
SageMaker HyperPod の API 主導型 Slurm 設定を試してみた
はじめに
2026 年 2 月 26 日、SageMaker HyperPod の Slurm 向けに「API 主導型 Slurm 設定(API-driven Slurm configuration)」が追加されました。
従来は S3 の provisioning_parameters.json と Lifecycle Script でコントローラーやパーティションを定義していました。新機能では CreateCluster API のパラメーターに Slurm トポロジーを直接書けるため、IaC との親和性が上がります。
AWS CLI から CreateCluster と UpdateCluster を呼び出して、クラスター作成と、新規インスタンスグループ追加によるパーティション拡張を試しました。
確認結果
API 主導型 Slurm 設定で、クラスター作成と構成変更をそれぞれ 1 回の API コールで実行できました。
クラスター作成(CreateCluster)
- Slurm のパーティションとノードタイプを
CreateClusterAPI のペイロードで直接宣言できる - S3 への
provisioning_parameters.jsonアップロードが不要 DescribeClusterの出力だけでクラスター構成を一元把握できる
構成変更(UpdateCluster)
UpdateClusterAPI で新しいコンピュートインスタンスグループextra-groupを追加するだけで、新パーティションextraを拡張できた- S3 ファイル編集や Lifecycle Script の再実行は不要
API 主導型 Slurm 設定とは
API 主導型 Slurm 設定(API-driven Slurm configuration)は、Slurm トポロジーを API のパラメーターで宣言できる機能です。CreateCluster と UpdateCluster の両方で使えます。
InstanceGroups の SlurmConfig
インスタンスグループごとに SlurmConfig を指定します。
NodeType:Controller/Login/Computeの 3 種類で作成後は変更できませんPartitionNames:Computeでは必須、Controller/Loginでは指定不可- 1 インスタンスグループにつき 1 パーティション
コントローラーは 1 インスタンスグループ必須です。コンピュートは複数持てます。ログインは任意で、追加する場合は最大 1 インスタンスグループまでです。指定したパーティションとは別に、検証用の dev パーティションが自動作成されます。
SlurmConfigStrategy
Orchestrator.Slurm.SlurmConfigStrategy でドリフト管理の挙動を選択します。
| 戦略 | 挙動 | 向いているケース |
|---|---|---|
Managed(推奨) |
HyperPod がパーティションとノードのマッピングを管理。手動変更を検出するとクラスター更新が失敗する | IaC で構成を管理したい場合 |
Overwrite |
API 定義を強制適用し、手動変更は上書きする | ドリフトが生じた状態を既知の構成にリセットする用途 |
Merge |
手動変更を保持しつつ API 定義とマージする | カスタマイズ済みの slurm.conf と共存させたい場合 |
通常のクラスターでは UpdateCluster でいつでも戦略を切り替えられます(Continuous provisioning 有効時は後述の制約があります)。
Continuous provisioning(2026 年 3 月発表)と併用する場合、SlurmConfigStrategy パラメーター自体を指定できません。Managed / Overwrite / Merge のいずれを渡しても API エラーになります。Continuous provisioning は内部的に Merge 相当の挙動で slurm.conf のパーティション部分を追記管理します。
The SlurmConfigStrategy parameter (Managed, Merge, Overwrite) is not supported with continuous provisioning. Passing any SlurmConfigStrategy value results in an API error.
