
AMD BC-250でローカルLLMを試してみた
はじめに
製造ビジネステクノロジー部の水島が札幌よりお届けします。
DRAMやフラッシュメモリの価格が高騰している昨今、PCのみならずRaspberryPiのようなSBCですら気軽には買えない状況になってきています。そんな中、安価で高性能なGPUを搭載したワンボードPCがあるという噂を耳にし、これは是非試してみたいと考え、今年のセルフ誕生日プレゼントとして購入してみることにしました。
ボード形状のPCのため、ケース・電源・冷却装置の準備にはひと手間かかりそうですが、小粒でもピリリと辛いマシンになりそうな予感がします。
特徴
このボードが搭載しているものを列挙します。
- Zen2 6コア12スレッドCPU(3.5GHz)
- RDNA 24CU GPU(2GHz)
- GDDR6 16GB 統合メモリ(448GB/s 推定)
- M.2 2280スロット(Gen2x2)
- USB3.0 x2 USB2.0 x2
- DisplayPort x1
- GbE x1
- 12V PCIe補助電源端子
- サイドフロー仕様のヒートシンク
アーキテクチャ的には普通のPCのようですが、モバイル/ミニPC向けのAMD APUよりもGPUコア数が多く、メインメモリにGDDR6のメモリを共用する点が一般的なPCと異なります。
このボードに使われているAPUの前世が何であったかという話題については、ここでは特に触れないことにしましょう。
セットアップ
用意するもの
- BC-250
- M.2 NVMe SSD
- コイン電池 CR2032
- 12V 220W程度を出力できる電源
- 強力なファン
- ファンを取り付けられるケース
BC-250の入手方法はいくつかあるようですが、以前にも利用したことがあるAliexpressにて購入しました。
価格は2万円程度、送料は無料でした。価格は変動するようですので、あくまで参考程度にしていただければと思います。
ケースと冷却装置
このボード用の最適なケースは市販されていません。幸いヒートシンクは搭載されており、ブロアーファンのような静圧の大きいファンがあれば冷却できそうな構造です。
本来はボード後方より端子側にむけてエアフローがあるシャーシに搭載されるようですが、SSDを温風に晒すのはパフォーマンスと寿命の観点で懸念があるので、端子側から後方向きのエアフローで冷却するためのケースを設計して、3Dプリンターで出力しました。

ファンは手持ちの「BG0903-B049-P0S」を使用しました。DELL製PCの補修用として現在でも入手可能のようです。ピンの配列が異なるので、コンタクトを差し替えて対応します。(黒=GND, 赤=12V, 白=Tacho, 青=PWM)
電源制御
電源に250WのTFX電源を用意しましたが、このボードの電源は、PCIe補助電源(8ピン)より供給されるため、ATX電源のオンオフは制御されません。そこで、シャットダウンしたときにATX電源が電源オフされるよう回路を追加しました。
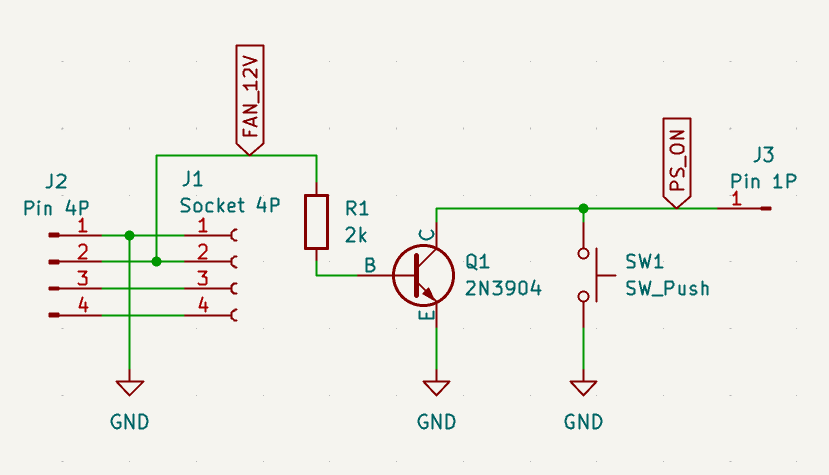
