
2026年4月にリリースされたSnowflakeの新機能・変更点のまとめ #SnowflakeDB
2026年4月にリリースされたSnowflakeの新機能・変更点のまとめ記事になります。
※注意事項:本記事ではすべての情報についての記述はせず、特筆すべきだと感じた情報だけピックしております。基本的には以下の情報を参考にしておりますので、全ての最新情報を確認したい場合は下記のURLからご確認ください。
10.14 Release Notes: Apr 20, 2026-Apr 23, 2026
セッションポリシーで最大セッション有効期限の設定が可能に
セッションポリシーで、アイドル状態に関わらず設定期間が経過したら強制的にセッションを終了する最大セッション有効期限を設定できるようになりました。
これにより、一定時間ごとに再認証を強制させることができ、セキュリティポリシー上の要件への対応が容易になります。
具体的には、セッションポリシーに新しいプロパティが2つ追加されました。
SESSION_MAX_LIFESPAN_MINS:サービスなどの Snowflake クライアント向けSESSION_UI_MAX_LIFESPAN_MINS:Snowsight 用
値が0(デフォルト値)の場合は、最大有効期間の制限は適用されません。
詳細は以下をご参照ください。
スキーマレベルでのデータメトリック関数(DMF)の関連付けが一般提供
これまでデータメトリック関数(DMF)はテーブル単位での関連付けが必要でしたが、スキーマ内の全テーブルに一括でDMFを適用できるようになりました。
これにより、スキーマ全体のデータ品質を効率的に監視できます。
スキーマレベルの関連付けでは、SNOWFLAKE.CORE.ROW_COUNTとSNOWFLAKE.CORE.FRESHNESSの指定が可能です。
関連付けの際は、EXCLUDE_TABLE_TYPESを指定することで、指定されたタイプのすべてのオブジェクトは除外するなどの制御も可能です。
詳細は以下をご参照ください。
ダイナミックテーブルの増分更新モードで外部結合パターンの対応範囲が拡大
ダイナミックテーブルの増分更新モードにおいて、以下の外部結合パターンがサポートされました。
- 同一テーブル同士の外部結合
- 階層構造の展開などの自己結合のユースケースで増分更新が効くようになります
- GROUP BY付きサブクエリ同士の外部結合
- 集計済みデータ同士を結合するパターンで利用できます
詳細は以下をご参照ください。
ACCUMULATE 集計関数
ユーザー定義の SQL ラムダ関数4つを組み合わせてカスタムの集計計算を行えるACCUMULATE関数が追加されました。
1回の走査で複数統計を作りたいケースや、組み込み関数にない独自ロジックで集約したい場合に使用できます。
例として、以下のテーブルがあるとします。
CREATE OR REPLACE TEMP TABLE T (c1 INT);
INSERT INTO T VALUES (2), (3), (4);
>SELECT * FROM T;
+----+
| C1 |
|----|
| 2 |
| 3 |
| 4 |
+----+
ここで、列の数値を全部掛け合わせた値を求めたい場合、以下のように使用できます。
SELECT ACCUMULATE(
c1, -- 各行の c1 を入力値として使う
(v INT) -> v,
-- 最初の行を初期値にする
-- 例: 最初の行が 2 なら state = 2
(state INT, v INT) -> state * v,
-- 今までの積(state)に次の行の値(v)を掛ける
-- 例:
-- 1行目: state = 2
-- 2行目: state = 2 * 3 = 6
-- 3行目: state = 6 * 4 = 24
(state1 INT, state2 INT) -> state1 * state2,
-- 並列処理で分かれた部分結果どうしを掛け合わせる
-- 例:
-- ワーカーA: 2*3 = 6
-- ワーカーB: 4
-- 結合: 6*4 = 24
(state INT) -> state
-- 最後に state をそのまま結果として返す
) AS product
FROM T;
+---------+
| PRODUCT |
|---------|
| 24 |
+---------+
その他、初期状態で ARRAY などにまとめて渡すことで、複数カラムを使うことも可能です。
詳細は以下をご参照ください。
Apr 30, 2026: AI_PARSE_DOCUMENT
