Snowflake Cortex LLM関数のPARSE_DOCUMENT・TRANSLATE・CLASSIFY_TEXT・COMPLETEを試してみた
かわばたです。
SnowPro® Associate: Platform認定試験の試験範囲にSnowflake CortexのLLM関数が含まれています。
私も受験予定なので、代表的な4つの関数を試していきます。
本記事で行うこと
- PARSE_DOCUMENT 関数
- TRANSLATE 関数
- CLASSIFY_TEXT 関数
- COMPLETE 関数
検証環境
-
Snowflakeのアカウント
※SnowflakeはトライアルアカウントのEnterprise版で試しています。 -
使用データ
※生成AIで作成したダミーデータを使用しています。
製品データ 25行
| product_id | product_name | price |
|---|---|---|
| 201 | リンゴ | 150 |
| 202 | バナナ | 100 |
| 203 | オレンジ | 120 |
| 204 | 牛乳 | 250 |
| 205 | パン | 180 |
| ~~~ | ~~~ | ~~~ |
Snowflake Cortexとは
公式ドキュメントから概要を引用しました。
Snowflake Cortexでは、Anthropic、Mistral、Reka、Meta、Google などの企業の研究者によってトレーニングされた、業界をリードする大規模言語モデル(LLMs)に即座にアクセスできます。これには、Snowflakeが開発したオープンなエンタープライズグレードのモデルである Snowflake Arctic も含まれます。
