![[新機能]SQLコマンドでテキストや画像などマルチモーダルなデータ分析を可能にする「Cortex AISQL」を試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake?w=3840&fm=webp)
[新機能]SQLコマンドでテキストや画像などマルチモーダルなデータ分析を可能にする「Cortex AISQL」を試してみた
さがらです。
Snowflake Summit 2025で発表された新機能の1つとして、SQLコマンドでテキストや画像などマルチモーダルなデータ分析を可能にする「Cortex AISQL」があります。
このCortex AISQLを試してみたので、その内容をまとめてみます。
Cortex AISQLとは
Cortex AISQLは、SnowflakeのSQLエンジンにAI機能を直接統合し、使い慣れたSQLコマンドでテキストや画像などの多様なデータ(マルチモーダルデータ)を分析可能にする新しい機能です。
主な特徴として、以下が挙げられます。
- 使い慣れたSQLでAI活用: 複雑なコーディングなしで、データアナリストがAIエンジニアのように高度な分析を行えます。
- 高速・低コスト: Snowflakeのエンジンに深く統合されているため、従来のAI実装に比べて30%以上高速で、最大60%のコスト削減を実現します。
- 多様なデータに対応: 新しい
FILEデータ型により、テキストや画像などの非構造化データを構造化データとシームレスに組み合わせた分析が可能です。
Cortex AISQLについては、以下のSnowflake Summitでのセッションレポート記事も大変参考になります。
以前からあったLLM Functionsとの違いについて
ここまでの説明を聞くと、「あれ、SQL内でのAI利用ってLLM Functionsという機能群で提供されていなかったっけ?」と思う方もいると思います。
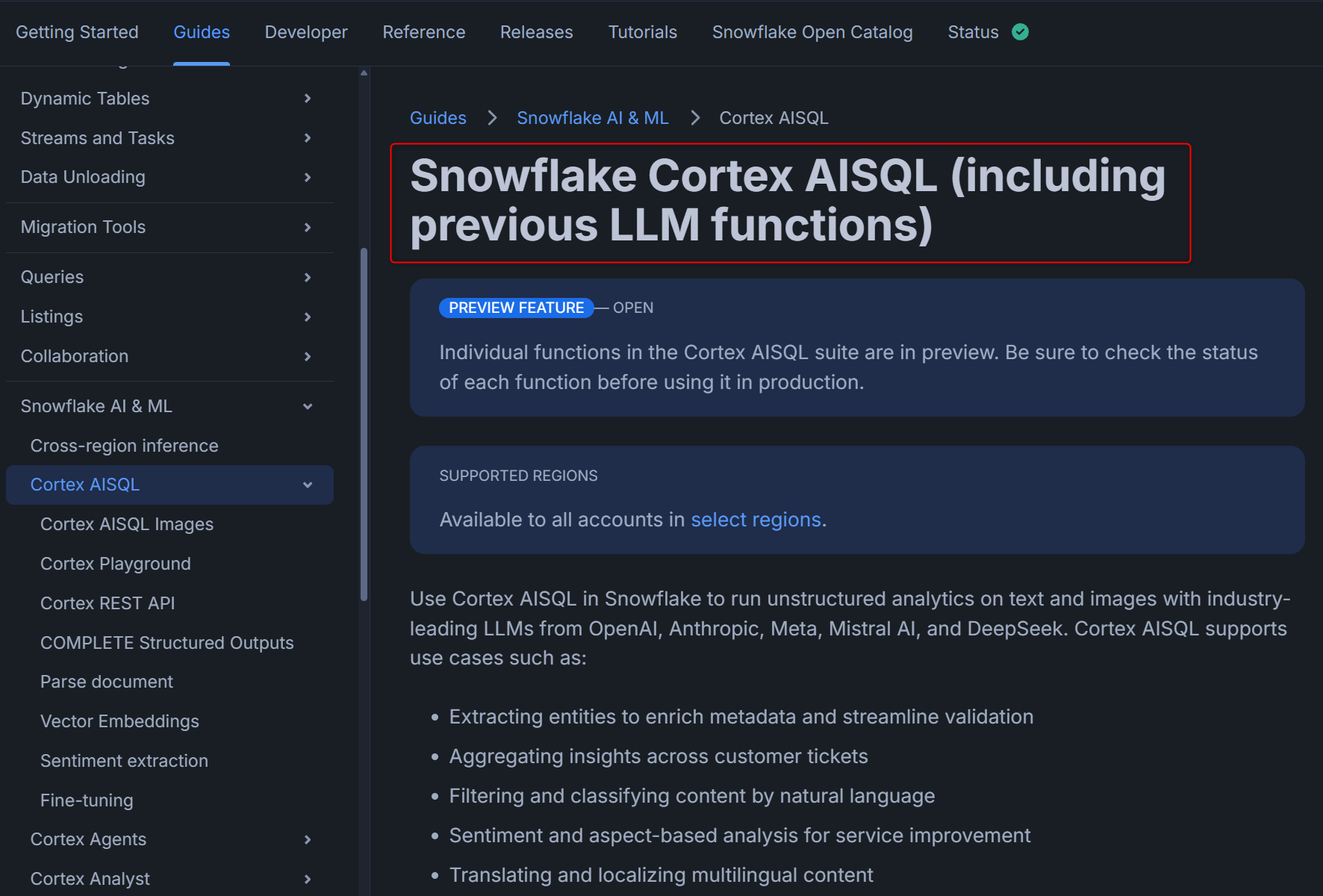
このLLM Functionsですが、今回のCortex AISQLのリリースをきっかけに全てCortex AISQLの機能群に組み込まれました。下図はCortex AISQLのドキュメントですが、「(including previous LLM functions)」と書かれています。