出展: https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-hyperpod-scaling-slurm.html
Amazon SageMaker HyperPod で Slurm オーケストレーションクラスター向けの Continuous provisioning のサポートを開始
従来方式との比較
従来の Lifecycle Script 方式と API 主導型の主な違いを整理します。
| 観点 | 従来方式(Lifecycle Script) | API 主導型 |
|---|---|---|
| Slurm トポロジー定義 | S3 の provisioning_parameters.json |
CreateCluster / UpdateCluster API |
| パーティション変更 | S3 ファイル編集 + Lifecycle 再実行 | UpdateCluster API |
| FSx マウント | on_create.sh 内の mount 処理 |
InstanceStorageConfigs で宣言的に指定 |
| ドリフト検出 | なし(手動管理) | Managed 戦略で自動検出 |
| 設定の可視性 | S3 とノード内のスクリプトに分散 | DescribeCluster で一元把握 |
| IaC 親和性 | S3 アップロードが別工程で必要 | API ペイロードのみで完結 |
検証構成
ap-northeast-1
[VPC 10.0.0.0/16]
├── private subnet (10.0.1.0/24)
│ ├── コントローラーノード ml.t3.medium × 1 (controller-group)
│ ├── コンピュートノード ml.t3.medium × 2 (compute-group)
│ └── 追加コンピュートノード ml.t3.medium × 1 (extra-group / UpdateCluster で追加)
└── public subnet (10.0.0.0/24)
└── NAT Gateway → インターネット
FSx for Lustre / OpenZFS は使用しません。HyperPod クラスター本体は AWS CLI で CreateCluster / UpdateCluster を呼び出して構築します。
やってみた
前提リソースを用意する
Lifecycle Script 置き場の S3 バケットは sagemaker- プレフィックスで始まる名前にします。マネージドポリシー AmazonSageMakerClusterInstanceRolePolicy のスコープが arn:aws:s3:::sagemaker-* に限定されているためです。この命名規約に従えば追加の S3 インラインポリシーは不要です。
awsome-distributed-training の base-config を S3 にアップロードします。
git clone https://github.com/aws-samples/awsome-distributed-training.git
aws s3 sync \
awsome-distributed-training/1.architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/ \
s3://${S3_BUCKET_NAME}/base-config/ \
--region ap-northeast-1
API 主導型でも Lifecycle Script は引き続き必要でした。provisioning_parameters.json は不要になりますが、Slurm デーモンの起動は Lifecycle Script が担います。
CreateCluster API で Slurm トポロジーを宣言する
CreateCluster API のペイロードに Slurm トポロジーを直接書きます。従来は provisioning_parameters.json に書いていた内容が API ペイロードに集約されます。
新しく指定できるようになったフィールドは 3 つあります。
Orchestrator.Slurm.SlurmConfigStrategy- ドリフト管理戦略(
Managed/Overwrite/Merge)
- ドリフト管理戦略(
InstanceGroups[].SlurmConfig.NodeType- ノードの役割(
Controller/Login/Compute)
- ノードの役割(
InstanceGroups[].SlurmConfig.PartitionNames- パーティション名(
Computeでは必須、Controller/Loginでは指定不可)
- パーティション名(
以降の手順では、事前に用意したリソースの値を次のシェル変数に設定します。
EXECUTION_ROLE_ARN=arn:aws:iam::123456789012:role/hyperpod-api-driven-exec-role
SUBNET_ID=<your-private-subnet-id>
