![[アップデート] Amazon SageMaker HyperPod の node actions がコンソール対応したので Slurm クラスターで再起動を試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[アップデート] Amazon SageMaker HyperPod の node actions がコンソール対応したので Slurm クラスターで再起動を試してみた
はじめに
少し前のアップデートになりますが、2026 年 2 月 10 日、Amazon SageMaker HyperPod の node actions がマネジメントコンソールから操作できるようになりました。node actions は、クラスター内の個別インスタンスに対して再起動・置換・削除・接続(SSM 経由)を実行できる機能です。これまでは CLI や API を直接叩く必要がありましたが、コンソールから手軽に実行できるようになりました。
今回は Slurm クラスターのコントローラーインスタンスを対象に、コンソールから再起動を試しました。あわせて Session Manager 接続(接続アクション)も確認しました。
確認結果
- 接続(SSM 経由)もアクションメニューから完結するため、別途 Systems Manager のコンソールを開く必要はなく便利
- コンソールの node actions で再起動すると、直接アクセスのできない AWS 管理の EC2 の再起動を行える
- コントローラーインスタンスに対しても実行可能
- 再起動中は Slurm スケジューラへの問い合わせが一時的に応答しなくなるが、再起動完了後に
sinfoが正常応答することを確認できた
- 再起動中は Slurm スケジューラへの問い合わせが一時的に応答しなくなるが、再起動完了後に
node actions とは
HyperPod クラスターのインスタンスに対して、コンソール・API・CLI から直接操作する機能です。コンソールのアクションプルダウンから選択できる操作は以下の 4 種類です。
| アクション | 概要 |
|---|---|
| 接続 | AWS Systems Manager Session Manager でインスタンスにアクセス |
| 再起動 | EC2 の RebootInstances 相当。OS をクリーンに停止してから再起動 |
| 置換 | 障害インスタンスを新しい EC2 インスタンスに置き換え |
| 削除 | インスタンスをクラスターから削除 |
EKS と Slurm の両オーケストレーターで利用できます。
従来の運用との違い
node actions 対応前、Slurm クラスターでノードを手動で復旧するには、コントローラーに SSM 接続して以下のように scontrol を実行する必要がありました。
# 再起動をトリガー
scontrol update node=<ip-hostname> state=fail reason="Action:Reboot"
# 置換をトリガー
scontrol update node=<ip-hostname> state=fail reason="Action:Replace"
この scontrol ベースの手順は Slurm 固有で、EKS オーケストレーターでは kubectl による別の手順が必要でした。node actions API は オーケストレーター非依存で動作し、コンソールからも実行できます。 公式ドキュメントでは API 方式が推奨アクションとして明記されています。
SageMaker HyperPod offers two methods for manual node recovery. The preferred approach is using the SageMaker HyperPod Reboot and Replace APIs, which provides a faster and more transparent recovery process that works across all orchestrators.
出典: Manually replace or reboot a node using Slurm - SageMaker AI User Guide
検証環境
クラスター構成は以下のとおりです。
| 項目 | 値 |
|---|---|
| リージョン | ap-northeast-1(東京) |
| オーケストレーター | Slurm |
| インスタンスタイプ | ml.t3.medium |
| インスタンス構成 | controller-group: 1 台、compute-group: 2 台 |
コンソールからノードを操作する
クラスター詳細画面のインスタンスセクションで、右上のアクションプルダウンを開くと「接続」「再起動」「置換」「削除」の 4 つが並んでいます。以前はこのメニューに操作項目がなく、CLI/API から実行する必要がありました。

Session Manager で接続してみる
再起動の前に、アクションメニューの「接続」から Session Manager 接続を試しました。今回は compute-group のインスタンス(i-0738b0d19e9ff899f)を選んでいます。
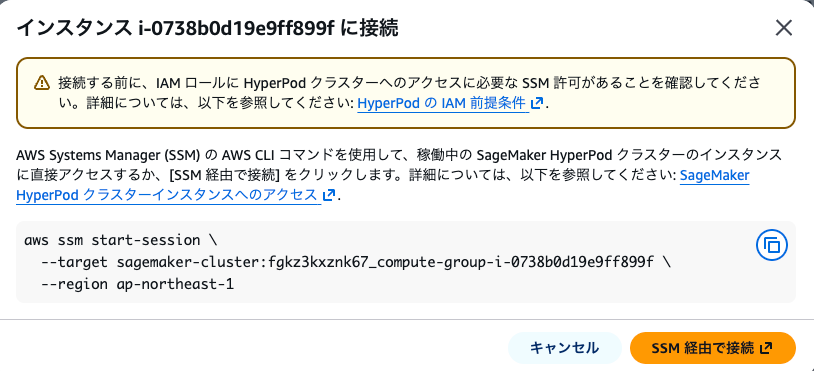
対象インスタンスのチェックボックスを入れて、アクション → 接続を選択します。

