
Snowflake の スキーマ追従(schema evolution)機能の挙動を確認してみた。
こんにちは、みかみです。
沖縄、台風6号の影響で月曜は停電発生しましたが、火曜には復旧しました。過去1週間ほど停電が続いたこともあったので、今回も覚悟して近くのコワーキングスペースを探したりしましたが、復旧してくれて一安心です。
本州近くの進路を取りそうとのことで、どうぞお気をつけください。
はじめに
Snowflake の schema evolution 機能を使うと、ロードファイルのフォーマットがテーブル定義と異なっていても、自動でテーブル定義を更新してエラーになることなくデータを取り込むことができます。
しかし、公式ドキュメントには、この schema evolution 機能は Task では未サポートとの記載があります。
COPY INTO を実行する Task でも schema evolution はサポートされていないのかどうか確かめたいと思いました。
本ブログでは、COPY INTO の 手動実行、COPY INTO の Task 実行、Snowpipe の3パターンで、以下の5つのケースのスキーマ差異のあるファイルの取り込み時の挙動を確認します。
- case1:カラム追加 + カラム削除
- case2:カラム順序差異あり
- case3:カラム(ファイルヘッダ)名差異あり
- case4:NOT NULL カラムのファイルデータ値欠如
- case5:データ型差異あり
やりたいこと
- Snowflake の schema evolution 機能の挙動を確認したい
- Snowflake の schema evolution 機能は snowpipe や Task からでも利用できるか確認したい
前提
本ブログでは、GCS から Snowflake on AWS へのデータ取り込みを検証します。
Snowflake の ストレージ統合や外部ステージなどの、Task や Snowpipe に必要なリソースは作成済みであるものとします。
新規作成が必要な場合は、以下ご参照ください。
また、Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
GCS の操作に必要な API の有効化と権限は付与済みです。
Snowflake 環境側でも、必要なユーザーの作成や権限付与は実施済みです。
準備:検証用テーブルとサンプルデータファイルを準備
以下の SQL を実行して、データロード先の Snowflake のテーブルとファイルフォーマットを作成します。
CREATE OR REPLACE TABLE SE_TEST (id NUMBER NOT NULL, name STRING, age NUMBER)
ENABLE_SCHEMA_EVOLUTION = TRUE;
CREATE OR REPLACE FILE FORMAT SE_CSV_FORMAT
TYPE = 'CSV'
PARSE_HEADER = TRUE
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
ERROR_ON_COLUMN_COUNT_MISMATCH = FALSE;
続いて以下のコマンドで、サンプルデータファイルを作成して GCS バケットにアップロードします。
# 初期データファイル(全ケース共通)
cat << 'EOF' > initial.csv
id,name,age
1,Alice,25
2,Bob,30
EOF
# case1:カラム追加(email を id と name の間に挿入)+ age カラム削除
cat << 'EOF' > case1_evolution.csv
id,email,name
3,charlie@example.com,Charlie
EOF
# case2:カラム順序変更(age, name, id の順)
cat << 'EOF' > case2_evolution.csv
