
Snowflake Cortex Analyst で生成されるクエリの精度向上のため確認すべきポイントをまとめてみた
こんにちは。データアナリティクス事業本部 サービスソリューション部の北川です。
Snowflake Cortex Analyst を利用する機会があり、その際にセマンティックモデルの設定方法や精度向上のためのポイントを確認しましたので共有します。
Snowflake Cortex Analyst とは
Snowflake Cortex Analyst は、Snowflake が提供する生成 AI を活用した自然言語分析のためのツールです。ユーザーが日本語や英語などの自然言語で質問を投げかけると、セマンティックモデルを基に適切な SQL クエリを自動生成し、データ分析結果を返してくれます。
具体的な使い方については、以下のブログで解説されております。
セマンティックモデルとは
セマンティックモデルは、Cortex Analyst を利用する際に、データベースのテーブルや列に対してビジネス的な意味を付与し、自然言語での問い合わせを可能にする仕組みです。簡単に言うと、テーブル情報やクエリ生成ルールを保持する定義書のような位置付けで、メタデータとして扱われます。
このセマンティックモデルの設定によって、生成されるクエリの精度が大きく変わってきます。
前提:モデルの作成は用途ごとに
まず、セマンティックモデルには以下のような推奨値が設けられています:
- テーブル数:10 個まで
- カラム数:50 個まで
また、Snowflake の公式ドキュメントに「セマンティックモデルを作成するためのヒント」として以下の記載があります:
- エンドユーザーの視点から考える
- トピックに関してユーザーが尋ねる可能性のある主な質問を特定し、それらの質問に答えるために必要な表と列のみを含めます。
上記から分かる通り、様々なユースケースに対応できる万能なセマンティックモデルを 1 つ作るというよりは、分析する範囲を絞って用途ごとにモデルを作成することが推奨されています。
そのため、セマンティックモデルに指定するテーブルは、ある程度整形され、必要なカラムに絞ったマートテーブルを用意するのが良いでしょう。
セマンティックモデルの作成方法
セマンティックモデルの作成方法は大きく 2 つあります。
1. Snowsight で自動作成する方法
Snowsight にはセマンティックモデルジェネレーターという機能があり、画面上で利用するテーブルやカラムを指定するだけで簡単にモデルを作成できます。実データの中身を見てsample_valuesやsynonyms(同義語)なども自動的に生成してくれます。
2. YAML ファイルで手動作成する方法
自分で作成した YAML ファイルをアップロードすることも可能です。
ゼロから YAML ファイルを定義するのは時間がかかるため、まずモデルジェネレーターを利用し大枠を自動生成し、その後ファイルを更新して精度を上げていくのが効率的です。
ただし、2025 年 1 月時点ではモデルジェネレーターは日本語のカラム名には対応していないので、その点は注意が必要です。
以下は、サンプルテーブルから自動生成されたモデルの例です。カラムの説明や同義語まで自動で生成されており、これだけでもある程度の精度が期待できます。
CREATE OR REPLACE TABLE PRODUCT_INVENTORY (
product_id VARCHAR(50) PRIMARY KEY,
product_name VARCHAR(200) NOT NULL,
category VARCHAR(100) NOT NULL,
subcategory VARCHAR(100),
brand VARCHAR(100),
supplier_id VARCHAR(50) NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
unit_cost DECIMAL(10,2) NOT NULL,
current_stock INTEGER NOT NULL,
reorder_level INTEGER NOT NULL,
reorder_quantity INTEGER NOT NULL,
last_restock_date DATE,
expiry_date DATE,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP(),
updated_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
name: POS_RETAIL_ANALYTICS
tables:
- name: PRODUCT_INVENTORY
base_table:
database: KITAGAWA_KEITA
schema: TEST_CORTEX
table: PRODUCT_INVENTORY
dimensions:
- name: PRODUCT_ID
expr: PRODUCT_ID
data_type: VARCHAR(50)
cortex_search_service:
database: KITAGAWA_KEITA
schema: TEST_CORTEX
service: _CORTEX_ANALYST_PRODUCT_INVENTORY_PRODUCT_ID_95ADE535_A197_4412_9B13_EDB24B085DCE
sample_values:
- PROD070
- PROD001
- PROD085
description: Unique identifier for a product in the inventory.
synonyms:
- product_code
- item_id
- product_key
- item_number
- product_identifier
- sku
- stock_id
- name: PRODUCT_NAME
expr: PRODUCT_NAME
data_type: VARCHAR(200)
cortex_search_service:
database: KITAGAWA_KEITA
schema: TEST_CORTEX
service: _CORTEX_ANALYST_PRODUCT_INVENTORY_PRODUCT_NAME_AC986FAB_8192_40F0_93F9_9BAD889797C9
sample_values:
- Bananas
- Premium Coffee Beans
- Sourdough Bread
description: The name of the product being tracked in the inventory.