コスト
コストについては、下図のようなコスト感となっております。(100万トークンあたりの消費クレジットが書かれています。)
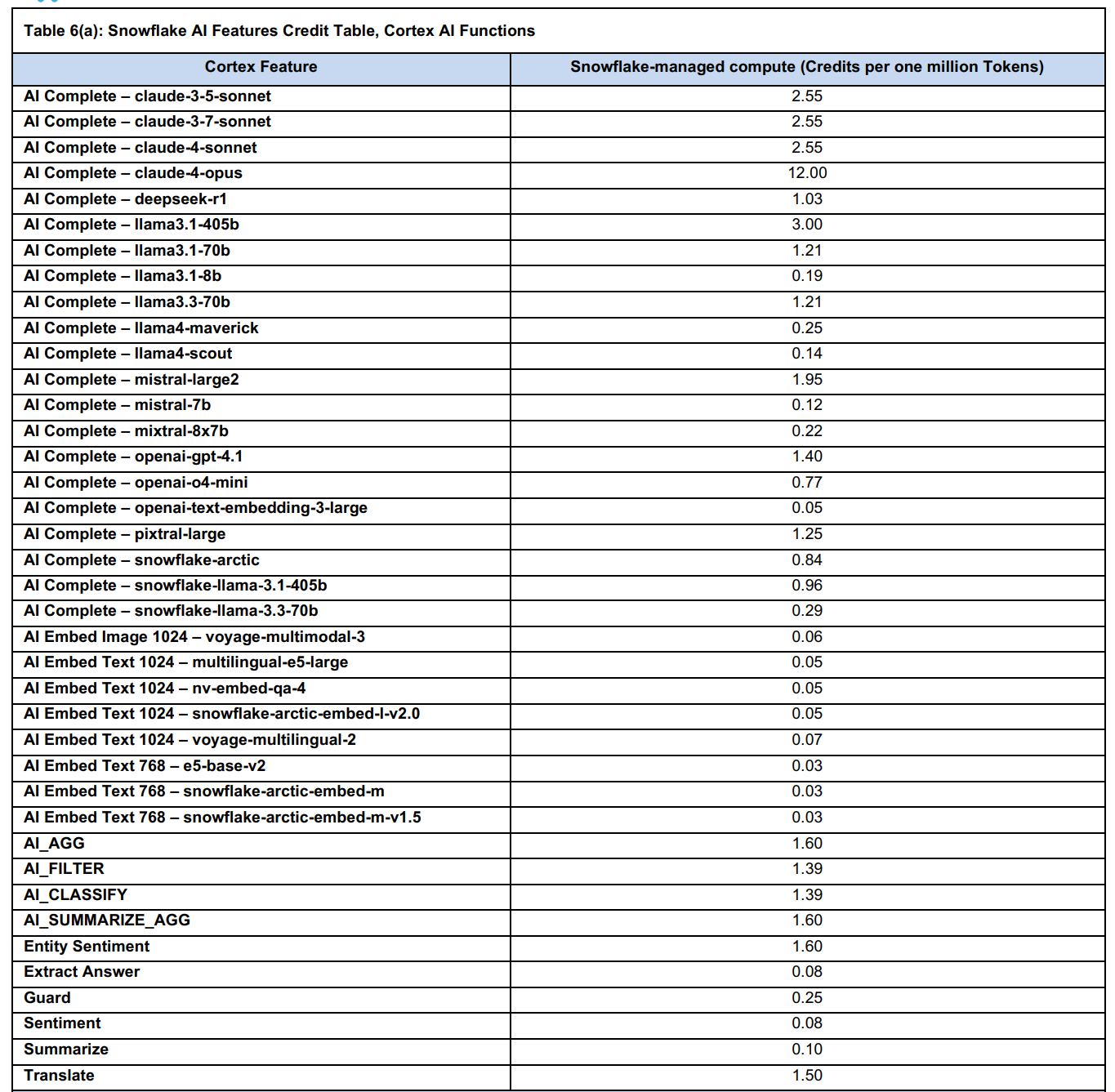
※以下のリンク先から引用
試す内容
このCortex AISQLを試せる以下のQuickstartが公式から提供されていますので、これを試してみます。
事前準備
以下のリンク先の「2.Setup」の内容に沿って、準備を行います。
- Snowflakeアカウントでワークシートを立ち上げ、setup.sqlに記載のクエリを上から順に全て実行
- このリンク先のフォルダにある画像ファイルをすべてダウンロードし、1番で作成したステージ
@DASH_DB.DASH_SCHEMA.DASH_IMAGE_FILESにアップロード - Snowflakeアカウントでワークシートを立ち上げ、images.sqlに記載のクエリを上から順に全て実行
- 私が試したときは
USE WAREHOUSE DASH_S;となっておりエラーになったので、USE WAREHOUSE DASH_WH_S;に変更して実行しました。 - このクエリで、ステージにアップロードしたスクリーンショットの内容を元に
TO_FILE関数でFILE型のカラムIMG_FILEを含むテーブルを作成しています。
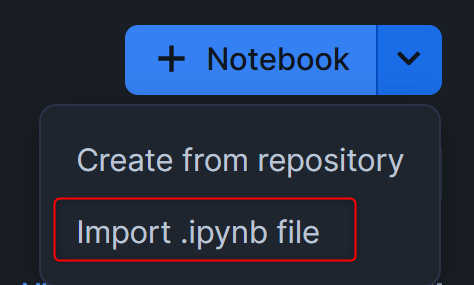
- cortex_aisql.ipynbをダウンロードし、下図の手順に沿ってSnowflakeアカウントにアップロードしながらNotebookを作成
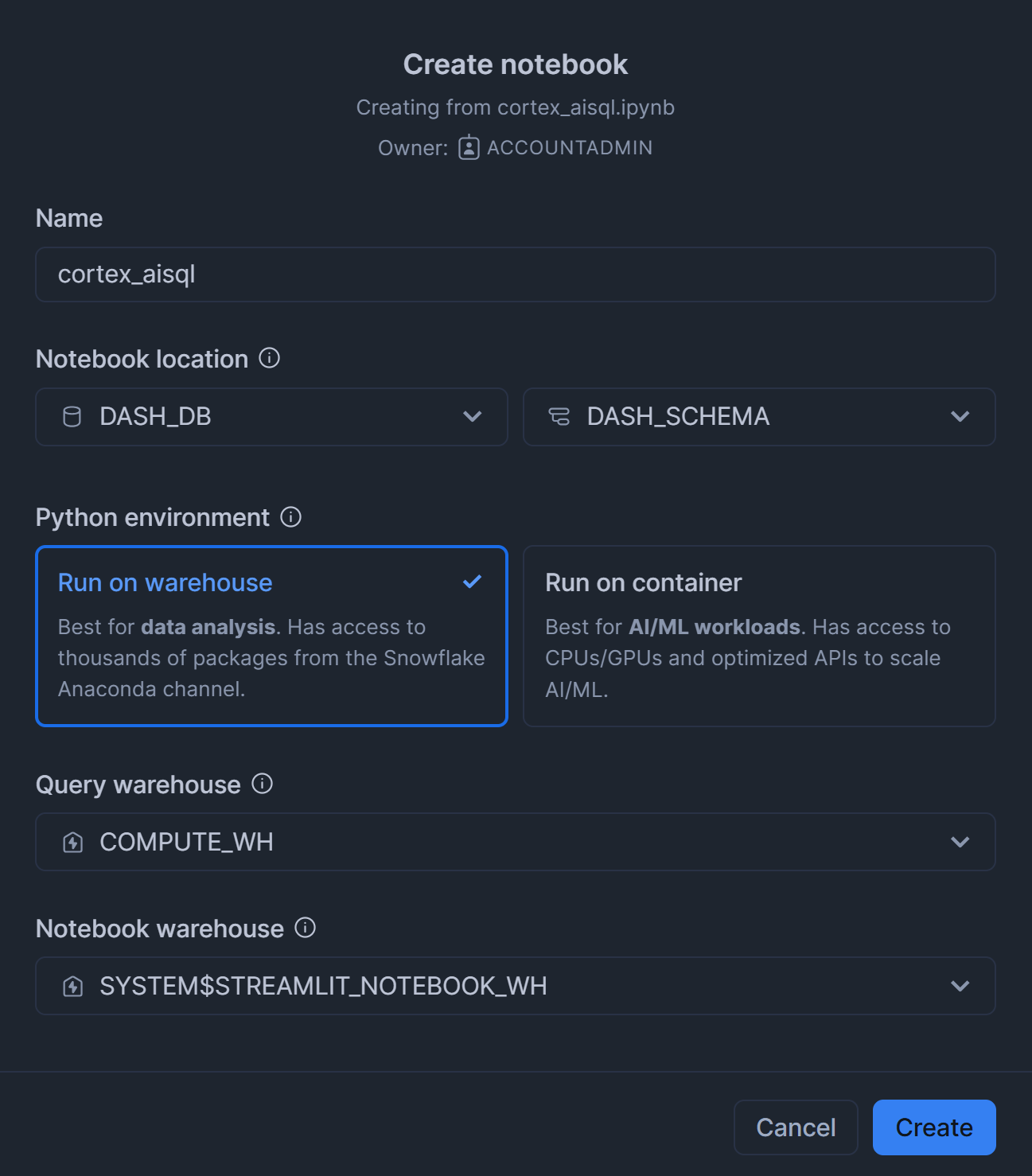
その後、Notebookが立ち上がったら一番上のライブラリをインポートしているセルを実行します。
Notebook内のSQLを実行しながらCortex AISQLを試す
AI_COMPLETE関数
まず、Identify Customer Issues Across Text and Image Data Formats内の以下のクエリを実行します。
このクエリでは、AI_COMPLETE関数を使用して、以下のことを行っています。PROMPT関数も用いることで、引数で指定したカラムの値を動的に入れるようにしています。({0}でどの引数のカラムを入れるかを指定)