これらの LLMs は完全にSnowflakeによってホストされ、管理されているため、使用する際にセットアップは必要ありません。お客様のデータはSnowflake内に留まり、お客様が期待するパフォーマンス、スケーラビリティ、ガバナンスを実現します。
LLM機能をSnowflakeが提供するため、安全に活用できるのは良いポイントですね!
【公式ドキュメント~大規模言語モデル(LLM)関数(Snowflake Cortex)~】
PARSE_DOCUMENT関数
PARSE_DOCUMENT関数は、内部ステージまたは外部ステージに保存されている文書からテキストまたはレイアウトを抽出します。
公式ドキュメントより引用。
PDFのような文書ファイルから自動でテキスト情報を読み取り、抽出してくれる関数です。
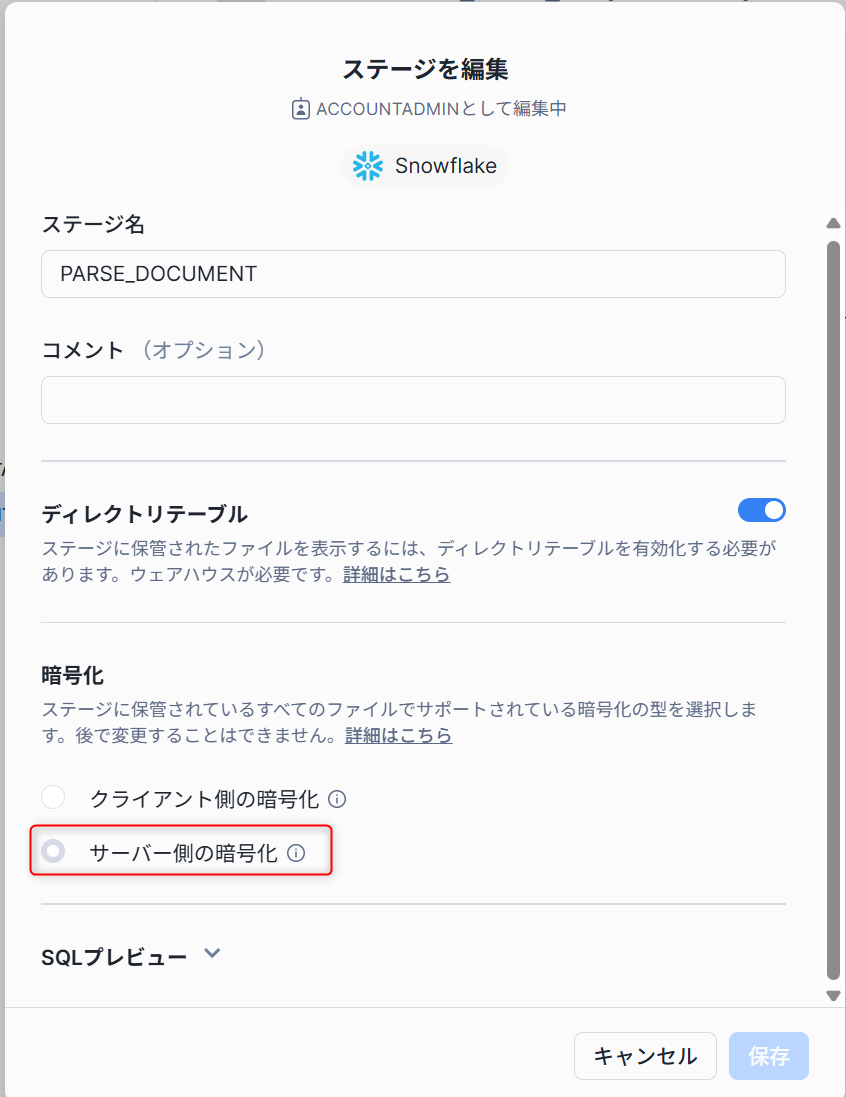
まずはステージにテキストを抽出したいファイルを格納します。
このとき、ステージはサーバーサイド暗号化 (SNOWFLAKE_SSE) を有効にする必要があります。
クライアント側の暗号化では実行できないため注意が必要です。
【公式ドキュメント~Snowflakeの暗号化キー管理~】
ステージにpdfを格納しました。

※下記記事をpdf化したものになります。
準備が出来たので実際実行してみましょう!
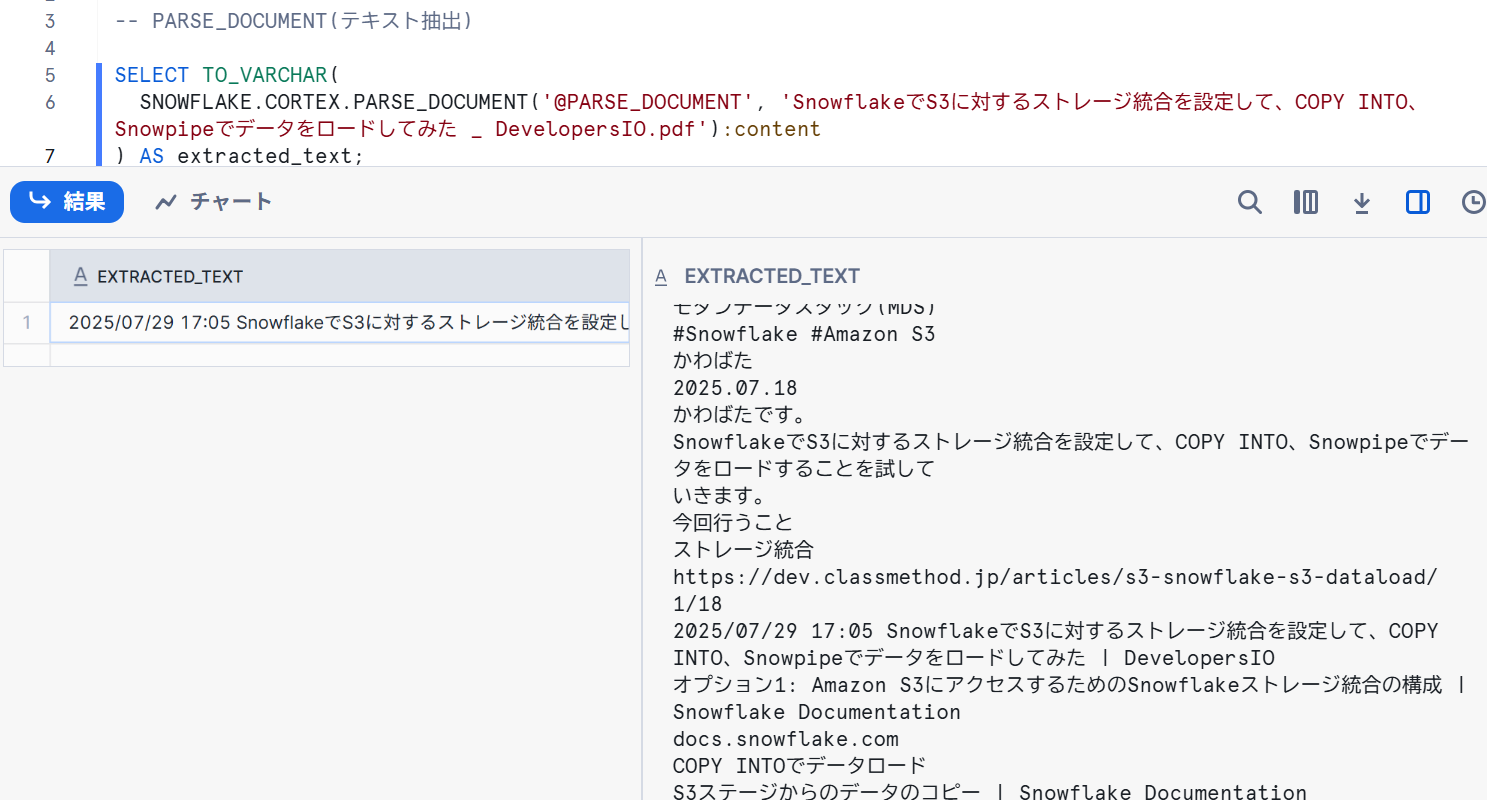
【OCRモードでテキストを抽出】