下記の要領で動作します。
- J1-J2をファン端子に割り込ませ、J3をATX電源のPS_ON端子に接続します
- ボード上のジャンパピン(JP1)を自動電源ON(1-2)に設定しておきます
- 電源を入れるときは、ボタンSW1を電源が入るまで押します
- 電源が入りファンに電源が供給されると、電源ONの状態が保持されます
- シャットダウンしてファンが停止すると、ATX電源がオフになります
電源ユニットに直接スイッチをつける場合や、常時電源オンで運用する場合は、電源制御に関して考慮しなくても良いでしょう。

電源制御回路をファンの端子に割り込ませて、ケースに収めた状態です。
OS選定とインストール
コイン電池とSSDを取り付けて組み立てが終わったら、OSをインストールします。
最近のLinuxカーネルにいくつかのBC-250向けの対応が入っているため、新しいカーネルを利用できるディストリビューションを選びましょう。
今回はBC-250のパフォーマンスが発揮できると評判のCachyOSを選択しました。
インストール時に気を付けることは特になく、デフォルトのまま進めて問題ありませんが、ブートローダーにはGRUBを選択することをおすすめします。
インストール後、マウスカーソルのみ表示され先に進まない状態になったため、Gnome環境を追加し、そちらを利用することにました。インストールの段階でGnomeを選択した場合はこの問題は起きないかもしれません。
sudo pacman -S gdm
sudo systemctl disable sddm
sudo systemctl disable plasmalogin
sudo systemctl enable gdm
sudo reboot
GPUチューニング
アイドル時の消費電力抑制と実行時のパフォーマンスのため、GPUガバナーを導入します。これにより、GPUクロックを負荷状態に応じて変更できるようになります。導入しない場合、GPUクロックは1500MHz固定で動作します。
sudo pacman -S base-devel cmake git
git clone https://gitlab.com/mothenjoyer69/oberon-governor.git
cd oberon-governor
cmake .
make -j(nproc)
sudo make install
初期設定のままでは電圧を調整してくれないため、設定ファイルを編集します。下記は設定例です。
opps:
- frequency:
- min: 1000
- max: 1900
- voltage:
- min: 700
- max: 930
標準のカーネルの場合、frequencyは1000-2000(MHz)の間で、voltageは700-1000(mV)の間で調整可能です。稼働時の温度や電源の状況に応じて無理のない範囲で調整しましょう。
設定を変更したら、サービスを再起動して変更を適用します。
sudo systemctl restart oberon-governor.service