- WITH句
IMAGE_INSIGHTS:IMAGESテーブルにあるスクリーンショット画像の内容をAIで要約します。 - WITH句
EMAIL_INSIGHTS:EMAILSテーブルにある問い合わせメールの内容をAIで要約します。 - UNIONとCREATE TABLE: 上記2つの結果をUNIONし、最終的に
INSIGHTSという新しいテーブルとして保存します。
create table if not exists insights as
with IMAGE_INSIGHTS as (
select created_at,user_id,relative_path as ticket_id,img_file as input_file,file_url as input_file_url,
AI_COMPLETE('pixtral-large', prompt('Summarize this issue shown in this screenshot in one concise sentence: {0}', img_file)) as summary, summary as content
from images
),
EMAIL_INSIGHTS as (
select created_at,user_id,ticket_id::text as ticket_id,null as input_file,'' as input_file_url,content as content,
AI_COMPLETE('claude-3-7-sonnet', prompt('Summarize this issue in one concise sentence.
If the user mentioned anything related to music preference, please keep that information: {0}', content)) as summary
from emails
)
select 'Image' as source, created_at, user_id, ticket_id, input_file, input_file_url, content, summary
from IMAGE_INSIGHTS
union
select 'Email' as source, created_at, user_id, ticket_id, input_file, input_file_url, content, summary
from EMAIL_INSIGHTS;
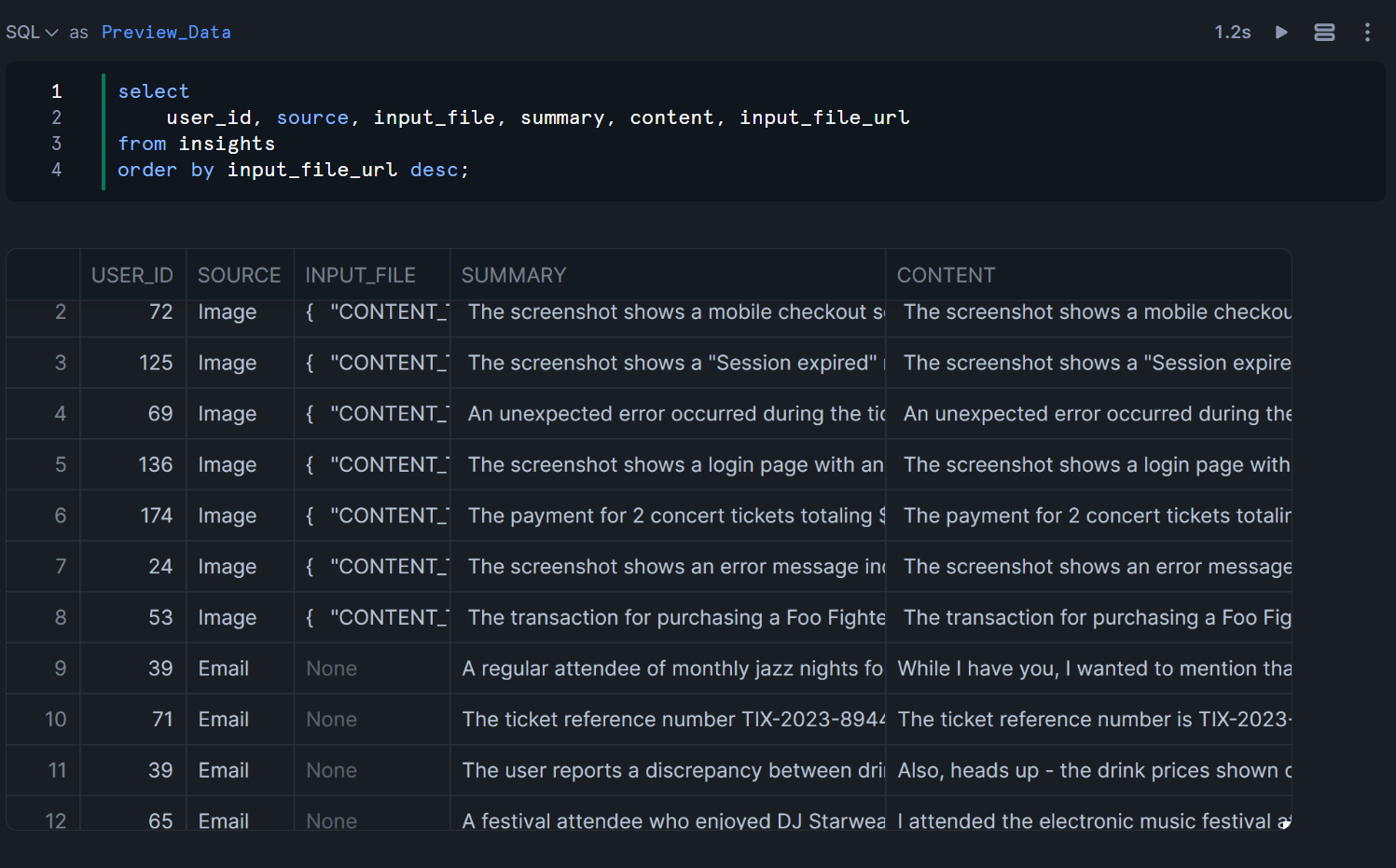
このテーブルを作成したあと、NotebookのConsolidated Data Across Text, Image, and Audio Data Formatsにある以下のSQLを実行すると、SUMMARY列で対象のスクリーンショットとメールの要約、CONTENT列ではメール文の原文が確認できます。(CONTENT列での画像に関する説明は、上述のCTAS文の内容を見るとSUMMARY列と全く同じ内容を出力するようになっています。)
JOIN句におけるAI_FILTER関数
まず前置きとして、SOLUTION_CENTER_ARTICLESテーブルでは下図のようにトラブルに対する解決策をSOLUTION列でまとめたテーブルとなっております。
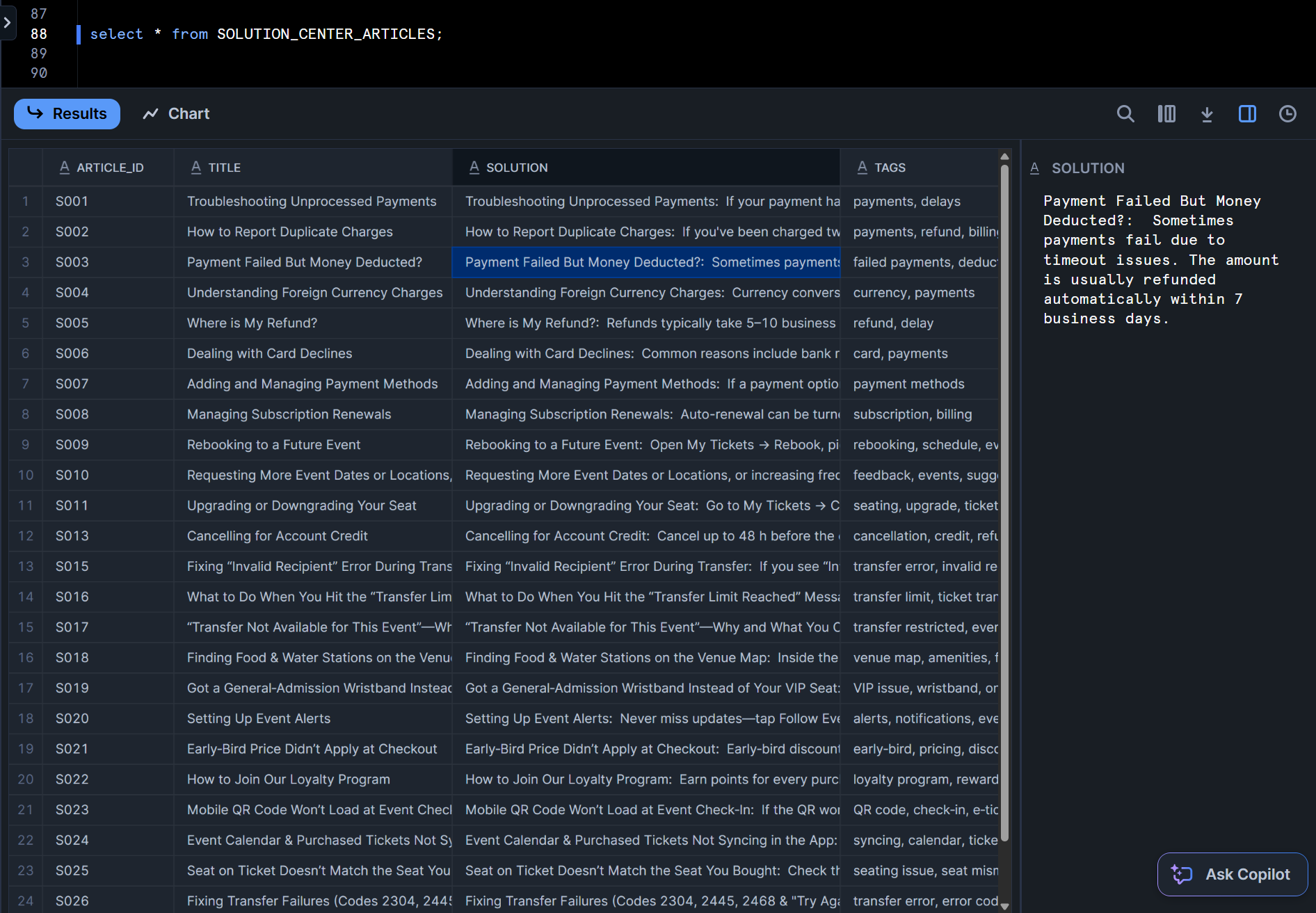
この上でSemantically JOIN Issues with Solutions Libraryのクエリでは、先程AI_COMPLETE関数を用いて作成したINSIGHTSテーブルの顧客の問題を保持しているCONTENT列に対して、AI_FILTER関数を用いてSOLUTION_CENTER_ARTICLESテーブルのSOLUTION列が解決策とマッチしそうな場合に結合を行って出力する、ということを行っています。
複数のsolution列がマッチする場合もあります。※下図でいう、TICKET_ID列が177の場合など。
select
c.ticket_id,
c.content as "CUSTOMER ISSUE",
s.solution,
c.created_at,
from
INSIGHTS c
left join
SOLUTION_CENTER_ARTICLES s