-- PARSE_DOCUMENT(テキスト抽出)
SELECT TO_VARCHAR(
SNOWFLAKE.CORTEX.PARSE_DOCUMENT('@PARSE_DOCUMENT', 'SnowflakeでS3に対するストレージ統合を設定して、COPY INTO、Snowpipeでデータをロードしてみた _ DevelopersIO.pdf'):content
) AS extracted_text;
- 結果
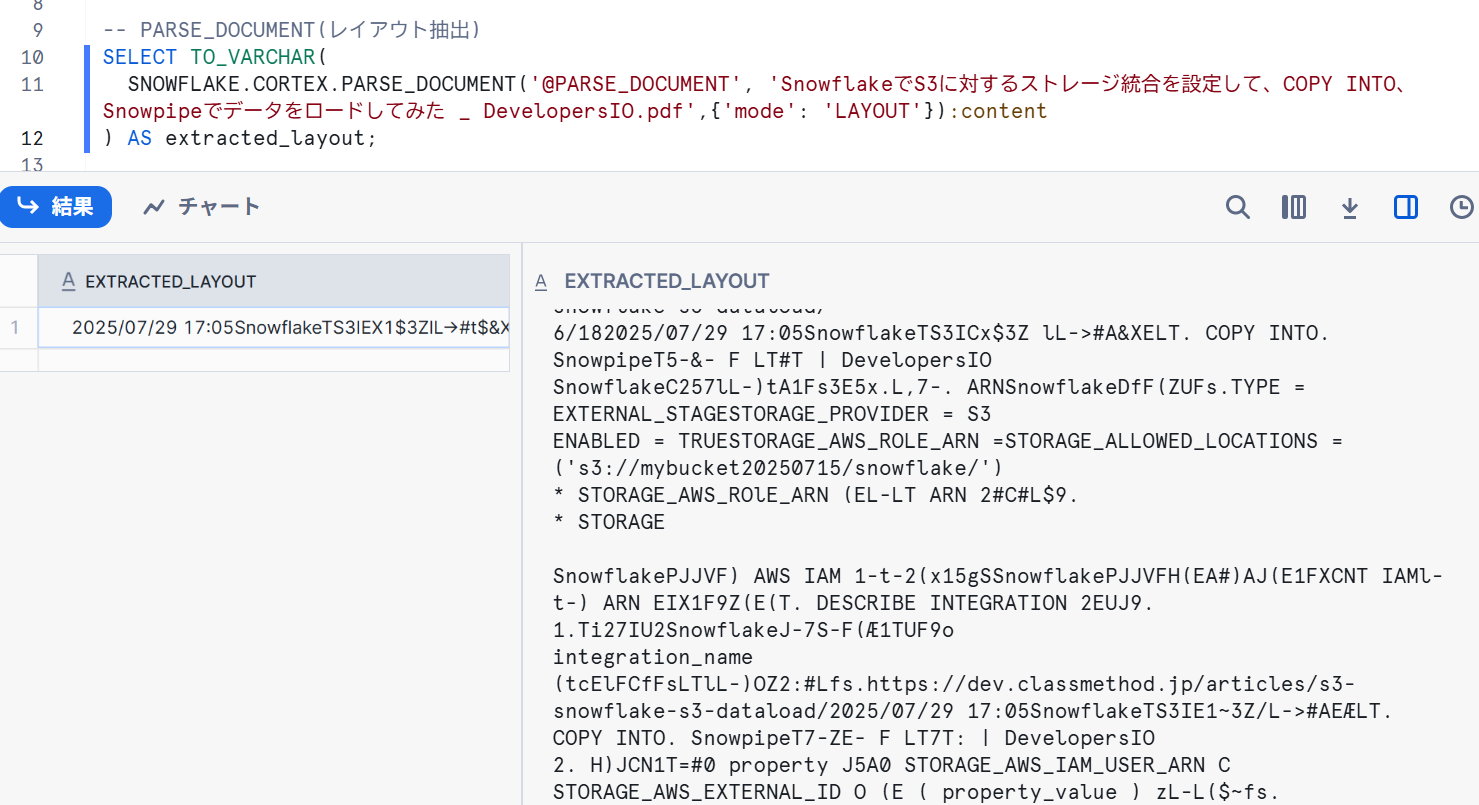
【レイアウトモードでテキストを抽出】
-- PARSE_DOCUMENT(レイアウト抽出)
SELECT TO_VARCHAR(
SNOWFLAKE.CORTEX.PARSE_DOCUMENT('@PARSE_DOCUMENT', 'SnowflakeでS3に対するストレージ統合を設定して、COPY INTO、Snowpipeでデータをロードしてみた _ DevelopersIO.pdf',{'mode': 'LAYOUT'}):content
) AS extracted_layout;
- 結果
【まとめ】
OCRモードではテキストを抽出することが出来ました。精度も思ったより高く、PDF形式のアンケートの自由記述などを分析する際に利用できると感じました。(手書きの文字でどこまで認識できるかも試してみたいです)
レイアウトモードは検証する題材が悪かったからかうまく半構造化できていませんでした。現時点では元の文書の品質に依存しそうです。論文等に含まれる表形式のデータを抽出するなど、活用方法はありそうでした。
