
SnowflakeでS3に対するストレージ統合を設定して、COPY INTO、Snowpipeでデータをロードしてみた
かわばたです。
SnowflakeでS3に対するストレージ統合を設定して、COPY INTO、Snowpipeでデータをロードすることを試していきます。
今回行うこと
- ストレージ統合
- COPY INTOでデータロード
- Snowpipeでデータロード
検証環境
今回はSnowflakeトライアルアカウントのEnterprise版で試していきます。
検証のため、権限はACCOUNTADMINを利用しています。
ストレージ統合
Amazon S3にアクセスするためのSnowflakeストレージ統合を行っていきます。
ストレージ統合を使用して、Snowflakeが外部(つまり、S3)ステージで参照されるAmazon S3バケットに対してデータを読み書きできるようにする方法について説明します。統合は、名前付きのファーストクラスのSnowflakeオブジェクトであり、秘密キーまたはアクセストークンといった、クラウドプロバイダーの明示的な認証情報を渡す必要がありません。統合オブジェクトには、 AWS IDおよびアクセス管理(IAM)ユーザー IDが保存されます。> 組織の管理者が、 AWS アカウントの統合 IAM ユーザー権限を付与します。
上記公式ドキュメントからの引用となりますが、簡単に説明するとストレージ統合とは、AWSのアクセスキーを使わずに、SnowflakeとS3を安全に連携させる仕組みとなります。
実際に試していきましょう。
S3バケットのアクセス許可を構成する
Snowflakeでは、ファイルにアクセスできるようにするために、S3バケットおよびフォルダーに対する以下の権限が最低でも必要となります。
| 権限 | 内容 |
|---|---|
| s3:GetBucketLocation | Amazon S3 バケットが存在するリージョンを返すアクセス許可を付与します |