万一、動作不可能な設定にしてしまった場合は、OSインストール用のメディアから起動してファイルシステムをマウントし、設定ファイルを編集して復旧することができます。
共有VRAMサイズの変更
GTTと呼ばれるメインメモリ上の共有VRAMのサイズは、デフォルトではメインメモリ割り当て分の約半分が確保されます。
カーネルに起動オプションを追加することで変更することが可能なので、モデルやコンテキストメモリが収まるように調整しましょう。
パラメータに与える数値は、1ページ=4096バイトとして計算します。たとえば10GiB割り当てる場合は 2621440 となります。GRUB設定ファイルのカーネルの起動オプションに下記のパラメータを追加します。
GRUB_CMDLINE_LINUX_DEFAULT='(中略) amdttm.pages_limit=2621440'
grubの設定を適用します。
sudo grub-mkconfig -o /boot/grub/grub.cfg
後述するqwen3:8bを動かすには、VRAMとGTTの合計で11GB程度必要となるようです。
GPUからアクセス可能なメモリに収まりきらない状態で実行した場合、CPUで推論が行われました。
LLMを動かして活用する
Ollamaのセットアップ
Radeonを搭載しているのでROCmを利用してみたいところですが、現状では動作報告がないようです。ランタイム側の対応状況が掴めないため、ここでは確実に動作するVulkanを使用することにします。
sudo pacman -S ollama-vulkan
Vulkanを使用するように下記の設定を追加します。
[Service]
Environment="OLLAMA_VULKAN=1"
準備ができたら、ollamaのサービスを起動しておきます
sudo systemctl start ollama.service
日本語での会話に強いNemotron-Nano-9B-v2-Japaneseベースのモデルを試してみます。
ollama run "hf.co/mradermacher/NVIDIA-Nemotron-Nano-9B-v2-Japanese-GGUF:Q6_K"
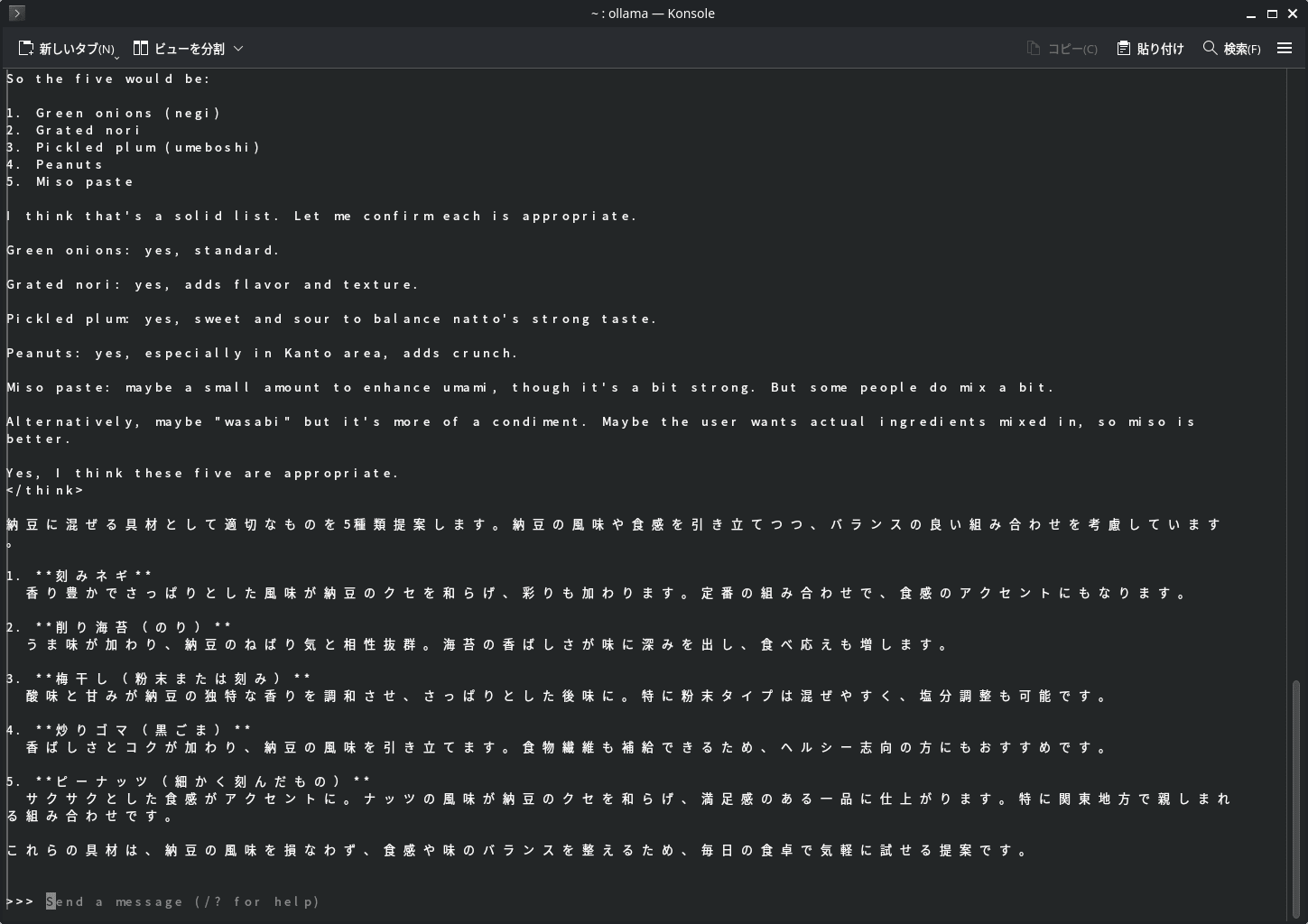
納豆に入れる具について提案してもらいました。ちゃんと日本語で受け答えできています。
Ollamaのベンチマーク
動作することがわかったら、どれくらいの速度が出るかも気になるところです。
llm-benchmark (ollama-benchmark) を実行してみます。
qwen3:8bでは最後の項目を完走することができませんでしたが、42tok/s程度は出ています。
Running custom-model
model_name = qwen3:8b
prompt = Summarize the key differences between classical and operant conditioning in psychology.
