
【レポート】あらゆるデータをつなぐ。Snowflake Openflowで実現する統合パイプラインと相互運用性 #SWTTokyo25
Snowflake Openflowを活用することで、構造化データ、非構造化データ、バッチデータ、ストリーミングデータなど、あらゆる種類のデータを統合し、制限のない相互運用性と展開の柔軟性を実現させます。本セッションでは、Enterprise AIの利点を最大限に利用するための統合パイプラインの構築について解説します。
2025.09.16
かわばたです。
2025年9月11日~2025年9月12日に、「SNOWFLAKE WORLD TOUR 2025 - TOKYO」が開催されました。
本記事はセッション
【あらゆるデータをつなぐ。Snowflake Openflowで実現する統合パイプラインと相互運用性】
のレポートブログとなります。
登壇者
Snowflake
第三ソリューションエンジニアリング
本部長
草野 繁 氏
お客様の声

- 上記以外に、生成AIの仕組みを活用したいというニーズが高まっています。
- そのために、社内で活用しているデータをどのようにして生成AIの環境に持っていくか、という課題が必ず出てきます。
データ統合における課題

- 複雑化するニーズと分断されたパイプライン:様々なユースケースを適用しようとすると、新しいツールを加えたり、システムを変更したりする必要がある。
- 生成AI活用という新たな要件:生成AIのユースケースを社内で展開しようとすると、データベース以外の非構造化データなど、今まで想定もしなかったデータソースからデータを持ってくる必要がある。
- 利便性と実装の複雑さのバランス:GUIで簡単に定義できるシンプルなデータの取り込みは便利ですが、少し複雑な実装をしようとすると、途端に全てスクリプトベースでの対応が必要になる。
現代の統合ニーズ

- シンプル:あらゆるデータをシンプルに取り込む