| s3:GetObject | Amazon S3 からオブジェクトを取得するためのアクセス許可を付与します |
| s3:GetObjectVersion | 特定のバージョンのオブジェクトを取得するためのアクセス許可を付与します |
| s3:ListBucket | Amazon S3 バケット内のオブジェクトの一部またはすべてを一覧表示するアクセス許可を付与します |
公式ドキュメント
上記権限を含めてIAM ポリシーの作成を行っていきます。
1.AWS管理コンソールからIAMを検索して開きます。
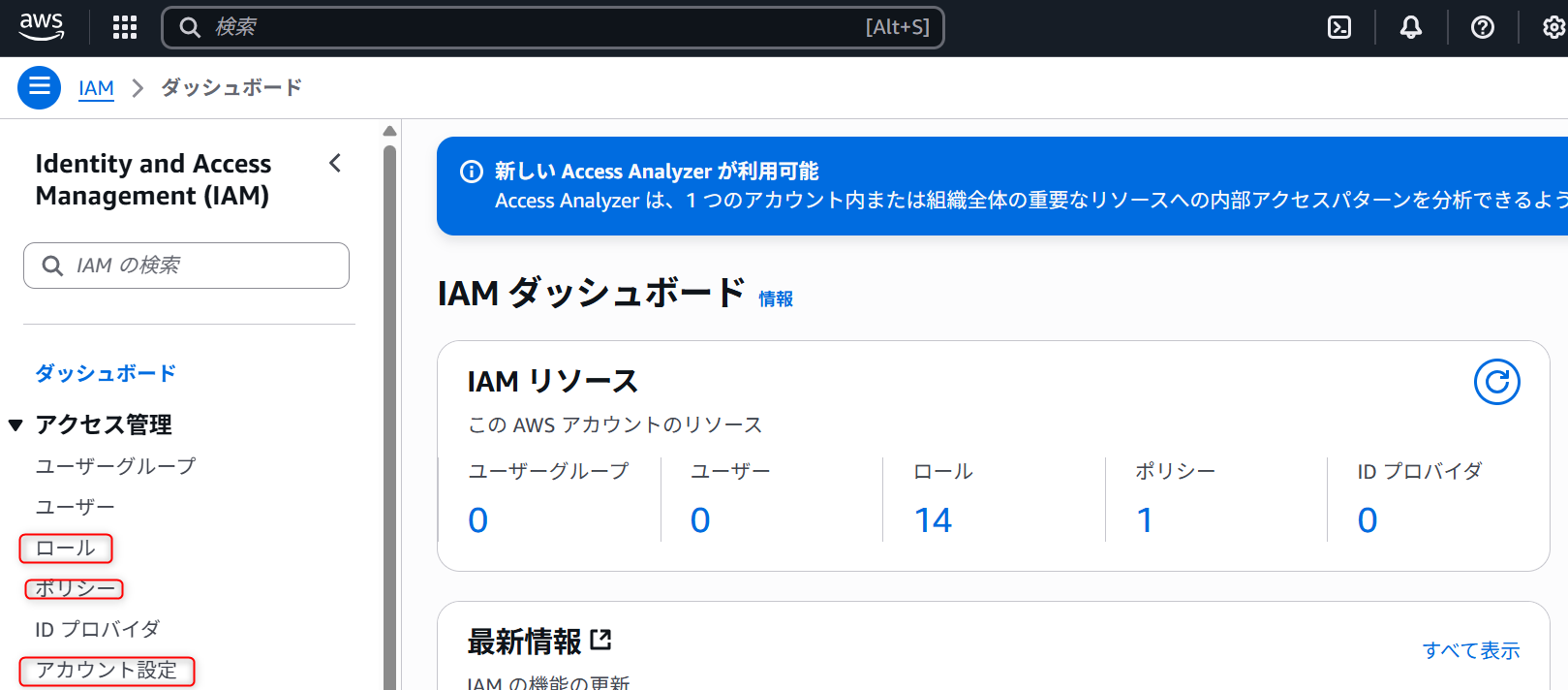
2. 上記画面が開くので、アカウント設定をクリックします。
エンドポイントリストのSTSステータスがアクティブか確認します。
この際、リージョンはSnowflakeのリージョンと同じである必要があります。

3. 1のポリシーをクリックします。その後、左上部にあるポリシーの作成をクリックします。
赤枠のJSONを選択し、ポリシーエディタに下記コードを記載します。
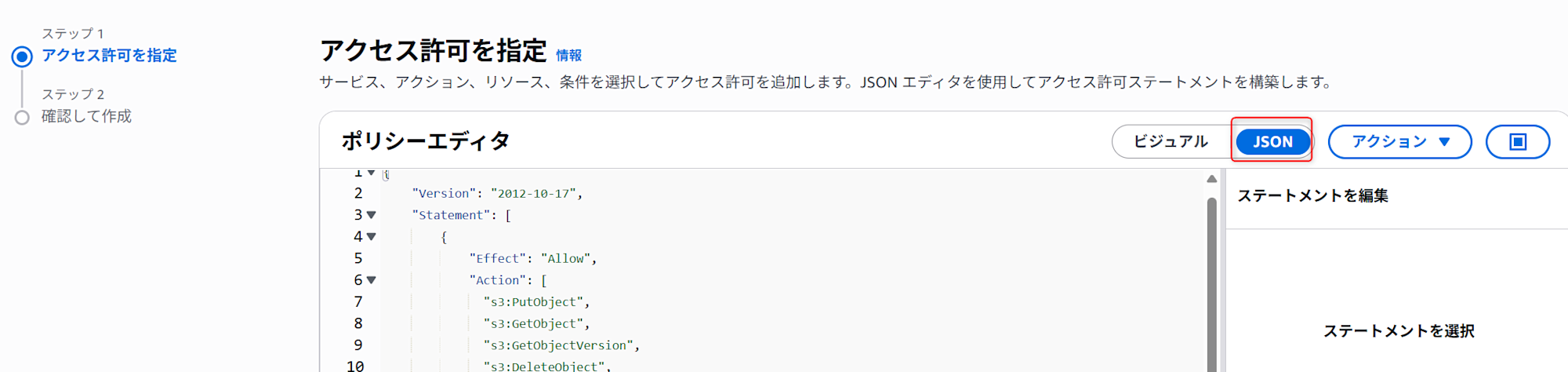
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::<bucket>/<prefix>/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::<bucket>",
"Condition": {
"StringLike": {
"s3:prefix": [
"<prefix>/*"
]
}
}
}
]
}
その際、<bucket>と<prefix>には実際のバケット名とフォルダーパスプレフィックスに置き換えてください。