ページ制限が2,000ページに増加
AI_PARSE_DOCUMENT関数で処理できるドキュメントのページ上限が 2,000 ページまで対応するようになりました。
これまでは大規模なドキュメントを事前に分割して処理する必要がありましたが、本アップデートにより、大量ページを持つドキュメントを1回のリクエストで処理できるようになります。LAYOUT・OCR のいずれのモードでも 2,000 ページまで対応しています。
詳細は以下をご参照ください。
image extraction が一般提供
AI_PARSE_DOCUMENT関数の LAYOUT モードにおける画像抽出機能が一般提供となりました。
これにより、ドキュメントからテキストと合わせて画像(チャート・署名・グラフィックス等)を抽出できるようになり、マルチモーダルなドキュメント処理が可能になります。抽出した画像とテキストを組み合わせることで、RAG(検索拡張生成)の精度向上も期待できます。
extract_images: trueを指定することで画像抽出が有効になります。
SELECT AI_PARSE_DOCUMENT(
TO_FILE('@my_stage', 'my_document.pdf'),
{'mode': 'LAYOUT', 'extract_images': true}
) AS layout_with_images;
出力の JSON には images 配列が含まれ、各要素には Base64 エンコードされた画像データ(image_base64)・一意の識別子(id)・ドキュメント上の位置情報(bounding boxes)が格納されます。抽出した画像はBASE64_DECODE_BINARYでデコードしてAI_EXTRACT等に渡すことで、画像内容の説明生成も可能です。
なお、1ドキュメントあたり最大50枚まで抽出でき、追加費用は発生しません(ページ処理費用に含まれ、画像ファイル1つにつき1ページとみなされます)。
詳細は以下をご参照ください。
Apr 30, 2026: Create tags and expanded Tags & policies coverage in Snowsight (パブリックプレビュー)
Snowsight 上でタグを直接作成できるようになりました。
「Governance & security > Tags & policies」から「Tags」タブ内の「+ Create tag」により、UI 上からタグを作成できます。
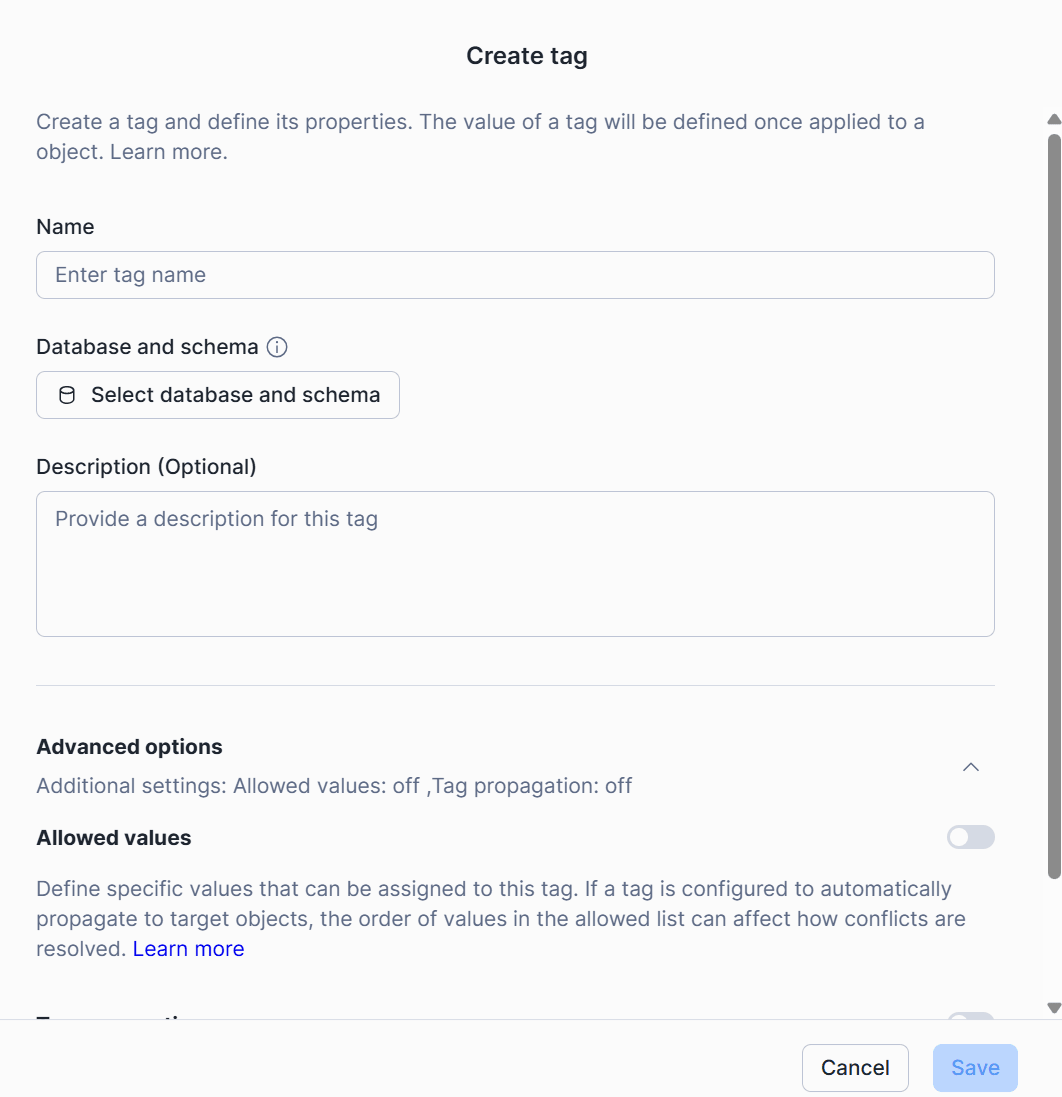
また、アカウントのオブジェクトタイプ全体におけるタグ付けの適用範囲の概要が表示されるようになりました。
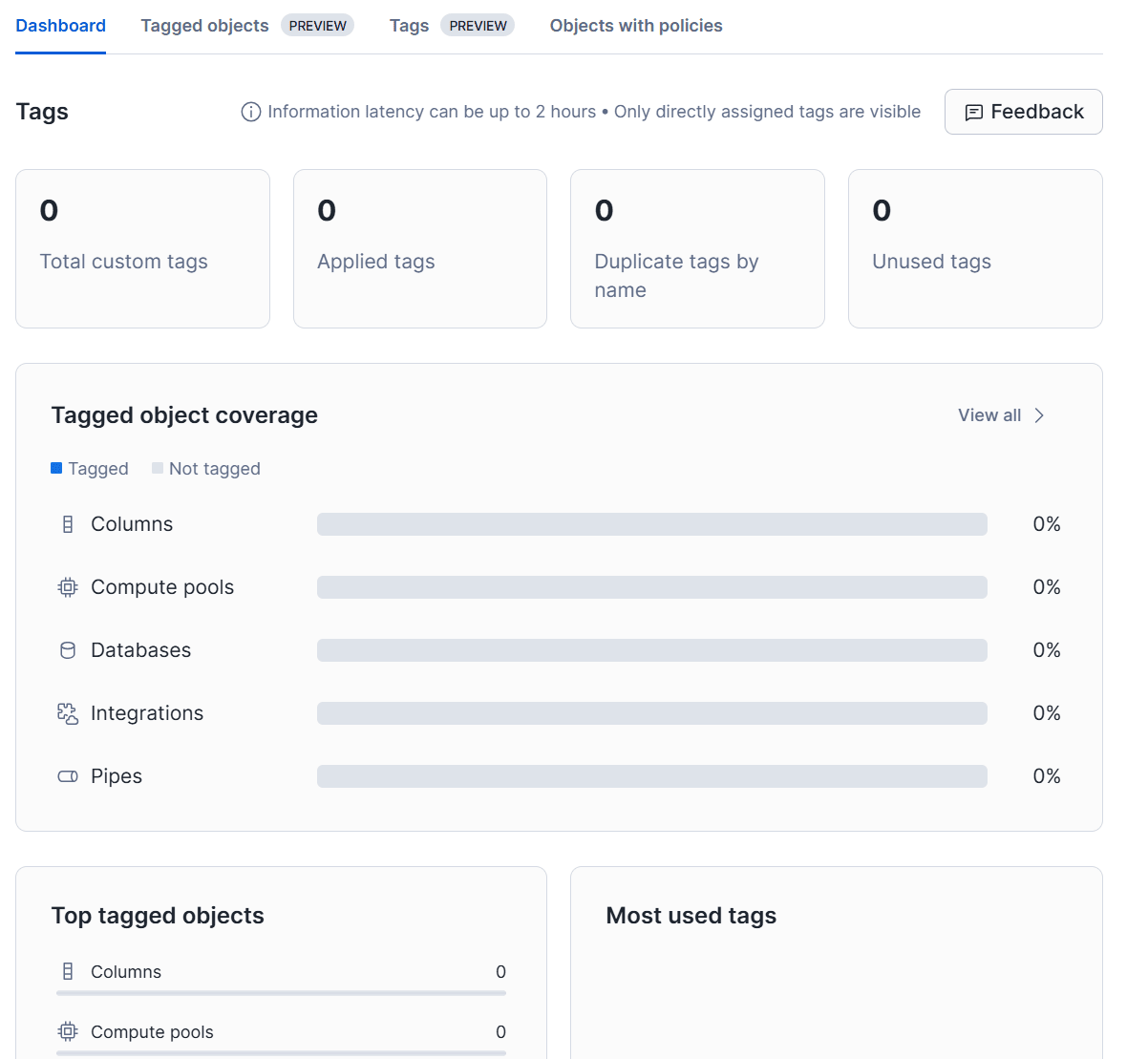
詳細は以下をご参照ください。
Apr 29, 2026: Trust Center detections が一般提供
Trust Center の検出(Detections)が一般提供となりました。
従来の違反(Violations)とは異なり、アカウント内で発生した特定のイベントや挙動をスキャナが記録する「イベント型の検知」となります。これにより、現時点の設定の状態だけでなく、「いつ・何が起きたか」という観点から評価項目を把握できます。
また、これを生成するスキャナとしてイベント駆動(Event-driven)型が新たに追加されました(従来のスケジュール型でも Detections を生成するものがあります)。
イベント駆動型のスキャナは特定のイベント発生をトリガーに継続監視を行います。
イベント駆動型のスキャナの最新の一覧は、Threat Intelligence scanner package に記載があります。
詳細は以下をご参照ください。
Apr 24, 2026: Data Security in the Trust Center が一般提供
Trust Center の Data Security 機能が一般提供となりました。
SQL を記載することなく、指定のデータベース全体にわたって PII などの機密データを自動分類・識別できる機能です。機密データの所在を統合ビューで確認したり、コンプライアンス義務へのマッピング状況やマスキングポリシーの適用状況を把握したりできます。
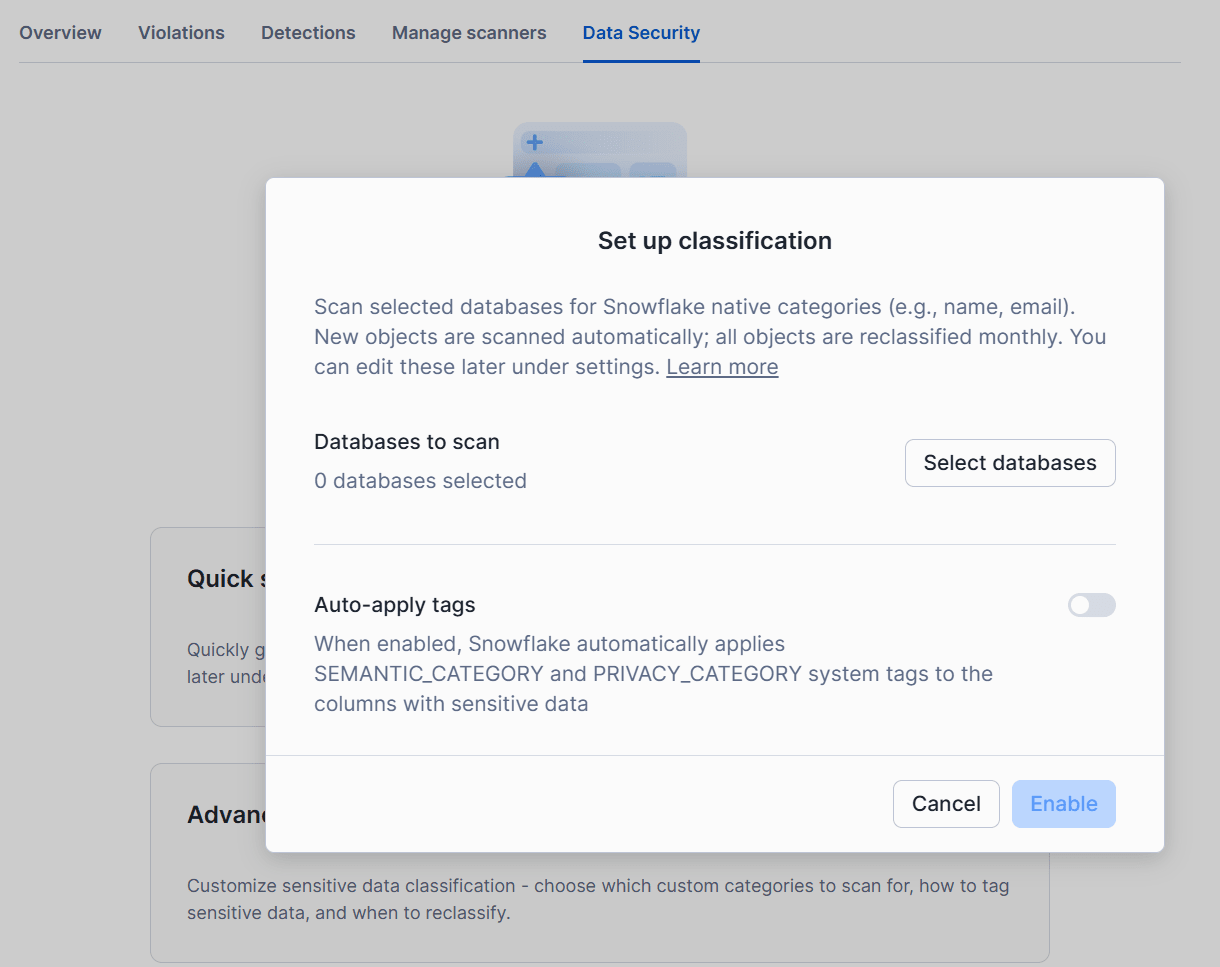
詳細は以下をご参照ください。
Apr 24, 2026: Storage lifecycle policies が Google Cloud でもサポート