【公式ドキュメント~Cortex PARSE_DOCUMENT 関数~】
TRANSLATE関数
指定された入力テキストをサポートされている言語から別の言語に翻訳します。
公式ドキュメントより引用。
サポートされている言語は下記のとおりです。
| 言語 | コード |
|---|---|
| 中国語 | 'zh' |
| オランダ語 | 'nl' |
| 英語 | 'en' |
| フランス語 | 'fr' |
| ドイツ語 | 'de' |
| ヒンディー語 | 'hi' |
| イタリア語 | 'it' |
| 日本語 | 'ja' |
| 韓国語 | 'ko' |
| ポーランド語 | 'pl' |
| ポルトガル語 | 'pt' |
| ロシア語 | 'ru' |
| スペイン語 | 'es' |
| スウェーデン語 | 'sv' |
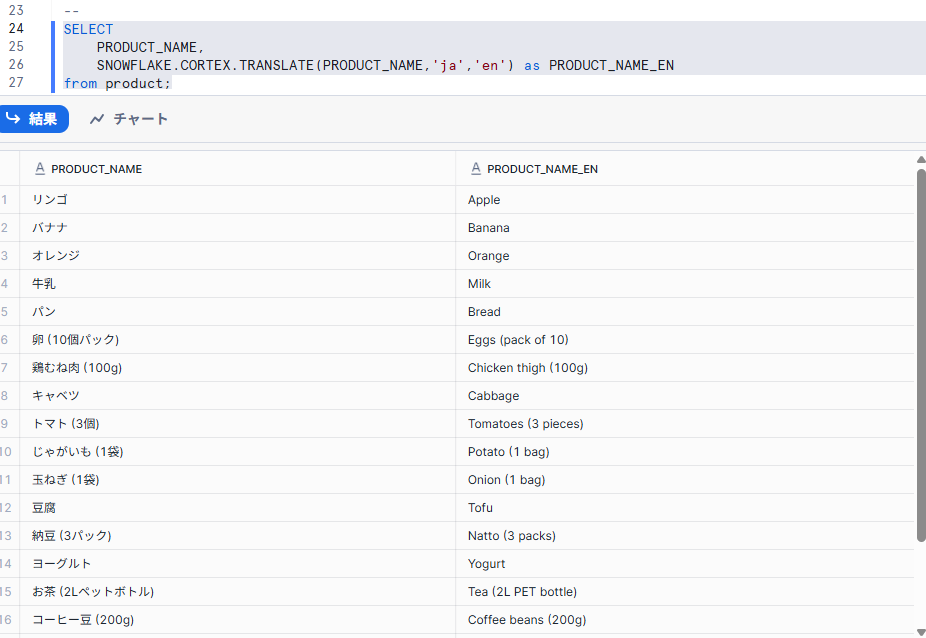
実際に日本語から英語で試してみました。
SELECT
PRODUCT_NAME,
SNOWFLAKE.CORTEX.TRANSLATE(PRODUCT_NAME,'ja','en') as PRODUCT_NAME_EN
from product;
- 結果
【まとめ】
今回日本語から英語で試してみましたが、精度高く変換できていました。
ドキュメントに「ソース言語またはターゲット言語のいずれかが英語の場合に最良の結果を生成します」とあるため、英語以外の言語ペアでは正確さに欠ける場合もあるようです。
かなり使えそうな機能だと感じました!
