
ロボットアーム(SO-ARM101)で、アヒルを掴んでみました 〜模倣学習〜
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
下記の記事に刺激をいただき、「私もやってみたい!」って事で、ロボットアーム買ってきました。
上記記事と同じ内容で誠に恐縮なのですが、ロボットアーム全くの初心者が、初めて取り組んだ模倣学習(Imitation Learning)についての記録ということで、どうかお許しください。
やってみたのは、「アヒルを摘み上げてボックスに入れる」という、シンプルなアクションです。
最初に、学習で得られたモデルが動作しているようすです。
「典型的な Pick & Place タスク」で、「ターゲット(アヒル)は毎回1つ」「配置場所も殆ど同じ(約5cm以内の矩形の中)」「目的位置(グレーのバスケット)も比較的大きなもの」ということで、超簡単なタスクであるためか、データ(デモンストレーション)30エピソードで、なんとか動作できるものができました。
なお、今回は、学習も推論も手元の Mac (Apple Silicon M2) で行っています。
学習は、30,000 stepで約7時間、推論も辿々しいながら一応成功ってところですが、この辺、CUDAなどで進めれば、色々結果は変わってくるかも知れないのですが、その辺の確認は、別途挑戦とさせて頂きました。
2 概要
今回利用した環境は以下のとおりです。
| 項目 | 値 |
|---|---|
| ハードウェア(学習・推論) | MacOS (Apple Silicon、M2 系列) |
| ロボット | SO-ARM101(Leader + Follower) |
| Webカメラ | ロジクール C920n |
| LeRobot | v0.5.1 |
| モデル | ACT (Action Chunking Transformer) |
実施した作業は、概ね以下となります。
| 作業 | 内容 |
|---|---|
| データ収集 | Leaderで「アヒルを掴む」操作を 30 エピソード実演して記録 |
| 学習 | Mac (MPS) で ACT モデルを 30,000 step 学習(約 6h 40m) |
| 推論評価 | Followerのみで自律的にアヒルを掴む 各チェックポイントで成功率を比較 |
精度が出なければ、「データ収集からやり直し」を覚悟で始めたのですが、幸い、単純なタスクにしたためか、1回の学習で何とか動作できるモデルが作成できました。ただ、30エピソードのデータで30,000ステップは、多かったみたいで、Overfittingの症状が確認されました。冒頭に紹介した動画は、25,000stepのモデルです。
3 セットアップ
セットアップは以下のとおりです。
$ uv init --python 3.12 lerobot-workspace
$ cd lerobot-workspace
$ uv add "lerobot[feetech]>=0.5.1" matplotlib
// LeRobotの確認
$ uv run lerobot-info
- LeRobot version: 0.5.1
- Platform: macOS-15.7.3-arm64-arm-64bit
- Python version: 3.12.2
- Huggingface Hub version: 1.13.0
- Transformers version: N/A
- Datasets version: 4.8.5
- Numpy version: 2.2.6
- FFmpeg version: N/A
- PyTorch version: 2.10.0
- Is PyTorch built with CUDA support?: False
- Cuda version: N/A
- GPU model: N/A
- Using GPU in script?: <fill in>
- lerobot scripts: ['lerobot-calibrate', 'lerobot-dataset-viz', 'lerobot-edit-dataset', 'lerobot-eval', 'lerobot-find-cameras', 'lerobot-find-joint-limits', 'lerobot-find-port', 'lerobot-imgtransform-viz', 'lerobot-info', 'lerobot-record', 'lerobot-replay', 'lerobot-setup-can', 'lerobot-setup-motors', 'lerobot-teleoperate', 'lerobot-train', 'lerobot-train-tokenizer']
// Feetech SDK の確認
$ uv run python -c "import scservo_sdk; print('OK')"
// matplotlib の確認
$ uv run python -c "import matplotlib; print(matplotlib.__version__)"
3.10.9
// MPS の確認
$ uv run python -c "import torch; print(f'MPS: {torch.backends.mps.is_available()}')"
MPS: True
// PyTorch からの MPS利用 確認
uv run python -c "import torch; print(f'MPS available: {torch.backends.mps.is_available()}'); print(f'MPS built:{torch.backends.mps.is_built()}')"
MPS available: True