age,name,id
35,Charlie,3
EOF
# case3:カラム名変更(name → full_name)
cat << 'EOF' > case3_evolution.csv
id,full_name,age
3,Charlie,35
EOF
# case4:NOT NULL カラムの欠落(id カラムなし)
cat << 'EOF' > case4_evolution.csv
name,age
Charlie,35
EOF
# case5:データ型変更(age に数値として解釈できない文字列)
cat << 'EOF' > case5_evolution.csv
id,name,age
3,Charlie,thirty-five
EOF
# 初期データアップロード
gcloud storage cp initial.csv gs://test-mikami/schema_evolution/initial/
# COPY INTO 用 evolution ファイル(全ケース分をアップロード)
gcloud storage cp case1_evolution.csv gs://test-mikami/schema_evolution/copy/
gcloud storage cp case2_evolution.csv gs://test-mikami/schema_evolution/copy/
gcloud storage cp case3_evolution.csv gs://test-mikami/schema_evolution/copy/
gcloud storage cp case4_evolution.csv gs://test-mikami/schema_evolution/copy/
gcloud storage cp case5_evolution.csv gs://test-mikami/schema_evolution/copy/
# Task 用 evolution ファイル(全ケース分をアップロード)
gcloud storage cp case1_evolution.csv gs://test-mikami/schema_evolution/task/
gcloud storage cp case2_evolution.csv gs://test-mikami/schema_evolution/task/
gcloud storage cp case3_evolution.csv gs://test-mikami/schema_evolution/task/
gcloud storage cp case4_evolution.csv gs://test-mikami/schema_evolution/task/
gcloud storage cp case5_evolution.csv gs://test-mikami/schema_evolution/task/
COPY INTO 手動実行
Snowflake で COPY INTO 文を手動実行した場合の schema evolution の挙動を確認します。
以下の SQL で、初期データをロードします。
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/initial/
FILES = ('initial.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
テーブルに2行のデータがロードできました。
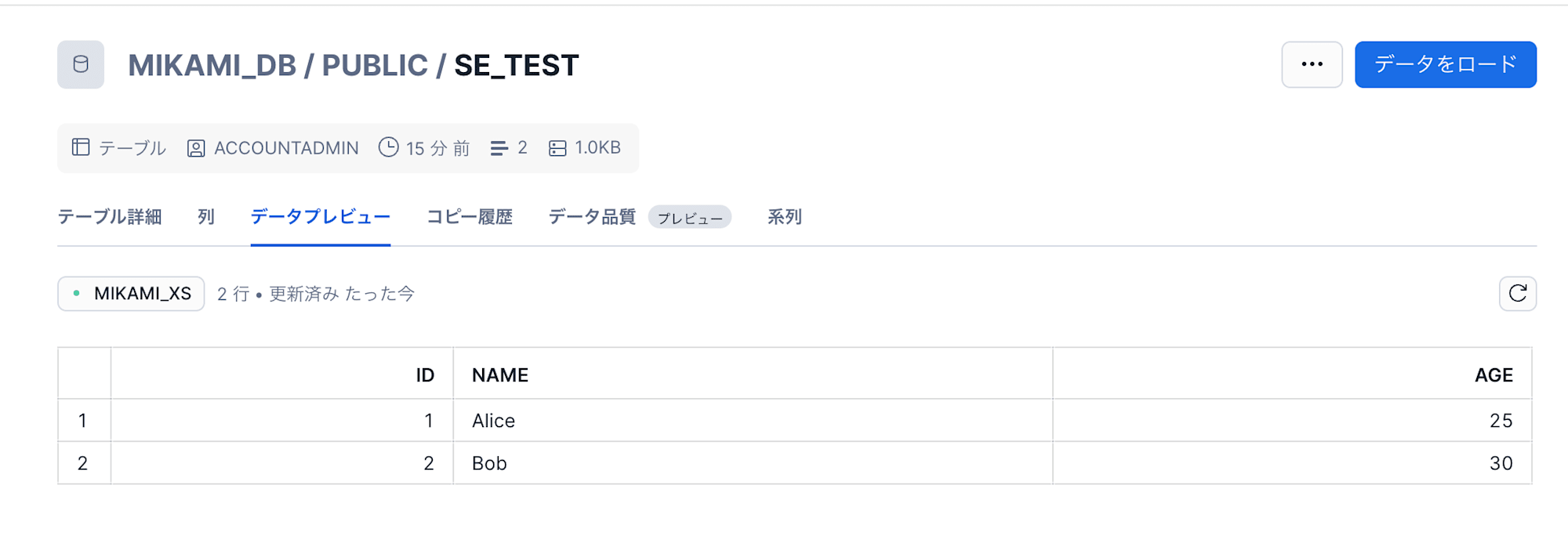
case1:カラム追加 + カラム削除
以下のファイルデータを、先程初期データをロードしたテーブルに取り込みます。
$ gcloud storage cp gs://test-mikami/schema_evolution/copy/case1_evolution.csv -