- 効率性:お客様ごとのセキュリティレベルや要件のバランスを考え、柔軟な導入形態をサポートする
- 信頼性:どのようなデータソースから、どれくらいのデータ量を取り込んでいるのかを正確に把握できる可視性を担保
上記を実現するのが、Snowflake Openflow

Snowflake Openflow

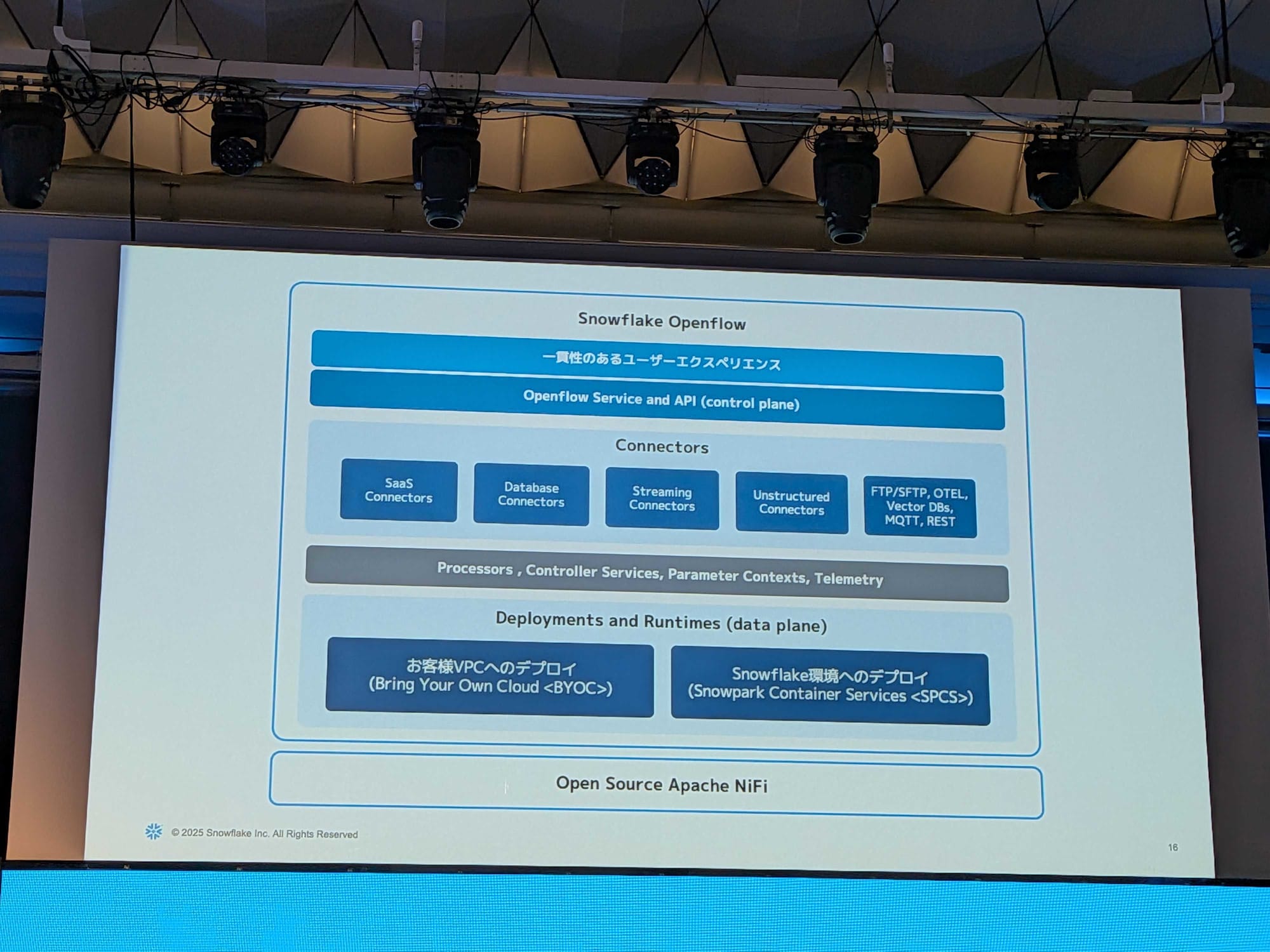
- Open Flowは、様々なデータソースからデータを「持ってくる」という役割を担っています。
Apache NiFiをベースに作られている。
データ移動への対応
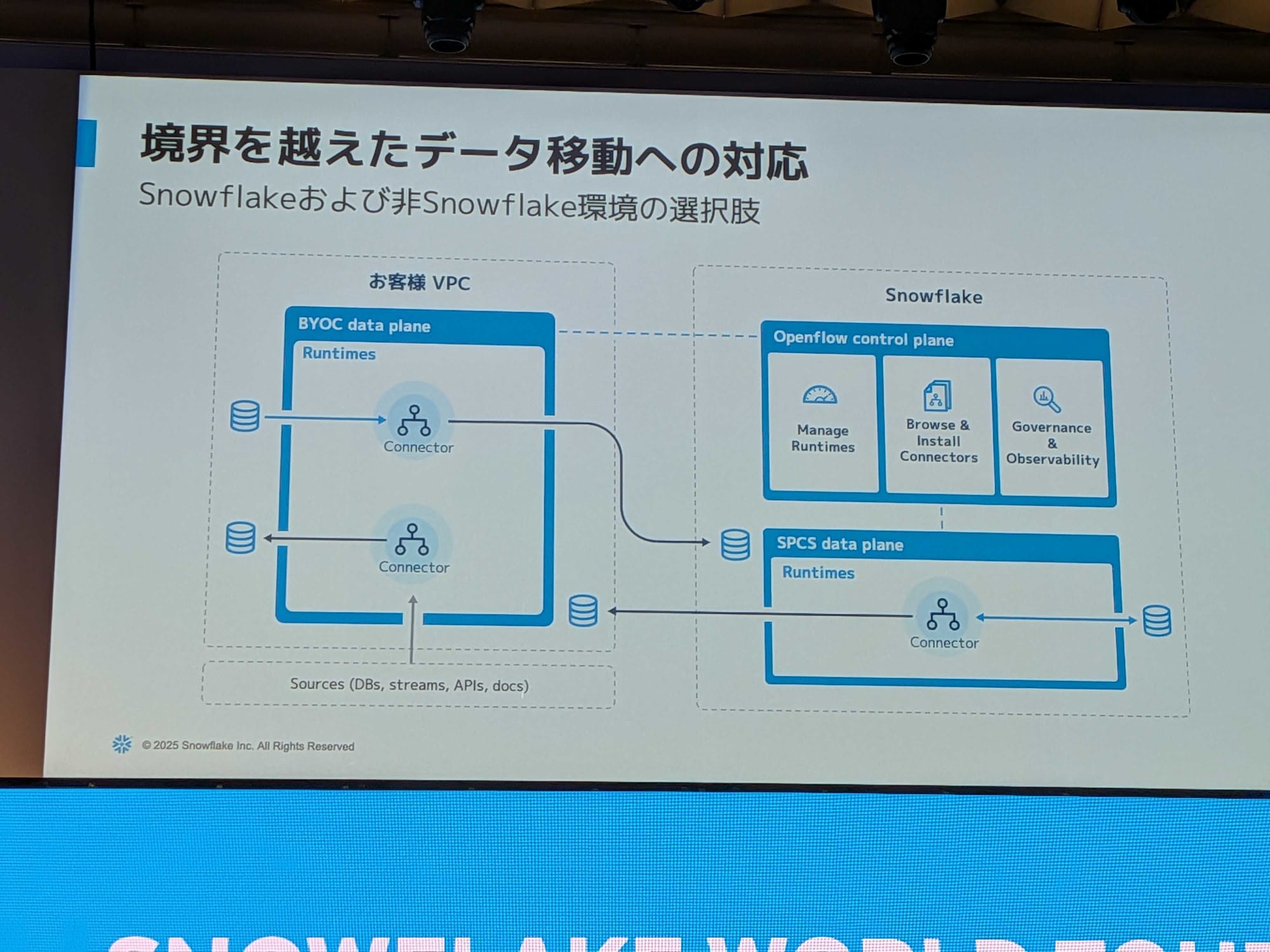
Open Flowは、実際にデータを取ってくるデータプレーンと、それを管理するコントロールプレーンで構成されています。
データプレーンの導入形態
