![[レポート]Snowflake MLを活用したエンドツーエンドの機械学習ワークロードのスケーリング #SWTTokyo25](https://images.ctfassets.net/ct0aopd36mqt/4c23cKcRWSfL7fbZjZSEYa/9a2f285542f7937bedd49a78ad421a45/eyecatch_snowflakeworldtourtokyo2025_1200x630.png?w=3840&fm=webp)
[レポート]Snowflake MLを活用したエンドツーエンドの機械学習ワークロードのスケーリング #SWTTokyo25
Snowflake MLは、データ移動を一切行わずに高度なモデルの効率的な開発と展開を可能にします。マルチGPUサポート、MLOps統合、Gitベースのワークフローを備えたContainer Runtimeは、トレーニング用のスケーラブルな環境を提供し、Snowflake MLの製品であるModel RegistryやModel Servingを活用することで、これらのモデルを本番環境へ容易に展開できます。本セッションでは、SnowflakeにおけるスケーラブルなMLワークフローのベストプラクティスと、本番環境対応のMLパイプラインの構築方法について解説します。
※SNOWFLAKE WORLD TOUR 2025 イベントサイトより抜粋
2025.09.15
かわばたです。
2025年9月11日~2025年9月12日に、「SNOWFLAKE WORLD TOUR 2025 - TOKYO」が開催されました。
本記事はセッション
