
Cortex Search Service用にPDFをパースしてチャンキングするdbtのIncremental modelを考えてみた
さがらです。
Cortex Search Serviceを使用してRAGを構築するためには、PDFなどのドキュメントをAI_PARSE_DOCUMENT関数などでパースしたテーブルを用意する必要があります。
このテーブルについてdbtで構築する方法を考えてみたので、その内容について本記事でまとめます。
実装したdbt model
早速ですが、実装したdbt modelは以下となります。Snowflake社の事例PDFを置いたS3バケットのディレクトリテーブルに対して、ドキュメントのパースとチャンキングを行っています。
このdbt modelのポイントは以下となります。
unique_key='relative_path'+incremental_strategy='delete+insert'でIncremental modelとして構成。同一ファイルパスのデータは削除後に再挿入される- 既存のディレクトリテーブルに同一パス・同一またはそれ以降の更新日時のレコードがあればスキップ(未処理 or 更新されたファイルのみ処理されるため、
AI_PARSE_DOCUMENTによるパース処理のコストを抑えることが可能です)
- 既存のディレクトリテーブルに同一パス・同一またはそれ以降の更新日時のレコードがあればスキップ(未処理 or 更新されたファイルのみ処理されるため、
- チャンキングは
SNOWFLAKE.CORTEX.SPLIT_TEXT_MARKDOWN_HEADER関数を使用- Snowflake社の高田さんのブログを見て、採用しています
