で余裕があります。
Step 5: Open WebUI でチャットUIを構築する
Ollama 自体はAPIサーバーなので、ブラウザで使えるチャットUIを別途用意します。Open WebUI が最も人気のある選択肢です。
Docker 実行環境の準備
macOS で Docker を使うにはいくつかの選択肢があります。
| ツール | 料金 | 特徴 |
|---|---|---|
| Docker Desktop | 個人利用は無料、商用(250人以上 or 売上$10M以上)は有料 | 公式GUI |
| OrbStack | 個人利用は無料、商用(売上$10K以上)は$8/月 | 軽量・高速、Apple Silicon最適化 |
| Colima | 完全無料(MIT License) | CLI ベース、商用利用もライセンス問題なし |
| Podman Desktop | 完全無料(Apache 2.0) | Red Hat が開発、GUI あり |
Docker Desktop と OrbStack はどちらも商用利用時にライセンス料が発生します。業務で使う場合は注意が必要です。今回はライセンスを気にせず使える Colima を選びました。
brew install colima docker
colima start
colima start で Docker Engine が使える Linux VM が起動します。以降は通常の docker コマンドがそのまま使えます。
Open WebUI の起動
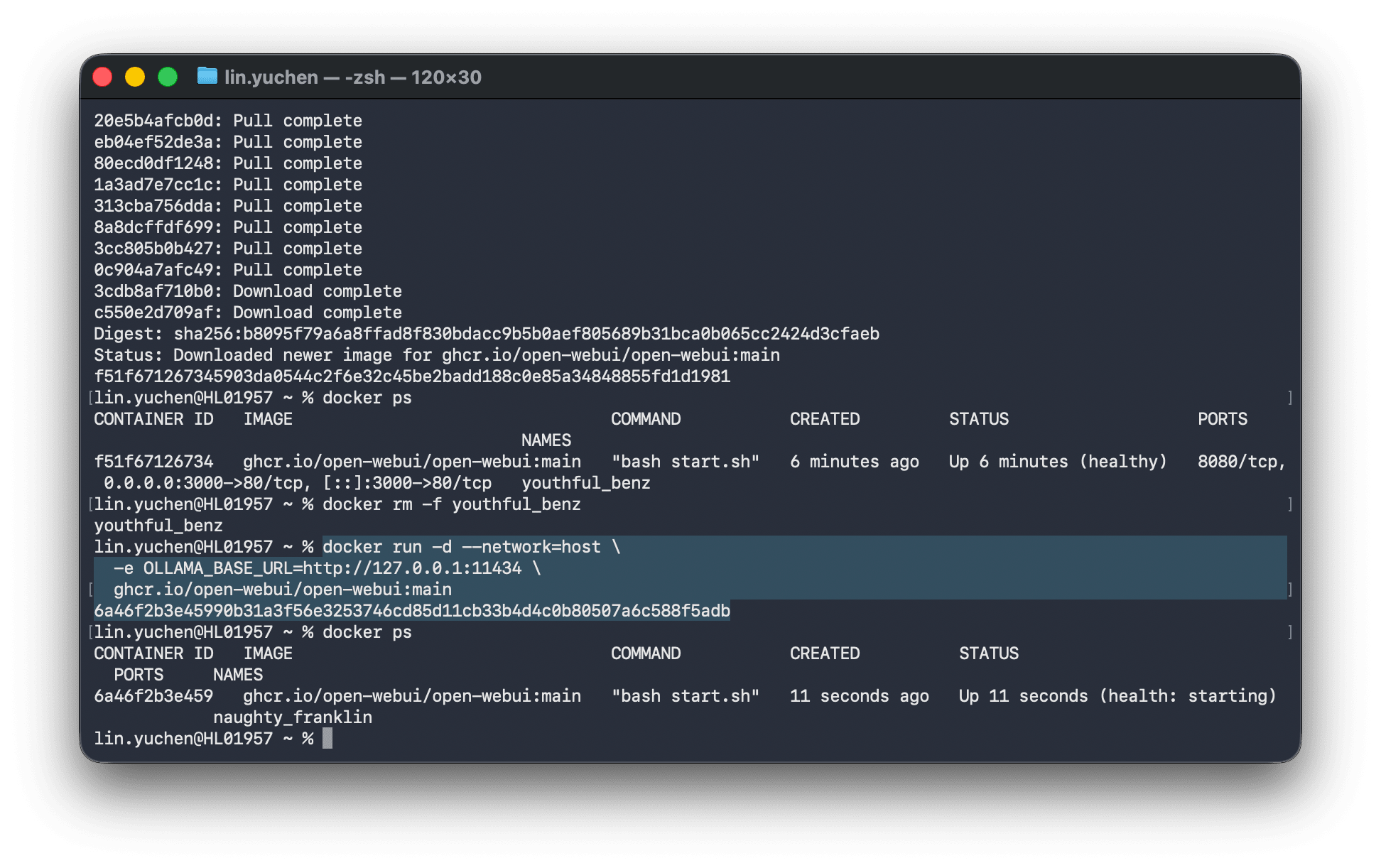
docker run -d --network=host \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
ghcr.io/open-webui/open-webui:main
--network=host を使うことで、コンテナがホストマシンのネットワークを直接共有し、Ollama に確実に接続できます。この場合、Open WebUI のポートは 8080 になります。
http://localhost:8080 をブラウザで開くと、ChatGPT風のインターフェースが表示されます。初回アクセス時にアカウントを作成します。
Ollama 接続の設定