【Snowflake MLを活用したエンドツーエンドの機械学習ワークロードのスケーリング】
のレポートブログとなります。
登壇者
Snowflake
第4ソリューションエンジニアリング本部
シニアソリューションエンジニア
河上 伸一氏
機械学習ライフサイクル
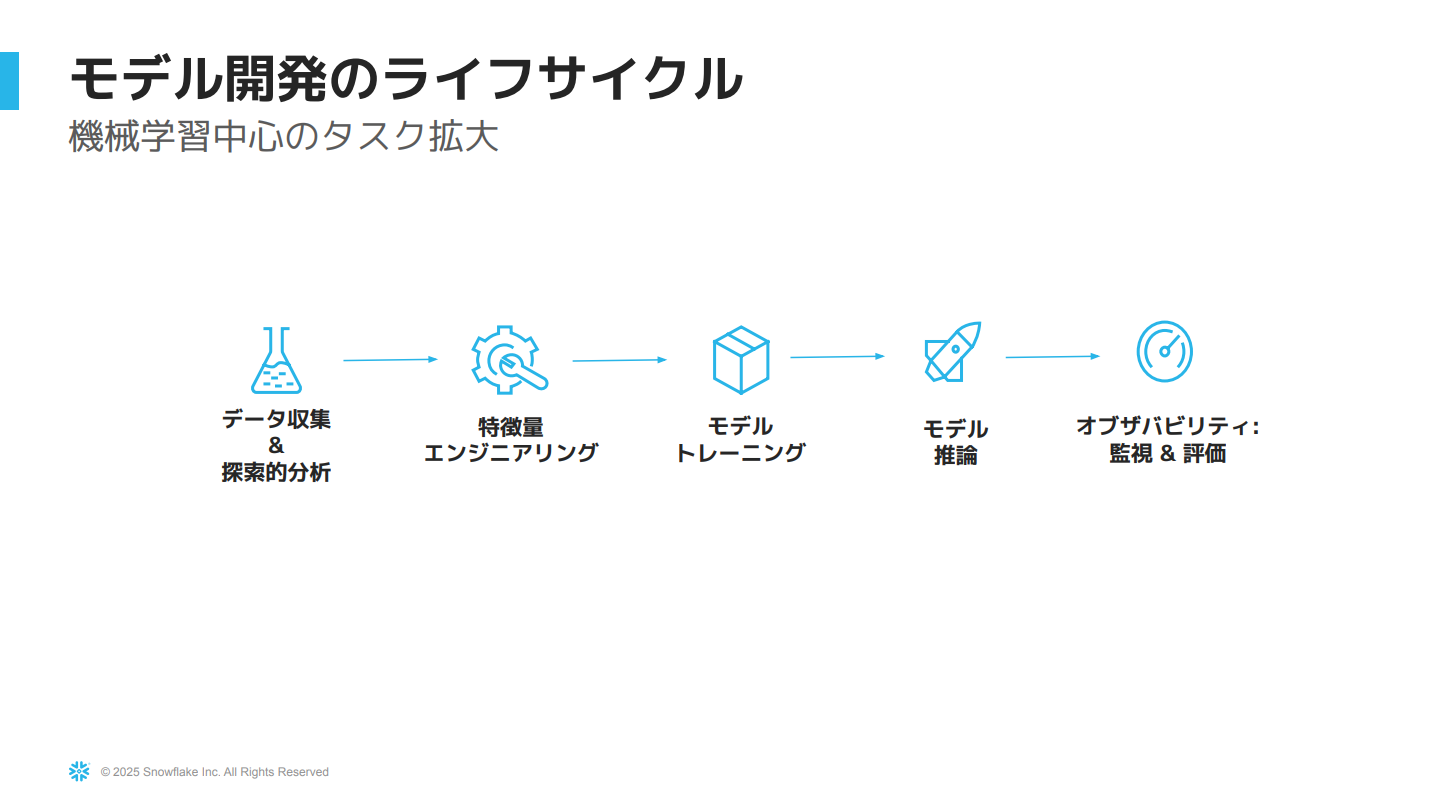
従来のMLライフサイクルの課題
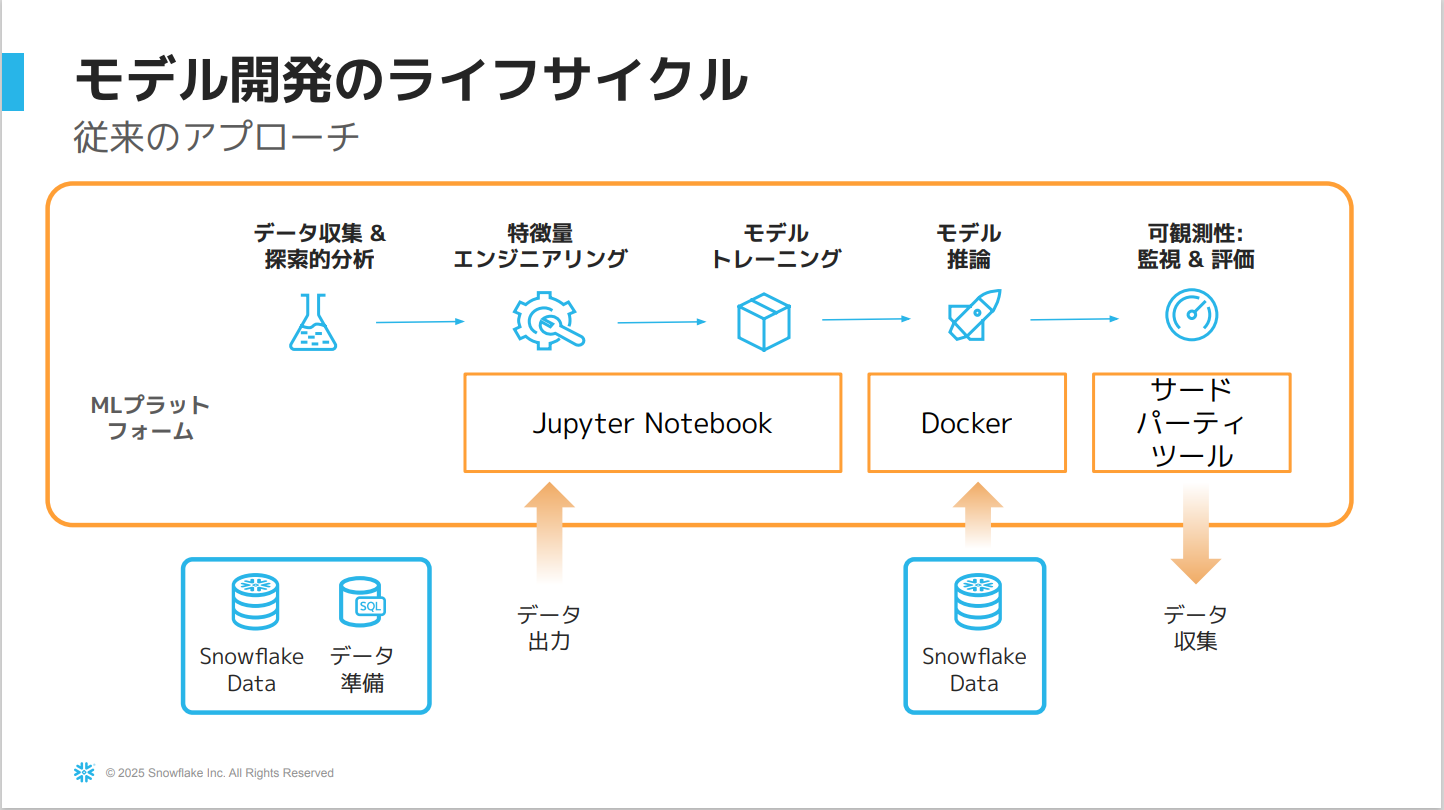
- 従来は、各ステップごとに様々なツールを使い分ける必要があった。
- 例:データ準備にSnowflake、モデル開発にJupyter Notebook、推論にDocker、モニタリングにサードパーティーツールのような形。
