![[SageMaker HyperPod] sample-physical-ai-scaffolding-kit ベースで FSx for Lustre 込みの最小クラスタを試してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[SageMaker HyperPod] sample-physical-ai-scaffolding-kit ベースで FSx for Lustre 込みの最小クラスタを試してみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
Amazon SageMaker HyperPod は、大規模な機械学習向けに永続的な計算クラスタを提供するサービスです。SageMaker Training Job がジョブ単位の課金で「使った時間だけ」払うのに対し、HyperPod は 「クラスタが上がっている間、継続課金」 という違いがあります。
今回は AWS Samples の sample-physical-ai-scaffolding-kit で紹介されている構成をベースに、最小限の 2 ノード(controller + worker)+ FSx for Lustre で立ち上げ、Slurm の hello world、GPU 認識テスト、/fsx 共有ストレージの動作確認を試してみました。
継続課金となると、その費用が気になってしまうのですが、本記事では、フェーズを分けて課金感覚を体感する構成を目指してみました。
フェーズを分けて課金感覚を体感する構成
作業ステップごとに「次に何が課金され、累計でいくらになるか」が見えやすいように、リソースの作成を 3 つのフェーズに分けています。
| フェーズ | 操作 | 追加で課金開始するリソース | 累計の目安(日) | 累計の目安(時) |
|---|---|---|---|---|
| 🟡 少額 | pnpm cdk deploy |
VPC + NAT + IAM + S3 + FsxSg | 約 220 円 | 約 10 円 |
| 🟠 中額 | ./scripts/create-fsx.sh |
+ FSx for Lustre | 約 1,400 円 | 約 60 円 |
| 🔴 高額 | ./scripts/create.sh |
+ HyperPod クラスタ 2 ノード | 約 10,200 円 | 約 430円 |
コスト・単価は 2026/05/15 時点のものです。
参考: Amazon SageMaker AI 料金ページ
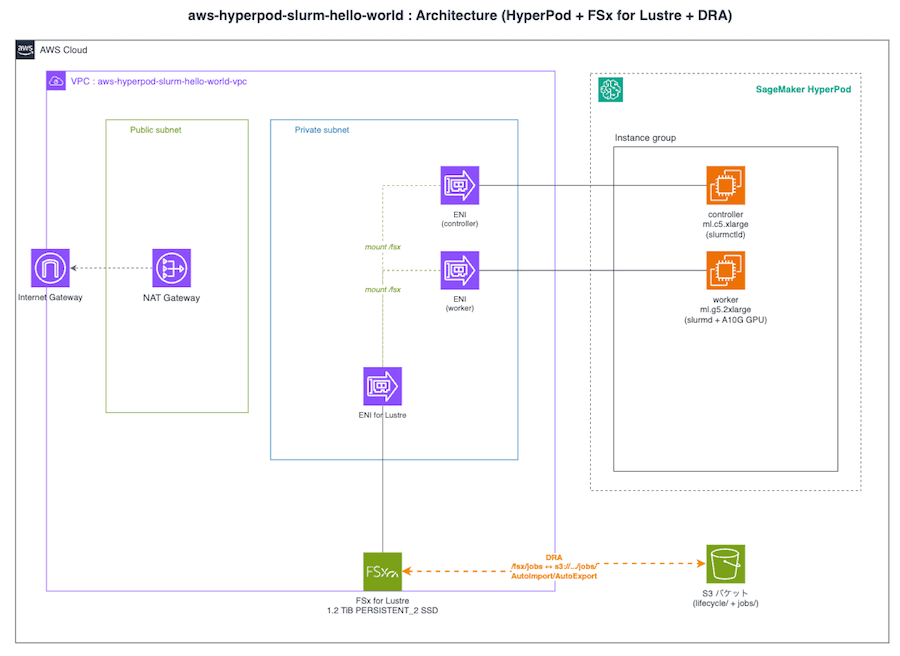
※ ENIは、FSx for Lustre・HyperPod クラスタ 作成時に作成されます。
2 前提
(1) スコープ
最初に、本稿で扱っているスコープについて整理させてください。
| 含めること | 含めないこと |
|---|---|
| CDK で VPC / IAM / S3 / FSx 用 SG の最小構成 | マルチ AZ、NACLなど |
HyperPod クラスタ 2 ノード(controller: ml.c5.xlarge / worker: ml.g5.2xlarge)作成 |
3 ノード以上のスケールアウト、Spot |
FSx for Lustre(PERSISTENT_2 SSD, 1.2 TiB)+ DRA による /fsx/jobs ↔ S3 自動連携 |
FSx ベンチマーク / FSx for OpenZFS / kit 流の Lambda カスタムリソース実装 |
Slurm 疎通(sinfo / srun / sbatch) |
ジョブ間依存、配列ジョブ |
GPU 認識テスト(nvidia-smi) |
ベンチマーク |
ダミー Python ジョブ(nvidia-smi を subprocess 経由で呼び出し) |
- |
scripts/teardown.sh による削除順序付き完全削除 |
- |
(2) 事前確認
本記事で利用するリソース・ツールが利用可能かどうか、次のコマンドで確認できます。
本記事は controller (ml.c5.xlarge) × 1 + worker (ml.g5.2xlarge) × 1 の 2 ノード構成 + FSx for Lustre 1.2 TiB なので、インスタンスタイプごとのクラスタ枠と、FSx for Lustre のストレージ枠を確認します。
# (1) worker (ml.g5.2xlarge × 1) 用のクラスタ枠を確認 — 1 以上必要
aws service-quotas list-service-quotas \
