
S3のパスに"/"が連続するとAthenaでクエリができなかった話
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
タイトル通りですが、
S3のパスに"/"が連続するとAthenaでクエリした際、結果がレコード0件になります。
こちらのre:Postに書かれていました。
LOCATION パス内の二重スラッシュ
Athena は、二重スラッシュ (//) を含むテーブル LOCATION パスをサポートしていません。たとえば、次の LOCATION パスは空の結果を返します。s3://doc-example-bucket/myprefix//input//
"/"が2回続くというのは、S3で名無しのフォルダを作成した場合に発生します。
コンソール画面で名無しのフォルダを作成しようとすると、「フォルダ名は空欄にはできません。」と怒られます。
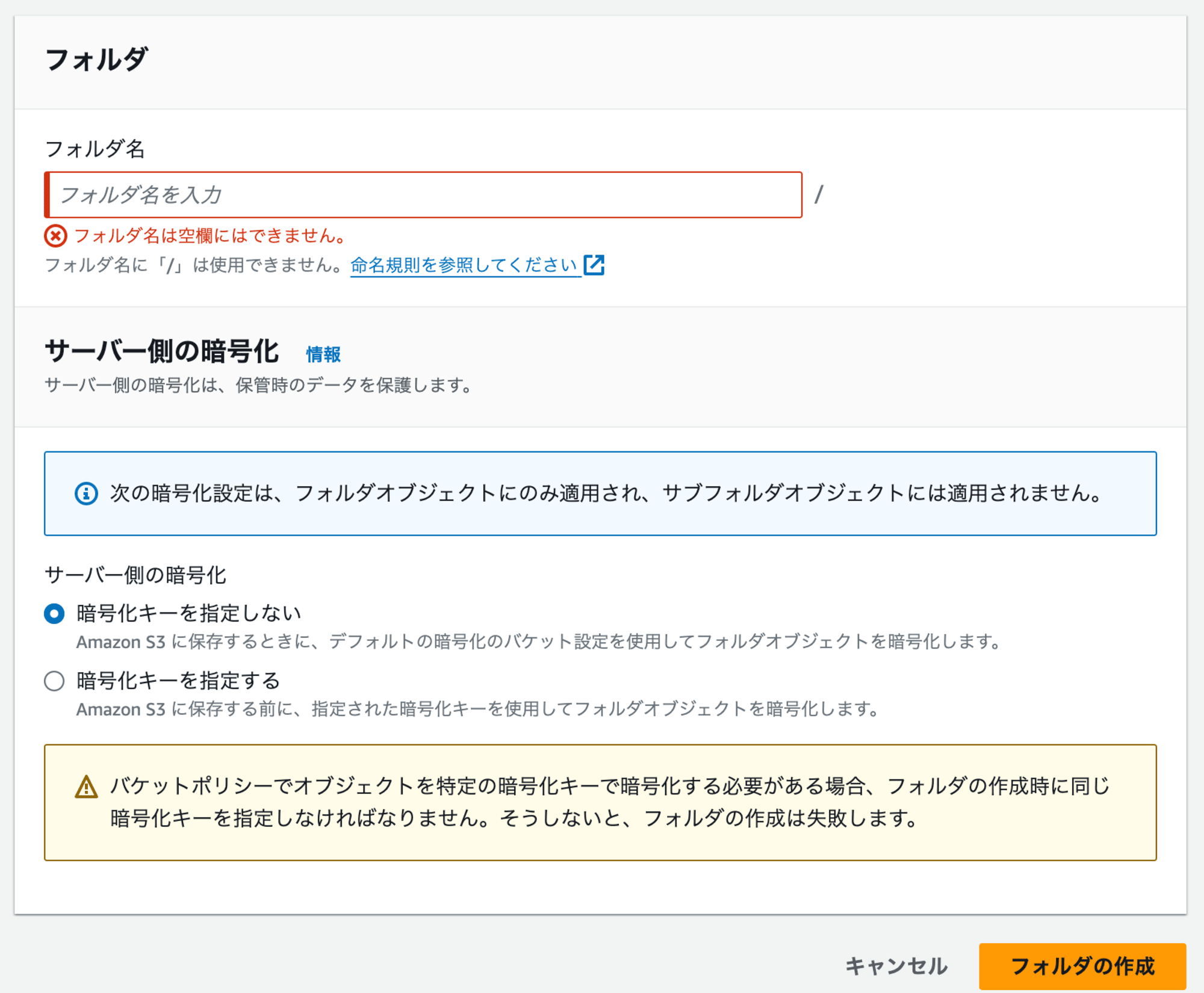
ただし、AWS CLIコマンドであれば名無しのフォルダを作成することができます。
$ aws s3api put-object --bucket <bucket-name> --key /
意図的に名無しのフォルダを作成することは無いとは思います。
しかし、稀にAWSサービスが自動的に作成するS3のパスに"/"が2つ続くことがあります。
私が遭遇したのはAWS CURでレポートを出力する際に作成されるS3に名無しのフォルダが含まれていました。
AWSのCURについては以下を参照してください。