※今回は検証用のため、上記の権限としていますが、必要に応じて編集することを推奨しています。
4. ポリシー名を記載して、ポリシーを作成してください。
IAM AWS ロールを作成する
S3バケットのアクセス許可を構成するの1と同様に、AWS管理コンソールからIAMを検索して開きロールをクリックします。- 左上部にある
ロールを作成をクリックします。 - 下記画面に遷移するので、
AWSアカウントを選択します。
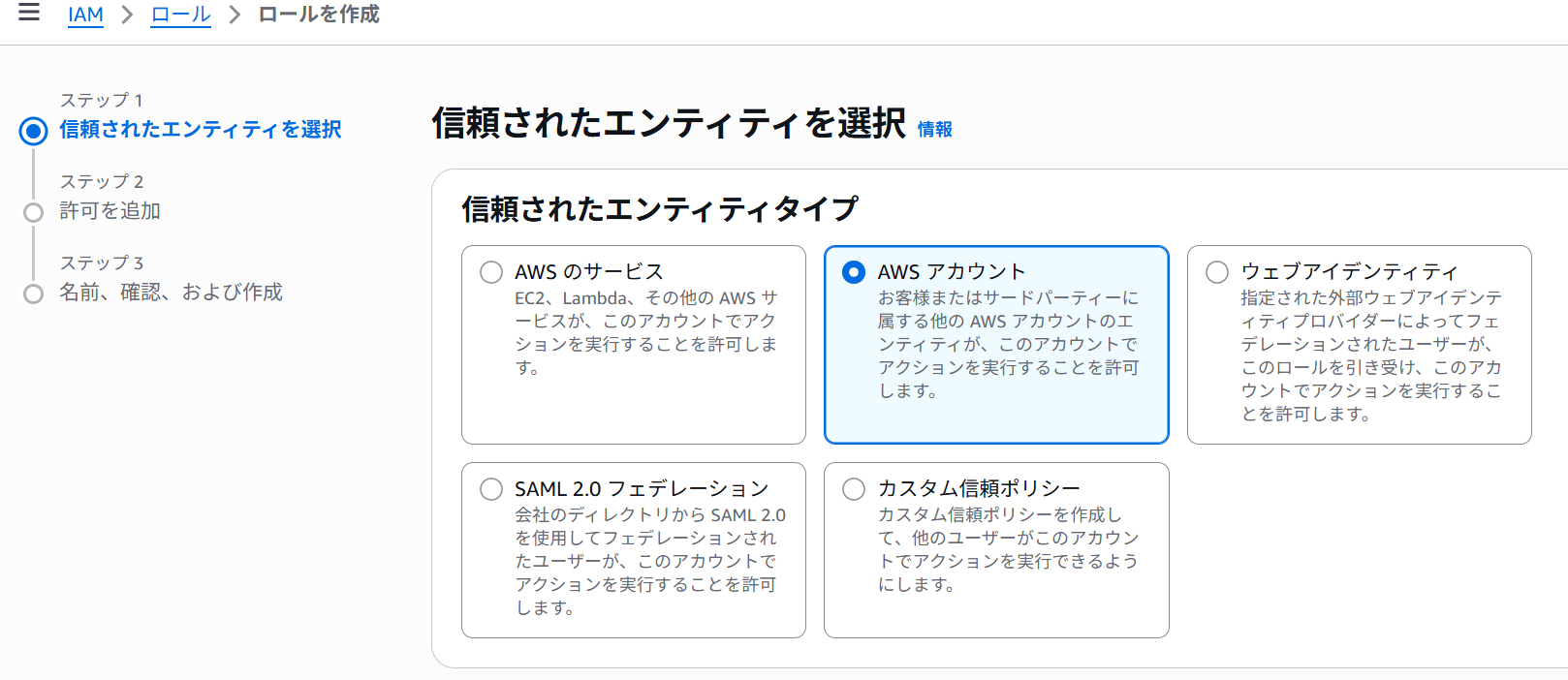
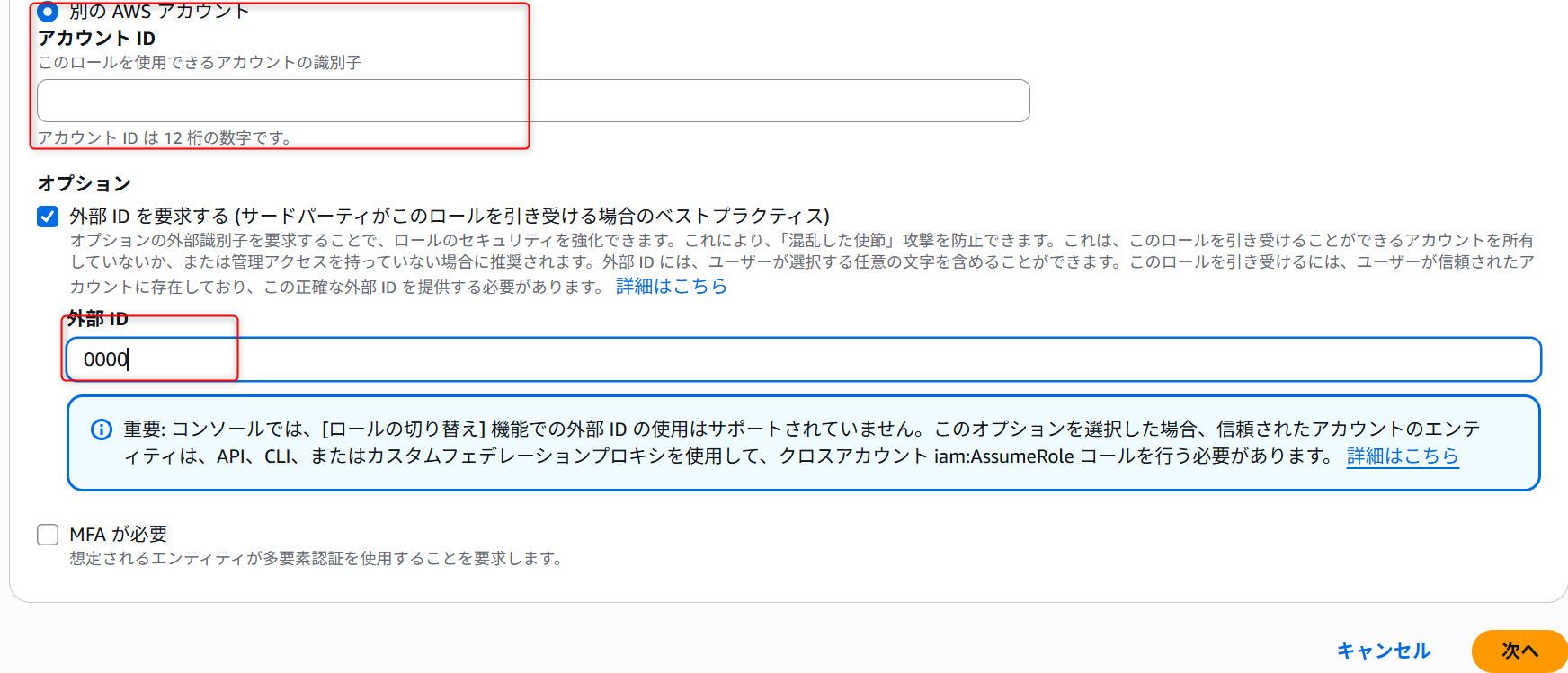
別のAWSアカウントを選択し、自身のAWSアカウントIDを入力します。(後ほど変更します)
オプションの外部IDを要求するを選択し、外部IDに0000を入力し、次へをクリックします。(後ほど変更します)
- 作成したポリシーを選択し、
次へをクリックします。

- ロールの名前と説明を入力し、
ロールを作成を選択します。
Snowflakeでクラウドストレージ統合を作成する
作成した、ロールのARNを調べます。
- AWS管理コンソールからIAMを検索して開き
ロールをクリックします。 - 作成したロールを選択し、クリックします。
- 概要部分に
ARNが記載されているので、コピーしておきます。
Snowflakeの操作に移ります。
ワークシートを開き、下記クエリを実行します。
--ストレージ統合の作成
CREATE STORAGE INTEGRATION <integration_name>
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = ''
STORAGE_ALLOWED_LOCATIONS = ('s3://mybucket20250715/snowflake/')
