
Snowflake と Glue Data Catalog をカタログ統合し自動リフレッシュの動作を確認する
とーかみです。
Snowflake の Iceberg テーブルはテーブルメタデータの自動リフレッシュ機能があります。
カタログ統合を Glue Data Catalog に対して設定し、メタデータの自動リフレッシュ機能を有効にする方法と動作を確認しました。
条件
- Snowflake と Glue Data Catalog のカタログ統合を構成する
- Glue Data Catalog で管理される Iceberg テーブルを Snowflake から参照する
- Iceberg テーブルのストレージは S3 を使用する
- Snowflake 側でメタデータの自動リフレッシュ機能を有効にする
設定手順
以下の流れで設定します。
- Glue Data Catalog に検証用 Iceberg テーブルを作成
- カタログ統合を作成
- 外部ボリュームを作成
- Snowflake で Iceberg テーブルを作成
- Snowflake の Iceberg テーブルで自動リフレッシュを有効化
Glue Data Catalog に検証用 Iceberg テーブルを作成
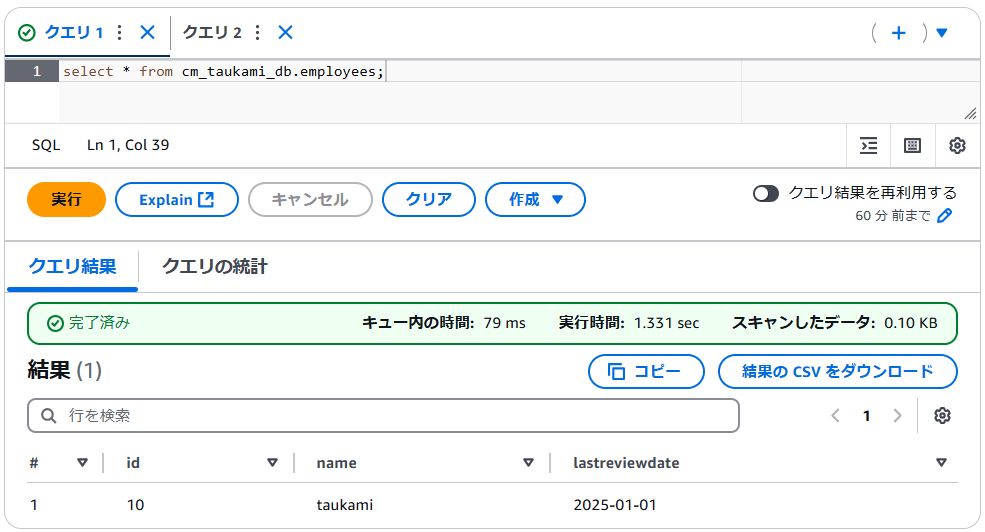
Athena から以下のクエリをして検証用の Iceberg テーブルを作成し、ダミーレコードを追加します。
Glue Data Catalog のデータベースと S3 バケットは事前に作成しておきます。
CREATE TABLE `<your_database>`.`employees`(
ID INT,
Name STRING,
LastReviewDate STRING
)
LOCATION
's3://<your_bucket>/tables/iceberg/employees/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet',
'write_compression'='snappy'
);
INSERT INTO <your_database>.employees
VALUES (10 , 'taukami', '2025-01-01');
SELECT * FROM <your_database>.employees;
カタログ統合を作成
Snowflake で以下のクエリを実行し、カタログ統合を作成します。
接続に使用する IAM ロールは後で作成する方が操作が少なくできます。
ロール名を先に決めて ARN として指定します。
IAM ロールの ARN の形式は arn:aws:iam::<AWS Account ID>:role/<ロール名> です。
CREATE OR REPLACE CATALOG INTEGRATION
my_catalog_integration
CATALOG_SOURCE = GLUE
TABLE_FORMAT = ICEBERG
GLUE_AWS_ROLE_ARN = '<IAM Role ARN>' -- Glue Data Catalog を取得する際の IAM ロール
GLUE_CATALOG_ID = '<AWS Account ID>' -- Glue Data Catalog を管理する AWS アカウント ID
GLUE_REGION = 'ap-northeast-1' -- Glue Data Catalog の AWS リージョン
CATALOG_NAMESPACE = '<glue_data_catalog_database>' -- Glue Data Catalog のデータベース名