--service-code sagemaker \
--region ap-northeast-1 \
--query 'Quotas[?QuotaName==`ml.g5.2xlarge for cluster usage`].[QuotaName,Value,QuotaCode]' \
--output table
----------------------------------------------------------
| ListServiceQuotas |
+----------------------------------+------+--------------+
| ml.g5.2xlarge for cluster usage | 1.0 | L-596C3331 |
+----------------------------------+------+--------------+
# (2) controller (ml.c5.xlarge × 1) 用のクラスタ枠を確認 — 1 以上必要
aws service-quotas list-service-quotas \
--service-code sagemaker \
--region ap-northeast-1 \
--query 'Quotas[?QuotaName==`ml.c5.xlarge for cluster usage`].[QuotaName,Value,QuotaCode]' \
--output table
---------------------------------------------------------
| ListServiceQuotas |
+---------------------------------+-------+--------------+
| ml.c5.xlarge for cluster usage | 30.0 | L-AD3B35FF |
+---------------------------------+-------+--------------+
# (3) FSx for Lustre のストレージ枠(SSD)を確認 — 1.2 TiB(1228 GiB)以上必要
# 既存の FSx 利用量との合算で枠が足りるかを判断する
aws service-quotas list-service-quotas \
--service-code fsx \
--region ap-northeast-1 \
--query 'Quotas[?contains(QuotaName, `SSD storage capacity`)].[QuotaName,Value,QuotaCode]' \
--output table
# (4) ローカル必須ツール(無いものは事前に導入)
which aws pnpm node git jq python3 session-manager-plugin
クォータが足りない場合(上限緩和申請)
(1)(2) のいずれかで Value が 0 だった場合は、そのインスタンスタイプの上限緩和申請が必要です。SageMaker のクラスタ枠は調整可能(Adjustable)です。
# 上限緩和したいインスタンスタイプの QuotaName を指定
QUOTA_NAME="ml.g5.2xlarge for cluster usage"
# (a) QuotaCode を取得
QUOTA_CODE=$(aws service-quotas list-service-quotas \
--service-code sagemaker \
--region ap-northeast-1 \
--query 'Quotas[?QuotaName==`'"${QUOTA_NAME}"'`].QuotaCode' \
--output text)
echo "${QUOTA_CODE}"
# (b) 1 に引き上げる申請を出す
aws service-quotas request-service-quota-increase \
--service-code sagemaker \
--quota-code "${QUOTA_CODE}" \
--desired-value 1 \
--region ap-northeast-1
# (c) 申請状況の確認(Status が CASE_CLOSED + DesiredValue 達成で完了)
aws service-quotas list-requested-service-quota-change-history \