SECURITY_GROUP_ID=<your-security-group-id>
S3_BUCKET_NAME=sagemaker-hyperpod-api-driven-lcc-b466065b
EXECUTION_ROLE_ARN に指定する ExecutionRole には、以下の権限を付与します。
- AWS マネージドポリシー:
AmazonSageMakerClusterInstanceRolePolicy,AmazonSSMManagedInstanceCore - VPC アクセス用インラインポリシー: ENI 管理権限(
ec2:CreateNetworkInterface等)。HyperPod がカスタマー VPC に ENI をアタッチするために必要
scripts/create_cluster.json を作成します。
controller-groupはNodeType: "Controller"で宣言。PartitionNamesは付けないcompute-groupはNodeType: "Compute"とPartitionNames: ["compute"]でcomputeパーティションを割り当てるSlurmConfigStrategy: "Managed"でパーティションとノードのマッピング管理を HyperPod に委ねる
mkdir -p scripts
cat > scripts/create_cluster.json << EOF
{
"ClusterName": "hyperpod-api-driven-cluster",
"InstanceGroups": [
{
"InstanceGroupName": "controller-group",
"InstanceType": "ml.t3.medium",
"InstanceCount": 1,
"ThreadsPerCore": 1,
"ExecutionRole": "${EXECUTION_ROLE_ARN}",
"SlurmConfig": {
"NodeType": "Controller"
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://${S3_BUCKET_NAME}/base-config/",
"OnCreate": "on_create.sh"
}
},
{
"InstanceGroupName": "compute-group",
"InstanceType": "ml.t3.medium",
"InstanceCount": 2,
"ThreadsPerCore": 1,
"ExecutionRole": "${EXECUTION_ROLE_ARN}",
"SlurmConfig": {
"NodeType": "Compute",
"PartitionNames": ["compute"]
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://${S3_BUCKET_NAME}/base-config/",
"OnCreate": "on_create.sh"
}
}
],
"Orchestrator": {
"Slurm": {
"SlurmConfigStrategy": "Managed"
}
},
"VpcConfig": {
"SecurityGroupIds": ["${SECURITY_GROUP_ID}"],
"Subnets": ["${SUBNET_ID}"]
},
"Tags": [
{"Key": "Project", "Value": "hyperpod-api-driven-blog"},
{"Key": "ManagedBy", "Value": "manual"}
]
}
EOF
JSON を渡してクラスターを作成します。
aws sagemaker create-cluster \
--cli-input-json file://scripts/create_cluster.json \
--region ap-northeast-1
{
"ClusterArn": "arn:aws:sagemaker:ap-northeast-1:123456789012:cluster/tyjxlpi1nicr"
}
成功すると ClusterArn が返ります。クラスターが InService になるまで 8 分かかりました。
DescribeCluster で宣言内容を確認する
CreateCluster で渡した Slurm トポロジーが正しく設定されているか確認します。ClusterStatus・SlurmConfigStrategy・各インスタンスグループの NodeType と PartitionNames を絞り込んで取得します。
aws sagemaker describe-cluster \
--cluster-name hyperpod-api-driven-cluster \
--region ap-northeast-1 \