Google Cloud でホストされているアカウントで、COOL または COLD ストレージ ティアを使用するアーカイブ ポリシーを作成できるようになりました。
今回のアップデートにより AWS・Microsoft Azure・Google Cloud の各クラウドプロバイダー全体でアーカイブポリシーを使用できるようになりす。
詳細は以下をご参照ください。
Apr 20, 2026: Cortex AI Guardrails が一般提供
Cortex Code におけるプロンプトインジェクションやジェイルブレイク攻撃に対する保護機能である Cortex AI Guardrails が一般提供となりました。
Snowflake Horizon Catalog の一部として提供されており、AIを活用したアプリケーション開発においてエンタープライズレベルのセキュリティを確保できます。
アカウントで Cortex AI Guardrails を有効にするには、以下のように ALTER ACCOUNT コマンドに AI_SETTINGS パラメーターを指定します。
ALTER ACCOUNT SET AI_SETTINGS = $$
guardrails:
advanced_prompt_injection:
- enabled: true
$$;
Cortex AI Guardrails の利用には、100万トークンあたり 0.35 クレジット消費されます。
詳細は以下をご参照ください。
Apr 20, 2026: Apache Iceberg tables: 外部カタログからのテーブルおよび列の説明の伝播が一般提供
Snowflake と外部 Iceberg カタログ(AWS Glue・Databricks Unity Catalog・Apache Polaris など)間で、テーブルおよびカラムの説明を双方向に同期できるようになりました。
外部カタログの説明を Snowflake へ取り込むだけでなく、Snowflake 側で設定した説明を外部カタログに書き戻すことも可能です。
説明の同期には以下のルールが適用されます。
- 外部カタログに説明があり、Snowflake 側に説明がない場合: カタログリフレッシュ時に外部カタログの説明が Snowflake へコピーされます
- Snowflake 側に
COMMENTが設定されており、外部カタログの説明が空の場合: Snowflake の説明が外部カタログへ書き戻されます - 双方に異なる説明が存在する場合: 直近の同期操作の方向によって優先順位が決まります。カタログリフレッシュ時はカタログ側の説明が優先され、Snowflake からカタログへの書き込み時は Snowflake 側の説明が優先されます
なお、同期によって既存の説明が上書きされることはあっても、空でない説明が空に置き換えられることはありません。
詳細は以下をご参照ください。
Apr 16, 2026: 動的テーブルにおける主キーのサポート(一般提供)
ダイナミックテーブルでプライマリキーのサポートが一般提供となりました。
これは、以下の主キーを使用するシナリオで役立ち、コストと遅延の大幅削減が期待できます。
INSERT OVERWRITE 時の差分処理
これまで、ベーステーブルが INSERT OVERWRITE で更新されると、データが変わっていない行も含めて全行が変更扱いとなり、下流のダイナミックテーブルは全行を再処理していました。
ベーステーブルに RELY プロパティ付きの主キー制約(PRIMARY KEY RELY)がある場合、主キーで新旧データを突き合わせ、実際に値が変わった行だけを検出して下流のダイナミックテーブルを差分処理できるようになります。
フルリフレッシュDTの下流DTの増分更新
これまで、フルリフレッシュモードのダイナミックテーブルの下流にあるダイナミックテーブルは、必ずフルリフレッシュされていました。
上流のフルリフレッシュ DT にシステム導出の一意キー(GROUP BY や QUALIFY ROW_NUMBER()=1から自動導出)がある場合、フルリフレッシュ間の差分を計算できるため、下流のダイナミックテーブルを増分更新できるようになります。
なお、下流 DT には REFRESH_MODE = INCREMENTAL の明示指定が必要です。導出キーの有無はSHOW UNIQUE KEYS IN <DT名>で確認できます。
詳細は以下をご参照ください。
Apr 15, 2026: Snowflake documentation for AI agents and LLMs