「接続」を選ぶと確認モーダルが開きます。IAM ロールに SSM 権限があれば「SSM 経由で接続」ボタンからブラウザターミナルが起動します。
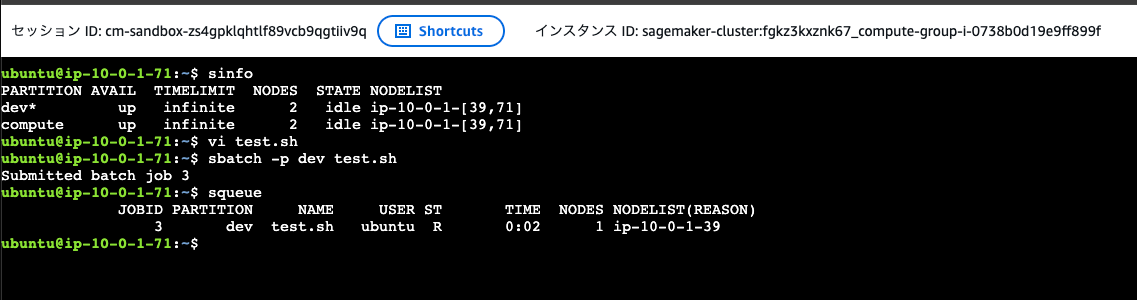
ブラウザ内で Session Manager のターミナルが開き、対象の コンピュートインスタンスへの接続に成功しました。

接続したまま コンピュートインスタンスから sinfo でクラスター状態を確認し、sbatch -p dev test.sh でジョブを投入しました。squeue を見るとジョブは接続先とは別の コンピュートノード(ip-10-0-1-39)で実行中です。Slurm が正常稼働していることを確認できます。
コントローラーインスタンスを再起動してみる
Slurm が正常稼働している状態で、コントローラーインスタンスを再起動します。
再起動したいコントローラーインスタンス(i-01cdf09da6ae1de41)の行にチェックを入れます。instance group は controller-group です。右上のアクション → 再起動を選択します。

「インスタンスを再起動」モーダルが開きます。対象インスタンスの ID・instance group 名・インスタンスタイプが表示されます。ワークロードが一時中断される旨の警告を確認したら「再起動」ボタンで確定します。

再起動を受け付けた直後、コントローラーインスタンスのステータスが Pending に変わります。

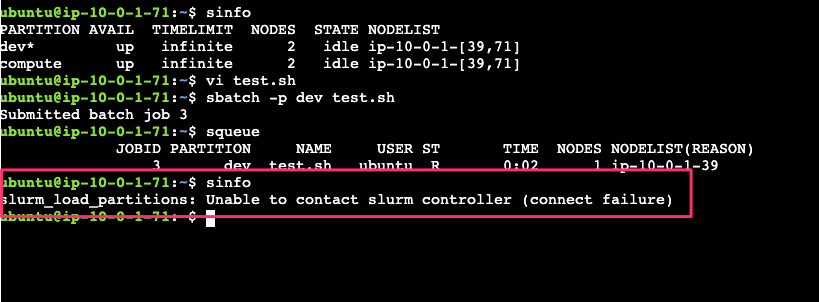
このとき コンピュートインスタンスから sinfo を実行するとエラーになります。コントローラー側の slurmctld がインスタンス再起動中により、応答できないためスケジューラへの問い合わせが失敗します。返るエラーは以下です。
slurm_load_partitions: Unable to contact slurm controller (connect failure)
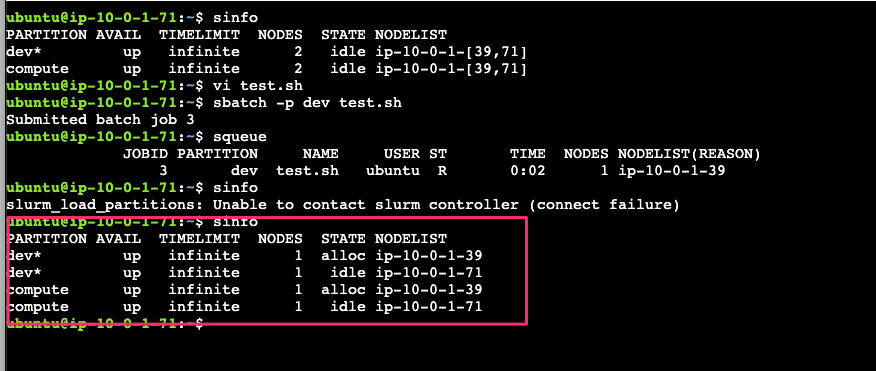
数分待つと、コントローラーインスタンスのステータスが Running に戻ります。

コントローラーインスタンスが復帰したあと、コンピュートインスタンスから再度 sinfo を打つと通常通り応答が返ってきます。再起動前に投入していたジョブの状態(alloc)も保持されていることが確認できます。
さいごに
コンソールからコントローラーインスタンスを再起動できることを確認しました。再起動中は Slurm が応答しませんが、完了後は自動で復帰し、ジョブ状態も維持されます。接続もアクションメニューから完結するため、Systems Manager のコンソールを別途開く必要がありません。たとえコントローラーインスタンスであっても、外部から簡単にリカバリ対応を取れるようになったのは運用が楽になりよいアップデートでした。
参考
- Amazon SageMaker HyperPod がコンソールからのノードアクションのサポートを開始
- Amazon SageMaker HyperPod がプログラムによるノードの再起動と置換をサポート
- BatchRebootClusterNodes - Amazon SageMaker
- Manually replace or reboot a node using Slurm - Amazon SageMaker AI
- Actions, resources, and condition keys for Amazon SageMaker - Identity and Access Management
- SageMaker HyperPod Workshop でクラスター作成時に学んだこと(DevelopersIO)
- ユーザー管理 VPC で SageMaker HyperPod をホストする(DevelopersIO)
- awsome-distributed-training - A collection of best practices, reference architectures, model training examples and utilities for distributed large model training on AWS








