![[Amazon SageMaker] 2026年版 SageMakerでCartPoleをやってみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[Amazon SageMaker] 2026年版 SageMakerでCartPoleをやってみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
Amazon SageMaker AI での CartPole(倒立振子課題)ということで、ここ DevelopersIO では、2018年に以下の記事が公開されています。
Amazon SageMaker RLでCartPole(倒立振子)を強化学習してみる
Intel Coach + MXNet + SageMaker RL Toolkit で学習からエンドポイント推論まで一気通貫に再現した、すばらしい記事です。
しかし、8年が経過した今、こちらの記事で勉強させて頂いていた所、当時の中核コンポーネントの多くがメンテナンスを終えているか別エコシステムに置き換わっていることに気づきました。
いずれも 2018 年当時は最先端のスタックでしたが、技術エコシステムの変化により、現在は次の表のような状態になっています。
| 役割 | 2018年 | 2026年の状態 | 現在の主流 |
|---|---|---|---|
| RLライブラリ | Intel Coach | 開発終了 | Stable-Baselines3 / Ray RLlib |
| DLフレームワーク | Apache MXNet | Apache Attic 移管(=終息) | PyTorch |
| RL専用SDK | RLEstimator / RLToolkit | Ray 1.6.0 で更新停止 | 標準 PyTorch Estimator + Script Mode |
| 環境ライブラリ (Gym) | OpenAI Gym | 2020年末メンテ終了、Farama Foundation にフォーク | Gymnasium (CartPole-v1) |
同じ内容で恐縮なのですが、今回は「2026年版」と位置づけ、PyTorch エコシステムで組み立てられた、SageMaker AI での強化学習のはじめの一歩を学習した記録として、紹介させてください。
なお、モデルがどのように学習されていくのかを、学習量の異なる4つのチェックポイントで比較した動画を作成してみました。
学習量がゼロのとき(左上 / Step 0)、ポール(倒立振子)はわずか 95 ステップで倒れてしまいます。8,000 ステップ学習しても 141 ステップで倒れますが、16,000 ステップを越えたあたりで突然「満点(500 ステップ持続)」に到達するのが見て取れます。
サンプルコードは、以下のリポジトリで公開しています。
GitHub: aws-sagemaker-rl-cartpole
2 設計と運用の考え方
本プロジェクトは、Endpoint を使った推論を「ちょっと試したい」という検証用途を前提に組み立てています。学習にかかる費用は学習量に応じて必要な分だけ発生するコストとして受け入れる前提ですが、推論用の Endpoint は立てっぱなしにすると検証していない時間まで時間課金が続いてしまうため、その「放置による無駄な費用」を削減することを主な狙いとしています。
そのために、以下のような3層構造を取っています。
| 層 | スタック | リソース | コスト | ライフサイクル |
|---|---|---|---|---|
| L1 永続層 | BaseStack | S3 / IAM Role | ≒ 0 | 最初から最後まで |
| L2 メタデータ層 | ModelStack | Model / EndpointConfig | 0 | 学習ごとに更新 |
| L3 実行層 | スクリプト(start/stop_endpoint.py) | Endpoint | 時間課金 | 検証時のみ起動・停止 |
そして、作業手順は、以下のようになります。
| 手順 | 詳細 | コスト | |
|---|---|---|---|
| 1 | cdk deploy | L1(永続層)S3 / Role を構築 | ほぼ無料 |
| 2 | launch_training.py | Training Job で PPO を学習(5 分程度) | 学習にかかった時間のみ(数円) |
| 3 | cdk deploy ModelStack -c model_data_url=<URI> | L2(メタデータ層)Model / EndpointConfig を登録 | 無料 |
| 4 | start_endpoint.py | L3(実行層)Endpoint 起動 | 時間課金開始(約 $0.149/h、東京) |
| 5 | invoke_endpoint.py | 推論で動作確認(CartPole-v1 × 5 エピソード) | 時間課金継続 |
| 6 | stop_endpoint.py | L3(実行層)Endpoint を削除 | 時間課金停止 |
| 7 | cdk destroy --all -c model_data_url=placeholder | L1, L2 を削除 |
学習は 2 と 3 で必要分のみ、推論は 4〜6 のサイクルを繰り返すことで、Endpoint が必要な時だけ動いている状態を保てる、という構成です。
3 作業手順
下記が、本記事の作業の流れです。コマンドの詳細は README.ja.md を参照してください。
(1) cdk deploy(L1 永続層)
S3 バケットと SageMaker 実行ロールを作成します。永続層なので、最初に1回だけ実行します。
cd cdk
pnpm exec cdk bootstrap # 初回のみ
pnpm exec cdk deploy AwsSagemakerRlCartpoleBaseStack
cd ..