MPS built:True
4 データ収集
(1) タスク設計
今回設計したタスクは以下のとおりです。
- 対象物: アヒル
- 目的地: グレーのバスケット
- 配置エリア: 5 × 5 cm(毎回ランダムに配置)
- 1 エピソード: 20 秒
- 収録回数: 30 エピソード
- カメラ: やや上方からアームと対象物・目的地を俯瞰できる
模倣学習は「人間が見せた動きをモデルが真似る」のが基本なので、データ収集は非常に重要になります。その考えの上で考慮したのは以下のような事項です。
アヒルのスタート位置は、約5 × 5 cm のエリア内に制限しています。エリア広げすぎるとデータの分布が安定せず、30エピソードでは網羅できないと考えたからです。また、ランダムに少しずらしたのは、モデルが完全な定位置座標を学習してしまわないようにです。
目的地や、アームは、ズレることが無いように、マーキングして固定しています。これは、学習する必要ないものを、可能な限り排除するためです。

カメラは、対象物以外のものが、映り込まないように配置し、ブレることが無いように可能な限り、完全固定しました。
OpenCVでカメラの写り具合を確認しています。
GitHub preview_camera.py
$ uv run python preview_camera.py 1

Webカメラの性能により制限はあると思うのですが、今回は、640 * 480 15FPSで使用しました。解像度やFPSは、そのままデータサイズに影響し、結果的に学習コストに反映されることから、パターンが学習できる範囲で、可能な限り小さい方が経済的かと思うのですが、結果的に15FPSで大丈夫みたいでした。
また、ACTが画像認識に使用している ResNet(CNN)は、入力サイズが224×224なので、解像度も、もっと落としても行けると思ったのですが、Webカメラの設定がちょっとうまくいかず、このサイズとなりました。
(2) lerobot-record (--teleop)
GitHub record.sh
$ bash record.sh
lerobot-record(--teleop) でデータ収集しています。
record.sh
#!/bin/bash
# Main recording: 30 episodes of "Pick up the yellow duck" task
uv run lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem5B3D0430421 \
--robot.id=my_follower \
--robot.cameras="{ front: {type: opencv, index_or_path: 1, width: 640, height: 480, fps: 15} }" \
--teleop.type=so101_leader \
--teleop.port=/dev/tty.usbmodem5B3D0413001 \
--teleop.id=my_leader \
--display_data=true \
--dataset.repo_id=duck_pickup_v1 \
--dataset.num_episodes=30 \
--dataset.single_task="Pick up the yellow duck and put it in the basket" \
--dataset.push_to_hub=false \
--dataset.fps=15 \
--dataset.episode_time_s=20 \
--dataset.reset_time_s=10 \
--dataset.video_encoding_batch_size=1 \
--dataset.vcodec=h264_videotoolbox
| 項目 | 値 | 備考 |
|---|---|---|
| robot.type | so101_follower | Follower アーム |
| teleop.type | so101_leader | Leader アーム |
| robot.cameras | index 1, 640x480, 15FPS, opencv | front 視点 |
| dataset.num_episodes | 30 | データ収集数 |
| dataset.episode_time_s | 20 | 1 エピソード 20 秒 |
| dataset.reset_time_s | 10 | エピソード間のリセット時間 |
| dataset.fps | 15 | カメラ FPS と合わせる |
| dataset.vcodec | h264_videotoolbox | Apple Silicon HW エンコーダ |
| dataset.video_encoding_batch_size | 1 | メモリ節約 |
| dataset.push_to_hub | false | ローカル保存のみ |
| dataset.repo_id | duck_pickup_v1 |
lerobot-recordのアナウンスに従って、Leaderを操作してデータを作成していきますが、「右矢印(→) 早期決定」や「左矢印(←) やり直し」で30回地味に進めます。
(3) 品質確認
30 エピソードのデータ生成が終わった時点で、動画を確認しました。
- カメラがズレていないか: アングルが変わると、「異なるタスク」と認識されてしまう
- アヒルがバスケットに入ったか: 失敗エピソードを混ぜると、モデルは「失敗」を学んでしまう
- 異物が映り込んでいないか: 対象物以外のものが映り込むと、ノイズになってしまう
- 照明が一定か: 照明による陰影の変化も、分布シフトになってしまう
Videoは、MP4で保存されているので、ビューアで早送りで確認しました。
$ tree .