{{
config(
materialized='incremental',
unique_key='relative_path',
incremental_strategy='delete+insert'
)
}}
with directory_files as (
select
relative_path,
last_modified,
TO_FILE('@RAW_DB.SAMPLE_SOURCE_SNOWPIPE.STAGE_CORPUS_SAMPLE', relative_path) as doc_file
from
DIRECTORY(@RAW_DB.SAMPLE_SOURCE_SNOWPIPE.STAGE_CORPUS_SAMPLE) as d
where
relative_path like 'snowflake-case-studies/%.pdf'
{% if is_incremental() %}
and not exists (
select 1
from {{ this }} as t
where t.relative_path = d.relative_path
and t.last_modified >= d.last_modified
)
{% endif %}
),
parsed as (
select
relative_path,
last_modified,
SNOWFLAKE.CORTEX.AI_PARSE_DOCUMENT(
doc_file,
{'mode': 'LAYOUT', 'page_split': TRUE}
) as parsed_result
from
directory_files
),
concatenated as (
select
p.relative_path,
p.last_modified,
LISTAGG(f.value:content::varchar, '\n\n') within group (order by f.index) as full_content
from
parsed as p,
lateral flatten(input => p.parsed_result:pages) as f
group by
p.relative_path, p.last_modified
),
chunked as (
select
c.relative_path,
c.last_modified,
ch.value:headers:header_1::varchar as header_1,
ch.value:headers:header_2::varchar as header_2,
ch.value:headers:header_3::varchar as header_3,
ch.value:chunk::varchar as chunk,
ch.index as chunk_index
from
concatenated as c,
lateral flatten(input =>
SNOWFLAKE.CORTEX.SPLIT_TEXT_MARKDOWN_HEADER(
c.full_content,
OBJECT_CONSTRUCT('#', 'header_1', '##', 'header_2', '###', 'header_3'),
10000
)
) as ch
)
select