CREATE STORAGE INTEGRATIONには任意の名称を記載します。STORAGE_AWS_ROLE_ARNにコピーしたARNを記載します。STORAGE_ALLOWED_LOCATIONSには実際のバケット名とフォルダーパスプレフィックスを記載します。
Snowflakeアカウントの AWS IAM ユーザーを取得する
Snowflakeアカウント用に自動的に作成された IAMユーザーの ARN を取得するには、DESCRIBE INTEGRATIONを使用します。
1.下記クエリをSnowflakeワークシートで実行します。
integration_nameはさきほど作成したストレージの名称を記載します。
DESC INTEGRATION <integration_name>;
- 出力された結果の
propertyカラムのSTORAGE_AWS_IAM_USER_ARNとSTORAGE_AWS_EXTERNAL_IDの値(property_value)をコピーしておきます。
バケットオブジェクトにアクセスするために IAM ユーザー権限を付与する
- AWS管理コンソールからIAMを検索して開き
ロールをクリックします。 IAM AWS ロールを作成するで作成したロールを選択します。- 下記画面の
信頼関係タブを開き、信頼ポリシーを編集をクリックします。

4.エディタに下記クエリを記載し、右側下部のポリシーを更新で更新します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "<snowflake_user_arn>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<snowflake_external_id>"
}
}
}
]
}
snowflake_user_arnにはSTORAGE_AWS_IAM_USER_ARNの値を記載snowflake_external_idにはSTORAGE_AWS_EXTERNAL_IDの値を記載