on AI_FILTER(prompt('You are provided a customer issue and a solution center article. Please check if the solution article can address customer concerns. Reminder to check if the error details are matching. Customer issues: {0}; \n\nSolution: {1}', content, s.solution))
order by created_at asc;
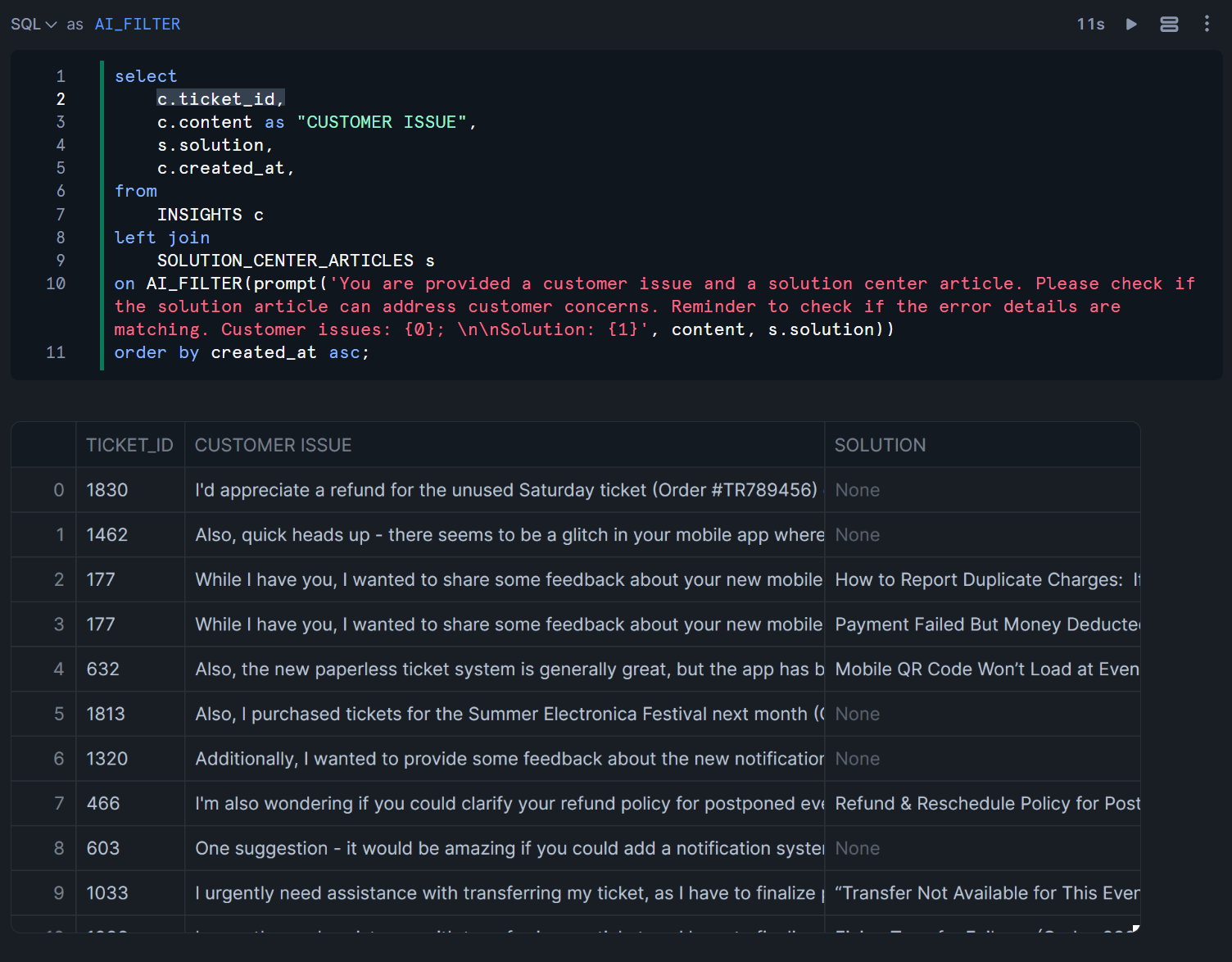
注意事項としては、AI_FILTER関数を利用するJOIN操作を実行する場合、JOIN内の各テーブルの行数は「500」を超えることはできません。(公式Docsより)まあ確かに、数万行のJOINとかすると、あっという間にトークンが桁違いの値になってしまいそうですもんね…
もしAI_FILTER関数を利用するJOIN操作で大規模な結合を有効にするには、アカウントマネージャーに連絡して、adaptive optimization previewを有効にしてください。
AI_AGG関数
Aggregate Top Pain Points By Monthでは、Pythonコードが記述されていますが、まずはこのPythonコードに含まれるAI_AGG関数を利用しているSQLだけを見ていきます。
以下のSQLでは、AI_AGG関数の第1引数に入れたカラムの値に対して、「すべてのサポートチケットのレビューを分析し、言及されているすべての問題の包括的なリストを提供してください。箇条書きの形式で、問題のおおよその頻度をパーセンテージで示してください。」という指示を出しています。
select
monthname(created_at) as month,
count(*) as total_tickets,
count(distinct user_id) as unique_users,
AI_AGG(summary,'Analyze all the support ticket reviews and provide a comprehensive list of all issues mentioned.
Format your response as a bulleted list of issues with their approximate frequency in percentage.') as top_issues_reported,