Copying gs://test-mikami/schema_evolution/copy/case1_evolution.csv to file://-
id,email,name
3,charlie@example.com,Charlie
テーブル定義と比べて、email が追加され、age が削除されています。
以下の SQL を手動実行します。
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/copy/
FILES = ('case1_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
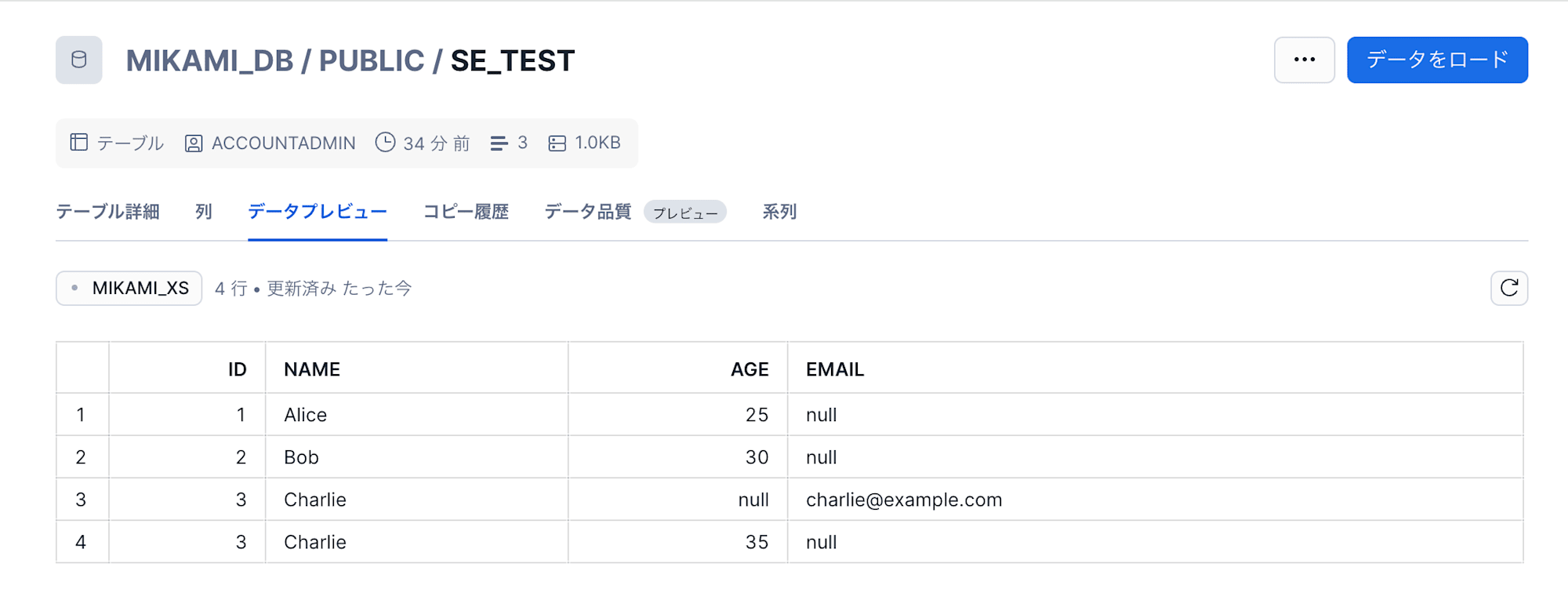
テーブルデータを確認します。

email カラムがテーブルに追加され、ファイルに存在しなかった age カラムは削除されることなく null 値でデータがロードされました。
case2:カラム順序差異あり
次に、以下のテーブル定義のカラム順とは異なるデータファイルを取り込みます。
$ gcloud storage cp gs://test-mikami/schema_evolution/copy/case2_evolution.csv -
Copying gs://test-mikami/schema_evolution/copy/case2_evolution.csv to file://-
age,name,id
35,Charlie,3
以下の SQL を実行します。
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/copy/
FILES = ('case2_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
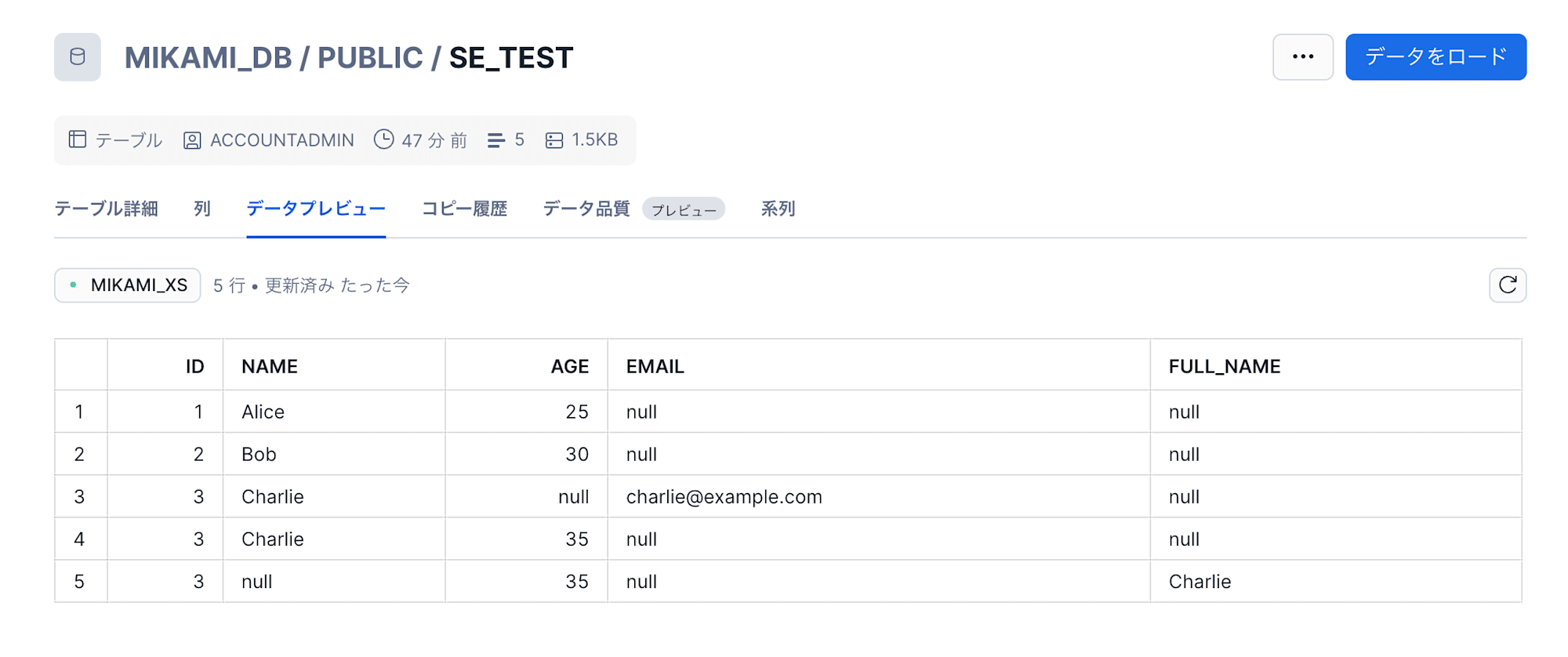
テーブル定義とデータファイルで項目の並び順が異なっていても、正常にデータが取り込めることが確認できました。
case3:カラム(ファイルヘッダ)名差異あり
続いて、テーブルのカラム名とデータファイルのヘッダの名前に差分があるファイルを取り込んでみます。
$ gcloud storage cp gs://test-mikami/schema_evolution/copy/case3_evolution.csv -
Copying gs://test-mikami/schema_evolution/copy/case3_evolution.csv to file://-
id,full_name,age
3,Charlie,35
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/copy/
FILES = ('case3_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
ファイルヘッダ名に対応する新しいカラム(full_name)が追加され、正常に取り込むことができました。
case4:NOT NULL カラムのファイルデータ値欠如
さらに、テーブルで NOT NULL 制約があるカラムのファイル項目がない場合の挙動を確認します。
$ gcloud storage cp gs://test-mikami/schema_evolution/copy/case4_evolution.csv -
Copying gs://test-mikami/schema_evolution/copy/case4_evolution.csv to file://-
name,age
Charlie,35
ロードファイルには id 項目がないので、schema evolution が適用されなければエラーでデータがロードができないはずです。
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/copy/