ENABLED = TRUE -- カタログ統合をIcebergテーブルで使用できるか
REFRESH_INTERVAL_SECONDS = 30 -- カタログの自動更新間隔 デフォルト: 30秒
COMMENT = 'glue data catalog integration' -- コメント
;
REFRESH_INTERVAL_SECONDS で自動更新間隔を指定していますが、この指定だけではこの記事の本題のメタデータの自動更新が有効になるわけではありません。後述のテーブル単位の設定が必要になります。
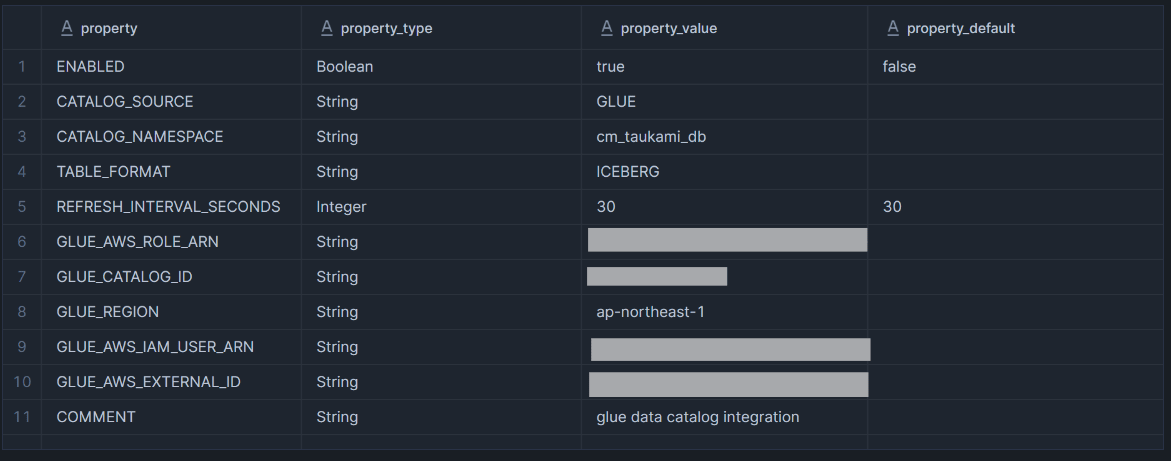
作成したカタログ統合を確認して、 IAM ロールにスイッチロールする Snowflake 側の IAM ユーザーと外部 ID を取得します。
DESCRIBE CATALOG INTEGRATION my_catalog_integration;
クエリ結果の以下の値を使用します。
GLUE_AWS_IAM_USER_ARN : 信頼関係に指定する IAM ユーザー ARN (1)
GLUE_AWS_EXTERNAL_ID : 外部 ID (2)
つづいて AWS で IAM ポリシーと IAM ロールを作成します。
IAM ロールはカタログ統合で指定した ARN になるように作成してください。
IAM ポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowGlueCatalogTableAccess",
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:GetTables"
],
"Resource": [
"arn:aws:glue:*:<AWS Account ID>:table/*/*",
"arn:aws:glue:*:<AWS Account ID>:catalog",
"arn:aws:glue:*:<AWS Account ID>:database/<glue_data_catalog_database>"
]
}
]
}
IAM ロール 信頼関係
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<信頼関係に指定する IAM ユーザー ARN (1)>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<外部 ID (2)>"
}
}
}
]
}
外部ボリュームを作成
Iceberg テーブルのストレージとして使用するため、外部ボリュームを作成します。
Snowflake で以下のクエリを実行し、外部ボリュームを作成します。
CREATE OR REPLACE EXTERNAL VOLUME iceberg_external_volume
STORAGE_LOCATIONS =
(
(
NAME = 'my-s3'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://<your_bucket>'
STORAGE_AWS_ROLE_ARN = '<IAM Role ARN>'
STORAGE_AWS_EXTERNAL_ID = '<External Id>' -- 省略した場合は自動生成されます
)
)
ALLOW_WRITES = false
;
作成した外部ボリュームを確認して、 IAM ロールにスイッチロールする Snowflake 側の IAM ユーザーと外部 ID を取得します。
クエリ結果の以下の値を使用します。