- データの移動が発生したり、管理が煩雑になったりするという課題がある。
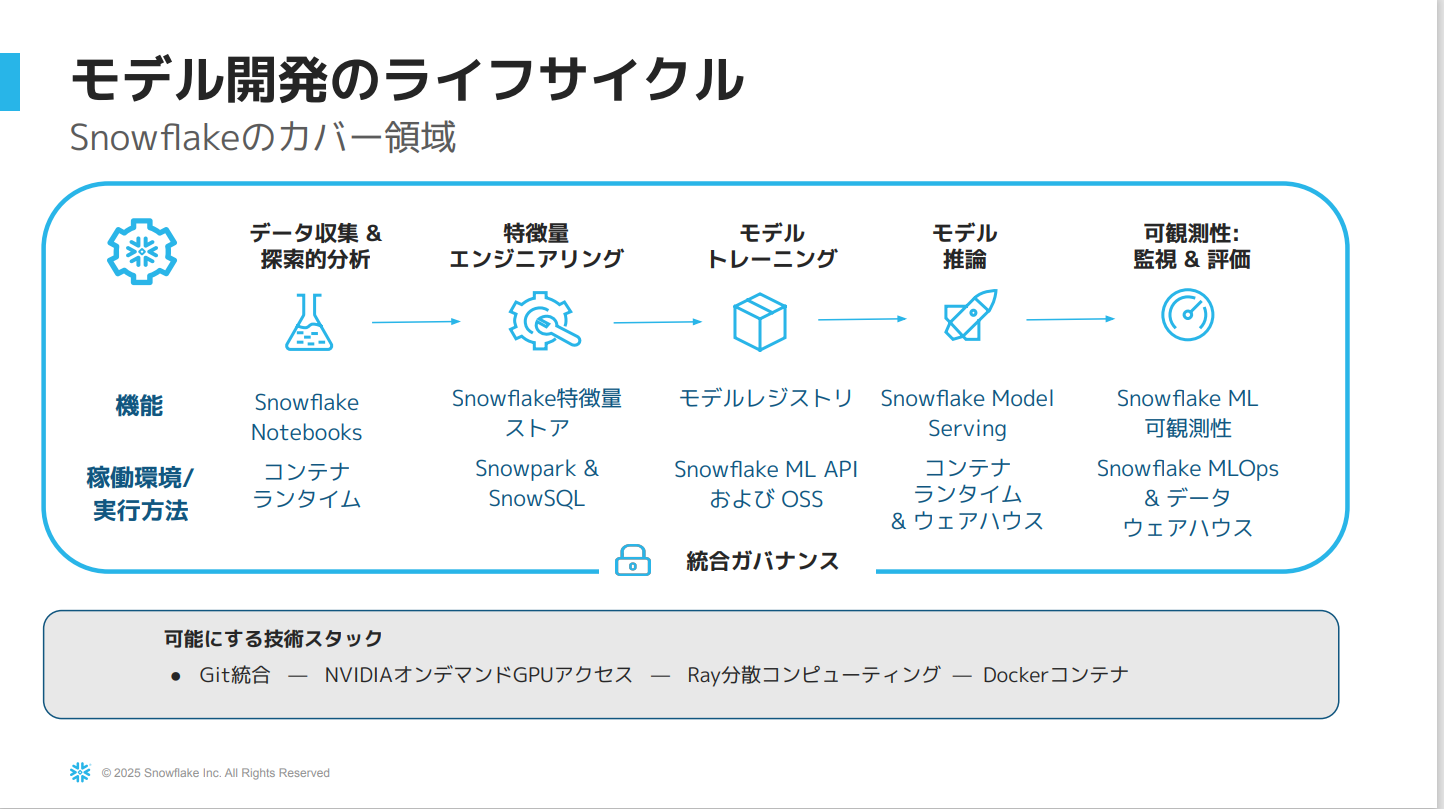
- Snowflake内のパイプラインで実行するための一連のメソッドがある。
各機能について以下で解説します。
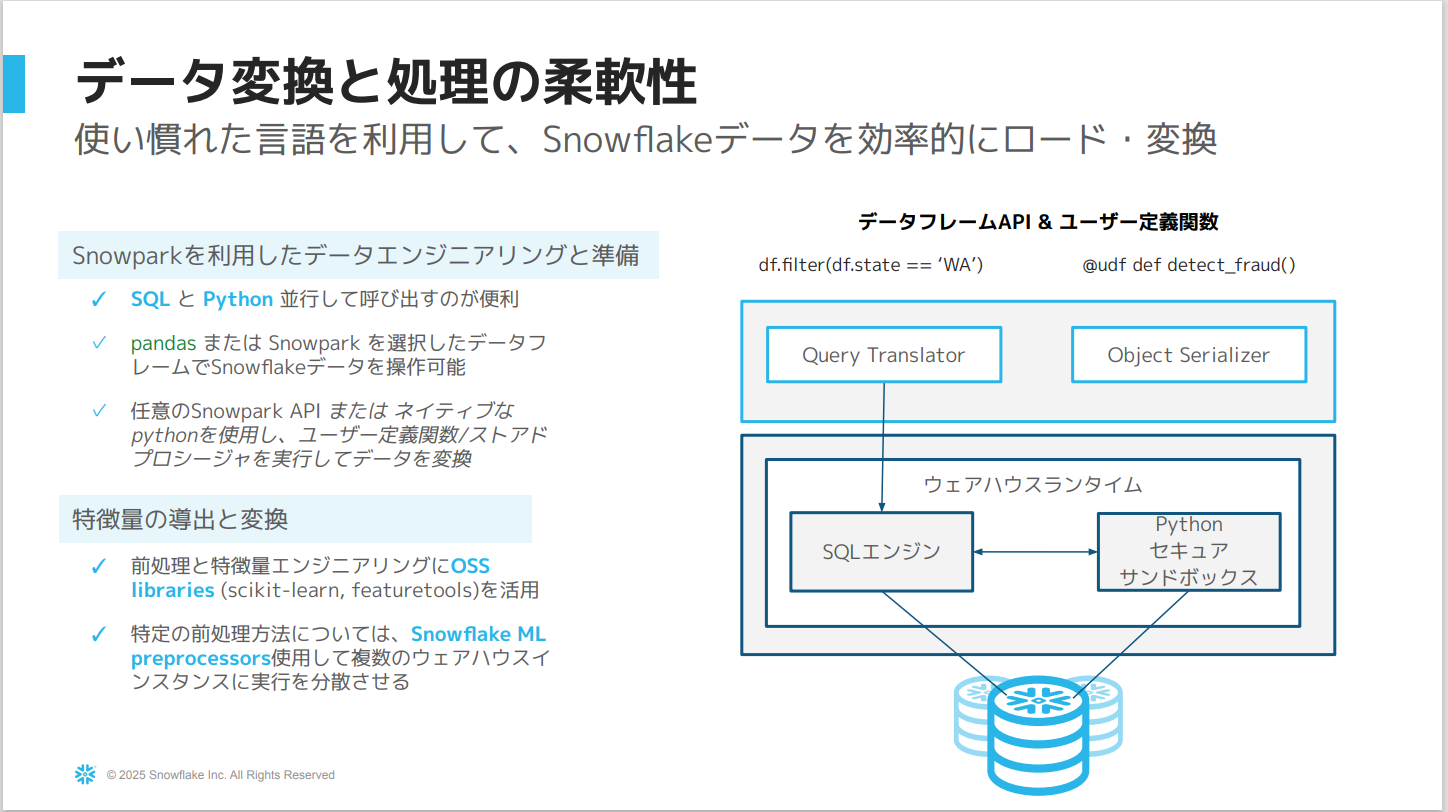
データ探索から特徴量エンジニアリングまで
Snowflake Notebooks コンテナランタイム
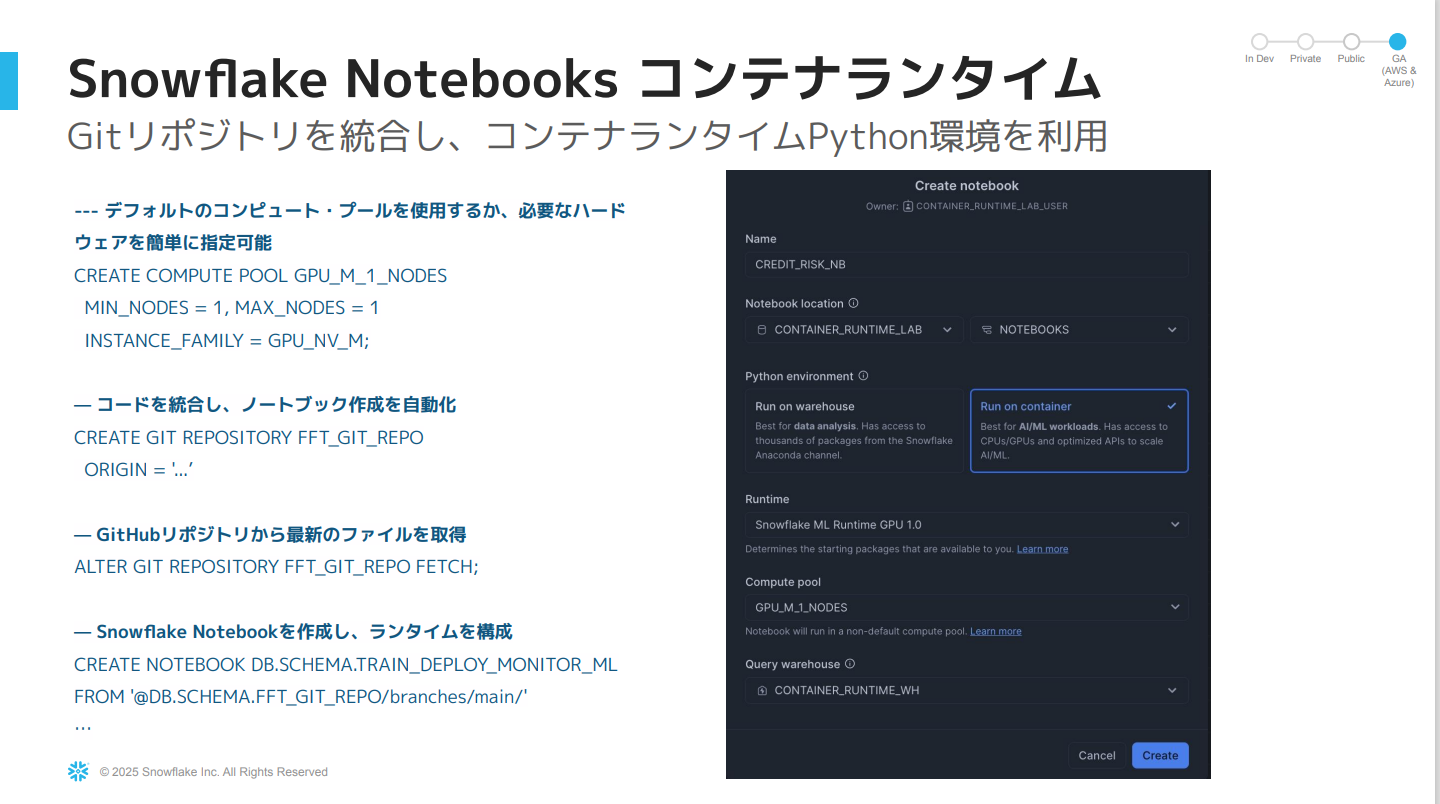
- コンテナサービス上で操作する構築済みのPython環境です。
- UIもしくはコードで作成でき、SQLとPythonの両方を使用できます。
- 主な利点は、Snowflakeのサーバーサイド機能と統合されていることです。
