カラムの数や構成がバラバラのファイルを1つのSnowflakeテーブルにロードしてみた
データ事業本部のsutoです。
1つのテーブルに複数のシステムから連携されたデータソースファイルを取り込む際に、微妙にカラムの数が異なっていたり、カラムの順序が違っているケースがあります。
本来ならばデータソースファイルのカラム構成は作成したテーブルのテーブル定義にマッチしていなければなりませんが、事前のファイル加工が難しい場合や、カラム構成の変更が発生し得る場合、SnowflakeのCOPYオプションである「MATCH_BY_COLUMN_NAME」を有効に利用できるかと思います。
今回はカラム構成の異なる複数のファイルから、必要なカラムのみで作成したテーブルにデータをロードしてみました。
やってみた
データ準備
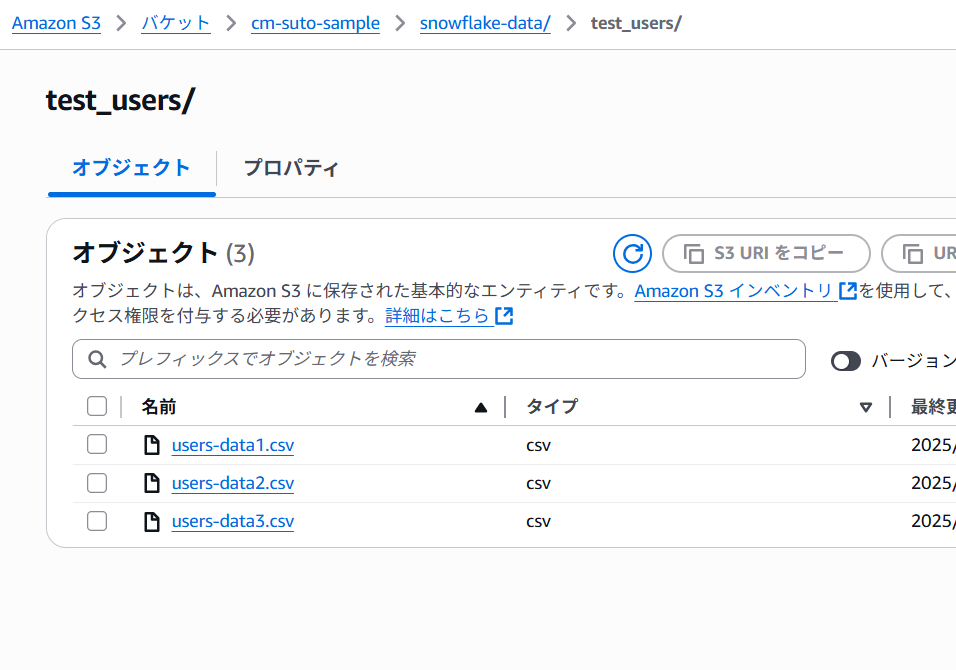
今回取り込むデータファイルは以下のcsvファイルです。こちらをAWS S3バケットに置きます。
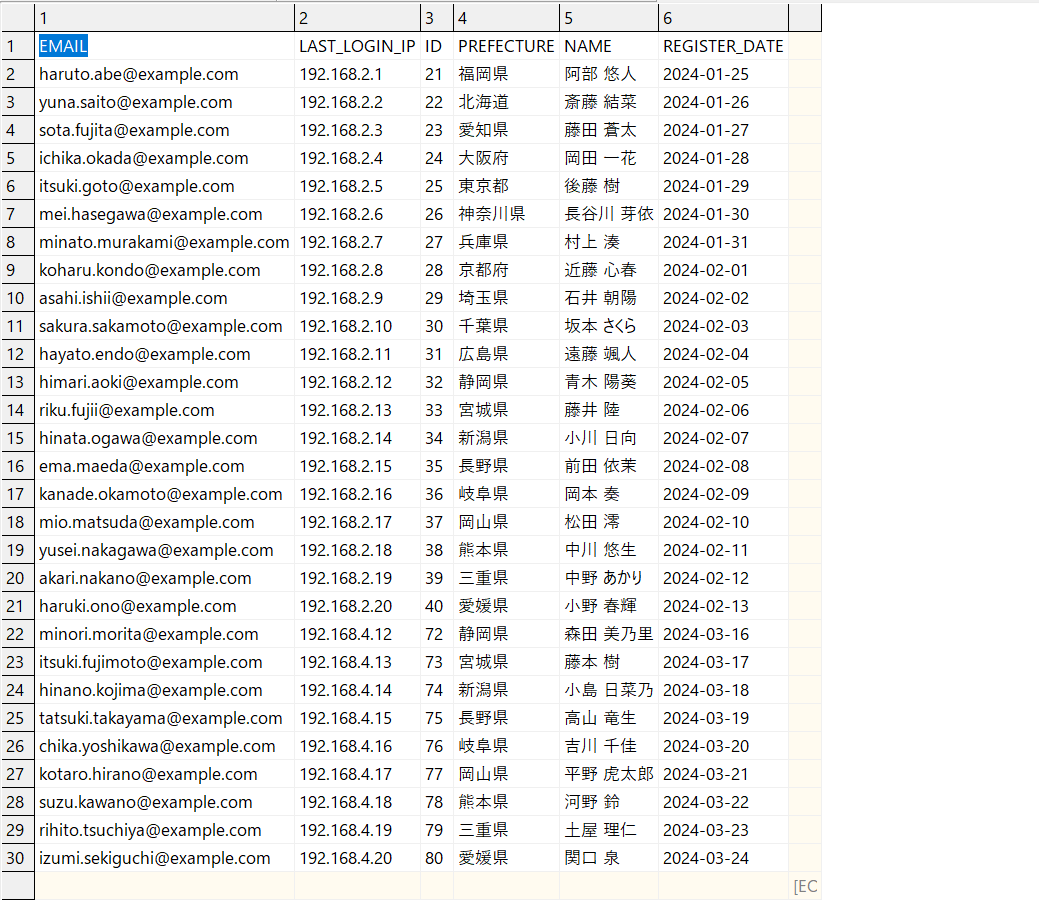
※ファイルデータはダミーデータです。微妙にカラムの数や順序を変えています。