SHA2(relative_path || ':' || chunk_index, 256) as doc_chunk_id,
relative_path,
SPLIT_PART(relative_path, '/', -1) as file_name,
REPLACE(REPLACE(SPLIT_PART(relative_path, '/', -1), 'Case_Study_', ''), '.pdf', '') as case_study_name,
header_1,
header_2,
header_3,
chunk_index,
chunk,
last_modified,
CURRENT_TIMESTAMP() as _parsed_at
from
chunked
また、dbt_project.ymlでは下記のようにpre_hookとpost_hookを設定しています。modelsフォルダ内でcorpusフォルダを用意し、この中でCortex Search Service用にパースとチャンキングを行うmodelを定義していく前提です。
pre_hook:PDFを置いているS3に対する外部ステージをリフレッシュすることで、dbt modelがクエリするディレクトリテーブルをmodel構築前に更新post_hook:Cortex Search Service用のテーブルはCHANGE_TRACKINGの有効化が必要のため、構築後に有効化するクエリを実施
name: 'sample_dbt_project'
version: '1.9.0'
config-version: 2
profile: 'sample_project'
models:
sample_dbt_project:
corpus:
sample:
+schema: corpus_sample
+pre-hook:
- "ALTER STAGE RAW_DB.SAMPLE_SOURCE_SNOWPIPE.STAGE_CORPUS_SAMPLE REFRESH"
+post-hook:
- "ALTER TABLE {{ this }} SET CHANGE_TRACKING = TRUE"
dbt model初回実行&Cortex Search Service構築
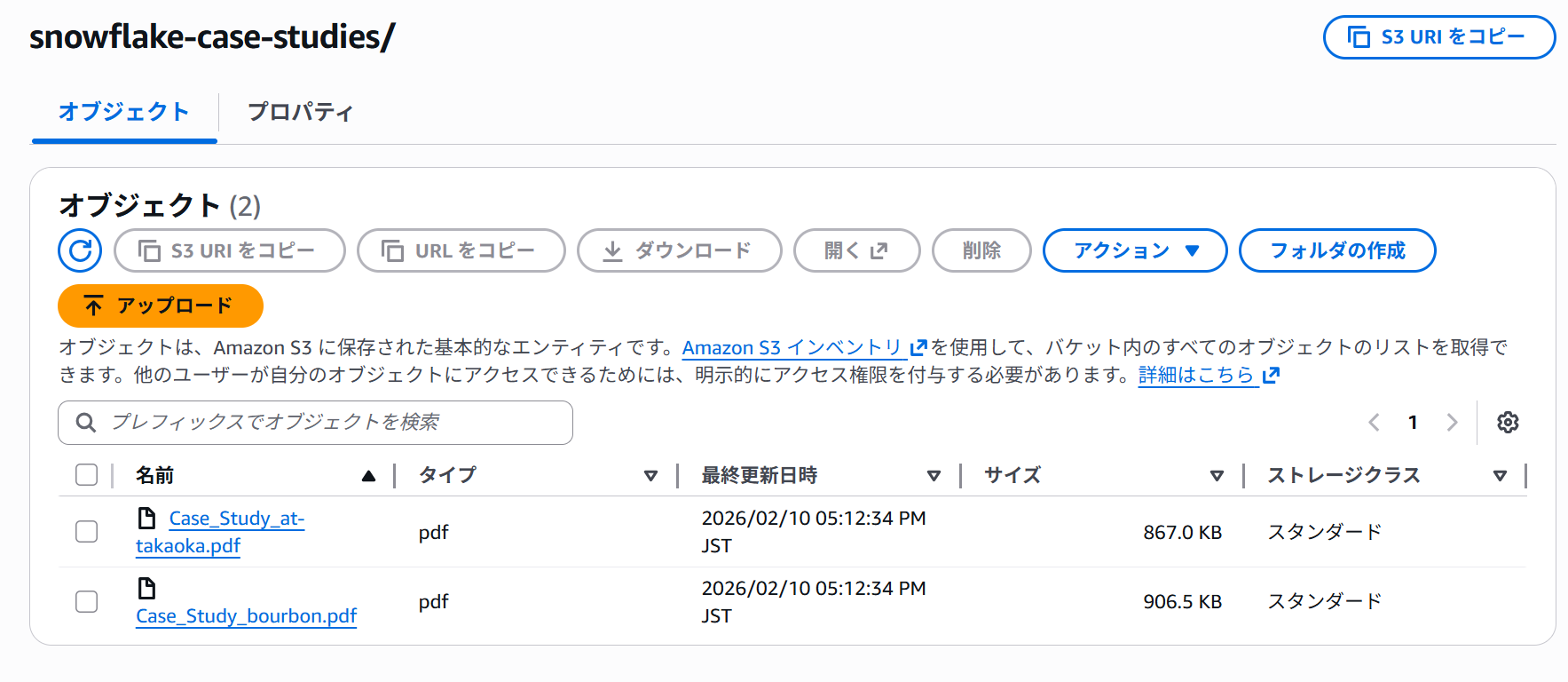
S3には下図のように、ブルボン様とアイシン高丘様の事例だけ入れておきます。(ステージ作成のクエリなどは割愛します。)
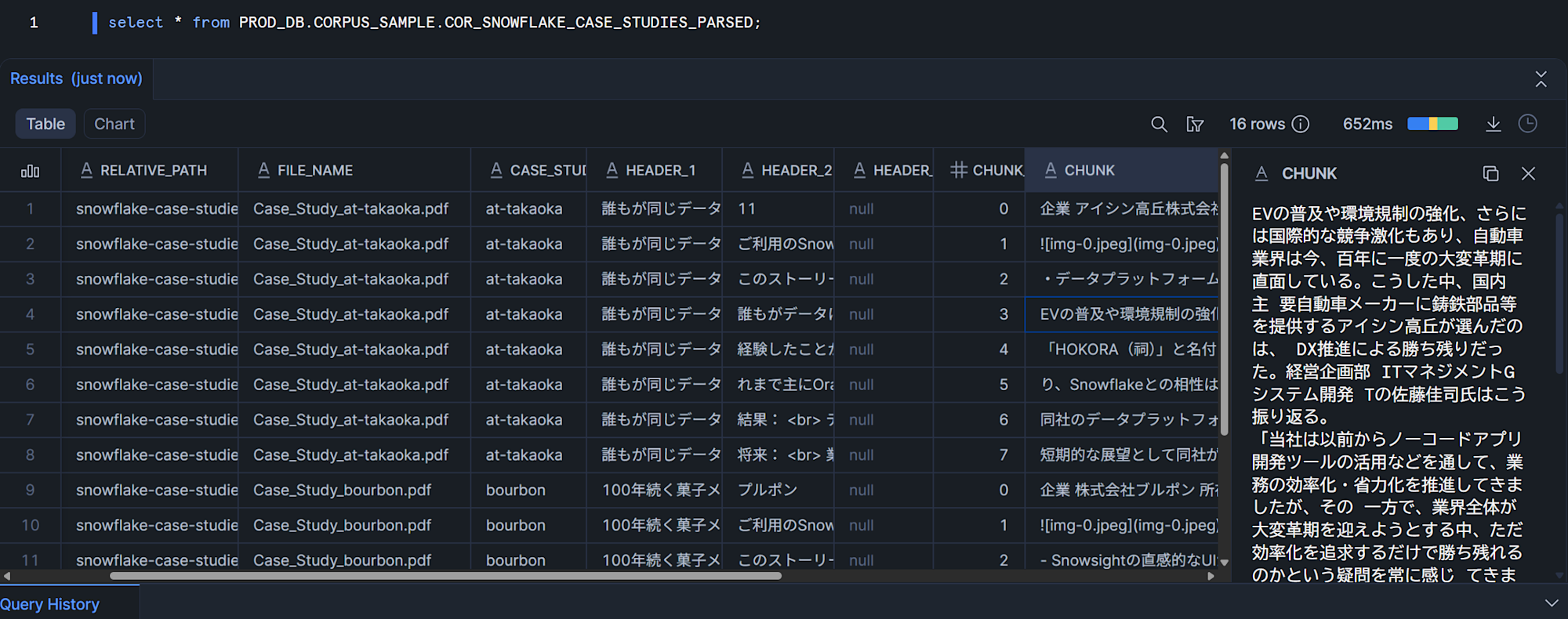
上述のdbt modelをdbt buildなどで実行すると、下図のように事例PDFをパースしてチャンキングしたテーブルがSnowflakeに作られます。
このdbt modelに対するCortex Search ServiceとCortex Agentを以下のクエリで構築します。
-- Cortex Search Service作成
CREATE OR REPLACE CORTEX SEARCH SERVICE PROD_DB.AIML_SAMPLE.CSS_SNOWFLAKE_CASE_STUDIES
ON chunk
ATTRIBUTES file_name, case_study_name, header_1, header_2, header_3, chunk_index, last_modified