Snowflake特徴量ストア
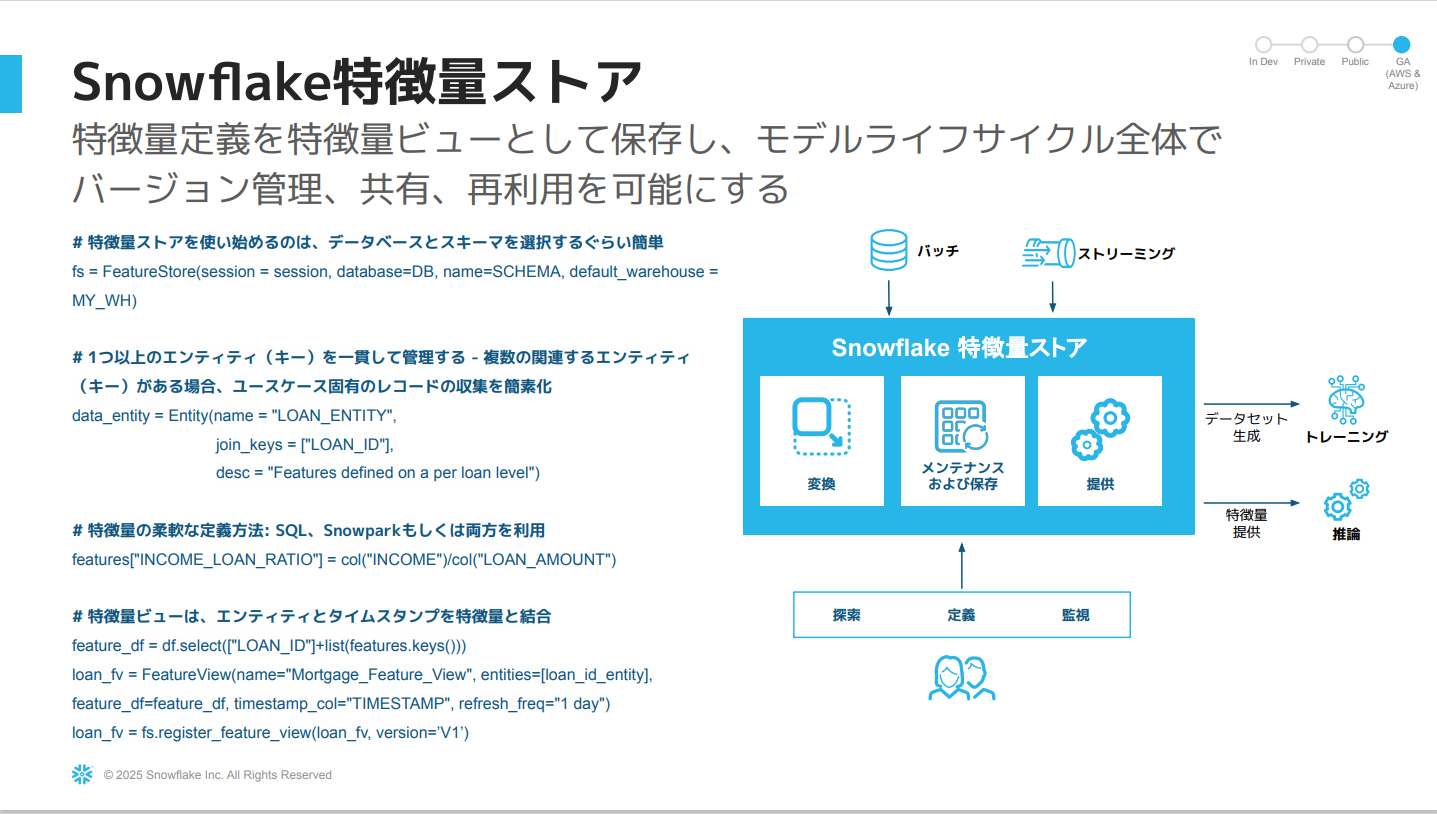
- SnowparkデータフレームAPIやSQLを組み合わせて特徴量変換を定義し、変換と特徴量ビューを保存し、バージョン管理できます。
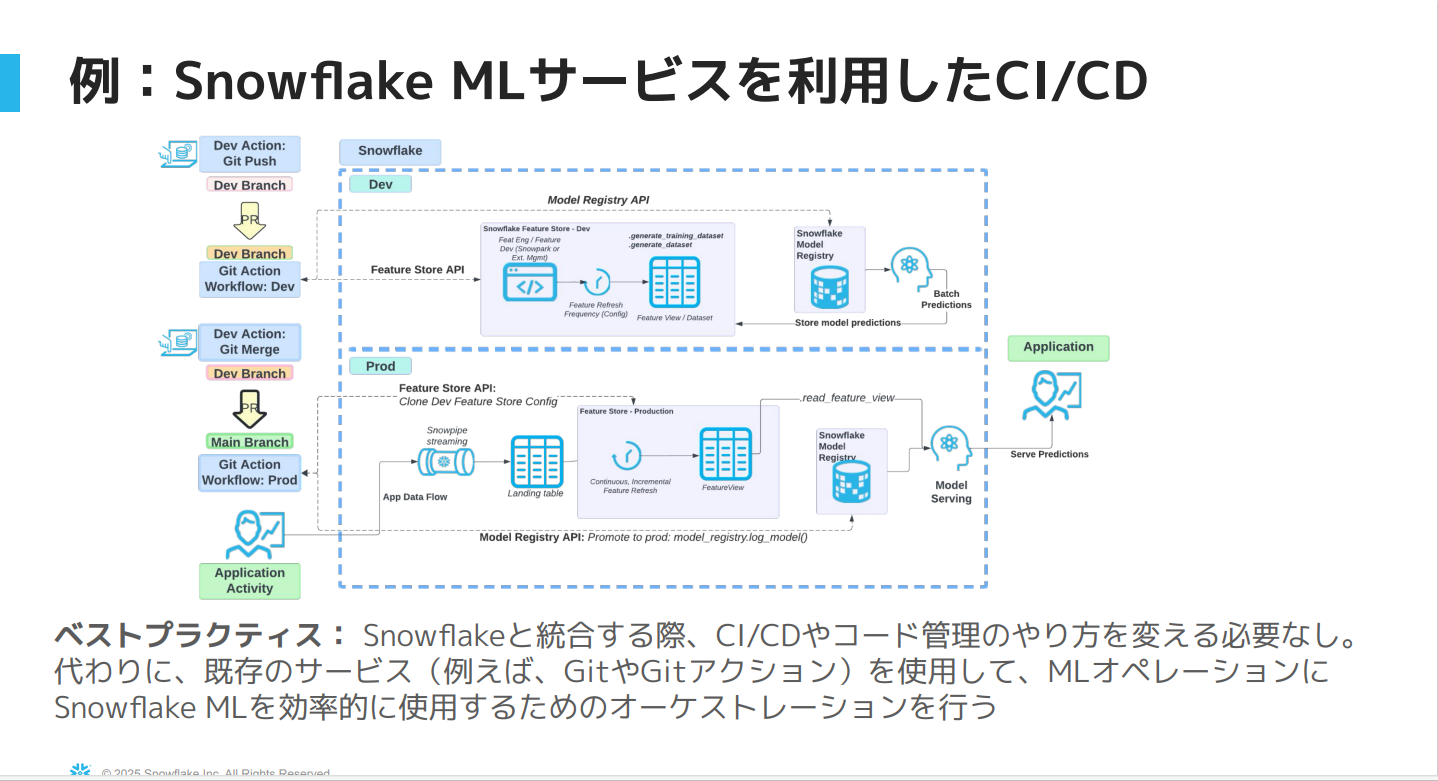
上記図はMLオプションにおいてSnowflakeのAPIを活用した開発から本番環境への移行プロセスを説明しています。
ポイントは、既存のCI/CDのプロセスやコード管理のプロセスを変更する必要がないこと。
Snowpark ML API & OSS
Snowflakeモデルトレーニング
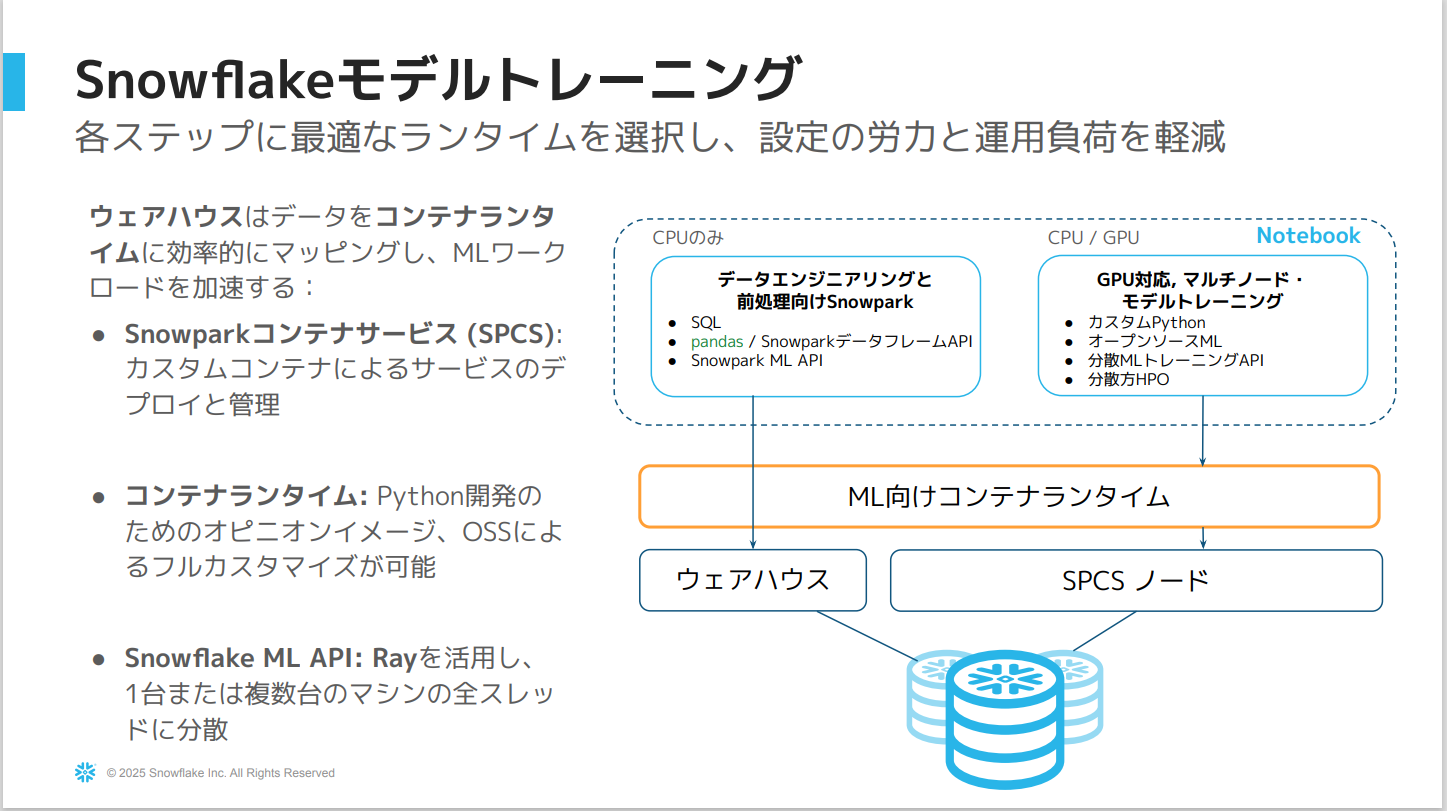
