Snowflake Cortex AIのCortex Analystでマルチターンの会話をしてみる
データ事業本部の鈴木です。
Snowflake Cortex AIのCortex AnalystはSnowflakeの構造化データに基づいたビジネス上の質問に確実に回答できるアプリケーションの作成を実現する機能です。
より具体的にはREST APIを提供しており、Snowflakeへの接続情報を使ってさまざまなアプリケーションからCortex Analystに問い合わせを行い、Snowflakeの構造化データに基づいた回答を受け取ることができます。
Cortex Analystの特徴としてマルチターンの会話をサポートしています。
クイックスタートなどではマルチターンの会話を踏まえた実装はあまり公開されていなさそうでしたので試してみました。
マルチターンの会話の実現方法について
Cortex AnalystではREST APIに対してメッセージをPOSTしますが、メッセージに過去の会話も含めることでマルチターンの会話を行うことが可能です。
以下は上記ガイドに記載のメッセージの例です。messagesのバリューとして会話の履歴を格納したJSONを含めており、リストの前にある会話ほど前の会話になります。
{
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the month over month revenue growth for 2021 in Asia?"
}
]
},
{
"role": "analyst",
"content": [
{
"type": "text",
"text": "We interpreted your question as ..."
},
{
"type": "sql",
"statement": "SELECT * FROM table"
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What about North America?"
}
]
},