.
├── data
│ └── chunk-000
│ └── file-000.parquet
├── meta
│ ├── episodes
│ │ └── chunk-000
│ │ └── file-000.parquet
│ ├── info.json
│ ├── stats.json
│ └── tasks.parquet
└── videos
└── observation.images.front
└── chunk-000
├── file-000.mp4
└── file-001.mp4

5 学習
(1) lerobot-train
lerobot-trainで、学習します。
$ caffeinate -d -i bash train_act.sh
caffeinate -d -iを使用しているのは、長時間の学習で、Mac がスリープすると学習プロセスが停止(中断)してしまうため、これを防ぐためです。(-d でディスプレイのスリープ、-i でアイドルスリープを抑止)
GitHub train_act.sh
train_act.sh
uv run lerobot-train \
--dataset.repo_id=duck_pickup_v1 \
--dataset.video_backend=pyav \
--policy.type=act \
--policy.device=mps \
--output_dir=outputs/train/act_duck_pickup_v1 \
--steps=30000 \
--save_freq=5000 \
--wandb.enable=false \
--policy.push_to_hub=false
| 項目 | 値 | 備考 |
|---|---|---|
| dataset.video_backend | pyav | torchcodec がデフォルトだが、手元の Macでは FFmpeg が見つからないことがあり、pyav のほうが安定したため |
| policy.type | act | ACT (Action Chunking Transformer) を使用 |
| policy.device | mps | Apple Silicon の GPU を指定 |
| steps | 30000 | 学習のステップ数 |
| save_freq | 5000 | 5,000 step ごとに checkpoint を保存 |
(2) 学習の進捗
実際の学習の進捗は、以下のようになりました。