eval rate: 42.50 tokens/s
prompt = Translate the following English paragraph into Chinese and elaborate more -> Artificial intelligence is transforming various industries by enhancing efficiency and enabling new capabilities.
eval rate: 43.30 tokens/s
prompt = What are the main causes of the American Civil War?
eval rate: 41.91 tokens/s
prompt = How does photosynthesis contribute to the carbon cycle?
eval rate: 41.99 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game.
^C
Nemotron-Nano-9B-v2-Japaneseの量子化モデルでは、29.354tok/sとなりました。
Running custom-model
model_name = hf.co/mradermacher/NVIDIA-Nemotron-Nano-9B-v2-Japanese-GGUF:Q6_K
prompt = Summarize the key differences between classical and operant conditioning in psychology.
eval rate: 29.33 tokens/s
prompt = Translate the following English paragraph into Chinese and elaborate more -> Artificial intelligence is transforming various industries by enhancing efficiency and enabling new capabilities.
eval rate: 29.39 tokens/s
prompt = What are the main causes of the American Civil War?
eval rate: 29.33 tokens/s
prompt = How does photosynthesis contribute to the carbon cycle?
eval rate: 29.34 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game.
eval rate: 29.38 tokens/s
--------------------
Average of eval rate: 29.354 tokens/s
実際の使用感としては、わりとサクサクとレスポンスが返ってきて楽しいです。推論が実行されると本体の温度が上がり、ファンが強く回転する様子も、頑張ってる感が伝わってきて良いですね。
vibe-localを動かす
vibe-localは、OllamaとPythonのみで動くコーディングアシスタントです。
ローカル推論環境、完全オフラインでもバイブコーディングが体験できます。
ollamaサービスが動いている状態で、vibe-localのインストーラーを実行します。
curl -fsSL https://raw.githubusercontent.com/ochyai/vibe-local/main/install.sh | bash
インストーラーはメインメモリの量でモデルを選択しているようで、qwen3:1.7bが選択されました。
ちょっと試してみましたがあまり頭が良くなかったので、モデルをqwen3:8bに変更してみます。
ollama pull qwen3:8b
MODEL="qwen3:8b"
SIDECAR_MODEL="qwen3:1.7b"
再度vive-localを起動して、ブラウザで動くマルバツゲームを作らせてみました。
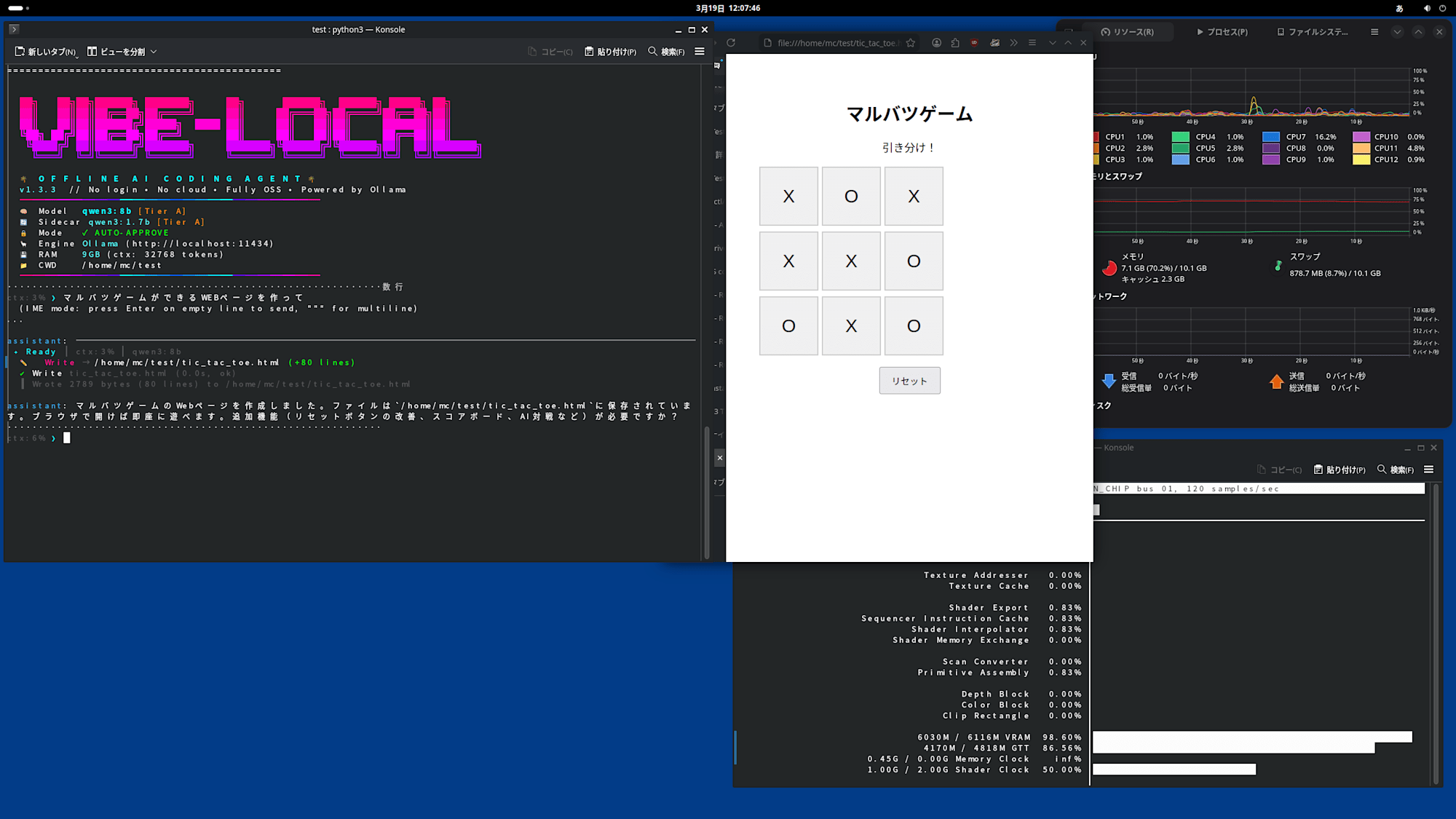
2~3分程度で出力されました。まずまずの速度です。
qwen3:8bでは複雑な作業はできなさそうですが、ちょっと思いついたものを形にしたいときや、軽い作業をオフロードしてメインで使用しているサービスの使用量を節約するといった使い方にはちょうど良さそうです。
これからもコンパクトで性能の良いモデルが出てくるでしょうから、試してみたいですね。
まとめ
BC-250はミドルクラス単体GPU並みの演算性能とハイエンドGPUに迫る広帯域なメモリを持った不思議なPCボードで、10GB程度までのモデルを実用的な速度で推論できる性能でした。
12~16GBのVRAMを搭載するGPUを搭載したPCを持って歩くとなると腰が痛くなりそうですが、このサイズでしたらぎりぎりカバンに入れて持ち運べそうです。PCと同じアーキテクチャなので、Dockerイメージやビルド済みのバイナリをそのまま実行できるところも魅力的です。
大きなサイズのモデルを載せる用途には、128GBのメモリを積んだRyzen AI Max+ 395のミニPCやDGX Sparkが適していそうですが、小さいながらパワフルなBC-250を並列に使用するというのも面白いかもしれません。メインマシンとは別に「エージェントコンピュータ」をもう一台という時代ですし、活用法はユーザーの数だけありそうです。