- BYOC (Bring Your Own Cloud) 形式:管理するクラウド環境のネットワーク内に、データを取得するためのエンジンを配置する形態。
- Snowflake Managed形式:データプレーンをSnowpark Container Services (SPCS) という、Snowflakeが提供するコンテナプラットフォーム上に配置する形態。
リリース状況

- 現時点で一般提供されているのは、AWS環境におけるBYOC形式のパターンのみ ※ブログ投稿時点
- データプレーンとして展開された環境で利用されたコンピューティングリソースが動いていた時間分だけ課金されます。
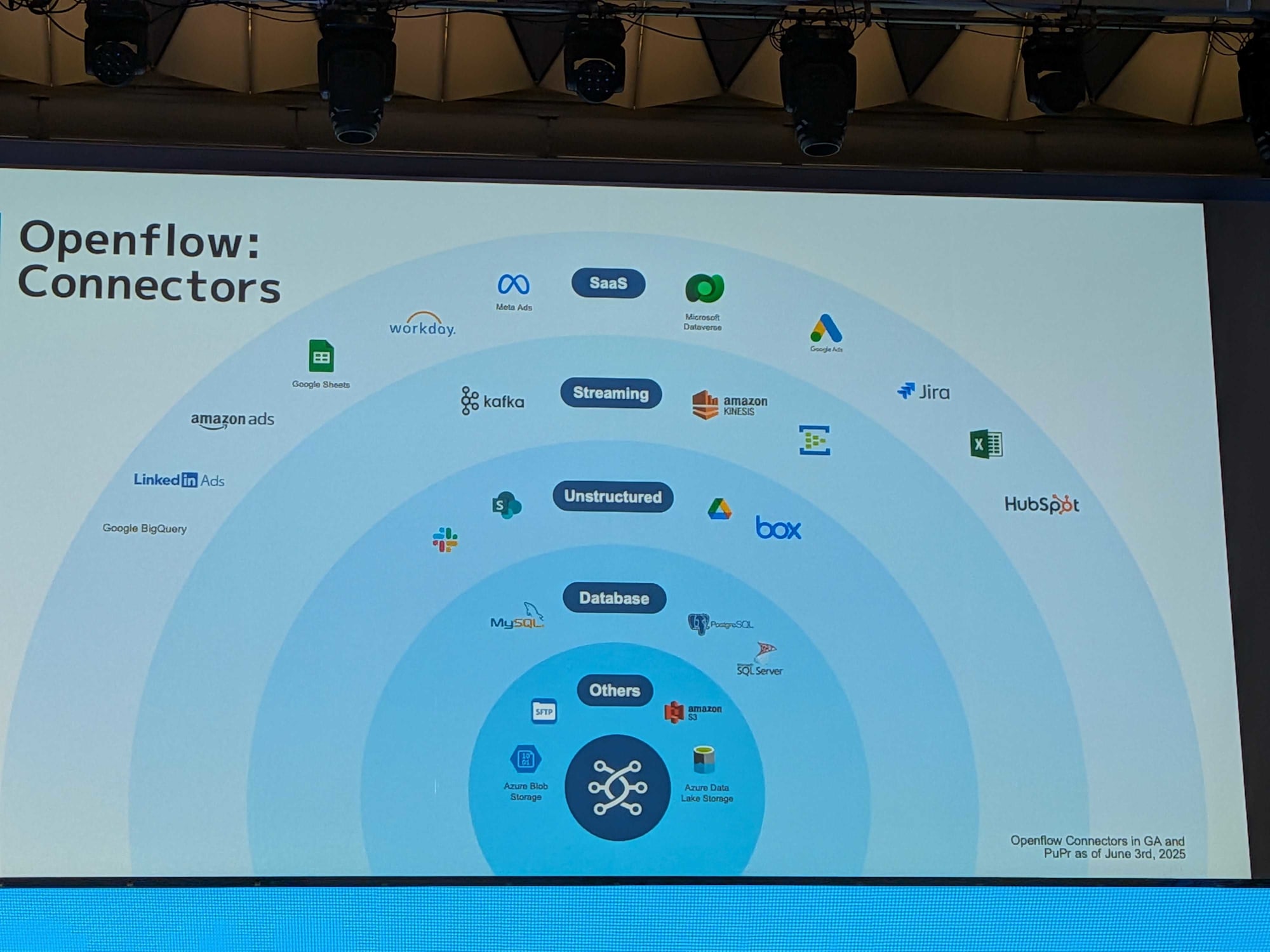
現在サポートされているコネクタ
ユースケース

- 変更データキャプチャー(CDC)with OLTP:業務システムのデータベースで発生した変更情報を逐次キャプチャーし、Snowflakeに取り込むことで、より準リアルタイムな情報に基づいた分析やAI活用が可能になります。