GLUE_AWS_IAM_USER_ARN : 信頼関係に指定する IAM ユーザー ARN (1)
GLUE_AWS_EXTERNAL_ID : 外部 ID (2)
DESC EXTERNAL VOLUME iceberg_external_volume;

クエリ結果の中の property = 'STORAGE_LOCATION_1' のレコードの property_value の値に入っている JSON から以下の値を使用します。
STORAGE_AWS_IAM_USER_ARN : 信頼関係に指定する IAM ユーザー ARN (1)
STORAGE_AWS_EXTERNAL_ID : 外部 ID (2)
JSON は以下のような内容です。
{
"NAME": "my-s3",
"STORAGE_PROVIDER": "S3",
"STORAGE_BASE_URL": "s3://<your_bucket>",
"STORAGE_ALLOWED_LOCATIONS": ["s3://<your_bucket>/*"],
"STORAGE_REGION": "ap-northeast-1",
"STORAGE_AWS_ROLE_ARN": "<My IAM Role ARN>",
"STORAGE_AWS_IAM_USER_ARN": "<Snowflake IAM User ARN>",
"STORAGE_AWS_EXTERNAL_ID": "<External ID>",
"ENCRYPTION_TYPE": "NONE",
"ENCRYPTION_KMS_KEY_ID": ""
}
次のクエリを実行すると、外部ボリュームにアクセスできるのかをテストすることができます。
SELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('iceberg_external_volume');
結果は JSON 形式の値として取得でき、 "success":true のような結果が含まれます。
Snowflake で Iceberg テーブルを作成
Snowflake で以下のクエリを実行し、 Glue Data Catalog 上のテーブルを参照する形で Iceberg テーブルを作成します。
CREATE ICEBERG TABLE sample_db.sample_schema.myGlueTable -- Snowflake から参照する際のテーブル名
EXTERNAL_VOLUME='iceberg_external_volume' -- 使用する外部ボリューム
CATALOG='my_catalog_integration' -- 使用するカタログ(Glue Data Catalog とのカタログ統合)
CATALOG_TABLE_NAME='employees'; -- Glue Data Catalog 上のテーブル名
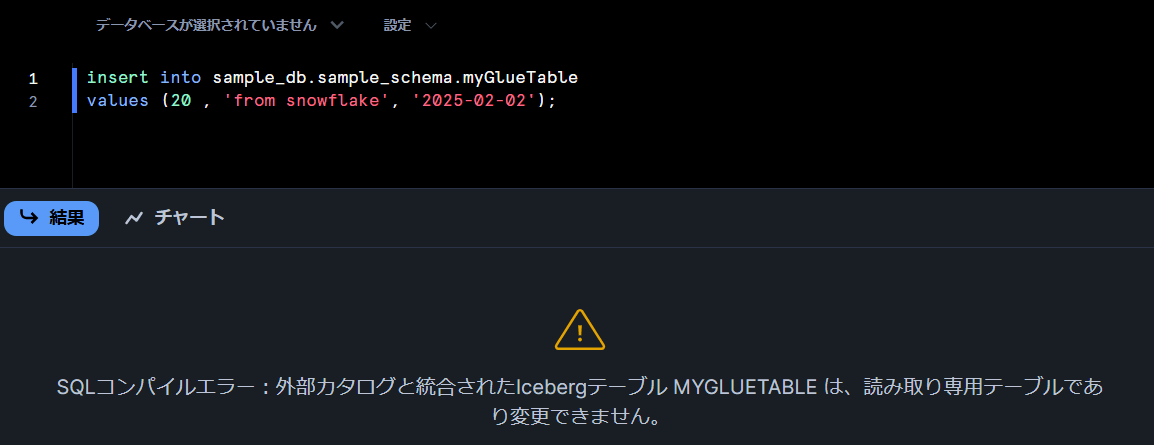
SELECT すると Athena から見たときと同じレコードが参照できます。

INSERT しようとすると読み取り専用テーブルである旨がエラーとして返ってきます。
Snowflake の Iceberg テーブルで自動リフレッシュを有効化
自動リフレッシュの有効化は AUTO_REFRESH オプションで指定できます。
ALTER ICEBERG TABLE myGlueTable SET AUTO_REFRESH = TRUE;
-- ALTER ICEBERG TABLE myGlueTable SET AUTO_REFRESH = FALSE;
自動リフレッシュが無効の状態では、次のクエリにより手動リフレッシュができます。