- 従来もウェアハウス内でモデルをトレーニング・推論することは可能でしたが、新たにNotebookからコンテナランタイムを使用することでコンピューティングプール内で直接モデルをトレーニングすることが可能になりました。
コンテナランタイム
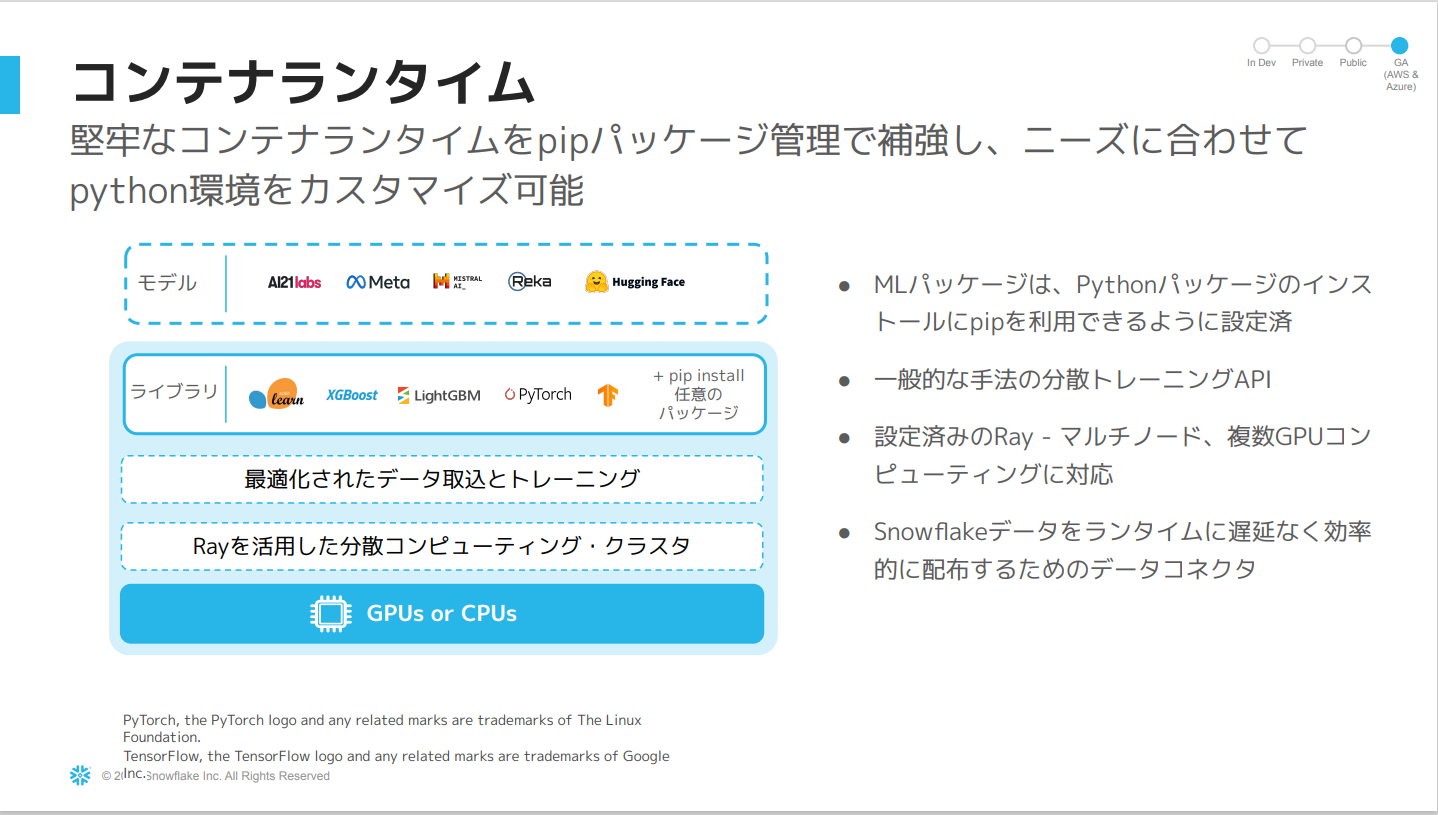
- コンテナランタイムの利点は、機械学習に特化した柔軟な計算環境であること。
- カスタマイズ可能な事前構築済みの環境を提供しているため
pip installが可能。
【公式ドキュメント】
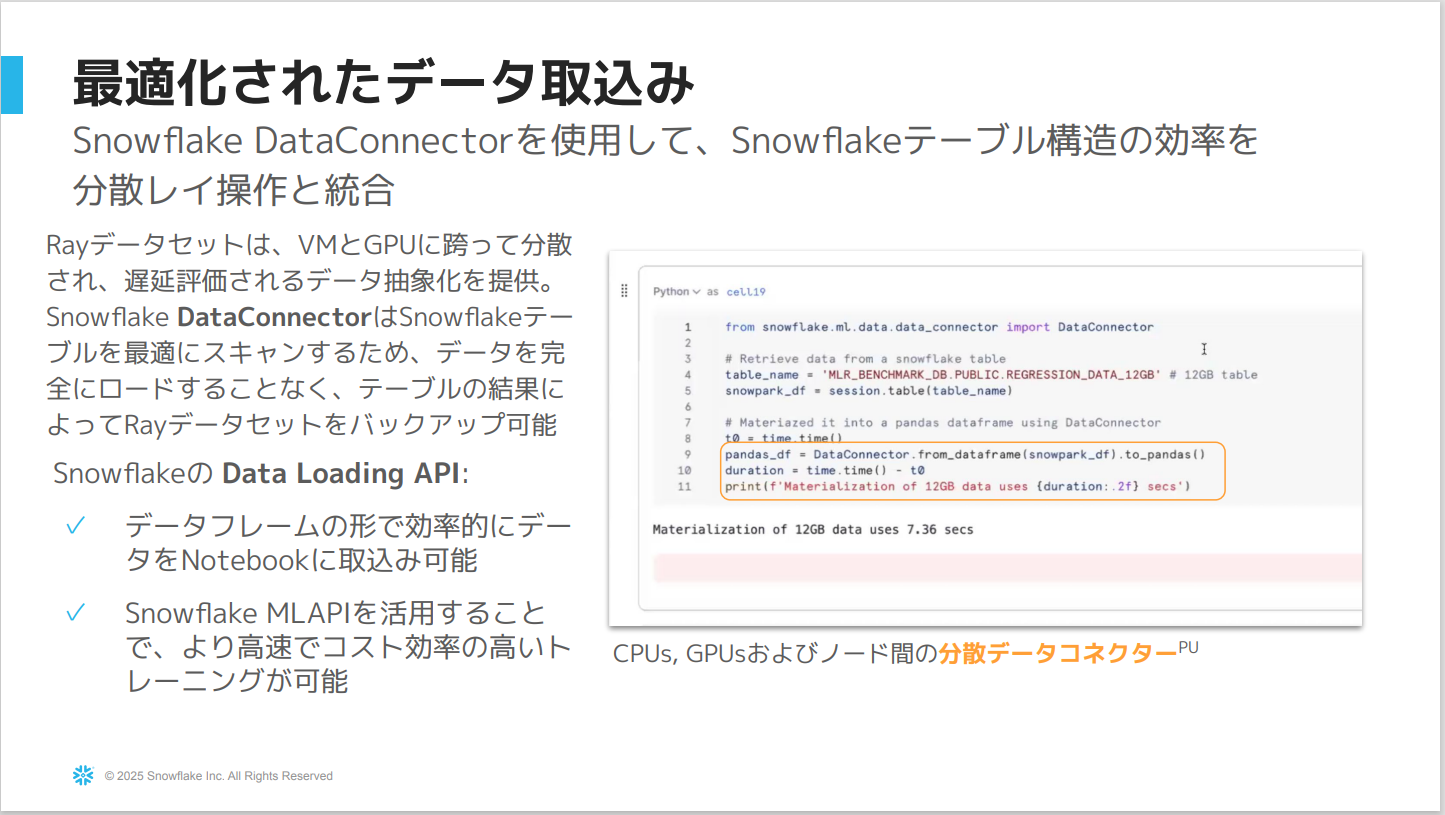