--service-code sagemaker \
--region ap-northeast-1 \
--query 'RequestedQuotas[?QuotaCode==`'"${QUOTA_CODE}"'`].[QuotaName,Status,DesiredValue,LastUpdated]' \
--output table
3 全体の流れ
作業の流れは、以下のとおりです。
| 操作 | 課金状態 | 主な課金リソース | 目安(日) | 目安(時) | |
|---|---|---|---|---|---|
| 1 | sync-lifecycle.sh(lifecycle スクリプト取り込み) |
🟢 | なし | - | - |
| 2 | pnpm cdk deploy(VPC + NAT + IAM + S3 + FsxSg) |
🟡 | NAT Gateway | 約 220 円 | 約 10 円 |
| 3 | create-fsx.sh(FSx for Lustre + DRA 作成) |
🟠 | + FSx for Lustre | 約 1,400 円 | 約 60 円 |
| 4 | aws sagemaker create-cluster(クラスタ作成) |
🔴 | + HyperPod クラスタ 2 ノード | 約 10,200 円 | 約 430 円 |
| 5 | SSM 接続 → srun / sbatch 実行(動作確認) |
🔴 | 同上 | 同上 | 同上 |
| 6 | delete-cluster.sh(クラスタ削除) |
🟠 | NAT + FSx 残 | 約 1,400 円 | 約 60 円 |
| 7 | delete-fsx.sh(DRA → FSx の順に削除 ) |
🟡 | NAT Gateway のみ | 約 220 円 | 約 10 円 |
| 8 | cdk destroy(cdk 削除) |
🟢 | なし | - | - |
4〜5 が、最も高額なゾーンとなります。クラスターの確認後は、速やかに6まで実施することで費用を抑えることができます。
なお手順 6〜8 をまとめて一気に実行する scripts/teardown.sh も用意されています。
4 sync-lifecycle.sh
(1) AWS Samples からの取り込み
HyperPod の lifecycle スクリプト本体は AWS Samples の awsome-distributed-training からコピーして使用させて頂いています。
Github scripts/sync-lifecycle.sh
./scripts/sync-lifecycle.sh
| ファイル / ディレクトリ | 概要 | 本記事での使用 |
|---|---|---|
on_create.sh |
エントリポイント。HyperPod が OnCreate で実行し、lifecycle_script.py を呼び出す |
✅ |
lifecycle_script.py |
lifecycle の本体。provisioning_parameters.json を読み、ノードの役割(controller / login / compute)を判定して各セットアップを実行 |
✅ |
start_slurm.sh |
Slurm デーモン(slurmctld / slurmd)を起動。prolog.sh / epilog.sh の配置と slurm.conf への登録も行う |
✅ |
prolog.sh / epilog.sh |
Slurm ジョブの開始前 / 終了後に実行されるフック(start_slurm.sh が slurm.conf に登録) |
✅ |
apply_hotfix.sh / hotfix/ |
既知の不具合に対するホットフィックスの適用(全ノードで実行) | ✅ |
add_users.sh |
OS ユーザーの追加(shared_users.txt があれば反映、無ければ ubuntu のみ) |
✅ |
utils/ |
各セットアップから呼ばれる共通サブスクリプト群(Ansible 導入・SSH 鍵生成など) | ✅ |
setup_mariadb_accounting.sh |
controller にローカル MariaDB で Slurm アカウンティングをセットアップ | ✅(controller のみ) |
setup_user_associations.sh |
Slurm のユーザー / アカウント関連付け設定 | ✅(controller のみ) |