初回起動時、モデル選択で「No models available」と表示される場合があります。これは Open WebUI が Ollama のエンドポイントを見つけられていない状態です。
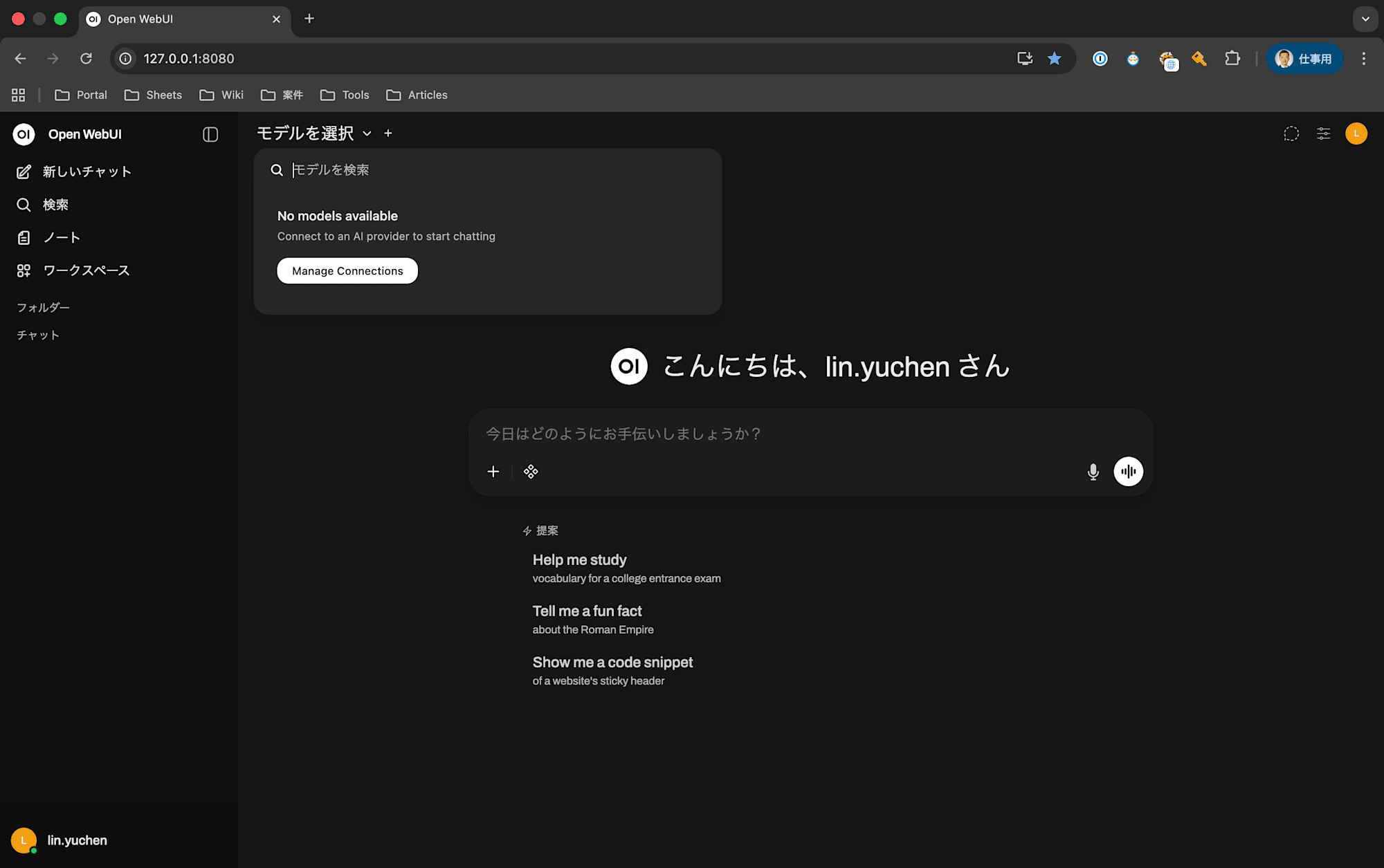
- 画面上部の「Manage Connections」をクリック
- Ollama API の URL を以下に設定:
http://host.docker.internal:11434 - 接続が確認できると、
gemma4:e4bがモデル一覧に表示される
接続が完了すれば、ChatGPT風のインターフェースで Gemma 4 と対話できるようになります。
Step 6: 実プロジェクトでの活用例 ─ Text-to-SQL エージェント
ローカルLLMの真価は、実際のプロジェクトで使ってこそわかります。ここでは、日本語の自然言語から SQL を生成する Text-to-SQL エージェントでの活用例を紹介します。
プロジェクト概要
日本語の財務データ(エリア別P&L、商品カテゴリ別売上)に対して、自然言語で質問すると SQL を生成・実行して結果を返す仕組みです。
ユーザー: 「関東の2025年の累計売上は?」
↓
Gemma 4 (E4B) が SQL を生成
↓
SELECT SUM(売上_実績) FROM area_pl WHERE エリア = '関東' AND 年度 = 2025
↓
結果: 12,345 百万円
Ollama Python クライアントの統合
Python から Ollama を呼び出すのは非常にシンプルです。
pip install ollama
import ollama
MODEL = "gemma4:e4b"
response = ollama.chat(
model=MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "関東の売上は?"},
],
)
sql = response.message.content.strip()
ollama ライブラリはデフォルトで localhost:11434 に接続するため、環境変数やURLの設定は不要です。
スキーマ情報をプロンプトに含める
LLM に正確な SQL を生成させるため、テーブル定義やカラム名をシステムプロンプトに動的に組み込んでいます。