出力された ArtifactsBucketName と SageMakerExecutionRoleArn を控えます。

(2) launch_training.py(学習)
SageMaker Training Job(PyTorch DLC + Script Mode)で PPO を学習します。ml.m5.large(CPU)で約 4 分、課金は数円程度です。
python scripts/launch_training.py \
--role-arn <SageMakerExecutionRoleArn> \
--bucket <ArtifactsBucketName>
完了時に表示される Model artifact S3 URI(例: s3://.../model.tar.gz)を控えます。

- S3に保存されたモデル

- Training & training jobs
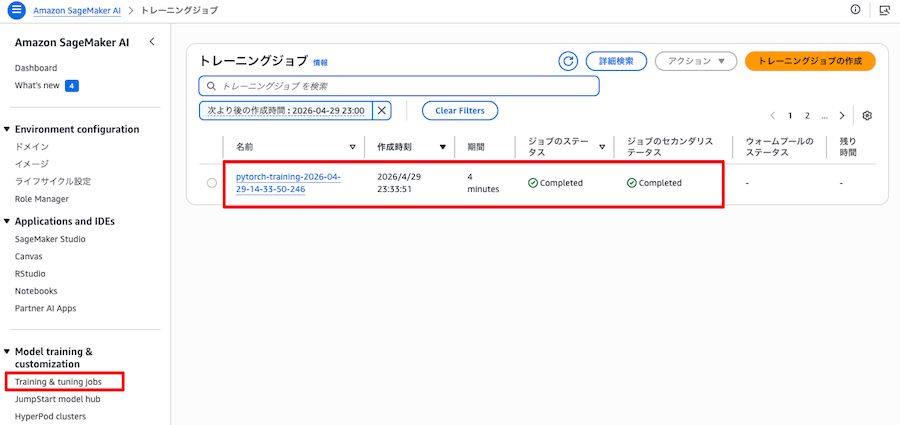
(3) cdk deploy ModelStack(L2 メタデータ層)
学習済み model.tar.gz を指す Model リソースと EndpointConfig を登録します。どちらもメタデータのみで無料です。
cd cdk
pnpm exec cdk deploy AwsSagemakerRlCartpoleModelStack \
-c model_data_url=<Model artifact S3 URI>
cd ..
出力された CartPoleEndpointConfigName を控えます。

- Deployments & inference / エンドポイント設定 から確認できます
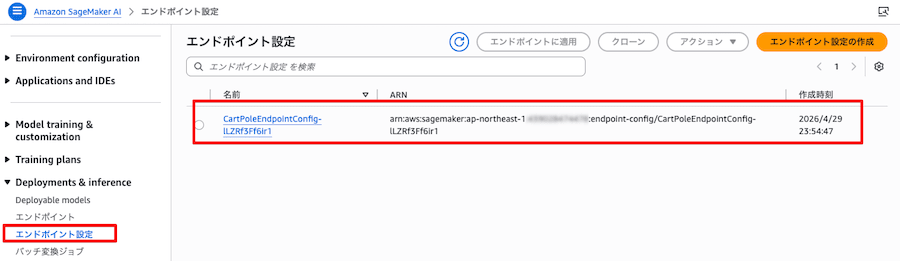
(4) start_endpoint.py(L3 Endpoint 起動)
ここから時間課金(東京リージョンで約 $0.149/時)が始まります。起動には 4〜6 分ほどかかります。
python scripts/start_endpoint.py \
--endpoint-config-name <CartPoleEndpointConfigName>
Endpoint 名はデフォルトで cartpole-endpoint です(--endpoint-name で上書き可)。
- Deployments & inference / エンドポイント から確認できます
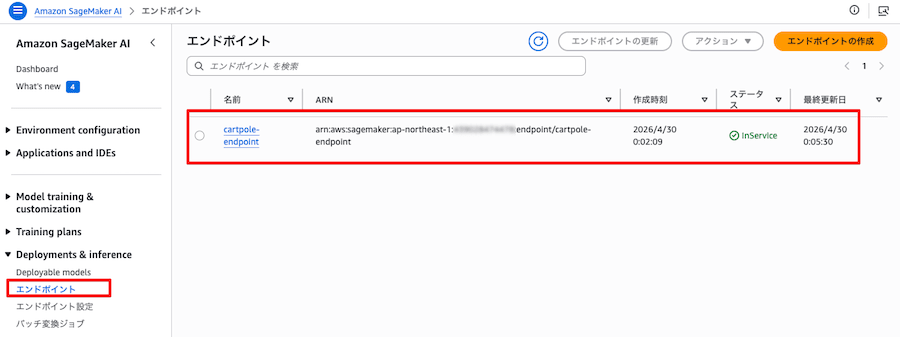
(5) invoke_endpoint.py(推論で動作確認)
CartPole-v1 環境で 5 エピソード(5種類の初期状態)を実行し、各エピソードの steps / reward を表示します。
python scripts/invoke_endpoint.py --endpoint-name cartpole-endpoint
学習が十分に進んでいることが、5 エピソード全てで満点(500 ステップの間ポールが倒れずに、毎ステップ +1 の報酬を得ている)であることから分かります。

(6) stop_endpoint.py(L3 Endpoint 停止)
時間課金を止めます。Model と EndpointConfig は残ったままなので、再度 (4) を実行すれば即座に再起動することができます。((4)〜(6) は何度でも繰り返せます)
python scripts/stop_endpoint.py --endpoint-name cartpole-endpoint
(7) cdk destroy(完全クリーンアップ)
検証が終わったら、L1 / L2 を含めて丸ごと削除します。
cd cdk
pnpm exec cdk destroy --all -c model_data_url=placeholder
cd ..
4 学習・推論コードと SageMaker DLC
(1) SageMaker DLC(Deep Learning Containers)について
DLC(Deep Learning Containers)は、AWS が公式に管理している、機械学習フレームワークがプリインストール済みの Docker イメージです。AWS 公式の ECR アカウント 763104351884 から配布されています。
イメージは、フレームワーク × バージョン × Python × OS × CPU/GPU × Training/Inference の組み合わせで多数バリエーションが用意されています。例えば、本記事で使っている推論用 DLC のフルパスは次のようになります。