users-data1.csv
users-data2.csv
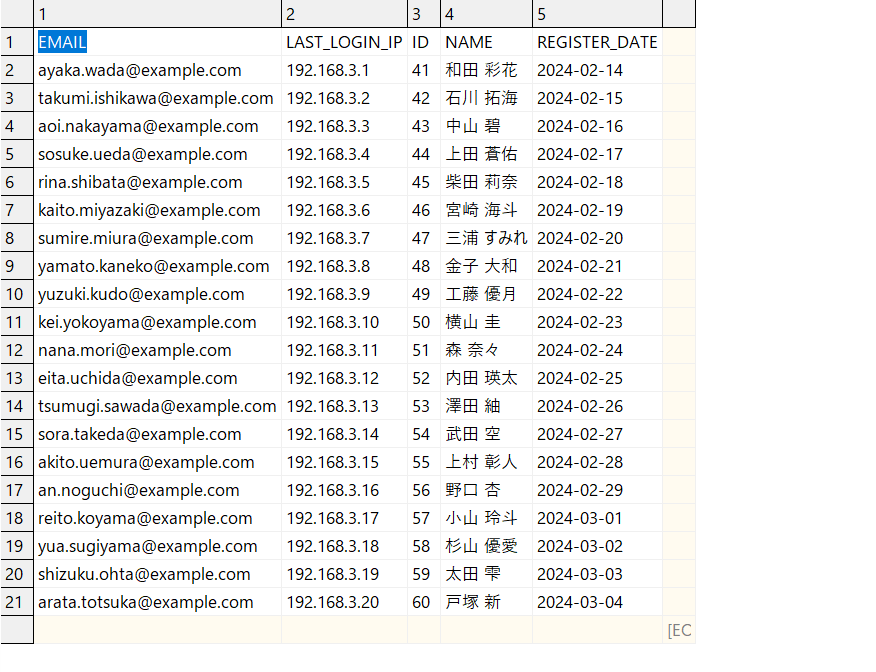
users-data3.csv
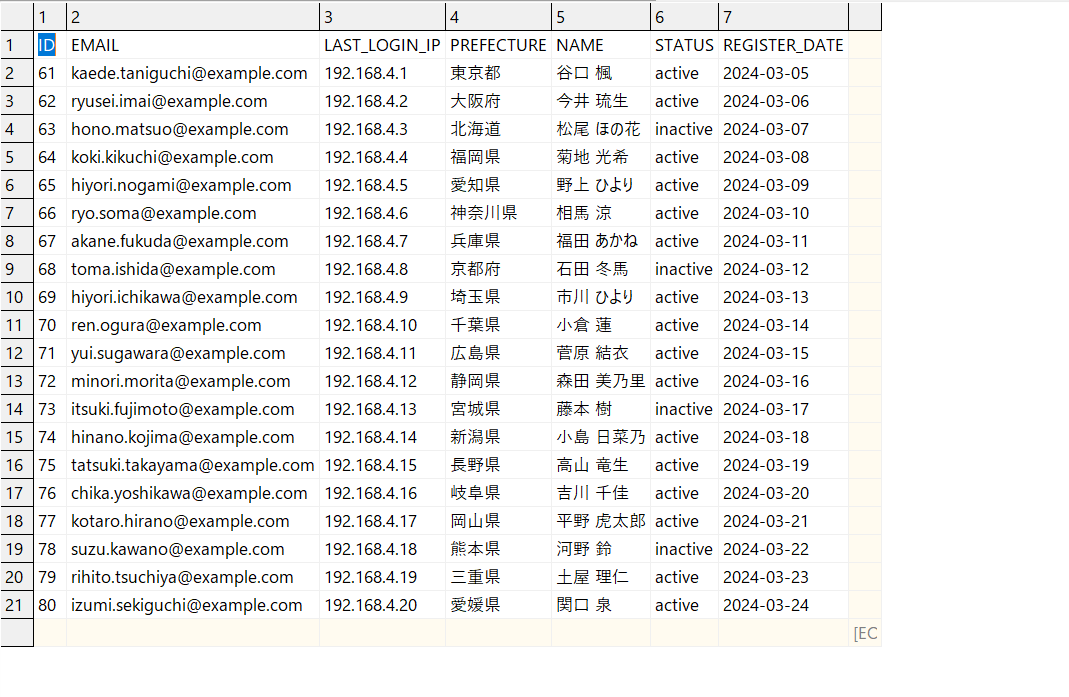
Snowflake側の準備
※今回はスキーマまでは事前作成しています。スキーマ「TEST_DBT」配下で操作を行っていきます。
まずファイルフォーマットと外部ステージを設定します。今回はSTORAGE INTEGRATIONの作成手順は省略していますので、まだの場合は下記リンクを参考に。
ファイル側のカラム構成とテーブル側のカラム構成が不一致でもロード時にエラーで止まらないように「ERROR_ON_COLUMN_COUNT_MISMATCH=FALSE」をオプションに入れています。
CREATE OR REPLACE FILE FORMAT TEST_DBT.suto_csv_format
TYPE = csv
COMPRESSION = AUTO
RECORD_DELIMITER = '\n'
FIELD_DELIMITER = ','
PARSE_HEADER = TRUE,