外部ステージを作成する
作成したストレージ統合を参照する、外部ステージを作成します。
事前に、保存するデータベース・スキーマ・テーブル・ファイルフォーマットを作成しましょう。
今回はCSVデータを連携予定のため、下記クエリでファイルフォーマットを作成しました。
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = 'CSV',
FIELD_DELIMITER = ',',
SKIP_HEADER = 1;
※ファイルフォーマット公式ドキュメント
下記クエリを実行し、外部ステージを作成します。
USE SCHEMA mydb.public;
CREATE STAGE my_s3_stage
STORAGE_INTEGRATION = s3_int
URL = 's3://bucket1/path1/'
FILE_FORMAT = my_csv_format;
my_s3_stageには任意のステージ名を記載します。STORAGE_INTEGRATIONには作成したストレージ統合名を記載してください。URLには実際のバケット名とフォルダーパスプレフィックスに置き換えます。my_csv_formatは該当のファイルフォーマットを記載してください
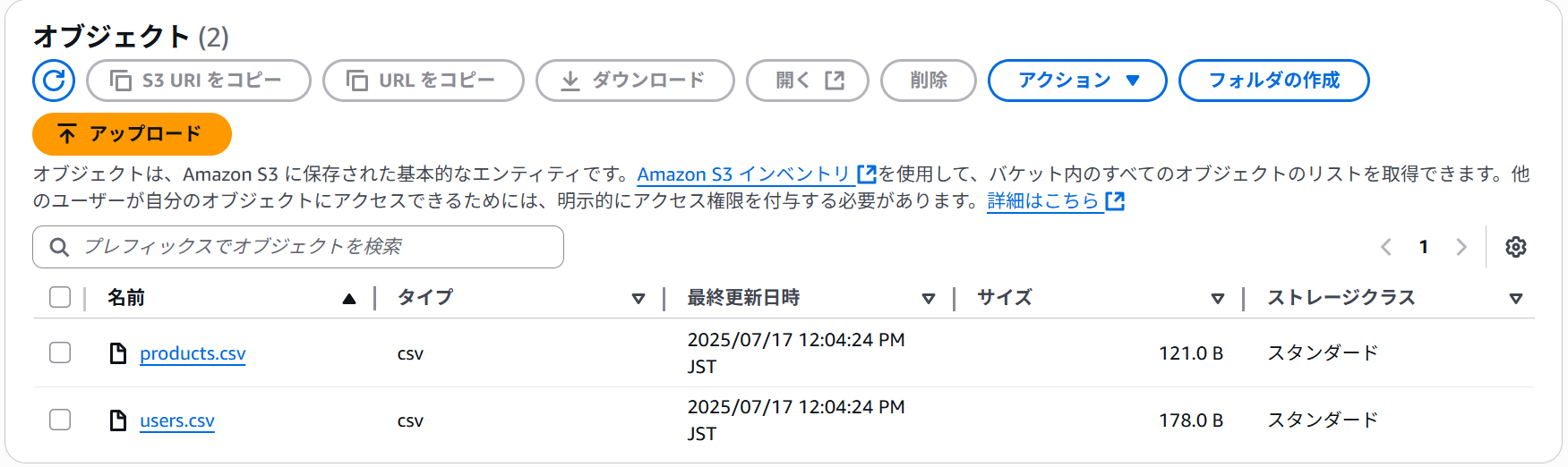
- S3のオブジェクト
- Snowflakeのステージ
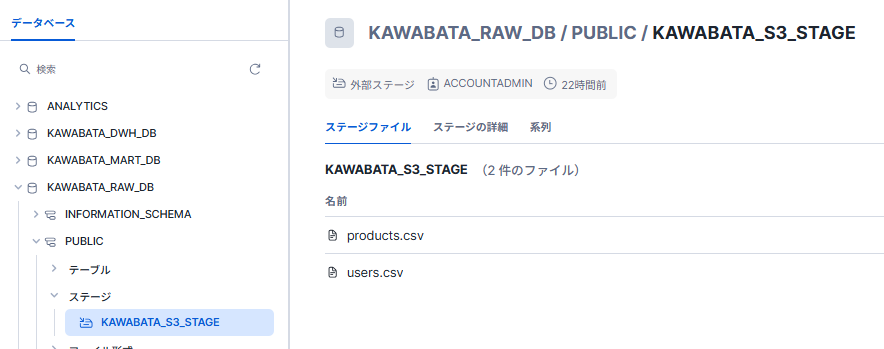
上記の通り、S3オブジェクトをステージから参照できました。
COPY INTOでデータロード
ここから、COPY INTO <テーブル>を実行して、データをターゲットテーブルにロードします。
下記クエリを実行します。
--データロード
COPY INTO KAWABATA_RAW_DB.public.user_id
