[新機能]ファイル名からテーブルを動的に作成できる S3 コネクタの Dynamic Table Mapping を試してみた #Fivetran
はじめに
2025年11月のアップデートで、S3 コネクタで使用できる Dynamic Table Mapping オプションが追加されました。
こちらを試してみた内容を本記事でまとめます。
アップデートの概要
本機能については以下に記載があります。
これまでファイルコネクタでは、マジックフォルダモードがサポートされていない限りは、各コネクションで単一のテーブルを宛先に作成することができました。
S3 コネクタについては、2025年4月のリリースで「複数の宛先テーブルへのファイル同期とファイルパターンの処理」がサポートされました。
これにより、ファイル名の命名規則に応じて単一のコネクションから宛先に複数のテーブルを作成・データを同期できるようになりました。
Fivetran の価格体系の変更に伴い、現在はコネクション毎に MAR の閾値が適用され金額が決まります。本機能により、単一のコネクションに MAR を集約できれば、MAR の単価を低くすることが期待できます。
こちらについては、以下の記事で検証しています。
今回リリースされた「Dynamic Table Mapping」オプションも同様の機能で、ファイル名やパス構成などの命名規則に応じて単一の S3 コネクションから宛先に複数のテーブルを作成・データを同期できます。
「複数の宛先テーブルへのファイル同期とファイルパターンの処理」では、宛先に作成するテーブルごとに、正規表現を使用し、ファイル名やパスのフィルタリングを設定します。