AI コーディングアシスタントやエージェントが Snowflake のドキュメントを活用しやすくするための改善が行われました。
- *層的な llms.txt ファイル
- 従来の単一の大規模ファイルからセクション別のインデックス構造へ移行しました。エージェントが必要なセクションのみを取得できるため、トークン使用量の削減と関連性の向上が期待できます
- 全ページの Markdown 版提供
- ドキュメントのURLの末尾に
.mdを付加することで、HTML より軽量な Markdown 形式でアクセスできるようになりました - Cortex Code・Cursor・Claude Code などのツールから直接 URL をコンテキストとして活用しやすくなります
- ドキュメントのURLの末尾に

Apr 15, 2026: Openflow Connector for HubSpot がパブリックプレビュー
HubSpot の CRM データを Snowflake に取り込むための Openflow コネクタがパブリックプレビューとなりました。
初回は完全ロードを実行し、以降は前回実行時のタイムスタンプを基に新規・更新レコードを増分でマージします。HubSpot で管理している顧客データや営業情報を Snowflake に統合し、高度なデータ分析や BI 活用が可能になります。
詳細は以下をご参照ください。
Apr 14, 2026: Cortex Search のリクエスト監視機能がパブリックプレビュー
Cortex Search Service のリクエストをモニタリングできる機能がパブリックプレビューとなりました。
リクエストログを有効にすると、クエリパターン・レスポンス時間・リクエスト詳細などの情報が収集され、SNOWFLAKE.LOCAL.AI_OBSERVABILITY_EVENTSイベントテーブルに保存されます。snowflake.local.get_ai_observability_events関数またはイベントテーブルへの直接クエリからアクセスでき、Cortex Search Service の動作把握や問題のデバッグに活用できます。
既存のサービスであれば以下のようにリクエストログを有効化できます。
ALTER CORTEX SEARCH SERVICE my_search_service SET REQUEST_LOGGING = TRUE;
詳細は以下をご参照ください。
Apr 14, 2026: Cortex Search Service のレプリケーションが一般提供
Cortex Search Service のレプリケーション機能が一般提供となりました。
レプリケーショングループまたはフェイルオーバーグループを使用して、ソースアカウントから同一組織内の別アカウントに Cortex Search Service を複製できます。
詳細は以下をご参照ください。
Apr 14, 2026: Snowflake ストレージを使用する Apache Iceberg tables がパブリックプレビュー
Snowflake のストレージを使用して Apache Iceberg テーブルを作成・管理できる機能がパブリックプレビューとなりました。
これまで Iceberg テーブルは外部クラウドストレージ(AWS S3・Azure Blob Storage 等)へのアクセス設定が必要でしたが、本機能では Snowflake がファイル管理を担当するため外部ストレージのセットアップが不要です。
標準の Snowflake テーブルと同様に Fail-safe によるデータ保護も有効になります。Snowflake Horizon Catalog を通じた外部クエリエンジンからのアクセスもサポートされています。
詳細は以下をご参照ください。
Apr 13, 2026: ダイナミック Iceberg テーブルでの PARTITION BY, TARGET_FILE_SIZE, PATH_LAYOUT のサポートが一般提供
ダイナミック Iceberg テーブルで、以下の3つのテーブルプロパティが一般提供となりました。
- PARTITION BY
- identity・bucket・truncate・year・month・day・hour などの変換式を使用したパーティショニングが可能になりました
- TARGET_FILE_SIZE
- Parquet ファイルのターゲットサイズを指定できます。デフォルトは
AUTO(Snowflake が最適サイズを自動選択)です
- Parquet ファイルのターゲットサイズを指定できます。デフォルトは