【公式ドキュメント~TRANSLATE (SNOWFLAKE.CORTEX)~】
CLASSIFY_TEXT 関数
自由形式のテキストをプロバイダーが指定したカテゴリに分類します。
公式ドキュメントより引用。
簡単に言うと、テキストの内容をAIが読み取り、指定したカテゴリに自動で分類してくれる便利な関数です。
実際に試します。
SELECT
PRODUCT_NAME,
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(PRODUCT_NAME,['野菜','フルーツ','乳製品','その他']) as PRODUCT_CATEGORIES
from PRODUCT;
- 結果
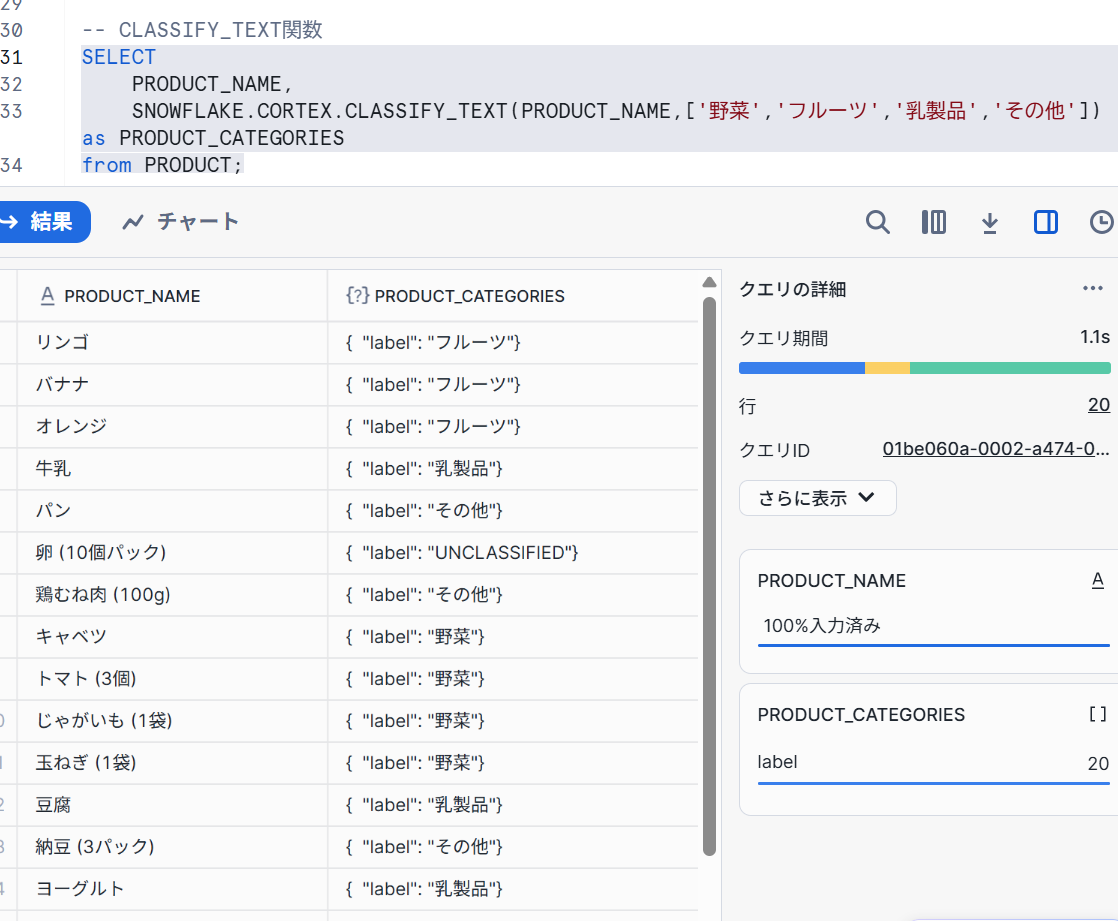
【まとめ】
これは非常に便利な関数だと思いました。属性を振り分けるときの精度には注意が必要ですが、サクッと属性分析ができるのは良いと感じました。
他にも顧客レビューの感情分析や問い合わせ内容の自動仕分け・アンケートの自由回答の整理などで利用できそうです!