FILES = ('case4_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
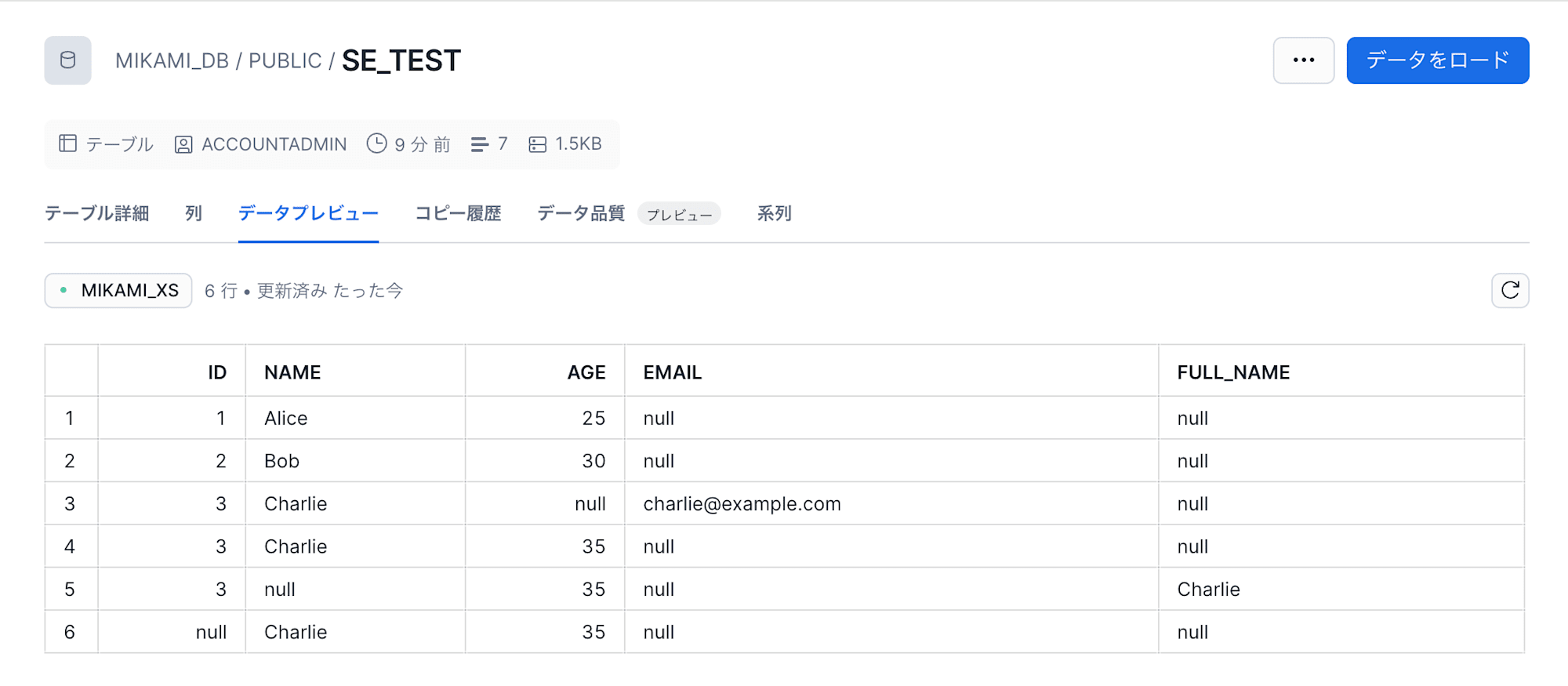
id カラム値が null となり、ファイルデータがロードできました。
テーブル定義を確認してみると
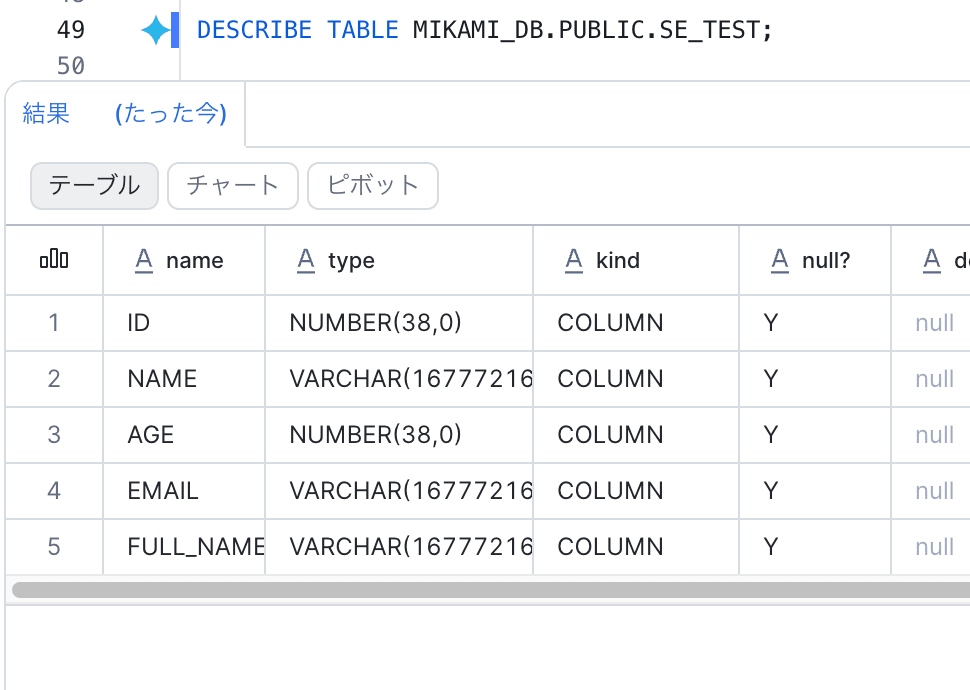
id カラムの NOT NULL 制約がなくなっています。
エラーに煩わされなくなるメリットはありますが、後続処理で結合キーに使っているカラムなどではデータ不正を検出できないリスクがあるので、ご利用の際にはご留意ください。
case5:データ型差異あり
最後に、INT 型で定義されているテーブルカラムに、STRING 型のデータを取り込もうとしてみます。
以下のデータファイルをロードします。
$ gcloud storage cp gs://test-mikami/schema_evolution/copy/case5_evolution.csv -
Copying gs://test-mikami/schema_evolution/copy/case5_evolution.csv to file://-
id,name,age
3,Charlie,thirty-five
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/copy/
FILES = ('case5_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
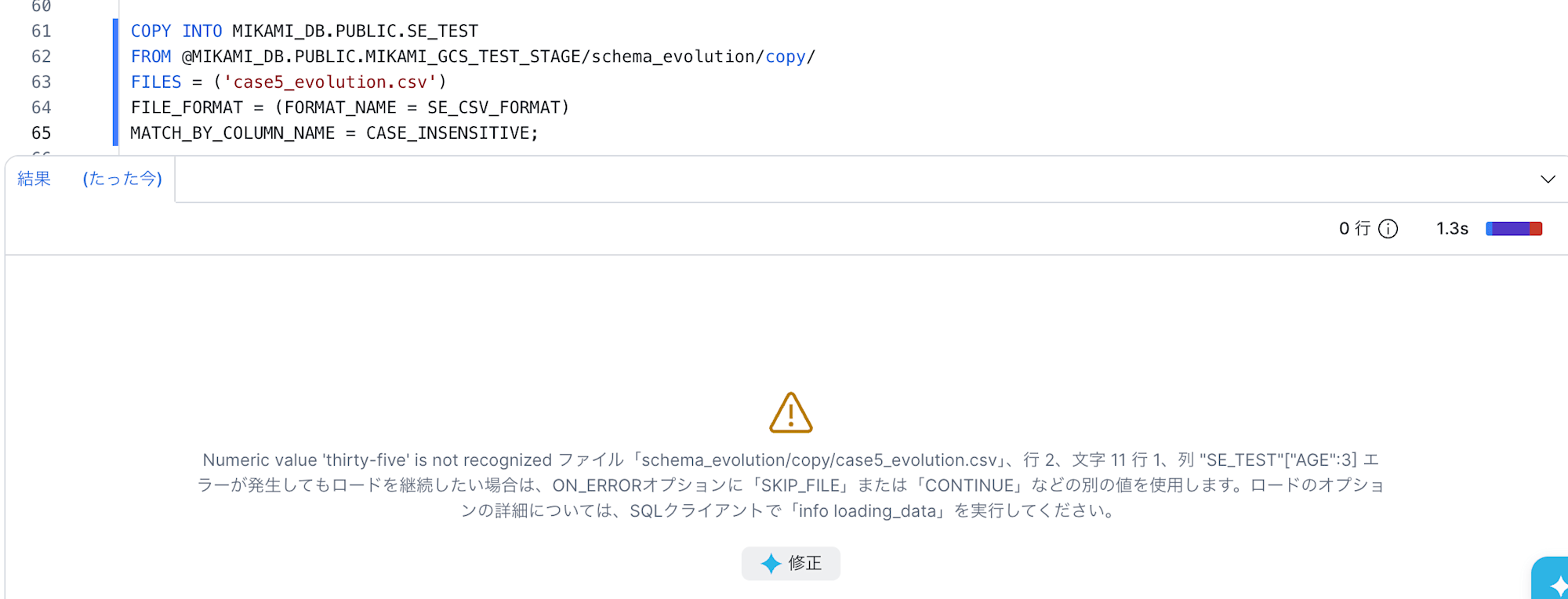
エラーが発生しました。
さすがにデータ型の変更には自動追従されないようです。
COPY INTO Task 実行
先ほどの COPY INTO 手動実行と同じ内容を、公式ドキュメントで未サポートとの記載がある Task で実行してみます。
まずはデータロード先テーブルを初期化しておきます。
CREATE OR REPLACE TABLE SE_TEST (id NUMBER NOT NULL, name STRING, age NUMBER)
ENABLE_SCHEMA_EVOLUTION = TRUE;
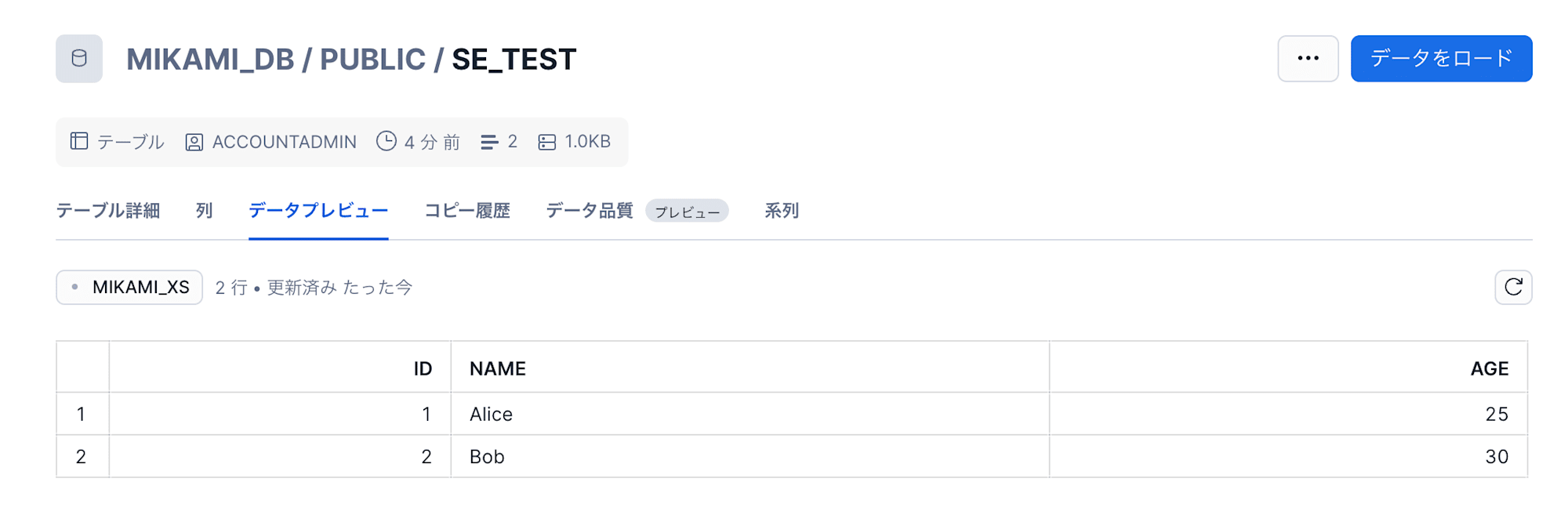
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/initial/
FILES = ('initial.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
テーブルデータは以下の状態です。
case1:カラム追加 + カラム削除
COPY INTO 手動実行時と同じデータを、Task 実行で取り込みます。
$ gcloud storage cp gs://test-mikami/schema_evolution/task/case1_evolution.csv -
Copying gs://test-mikami/schema_evolution/task/case1_evolution.csv to file://-
id,email,name
3,charlie@example.com,Charlie
以下の SQL で COPY INTO を実行する Task を作成して実行します。
CREATE OR REPLACE TASK SE_TASK WAREHOUSE = MIKAMI_XS AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case1_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