--query '{Status: ClusterStatus, Strategy: Orchestrator.Slurm.SlurmConfigStrategy, Groups: InstanceGroups[*].{Name: InstanceGroupName, Type: SlurmConfig.NodeType, Partitions: SlurmConfig.PartitionNames}}'
{
"Status": "InService",
+ "Strategy": "Managed",
"Groups": [
{
"Name": "controller-group",
"Type": "Controller",
"Partitions": null
},
{
"Name": "compute-group",
"Type": "Compute",
"Partitions": [
"compute"
]
}
]
}
CreateCluster で渡した JSON どおり、SlurmConfigStrategy と各グループの Type / Partitions が返ります。従来は S3 ファイルと EC2 内スクリプトに分散していた定義を、describe-cluster で把握できます。
マネジメントコンソールの HyperPod クラスター詳細画面からも確認できます。
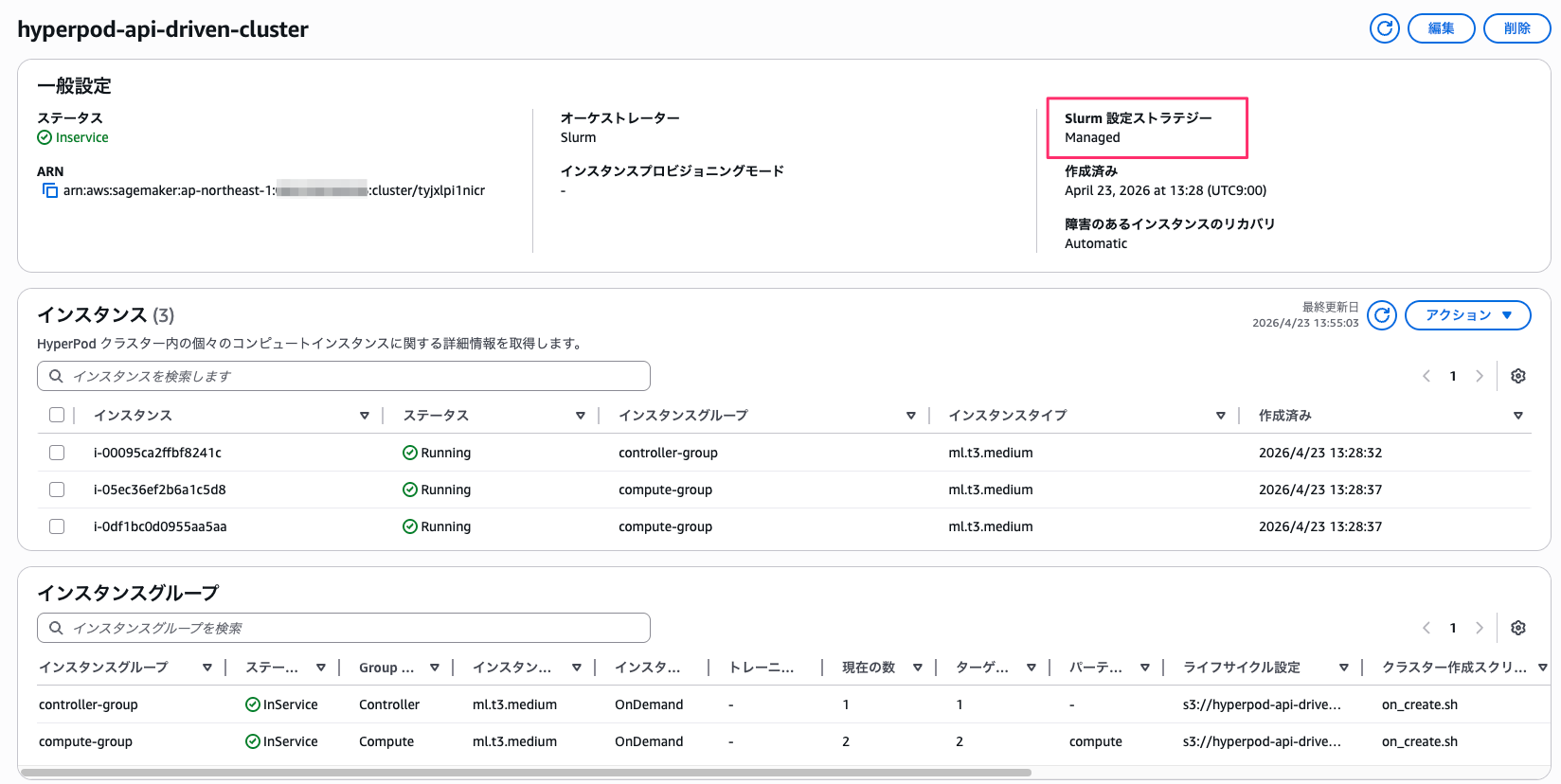
SSM でコントローラーノードに接続する
HyperPod クラスターノードへの SSM 接続には専用ターゲット記法を使います。
sagemaker-cluster:<cluster-id>_<instance-group-name>-<instance-id>
<cluster-id> はクラスター名ではなく ClusterArn 末尾の短い ID です。例えば ARN が arn:aws:sagemaker:...:cluster/tyjxlpi1nicr なら、Cluster ID は tyjxlpi1nicr になります。
describe-cluster で Cluster ID を、list-cluster-nodes でコントローラーノードのインスタンス ID を取得します。
CLUSTER_ID=$(aws sagemaker describe-cluster \
--cluster-name hyperpod-api-driven-cluster \
--region ap-northeast-1 \
--query 'ClusterArn' \
--output text | awk -F/ '{print $NF}')
CONTROLLER_INSTANCE_ID=$(aws sagemaker list-cluster-nodes \
--cluster-name hyperpod-api-driven-cluster \
--region ap-northeast-1 \
--query 'ClusterNodeSummaries[?InstanceGroupName==`controller-group`].InstanceId' \
--output text)
echo "Cluster ID: ${CLUSTER_ID}"
echo "Controller Instance ID: ${CONTROLLER_INSTANCE_ID}"
Cluster ID: tyjxlpi1nicr
Controller Instance ID: i-0fbd4b7ba6f3b477f
取得した値で SSM セッションを開始します。
aws ssm start-session \
--target "sagemaker-cluster:${CLUSTER_ID}_controller-group-${CONTROLLER_INSTANCE_ID}" \
--region ap-northeast-1
マネジメントコンソールのクラスターノード一覧で対象ノードを選び、「アクション」メニューから「接続」を選ぶと同じセッションが開きます。詳細は過去記事を参照してください。
Slurm の動作を確認する
コントローラーノードに接続した状態で実行します。
compute パーティションと dev パーティションの両方が表示されます。dev は全ノードが自動所属する universal partition です。手動で定義していなくても必ず作られます。
ubuntu@ip-10-0-1-75:~$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
dev* up infinite 2 idle ip-10-0-1-[24,99]
compute up infinite 2 idle ip-10-0-1-[24,99]
dev パーティションの詳細を確認します。
scontrol show partition dev
ubuntu@ip-10-0-1-75:~$ scontrol show partition dev
PartitionName=dev
AllowGroups=ALL AllowAccounts=ALL AllowQos=ALL
AllocNodes=ALL Default=YES QoS=N/A