【公式ドキュメント~CLASSIFY_TEXT (SNOWFLAKE.CORTEX~】
COMPLETE 関数
プロンプトを与えると、サポートされている言語モデルの中から選択したものを使用して応答(完了)を生成します。
公式ドキュメントより引用。
SQLから直接、ChatGPTやGeminiのような生成AI(大規模言語モデル)を呼び出せる関数です。
現在(2025/07/30)東京リージョンでは下記モデルが利用可能です。
| モデル |
|---|
| llama3.1-8b |
| llama3.1-70b |
| reka-flash |
| mistral-large2 |
| mixtral-8x7b |
| mistral-7b |
| jamba-instruct |
| jamba-1.5-mini |
claude-3-5-sonnetなど別のモデルを使用したい場合は、クロスリージョン推論を行う必要があります。
ただし、クロスリージョン推論を行うということは、データが一時的に契約リージョン外に転送されることを意味します。 自社内で確認の上利用することを推奨します。
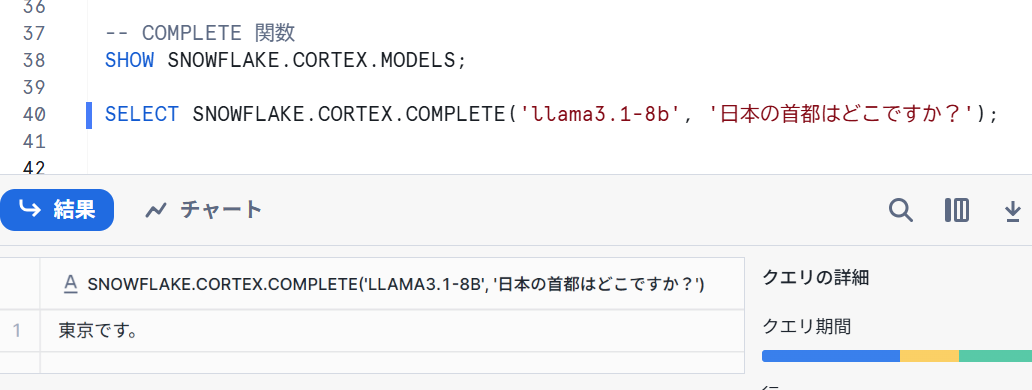
早速COMPLETE関数試していきます。