synonyms:
- item_name
- product_title
- product_description
- item_description
- product_label
# ... 以下省略(実際のファイルには全て含まれています)
セマンティックモデルの精度を向上させるポイント
1:synonyms、description、sample_values の改善
「セマンティックモデルを作成するためのヒント」にある通り、まずは自動生成された値が実際のテーブルの用途と一致しているかを確認し、より詳細に定義します。
自動生成された説明を確認する
セマンティックモデルジェネレーターを使用している場合、テーブルと列の説明が自動的に生成されます。これらの説明が適切かつ関連性のあるものであることを常に確認し、必要に応じて修正してください。
description(説明)
カラム名が企業独自のドメイン知識を必要とする場合も多いかと思います。そのような場合、description にカラムの意味を詳しく記載することで、より高い精度の結果を返すようになります。
columns:
- name: SALES_CHANNEL_CD
description: 販売チャネルを表すコード。01=店頭販売、02=EC販売、03=法人営業、04=代理店販売などを表す社内管理コード
synonyms(同義語)
同義語を設定することで、自然言語で問われる質問に対して正確なカラムを選択する可能性が向上します。
columns:
- name: hoge_no
description: 取引を一意に識別するための番号
synonyms:
- 取引番号
- 取引ID
- トランザクション番号
- 伝票番号
- オーダー番号
sample_values(サンプル値)
カラム名だけでは、どのような値が格納されているか判断が難しい場合があります。実際のデータのサンプル値を指定しておくことで、Cortex Analyst がより適切な判断を行えるようになります。
2:verified_queries(検証済みクエリ)の定義
verified_queries プロパティを使用して、想定されるクエリ例をモデルに設定できます。
事前に想定される自然言語の質問とそれに対応する SQL クエリを例として記載しておくことで、類似の質問が問われた時のクエリの正確性を向上させることができます。複数のバリエーションを登録できるので、よく使われる質問は全て定義するのが良いと思います。
何度か試してみたところ、JOIN を含む検証済みクエリでは、同じ質問を投げても異なるクエリが生成されることがありました。これは日本語を英語に翻訳する過程での揺れが原因と考えられます。将来的に日本語のまま質問できるようになれば、改善しそうな点です。
verified_queries:
- name: 日別売上集計
question: 最近7日間の日別売上高はどのように推移していますか?
verified_at: 1723420800
verified_by: Keita Kitagawa
use_as_onboarding_question: true
sql: |
SELECT
transaction_date,
COUNT(DISTINCT transaction_id) as transaction_count,
SUM(total_amount) as total_sales,
AVG(total_amount) as avg_transaction_value
FROM KITAGAWA_KEITA.TEST_CORTEX.SALES_TRANSACTIONS
WHERE transaction_date >= DATEADD(DAY, -7, CURRENT_DATE())
GROUP BY transaction_date
ORDER BY transaction_date DESC
3:relationships(テーブル間の関係)の定義
複数のテーブルを結合して扱う場合、relationships を定義する必要があります。
relationships にそれぞれのテーブルの結合条件を記載します。
実際に検証してみたところ、検証済クエリに記載した質問と全く同じ質問を投げた場合でも、relationships を記載していないと以下のエラーが返ってきました:
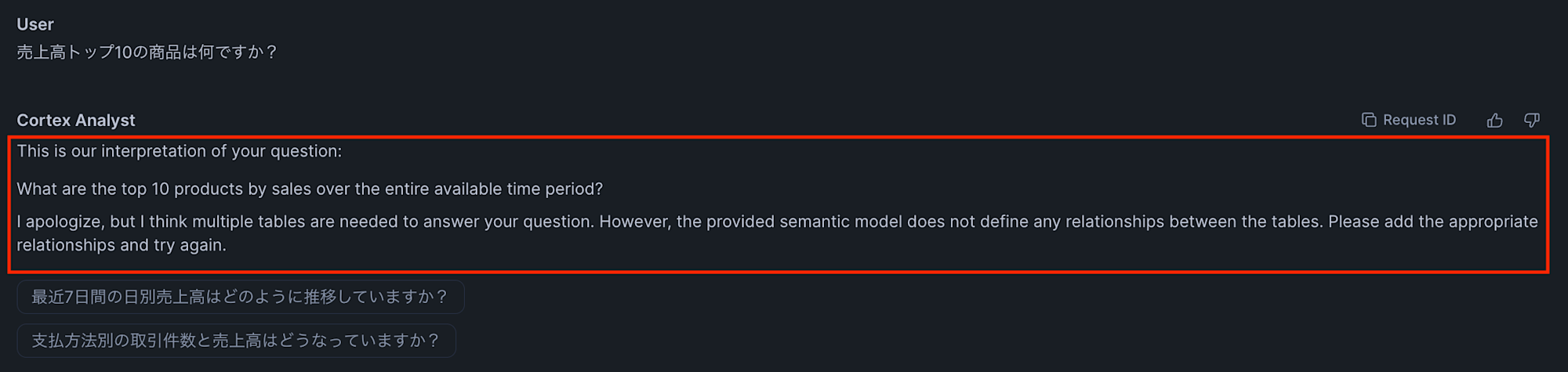
I apologize, but I think multiple tables are needed to answer your question.
However, the provided semantic model does not define any relationships between the tables.
Please add the appropriate relationships and try again.