763104351884.dkr.ecr.ap-northeast-1.amazonaws.com/pytorch-inference:2.1.0-cpu-py310-ubuntu20.04-sagemaker
本プロジェクトで使用している DLC は以下の 2 つです。
| 用途 | DLC イメージ |
|---|---|
| 学習 | pytorch-training 2.1.0 / Python 3.10 / Ubuntu 20.04 / CPU |
| 推論 | pytorch-inference 2.1.0 / Python 3.10 / Ubuntu 20.04 / CPU |
DLC を使用することで、PyTorch・CUDA・cuDNN といった依存が整備された、再現性の高い実行環境がすぐに利用可能になります。
(2) Script Mode の仕組み
Script Mode は、DLC の上で 自分の Python コードを動かす SageMaker AI の基本方式です。Dockerfile を書いたりコンテナをビルドしたりすることなく、ローカルの Python ファイルだけを用意すれば、SageMaker AI が DLC への配布と実行を肩代わりしてくれます。
本記事のコードと DLC の対応
| ローカル側のファイル | DLC コンテナ内での扱い |
|---|---|
scripts/launch_training.py |
ローカルから SageMaker SDK 経由で Training Job を起動する |
training/train.py |
学習用 DLC で entry_point として実行される |
training/inference.py |
学習時にモデルと同梱され、推論用 DLC のエントリポイントとして呼ばれる |
training/requirements.txt |
DLC 起動時に自動で pip install される |
学習時の動作
- ローカルの
launch_training.pyが SageMaker SDK 経由で Training Job を起動 - SDK が
source_dir(training/)を S3 にアップロードし、学習用 DLC が取得 - 学習用 DLC が
/opt/ml/code/train.pyを実行 train.pyが/opt/ml/model/配下にモデルとcode/(推論用コード)を保存- ジョブ終了時、SageMaker AI が
/opt/ml/model/配下をmodel.tar.gzにまとめて S3 へアップロード
学習中の DLC コンテナ内のディレクトリ構造は、以下のようになっています。
/opt/ml/
├── code/ # S3 から展開された source_dir(本プロジェクトでは training/)
│ ├── train.py # entry_point として実行されるスクリプト
│ ├── inference.py
│ └── requirements.txt
├── input/
│ ├── config/
│ │ ├── hyperparameters.json # launch_training.py の hyperparameters がここに書かれ、CLI引数に変換される
│ │ └── resourceconfig.json # 分散学習用のクラスタ情報(本プロジェクトでは未使用)
│ └── data/ # 入力データ(チャネル毎、本プロジェクトでは未使用)
├── model/ # 学習成果物の出力先(→ S3 に model.tar.gz 化)
└── output/ # 失敗時のエラー出力
推論時の動作
start_endpoint.pyが Endpoint を起動すると、推論用 DLC が S3 からmodel.tar.gzをダウンロード/opt/ml/model/に展開し、code/requirements.txtをpip installcode/inference.pyをエントリポイントとして、起動時に 1 回model_fn()を呼びモデルをロード- 以降のリクエストごとに
input_fn → predict_fn → output_fnのパイプラインで処理
推論中の DLC コンテナ内のディレクトリ構造は、以下のようになっています(学習時と異なり、/opt/ml/model/ のみが使われます)。
/opt/ml/
└── model/ # S3 から取得した model.tar.gz が展開される
├── cartpole_ppo.zip # 最終モデル(model_fn() がロード)
├── checkpoints/ # 学習中チェックポイント(推論時は使われない)
│ ├── cartpole_ppo_0_steps.zip
│ ├── cartpole_ppo_10000_steps.zip