from functools import lru_cache
@lru_cache
def build_system_prompt():
return f"""あなたはSQLエキスパートです。
以下のテーブル定義に基づき、ユーザーの質問に対してDuckDB互換のSELECT文のみを生成してください。
{schema_definitions}
ルール:
- SELECT文のみ生成すること(INSERT, UPDATE, DELETE は禁止)
- テーブル名・カラム名は日本語のまま使用すること
"""
ローカルLLMを選んだ理由
| 観点 | ローカル (Ollama) | クラウドAPI |
|---|---|---|
| コスト | 無料 | トークン課金 |
| レイテンシ | ネットワーク不要 | API往復あり |
| プライバシー | データが外部に出ない | 送信が必要 |
| 品質 | E4Bクラス | Claude/GPT-4クラス |
| セットアップ | Ollama起動のみ | APIキー管理が必要 |
PoCフェーズでは、コストゼロで高速にイテレーションできるローカルLLMが最適でした。本番環境ではクラウドAPI(Claude等)に切り替える設計にしているため、ollama.chat() を Anthropic SDK に差し替えるだけで移行できます。
まとめ
MacBook (16GB) で Gemma 4 をローカル実行する過程をまとめます。
- Apple Silicon の統合メモリは約70-75%がモデルに使える(16GBなら約11.8GB)
- MoE の Active パラメータ数 ≠ 必要メモリ量。26B MoE は18.8GB必要で16GBマシンでは動かなかった
- Gemma 4 E4B が16GBマシンのスイートスポット。5-6GBで収まり、応答も高速
- Ollama + Open WebUI で、コードを書かずにチャットUIまで構築できる
- 実プロジェクトでも
ollamaPython ライブラリ経由で簡単に統合可能
ローカルLLMは、PoCや開発初期のプロトタイピングに最適です。APIキーの管理もトークン課金も不要で、プライバシーを保ちながら素早くイテレーションできます。16GBのMacBookでも、適切なモデルを選べば十分に実用的な環境が構築できました。