- PATH_LAYOUT
- データファイルの保存ディレクトリ構造として、フラット構造または Hive 形式の階層構造を選択できます。
PARTITION BYと組み合わせるとパーティション対応パスへの書き込みが可能です
- データファイルの保存ディレクトリ構造として、フラット構造または Hive 形式の階層構造を選択できます。
詳細は以下をご参照ください。
Apr 10, 2026: Budgets for AI features (一般提供)
AI 機能向けのカスタム予算管理機能が一般提供となりました。
予算での Cortex Agents, Snowflake Intelligence の他 AI Functions・Cortex Code のクレジット消費をトラッキング・管理できます。
また、ユーザーにタグを付与することで、特定チームやコストセンター単位での AI クレジット消費を分別して把握できます。
詳細は以下をご参照ください。
10.12 Release Notes (with behavior changes): Apr 03, 2026-Apr 08, 2026
CHECK 制約(標準テーブル)が一般提供
テーブルの列に挿入・更新できる値を条件式で制限できる CHECK 制約が一般提供となりました。列定義内またはテーブル作成時に条件式を指定でき、違反する値の挿入・更新はエラーとなります。
以下のように使用できます。
-- テスト用テーブル作成
CREATE OR REPLACE TABLE CHK_ORDERS (
order_id INT,
quantity INT CHECK (quantity > 0),
price NUMBER(10,2),
max_price NUMBER(10,2),
status VARCHAR(20) CHECK (status IN ('pending', 'shipped', 'delivered', 'cancelled')),
CONSTRAINT chk_price_range CHECK (price > 0 AND price <= max_price)
);
-- CHECK 制約の確認
> SELECT constraint_name, check_clause FROM INFORMATION_SCHEMA.CHECK_CONSTRAINTS
WHERE CONSTRAINT_SCHEMA = '<スキーマ名>';
+-----------------------------------------------------+------------------------------------------------------------+
| CONSTRAINT_NAME | CHECK_CLAUSE |
|-----------------------------------------------------+------------------------------------------------------------|
| SYS_CONSTRAINT_7f0ee020-0d8c-4e26-91c7-4d89c8057ba4 | quantity > 0 |
| CHK_PRICE_RANGE | price > 0 AND price <= max_price |
| SYS_CONSTRAINT_8cc9c981-4b05-42f1-a1ca-7cd5f3e42835 | status IN ('pending', 'shipped', 'delivered', 'cancelled') |
+-----------------------------------------------------+------------------------------------------------------------+
名前付き制約(chk_price_range)は指定した名前で、列定義内の無名制約はシステム名(SYS_CONSTRAINT_...)が自動付与されていました。
-- 正常データの挿入 → 成功
INSERT INTO DBT_SL_DB.DBT_TYASUHARA.CHK_ORDERS VALUES
(1, 10, 100.00, 200.00, 'pending');
-- number of rows inserted: 1
-- quantity <= 0 → 失敗
INSERT INTO DBT_SL_DB.DBT_TYASUHARA.CHK_ORDERS VALUES