EXECUTE TASK MIKAMI_DB.PUBLIC.SE_TASK;
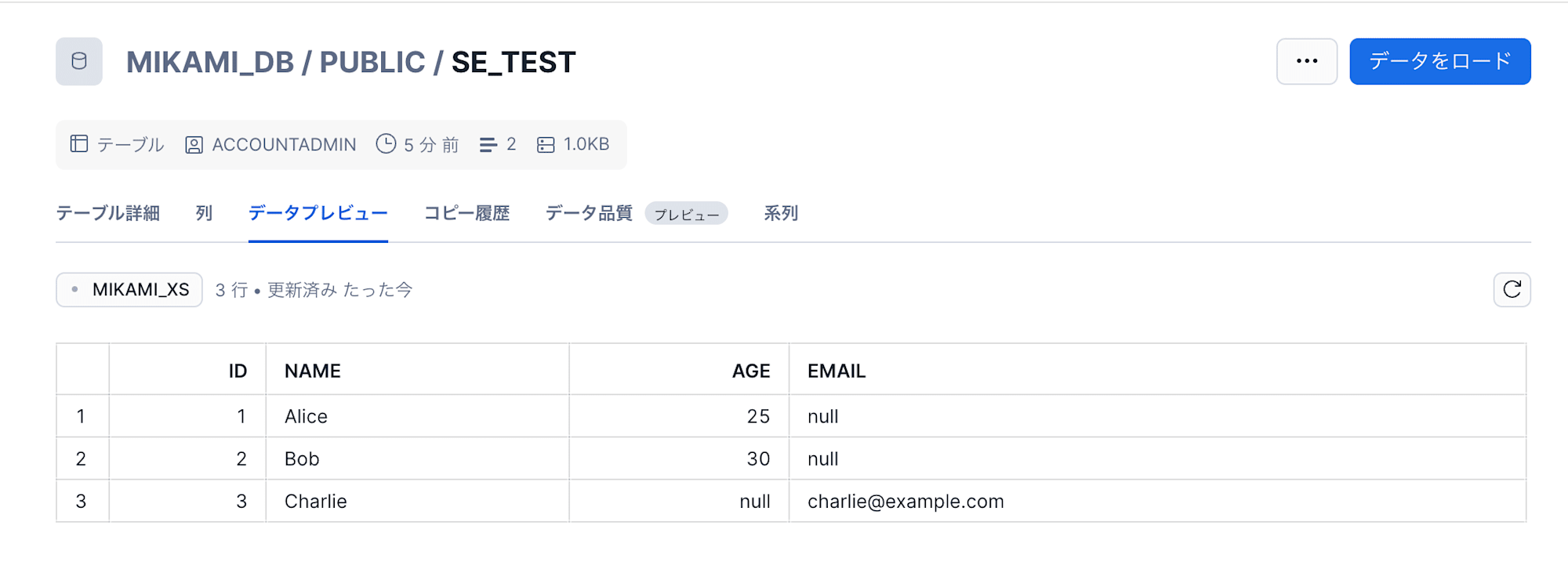
手動実行時と同じく、schema evolution が適用されているようです。
case2:カラム順序差異あり
他のケースも確認してみます。
以下の、カラム順が異なるファイルを Task 実行でロードします。
$ gcloud storage cp gs://test-mikami/schema_evolution/task/case2_evolution.csv -
Copying gs://test-mikami/schema_evolution/task/case2_evolution.csv to file://-
age,name,id
35,Charlie,3
CREATE OR REPLACE TASK SE_TASK WAREHOUSE = MIKAMI_XS AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case2_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
EXECUTE TASK MIKAMI_DB.PUBLIC.SE_TASK;
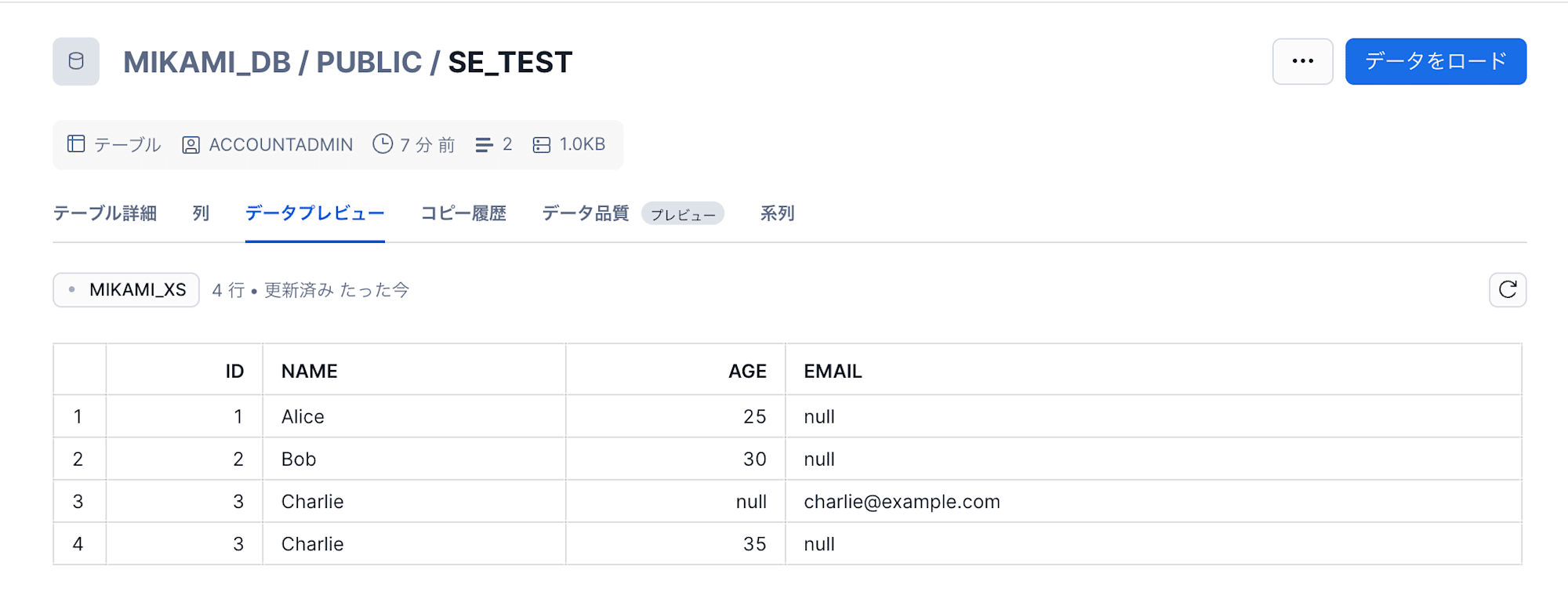
こちらも、正常にロードすることができました。
case3:カラム(ファイルヘッダ)名差異あり
データファイルのヘッダ名とテーブルカラム名に差異があるファイルです。
$ gcloud storage cp gs://test-mikami/schema_evolution/task/case3_evolution.csv -
Copying gs://test-mikami/schema_evolution/task/case3_evolution.csv to file://-
id,full_name,age
3,Charlie,35
CREATE OR REPLACE TASK SE_TASK WAREHOUSE = MIKAMI_XS AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case3_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
EXECUTE TASK MIKAMI_DB.PUBLIC.SE_TASK;
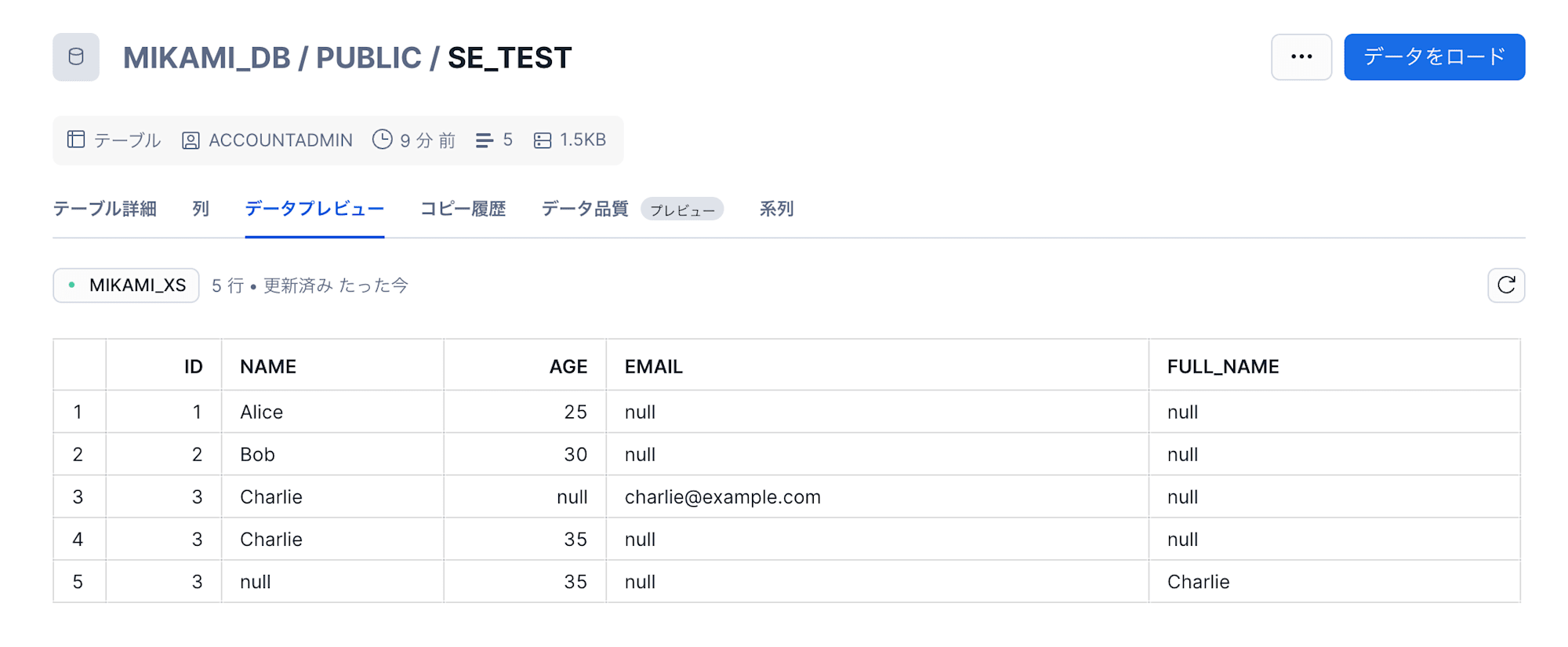
正常にロードできました。
case4:NOT NULL カラムのファイルデータ値欠如
NOT NULL カラムに相当する id 項目がないデータファイルです。
$ gcloud storage cp gs://test-mikami/schema_evolution/task/case4_evolution.csv -
Copying gs://test-mikami/schema_evolution/task/case4_evolution.csv to file://-
name,age
Charlie,35
CREATE OR REPLACE TASK SE_TASK WAREHOUSE = MIKAMI_XS AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case4_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
EXECUTE TASK MIKAMI_DB.PUBLIC.SE_TASK;

同じく、エラーになることなく取り込めています。
case5:データ型差異あり
テーブル定義とロードファイルのデータ型に差分のあるファイルです。
$ gcloud storage cp gs://test-mikami/schema_evolution/task/case5_evolution.csv -