Data ConnectorはSnowflakeのソースからデータを効率的に、かつ遅延処理によってメモリ内にロードします。- この処理は制御された分散方式で実行されるため、大量のデータであってもメモリが溢れることはなくメモリ内に収まるように設定されている。
Snowflakeモデルレジストリ

- pipの依存関係を内部に含めることができます。
- モデルレジストリを作成しておくことで、デプロイに必要な全ての要素をモデルレジストリにまとめておくことが可能になります。
モデルレジストリからのモデル推論
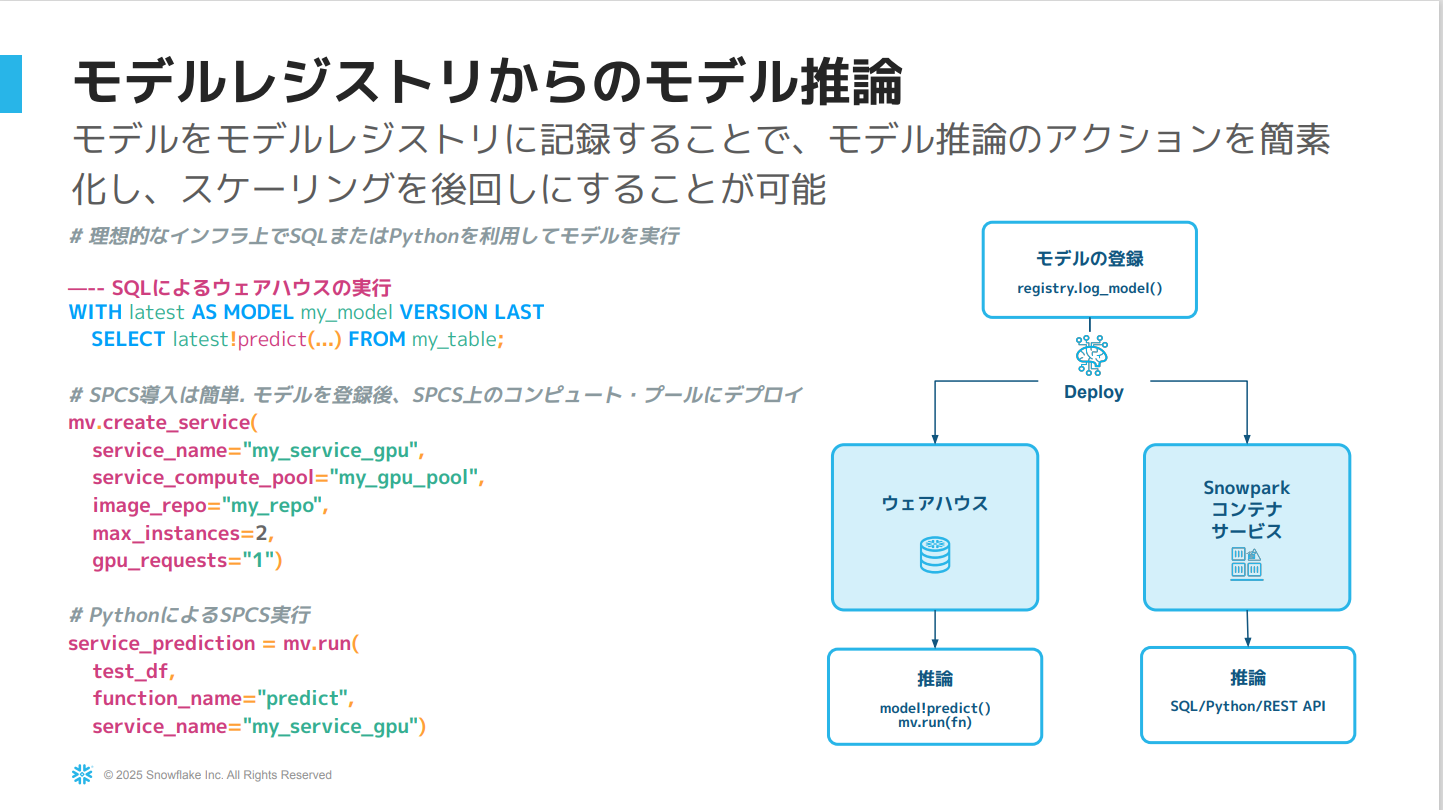
- モデルレジストリを活用し、そのモデルをウェアハウス、またはSnowflakeのコンテナサービス内にデプロイできる。
- 特にコンピュートプール上で実行された推論がある場合非常に有効です。
