
図表付きのPDFも対応可能!Snowflake Cortex AgentでPDFとテーブルを横断したクラスメソッドの情報収集・分析をやってみた
さがらです。
これまでSnowflakeで非構造化データを分析するにはCortex Searchを使う方法がありましたが、テキストをパースしてテーブル化する必要があるため、グラフや表を含むPDFなどでは活用が難しいところがありました。しかし、AI_COMPLETE関数がステージ上のPDFファイルを直接クエリできるようになったことで、テキスト抽出やチャンク分割なしにPDFを丸ごとLLMに渡せるようになっています。
これにより、AI_COMPLETEをストアドプロシージャでラップしてPDFカスタムツールとし、Cortex Analyst(Semantic View) と組み合わせることで、「ステージ上のPDFなどの非構造化データ」と「テーブルデータ」を横断した自然言語での分析が1つのCortex Agentで実現できるのではと考え、実際に検証してみました。
なお、本記事のアイデアは以下のブログから着想を得ています。AI_COMPLETEでPDFを読み取るストアドプロシージャをCortex Agentのカスタムツールとして活用するアプローチが非常に参考になりました。
背景・課題
Snowflake上で非構造化データを分析したい場合、これまでは主に以下のアプローチが考えられました。
- Cortex Search: テキストを抽出・チャンク分割してテーブルに格納し、RAG(Retrieval-Augmented Generation)で検索・回答する
- Document AI: PDFからの構造化データ抽出(テーブル化)
これらはテキスト中心のドキュメントには有効ですが、以下のような課題がありました。
- グラフ・チャートを含むPDFでは、テキスト抽出だけでは情報が欠落する
- テキストをパースしてテーブル化する前処理パイプラインが必要で、セットアップの手間がかかる
技術的アプローチ
AI_COMPLETE関数のドキュメントインテリジェンス機能(TO_FILE + PROMPT)を使えば、ステージ上のPDFをテキスト抽出なしにLLMへ直接渡すことができます。グラフや表もビジュアル要素として参照できるため、従来のテキスト抽出では失われていた情報も分析対象にできます。
これをPythonストアドプロシージャでラップしてCortex Agentのカスタムツール として登録し、Cortex Analyst(Semantic View経由のcortex_analyst_text_to_sqlツール)と組み合わせることで、以下の構成を実現します。
AGENT_CM_FINANCIAL_ANALYST(統合Agent)
├── SP_ASK_CM_FINANCIALS(genericツール)
│ └── AI_COMPLETE + TO_FILE → ステージ上のPDFを直接クエリ
└── AnalystMonthlySales(cortex_analyst_text_to_sqlツール)
└── Semantic View → 月次売上テーブルをSQL集計
ツール選択はAgentが自動で判断します。質問内容に応じて、PDFツール・Analystツール・またはその両方を呼び出し、結果を統合して回答します。
制限事項
- AI_COMPLETE with documentsは2026年3月30日時点ではPublic Previewの機能です
- ステージはサーバーサイド暗号化(
SNOWFLAKE_SSE) が必須です - ファイルサイズ制限: Gemini 3.1 Proで最大10MB(900ページ)、Claudeモデルで最大4.5MB
- 1回のリクエストあたりのドキュメント数制限: Gemini最大20個、Claude最大5個
- ステージはサーバーサイド暗号化(
コスト
- AI_COMPLETEのコストはファイルサイズではなく処理トークン数で決定されます。テキスト部分とビジュアル要素がトークン化され、入出力の合計で課金対象になります
- Cortex Analyst(Semantic View)はCortex Agentsを介した方が単価が安くなります(Consumption Table Table 6(f)と6(h)を参照)
前提条件
- Snowflake: Enterpriseエディション
- 本機能のステータス: 2026年3月30日時点ではPublic Preview(AI_COMPLETE with documents, Cortex Agents, Semantic View)
- 必要な権限: SYSADMINロール、
SNOWFLAKE.CORTEX_USERデータベースロールの付与 - クロスリージョン推論:
gemini-3.1-proを使用するため、CORTEX_ENABLED_CROSS_REGION = 'ANY_REGION'の設定が必要な場合があります(ACCOUNTADMINで設定) - 使用モデル:
gemini-3.1-pro(PDF読取用。10MBまで対応のため採用)
事前準備
全体の構成
今回作成するSnowflakeオブジェクトの全体像です。
POC_CM.SAGARA_TEST
├── STG_CM_FINANCIAL_REPORTS -- PDFステージ
├── V_CM_FINANCIAL_METADATA -- PDFメタデータビュー
├── T_MONTHLY_SALES -- ダミー売上テーブル
├── SV_MONTHLY_SALES -- Semantic View(Cortex Analyst用)
├── SP_ASK_CM_FINANCIALS -- PDFカスタムツール(ストアドプロシージャ)
└── AGENT_CM_FINANCIAL_ANALYST -- 統合Agent
対象データ
PDF(非構造化データ)
以下の4つのPDFを使用します。決算報告書3期分に加え、グラフ・チャートを多数含む会社紹介資料(スライド形式)を対象にすることで、AI_COMPLETEのビジュアル読取能力も検証します。
| ファイル名 | 種別 | 期 | 対象期間 |
|---|---|---|---|
| financial-results_202306.pdf | 決算報告書 | 第19期 | 2022/7/1 - 2023/6/30 |
| financial-results_202406.pdf | 決算報告書 | 第20期 | 2023/7/1 - 2024/6/30 |