│ ├── cartpole_ppo_20000_steps.zip
│ └── cartpole_ppo_30000_steps.zip
└── code/ # SAGEMAKER_SUBMIT_DIRECTORY が指す場所
├── inference.py # SAGEMAKER_PROGRAM が指すエントリポイント
└── requirements.txt # 起動時に pip install される
(3) 学習スクリプト training/train.py
学習スクリプトは、以下のような流れになっています。
gym.make("CartPole-v1")で環境を作成PPO("MlpPolicy", env)で PPO モデルを構築(Stable-Baselines3)- 学習前(0 step)の状態を保存(比較動画のベースライン用)
CheckpointCallbackでtotal_timesteps/3ごとにチェックポイントを保存model.learn(total_timesteps)で学習を実行- 最終モデルを
cartpole_ppo.zipとして保存 inference.pyとrequirements.txtを/opt/ml/model/code/にコピー
7 番目のコピー処理がポイントです。SageMaker AI は /opt/ml/model/ 配下を model.tar.gz に固めて S3 にアップロードするため、ここに code/ を置いておけば、後の推論コンテナがそのコードをそのまま使用することができます。
GitHub のコードは、学習開始前(0 step)と学習中(CheckpointCallback)に複数のチェックポイントを保存することで、冒頭でご紹介した比較動画を作成しています。一方、チェックポイント保存が不要な場合(最終モデルだけあればよい場合)は、以下のような最小構成で十分です。
# チェックポイント保存なしの最小例
training_env = gym.make("CartPole-v1")
ppo_model = PPO("MlpPolicy", training_env, verbose=1)
ppo_model.learn(total_timesteps=args.total_timesteps)
ppo_model.save(model_output_dir / "cartpole_ppo.zip")
shutil.copy(source_dir / "inference.py", inference_code_dir / "inference.py")
(4) 推論ハンドラー training/inference.py
推論側は、SageMaker PyTorch DLC が呼び出す 4 関数の規約に従って実装します。
| 関数 | 呼ばれるタイミング | 役割 |
|---|---|---|
model_fn(model_dir) |
Endpoint 起動時に 1 回 | cartpole_ppo.zip を PPO.load() |
input_fn(body, content_type) |
リクエストごと | JSON → numpy 配列 |
predict_fn(obs, model) |
リクエストごと | model.predict(observation, deterministic=True) |
output_fn(prediction, accept) |
リクエストごと | dict → JSON |
リクエストとレスポンスは、いずれも JSON 形式です。
// リクエスト
{ "observation": [0.012, -0.034, 0.001, 0.058] }
// レスポンス
{ "action": 1 }
(5) model.tar.gz の構造
launch_training.py で起動した Training Job が完了すると、S3 に以下のような構造で model.tar.gz がアップロードされます。
model.tar.gz
├── cartpole_ppo.zip # 最終モデル
├── checkpoints/
│ ├── cartpole_ppo_0_steps.zip # 学習前(比較動画用ベースライン)
│ ├── cartpole_ppo_10000_steps.zip
│ ├── cartpole_ppo_20000_steps.zip
│ └── cartpole_ppo_30000_steps.zip
└── code/
├── inference.py
└── requirements.txt