setup_rds_accounting.sh |
Amazon RDS を使った Slurm アカウンティング(lifecycle_script.py からは呼ばれない) |
— |
mount_fsx.sh |
FSx for Lustre のマウント(provisioning_parameters.json の fsx_dns_name / fsx_mountname を読んで /fsx にマウント) |
✅ |
mount_fsx_openzfs.sh |
FSx for OpenZFS のマウント(provisioning_parameters.json に OpenZFS 設定なし) |
— |
setup_sssd.py |
SSSD(LDAP / AD 連携によるユーザー認証)のセットアップ(config.py で無効) |
— |
shared_users_sample.txt |
追加ユーザー定義のサンプル(テンプレートで、実行されない) | — |
observability/ |
Prometheus / Grafana 等によるモニタリングのセットアップ(config.py で無効) |
— |
multi_headnode_setup/ |
マルチヘッドノード(controller 冗長化)構成用(slurm_configurations 未指定のため不使用) |
— |
(2) 自前で持つ設定ファイル
Github:
リポジトリで自前に持っている設定ファイルは 3 つです。ファイル内のプレースホルダは、スクリプト実行時に自動で置換されます。
| ファイル | 役割 |
|---|---|
lifecycle/provisioning_parameters.json |
HyperPod のノード役割(controller_group / worker_groups)と FSx マウント設定(fsx_dns_name / fsx_mountname) |
lifecycle/config.py.override |
base-config の config.py を上書きします。本記事では Docker / Observability / SSSD など全機能 OFF |
cluster-config.json |
HyperPod クラスタの InstanceGroup 定義(controller + worker)と VPC 設定 |
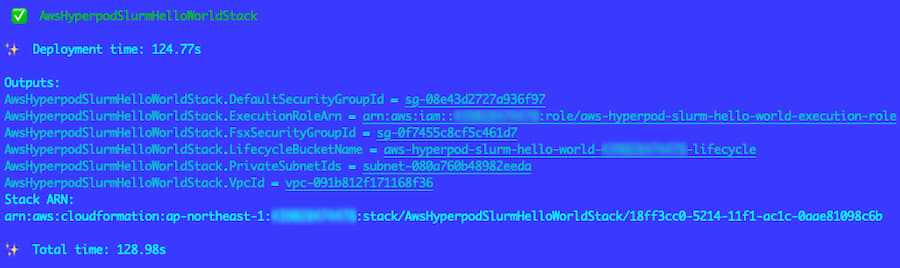
5 pnpm cdk deploy
Github cdk/lib/aws-hyperpod-slurm-hello-world-stack.ts
cdk/lib/aws-hyperpod-slurm-hello-world-stack.ts で、VPC / IAM Role / S3 Bucket / FSx 用 Security Group の 4 つを作成します。
cd cdk
pnpm install
pnpm cdk bootstrap # 初回のみ
pnpm cdk deploy
6 create-fsx.sh
FSx 本体と DRA(Data Repository Association)を作成します。
Github scripts/create-fsx.sh
./scripts/create-fsx.sh
scripts/create-fsx.sh は次を実行しています。
- CFn Outputs から
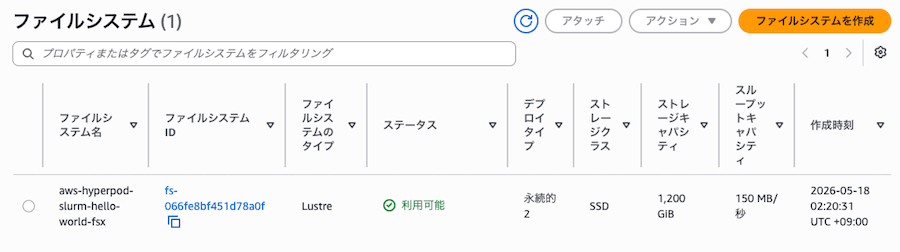
PrivateSubnetIds(先頭の AZ)/FsxSecurityGroupId/LifecycleBucketNameを取得 aws fsx create-file-systemで PERSISTENT_2 SSD / 1.2 TiB / 125 MB/s/TiB の FSx for Lustre を作成- FSx ステータスが
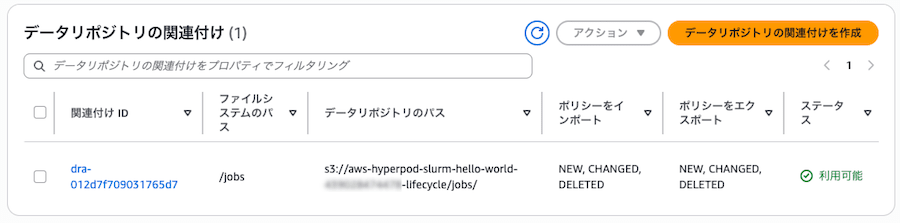
AVAILABLEになるまで 30 秒間隔でポーリング(10〜20 分) aws fsx create-data-repository-associationで DRA(/fsx/jobs↔s3://...lifecycle/jobs/)を作成。AutoImport / AutoExport ともにNEW,CHANGED,DELETEDで双方向自動同期- DRA ステータスが
AVAILABLEになるまで 30 秒間隔でポーリング(数分〜10 分)
$ ./scripts/create-fsx.sh