DATE_FORMAT = 'YYYY-MM-DD'
TIMESTAMP_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
TRIM_SPACE = TRUE
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
EMPTY_FIELD_AS_NULL = TRUE
ENCODING = UTF8
ERROR_ON_COLUMN_COUNT_MISMATCH=FALSE
;
CREATE STAGE IF NOT EXISTS TEST_DBT.suto_s3_test_stage
STORAGE_INTEGRATION = s3_test_integration
URL = 's3://cm-suto-sample/snowflake-data/'
FILE_FORMAT = suto_csv_format
;
次にターゲットテーブルを作成します。今回は明確に必要なカラムのみを選択して作成しています。
CREATE OR REPLACE TABLE TEST_DBT.test_users (
ID VARCHAR,
EMAIL VARCHAR,
LAST_LOGIN_IP VARCHAR,
REGISTER_DATE DATE
);
【参考】動的にカラム構成を読み取ってテーブル作成
「INFER_SCHEMA」を使うことで、ファイルのうちいずれか1つのカラム構成を動的に読み取ってテーブル作成を行うことができます。
-- INFER_SCHEMAでファイルのスキーマを検出と確認
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION => '@suto_s3_test_stage/test_users/users-main.csv',
FILE_FORMAT => 'suto_csv_format',
IGNORE_CASE => TRUE
)
);
-- 検出したスキーマを元にテーブルを自動作成
CREATE OR REPLACE TABLE test_users
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION => '@suto_s3_test_stage/test_users/users-main.csv',