このようなS3バケットに対してAthenaでクエリを行う場合は、一旦別のS3バケットにデータをコピーするなどして上記のトラブルを回避しましょう。
私はこれに気付かず、色々トラブルシューティングしたのでその内容を書き留めておきます。
上記の内容だけでお困りごとは解決すると思うので、私の確認した内容に興味のある方は続きを見ていってください。
事象
今回クエリを実施したバケットは以下のようなパスでした。
s3://cur-for-grafana/cur-for-grafana//grafana_export/data/BILLING_PERIOD=2024-07/sample.parquet
パスの中に"/"が続いてますね。
このバケットにクエリを行うため、以下のDDLでテーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS `cur-db`.`cur_table` (`bill_bill_type` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://cur-for-grafana/cur-for-grafana//grafana_export/data/BILLING_PERIOD=2024-07/'
TBLPROPERTIES ('classification' = 'parquet');
作成したテーブルにクエリを実行した際に以下のような結果になりました。
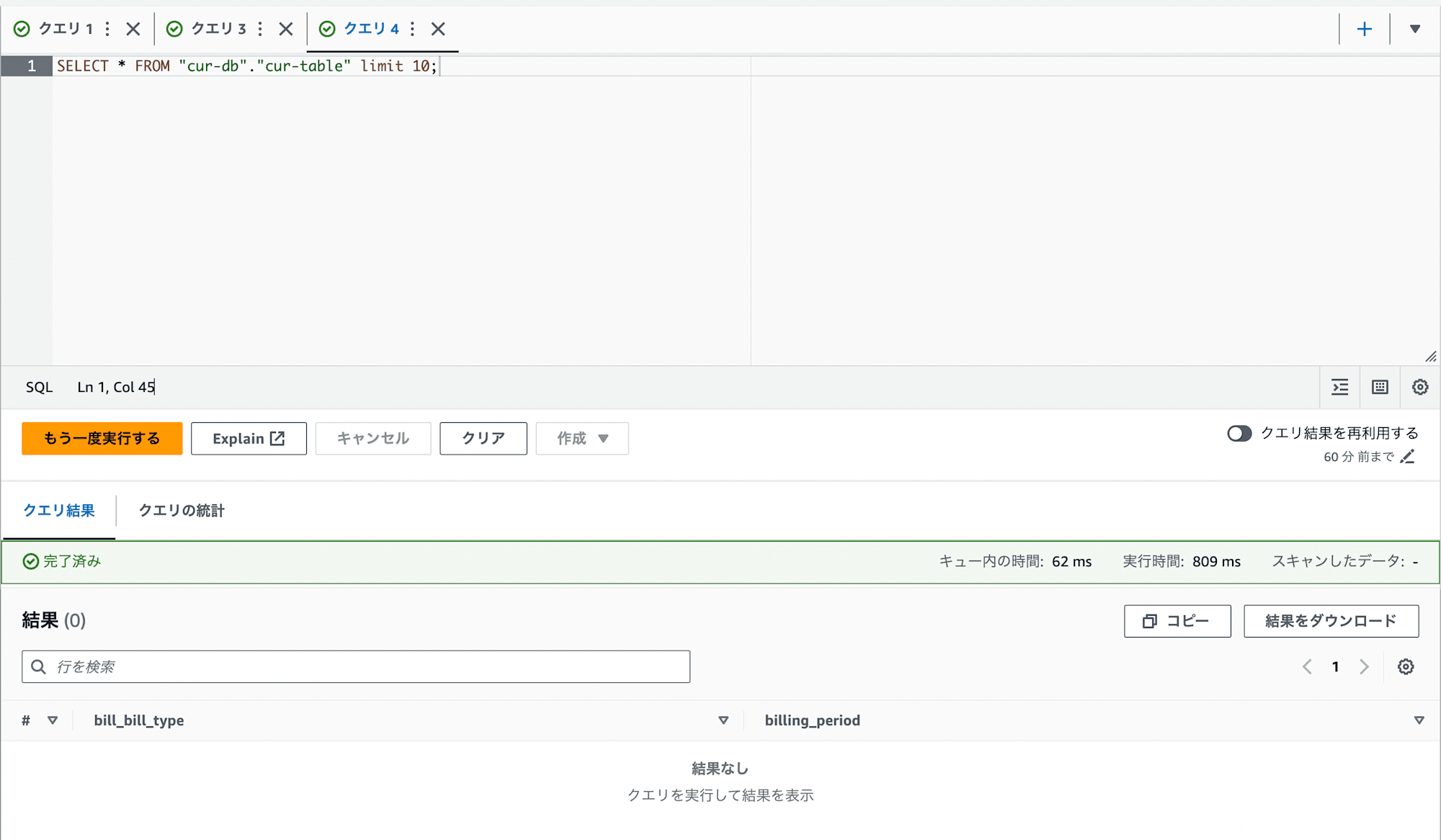
エラーは出ていないけど、結果が何も表示されない。という状態です。
ここで
- データが存在しない
- データの中身がない
