
promptfooでプロンプトをテストする
はじめに
LLM を組み込んだアプリケーションを開発していると、「システムプロンプトの正解がわからない」という悩みに突き当たります。プロンプトを少し変更しても、それで本当に良くなったのか、なんとなく良くなった気がするだけなのかがはっきりせず、評価がどうしても人の主観に依存しがちです。
さらに厄介なのが、モデルの新しいバージョンが出たときです。これまでと同じように正しく動くのかは、実際に試してみないとわかりません。とはいえ出力が自然言語で揺れる以上、入力に対して答えが一意に決まらないため、既存のユニットテストや E2E テストではうまく確認できない、というのが悩ましいところです。
この記事では、OSS のプロンプト評価ツール promptfoo を使って、こうしたプロンプトの良し悪しをコードのようにテストする方法を、Gemini APIと組み合わせて紹介します。
promptfoo とは
YAMLでプロンプト・モデル・テストケース・アサーションを定義し、promptfoo eval 一発で評価を回せる CLI ツールです。結果はターミナルにマトリクス表示されるほか、promptfoo view で Web UI から詳しく確認できます。複数モデルを横並びで比較したり、CI/CD に組み込んでプロンプトの回帰テストを回したりできます。
OpenAI / Anthropic / Google(Gemini) など主要プロバイダーに対応しており、今回は Google AI Studio の Gemini を使います。
なぜ promptfoo を選んだか
LLM評価ツールはもちろん promptfoo だけではありません。DeepEval、RAG評価に特化した Ragas、スコープを広げるならlangfuseなど...様々な選択肢があります。そのなかで今回 promptfoo を選んだのは、評価ツールに求めていた次の2点をOSS単体で満たせたからです。
1. 見やすい結果UIがあること
promptfoo view を実行するだけで、ローカルにWeb UIが立ち上がり、プロンプト・入力・出力・各アサーションの合否をブラウザで一覧できます。たとえば DeepEval はメトリクスが充実している一方、共有ダッシュボードや可視化は同社クラウドの Confident AI との連携が前提で、手元だけで完結する手軽なUIは持ちません。Ragas も基本はライブラリでUIはありません。
2. CIに組み込めること
プロンプトの品質を「変更のたびに自動で守る」には、CIに乗せられることが必要となります。
また手元で開発中の任意のタイミングで動かすことをメインのユースケースで考えているため、現状ではまだ試せてませんが、CIに組み込むことは想定されるため、対応が必須でした。
要するに「ローカルで手軽に結果が見えるUI」と「CIに素直に組み込めるCLI」を OSS単体で両立できたのが、今回の決め手です。
評価の構成要素
promptfoo の設定は、おおまかに次の4つの組み合わせでできています。
| 要素 | 役割 |
|---|---|
prompts |
テストしたいプロンプト({{var}} でテンプレート化できる) |
providers |
実行するモデル(例: google:gemini-3.5-flash) |
tests |
入力変数(vars)と期待(assert)のセット |
assert |
出力をどう判定するか(アサーション) |
評価はprompts × providers × tests の直積で実行されます。プロンプト1つ・モデル2つ・テスト3つなら、計6回の評価が走る、というイメージです。
環境
- Node.js 18+
- Gemini API キー(Google AI Studio で取得)
プロジェクトを作り、promptfoo をインストールします。
mkdir prompt-test && cd prompt-test
export GOOGLE_API_KEY="your-api-key"
pnpm add promptfoo
# npm install promptfoo でも可
pnpm 10 だと bindings file エラーになる
promptfoo は評価結果の保存に SQLite(better-sqlite3 というネイティブモジュール)を使います。pnpm はセキュリティのため、依存パッケージのライフサイクルスクリプトをデフォルトで実行しません。そのままだと、インストール時、実行時に次のエラーで落ちます。
Error: Could not locate the bindings file.