from (select * from insights order by random() limit 200)
group by month
order by total_tickets desc,month desc;
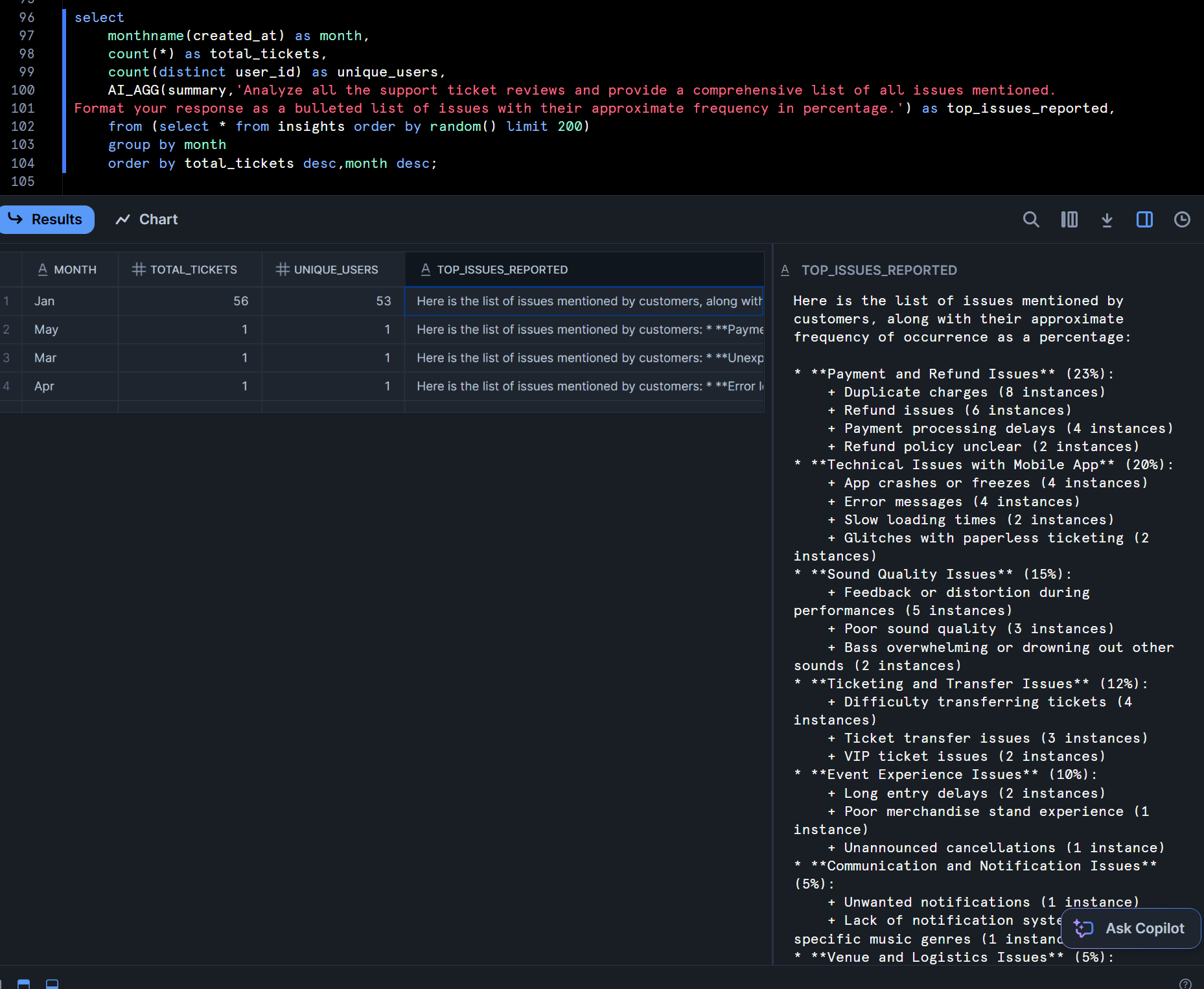
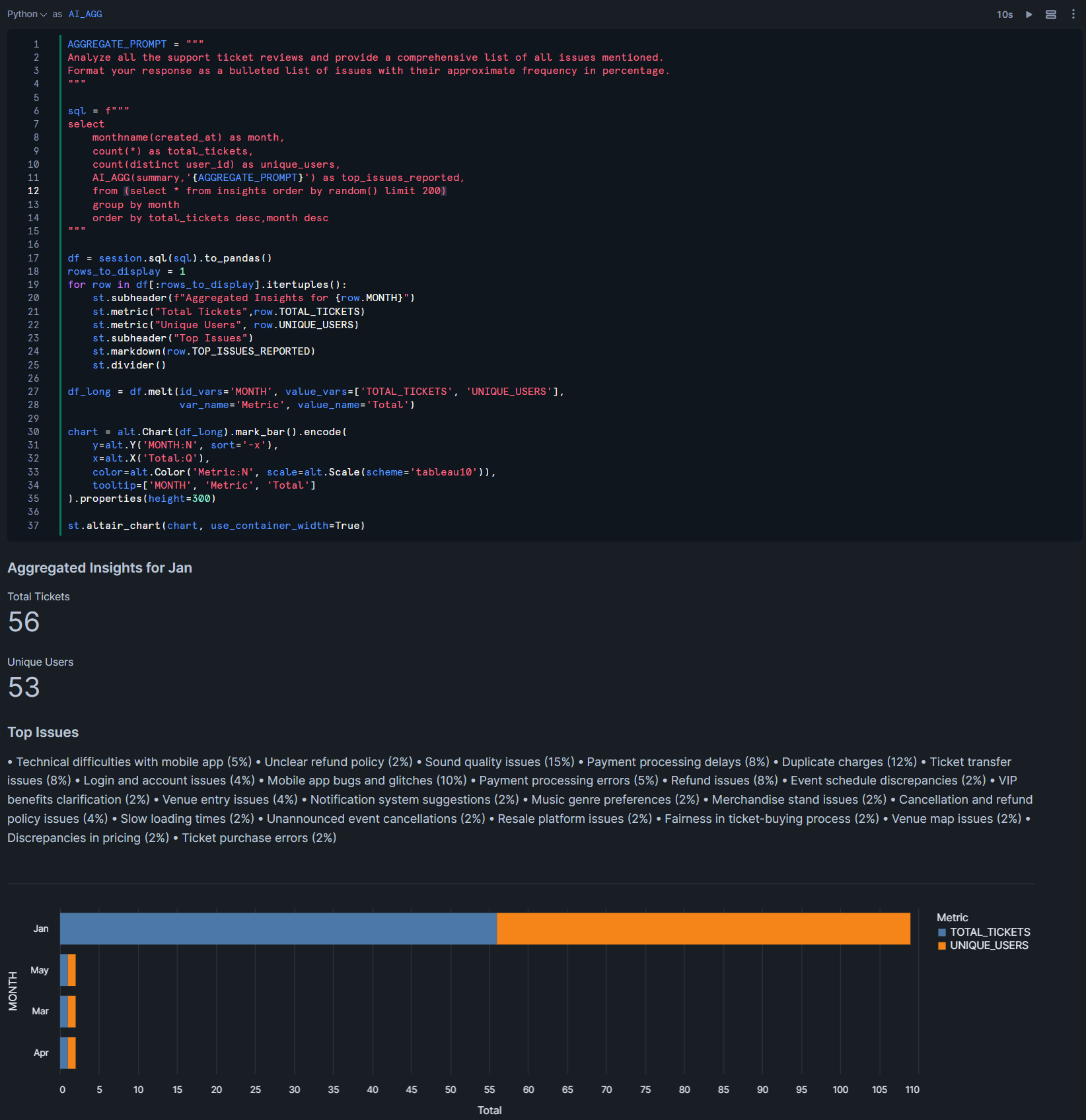
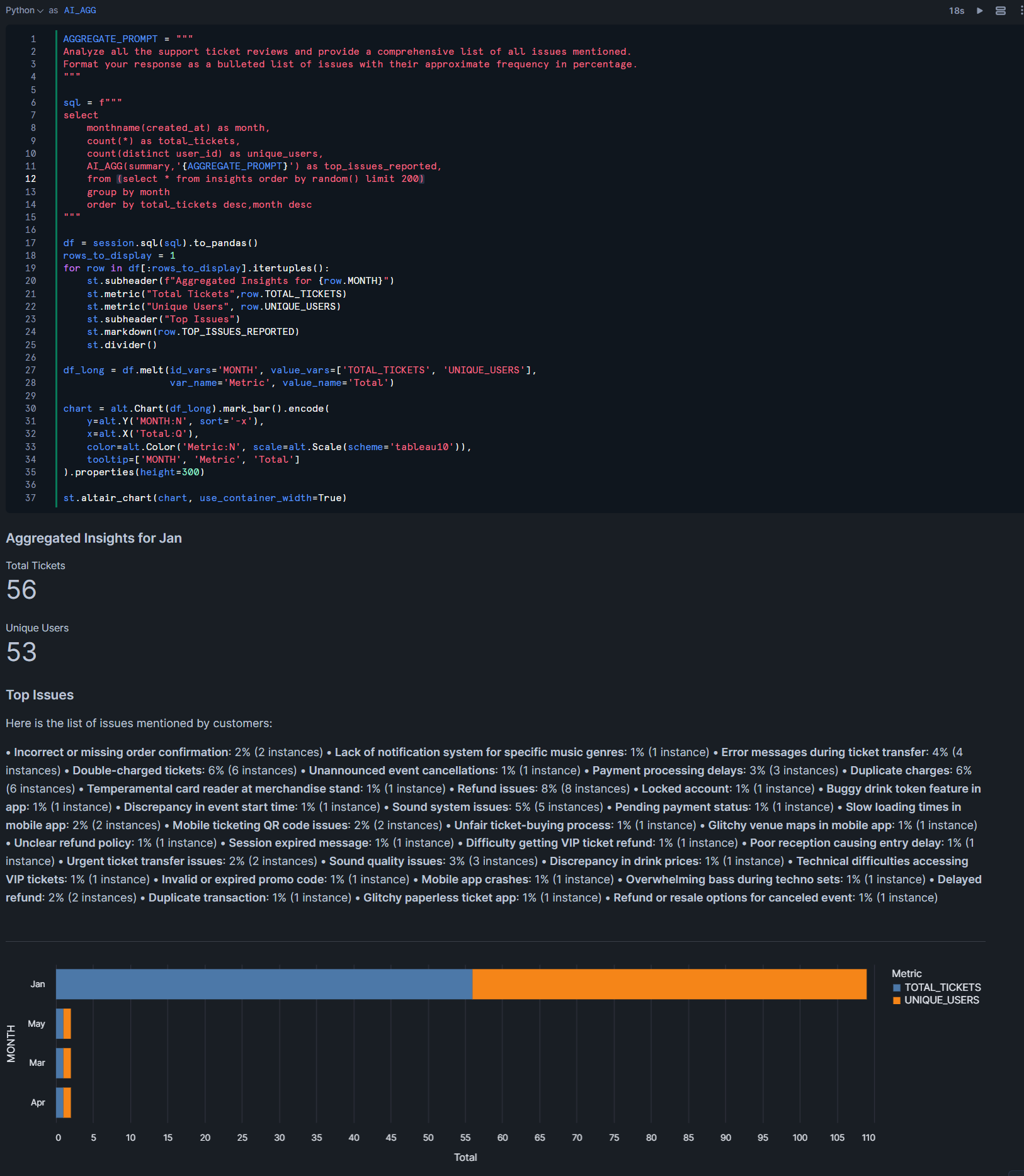
この上で、Notebook上のPythonコードでは、Streamlitを用いてこの集計結果の可視化まで行っています。対象のレコードはRANDOM関数で変えているとはいえ、1回目の実行と2回目の実行で、出力形式が若干変わっているのが気になりますが、これは生成AIの特性上避けられないのかもしれません…
AGGREGATE_PROMPT = """
Analyze all the support ticket reviews and provide a comprehensive list of all issues mentioned.
Format your response as a bulleted list of issues with their approximate frequency in percentage.
"""
sql = f"""
select
monthname(created_at) as month,
count(*) as total_tickets,
count(distinct user_id) as unique_users,
AI_AGG(summary,'{AGGREGATE_PROMPT}') as top_issues_reported,
from (select * from insights order by random() limit 200)
group by month
order by total_tickets desc,month desc
"""
df = session.sql(sql).to_pandas()
rows_to_display = 1
for row in df[:rows_to_display].itertuples():