| Step | Loss | Grad | Epoch | 経過時間 |
|---|---|---|---|---|
| 200 | 6.272 | 147.99 | 0.23 | 02:46 |
| 1,000 | 1.838 | 67.11 | 1.15 | 13:40 |
| 5,000 | 0.327 | 26.78 | 5.73 | 1:07:27 |
| 10,000 | 0.163 | 16.80 | 11.47 | 2:14:37 |
| 15,000 | 0.120 | 14.02 | 17.20 | 3:21:13 |
| 20,000 | 0.095 | 11.89 | 22.93 | 4:27:40 |
| 25,000 | 0.085 | 10.36 | 28.67 | 5:34:12 |
| 30,000 | 0.072 | 9.27 | 34.40 | 6:40:58 |
※ データセット 6,977 フレーム / batch_size 8 で、1 epoch ≈ 872 step
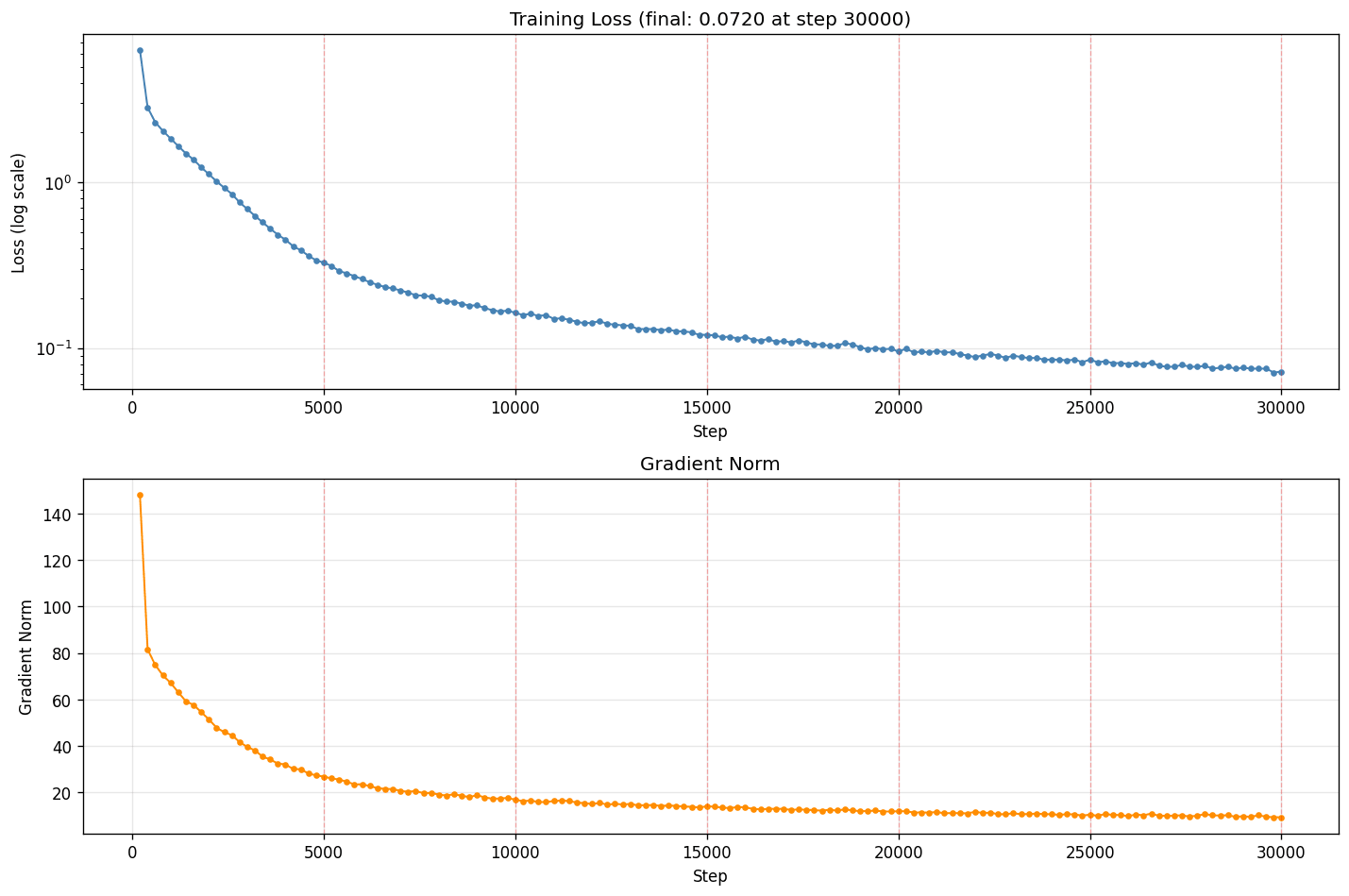
LossとGradをグラフにすると次のようになりました。
どちらも指数減衰のカーブを描き、勾配が安定して収束しているように見えます。数値だけで見ると「30,000 step まで回したほうが良さそう」に見えたのですが、結果は、ちょっと違っていました。
(3) GPU 利用状況の確認
--policy.device=mps を指定して Apple Silicon の GPU が使われているはずなのですが、念のため確認してみました。
使用したのは powermetrics です。
sudo powermetrics --samplers gpu_power -i 1000
--samplers gpu_power: GPU 関連のメトリクスのみ-i 1000: 1,000 ms(1 秒)ごとにサンプリング
実際に取れた出力がこちらです。
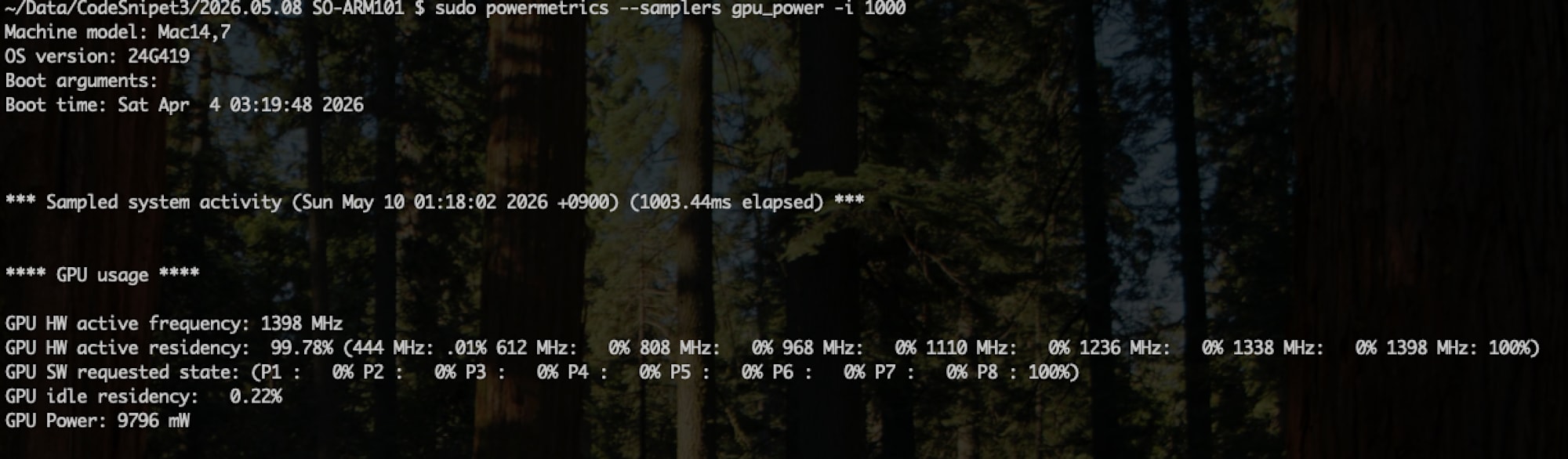
学習時
**** GPU usage ****
GPU HW active frequency: 1398 MHz
GPU HW active residency: 99.78% (444 MHz: .01% 612 MHz: 0% 808 MHz: 0%
968 MHz: 0% 1110 MHz: 0% 1236 MHz: 0%
1338 MHz: 0% 1398 MHz: 100%)