Dynamic Table Mapping では、事前に設定した正規表現パターンに含まれる名前付きキャプチャグループ(?<table>...)を利用して、ファイル名やファイルパスからテーブル名を動的に抽出・決定し、新しいファイルが配置された際にテーブルの作成と同期を自動的に行える点が特徴です。
試してみる
前提条件
以下の環境を使用しています。
- 宛先:Snowflake
S3 の構成
前提として、S3 には以下のようにファイルを配置しておきました。
$ aws s3 ls s3://<バケット名>/ --recursive
2025-10-17 09:45:24 0 customers/
2025-10-17 10:03:40 194 customers/customer-data.csv
2025-10-17 09:46:30 0 products/
2025-10-17 10:03:53 202 products/products_master.csv
2025-10-17 09:45:16 0 sales/
2025-10-17 10:04:10 240 sales/sales_transactions.csv
それぞれデータの種類やテーブルスキーマも異なるので、単一のテーブルには同期できません。そこで、各ファイルが配置されるパスに応じて、その名称で以下のような異なるテーブルとして宛先に同期したい設定です。
- customers テーブル
- products テーブル
- sales テーブル
Configure files の設定
アップデート後の S3 を使用するコネクション設定の Configure files オプションは下図のようになっています。「Define per table」は上述の「複数の宛先テーブルへのファイル同期とファイルパターンの処理」を使用する場合の設定となります。
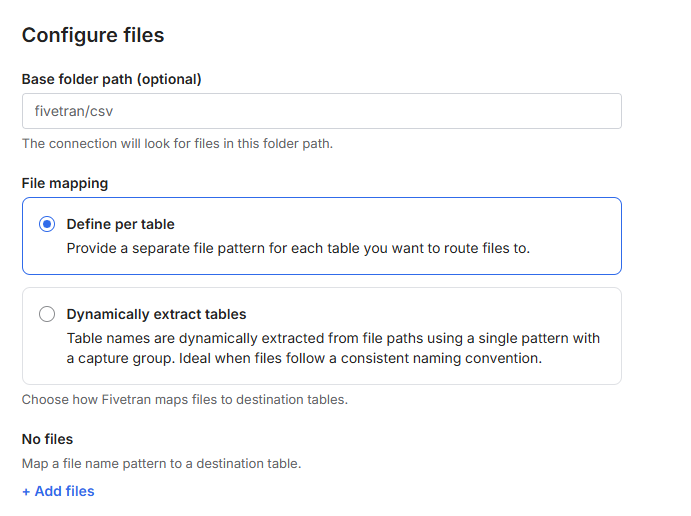
ここでは Dynamic Table Mapping オプションを試すので「Dynamically extract tables」を選択します。

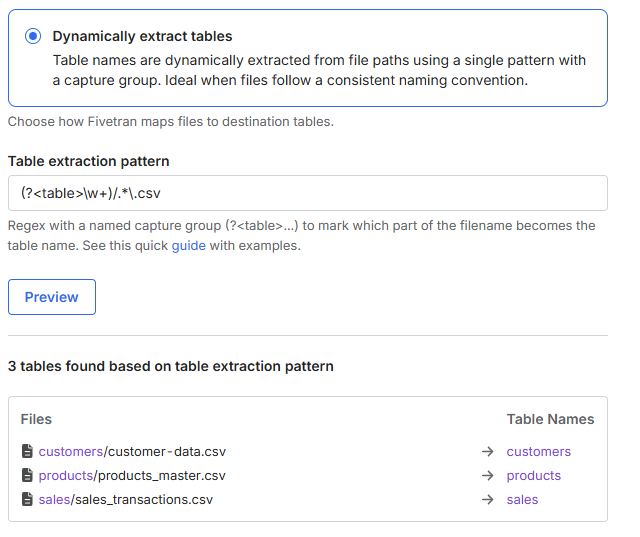
この場合「Table extraction pattern」として、S3 ファイルパスから宛先テーブル名として抽出したい文字列を定義するための正規表現を指定します。ここでは、以下の形式の名前付きキャプチャグループを含める必要があります。
(?<table>...)
この上で、以下の正規表現を指定しました。
(?<table>\w+)/.*\.csv
S3 のファイル構成(customers/customer-data.csv, products/products_master.csv, sales/sales_transactions.csv)から、最初のフォルダ名(例:customers,products,sales)をテーブル名として抽出する設定です。
設定した正規表現はテスト可能です。
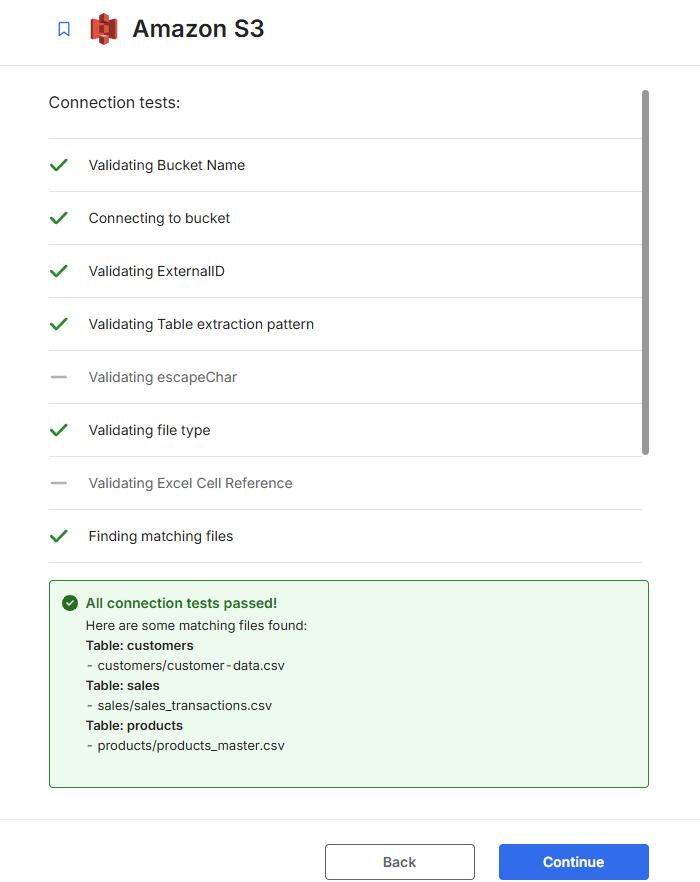