],
"semantic_model_file": "@my_stage/my_semantic_model.yaml"
}
メッセージはuser→analyst→user→...という順番になっていることにご留意ください。後ほどの実装で必要になります。
上記はWhat is the month over month revenue growth for 2021 in Asia?という質問に対してCortex Analystが回答とSQLを生成しますが、その結果についてさらにWhat about North America?と質問する例です。
この会話例は以下のSnowflakeのブログ記事でも取り上げられています。
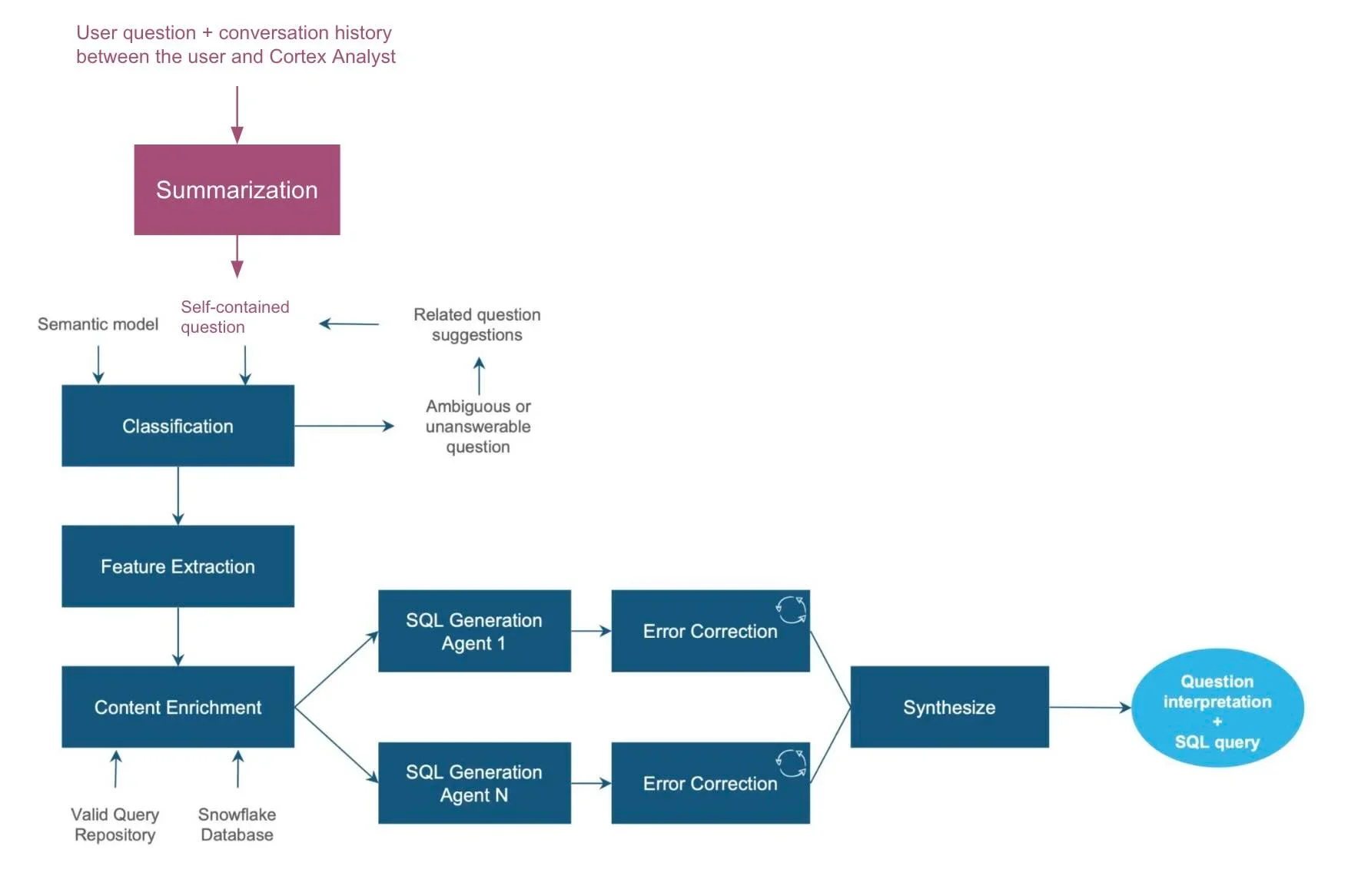
(上記ブログより2025/5/4に引用)
こちらの記事に記載があるように、Cortex Analystでは最初に要約をすることで過去の会話を効率的に使い、回答の生成をしているそうです。Text2SQLに明るくないとCortex Analystは1つのモデルなのかと思ってしまいますが、タスク自体が非常に難しいため、上記のようにさまざまな機能を組み合わせてより精度の高い回答を生成できるよう大変工夫されたものであることがよく分かります。特に適切なJOINの実装の生成などはとても難しいポイントですが、使ってみた肌感としてCortex Analystはかなり性能よく生成してくれます。
マルチターンの会話の実装について
実装自体は簡単で、REST APIにPOSTするメッセージに過去分も含めるだけでできました。
今回はStreamlit in Snowflakeで試した内容をご紹介します。
過去分のメッセージを与えないとき
単純に聞きたいテキストだけをREST APIにPOSTします。
例えば以下のブログで紹介されているような実装です。
def send_message(prompt: str) -> dict:
"""Calls the REST API and returns the response."""