[create-fsx] 作成要求送信: fs-xxxxxxxxxxxxxxxxx
[create-fsx] FSx Status: CREATING
[create-fsx] FSx Status: CREATING
...
[create-fsx] FSx Status: AVAILABLE
[create-fsx] FSx 完了: fs-xxxxxxxxxxxxxxxxx (AVAILABLE)
[create-fsx] DRA 作成要求送信: dra-xxxxxxxxxxxxxxxxx
[create-fsx] DRA Status: CREATING
[create-fsx] DRA Status: CREATING
...
[create-fsx] DRA Status: AVAILABLE
[create-fsx] DRA 完了: dra-xxxxxxxxxxxxxxxxx (AVAILABLE)
[create-fsx] 次は ./scripts/create.sh でクラスタを作成してください
7 aws sagemaker create-cluster
HyperPod クラスタ 2 ノードを起動します。
Github scripts/create.sh
./scripts/create.sh
scripts/create.sh は次のような流れです。
- CFn Outputs から
LifecycleBucketName/ExecutionRoleArn/PrivateSubnetIds/DefaultSecurityGroupIdを取得 aws fsx describe-file-systemsで Name タグaws-hyperpod-slurm-hello-world-fsxから FSx のDNSName/MountNameを取得(無ければ即終了)lifecycle/provisioning_parameters.jsonの<FSX_DNS_NAME>/<FSX_MOUNT_NAME>プレースホルダを実値に置換し/tmp/provisioning_parameters.jsonに書き出しlifecycle/配下を S3 にアップロード(config.py.overrideとREADME.mdは除外)/tmp/provisioning_parameters.jsonを S3 上の原本に上書きアップロードcluster-config.jsonのプレースホルダを置換aws sagemaker create-clusterを実行
クラスタの状態は次のコマンドで確認できます。Creating から InService に遷移するまで通常 10〜20 分かかります。
aws sagemaker describe-cluster \
--cluster-name aws-hyperpod-slurm-hello-world \
--region ap-northeast-1 \
--query 'ClusterStatus'
"Creating" <= この表示が、InService になったら完了
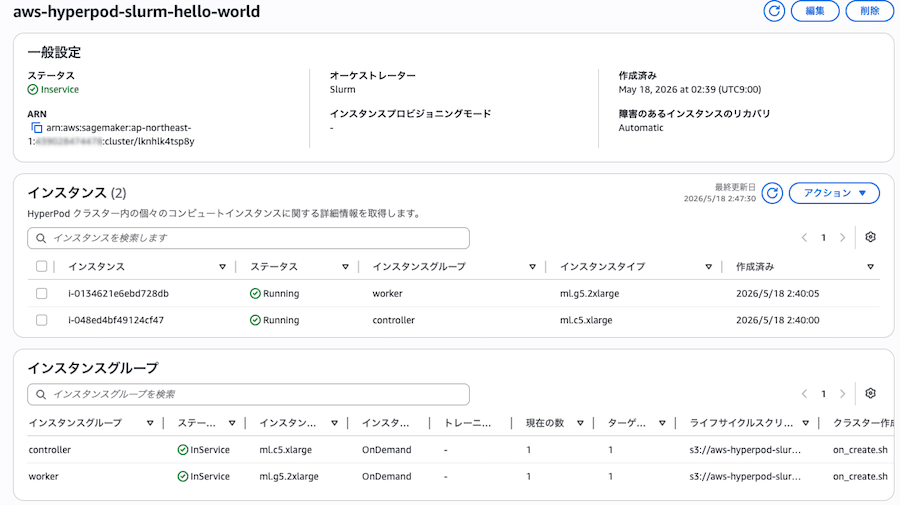
8 SSM 接続
controller ノードに SSM 接続し、Slurm 動作確認とダミー Python ジョブを実行します。
(1) SSM で接続
./scripts/connect.sh
scripts/connect.sh は内部で aws sagemaker list-cluster-nodes でインスタンス ID を取得し、aws ssm start-session で接続します。
(2) Slurm 動作確認
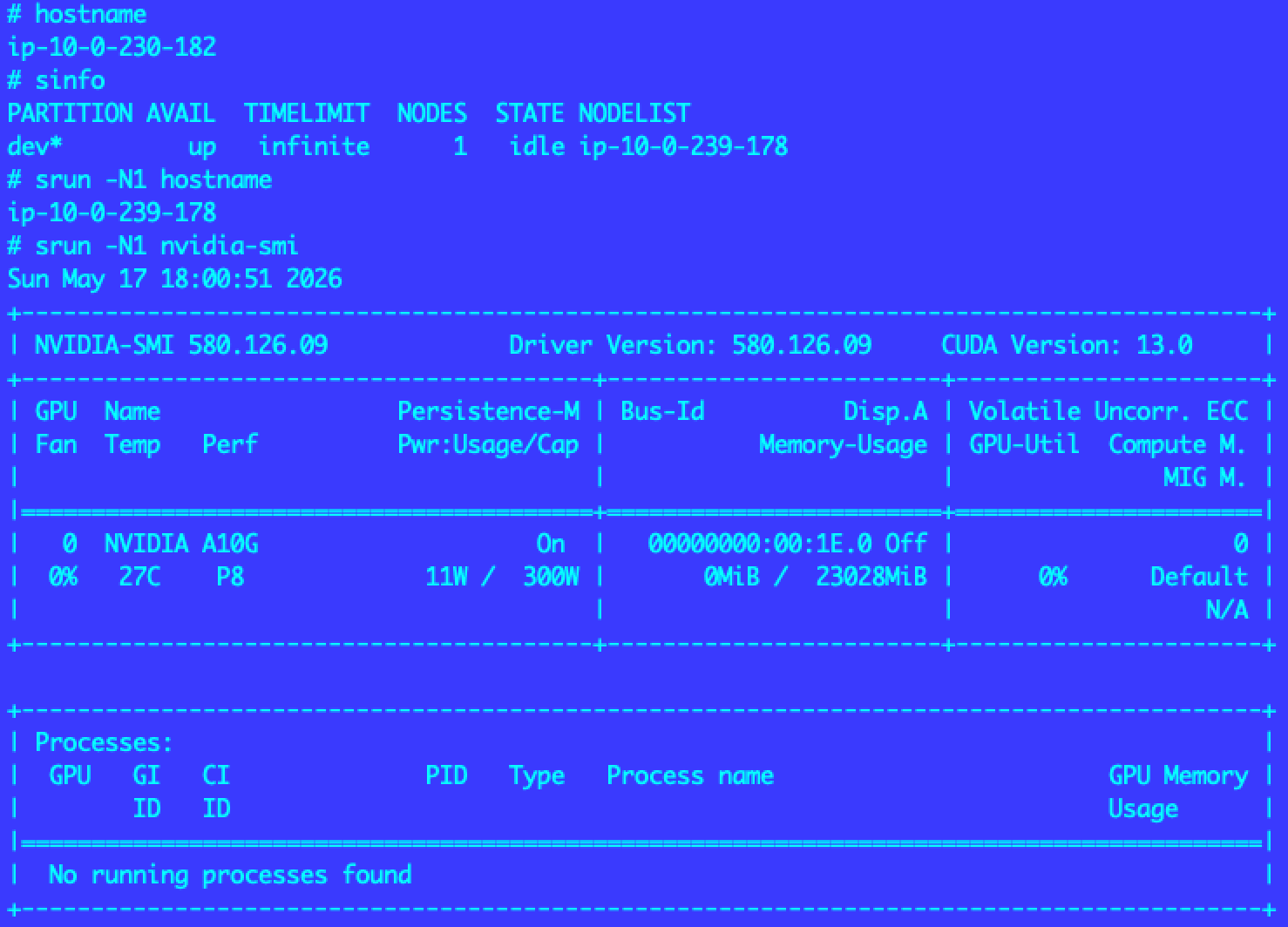
controller ノードに接続後、Slurm の基本コマンドを試します。
hostname # controller のホスト名確認
sinfo # クラスタ状態
srun -N1 hostname # worker のホスト名確認
srun -N1 nvidia-smi # GPU 認識確認
Controllerが、10.0.230.x、workerが、10.0.239.xで起動しています。
また、srun -N1 nvidia-smi で A10G の情報が確認できます。
FSx for Lustre のマウント確認
両ノードに FSx for Lustre が /fsx にマウントされていることも確認します。controller から自ノードと worker の両方で mount を実行し、lustrefs が出力されれば OK です。