| financial-results_202506.pdf | 決算報告書 | 第21期 | 2024/7/1 - 2025/6/30 |
| 会社紹介資料_20251031.pdf | 会社紹介 | — | 2025年10月時点 |
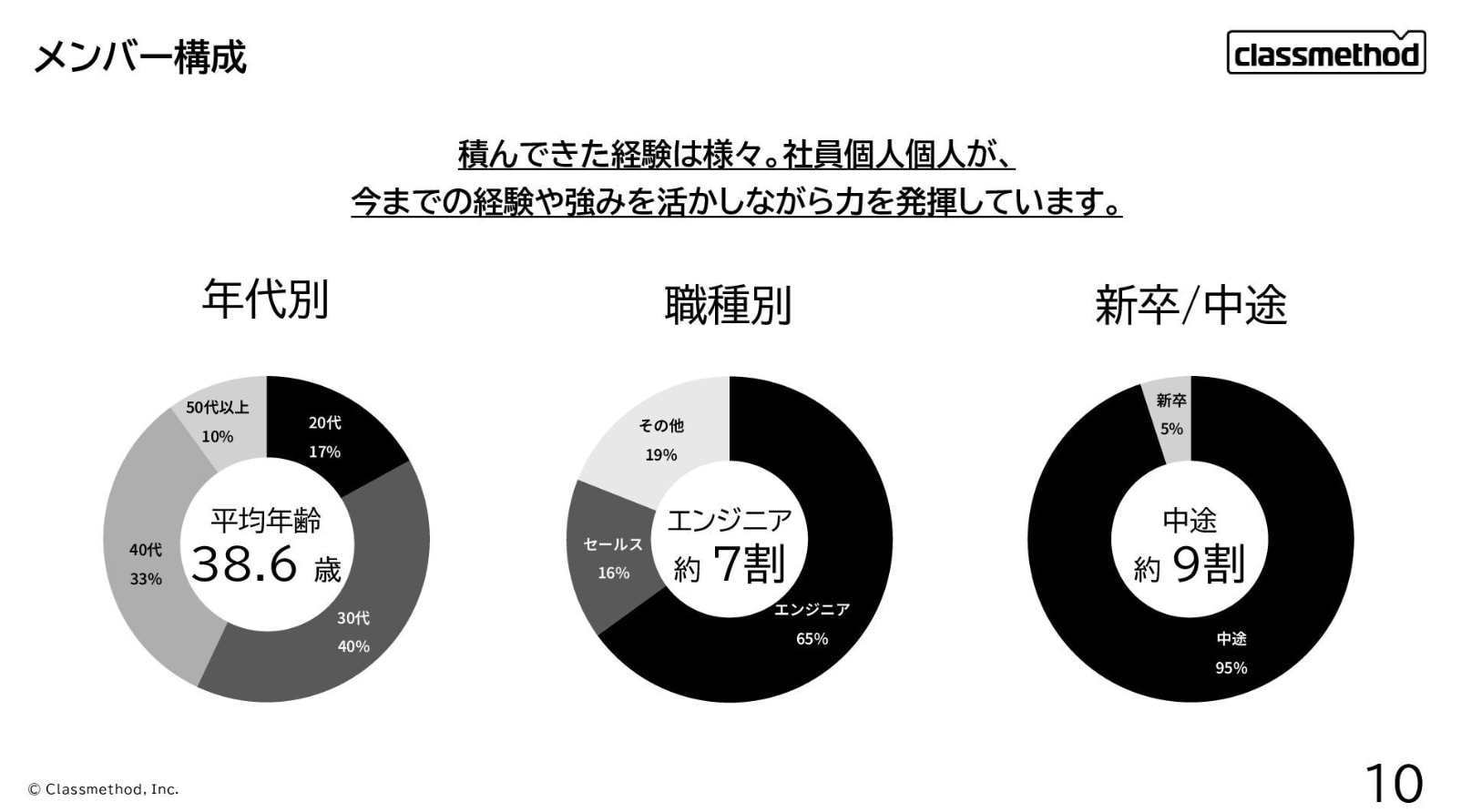
特に会社紹介資料には、業績推移の棒グラフ、社員数推移の棒グラフ、メンバー構成の円グラフ、拠点の地図など、テキスト抽出では失われるビジュアル情報が多く含まれています。従来のCortex Search(テキストパース方式)では対応が難しかったこの種の資料を、AI_COMPLETEで直接読み取れるかがポイントです。
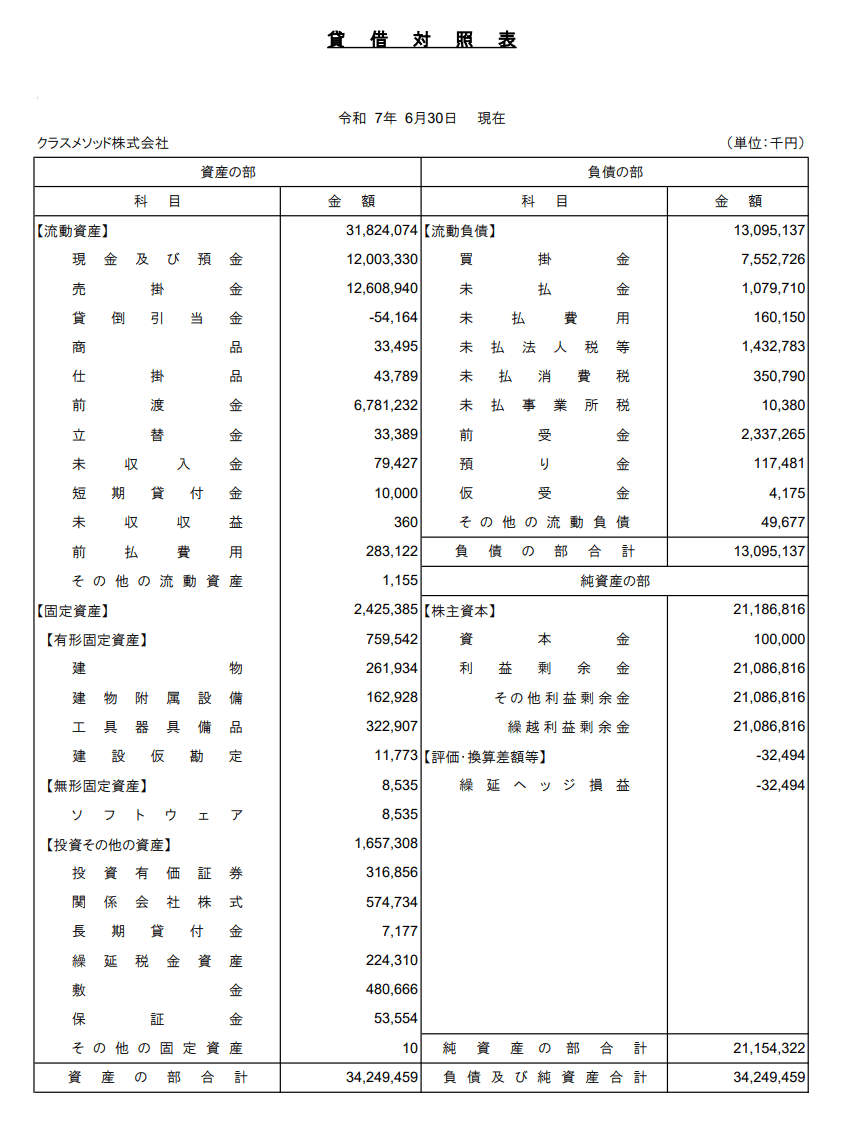
- 決算報告書のイメージ(弊社公式HPより取得)

- 会社紹介資料のイメージ(弊社公式SpeakerDeckより取得)
テーブル(構造化データ)— ダミーデータ
PDFの決算数値と整合するダミーデータを生成します。デモのポイントとして、「PDF側の年間売上高とテーブル側の月次売上集計が突合できる」ことを確認します。
| カラム | 型 | 説明 |
|---|---|---|
| SALE_ID | NUMBER | サロゲートキー(連番) |
| FISCAL_YEAR | NUMBER | 会計年度(19, 20, 21) |
| YEAR_MONTH | DATE | 月初日(36ヶ月分) |
| SERVICE_LINE | VARCHAR | サービスライン(6区分) |
| CUSTOMER_SEGMENT | VARCHAR | 顧客セグメント(5区分) |
| REGION | VARCHAR | 地域(6区分) |
| REVENUE | NUMBER | 売上(千円) |
| COGS | NUMBER | 売上原価(千円) |
| GROSS_PROFIT | NUMBER | 粗利(千円) |
| DEAL_COUNT | NUMBER | 案件数 |
PDFとの整合ルール:
- 各期のREVENUE合計 = PDFの売上高(19期: 59,005,311千円、20期: 77,190,340千円、21期: 95,056,018千円)
- 各期のCOGS合計 = PDFの売上原価(19期: 52,634,720千円、20期: 69,320,565千円、21期: 85,782,527千円)
試してみた
1. ステージ作成・PDFアップロード
まず、PDF格納用の内部ステージを作成します。暗号化タイプはSNOWFLAKE_SSEにしないとAI_COMPLETEで読めないのでご注意ください。
CREATE OR REPLACE STAGE STG_CM_FINANCIAL_REPORTS
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')
COMMENT = 'クラスメソッド決算報告書PDF格納用ステージ';
ステージ作成後、Snowsightの Data > Databases > POC_CM > SAGARA_TEST > Stages > STG_CM_FINANCIAL_REPORTS から + Files ボタンで4つのPDFをアップロードします。
アップロード後、下図のように表示されていれば問題ないです。
アップロード後、ディレクトリテーブルをリフレッシュしてファイルを確認します。
ALTER STAGE STG_CM_FINANCIAL_REPORTS REFRESH;
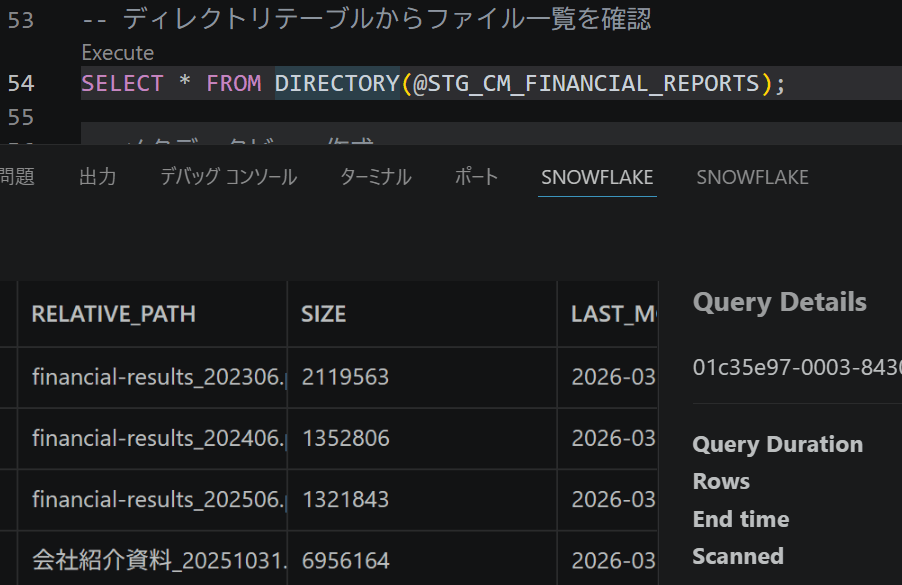
SELECT * FROM DIRECTORY(@STG_CM_FINANCIAL_REPORTS);
4ファイルが表示されればOKです。
次に、ファイル名から資料種別と会計年度を抽出するメタデータビューを作成します。決算報告書と会社紹介資料でファイル名の規則が異なるため、CASE文で分岐させます。
CREATE OR REPLACE VIEW V_CM_FINANCIAL_METADATA AS
SELECT
RELATIVE_PATH,
FILE_URL,
SIZE,
LAST_MODIFIED,
-- 資料種別を判定
CASE
WHEN RELATIVE_PATH LIKE 'financial-results%' THEN '決算報告書'
WHEN RELATIVE_PATH LIKE '会社紹介資料%' THEN '会社紹介資料'
ELSE 'その他'
END AS DOC_TYPE,
-- 決算報告書の場合のみ会計年度を抽出
CASE
WHEN RELATIVE_PATH LIKE 'financial-results%' THEN
CASE SPLIT_PART(REPLACE(RELATIVE_PATH, '.pdf', ''), '_', 2)
WHEN '202306' THEN 19
WHEN '202406' THEN 20
WHEN '202506' THEN 21
END
ELSE NULL
END AS FISCAL_YEAR,
CASE
WHEN RELATIVE_PATH LIKE 'financial-results%' THEN
CASE SPLIT_PART(REPLACE(RELATIVE_PATH, '.pdf', ''), '_', 2)
WHEN '202306' THEN '2022/7/1 - 2023/6/30'
WHEN '202406' THEN '2023/7/1 - 2024/6/30'
WHEN '202506' THEN '2024/7/1 - 2025/6/30'
END
WHEN RELATIVE_PATH LIKE '会社紹介資料%' THEN '2025年10月時点'
ELSE NULL
END AS FISCAL_PERIOD
FROM DIRECTORY(@STG_CM_FINANCIAL_REPORTS)
WHERE RELATIVE_PATH LIKE '%.pdf';
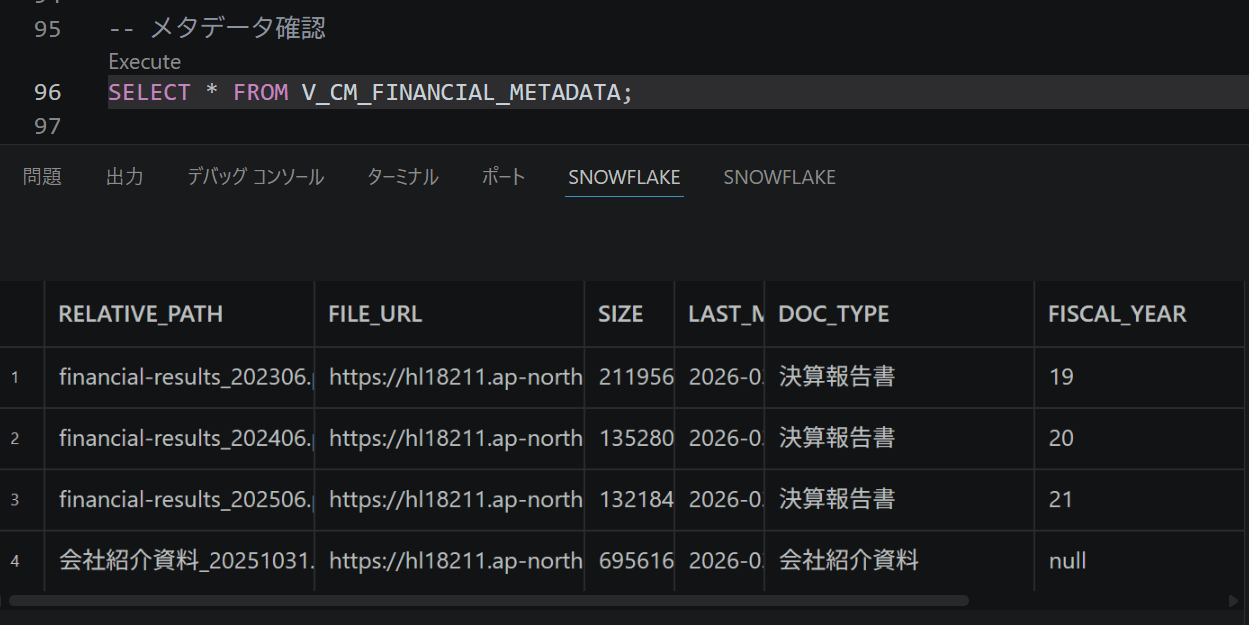
実際に作成したViewをクエリすると、下図のように確認できます。
2. AI_COMPLETE単体での動作確認
PDFカスタムツールを作る前に、AI_COMPLETEで直接PDFを読めるか確認します。
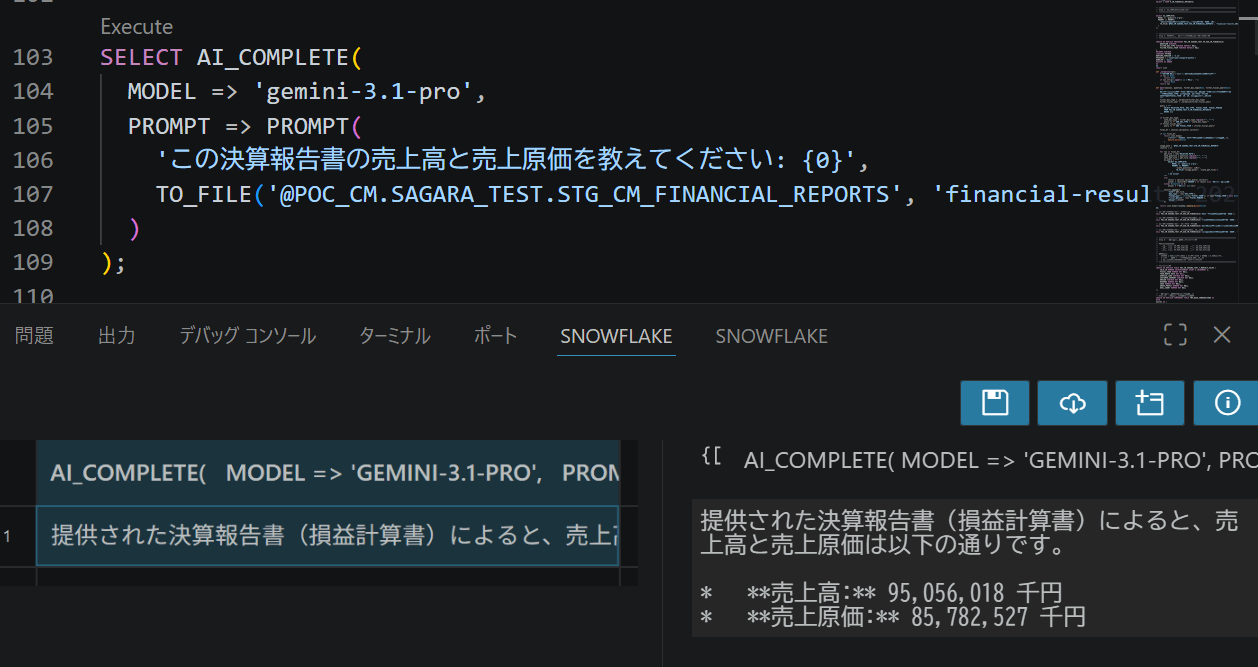
SELECT AI_COMPLETE(
MODEL => 'gemini-3.1-pro',