FROM @kawabata_s3_stage
PATTERN='.*users.*.csv';
FROMは作成した、ステージ名を記載します。PATTERNは今回'users'で始まるファイルのみロードするようにしています。
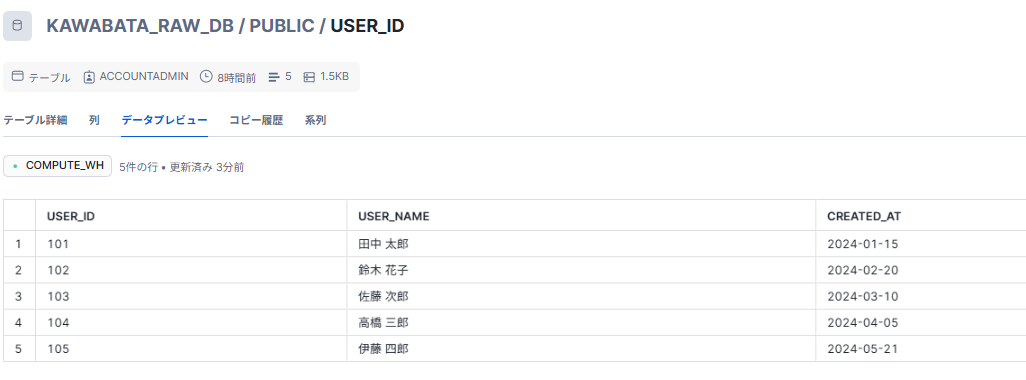
users.csvは生成AIでダミーデータを作成しました。詳細下記のとおりです。
| user_id | user_name | created_at |
|---|---|---|
| 101 | 田中 太郎 | 2024-01-15 |
| 102 | 鈴木 花子 | 2024-02-20 |
| 103 | 佐藤 次郎 | 2024-03-10 |
| 104 | 高橋 三郎 | 2024-04-05 |
| 105 | 伊藤 四郎 | 2024-05-21 |
Snowflake上で該当のテーブルを確認したところ、データがロードされていることが確認できました。
Snowpipeによるデータロード
Snowpipeでもデータをロードしていきます。
さきほど、ストレージ統合項目で外部ステージまで作成しましたが、Snowpipeでも必要となります。
今回は検証のため同じものを使用しますが、状況により作成することを推奨します。
概要
Snowpipeは、データウェアハウスサービスであるSnowflakeに、データを継続的かつ自動的にロードするための機能です。
あらかじめ定義したデータ形式(例:CSV、JSON、Parquetなど)と構造でデータが連携されることを前提としています。
定義と異なる形式のファイルや、データ構造が違うファイル、破損したファイルが連携された場合、そのファイルはエラーとなりロードないので注意が必要です。
自動インジェストを有効にしたパイプを作成する
今回連携するファイルはorders.csvを使用します。(同様に生成AIで作成しています。)