# controller ノード上で(自ノードのマウント確認)
mount | grep fsx
# 期待: <FSX_DNS>@tcp:/<MOUNT> on /fsx type lustre (rw,...)
# worker ノードで同じ確認(controller から srun 経由)
srun -N1 bash -c 'mount | grep fsx'
# 共有ストレージとして動作することの確認(controller で書き、worker で読む)
mkdir -p /fsx/jobs
echo "hello from controller" > /fsx/jobs/hello.txt
srun -N1 cat /fsx/jobs/hello.txt
# 期待: hello from controller

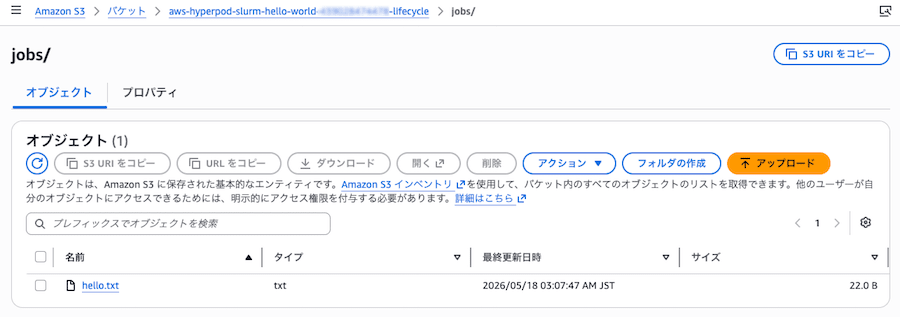
DRA 経由の S3 自動 export 確認
/fsx/jobs/ 配下に書いたファイルは DRA の AutoExport で s3://...lifecycle/jobs/ に自動アップロードされます(数十秒〜数分のラグあり)。
(3) ダミー Python ジョブ
jobs/hello.py は 標準ライブラリのみ で、実行ホスト名 / /fsx の中身 / GPU 情報を出力するスクリプトです。HyperPod の DLAMI には NVIDIA ドライバ + CUDA は含まれますが、PyTorch などの ML フレームワークはプリインストールされていないため、PyTorch を使わず nvidia-smi の subprocess 呼び出しで GPU を確認しています。
Github jobs/hello.py
import os
import socket
import subprocess
def main() -> None:
print(f"hostname: {socket.gethostname()}")
if os.path.exists("/fsx"):
entries = os.listdir("/fsx")
print(f"/fsx mounted: {entries}")
else:
print("/fsx not mounted")
try:
result = subprocess.run(
["nvidia-smi", "--query-gpu=name,memory.total", "--format=csv,noheader"],
capture_output=True,
text=True,
check=True,
)
print(f"gpu: {result.stdout.strip()}")
except (FileNotFoundError, subprocess.CalledProcessError) as e:
print(f"gpu: not available ({e})")
if __name__ == "__main__":
main()
jobs/hello.sh は sbatch スクリプトです。出力先を /fsx/jobs/ にすることで、ジョブ実行結果が DRA 経由で S3 にも自動 export されます。