PROMPT => PROMPT(
'この決算報告書の売上高と売上原価を教えてください: {0}',
TO_FILE('@POC_CM.SAGARA_TEST.STG_CM_FINANCIAL_REPORTS', 'financial-results_202506.pdf')
)
);
PROMPT関数内の {0} プレースホルダーにTO_FILEで指定したPDFが渡されます。売上高・売上原価の数値が正しく返ってくればOKです。
3. PDFカスタムツール用ストアドプロシージャの作成
AI_COMPLETEはCortex Agentのツールとして直接登録できないため、Pythonストアドプロシージャでラップします。ディレクトリテーブルからPDFファイル一覧を動的に取得し、資料種別(DOC_TYPE) と会計年度でフィルタした上で、各PDFに対してAI_COMPLETEを実行します。
CREATE OR REPLACE PROCEDURE POC_CM.SAGARA_TEST.SP_ASK_CM_FINANCIALS(
QUESTION VARCHAR,
FILTER_DOC_TYPE VARCHAR DEFAULT NULL,
FILTER_FISCAL_YEAR VARCHAR DEFAULT NULL
)
RETURNS VARCHAR
LANGUAGE PYTHON
RUNTIME_VERSION = '3.12'
PACKAGES = ('snowflake-snowpark-python')
HANDLER = 'main'
EXECUTE AS OWNER
AS
$$
import json
def _normalize(val):
"""文字列'NULL'/'null'/空文字をNone(無視)として扱う"""
if val is None:
return None
if val.strip().upper() in ('NULL', ''):
return None
return val
def main(session, question, filter_doc_type=None, filter_fiscal_year=None):
filter_doc_type = _normalize(filter_doc_type)
filter_fiscal_year = _normalize(filter_fiscal_year)
query = """
SELECT RELATIVE_PATH, DOC_TYPE, FISCAL_YEAR, FISCAL_PERIOD
FROM POC_CM.SAGARA_TEST.V_CM_FINANCIAL_METADATA
WHERE 1=1
"""
if filter_doc_type:
safe_doc_type = filter_doc_type.replace("'", "''")
query += f" AND DOC_TYPE = '{safe_doc_type}'"
if filter_fiscal_year:
query += f" AND FISCAL_YEAR = {filter_fiscal_year}"
files_df = session.sql(query).collect()
if not files_df:
return json.dumps(
{"error": "条件に一致するPDFファイルが見つかりませんでした"},
ensure_ascii=False
)
stage_path = '@POC_CM.SAGARA_TEST.STG_CM_FINANCIAL_REPORTS'
results = []
for row in files_df:
pdf_file = row['RELATIVE_PATH']
safe_question = question.replace("'", "''")
safe_pdf_file = pdf_file.replace("'", "''")
ai_query = f"""
SELECT AI_COMPLETE(
MODEL => 'gemini-3.1-pro',
PROMPT => PROMPT(
'{safe_question}: {{0}}',
TO_FILE('{stage_path}', '{safe_pdf_file}')
)
) AS answer
"""
try:
result = session.sql(ai_query).collect()
answer = result[0]['ANSWER'] if result else 'エラー: 結果なし'
except Exception as e:
answer = f'エラー: {str(e)}'
results.append({
'file': pdf_file,
'doc_type': row['DOC_TYPE'],
'fiscal_year': str(row['FISCAL_YEAR']) if row['FISCAL_YEAR'] else None,
'fiscal_period': row['FISCAL_PERIOD'],
'answer': answer
})
return json.dumps(results, ensure_ascii=False)
$$;
プロシージャでは、_normalize()関数を入れています。Cortex Agentからストアドプロシージャにパラメータが渡される際、SQL NULLではなく**文字列"NULL"**が渡されることがあります。これをPythonのNoneに変換するための関数です。
動作確認として、いくつかのパターンで呼び出します。
-- 全PDF横断
CALL POC_CM.SAGARA_TEST.SP_ASK_CM_FINANCIALS('この資料の要点を教えてください');
-- 決算報告書のみ、第21期
CALL POC_CM.SAGARA_TEST.SP_ASK_CM_FINANCIALS(
'売上高と営業利益を教えてください', '決算報告書', '21');
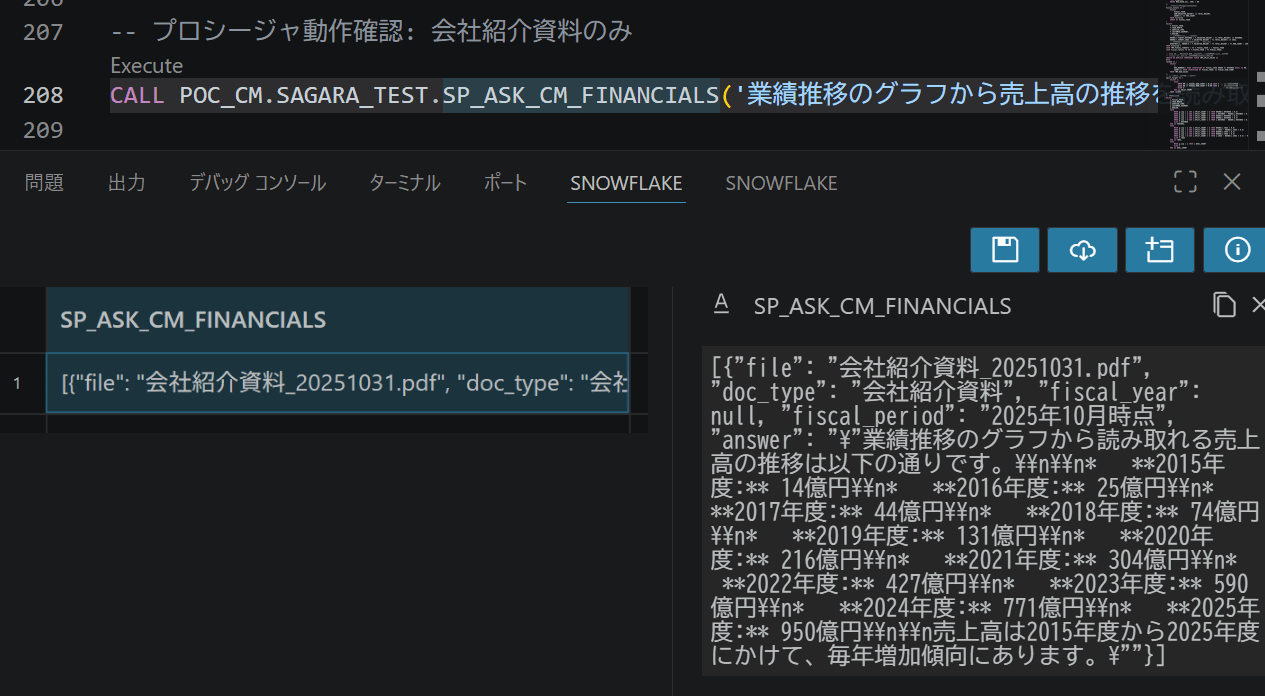
-- 会社紹介資料のみ(グラフ読取り)
CALL POC_CM.SAGARA_TEST.SP_ASK_CM_FINANCIALS(
'業績推移のグラフから売上高の推移を読み取ってください', '会社紹介資料');
特に3番目の会社紹介資料への質問は、棒グラフから数値を読み取るというAI_COMPLETEのビジュアル読取能力が試されるテストです。
下図のようにJSON形式で各PDFからの回答が返ってくればOKです。