DefaultTime=NONE DisableRootJobs=NO ExclusiveUser=NO ExclusiveTopo=NO GraceTime=0 Hidden=NO
MaxNodes=UNLIMITED MaxTime=UNLIMITED MinNodes=0 LLN=NO MaxCPUsPerNode=UNLIMITED MaxCPUsPerSocket=UNLIMITED
NodeSets=ALL
Nodes=ip-10-0-1-[24,99]
PriorityJobFactor=1 PriorityTier=1 RootOnly=NO ReqResv=NO OverSubscribe=EXCLUSIVE
OverTimeLimit=NONE PreemptMode=OFF
State=UP TotalCPUs=2 TotalNodes=2 SelectTypeParameters=NONE
JobDefaults=(null)
DefMemPerNode=UNLIMITED MaxMemPerNode=UNLIMITED
TRES=cpu=2,mem=8G,node=2,billing=2
ジョブを投入して実際にコンピュートノードで実行されるか確認します。
sbatch --partition=compute --wrap="hostname && sleep 30"
squeue でジョブが R(Running)になったので問題なく動きました。
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 compute wrap ubuntu PD 0:00 1 (None)
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 compute wrap ubuntu R 0:05 1 ip-10-0-1-24
UpdateCluster で新しいパーティション用のインスタンスグループを追加する
API 主導型の構成変更を試します。extra パーティションを生やすために、新しいコンピュートインスタンスグループ extra-group を追加します。
PartitionNames は 1 インスタンスグループにつき 1 つという制約があります。既存の compute-group に extra を追加するのではなく、新規インスタンスグループ extra-group に extra パーティションを割り当てました。
UpdateCluster の InstanceGroups には、更新後も残すインスタンスグループをすべて列挙します。既存の controller-group と compute-group を維持するため、変更なしの定義もそのまま含めます。なお Orchestrator を省略しているため、SlurmConfigStrategy は既存の Managed が維持されます。
cat > scripts/update_cluster.json << EOF
{
"ClusterName": "hyperpod-api-driven-cluster",
"InstanceGroups": [
{
"InstanceGroupName": "controller-group",
"InstanceType": "ml.t3.medium",
"InstanceCount": 1,
"ThreadsPerCore": 1,
"ExecutionRole": "${EXECUTION_ROLE_ARN}",
"SlurmConfig": {
"NodeType": "Controller"
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://${S3_BUCKET_NAME}/base-config/",
"OnCreate": "on_create.sh"
}
},
{
"InstanceGroupName": "compute-group",
"InstanceType": "ml.t3.medium",
"InstanceCount": 2,
"ThreadsPerCore": 1,
"ExecutionRole": "${EXECUTION_ROLE_ARN}",
"SlurmConfig": {
"NodeType": "Compute",
"PartitionNames": ["compute"]
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://${S3_BUCKET_NAME}/base-config/",
"OnCreate": "on_create.sh"
}
},
{
"InstanceGroupName": "extra-group",
"InstanceType": "ml.t3.medium",
"InstanceCount": 1,
"ThreadsPerCore": 1,
"ExecutionRole": "${EXECUTION_ROLE_ARN}",
"SlurmConfig": {
"NodeType": "Compute",
"PartitionNames": ["extra"]
},
"LifeCycleConfig": {