Copying gs://test-mikami/schema_evolution/task/case5_evolution.csv to file://-
id,name,age
3,Charlie,thirty-five
CREATE OR REPLACE TASK SE_TASK WAREHOUSE = MIKAMI_XS AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case5_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
EXECUTE TASK MIKAMI_DB.PUBLIC.SE_TASK;
以下の SQL で Task の実行結果を確認してみます。
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => 'SE_TASK',
SCHEDULED_TIME_RANGE_START => DATEADD(HOUR, -1, CURRENT_TIMESTAMP())
));
SELECT * FROM MIKAMI_DB.PUBLIC.SE_TEST;
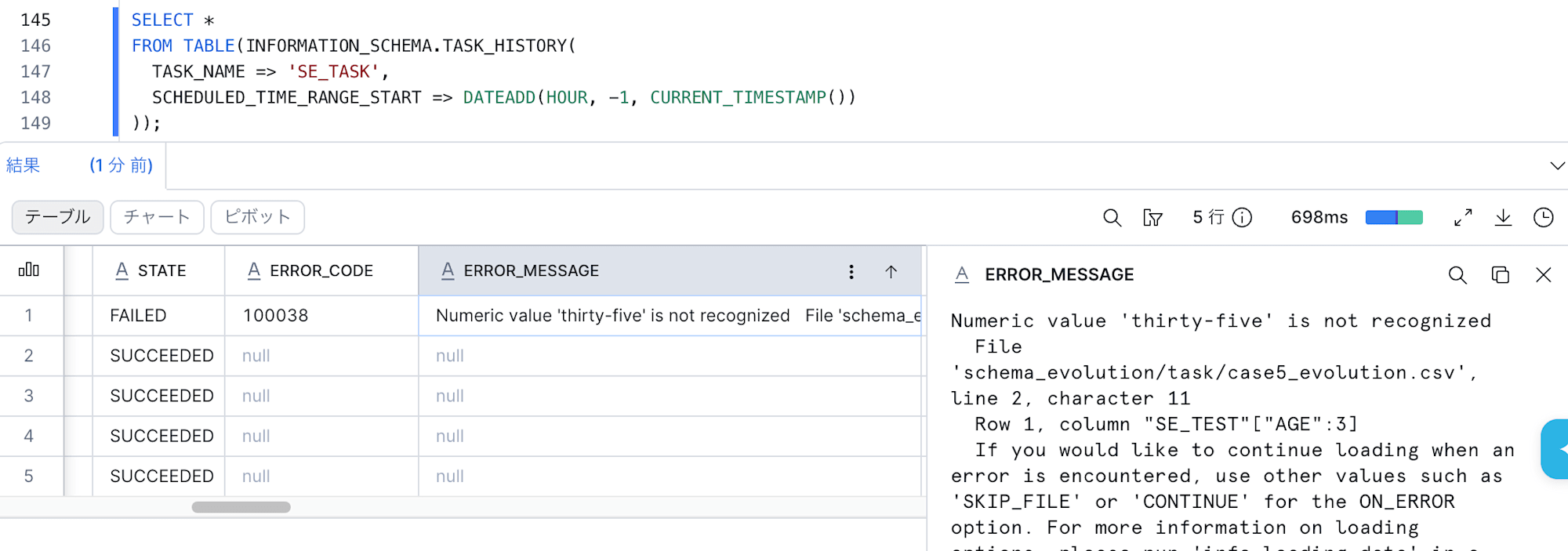
COPY INTO 手動実行時と同様、エラーが発生しました。
なお、以下のように、Task 作成時に ON_ERROR = 'CONTINUE' を追加すれば、エラーは発生せずに不正な行の取り込みはスキップされます。
CREATE OR REPLACE TASK SE_TASK WAREHOUSE = MIKAMI_XS AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case5_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
EXECUTE TASK MIKAMI_DB.PUBLIC.SE_TASK;
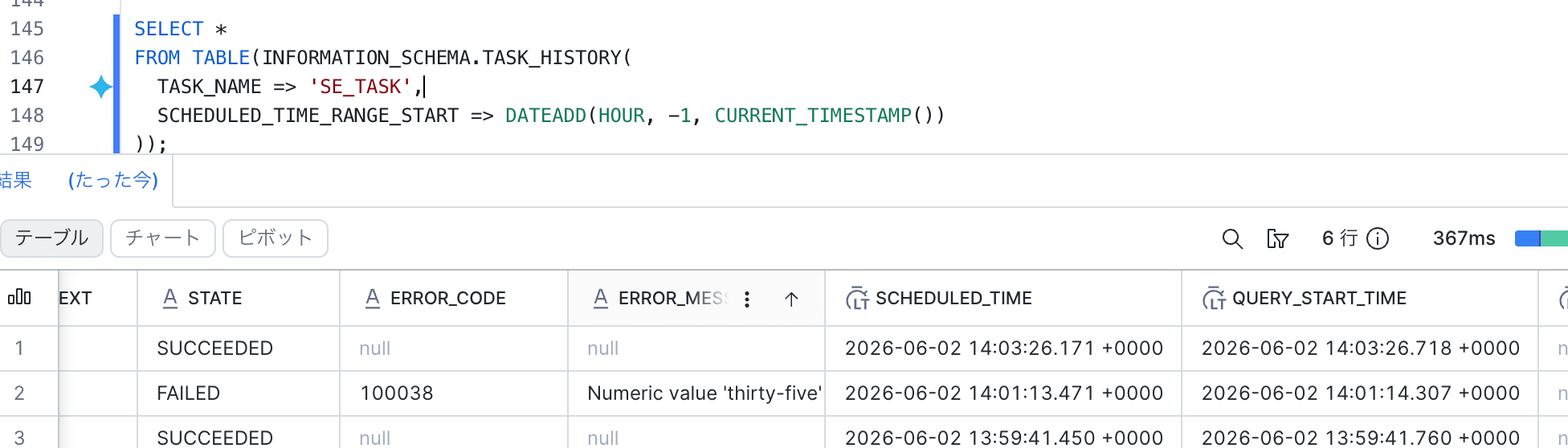
Task スケジュール実行結果を確認
検証結果から、公式ドキュメントでは未サポートと記載されている Task 実行でも、schema evolution が適用されているように見えます。
先程は EXECUTE TASK で Task を手動実行していたので、念のため Task をスケジュール実行した結果も確認しておきます。
テーブル初期化後、以下の毎分実行の Task を作成し、RESUME します。
CREATE OR REPLACE TASK SE_TASK
WAREHOUSE = MIKAMI_XS
SCHEDULE = 'USING CRON * * * * * UTC'
AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/task/
FILES = ('case1_evolution.csv')
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
ALTER TASK MIKAMI_DB.PUBLIC.SE_TASK RESUME;
case1 のカラム追加 + カラム削除 データファイルを取り込みます。
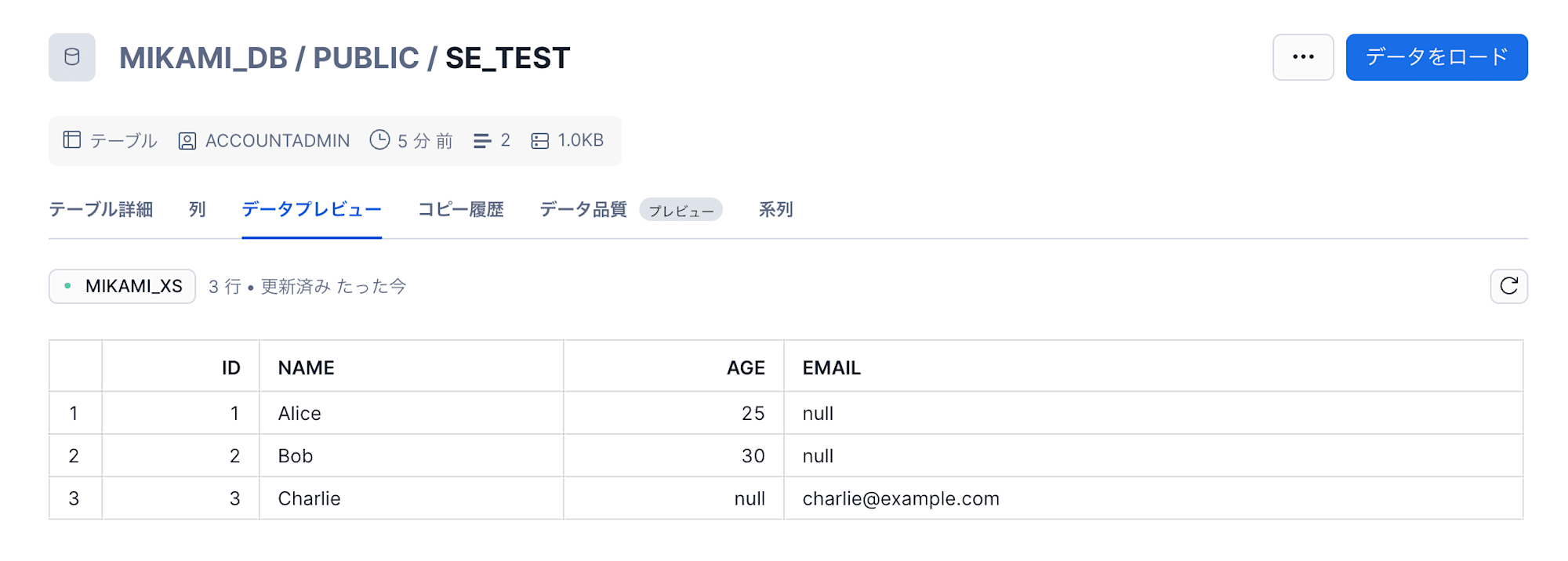
スケジュール実行 Task でも、schema evolution が利用できるようです。
ただし、本検証では Task の全ての機能を試したわけではないので、利用する際は十分に検証した上での適用をご検討ください。
動作確認後、以下の SQL で Task を停止しました。
ALTER TASK MIKAMI_DB.PUBLIC.SE_TASK SUSPEND;
Snowpipe
最後に Snowpipe での schema evolution の挙動も確認します。