4. ダミーデータ生成・テーブル作成
Cortex Analyst用のテーブルデータを生成します。
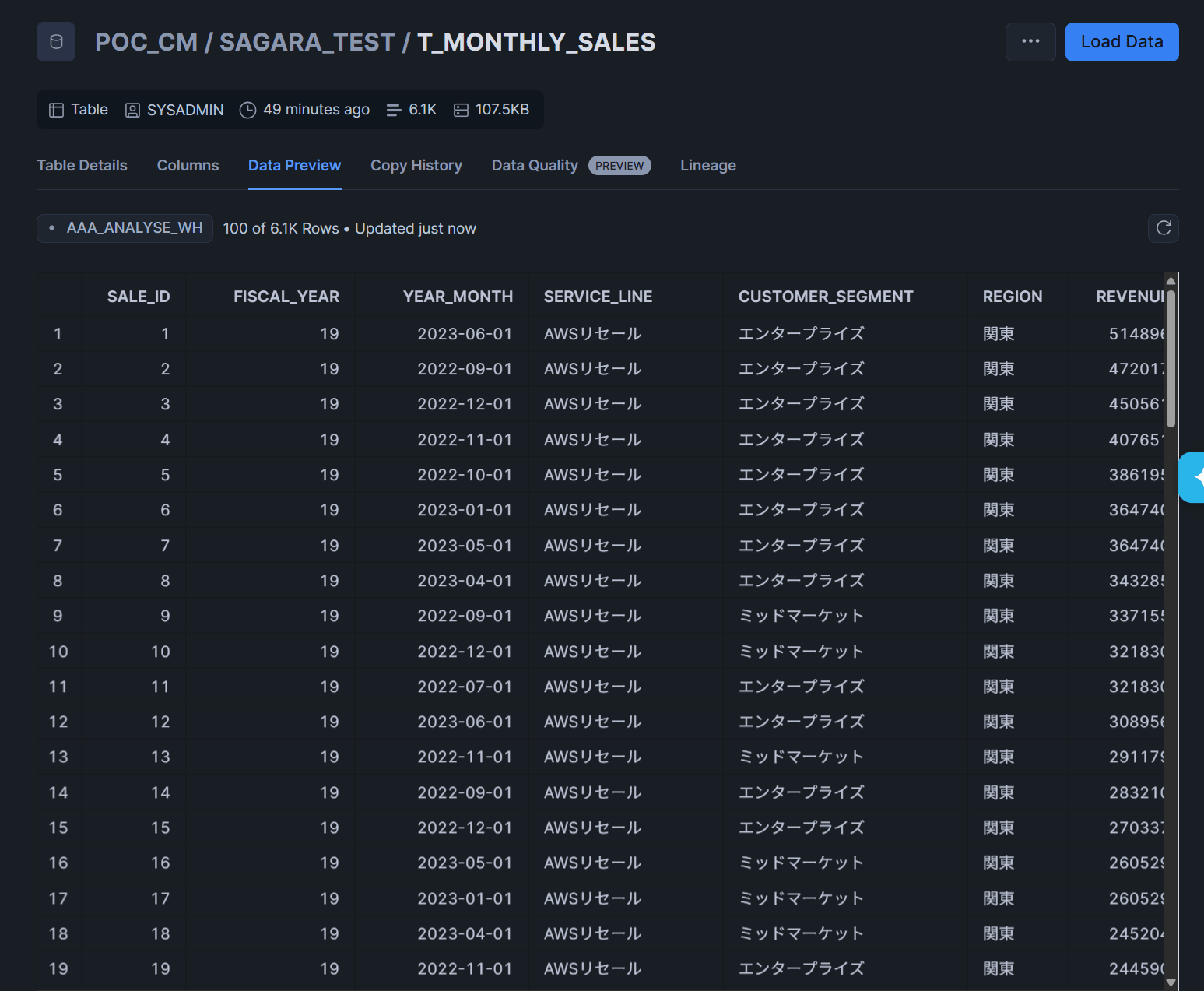
以下のようなT_MONTHLY_SALESテーブルを作成し、PDFの決算数値と整合するダミーデータを約6,000行INSERTしています。
| カラム | 説明 |
|---|---|
| FISCAL_YEAR | 会計年度(19, 20, 21) |
| YEAR_MONTH | 月初日(36ヶ月分) |
| SERVICE_LINE | サービスライン(AWSリセール、クラウド導入支援 等6区分) |
| CUSTOMER_SEGMENT | 顧客セグメント(エンタープライズ、ミッドマーケット 等5区分) |
| REGION | 地域(関東、関西 等6区分) |
| REVENUE / COGS / GROSS_PROFIT | 売上・原価・粗利(千円) |
| DEAL_COUNT | 案件数 |
5. Semantic View作成
Cortex Analyst用のSemantic Viewを作成します。日本語のSYNONYMSを設定することで、自然言語での質問精度を高めます。
CREATE OR REPLACE SEMANTIC VIEW POC_CM.SAGARA_TEST.SV_MONTHLY_SALES
TABLES (
T_MONTHLY_SALES AS POC_CM.SAGARA_TEST.T_MONTHLY_SALES
PRIMARY KEY (SALE_ID)
WITH SYNONYMS = ('月次売上', '売上データ', '売上明細', '売上実績')
COMMENT = 'クラスメソッド株式会社の月次売上明細データ'
)
DIMENSIONS (
T_MONTHLY_SALES.FISCAL_YEAR AS T_MONTHLY_SALES.FISCAL_YEAR
WITH SYNONYMS = ('期', '年度', '会計期間')
COMMENT = '会計年度(19=第19期, 20=第20期, 21=第21期)',
T_MONTHLY_SALES.YEAR_MONTH AS T_MONTHLY_SALES.YEAR_MONTH
WITH SYNONYMS = ('月', '年月', '対象月')
COMMENT = '対象月(月初日)',
T_MONTHLY_SALES.SERVICE_LINE AS T_MONTHLY_SALES.SERVICE_LINE
WITH SYNONYMS = ('サービス', '事業', '事業区分', 'サービス区分')
COMMENT = 'サービスライン',
T_MONTHLY_SALES.CUSTOMER_SEGMENT AS T_MONTHLY_SALES.CUSTOMER_SEGMENT
WITH SYNONYMS = ('顧客区分', 'セグメント', '顧客タイプ')
COMMENT = '顧客セグメント',
T_MONTHLY_SALES.REGION AS T_MONTHLY_SALES.REGION
WITH SYNONYMS = ('地域', 'エリア', '拠点')
COMMENT = '地域'
)
METRICS (
T_MONTHLY_SALES.TOTAL_REVENUE AS SUM(T_MONTHLY_SALES.REVENUE)
WITH SYNONYMS = ('売上', '売上額', '売上金額', '収益', '売上高')
COMMENT = '売上高(千円)',
T_MONTHLY_SALES.TOTAL_COGS AS SUM(T_MONTHLY_SALES.COGS)
WITH SYNONYMS = ('原価', '売上原価', 'コスト')
COMMENT = '売上原価(千円)',
T_MONTHLY_SALES.TOTAL_GROSS_PROFIT AS SUM(T_MONTHLY_SALES.GROSS_PROFIT)
WITH SYNONYMS = ('粗利', '粗利益', '売上総利益', 'GP')
COMMENT = '売上総利益(粗利)(千円)',
T_MONTHLY_SALES.TOTAL_DEAL_COUNT AS SUM(T_MONTHLY_SALES.DEAL_COUNT)
WITH SYNONYMS = ('案件数', '取引件数', 'ディール数')
COMMENT = '案件数'
)
COMMENT = 'クラスメソッド月次売上ダミーデータ(Cortex Analyst用)';
6. 統合Agent作成
続けて、PDFカスタムツールとCortex Analystツールを統合したAgentを作成します。使用するツールの使い方など、明確に明示するのがポイントです。
CREATE OR REPLACE AGENT POC_CM.SAGARA_TEST.AGENT_CM_FINANCIAL_ANALYST
COMMENT = 'クラスメソッド決算報告書 統合分析エージェント(PDF×テーブル)'
FROM SPECIFICATION
$$
models:
orchestration: auto
orchestration:
budget:
seconds: 120
tokens: 32000
instructions:
system: >
あなたはクラスメソッド株式会社の企業情報・財務分析アシスタントです。
以下の2つのデータソースを使って質問に回答できます。
【データソース1: PDF資料】
SP_ASK_CM_FINANCIALSツールで参照できます。
(A) 決算報告書(3期分): FILTER_DOC_TYPE=決算報告書
(B) 会社紹介資料: FILTER_DOC_TYPE=会社紹介資料
【データソース2: 月次売上テーブル】
AnalystMonthlySalesツールで参照できます。
【ツール選択ルール】
1. 決算書の定性的な内容 → PDFツール(FILTER_DOC_TYPE=決算報告書)
2. 会社概要、拠点、従業員数、経営理念、業績推移グラフ等
→ PDFツール(FILTER_DOC_TYPE=会社紹介資料)
3. 数値の集計・比較・推移分析 → Analystツール
4. PDF×テーブルの横断分析 → 両方呼び出して比較
response: >
日本語で回答してください。
数値を含む回答ではテーブル形式で見やすく整理してください。
sample_questions:
- question: "第21期の売上高は?"