"SourceS3Uri": "s3://${S3_BUCKET_NAME}/base-config/",
"OnCreate": "on_create.sh"
}
}
]
}
EOF
JSON を渡して UpdateCluster を呼び出します。
aws sagemaker update-cluster \
--cli-input-json file://scripts/update_cluster.json \
--region ap-northeast-1
マネジメントコンソールで更新中のステータスを確認できます。

extra-group のノードが追加され、インスタンスグループが 3 つに増えました。
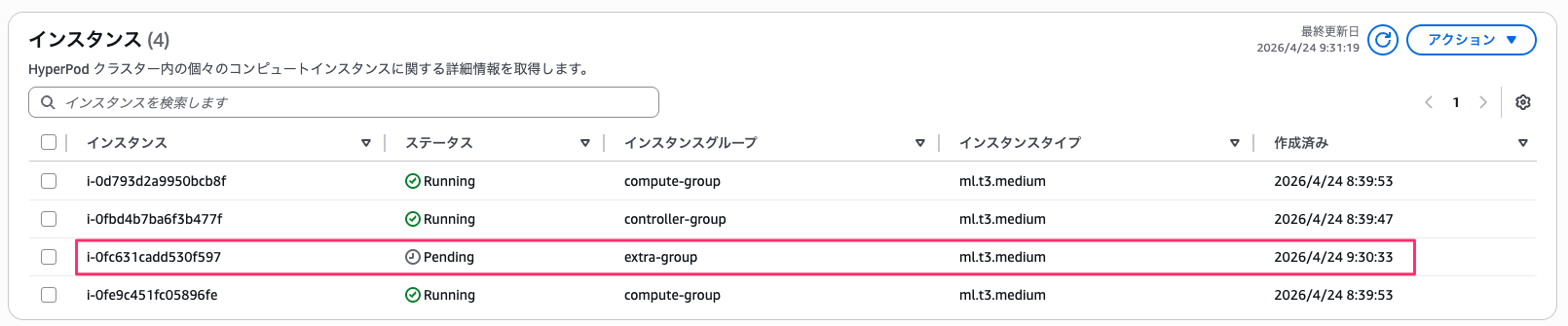
更新が完了したら、コントローラーノード上で sinfo を実行し extra パーティションが追加されていることを確認します。
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
dev* up infinite 3 idle ip-10-0-1-[24,99,105]
compute up infinite 2 idle ip-10-0-1-[24,99]
extra up infinite 1 idle ip-10-0-1-105
ubuntu@ip-10-0-1-75:~$
従来方式なら S3 の provisioning_parameters.json を書き換えて Lifecycle Script を再実行する必要があります。API 主導型では update-cluster コマンド 1 つで完結します。
ハマりポイントと注意事項
Terraform からのクラスターデプロイの未対応(2026 年 4 月時点)
awscc プロバイダー(hashicorp/awscc)v1.80.0(2026 年 4 月時点)の awscc_sagemaker_cluster は Slurm 属性に未対応です。具体的には SlurmConfig と SlurmConfigStrategy が未実装です。CloudFormation(AWS::SageMaker::Cluster)はすでに対応済みです。
Continuous provisioning 併用時の制約
Continuous provisioning(2026 年 3 月発表)と組み合わせる場合、SlurmConfigStrategy パラメーター自体を指定できません。Managed / Overwrite / Merge のいずれを渡しても API エラーになります。Continuous provisioning は内部的に Merge 相当の挙動で slurm.conf のパーティション部分を追記管理します。
既存クラスターからの移行パスは現時点で未提供
従来の Lifecycle Script 方式で作成したクラスターを API 主導型に自動変換する手段は 2026 年 4 月時点では提供されていません。新規クラスターとして作り直す形になります。
さいごに
API 主導型 Slurm 設定により、次の 2 シナリオを AWS CLI から実行して確認しました。IaC で管理しやすくなるアップデートでした。
CreateClusterでcontroller-group+compute-groupの 2 インスタンスグループを 1 回のコールで宣言UpdateClusterで新規コンピュートインスタンスグループextra-groupを追加し、extraパーティションを 1 コールで拡張
Slurm トポロジー定義が API ペイロードに集約されるため、DescribeCluster 1 回で構成を把握できます。SlurmConfigStrategy: Managed を使えばドリフトも自動検出できます。S3 ファイルを書き換えて Lifecycle Script を再実行する従来の往復がなくなり、構成変更のコストが下がります。
Continuous provisioning と組み合わせる場合は SlurmConfigStrategy の指定そのものが不可で、内部的に Merge 相当で動作する点に注意が必要です。
参考
- Amazon SageMaker HyperPod で API 主導型 Slurm 設定のサポートを開始
- Getting started with SageMaker HyperPod using the AWS CLI - Amazon SageMaker AI
- CreateCluster - Amazon SageMaker
- ClusterOrchestratorSlurmConfig - Amazon SageMaker
- SageMaker HyperPod references - Amazon SageMaker AI
- Continuous provisioning for enhanced cluster operations with Slurm - Amazon SageMaker AI
- base-config at main · aws-samples/awsome-distributed-training