GPU SW requested state: (P1 : 0% P2 : 0% P3 : 0% P4 : 0% P5 : 0% P6 : 0% P7 : 0% P8 : 100%)
GPU idle residency: 0.22%
GPU Power: 9796 mW
通常時
**** GPU usage ****
GPU HW active frequency: 444 MHz
GPU HW active residency: 48.02% (444 MHz: 48% 612 MHz: 0% 808 MHz: 0% 968 MHz: 0% 1110 MHz: 0% 1236 MHz: 0% 1338 MHz: 0% 1398 MHz: 0%)
GPU SW requested state: (P1 : 100% P2 : 0% P3 : 0% P4 : 0% P5 : 0% P6 : 0% P7 : 0% P8 : 0%)
GPU idle residency: 51.98%
GPU Power: 225 mW
この一覧から、GPU を使い切っている状態と言えそうです。
| 項目 | 通常時 | 学習時 | 備考 |
|---|---|---|---|
| GPU HW active frequency | 444 MHz | 1398 MHz | GPU の動作周波数 最高周波数で動作している |
| GPU HW active residency | 48.02% | 99.78% | 99.78% は、ほぼ常時フル稼働 |
| GPU SW requested state | P1:100% P8:0% | P1:0% P8:100% | PyTorch / LeRobotが要求している電力ステート P8 が最高性能(常に最高性能を要求している) |
| GPU idle residency | 48.02% | 0.22% | GPU が休んでいる時間は、ほぼ0 |
| GPU Power | 225 mW | 9796 mW | 消費電力 Apple Silicon GPU の典型的なピーク値(10〜15 W) |
6 評価
作成されたモデルを実機で動かして評価してみました。
(1) lerobot-record (--policy.path)
$ bash eval_act.sh
学習データの収集で使用した lerobot-record は、--policy.path を指定すると、学習済みポリシーの実行として動作します。
GitHub eval_act.sh
eval_act.sh
#!/bin/bash