- question: "サービスライン別の売上推移を教えて"
- question: "第20期の監査報告書の内容は?"
- question: "PDFの年間売上とテーブルの月次合計を突合して"
- question: "会社の拠点一覧を教えて"
- question: "業績推移のグラフから売上高の成長率を教えて"
- question: "従業員数の推移と売上高の推移を比較して"
tools:
- tool_spec:
type: "generic"
name: "SP_ASK_CM_FINANCIALS"
description: >
クラスメソッドのPDF資料(決算報告書・会社紹介資料)に対して質問を行い、回答を取得するツール。
FILTER_DOC_TYPE(決算報告書, 会社紹介資料)とFILTER_FISCAL_YEAR(19, 20, 21)でフィルタ可能。
input_schema:
type: "object"
properties:
QUESTION:
type: "string"
description: "PDF資料に対して問い合わせる質問文"
FILTER_DOC_TYPE:
type: "string"
description: "資料種別フィルタ(決算報告書, 会社紹介資料)。指定しない場合はNULL。"
FILTER_FISCAL_YEAR:
type: "string"
description: "会計年度フィルタ(19, 20, 21)。指定しない場合はNULL。"
required:
- "QUESTION"
- tool_spec:
type: "cortex_analyst_text_to_sql"
name: "AnalystMonthlySales"
description: >
月次売上明細テーブルに対してSQL集計を行い、数値データを分析するツール。
tool_resources:
SP_ASK_CM_FINANCIALS:
type: "procedure"
identifier: "POC_CM.SAGARA_TEST.SP_ASK_CM_FINANCIALS"
execution_environment:
type: "warehouse"
warehouse: "COPUTE_WH"
query_timeout: 120
AnalystMonthlySales:
semantic_view: "POC_CM.SAGARA_TEST.SV_MONTHLY_SALES"
execution_environment:
type: "warehouse"
warehouse: "COPUTE_WH"
query_timeout: 60
$$;
7. Snowflake Intelligenceから動作テスト
作成したAgentについて、Snowflake Intelligence UIから、対話的にテストします。
以下のテスト質問を実行して、ツール選択が適切に行われるか確認します。
テスト1: 「第21期の売上高は?」
→ Analystツール or PDFツールで回答。どちらを使っても同じ値(95,056,018千円)が返ってくるはずです。

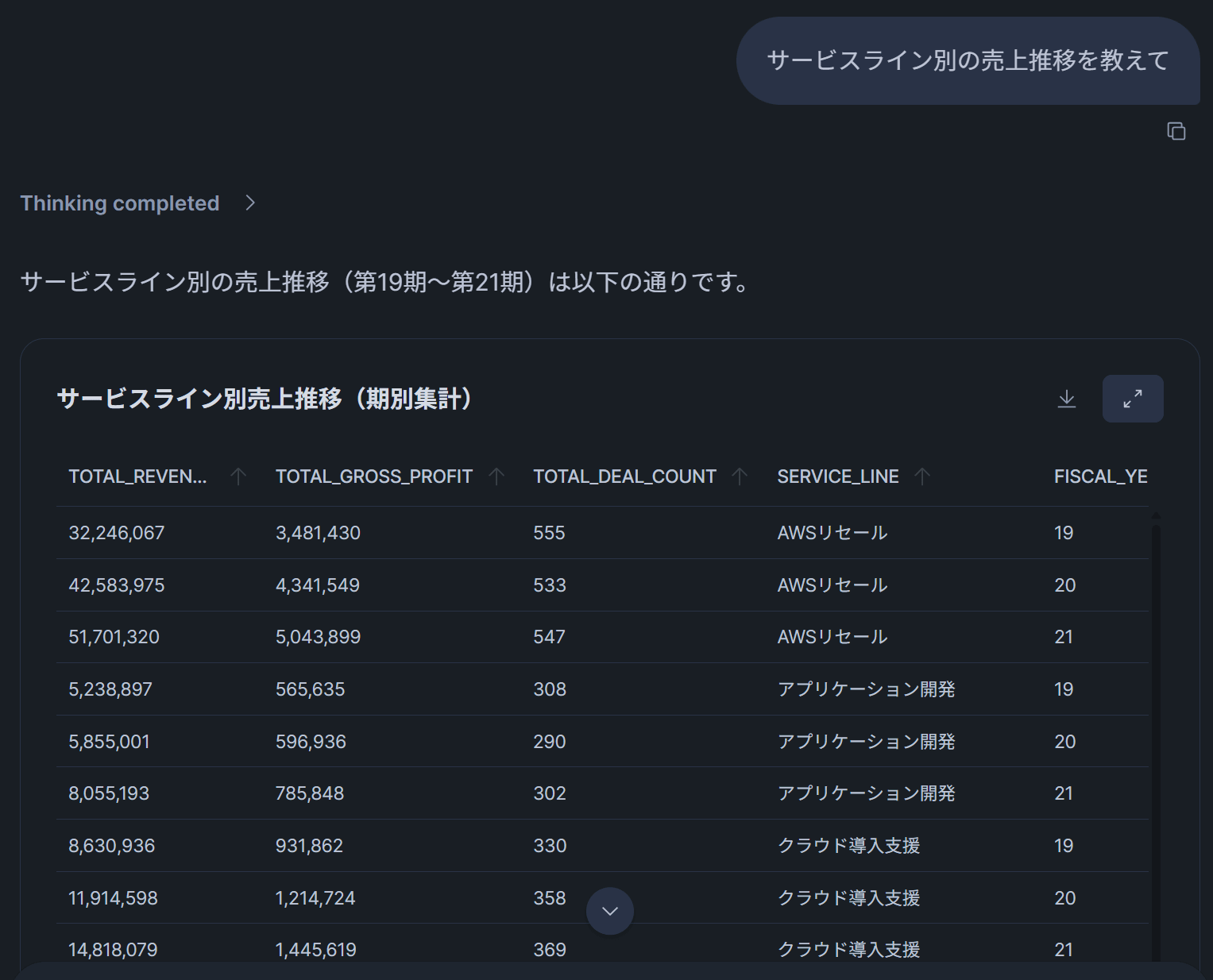
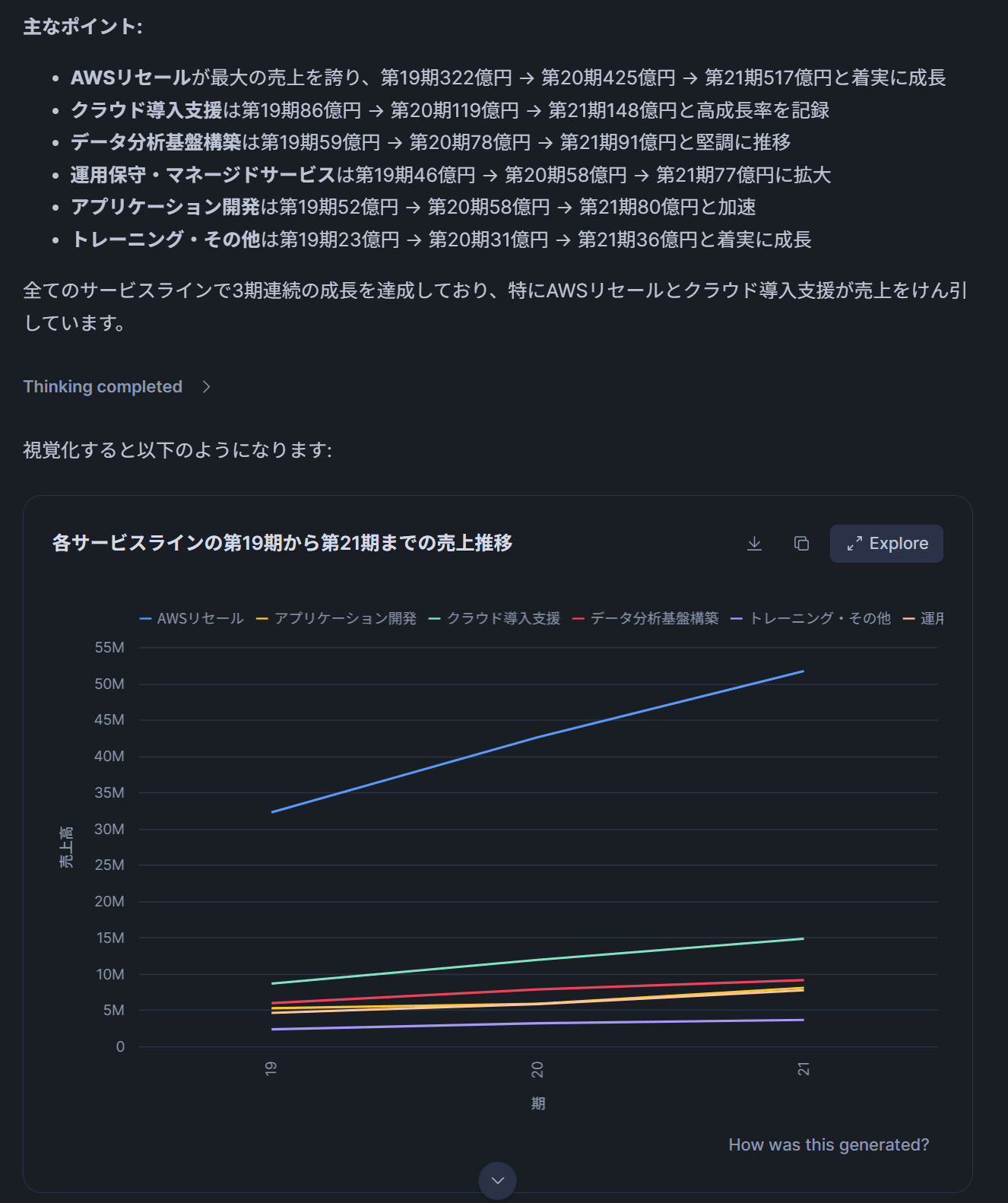
テスト2: 「サービスライン別の売上推移を教えて」