Github jobs/hello.sh
#!/bin/bash
#SBATCH --job-name=hello
#SBATCH --output=/fsx/jobs/hello.%j.out
#SBATCH --nodes=1
#SBATCH --ntasks=1
mkdir -p /fsx/jobs
cd /fsx/jobs
python3 hello.py
実行は次の通り(controller ノードに SSM 接続した状態で)。hello.py / hello.sh を /fsx/jobs/ に配置すれば、両ノードから見える共有ストレージなので worker 側からも参照できます。
# /fsx/jobs/ に hello.py / hello.sh を配置済みの前提
cd /fsx/jobs
sbatch hello.sh
squeue
ls /fsx/jobs/
cat /fsx/jobs/hello.*.out
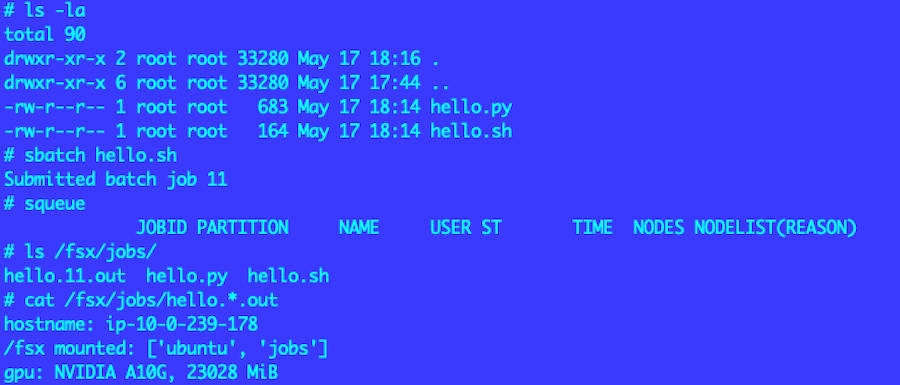
ログで hostname(worker ノード)、 /fsx mounted情報、gpu情報が確認できています。
そして、同じファイルが S3 にも export されていることも確認できます。
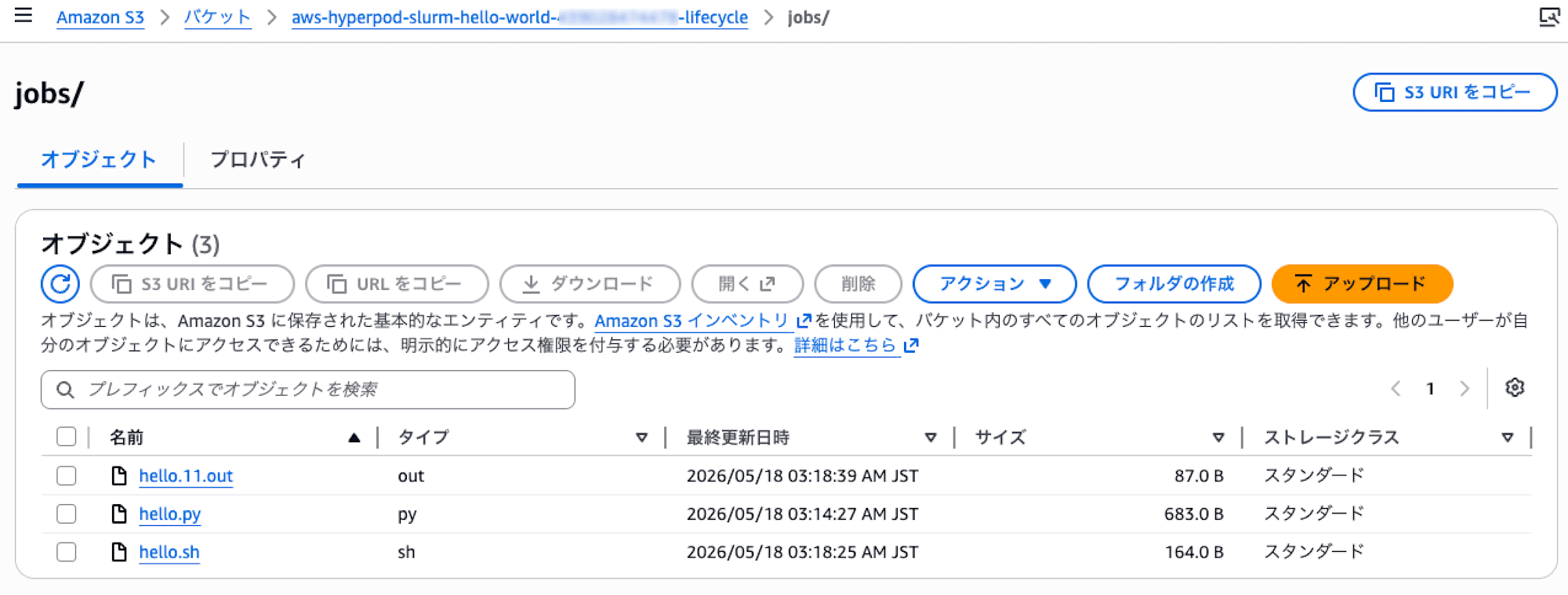
9 delete-cluster.sh
HyperPod クラスタを削除し、課金状態を中額(NAT + FSx 残)に戻します。
Github scripts/delete-cluster.sh
$ ./scripts/delete-cluster.sh
{
"ClusterArn": "arn:aws:sagemaker:ap-northeast-1:<ACCOUNT_ID>:cluster/xxxxxxxxxxxx"
}
[delete-cluster] クラスタ削除中...
[delete-cluster] クラスタ削除中...
...
[delete-cluster] クラスタ削除完了
describe-cluster が NotFound を返すまで 30 秒間隔でポーリングして削除完了を待ちます。
10 delete-fsx.sh
DRA → FSx for Lustre の順で削除し、課金状態を少額(NAT Gateway のみ)に戻します。クラスタが既に削除済みであることが前提です。
Github scripts/delete-fsx.sh
$ ./scripts/delete-fsx.sh
[delete-fsx] DRA 削除要求送信: dra-xxxxxxxxxxxxxxxxx
[delete-fsx] DRA dra-xxxxxxxxxxxxxxxxx Status: AVAILABLE
[delete-fsx] DRA dra-xxxxxxxxxxxxxxxxx Status: DELETING
[delete-fsx] DRA dra-xxxxxxxxxxxxxxxxx Status: DELETING
...