## 翻訳結果
申し訳ありませんが、ご質問にお答えするには複数のテーブルが必要だと思います。
しかし、提供されたセマンティックモデルにはテーブル間のリレーションシップが定義されていません。
適切なリレーションシップを追加して、再度お試しください。
このことから、セマンティックモデルに複数のテーブルを記載していたとしても、質問内容に応じて勝手に JOIN をすることはないようです。
テーブル情報を基に自動的に結合キーを判断しない分、柔軟性は落ちますが、誤った結合を防げるため信頼性の高い設計と言えるでしょう。なお、relationships を設定するには、対象テーブルのプロパティにprimary_keyを設定しておく必要があります。
relationships:
# 売上明細と売上取引の関係
- name: sales_transaction_items_to_sales_transactions
left_table: SALES_TRANSACTION_ITEMS
right_table: SALES_TRANSACTIONS
relationship_columns:
- left_column: TRANSACTION_ID
right_column: TRANSACTION_ID
join_type: left_outer
relationship_type: many_to_one
# 売上明細と商品在庫の関係
- name: sales_transaction_items_to_product_inventory
left_table: SALES_TRANSACTION_ITEMS
right_table: PRODUCT_INVENTORY
relationship_columns:
- left_column: PRODUCT_ID
right_column: PRODUCT_ID
join_type: left_outer
relationship_type: many_to_one
4:custom_instructions(カスタム指示)の定義
SQL のクエリ生成方法をカスタマイズすることもできます。出力する値を制御したい場合に利用することで、より期待する結果を返すことができます。
例えば、以下のような指示を追加できます:
# "すべての数値列が小数点以下2桁で丸められ出力されるようにする"
custom_instructions: "Ensure that all numeric columns are rounded to 2 decimal points in the output."
カスタム指示は、主に生成される SQL の精度を向上させるためのプロパティです。
そのため、「日本語に翻訳して出力して」のような全体的な指示も設定できますが、用途的には適切ではないのかなと思いました。
# "回答内容を日本語に翻訳して出力してください。"
custom_instructions: Please translate the response content into Japanese and output it.
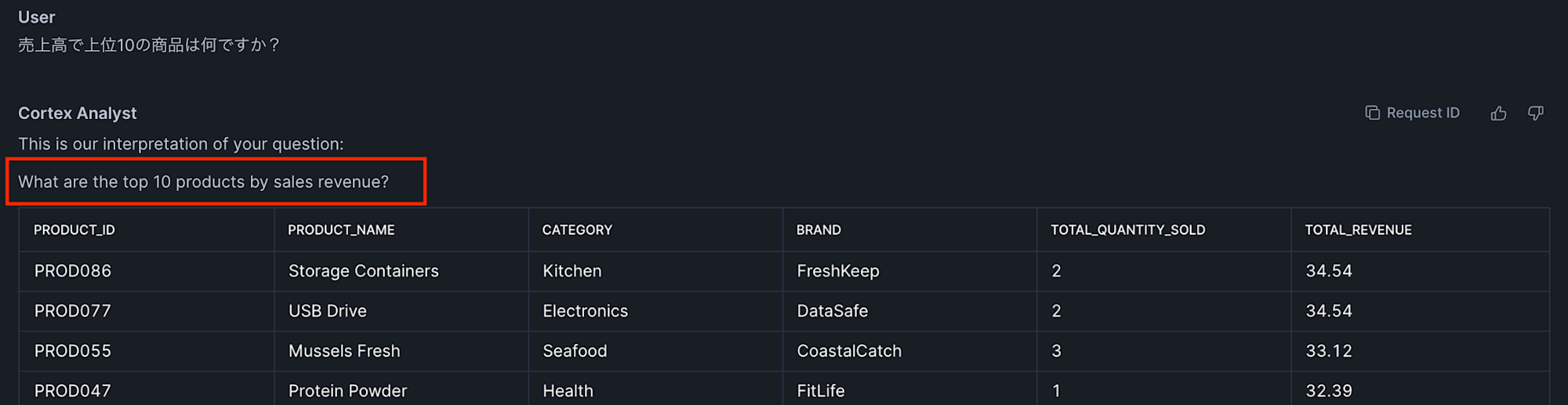
設定後は、シンプルな結果を返す場合、一部日本語で回答が返ってくるようになりました。設定前は英語でしたので、制御が働いていることは確かです。
まとめ
以上、Snowflake Cortex Analyst のセマンティックモデルの精度を向上させるためのポイントを、まとめてみました。
- synonyms、description、sample_values の改善 - 自動生成された値を確認し、実際の用途に合わせて詳細化
- verified_queries の定義 - よく使われる質問パターンを事前に登録
- relationships の定義 - 複数テーブル利用時は必須
- custom_instructions の定義 - 出力形式のカスタマイズ
まだプレビュー機能ということもあり、今後さらに使いやすくなっていくことが期待されます。特に日本語対応の強化や、クエリ全体に対するプロンプト設定など、より手軽に高精度なセマンティックモデルを構築できるようになると思います。
皆さんもぜひ、これらのポイントを押さえてセマンティックモデルを作成してみてください。