→ Analystツールが選択され、テーブルデータからSQL集計が実行されます。
テスト3: 「第20期の監査報告書の内容は?」
→ PDFツールが選択され、決算報告書のPDF内の監査報告書の内容が返ってきます。

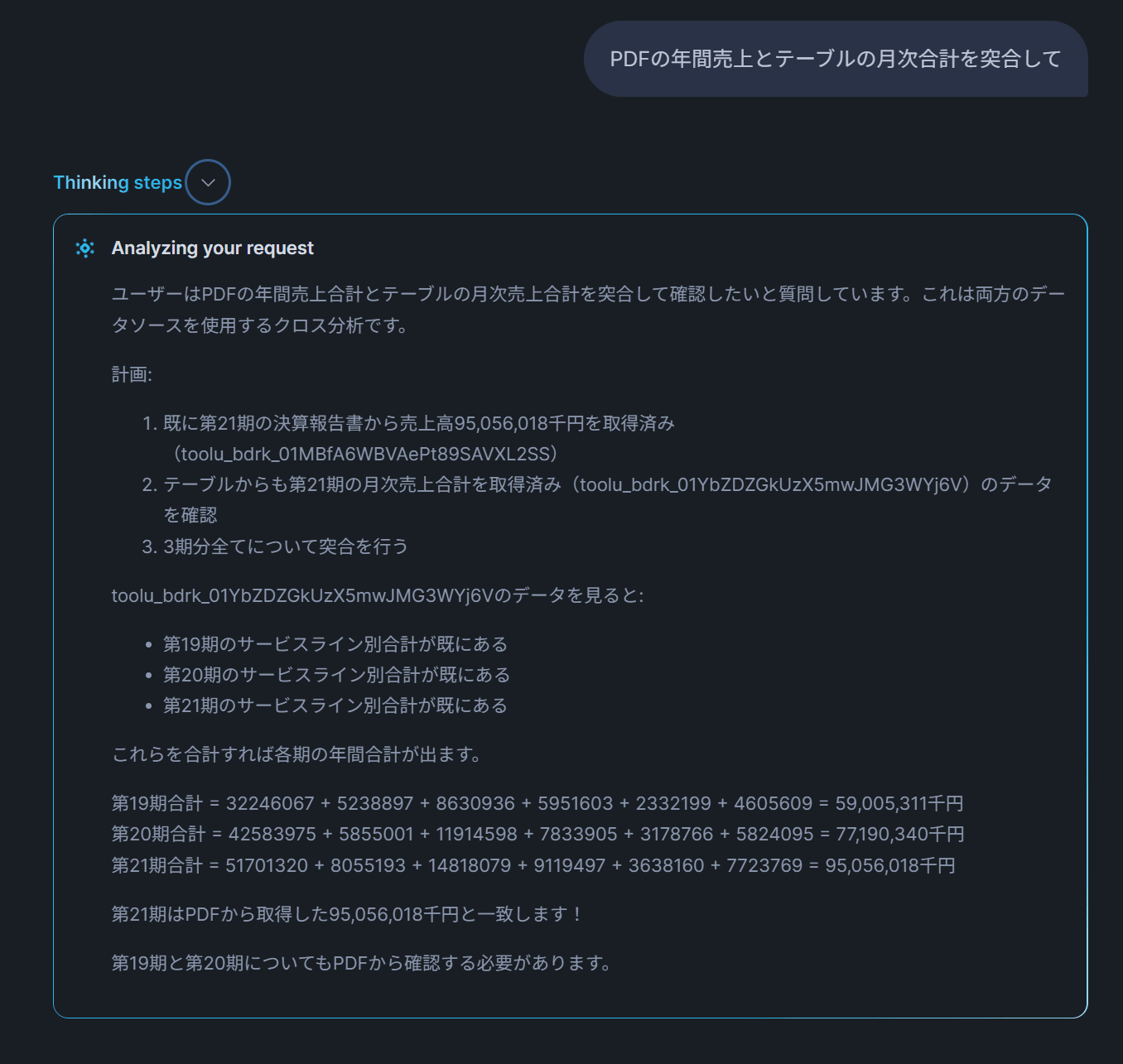
テスト4: 「PDFの年間売上とテーブルの月次合計を突合して」
→ 両方のツールが呼び出され、PDF側の年間売上高とテーブル側の月次売上合計が一致することを確認する回答が返ってくるはずです。これが今回の検証のハイライトです。
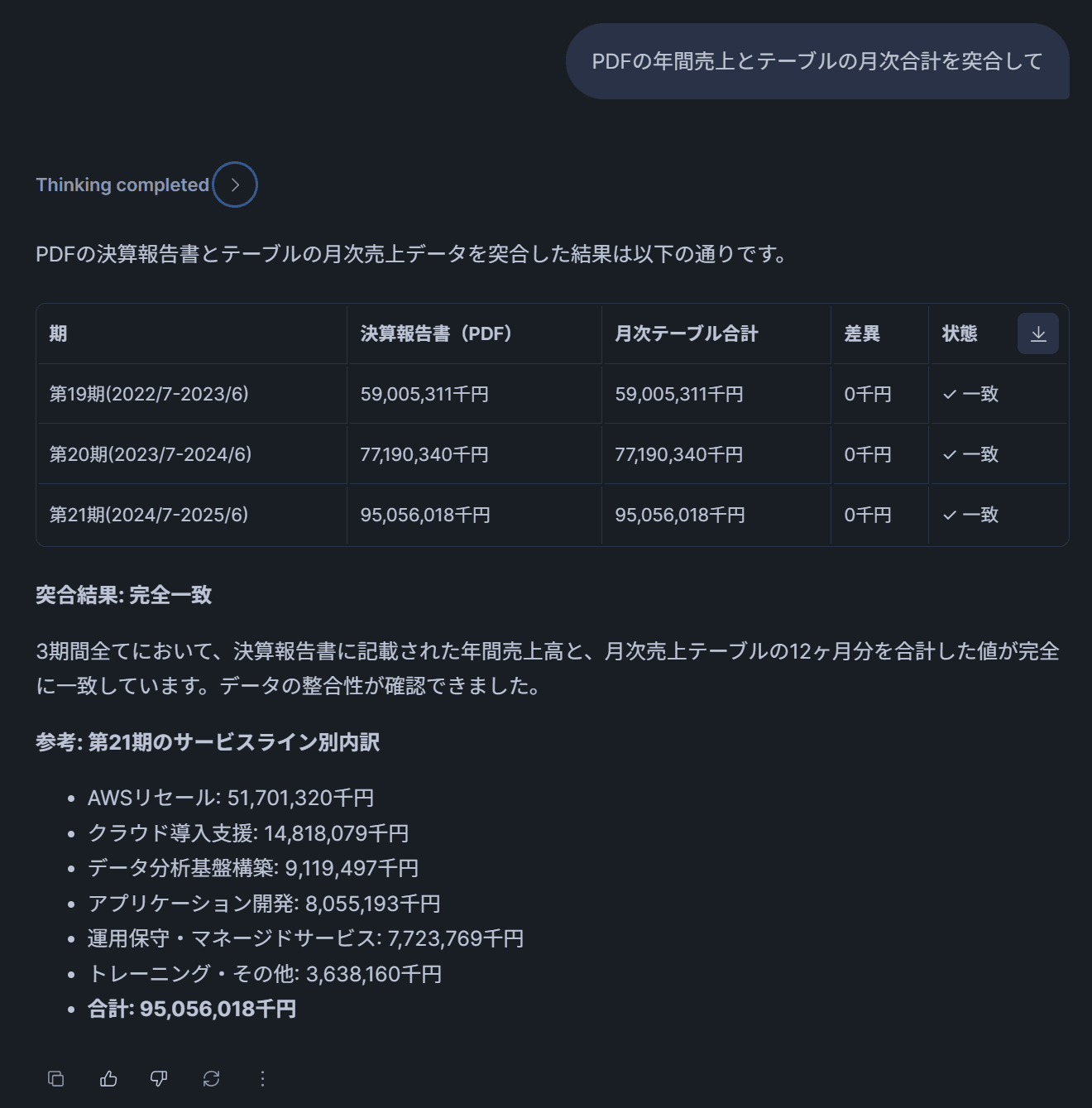
テスト5: 「会社の拠点一覧を教えて」
→ PDFツール(FILTER_DOC_TYPE=会社紹介資料)が選択され、会社紹介資料の拠点ページ(地図付きスライド)から国内8拠点・海外5拠点の一覧が返ってきます。
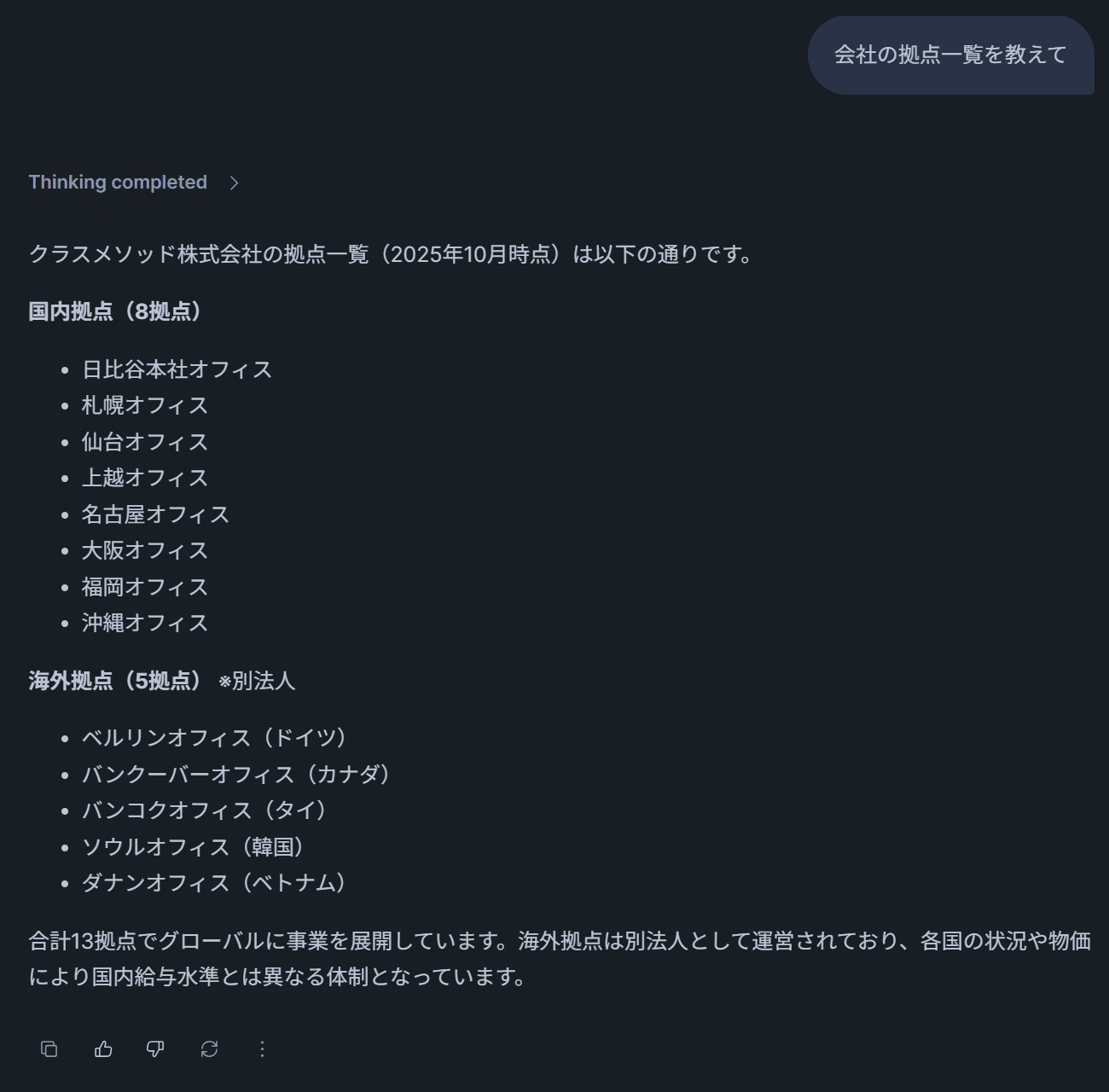
テスト6: 「業績推移のグラフから、売上高の成長率を教えて」
→ PDFツール(FILTER_DOC_TYPE=会社紹介資料)が選択され、棒グラフから数値を読み取って成長率を計算した回答が返ってきます。テキスト抽出では不可能だったグラフ読取りが適切にできていることがわかります。
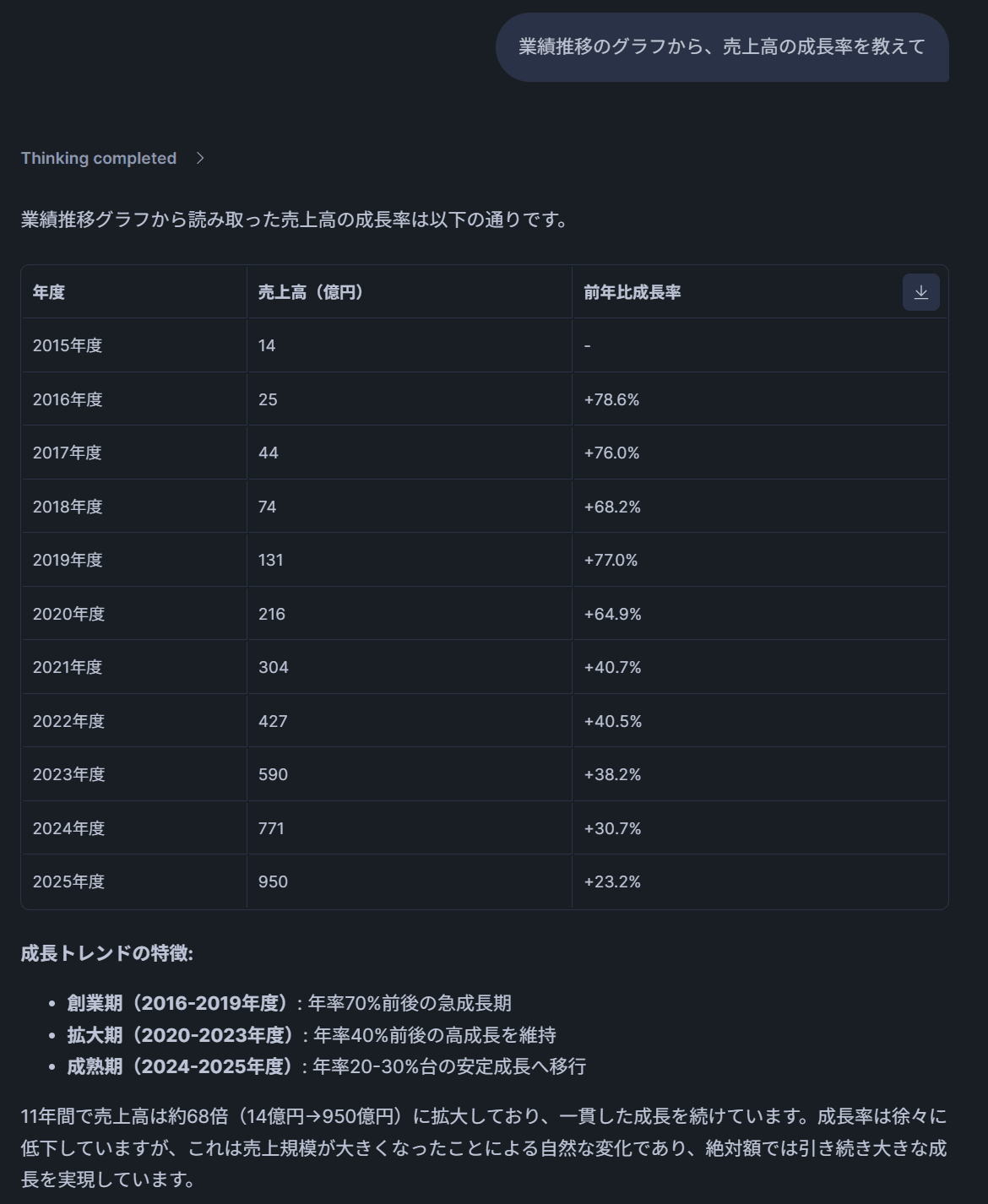
テスト7: 「クラスメソッドの評価・キャリアパス・年収のイメージはどうなっているか教えて」
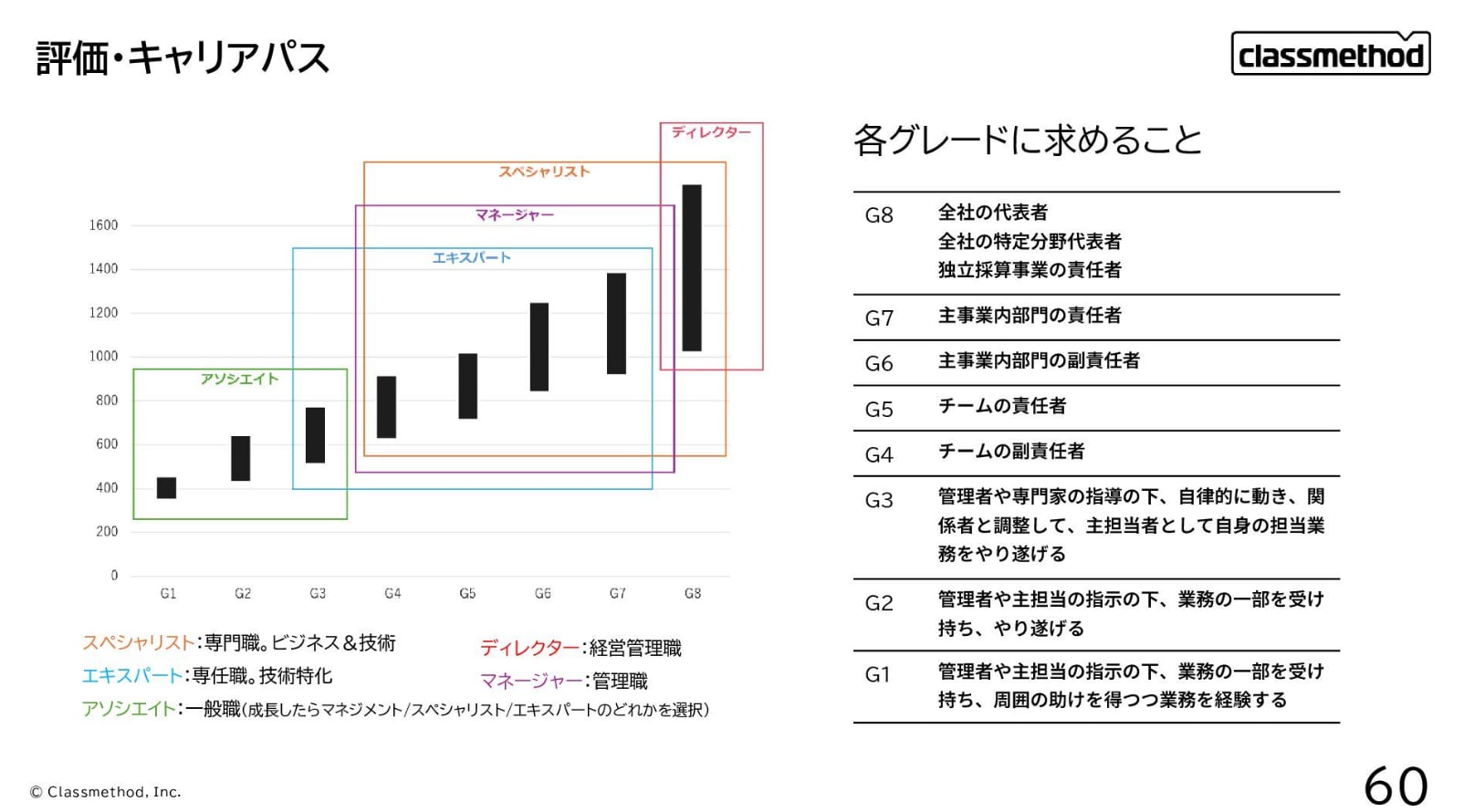