SELECT SNOWFLAKE.CORTEX.COMPLETE('llama3.1-8b', '日本の首都はどこですか?');
- 結果
先ほど試してみたCLASSIFY_TEXT 関数のような使い方をしてみます。
SELECT
PRODUCT_NAME,
SNOWFLAKE.CORTEX.COMPLETE('llama3.1-8b',CONCAT('次のPRODUCT_NAMEを確認し、製品カテゴリの名称を単語で示してください。', PRODUCT_NAME)) as PRODUCT_CATEGORIES
from PRODUCT;
- 結果
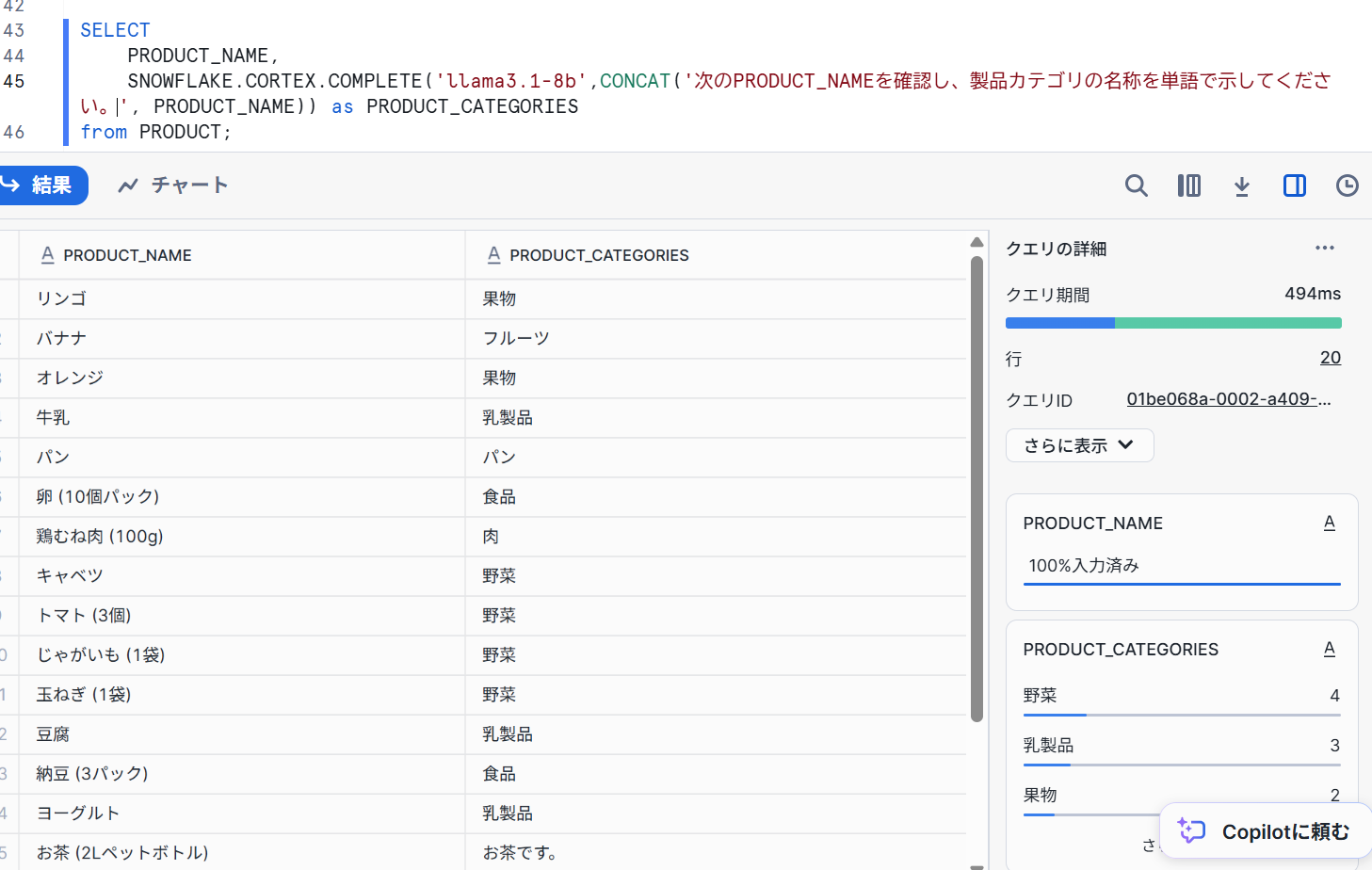
【まとめ】
柔軟性が高く便利です!精度がモデルやプロンプトに依存する部分があるので、確認が必要ではありますがいろいろな場面で活用できそうです。
【公式ドキュメント~COMPLETE (SNOWFLAKE.CORTEX)~】
最後に
Snowflake CortexのLLM機能について試してみましたがいかがでしたでしょうか。
実際に試してみると、AI機能を簡単に活用でき利便性を肌で感じました。
今後はこのような機能が拡張されていくと思うので、AI-Readyな状態を作っていくことが求められると感じました。
この記事が参考になれば幸いです。