データ取り込み先テーブル初期化後、以下の SQL で、Snowpipe を作成します。
CREATE OR REPLACE PIPE SE_PIPE
AUTO_INGEST = TRUE
INTEGRATION = 'MIKAMI_GCS_SNOWPIPE_NOTIFICATION'
AS
COPY INTO MIKAMI_DB.PUBLIC.SE_TEST
FROM @MIKAMI_DB.PUBLIC.MIKAMI_GCS_TEST_STAGE/schema_evolution/snowpipe/
FILE_FORMAT = (FORMAT_NAME = SE_CSV_FORMAT)
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
case1:カラム追加 + カラム削除
ロードファイルを GCS にアップロードして、取り込み結果を確認します。
gcloud storage cp case1_evolution.csv gs://test-mikami/schema_evolution/snowpipe/
Snowpipe では、GCS へのファイル put イベントを Cloud Pub/Sub 経由で検出してロード処理が動くので、ロード完了までに若干のタイムラグが発生します。
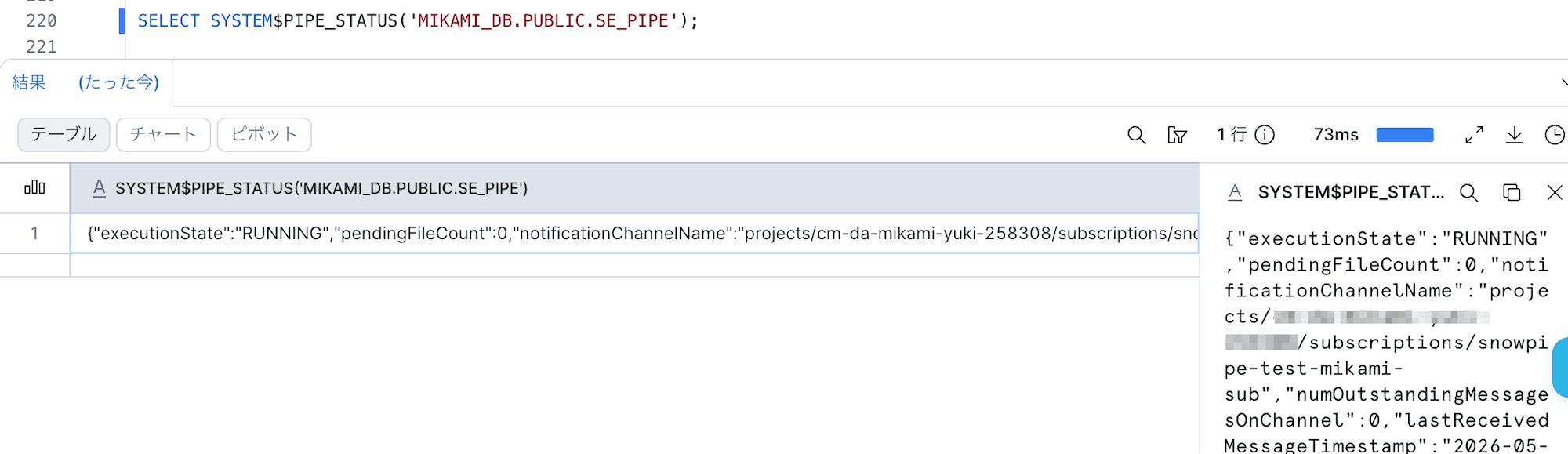
以下の SQL で Snowpipe が RUNNING であることを確認して少し待ちます。
SELECT SYSTEM$PIPE_STATUS('MIKAMI_DB.PUBLIC.SE_PIPE');
テーブルデータを確認してみると
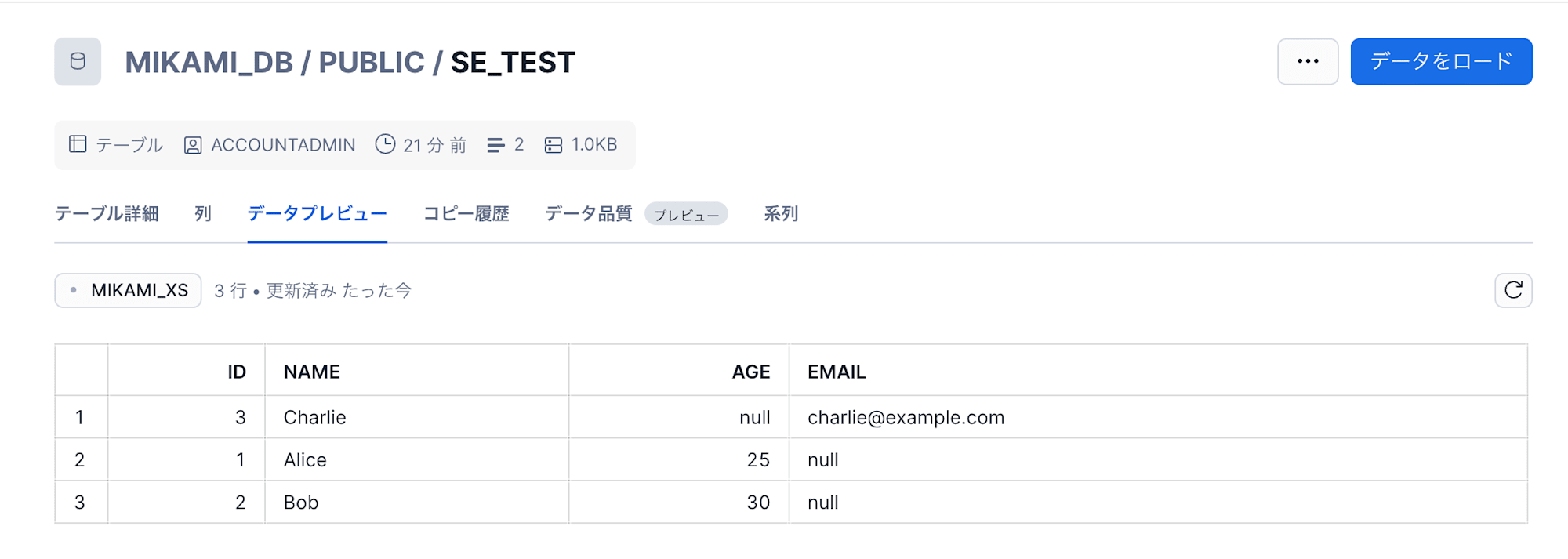
テーブルに email カラムが追加され、正常にデータがロードできました。
case2:カラム順序差異あり
同様に他ケースのデータ取り込みも確認します。
gcloud storage cp case2_evolution.csv gs://test-mikami/schema_evolution/snowpipe/
$ gcloud storage cp gs://test-mikami/schema_evolution/snowpipe/case2_evolution.csv -
Copying gs://test-mikami/schema_evolution/snowpipe/case2_evolution.csv to file://-
age,name,id
35,Charlie,3
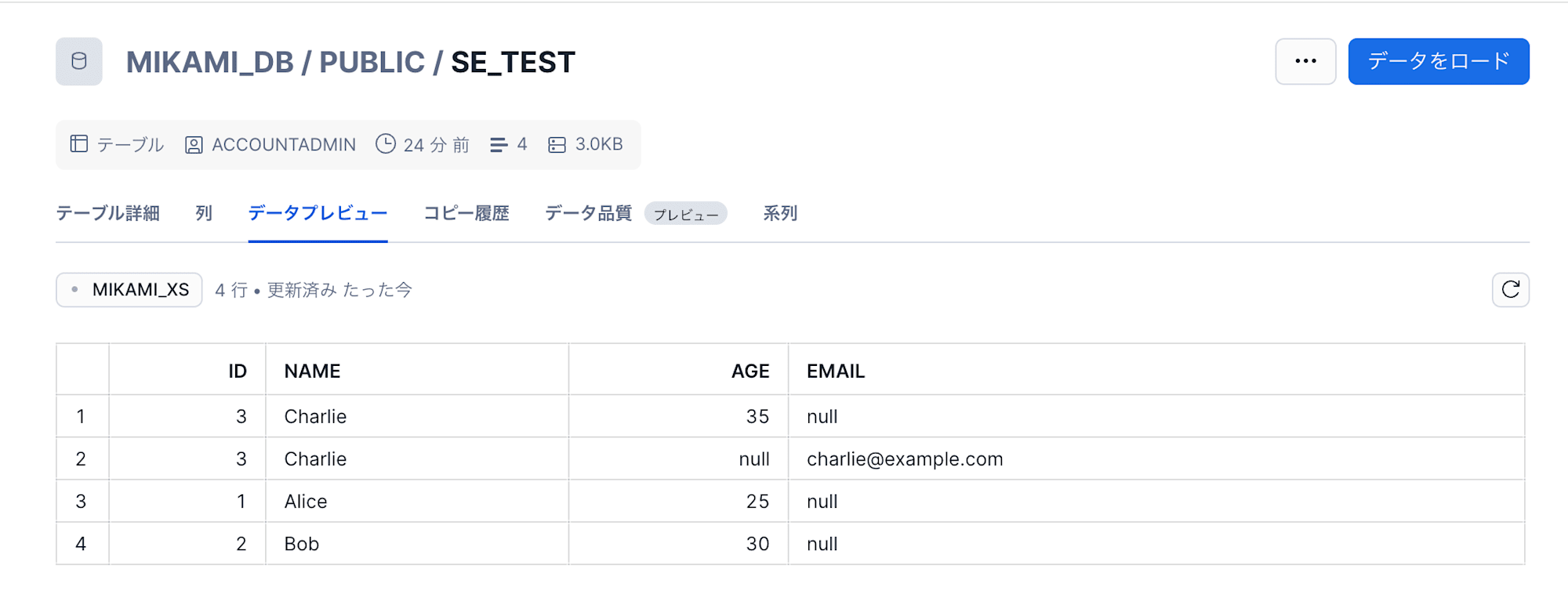
カラム順が異なるファイルも正常にロードできました。
case3:カラム(ファイルヘッダ)名差異あり
続いて、テーブルカラム名とロードファイルのヘッダ名が異なるファイルです。
gcloud storage cp case3_evolution.csv gs://test-mikami/schema_evolution/snowpipe/
$ gcloud storage cp gs://test-mikami/schema_evolution/snowpipe/case3_evolution.csv -
Copying gs://test-mikami/schema_evolution/snowpipe/case3_evolution.csv to file://-
id,full_name,age
3,Charlie,35
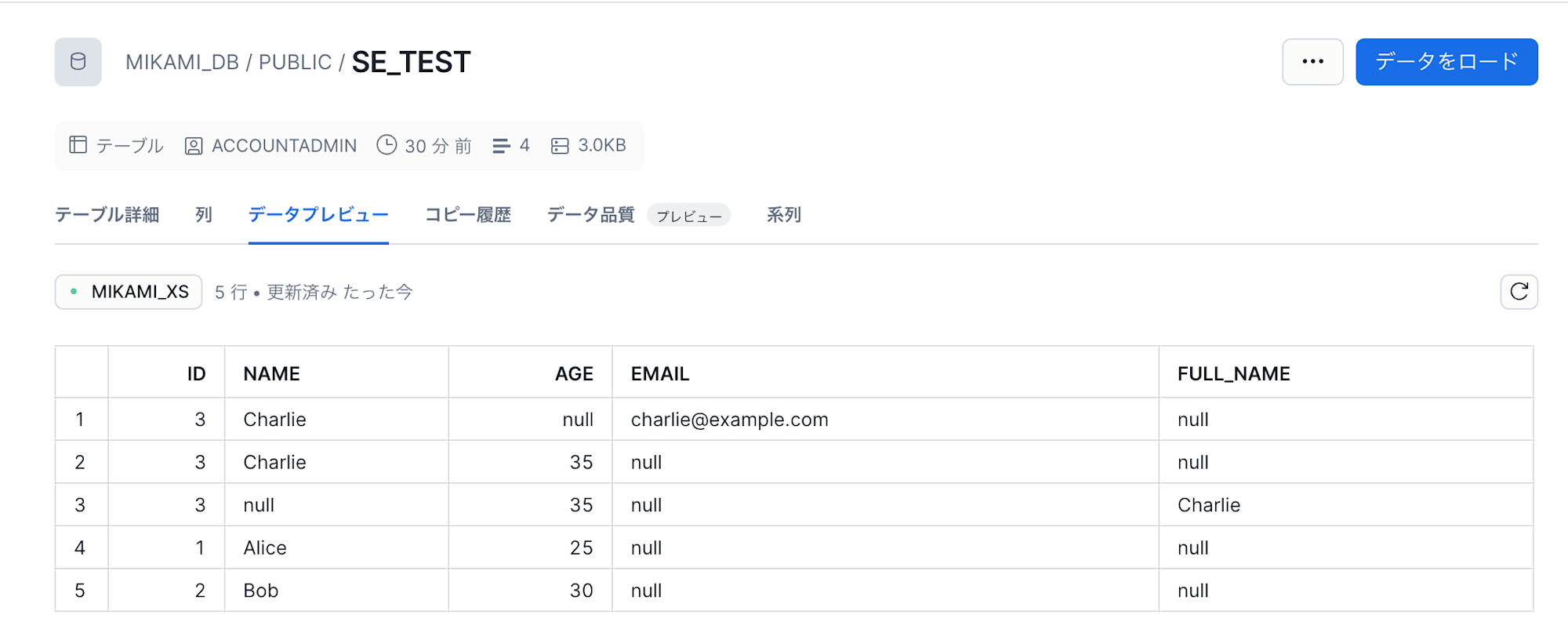
こちらも正常取り込みが確認できました。
case4:NOT NULL カラムのファイルデータ値欠如
NOT NULL 制約のあるカラムへの null 値取り込みの確認です。
gcloud storage cp case4_evolution.csv gs://test-mikami/schema_evolution/snowpipe/