| order_id | user_id | product_id | quantity | order_date | status |
|---|---|---|---|---|---|
| 3001 | 101 | 201 | 5 | 2024-06-01 | completed |
| 3002 | 102 | 204 | 1 | 2024-06-01 | completed |
| 3003 | 101 | 205 | 2 | 2024-06-02 | shipped |
| 3004 | 103 | 202 | 10 | 2024-06-03 | completed |
| 3005 | 104 | 203 | 3 | 2024-06-05 | shipped |
| 3006 | 102 | 201 | 2 | 2024-06-05 | pending |
| 3007 | 105 | 205 | 1 | 2024-06-08 | completed |
| 3008 | 101 | 204 | 1 | 2024-06-10 | pending |
事前にorders.csvを格納するテーブルを作成しておきましょう。
-- snowpipe利用
CREATE PIPE KAWABATA_RAW_DB.public.kawabata_order_id
AUTO_INGEST = TRUE
AS
COPY INTO KAWABATA_RAW_DB.public.order_id
FROM @KAWABATA_RAW_DB.public.kawabata_s3_stage
FILE_FORMAT = my_csv_format;
CREATE PIPEにはターゲットテーブルを記載します。FROMは作成した、ステージ名を記載します。
イベント通知を構成する
- 下記クエリを実行します。
SHOW PIPES;