WAREHOUSE = CORTEX_SEARCH_WH
TARGET_LAG = '365 day'
EMBEDDING_MODEL = 'voyage-multilingual-2'
INITIALIZE = ON_CREATE
COMMENT = 'Snowflake導入事例PDFのチャンクデータに対するCortex Search Service'
AS
SELECT
file_name,
case_study_name,
header_1,
header_2,
header_3,
chunk_index,
chunk,
last_modified
FROM PROD_DB.CORPUS_SAMPLE.COR_SNOWFLAKE_CASE_STUDIES_PARSED;
-- Agent作成
CREATE OR REPLACE AGENT PROD_DB.AIML_SAMPLE.AGENT_SNOWFLAKE_CASE_STUDIES
COMMENT = 'Snowflake導入事例PDFを検索・回答するCortex Agent'
PROFILE = '{"display_name": "Snowflake事例検索", "avatar": "search", "color": "#29B5E8"}'
FROM SPECIFICATION
$$
instructions:
system: |
あなたはSnowflake導入事例PDFの内容について質問に回答するアシスタントです。
ユーザーからの質問に対して、Cortex Search Serviceを使って関連する事例情報を検索し、
正確な情報に基づいて回答してください。
検索結果に含まれない情報については、推測せずにその旨を伝えてください。
response: |
日本語で簡潔に回答してください。
回答には参照した事例名(case_study_name)を明記してください。
tools:
- tool_spec:
type: "cortex_search"
name: "SearchCaseStudies"
description: "Snowflake導入事例PDFの検索"
tool_resources:
SearchCaseStudies:
name: "PROD_DB.AIML_SAMPLE.CSS_SNOWFLAKE_CASE_STUDIES"
max_results: "5"
$$;
-- Snowflake Intelligence への追加
ALTER SNOWFLAKE INTELLIGENCE SNOWFLAKE_INTELLIGENCE_OBJECT_DEFAULT
ADD AGENT PROD_DB.AIML_SAMPLE.AGENT_SNOWFLAKE_CASE_STUDIES;
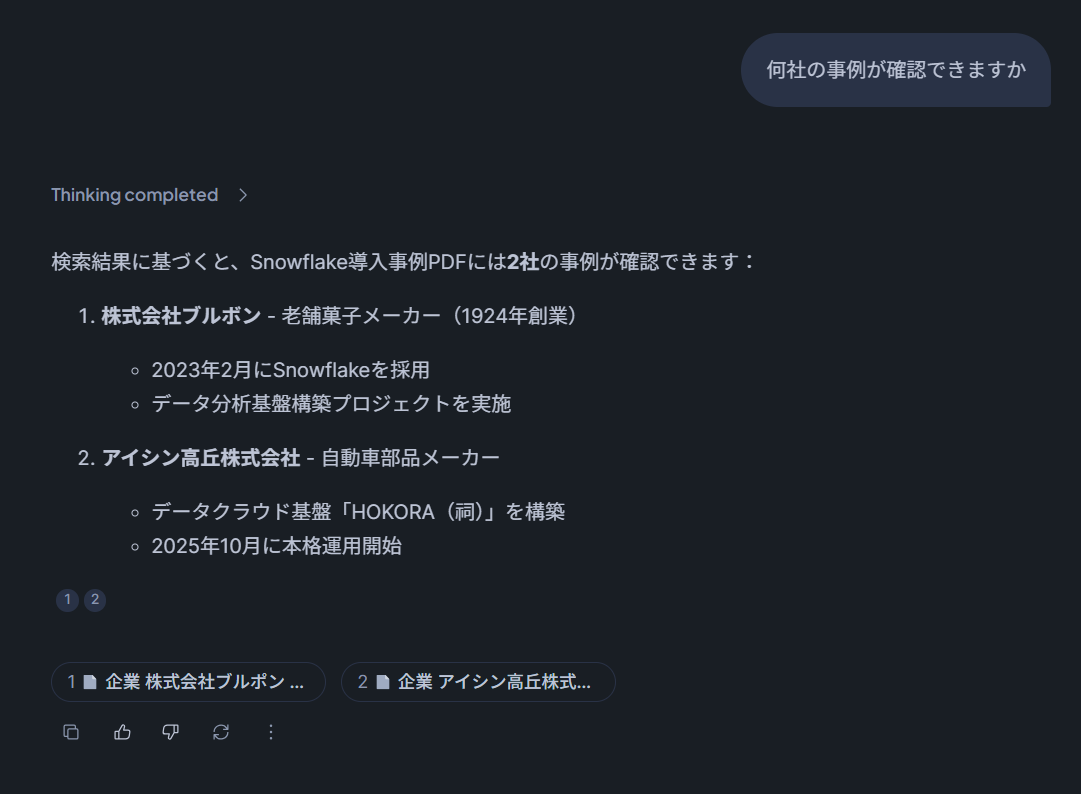
この上でSnowflake Intelligenceから問い合わせすると、下図のように結果を得られます。
S3バケットのデータを更新し、dbt model 2回目の実行
まず、差分更新がちゃんと効いているかを検証するため、S3バケットに以下2ファイルの変更を加えます。
- アイシン高丘様の事例のPDFの2ページ目を削除し、同じファイル名でS3バケットに配置
- 千葉銀行様の事例のPDFファイルを新規でS3バケットに配置