今回はpackage.json にビルド許可を足してから pnpm add(または pnpm install)すれば解決します。
{
"pnpm": {
"onlyBuiltDependencies": ["better-sqlite3", "esbuild"]
}
}
つづけて雛形を生成しておきます。
pnpm exec promptfoo init --no-interactive
# npx promptfoo@latest init --no-interactive
promptfooconfig.yaml が生成されます。以降はこのファイルを書き換えていきます。
実際に動かしてみる
まずシンプルなお題として、「文章を1文で要約する」プロンプトをテストしてみます。
# promptfooconfig.yaml
description: 要約プロンプト
prompts:
- "次の文章を1文で要約してください。\n\n{{text}}"
providers:
- google:gemini-3.5-flash
tests:
- vars:
text: |
クラスメソッドはAWSなどのクラウド活用を支援するクラウドインテグレーション企業です。
技術メディア「DevelopersIO」の運営でも知られています。
assert:
- type: contains
value: クラスメソッド
- type: llm-rubric
value: 1文で要約されている
contains は「出力に クラスメソッド という文字列が含まれるか」という決定的なチェック、llm-rubric は「1文で要約されているか」を LLM に採点させる主観的なチェックです。
曖昧な自然言語でアサーションを指示できるのが面白いですね。
実行します。
pnpm exec promptfoo eval # npx promptfoo@latest eval
ターミナルにマトリクス形式で結果が出ます。
Starting evaluation eval-i4D-2026-05-27T10:28:27
Running 1 test cases (up to 4 at a time)...
Evaluating [████████████████████████████████████████] 100% | 1/1
┌──────────────────────┬──────────────────────────────┐
│ text │ [google:gemini-3.5-flash] │
│ │ 次の文章を1文で要約... │
│ │ {{text}} │
├──────────────────────┼──────────────────────────────┤
│ クラスメソッドは... │ [PASS] │
│ │ クラスメソッドはAWS... │
└──────────────────────┴──────────────────────────────┘
✓ Eval complete (ID: eval-i4D-2026-05-27T10:28:27)
» View results: promptfoo view
» Share with your team: https://promptfoo.app
» Feedback: https://promptfoo.dev/feedback
Total Tokens: 1,315
Eval: 354 (43 prompt, 30 completion, 281 reasoning)
Grading: 961 (216 prompt, 52 completion)