出力された結果から、notification_channelカラムの値をコピーしておきます。
ここから再びAWS側での作業となります。
2. Amazon S3 コンソールに移動し汎用バケットを選択します。
3. 該当のバケットを選択すると下記画面となりプロパティを選択します。
4. イベント通知セクションに移動し、イベント通知作成を選択します。

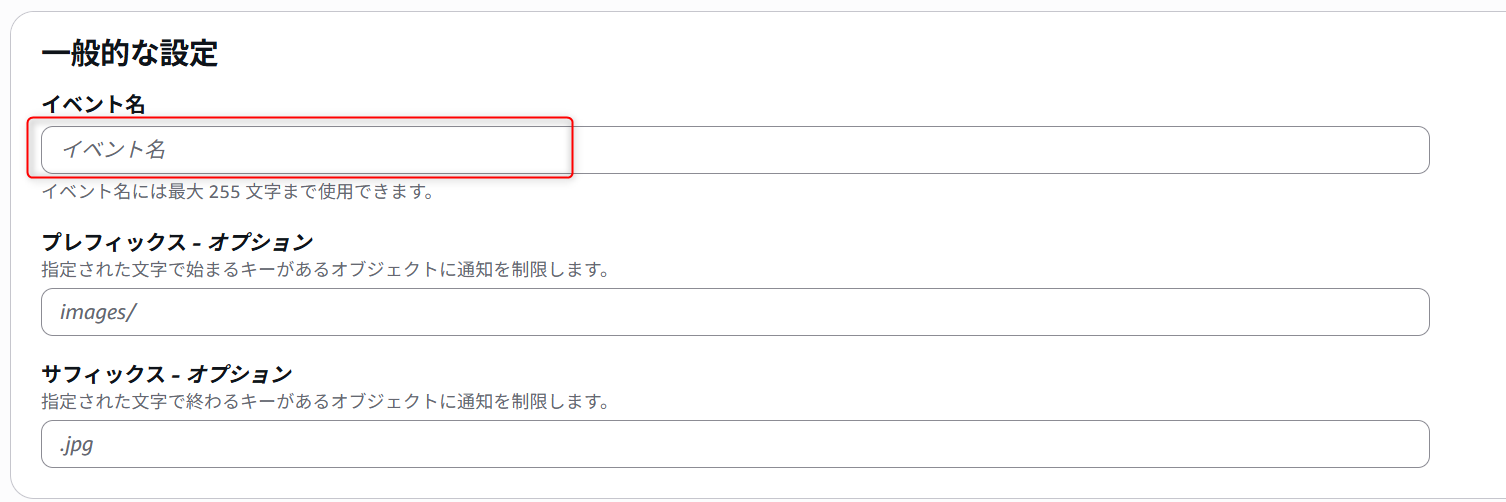
5. 一般的な設定部分セクションのイベント名を記載します。
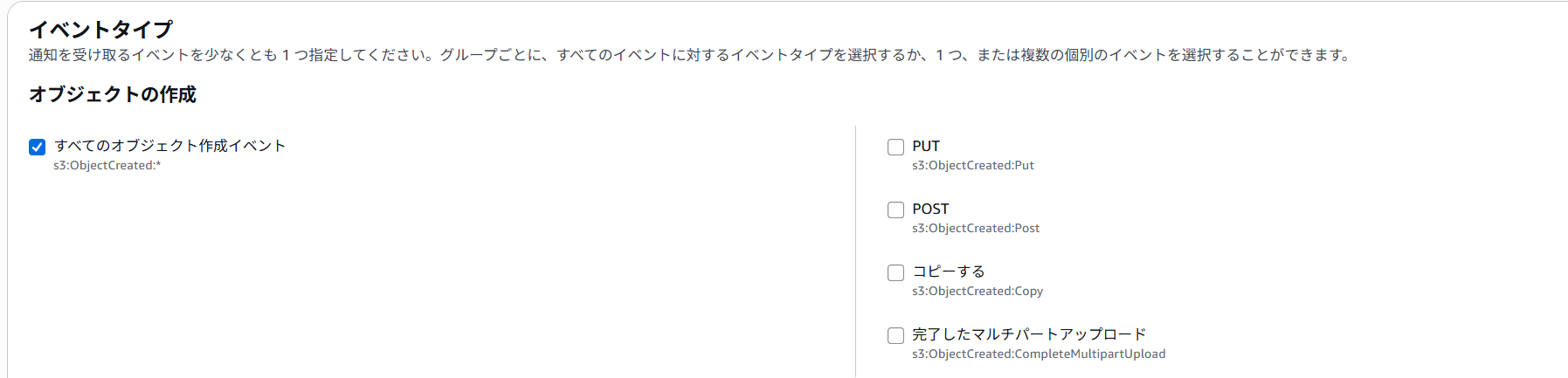
6.イベントタイプセクションはすべてのオブジェクト作成イベント にチェックを入れます。
7. 送信先セクションではSQSキューを選択,SQSキューの特定はSQSキューARNを入力を選択します。
SQSキューはSHOW PIPESで出力したnotification_channelカラムの値を入力します。
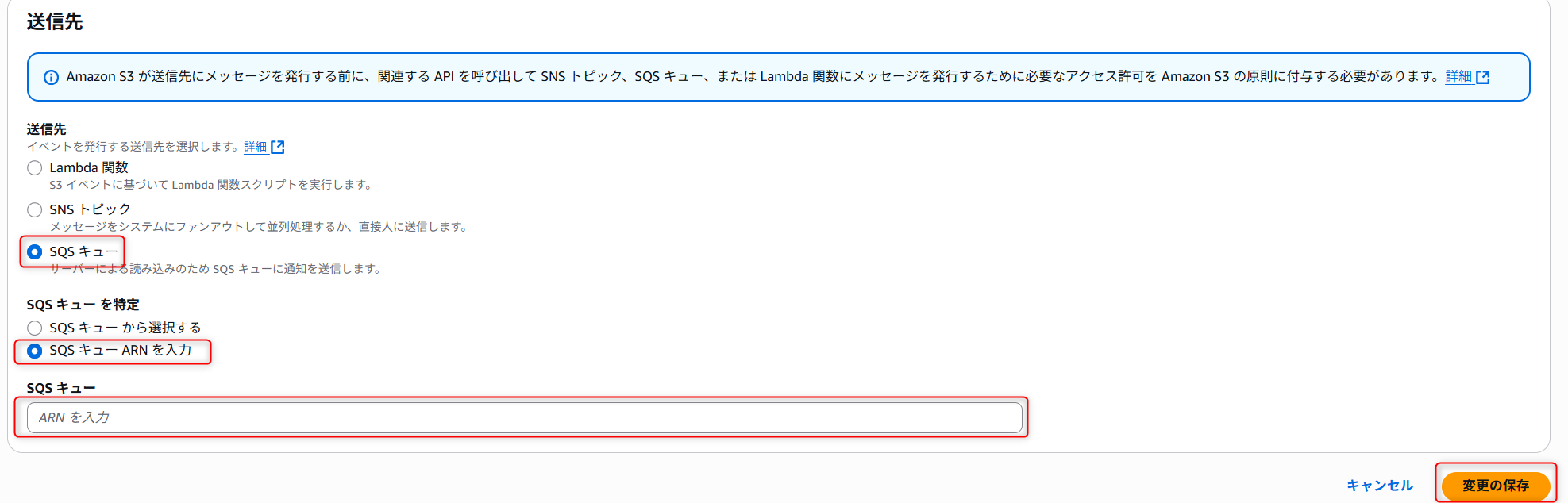
入力が完了したら、変更を保存します。
これで該当のS3バケットにオブジェクトが追加されたら、Snowpipeに通知して、それらをパイプで定義されたターゲットテーブルにロードします。
実際に確認してみましょう。
S3にorders.csvをアップロードします。

Snowflake側を確認すると
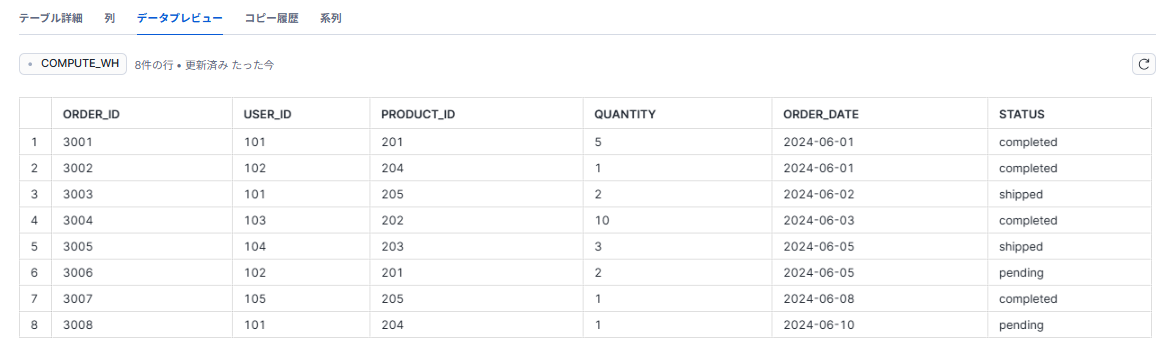
しっかりとデータロードが出来ていました。
最後に
いかがでしたでしょうか。
今回はデータロードの代表的な二つを紹介させていただきました。
データロードの仕方や連携先については他にも、外部テーブルへ自動更新やウェブインターフェイスを使用したデータのロード,Dynamic Table等あります。
状況に合わせてご活用ください。
この記事が参考になれば幸いです。