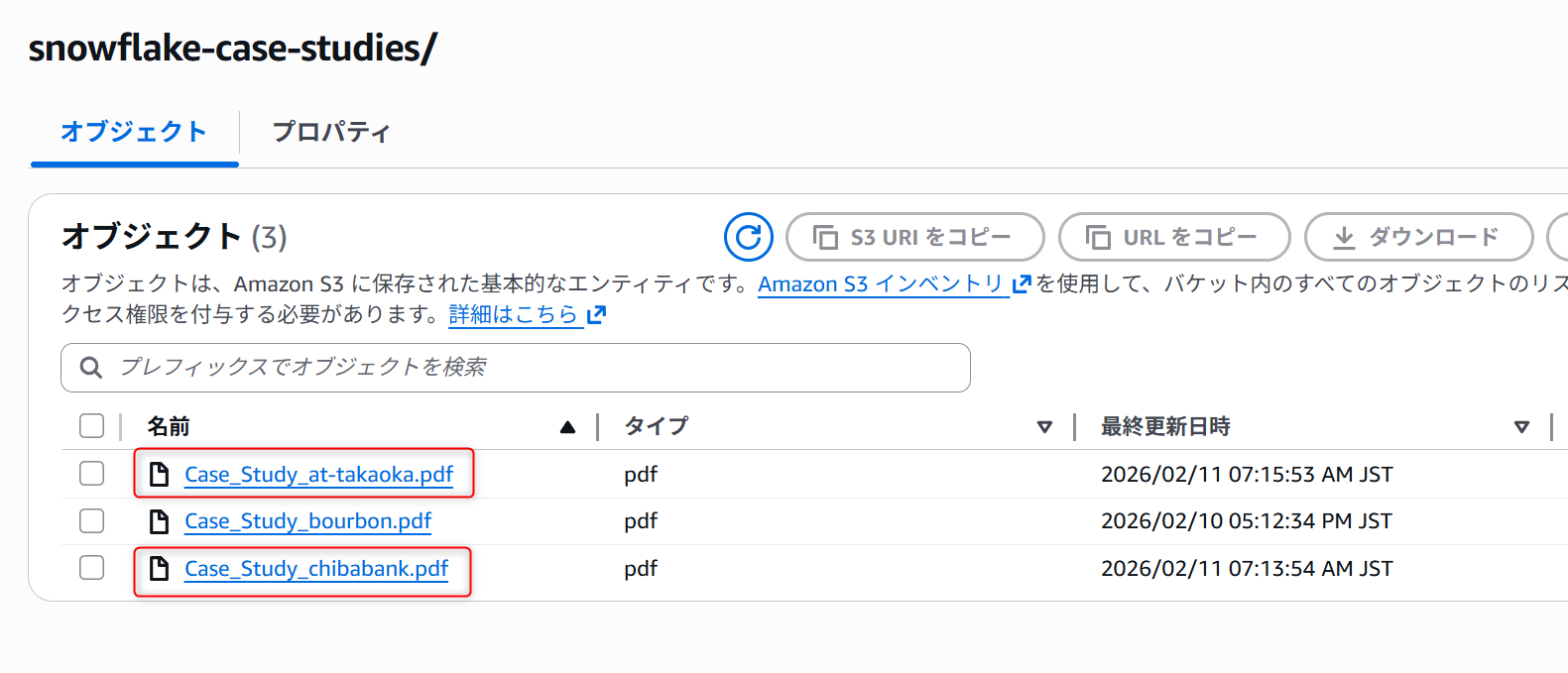
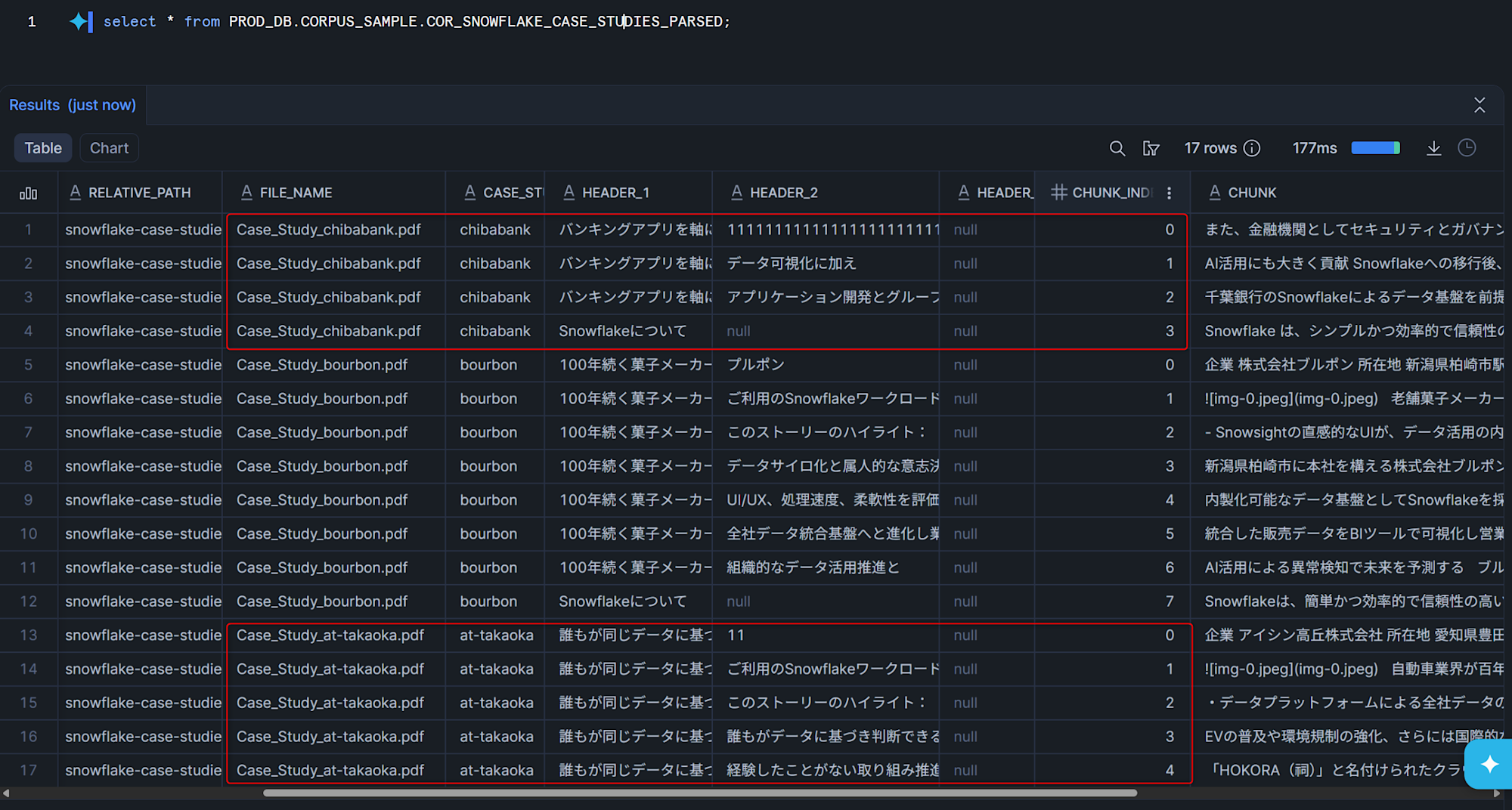
この状態で、dbt modelをdbt buildなどで実行して更新すると、アイシン高丘様のページ数が減ったためチャンク数が減っており、新しく千葉銀行様のレコードが追加されていることがわかります。
また、パースを行ったタイムスタンプを記録する_PARSED_AT列を見ると、差分があったアイシン高丘様と千葉銀行様のレコードのみ、タイムスタンプが更新されていることがわかります。
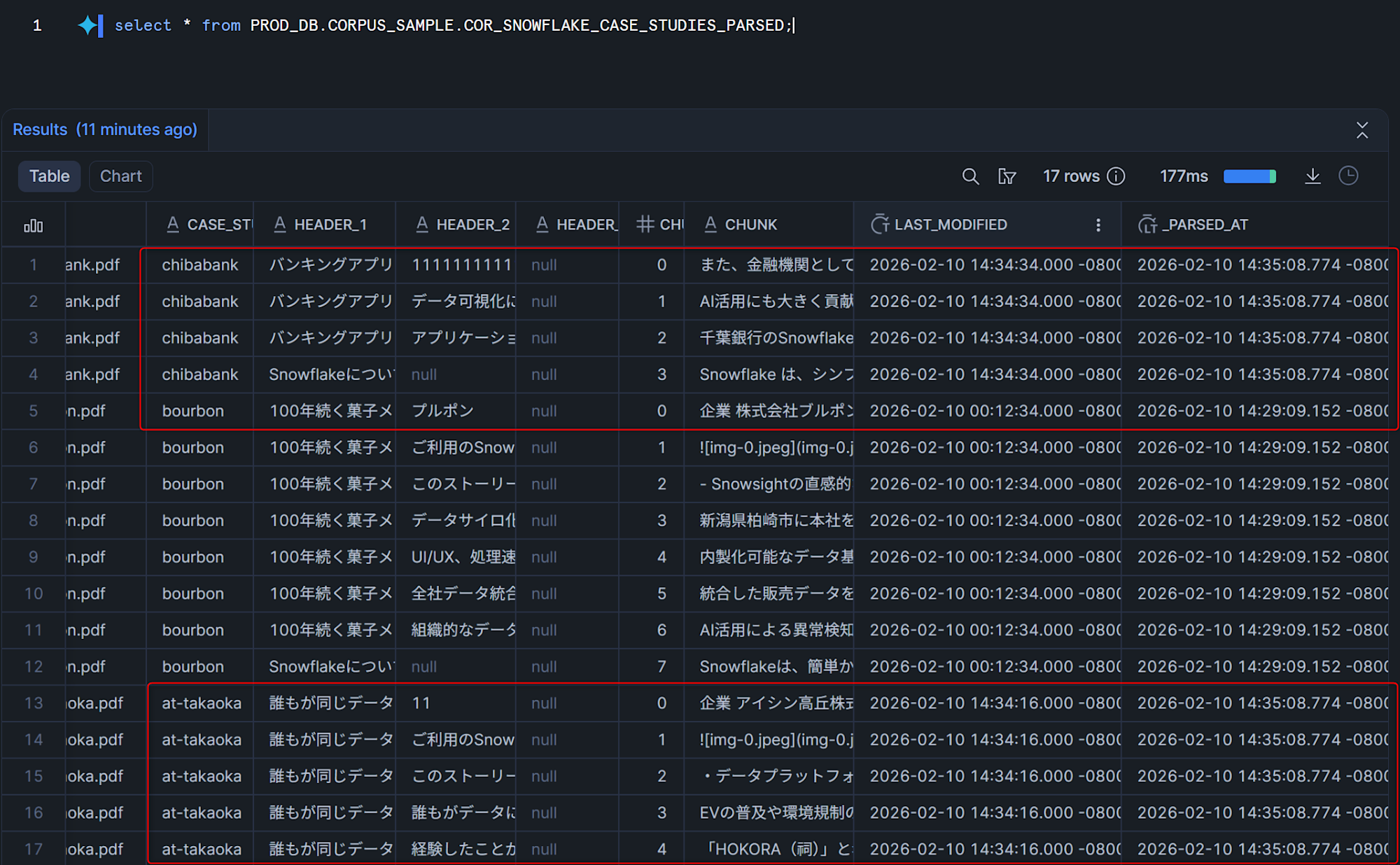
テーブルが更新できたので、以下のクエリを実行してCortex Search Serviceも更新します。
ALTER CORTEX SEARCH SERVICE PROD_DB.AIML_SAMPLE.CSS_SNOWFLAKE_CASE_STUDIES REFRESH;
この状態でSnowflake Intelligenceから再度質問をしてみると、更新したデータに対して問い合わせできていることがわかります。
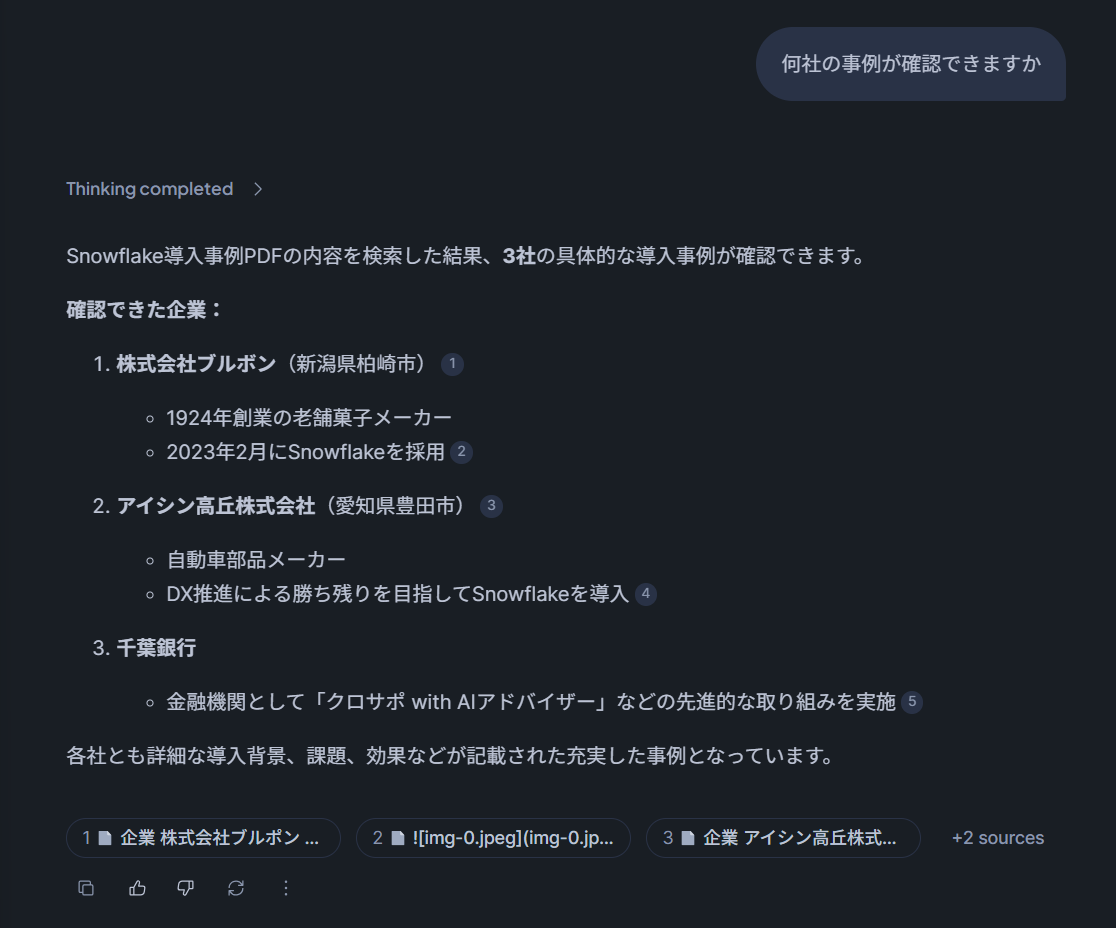
最後に
Cortex Search Service用にPDFをパースしてチャンキングするdbtのIncremental modelを考えてみたので、その内容についてまとめてみました。
dbtのIncremental modelを使うことで、差分が発生したファイルだけ検知してAI_PARSE_DOCUMENT関数の対象とできるので、コストを削減できます。
ぜひご活用ください!