(2, -5, 100.00, 200.00, 'pending');
-- 001185 (23514): CHECK constraint requires that quantity > 0, was violated
-- 無効なstatus → 失敗
INSERT INTO DBT_SL_DB.DBT_TYASUHARA.CHK_ORDERS VALUES
(4, 5, 100.00, 200.00, 'unknown');
-- 001185 (23514): CHECK constraint requires that status IN ('pending', 'shipped', 'delivered', 'cancelled'), was violated
-- UPDATEでの制約違反 → 失敗
UPDATE DBT_SL_DB.DBT_TYASUHARA.CHK_ORDERS
SET quantity = -1 WHERE order_id = 1;
-- 001185 (23514): CHECK constraint requires that quantity > 0, was violated
詳細は以下をご参照ください。
Dynamic Table Refresh Boundaries が追加
デフォルトでは、あるダイナミックテーブルが別のダイナミックテーブルを参照すると、両者は同一パイプラインとして扱われ、リフレッシュが連動(下流のリフレッシュが上流もトリガー)されます。
DYNAMIC_TABLE_REFRESH_BOUNDARY()関数を使用することで、上流のダイナミックテーブルと下流のテーブルが同時にリフレッシュされることを防げるようになりました。
CREATE DYNAMIC TABLE data_eng.enriched_clicks_dt
WAREHOUSE = de_wh
TARGET_LAG = '5 minutes'
AS
SELECT
c.*,
p.product_name
FROM data_eng.clickstream_dt AS c
LEFT JOIN DYNAMIC_TABLE_REFRESH_BOUNDARY(product_db.active_products_view) AS p
ON c.product_id = p.product_id;
これにより、パイプライン内の各ダイナミックテーブルを独立してリフレッシュできるようになります。
注意点として、2つのテーブルが同じ瞬間のデータでなければ結果がおかしくなるような、スナップショット分離が必要な依存関係には使わないようにします。
詳細は以下をご参照ください。
Trust Center 検出結果のプログラマティック通知がパブリックプレビュー
Trust Center の検出結果を外部サービスへ通知できる機能がパブリックプレビューとなりました。
PagerDuty・Slack・Microsoft Teams 等の Webhook や、AWS SNS・Azure Event Grid・Google Cloud Pub/Sub 等のキューを使用する通知統合機能と連携できます。これにより、Snowsight を確認しなくても、監視ツール側でアラートを受け取るように構成できます。
詳細は以下をご参照ください。
Apr 7, 2026: Workspaces replication (General availability)
Workspaces のレプリケーション機能が一般提供となりました。
ワークスペースまたはそのオーナーユーザーがレプリケーショングループ内にある場合、ワークスペースがセカンダリアカウントに複製されるようになりました。セカンダリアカウントの複製ワークスペースは読み取り専用(ファイルの実行は可)ですが、フェイルオーバー時にプライマリへ昇格すると書き込み可能になります。
本機能の使用には、Business Critical 以上でのエディションが必要です。
詳細は以下をご参照ください。
Apr 6, 2026: AI_SERVICES billing breakout for implemented AI Credits services
これまでAI_SERVICESとしてまとめて請求されていた一部の AI サービスが、個別の請求区分に分離されました。
| サービス | 新しい請求区分 |
|---|---|
| Cortex Agents | CORTEX_AGENTS |
| Cortex Code CLI | CORTEX_CODE_CLI |
| Cortex Code UI | CORTEX_CODE_SNOWSIGHT |