$ gcloud storage cp gs://test-mikami/schema_evolution/snowpipe/case4_evolution.csv -
Copying gs://test-mikami/schema_evolution/snowpipe/case4_evolution.csv to file://-
name,age
Charlie,35
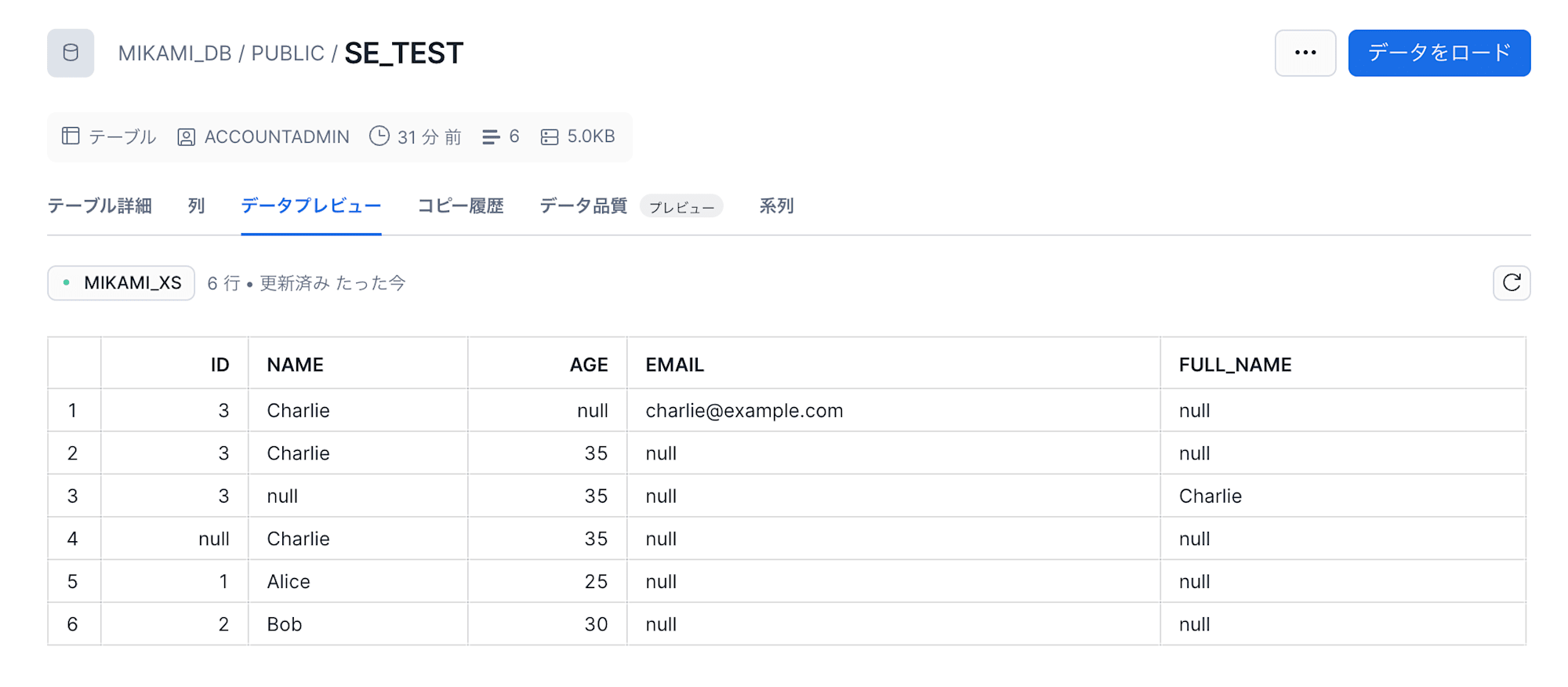
他パターン同様、NOT NULL 制約が解除され、データが取り込めることが確認できました。
case5:データ型差異あり
データ型が異なるファイルデータの取り込みです。
gcloud storage cp case5_evolution.csv gs://test-mikami/schema_evolution/snowpipe/
$ gcloud storage cp gs://test-mikami/schema_evolution/snowpipe/case5_evolution.csv -
Copying gs://test-mikami/schema_evolution/snowpipe/case5_evolution.csv to file://-
id,name,age
3,Charlie,thirty-five
しばらく待って、以下の SQL で Snowpipe のロード履歴を確認してみます。
SELECT
file_name,
status,
first_error_message,
first_error_line_number,
first_error_character_pos,
first_error_column_name,
row_count,
error_count,
last_load_time
FROM TABLE(
INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'SE_TEST',
START_TIME => DATEADD(HOUR, -1, CURRENT_TIMESTAMP())
)
)
ORDER BY last_load_time DESC;
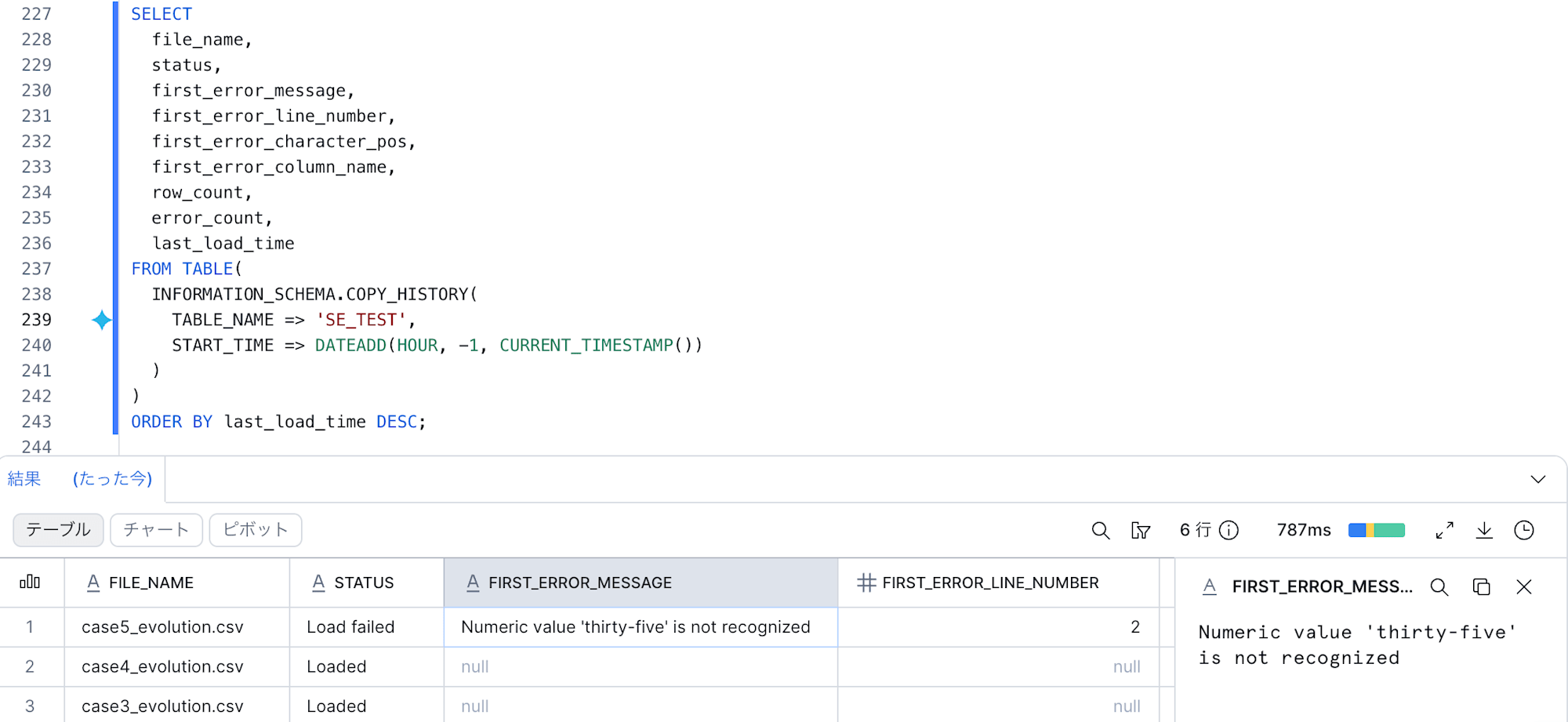
データ型が異なるファイルの取り込みは、snowpipe でもエラーになりました。
まとめ(所感)
今回の検証では、COPY INTO の 手動実行、COPY INTO の Task 実行、Snowpipe いずれの場合でも、以下の結果となりました。
| ケース | 検証内容 | 結果 |
|---|---|---|
| case1 | カラム追加 + カラム削除 | 新カラムがテーブルに追加される・削除カラムはテーブルに残留(値は NULL) |
| case2 | カラム順序差異あり | スキーマ変更なし・正常ロード |
| case3 | カラム(ファイルヘッダ)名差異あり | テーブルカラム名が変更される・旧カラムはテーブルに残留(値は NULL) |
| case4 | NOT NULL カラムのファイルデータ値欠如 | 欠落カラムの NOT NULL 制約が削除される |
| case5 | データ型差異あり | エラー(ロードされない) |
データパイプラインの運用において、データ出力元の仕様変更等に伴うスキーマ変更は避けられない対応ではないかと思います。
schema evolution 機能を利用すれば、データソースのフォーマット変更に手動で対応する必要がなくなり、運用コストを削減することができます。
一方で、ソースデータ不正を見落とすリスクもあるため、合わせてデータ品質チェックなども検討するとよいのではないかと思いました。
とはいえ schema evolution は、データパイプラインの安定運用を可能にする、嬉しい機能だと思いました。