request_body = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
],
"semantic_model_file": f"@{DATABASE}.{SCHEMA}.{STAGE}/{FILE}",
}
resp = _snowflake.send_snow_api_request(
"POST",
f"/api/v2/cortex/analyst/message",
{},
{},
request_body,
{},
30000,
)
以下は別途作成したStreamlitアプリでの検証結果ですが、確かに前の会話は忘れてしまっていることが分かります。
初回は確かに適切な回答を返してくれていますが、
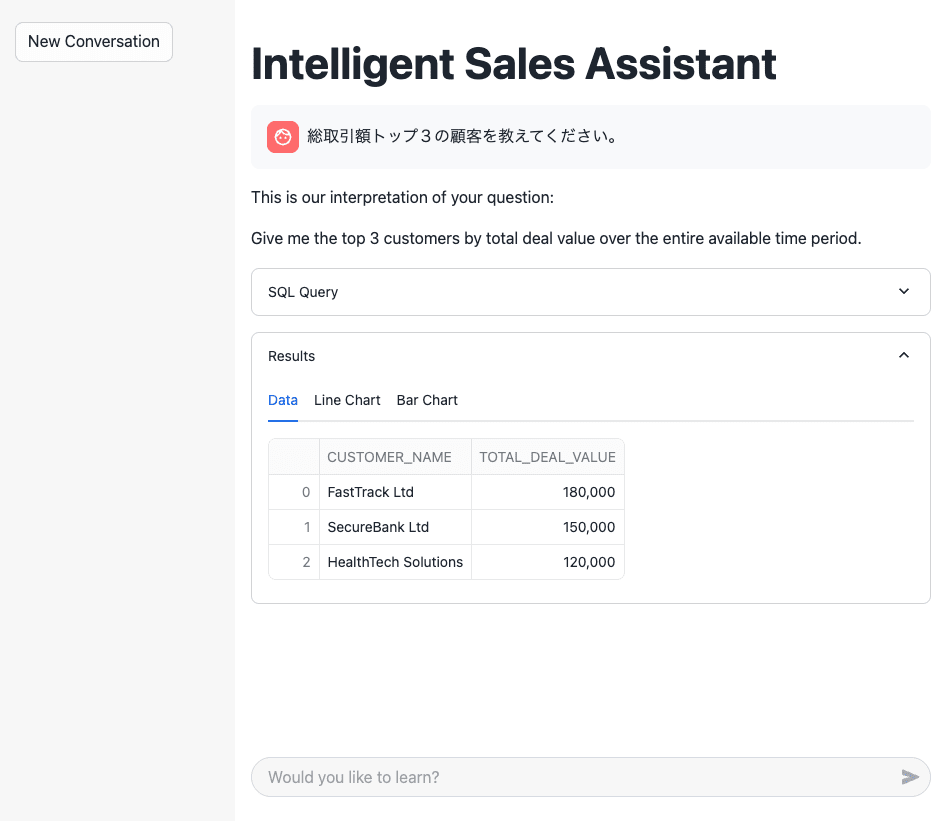
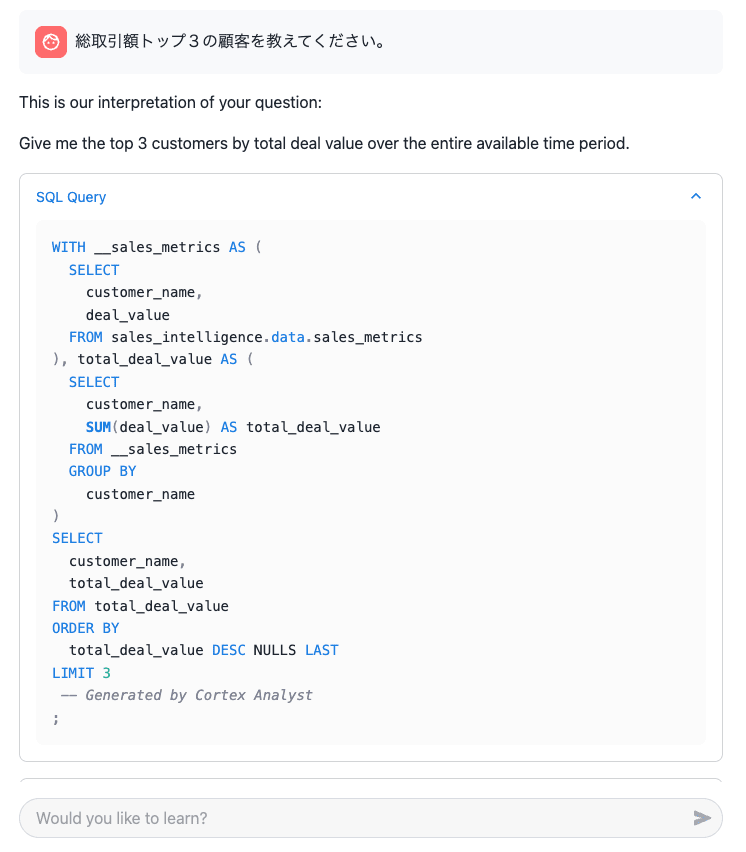
2回目に「その」のような過去履歴を参照する文言を入れると、過去履歴がないために分からないので近しい質問を考えて返してくれました。
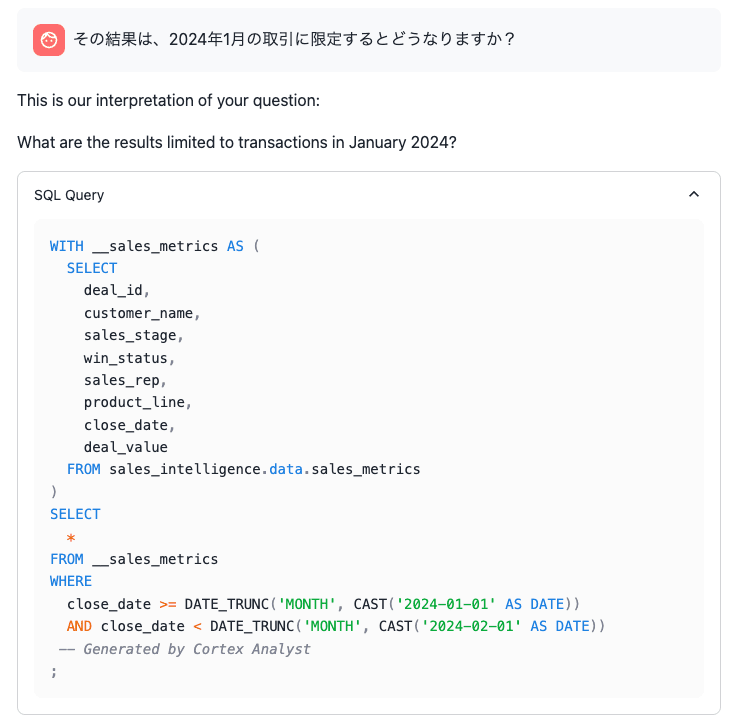
これは残念ながら、過去の会話を踏まえて回答を生成したとは言い難い結果ですね。
過去分のメッセージを与えるとき
続いて、messagesに過去履歴を入れたマルチターンの会話を実装した版で試してみました。