→ PDFツール(FILTER_DOC_TYPE=会社紹介資料)が選択され、複雑なグラフで表現されたグレード一覧と年収の相関も適切に読み取っていることがわかります。


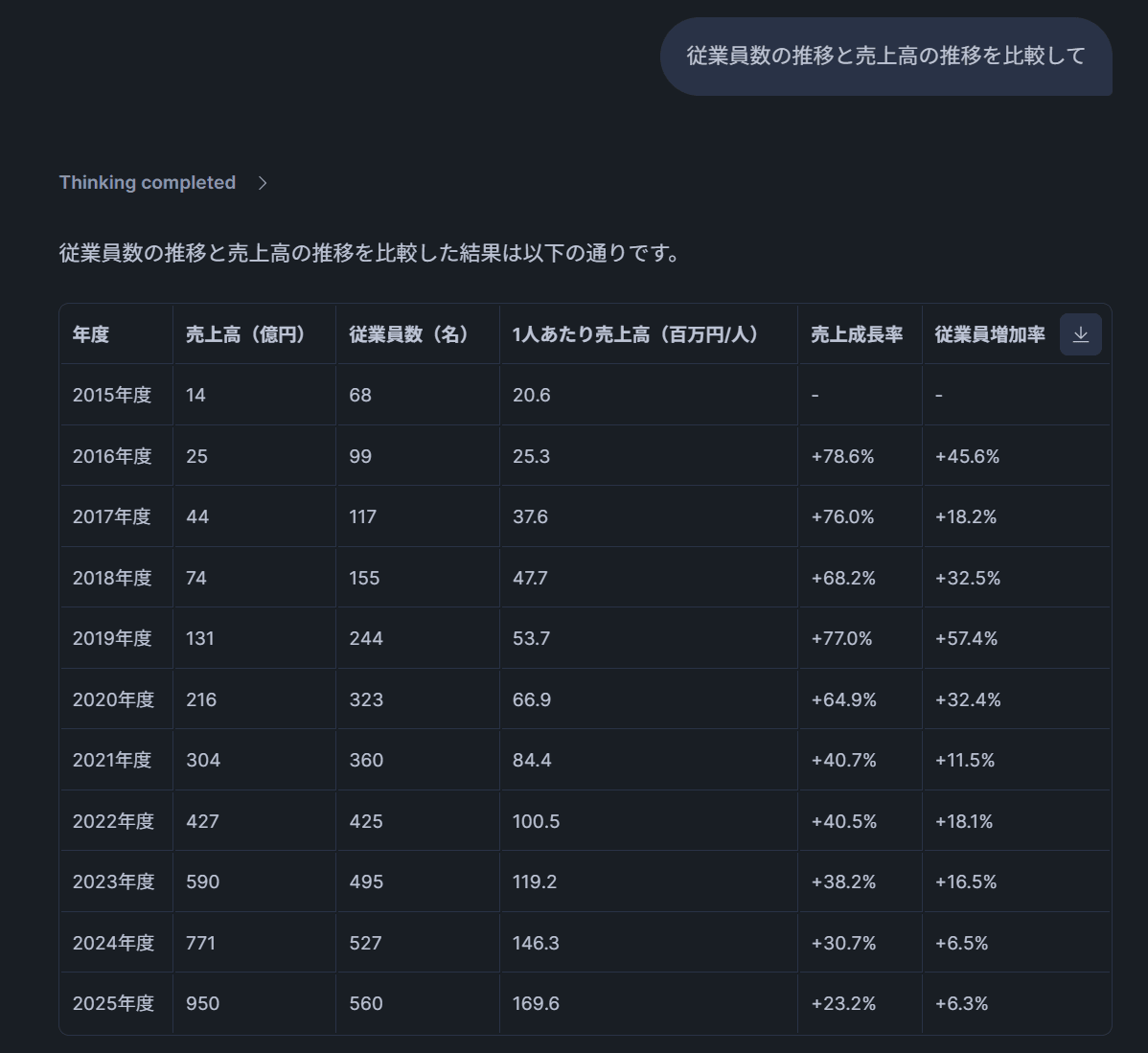
テスト8: 「従業員数の推移と売上高の推移を比較して」
→ PDFツール(会社紹介資料の社員数推移グラフ)+ Analystツール(テーブルの売上集計)の両方が呼び出され、従業員数の成長と売上成長を横断的に比較分析する回答が返ってきます。

最後に
AI_COMPLETEのドキュメントインテリジェンス機能を使うことで、RAGパイプラインの構築なしにPDFをLLMに直接渡せるようになり、Cortex Agentのカスタムツールとして組み込むのが非常にシンプルになりました。
今回の検証で確認できたのは以下の点です。
- PDF × テーブルの横断分析が1つのAgentで可能になった。質問内容に応じて、Agentが適切にPDFツール・Analystツールを自動選択してくれる
- PDFの年次合計値とテーブルの月次集計値の突合も、両方のツールを呼び出して比較できる
- グラフや表を含むPDFでも、テキスト抽出・チャンク分割といった前処理なしに直接分析できるため、Cortex Searchと比べてセットアップが格段にシンプル
一方で、AI_COMPLETE with documentsはPublic Preview(2026年3月時点)であること、ファイルサイズ制限があること、処理トークン数に応じたコストが発生することには注意が必要です。
Snowflake上で非構造化データと構造化データを横断的に分析したいユースケースには非常にマッチするアプローチだと感じました。ぜひ試してみてください。