ALTER ICEBERG TABLE myGlueTable REFRESH;
動作確認のために Athena 側でカラムを追加します。
ALTER TABLE <your_database>.employees ADD COLUMNS (additional_col string);
ついでに別のテーブルも作成しておきます。
CREATE TABLE `<your_database>`.`employees2`(
ID INT,
Name STRING,
LastReviewDate STRING
)
LOCATION
's3://<your_bucket>/tables/iceberg/employees2/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet',
'write_compression'='snappy'
);
この状態で自動リフレッシュ処理が走るまでしばらく待ちます。
リフレッシュ処理が走った後に SELECT するとカラムが追加されていることが確認できます。
(検証していた中でしばらく待っても反映されない場合があったのですが Athena 側でレコードを追加すると反映されたのでどこかのキャッシュで引っかかっているケースもありそうです)

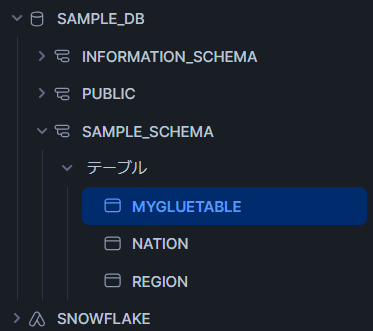
テーブルは明示的に追加しない限り Snowflake からは参照できないようです。
自動リフレッシュの費用
自動リフレッシュ機能は、 Snowflake から外部カタログに対してポーリングする形になるため費用に注意が必要です。
ドキュメントには以下のように記載されています。
Snowpipe と同じ動きになるかどうかはストレージおよびカタログの構成パターンによって変わるはずですが、請求項目としては Snowpipe と同じになるようです。
請求
SnowflakeはSnowpipeを使用してIcebergテーブルのリフレッシュを自動化するため、自動リフレッシュの料金はSnowpipeの料金と同じ項目で請求書に表示されます。この機能にSnowpipeのファイル料金はかかりません。
Account Usage PIPE_USAGE_HISTORY ビュー を調べることで、発生した料金を見積もることができます。自動リフレッシュパイプは、 NULL パイプ名の下にリストされます。
Icebergテーブルの料金に関する詳細は、 Icebergテーブルの請求 を参照してください。
まとめ
カタログ統合と外部ボリュームを設定し、 AWS 側で S3 と Glue Data Catalog で管理している Iceberg テーブルを Snowflake から参照できるように設定し、メタデータの自動リフレッシュ機能を検証しました。
設定済みのテーブルのメタデータの更新は自動化できることがわかりました。
この記事の執筆時点では、目立つ事例も少なく、ベストプラクティスと呼べるほどの構成はないようです。
Snowflake の Iceberg 周りの機能もまだまだ発展途上の状態なので、今後のアップデートに期待しつつ、どのように使えるかを検討していきたいと思います。
補足
Snowflake の Iceberg テーブルは、「カタログ情報をどこに持つか」、「データのストレージをどこにするか」によりいくつかのパターンで設定できます。
設定パターンが変わると設定内容やできることが変わるので注意が必要です。
例えば、 Glue Data Catalog のような Snowflake の外部でデータカタログを管理する場合、 Write はできず Read のみのアクセスになります。