その他はデフォルトで接続テストを行います。
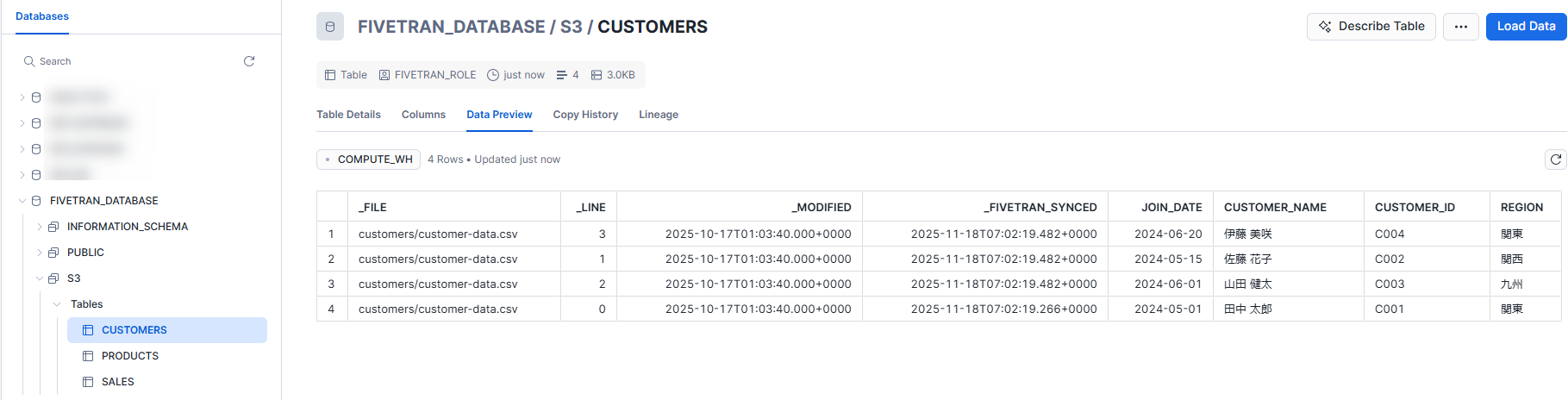
その後、初期同期を行い Snowflake 側で確認すると、指定の規則でテーブルが作成され、レコードが追加されていることを確認できました。
新しいテーブルを構成するファイルとパスを追加
Dynamically extract tables オプションの特徴として、新しいファイルがある場合、テーブルの作成と同期を自動的に行うことができます。
本機能を使用する条件として、コネクション設定のスキーマ変更に関する設定が下図のように、「Allow all new data」となっている必要があります。(デフォルト設定)

この状態であることを確認し、S3 側に以下のパスとファイルを追加しました。
s3://<bucket>/refunds/refunds.csv
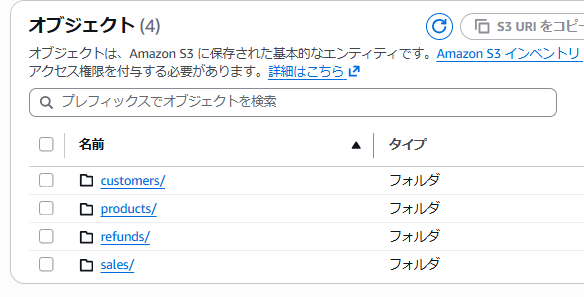
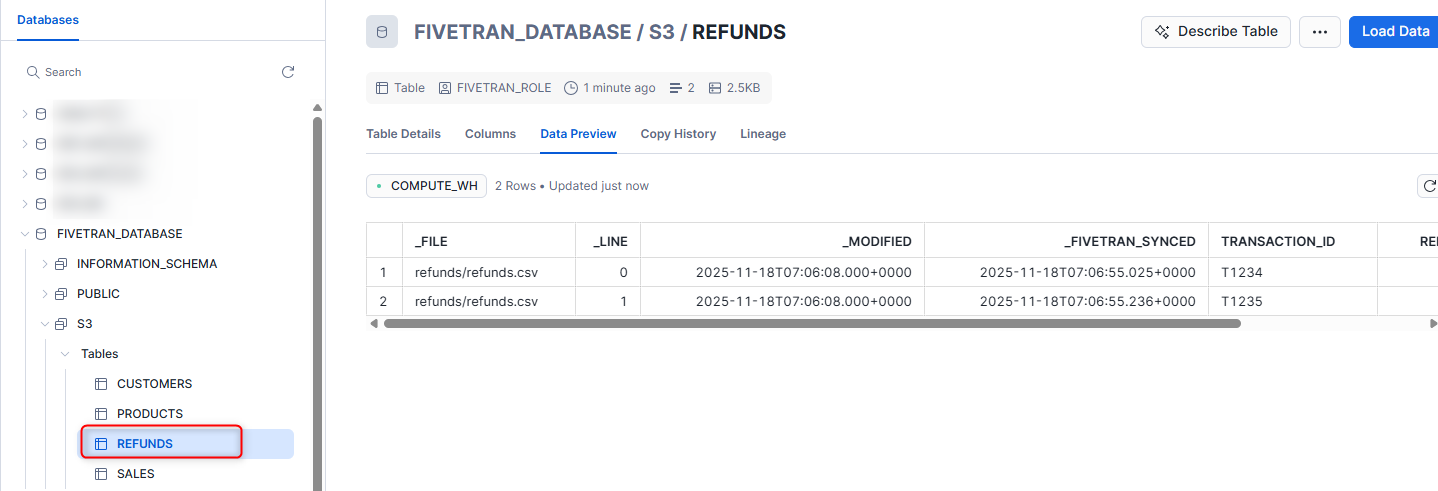
この上で再度同期を行います。すると、下図のように新たなテーブルが作成され、対応するレコードも追加されていました。
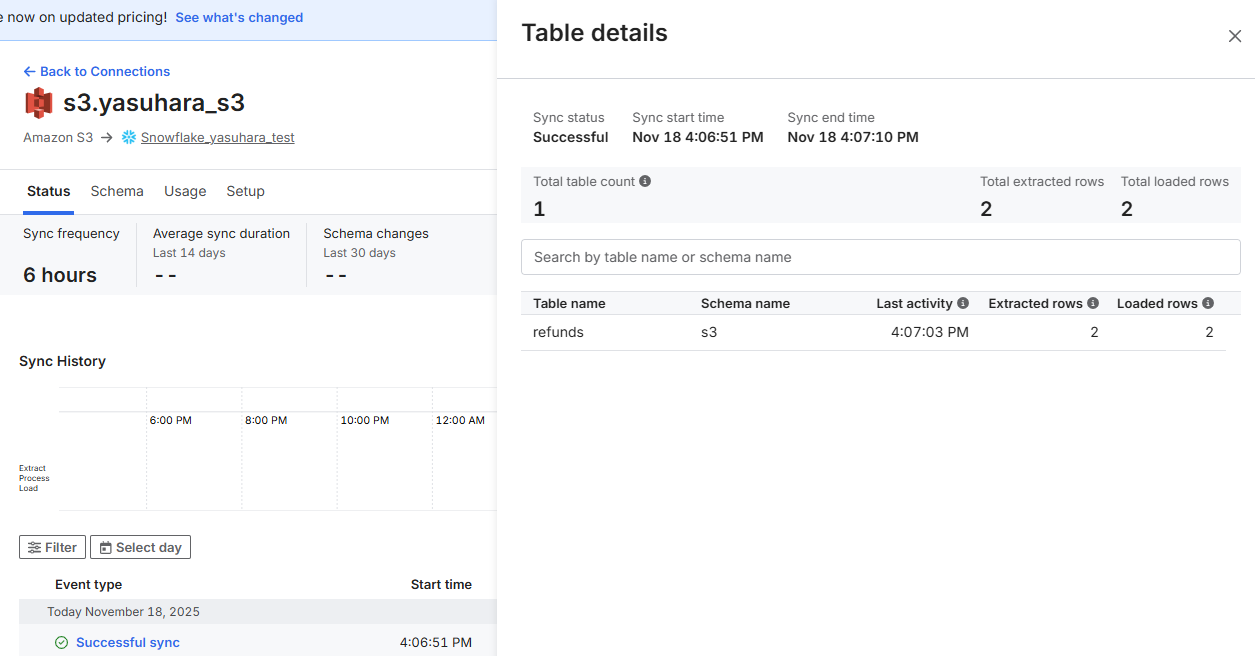
さいごに
S3 コネクタで使用できる Dynamic Table Mapping オプションが追加されました。新規データが継続的に追加されるケースで使える機能と思います。
本記事の内容が何かの参考になれば幸いです。