st.subheader(f"Aggregated Insights for {row.MONTH}")
st.metric("Total Tickets",row.TOTAL_TICKETS)
st.metric("Unique Users", row.UNIQUE_USERS)
st.subheader("Top Issues")
st.markdown(row.TOP_ISSUES_REPORTED)
st.divider()
df_long = df.melt(id_vars='MONTH', value_vars=['TOTAL_TICKETS', 'UNIQUE_USERS'],
var_name='Metric', value_name='Total')
chart = alt.Chart(df_long).mark_bar().encode(
y=alt.Y('MONTH:N', sort='-x'),
x=alt.X('Total:Q'),
color=alt.Color('Metric:N', scale=alt.Scale(scheme='tableau10')),
tooltip=['MONTH', 'Metric', 'Total']
).properties(height=300)
st.altair_chart(chart, use_container_width=True)
- 1回目実行
- 2回目実行
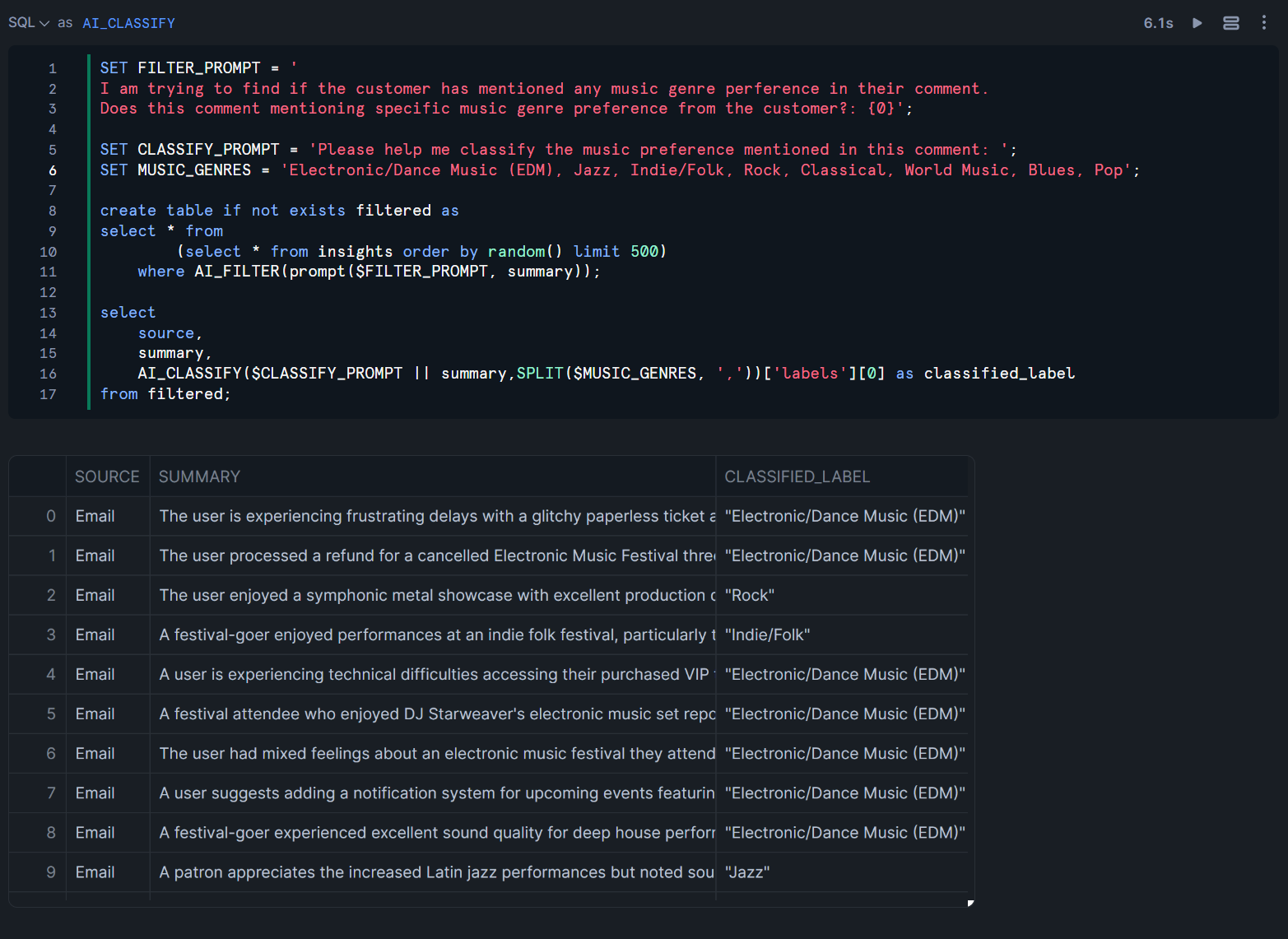
AI_CLASSIFY関数
Classificationでは、以下のクエリが記述されています。このクエリではAI_FILTER関数とAI_CLASSIFY関数を用いて、以下のことを行っています。
AI_FILTER関数を用いて、INSIGHTSテーブルから音楽に関係があるメールだけを抽出したFILTEREDテーブルを作成FILTEREDテーブルに対して、MUSIC_GENRESで指定した音楽ジャンルのうち、どのジャンルに該当するかをAI_CLASSIFY関数を用いて分類
SET FILTER_PROMPT = '
I am trying to find if the customer has mentioned any music genre perference in their comment.