| Snowflake Intelligence | SNOWFLAKE_INTELLIGENCE |
この変更はMETERING_HISTORYおよびMETERING_DAILY_HISTORYビューに反映されます。
各 AI サービスのクレジット消費をより詳細に把握・管理できるようになります。なお、AI Functions・Cortex Analyst・Cortex Search・Cortex Fine Tuning 等は引き続きAI_SERVICESとして請求されます。
Apr 6, 2026: Apache Iceberg tables: Azure 上の Databricks Unity カタログの書き込みサポート (一般提供)
Databricks Unity Catalog で管理される外部 Iceberg テーブルへの書き込みサポートが、Azure(Azure Data Lake Storage Gen2)でも一般提供となりました。
これまで本機能はストレージが AWS 上にあるワークスペースに限定されていましたが、今回のアップデートで Azure にも対応し、クラウドプロバイダーをまたいだ Iceberg テーブル管理の選択肢が広がりました。
詳細は以下をご参照ください。
Apr 5, 2026: セマンティックビューにおける検証済みクエリのサポート
セマンティックビューの定義時に検証済みクエリ(verified queries)を追加できるようになりました。
CREATE SEMANTIC VIEWコマンド内のAI_VERIFIED_QUERIES句で検証済みクエリを指定することで、Cortex Analyst の回答精度と信頼性を向上させることができます。事前に正解クエリを登録しておくことで、類似の質問に対して正確なSQLが生成されやすくなります。
以下のように登録できます。
AI_VERIFIED_QUERIES (
total_orders_by_status AS (
QUESTION 'What is the total number of orders by status?'
VERIFIED_AT 1777939200
ONBOARDING_QUESTION TRUE
VERIFIED_BY '(STEWARD = XXXX)'
SQL 'SELECT o.status, COUNT(o.order_id) AS order_count FROM o GROUP BY o.status ORDER BY order_count DESC'
),
orders_per_customer AS (
QUESTION 'How many orders does each customer have?'
VERIFIED_AT 1777939200
ONBOARDING_QUESTION FALSE
VERIFIED_BY '(STEWARD = XXXX)'
SQL 'SELECT c.full_name, COUNT(o.order_id) AS order_count FROM o JOIN c ON o.customer_id = c.customer_id GROUP BY c.full_name ORDER BY order_count DESC'
)
)
各パラメーターの意味は以下の通りです。
QUESTION:自然言語の質問SQL:検証済みのSQLVERIFIED_AT:UNIXタイムスタンプVERIFIED_BY:クエリが質問に回答していることを確認した担当者の名前(Contactオブジェクト)ONBOARDING_QUESTION:TRUEを設定すると、Cortex Analyst UIで最初に表示される提案質問になります
Snowsight でも登録されていることが確認できます。
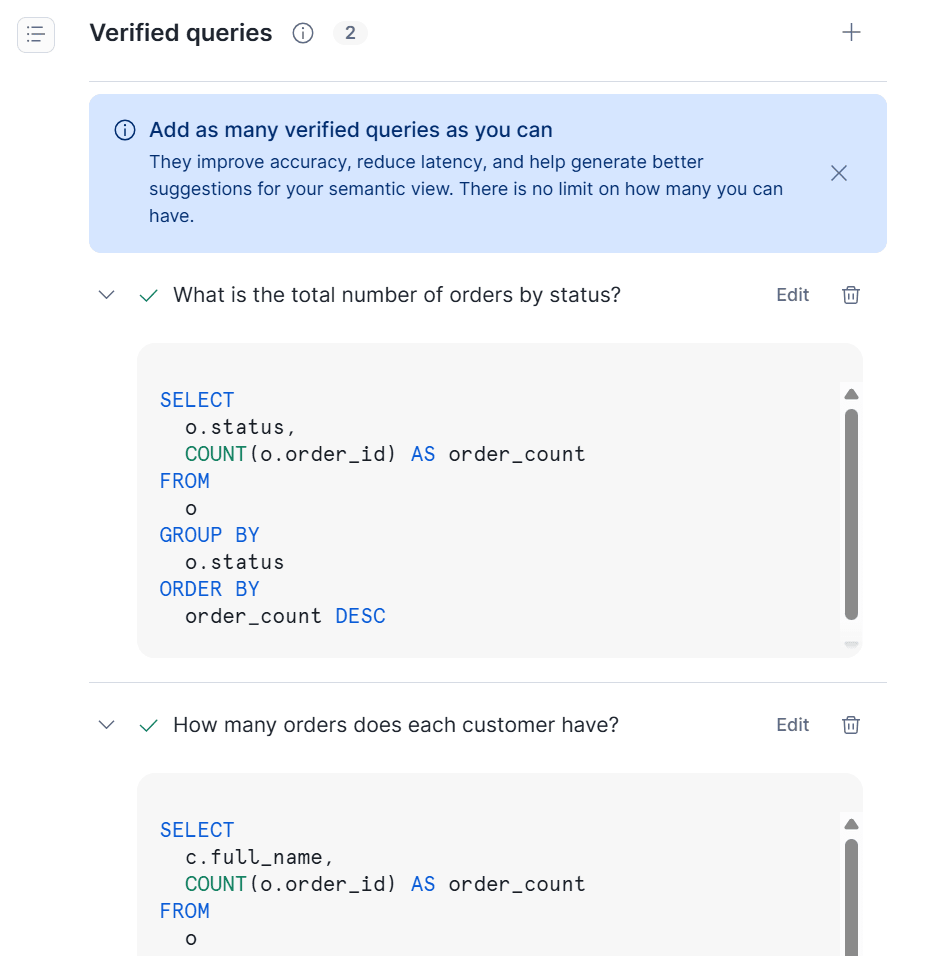
詳細は以下をご参照ください。
Apr 3, 2026: 機密データ分類における医療・健康データ分類器 (一般提供)
機密データ分類での医療・健康関連データの分類機能が一般提供となりました。
新たにMEDICAL_DATAとMEDICAL_SPECIALTYの2つのセマンティックカテゴリが追加され、ICD(国際疾病分類)コード・検査用語・医学的状態・医療手技・医薬品名(ブランド名・ジェネリック名を含む)などを検出・タグ付けできます。
詳細は以下をご参照ください。
Apr 2, 2026: AI_COMPLETE document intelligence (一般提供)