# Evaluate trained ACT model - 1 episode only (records video)
#CHECKPOINT="last"
CHECKPOINT="025000"
EVAL_NAME="eval_${CHECKPOINT}_single_$(date +%Y%m%d_%H%M%S)"
uv run lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/tty.usbmodem5B3D0430421 \
--robot.id=my_follower \
--robot.cameras="{ front: {type: opencv, index_or_path: 1, width: 640, height: 480, fps: 15} }" \
--display_data=true \
--dataset.repo_id=${EVAL_NAME} \
--dataset.num_episodes=1 \
--dataset.single_task="Pick up the yellow duck and put it in the basket" \
--dataset.push_to_hub=false \
--dataset.episode_time_s=20 \
--dataset.reset_time_s=5 \
--dataset.fps=15 \
--dataset.video_encoding_batch_size=1 \
--dataset.vcodec=h264_videotoolbox \
--policy.path=outputs/train/act_duck_pickup_v1/checkpoints/${CHECKPOINT}/pretrained_model
--policy.path を、評価したい checkpoint のパスに変えれば、好きな step のモデルで評価できます。
取得したチェックポイント 5000, 10000, 15000, 20000, 25000, 30000 の 6 つを順に試しました。
(2) チェックポイント比較
各チェックポイントについて、10 試行ずつ実機で評価し、成功率を測定しました。
| Step | Loss | 成功率 | 評価 |
|---|---|---|---|
| 5,000 | 0.327 | 0% | 学習不足 |
| 10,000 | 0.163 | 60% | 改善中 |
| 15,000 | 0.120 | 80% | 良好 |
| 20,000 | 0.095 | 100% | ベスト |