- Athenaのテーブル作成時に設定をミスしている
というのを疑いました。
他にもあると思いますが、パッと思いついたのはこの3つです。
データの確認
まずは本当にデータが存在するかバケットを確認しましたが、データは存在しています。
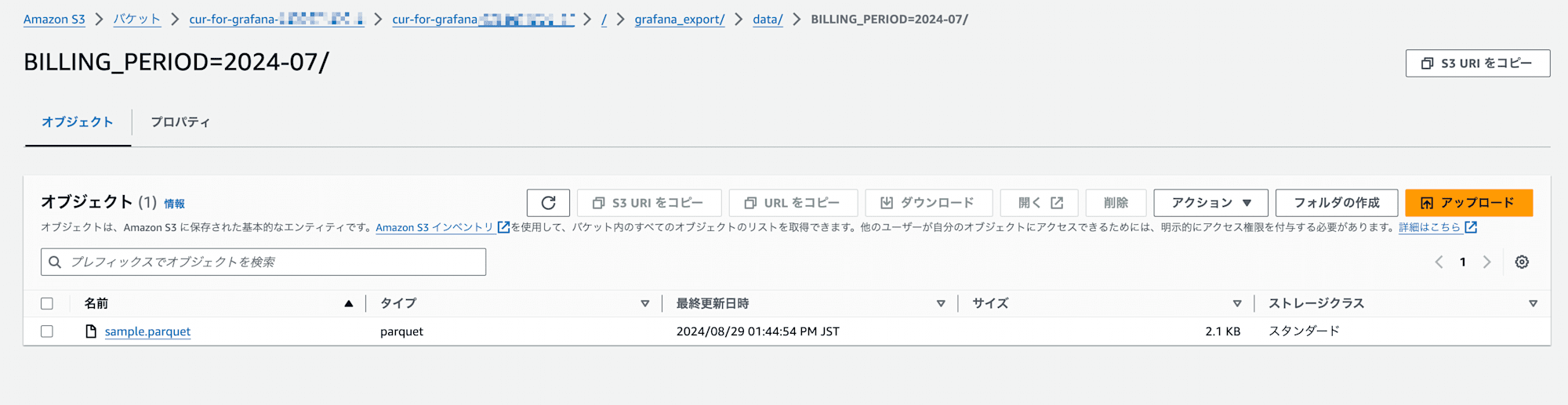
では次にデータの中身はどうでしょうか。
今回のデータはparquet形式だったのでpythonのpandasを使って中身を見てみます。
最初の5行だけ読み込むコードを書きます。
import pandas as pd
import sys
if len(sys.argv) < 2:
print("使用方法: python script.py <parquet_file_path>")
sys.exit(1)
parquet_file = sys.argv[1]
df = pd.read_parquet(parquet_file)
print("データフレームの最初の5行:")
print(df.head().to_string(index=False))
それではS3からデータを持ってきて中身を確認します。
$ python3 view.py sample.parquet
データフレームの最初の5行:
bill_bill_type
Standard
Standard
Basic
Basic
Enterprise
お、ちゃんとデータは入っていますね。
つまり、データの中身はあるけれどデータが表示されていない、または検索されていない。ということが分かりました。
別のバケットで試してみた
次に、新たにS3バケットを作成して、そこにデータをコピーしてクエリしてみます。