- 拡張性の高いストリーミングパイプライン:Open Flowは、Snowflakeがもともと提供しているSnowpipe Streamingとの連携が可能です。
- AI向けのデータパイプライン:Open Flowの原型である
Apache NiFiは、もともと非構造化データを扱う目的で作られた背景があり、生成AIの活用に不可欠な非構造化データをSnowflakeに流し込むといった用途に適しています。
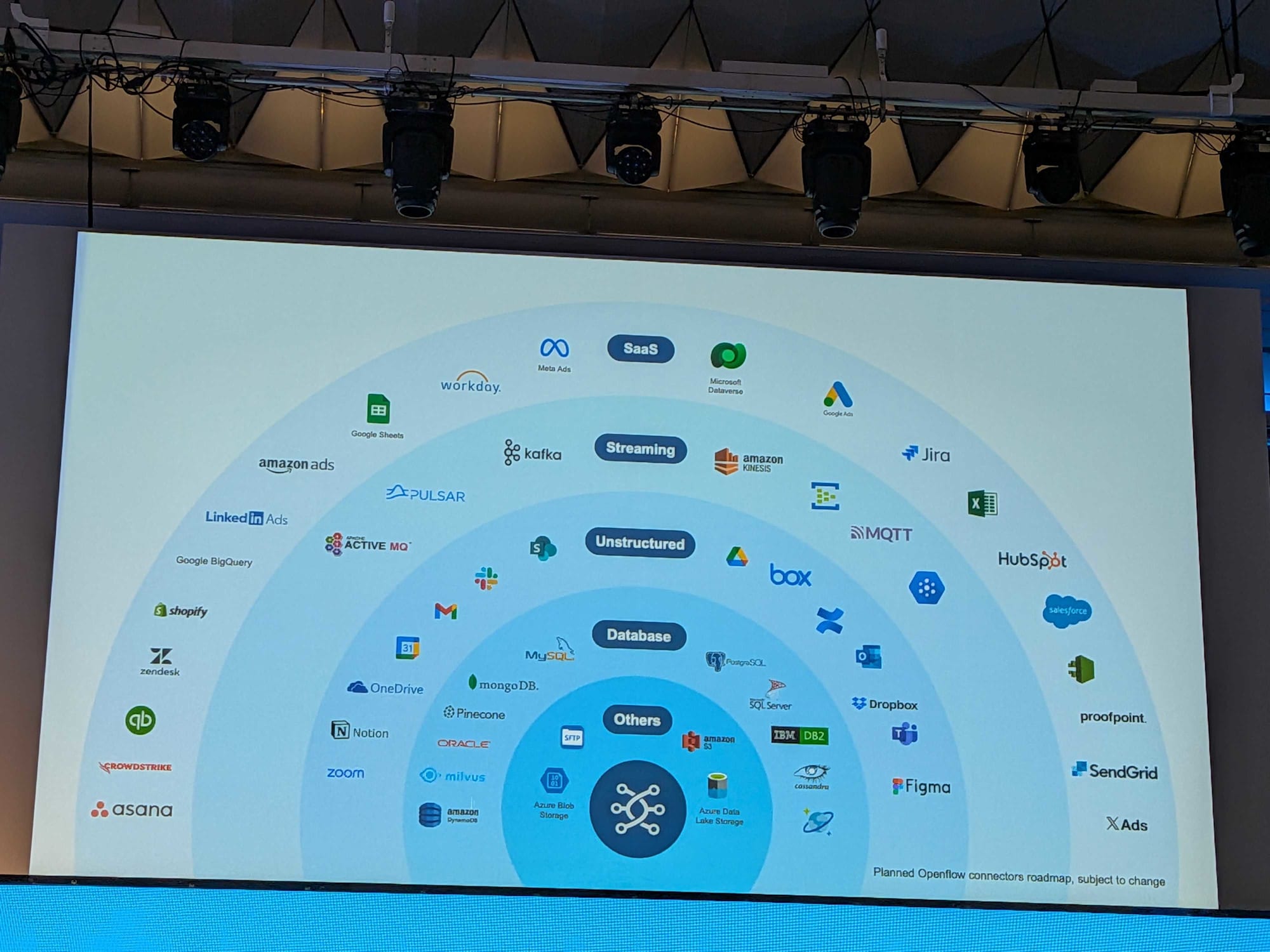
今後
最後に
Snowflake Openflowの技術的背景から今後の展望まで聞くことが出来たセッションでした!
コネクタが増えて色々なツールに接続できるようになると、便利ですね。
Snowflakeだけで完結する未来がくるかもしれません。
この記事が何かの参考になれば幸いです。