| 25,000 | 0.085 | 100% | ベスト |
| 30,000 | 0.072 | 90% | 過学習で低下 |
これをグラフにしたのが下図です。
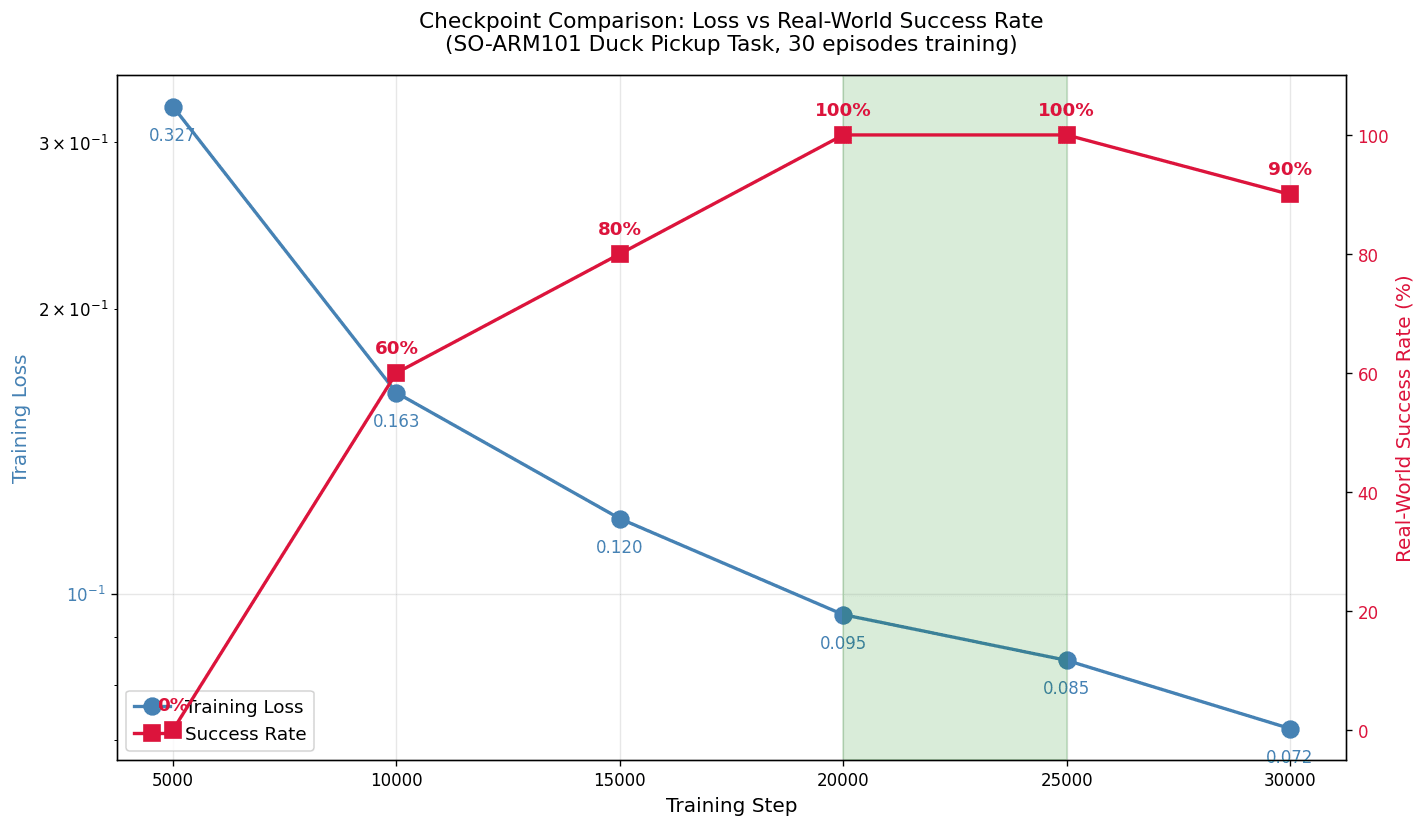
青い線が学習 Loss、赤い線が実機での成功率。背景の緑帯が成功率 100% のスイートスポット(20K〜25K)です。
このグラフの意味は明確で、Loss は最後まで右肩下がりに減り続けていましたが、成功率は 25,000 step 以降で低下していると言えます。
(3) 過学習
30,000 step (loss 0.072) より、20,000〜25,000 step (loss 0.085〜0.095) のほうが成功率が高いという結果は、典型的な 過学習 (overfitting) の現れと言えそうです。
--save_freq=5000 を指定して 6 つの checkpoint を残しておいたからこそ、この事に気づけました。最終モデルだけ残していたら、「過学習となってしまった 30K モデル」しか手元になく、性能の頂点に気づけなかった事になります。
「loss は下がっているから OK 」と思っていると、実機評価で足元をすくわれる、という典型例になりそうです。
(4) 失敗パターン分析
各 step での失敗の質も観察すると、面白い傾向が見えた気がしました。
- 5K (loss 0.327): そもそも動かない / 何もしない / 全く違う方向に手が伸びる。学習不足
- 10K〜15K (loss 0.16〜0.12): グリッパーが空振りする / アヒルを掴んでも落とす / 軌道は概ね正しいが精度が足りない。学習中
- 20K〜25K (loss 0.085〜0.095): 安定。アヒルの位置が多少ズレても追従する。スイートスポット
- 30K (loss 0.072): 動きが微妙にぎこちない / 配置エリアの端だとたまに失敗する。過学習
実機で動作確認すると、モデルの性能がよく分かる気がしました。特に過学習となったモデルの特徴をよく観察して、見極めができるといいなと感じました。
7 最後に
今回は、初めての模倣学習(Imitation Learning)ということで、一連の流れを確認することができました。
特に 「Loss が低い = 性能が高い」ではない (過学習の可能性あり)というのを実機で実証できたこと。また、チェックポイント保存の有効性、Early Stopping の重要性を体感できました。