これでクエリ結果が出なければ、そもそもテーブル定義が間違えている可能性がありそうです。
まずは以下のS3バケットを用意しました。
s3://cur-query-athena-bucket/data/sample.parquet
次に以下のDDLでテーブルを作成します。
CREATE EXTERNAL TABLE `cur_table_2`(
`bill_bill_type` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://cur-query-athena-bucket/data/'
TBLPROPERTIES (
'classification'='parquet')
それではクエリします。
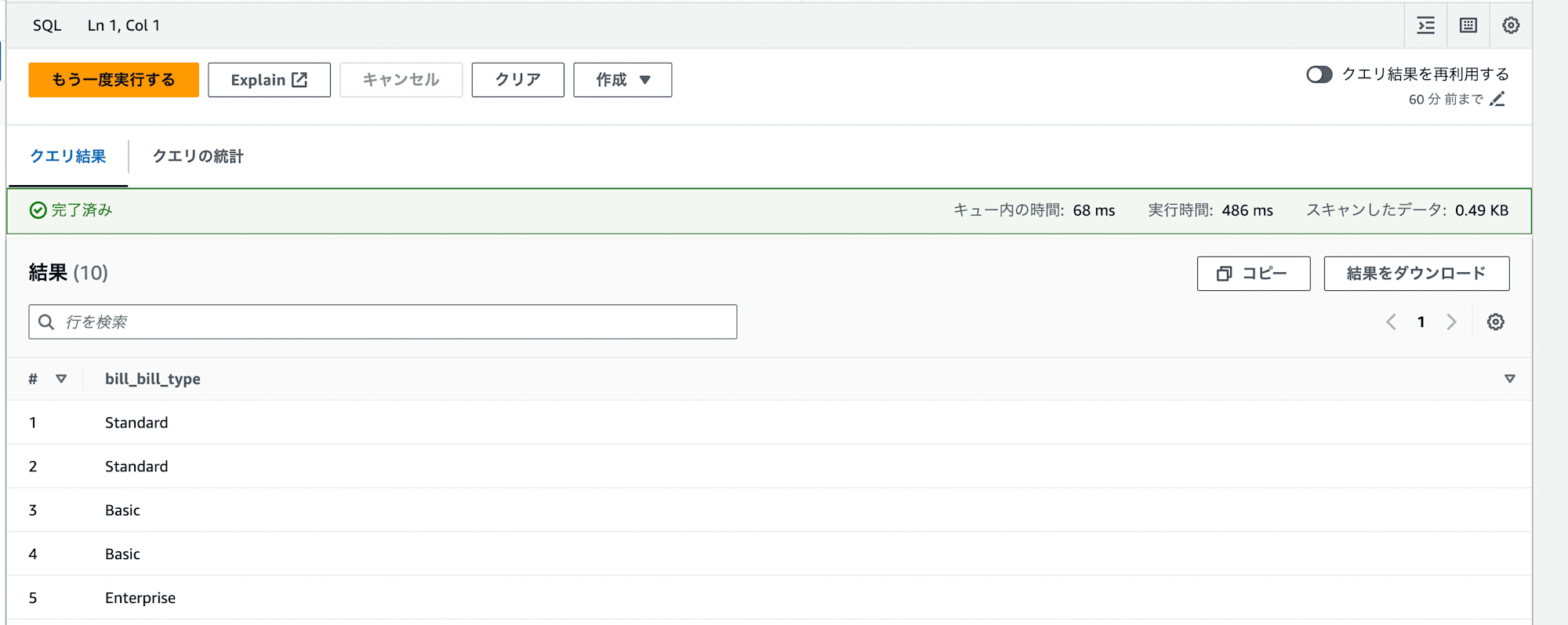
お、データが見えました!
つまり、テーブル作成時の設定は問題はなさそうですね。
ここで、詰まりました。
あれ?テーブル定義は間違っていない、かつデータの中身はあるのにデータが見えない?
しかもエラーも吐かないので原因の調査が難しい...ということで色々と調べていました。
そこで、冒頭でも紹介したこちらのre:Postでドンピシャの内容を発見しました。
これで無事?解決。めでたしめでたし。
ちなみに、対策としてはS3のデータが増える度に、S3イベント通知とLambdaを使って別のS3にデータコピーする方法を取ろうと思います。
こちらもうまくいけば、また記事を書きたいと思います。
まとめ
あまり遭遇することはないと思いますが、どなたかの助けとなれば幸いです。