マルチモーダル対応のAI_COMPLETE関数でドキュメント入力が一般提供となりました。
これまでテキストと画像の入力に対応していたAI_COMPLETE関数が、内部ステージと外部ステージ上のドキュメント入力をサポートするようになりました。
図表をドキュメント全体に対して推論・要約などが可能です。
詳細は以下をご参照ください。
Apr 2, 2026: AI_FUNCTIONS_USER database role (一般提供)
SNOWFLAKE データベースにAI_FUNCTIONS_USERデータベースロールが追加され、Cortex AI 関数へのアクセスをより細かく制御できるようになりました。
CORTEX_USERとの違いは以下の通りです。
| ロール | デフォルト付与 | アクセス範囲 |
|---|---|---|
CORTEX_USER |
PUBLIC(全ユーザー) | Cortex スカラー AI 関数 + Cortex Agent・Analyst・Fine-tuning・Search などのサービス |
AI_FUNCTIONS_USER |
付与なし(明示的に付与が必要) | Cortex スカラー AI 関数のみ(AI_AGG・AI_SUMMARIZE_AGGを除く) |
AI_FUNCTIONS_USERは、Cortex Agent や Cortex Analyst などのサービスへのアクセスを許可せず、AI 関数(AI_COMPLETE・AI_EXTRACT等)だけを有効化したい場合に適しています。
なお、Cortex AI 関数を呼び出すにはUSE AI FUNCTIONSアカウント権限と、CORTEX_USERまたはAI_FUNCTIONS_USERデータベースロールのいずれかが必要です。USE AI FUNCTIONSはデフォルトで PUBLIC ロールに付与されているため、通常は追加操作不要です。
詳細は以下をご参照ください。
Apr 2, 2026: CREATE OR REPLACE TABLE コマンド実行時におけるタグのコピー (一般提供)
CREATE OR REPLACE TABLE実行時にタグを引き継ぐCOPY TAGSパラメータが一般提供となりました。
これまでCREATE OR REPLACE TABLEを実行するとテーブルおよびカラムに設定されたタグが失われていましたが、COPY TAGSを指定することで元のテーブルとカラムのタグを新しいテーブルに保持できます。
LIKE・CLONE・WITH TAG句と組み合わせて使用した場合は複数ソースのタグを統合でき、置換前テーブルのタグが優先されます。
詳細は以下をご参照ください。
Apr 2, 2026: Performance Explorer で権限に応じた詳細なアクセス制御が適用されるように
Performance Explorer でのアクセス制御が、ユーザーの権限に基づいた粒度の細かい制御に変更されました。
これまではすべてのユーザーが同じレベルのアカウントアクティビティを閲覧できていましたが、今後はウェアハウス・データベース・Snowflake データベースロールに対する権限に応じて表示されるチャートやテーブルが制限されます。
ACCOUNTADMIN やSNOWFLAKE.PERFORMANCE_EXPLORER_USERアプリケーションロールを持つユーザーは引き続き完全な可視性を保持します。
詳細は以下をご参照ください。
Behavior Change Log
2026_03 バンドルが提供開始 ※デフォルトは無効化
10.12(2026/4/3 - 2026/4/8 リリース)で、2026_03 バンドルが提供開始となりました。先に挙動を確かめたい場合には手動でバンドルを有効化してテスト可能です。
このバンドルは、2026年5月のリリースでデフォルトで有効化される予定となっています。
2026_02 バンドルがデフォルトで有効化
10.12(2026/4/3 - 2026/4/8 リリース)で、2026_02 バンドルがデフォルトで有効化されました。
このバンドルは、2026年5月のリリースで一般的に有効化される予定となっています。
2026_01 バンドルが一般的に有効化
10.12(2026/4/3 - 2026/4/8 リリース)で、2026_01 バンドルが一般的に有効化されました。
Modern Data Stack全般の最新情報
Snowflakeも含め、Modern Data Stack 全般の最新情報についても、定期的にブログにまとめて投稿されています!こちらもぜひご覧ください。