ModelStack(CDK)では、推論コンテナに SAGEMAKER_PROGRAM=inference.py と SAGEMAKER_SUBMIT_DIRECTORY=/opt/ml/model/code の 2 つの環境変数を渡すことで、Endpoint 起動時に DLC が code/inference.py をエントリポイントとして認識します。
5 スクリプトの詳細
(1) launch_training.py
GitHub: scripts/launch_training.py
SageMaker Training Job を起動し、training/train.py を PyTorch DLC 上で実行します。sagemaker.pytorch.PyTorch Estimator を使用した Script Mode の典型的な構成で、ローカル PC からの実行のみで完結します。
| 引数 | 用途 |
|---|---|
--role-arn |
SageMaker 実行ロール ARN(BaseStack の出力) |
--bucket |
成果物 S3 バケット名(BaseStack の出力) |
--total-timesteps |
学習ステップ数(デフォルト 30,000) |
--instance-type |
学習インスタンス(デフォルト ml.m5.large) |
fit(wait=True) で Training Job の完了まで同期待機し、最後に Model artifact S3 URI を標準出力に表示します。
DLC イメージの URI は直接指定していませんが、sagemaker.pytorch.PyTorch クラスが framework_version="2.1" / py_version="py310" / instance_type の組み合わせから内部の image_uris.retrieve() を呼び出し、自動的に解決してくれます。実際に解決された URI は、SageMaker AI コンソールのトレーニングジョブ詳細画面、TrainingImage 欄で確認することができます。
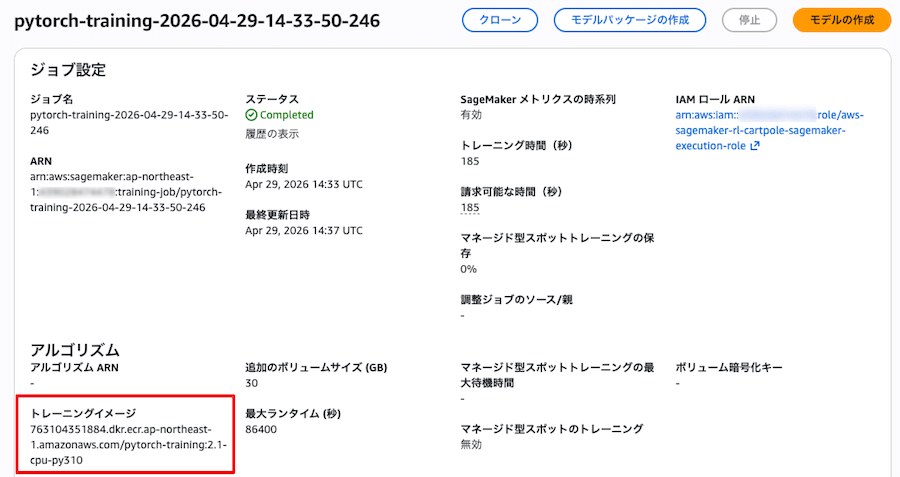
(2) start_endpoint.py
GitHub: scripts/start_endpoint.py
EndpointConfig(ModelStack で登録済み)から Endpoint を起動します。boto3 の create_endpoint API を直接呼び、endpoint_in_service Waiter で InService になるまで待機します(通常 4〜6 分)。
同名の Endpoint がすでに存在する場合は再利用するため、冪等に呼び出すことができます。完了時には BILLING STARTED のメッセージが出力され、ここから時間課金が始まることが明示されます。
(3) invoke_endpoint.py
GitHub: scripts/invoke_endpoint.py
CartPole-v1 環境をローカルで動かし、各 step ごとに観測値を Endpoint に POST して行動を受け取り、エピソードを進行させます。デフォルトで 5 エピソード(seed=0..4)を実行し、各エピソードの steps と reward を出力します。
# 要点抜粋
def query_action(runtime_client, endpoint_name, observation):
response = runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/json",
Body=json.dumps({"observation": observation.tolist()}),
)
prediction = json.loads(response["Body"].read().decode("utf-8"))
return int(prediction["action"])
(4) stop_endpoint.py
GitHub: scripts/stop_endpoint.py
Endpoint を削除して時間課金を止めます。boto3 の delete_endpoint API を呼び、endpoint_deleted Waiter で完全削除まで待機します(通常 1〜2 分)。
EndpointConfig と Model は残るため、再度 start_endpoint.py を実行すれば即座に再起動することができます。完了時には BILLING STOPPED のメッセージが出力されます。
6 ローカルで済ませる選択肢
本記事では SageMaker AI で学習・推論を行いましたが、CartPole のような小型のモデルであれば、学習も推論もローカルマシン上で完結することができます。
