
MLX Whisperのv3-turboの8bit量子化モデルを動かしてみる
こんばんは、情報システム部の夏目です。
最近音声の日本語文字起こしを色々試しているのですが、MLX Whisperのv3-turboの8bit量子化モデルを動かすために色々試したので共有します。
なぜMLX Whisperを使ったか

主な理由としては、この記事がよくまとまっています。
後追加するとすれば、Pythonのライブラリである mlx-whisper (or mlx-audio)をインストールするだけで使えるのが非常に良いと思いました。
mlx-communityのwhisper-v3-largeの8bitモデル
mlx-community には whisper-v3-largeの8bit量子化モデルが二つあります。
これは変換に使ったライブラリや作った人が違います。
後者は mlx-audio のメイン開発者が mlx-audio を使って変換したものなので、今回は後者を使います。
(前者は自分では動かすことができなかったということもあるのですが)
使ってみる
モデルカードに書かれている方法
モデルカードはpipでインストールしていたので、uvでインストールするように変えています。
uv init --python 3.14
uv add mlx-audio
uv run main.py
from mlx_audio.stt.utils import load_model
from mlx_audio.stt.generate import generate_transcription
model = load_model("mlx-community/whisper-large-v3-turbo-asr-8bit")
transcription = generate_transcription(
model=model,
audio_path="path_to_audio.wav",
output_path="path_to_output.txt",
format="txt",
verbose=True,
word_timestamps=True, # モデルカードには書かれていないが、話者識別を別途行いたいので付けた
)
print(transcription.text)
これで使うことができます。
verbose=Trueなので文字起こしの内容が標準出力に出力されます。
またpath_to_output.txt.txtというファイルが生成されます。
https://github.com/Blaizzy/mlx-audio/blob/main/mlx_audio/stt/generate.py#L283

この方法だとほぼ確実にファイルが作成されます。
formatに応じた拡張子が追加されるので /dev/null に向けることもできません。
ほぼと言ったのは format="" と空文字列を渡したときには何故かファイルが作成されませんでした。
明らかに想定した使い方とは違うと思うので、ファイルを作成しない別の方法を探しました。
ファイルを作成しない方法
model: mlx_audio.stt.models.whisper.whisper.Model の generate() 関数を使えばできることがわかりました。
from mlx_audio.stt import load_model
from mlx_audio.stt.models.whisper.whisper import Model, STTOutput
model: Model = load_model("mlx-community/whisper-large-v3-turbo-asr-8bit")
result: STTOutput = model.generate(
audio="path_to_audio.wav",
language="ja",
word_timestamps=True,
)
https://github.com/Blaizzy/mlx-audio/blob/main/mlx_audio/stt/models/whisper/whisper.py#L263
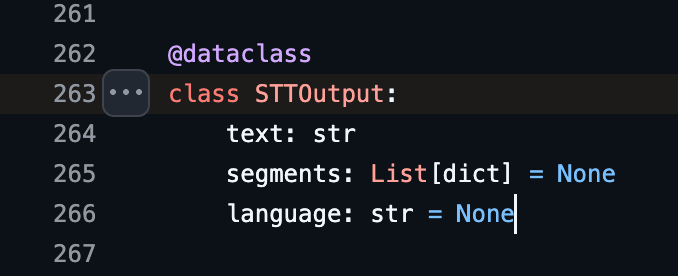
この方法ではファイルを勝手に作成することはありませんでした。
また、コードを読む限りもっと細かく設定ができそうでした。
この方法ならアプリケーションに組み込むというのもできそうです。
まとめ
以上、MLXのwhisper-v3-largeの8bit量子化モデルを使って文字起こしをするために試したことでした。
何かのお役に立てれば幸いです。