Does this comment mentioning specific music genre preference from the customer?: {0}';
SET CLASSIFY_PROMPT = 'Please help me classify the music preference mentioned in this comment: ';
SET MUSIC_GENRES = 'Electronic/Dance Music (EDM), Jazz, Indie/Folk, Rock, Classical, World Music, Blues, Pop';
create table if not exists filtered as
select * from
(select * from insights order by random() limit 500)
where AI_FILTER(prompt($FILTER_PROMPT, summary));
select
source,
summary,
AI_CLASSIFY($CLASSIFY_PROMPT || summary,SPLIT($MUSIC_GENRES, ','))['labels'][0] as classified_label
from filtered;
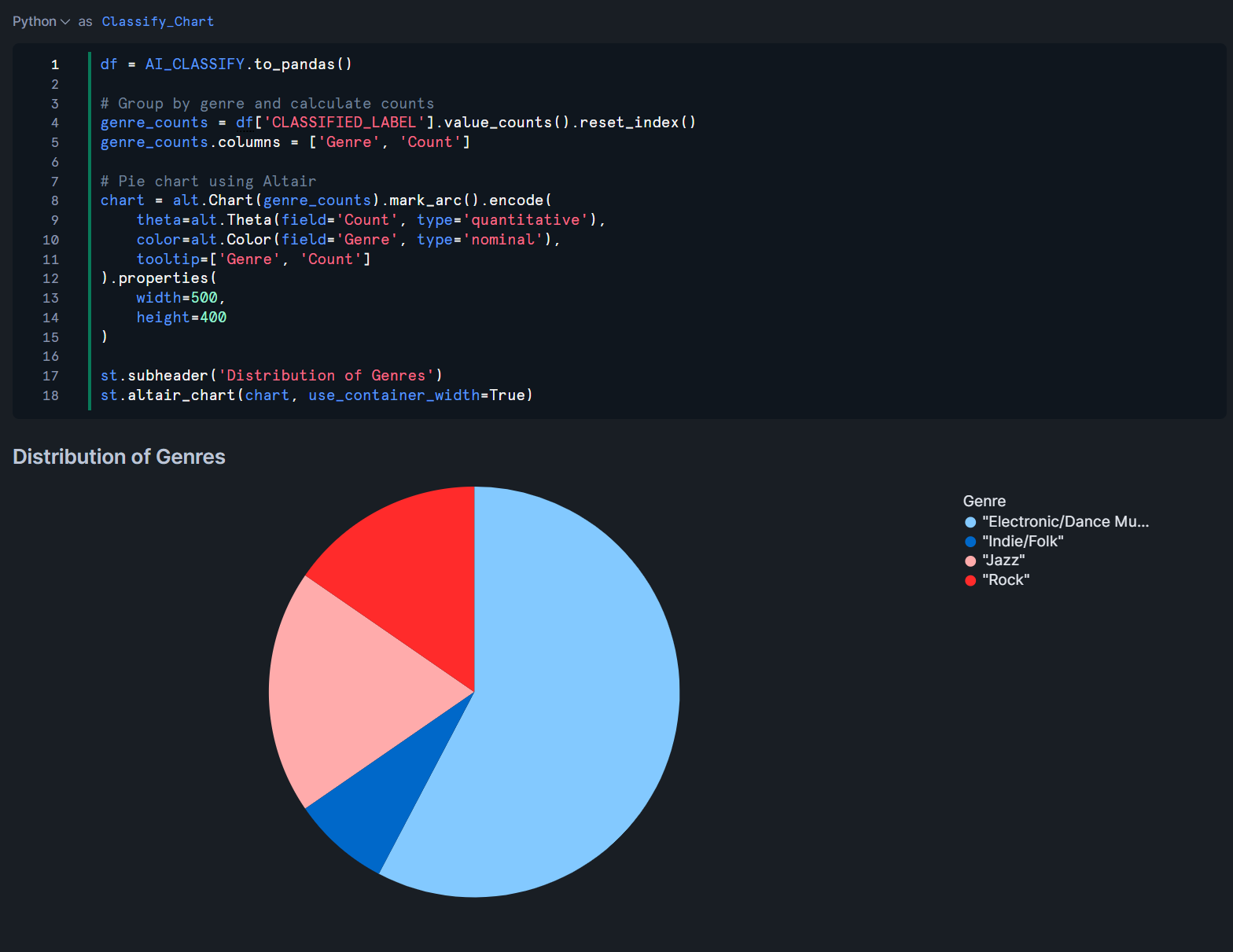
また、この分類結果を元に、Streamlitでの可視化も行われていました。
最後に
Snowflake Summit 2025で発表された新機能の1つ、SQLコマンドでテキストや画像などマルチモーダルなデータ分析を可能にする「Cortex AISQL」を試してみました。
純粋な感想として、AI_FILTER関数やAI_AGG関数は今までのSQLの書き方と全く異なる書き方だったので、理解するまでに脳が疲れましたねw
ただ、テキストデータや画像データでは結合の条件が明確に作れない場合などあると思いますので、その場合にはCortex AISQLがとても役に立つとも感じました!