学習をローカルで実行する例
import gymnasium as gym
from stable_baselines3 import PPO
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=30_000) # 約30秒〜1分(CPU)
model.save("cartpole_ppo.zip")
推論をローカルで実行する例
import gymnasium as gym
from stable_baselines3 import PPO
model = PPO.load("cartpole_ppo.zip")
env = gym.make("CartPole-v1")
observation, _ = env.reset(seed=0)
done = False
while not done:
action, _ = model.predict(observation, deterministic=True)
observation, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
env.close()
本稿は、あくまで「SageMaker AI を使用する場合」の例としてご理解ください。
7 record_checkpoints.py(学習過程の動画化)
学習済みの model.tar.gz には、学習途中のチェックポイント(cartpole_ppo_*_steps.zip)も含まれています。scripts/record_checkpoints.py は、これらを順番にロードして 1 エピソードずつ録画し、「学習量に応じてポールがどう倒れにくくなっていくか」を視覚化するスクリプトです。
このステップは Endpoint を使用せずローカルで完結するため、追加の課金はゼロです。
python scripts/record_checkpoints.py \
--model-data-url <Model artifact S3 URI>
出力: ./videos/checkpoints/cp_000000-episode-0.mp4 〜 cp_NNNNNN-episode-0.mp4(チェックポイント数分)。
冒頭でご紹介した比較動画(YouTube)は、ここで生成された 4 本を 2x2 グリッドに合成したものです。

8 最後に
PyTorch + Stable-Baselines3 + SageMaker Script Mode という構成で、CartPole の学習から推論まで一気通貫に動かしてみました。PyTorchエコシステムとの組み合わせにおける SageMaker AI の柔軟さを改めて感じる検証となりました。
なお、SageMaker による「学習 → デプロイ → 推論 → 削除」というワークフローの考え方や、estimator.deploy() / predictor.predict() / predictor.delete_endpoint() といった API そのものは、長く変わらない普遍的なものです。一方で、その内側で使うフレームワークやライブラリは時代とともに入れ替わっていくようであり、本記事が、「現時点で動く最小例」となれるかも知れません。
特に、
- DLC(Deep Learning Containers)のおかげで Docker の面倒を一切見なくて済むこと
- CDK でメタデータ層(Model / EndpointConfig)まで宣言的に書ける一方、Endpoint だけはスクリプトで起停させて時間課金を完全にコントロールできること
- Script Mode により、
train.pyとinference.pyという素朴な Python ファイルだけで学習から推論まで通じること
の 3 点は、強化学習に限らず、SageMaker AI で何かを動かす時の基本パターンとして応用が効くのではないかと思います。
CartPole は小さなタスクですが、こうした「最小例」を手元に置いておく事で、別のモデルを SageMaker AI に載せる際の足がかりになりそうです。
9 参考リンク
- GitHub: aws-sagemaker-rl-cartpole - 本記事のサンプルコード
- Amazon SageMaker RLでCartPole(倒立振子)を強化学習してみる - 2018年版の元記事
- Gymnasium Documentation - Cart Pole
- Stable-Baselines3 Documentation
- [AWS Deep Learning Containers Images(ap-northeast-1)]