下記記事も参考になると思うのでご確認ください。
リネージとオブザーバビリティによるモデル監視
リネージ

- Snowparkのデータフレームを使ってモデルをトレーニングすると、リネージが標準で提供している。
- 最終的にデータがどのように繋がっているか視覚的に追跡可能です。
MLモデルへのオブザバビリティ
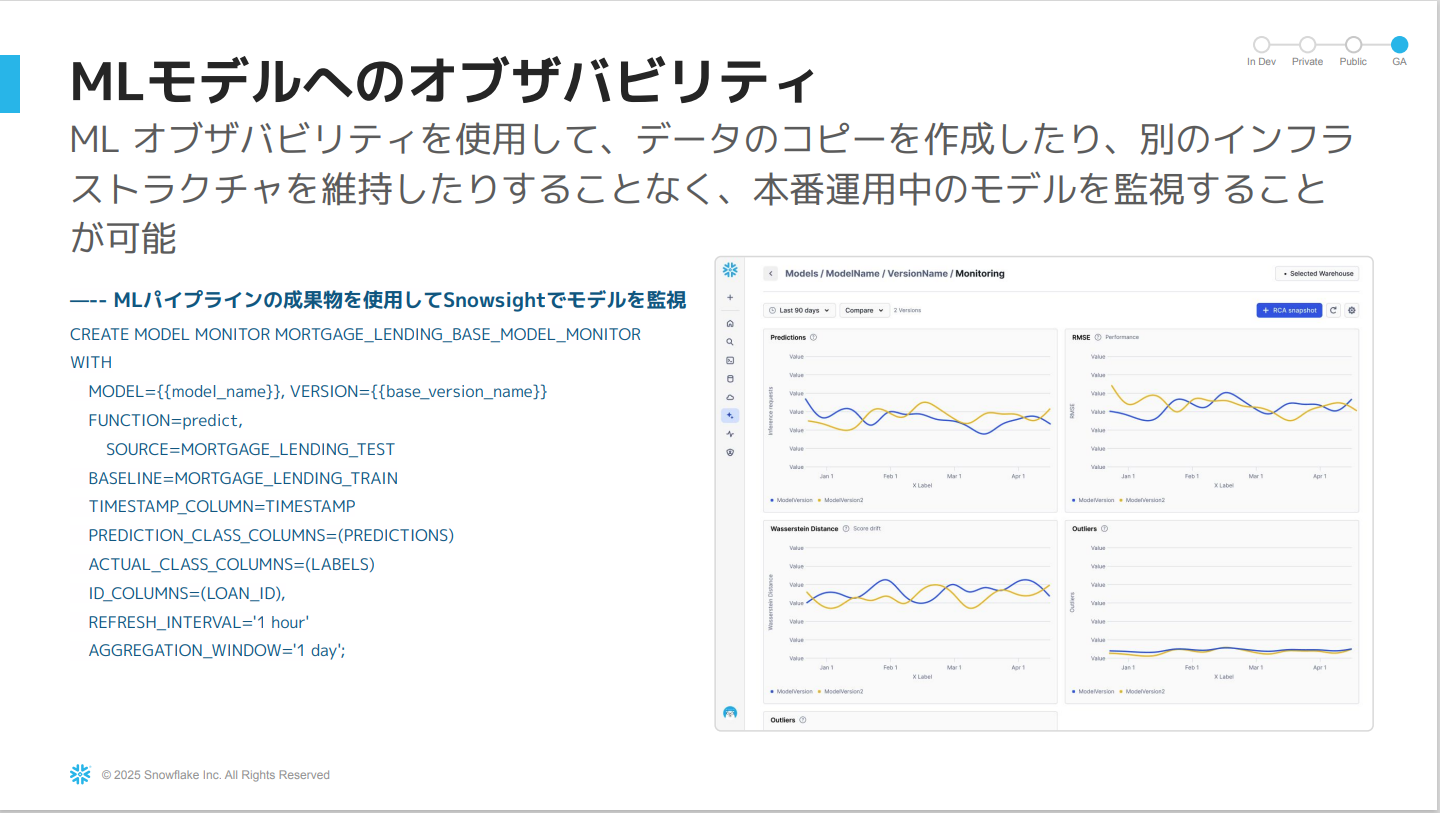
最後に
Snowflake上でエンドツーエンドに機械学習を行うための機能紹介セッションでした!
Snowflakeだけですべてが完結するのは改めて凄いですし、そこに価値があるなと感じました。
かわばたはまだこれらの機能を試せていないので、実際に試してみたいと思います。
この記事が何かの参考になれば幸いです。