FILE_FORMAT => 'suto_csv_format',
IGNORE_CASE => TRUE
)
)
);
COPY実行
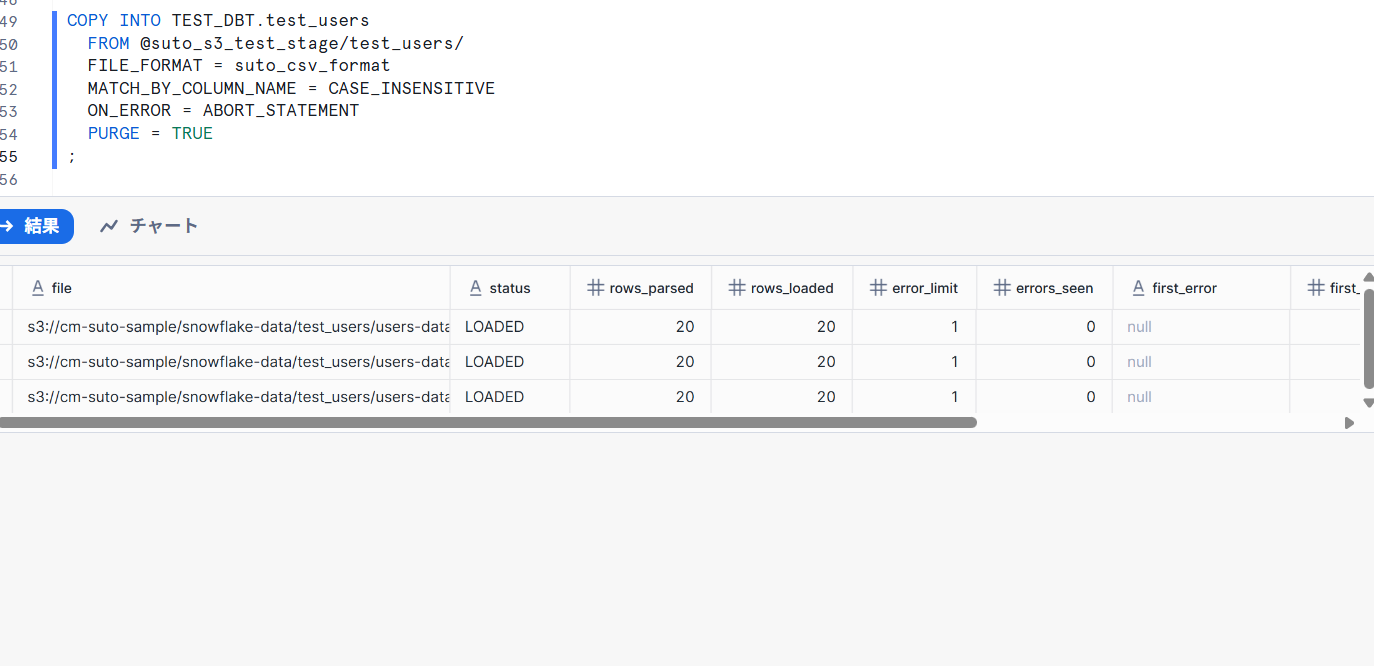
作成されたテーブルに対してCOPY INTOを実行します。
「 MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE 」によってカラムを自動で読み取ってロードします。
今回は大文字と小文字が区別されない CASE_INSENSITIVE を指定しています。
COPY INTO TEST_DBT.test_users
FROM @suto_s3_test_stage/test_users/
FILE_FORMAT = suto_csv_format
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = ABORT_STATEMENT
PURGE = TRUE
;
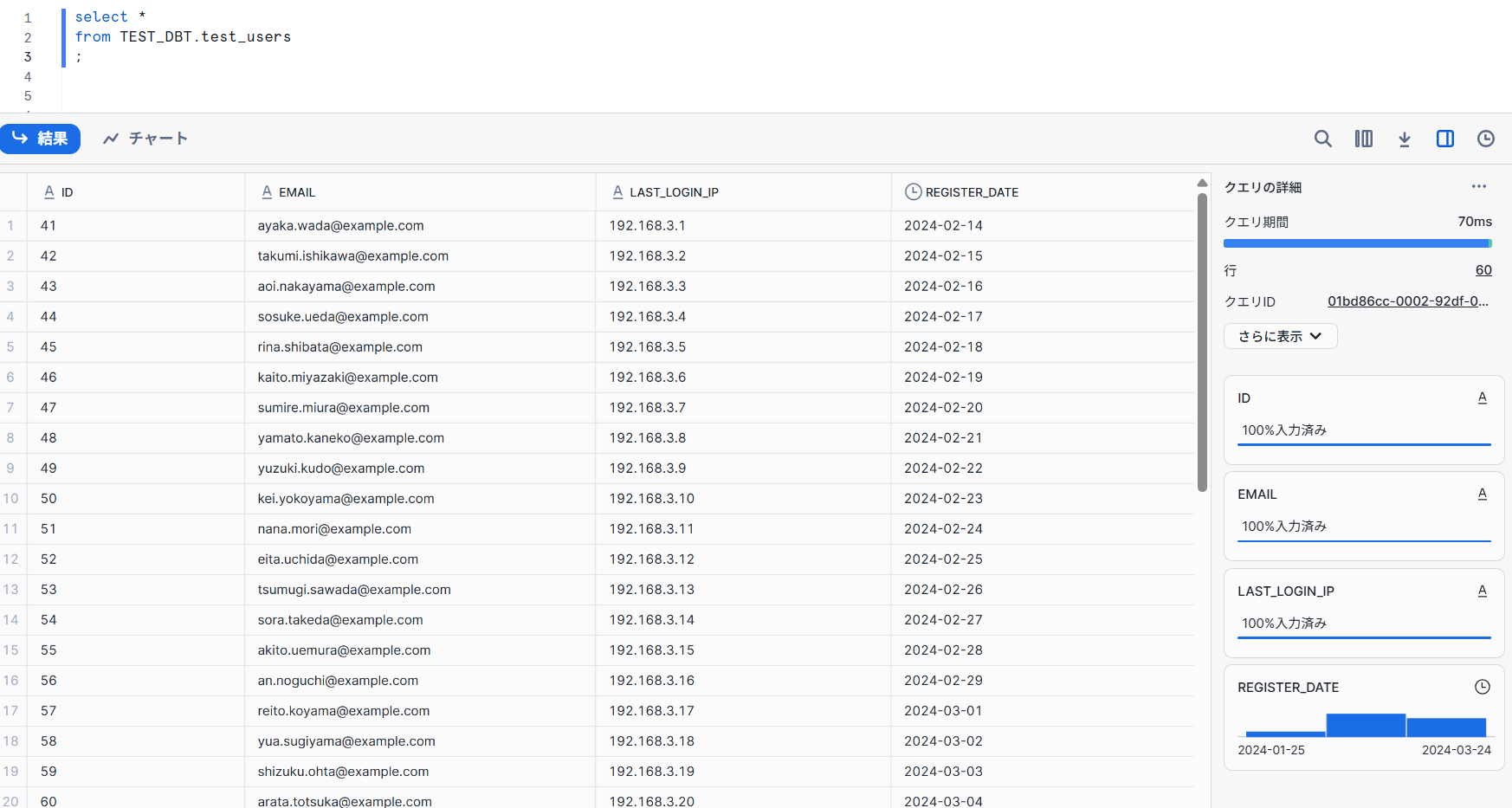
結果、ファイルごとにカラムの数・順序が違っていてもデータロードに成功しました。