初回は先の例と同様に適切な回答を返してくれています。
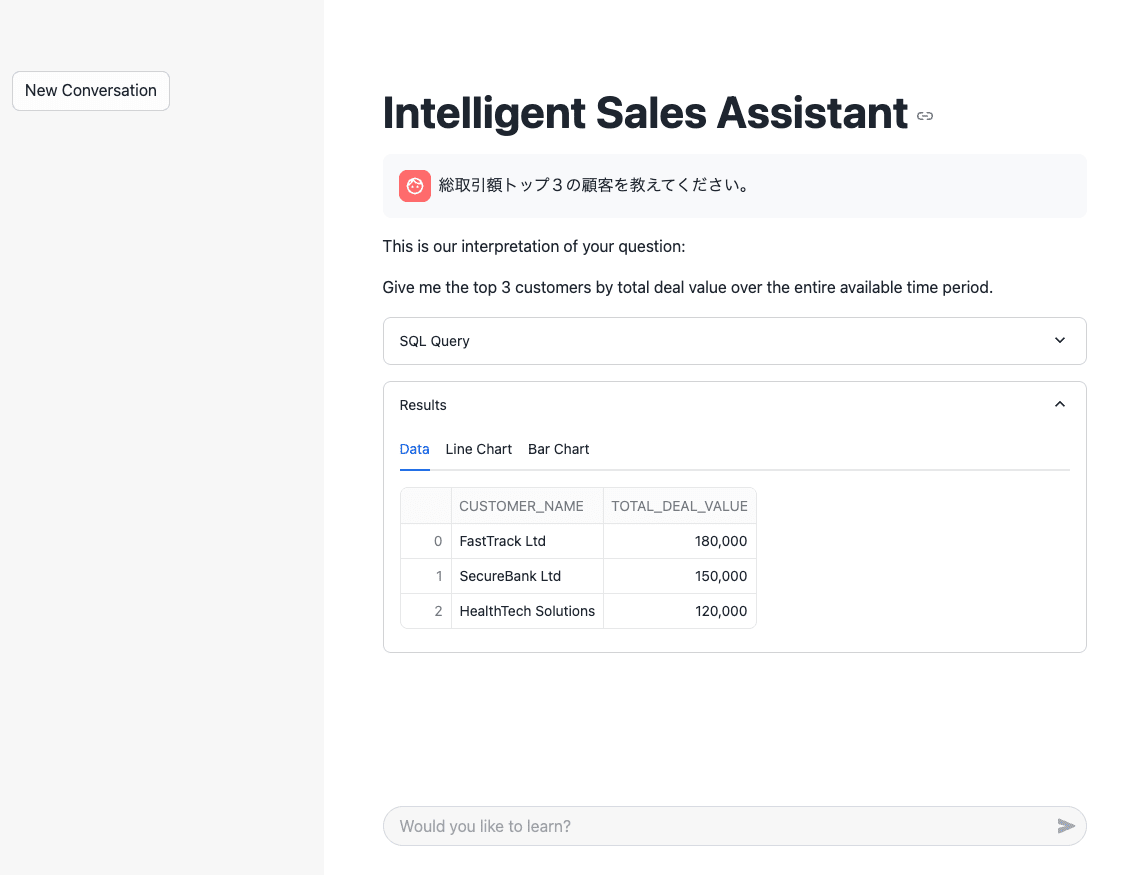
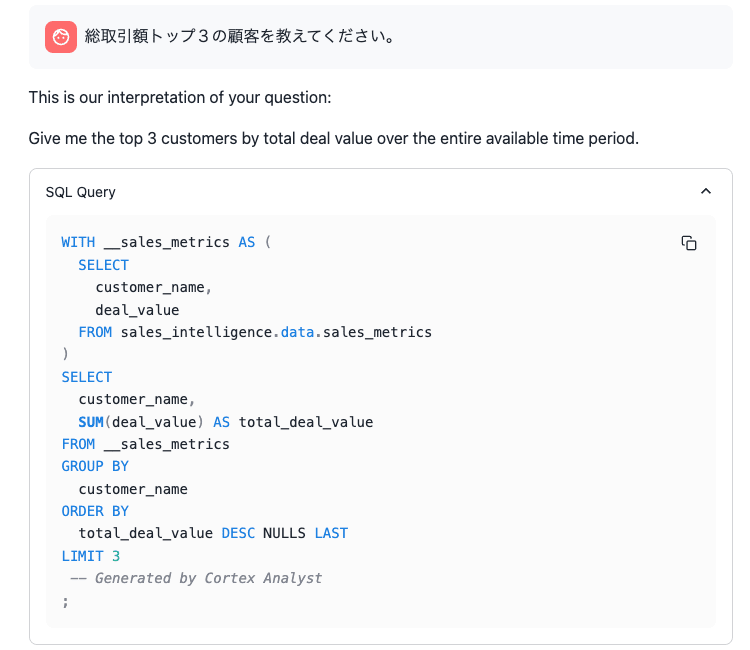
2回目に「その」のような過去履歴を参照する文言を入れると、messagesに含めた過去履歴を参照して、適切なSQLを作成して返してくれました。
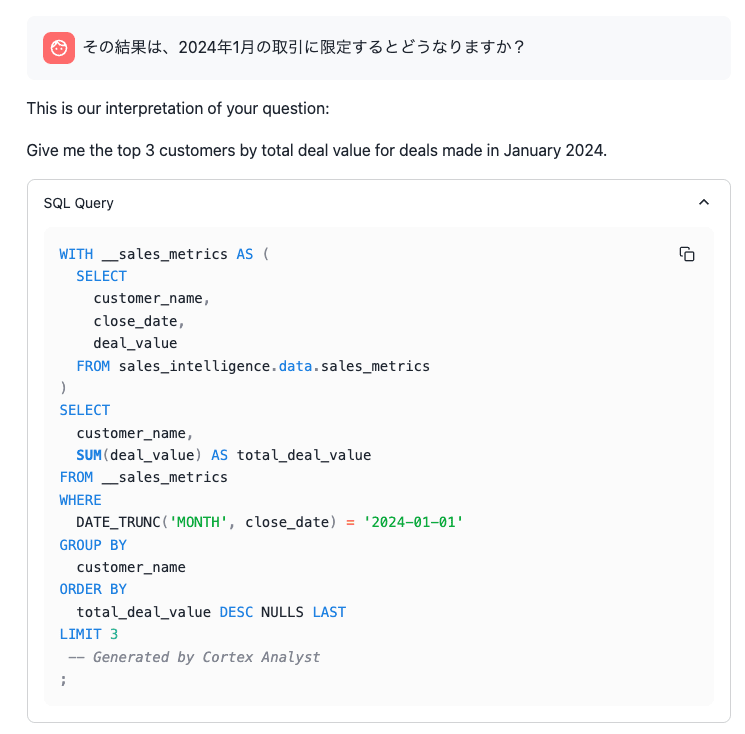
この結果であれば、マルチターンの会話とSQL生成として十分にさまざまなビジネスタスクを果たせそうですね。
以下のようなイメージで実装しました。
def snowflake_api_call(query: str, past_messages: List[str] = [], limit: int = 10):
new_message = {
"role": "user",
"content": [
{
"type": "text",
"text": query
}
]
}
past_messages.append(new_message)
payload = {
"messages": past_messages,
"semantic_model_file": f"@{DATABASE}.{SCHEMA}.{STAGE}/{FILE}",
}
try:
resp = _snowflake.send_snow_api_request(
"POST", # method
API_ENDPOINT, # path
{}, # headers
{}, # params
payload, # body
None, # request_guid
API_TIMEOUT, # timeout in milliseconds,
)
past_messagesには過去の履歴を入れています。過去履歴はSession Stateに入れています。
import copy
import streamlit as st
# 過去履歴の初期化
if 'messages' not in st.session_state:
st.session_state.messages = []
# 過去履歴を含めた回答の生成
past_messages = copy.deepcopy(st.session_state.messages)
response = snowflake_api_call(query, past_messages, 1)
# 自分の質問の保存
st.session_state.messages.append({"role": "user", "content": [{"type": "text", "text": query}]})
# 今回の回答から回答文とSQL文を取り出す、今回は簡単のため必ず回答文とSQL文をAnalystが返すこととする
text, statement = process_response(response)
# 会話履歴の保存
resp_contents = [{"type": "text", "text": text}, {"type": "sql", "statement": statement}]
if len(resp_contents) > 0:
st.session_state.messages.append({"role": "analyst", "content": resp_contents})
上記の会話履歴の保存は少し簡略化して記載しています。Cortex AnalystはレスポンスでSQL文の代わりにsuggestionを返す場合があります。suggestionはユーザーの入力から回答を生成できない場合に、代わりの質問を提案してくれます。suggestionが返る際にはSQL文は返してきません。
より詳しくは下記ガイドをご確認ください。
最後に
Snowflake Cortex AIのCortex Analystでマルチターンの会話の実装例をご紹介しました。アプリ側で過去履歴の保持とREST APIへのPOSTの実装が必要になります。Cortex AnalystがAPIを提供する形態であることを踏まえると、このような実装になることが理解しやすいと思います。