[delete-fsx] DRA dra-xxxxxxxxxxxxxxxxx Status: DELETING
[delete-fsx] DRA dra-xxxxxxxxxxxxxxxxx Status: None
[delete-fsx] DRA 削除完了: dra-xxxxxxxxxxxxxxxxx
[delete-fsx] FSx 削除要求送信: fs-xxxxxxxxxxxxxxxxx
[delete-fsx] FSx 削除中...
[delete-fsx] FSx 削除中...
...
[delete-fsx] FSx 削除中...
[delete-fsx] 完了
11 cdk destroy
VPC / NAT Gateway / IAM / S3 / FsxSg を削除し、課金状態をゼロに戻します。
cd cdk
pnpm cdk destroy --all --force
(1) teardown.sh による一括削除
scripts/teardown.shは、「9 delete-cluster.sh」、「10 delete-fsx.sh」、「11 cdk destroy」 を一括で実行するために用意しています。
Github scripts/teardown.sh
./scripts/teardown.sh
(2) 残留リソース確認
スクリプト完了後、残留リソースがないか確認するには、以下のコマンドが利用可能です。上から順に、利用費の高額なものになっています。
# HyperPod クラスタ残存チェック
aws sagemaker list-clusters --region ap-northeast-1
# FSx for Lustre 残存チェック
aws fsx describe-file-systems --region ap-northeast-1 \
--query 'FileSystems[?Lifecycle!=`DELETED`].[FileSystemId,Lifecycle,Tags[?Key==`Name`].Value|[0]]' \
--output table
# 利用可能状態の EBS(使われていないボリュームが残っていないか)
aws ec2 describe-volumes --region ap-northeast-1 \
--filters Name=status,Values=available
# NAT Gateway 残存チェック
aws ec2 describe-nat-gateways --region ap-northeast-1 \
--filter "Name=state,Values=available"
# 未関連付け EIP
aws ec2 describe-addresses --region ap-northeast-1 \
--query 'Addresses[?AssociationId==null]'
# CloudFormation スタック
aws cloudformation describe-stacks \
--stack-name AwsHyperpodSlurmHelloWorldStack \
--region ap-northeast-1 2>&1 | head -3
# → does not exist 等のエラーが返れば OK
# 残留 ENI 確認(課金はないが、VPC 削除を阻害していないか)
aws ec2 describe-network-interfaces \
--filters Name=description,Values="*hyperpod*" \
--region ap-northeast-1 \
--query 'NetworkInterfaces[].NetworkInterfaceId'
# → 空配列 [] であれば OK
12 ハマりどころなど
動作確認を実施していて、気になった点を列挙させて頂きます。
(1) delete-cluster の非同期完了を待たずに cdk destroy を走らせると VPC 削除が失敗する
aws sagemaker delete-cluster は非同期 API です。発行してすぐ cdk destroy を走らせると、HyperPod ノードに紐づいていた ENI がまだ VPC 内に残ったまま VPC 削除を試みることになり、削除が失敗します。
本記事の scripts/teardown.sh は describe-cluster が NotFound を返すまでポーリングしてから cdk destroy を呼ぶ設計のため、この問題は起きにくい構成にしています。
(2) awsome-distributed-training リポジトリ rename について
本記事で参照している lifecycle スクリプトの元リポジトリは、現在、awslabs/awsome-distributed-ai に rename + transfer されているようです。
(3) FSx for Lustre のセキュリティグループ (Lustre プロトコル)
FSx for Lustre は、Lustre プロトコル専用ポート 988 + 1021〜1023 を使います。これを SG で許可することに注意が必要です。
(4) FSx for Lustre の作成・削除には時間がかかる
FSx for Lustre は 作成と削除のそれぞれに 10〜20 分かかります。create-fsx.sh / delete-fsx.sh はこの待機をポーリングで吸収しています。また、DRA(Data Repository Association)も作成・削除それぞれに数分〜10 分かかります。create-fsx.sh は FSx と DRA を順に作成 + 待機するため、合計 15〜30 分程度を見込んでください。
(5) FSx for Lustre のデフォルトバージョンは 2.10
2025.05.18現在。aws fsx create-file-system で --file-system-type-version を省略すると Lustre 2.10 で作成されます。AWS マネジメントコンソールに「2.15 にアップグレードしてください」という通知が出ます。
13 最後に
HyperPod の最小構成(2 ノード: controller ml.c5.xlarge + worker ml.g5.2xlarge) + FSx for Lustre(PERSISTENT_2 SSD, 1.2 TiB) + DRA による S3 自動連携で、Slurm の hello world、GPU 認識テスト、共有ストレージ /fsx の動作確認、/fsx/jobs/ から S3 への自動 export を試し、削除順序付き(クラスタ → DRA → FSx → CDK)の完全削除まで一周しました。
フェーズをイメージしてリソースを構築することで、コストの感覚も少しは掴めたかも知れません。
コードは GitHub で公開しています。