Results:
✓ 1 passed (100%)
0 failed (0%)
0 errors (0%)
Duration: 11s (concurrency: 4)
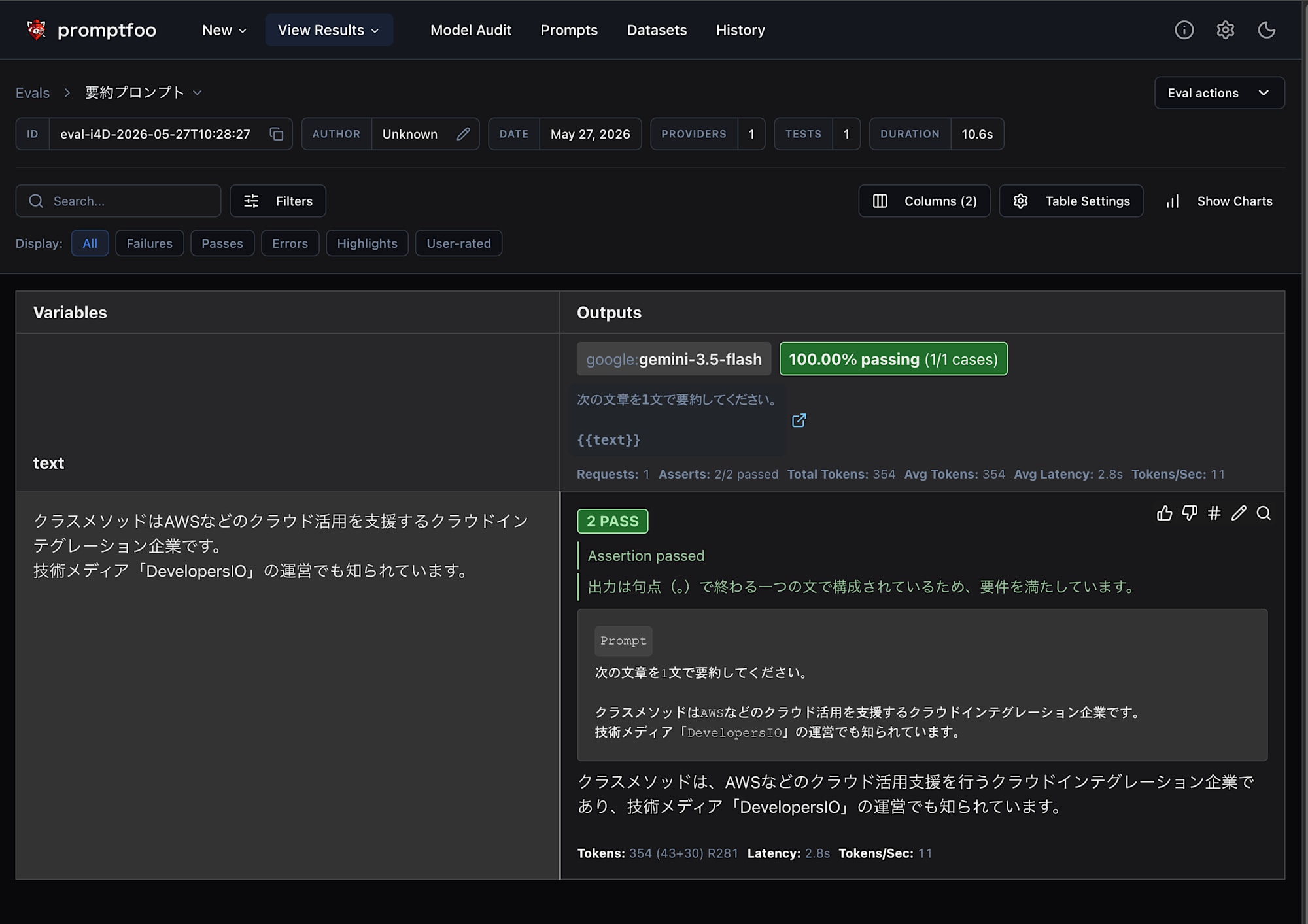
Web UI でも確認できます。
pnpm exec promptfoo view # npx promptfoo@latest view
ブラウザが開き、プロンプト・入力・出力・各アサーションの合否が一覧できます。
その評価の詳細(実際の出力や、アサーションごとの判定理由)が確認できます。
モデルを横並びで比較する
providers を複数並べると、同じプロンプト・同じテストを別モデルで実行して比較できます。ここでは現行の gemini-3.5-flash と、ひとつ前の世代の gemini-2.5-flash を並べて、世代が上がって出力品質がどう変わるかを見てみます。
providers:
- google:gemini-3.5-flash
- google:gemini-2.5-flash
# 採点係はgemini-3.5-flashにお願いする
defaultTest:
options:
provider: google:gemini-3.5-flash
eval を実行すると、モデルごとの合格率・レイテンシ・トークン数(コスト)が並びます。
Starting evaluation eval-vjp-2026-05-27T10:34:27
Running 2 test cases (up to 4 at a time)...
Evaluating [████████████████████████████████████████] 100% | 2/2
┌──────────────────────┬───────────────────────────┬───────────────────────────┐
│ text │ [google:gemini-3.5-flash] │ [google:gemini-2.5-flash] │
│ │ 次の文章を1文で要約... │ 次の文章を1文で要約... │
│ │ {{text}} │ {{text}} │
├──────────────────────┼───────────────────────────┼───────────────────────────┤
│ クラスメソッドは... │ [PASS] │ [PASS] │
│ │ クラスメソッドはAWS... │ クラスメソッドはAWS... │
└──────────────────────┴───────────────────────────┴───────────────────────────┘
✓ Eval complete (ID: eval-vjp-2026-05-27T10:34:27)
» View results: promptfoo view
» Share with your team: https://promptfoo.app
» Feedback: https://promptfoo.dev/feedback
Total Tokens: 1,751
Eval: 836 (43 prompt, 31 completion, 354 cached, 689 reasoning)
Grading: 915 (433 prompt, 115 completion)
Providers:
google:gemini-2.5-flash: 482 (1 requests; 43 prompt, 31 completion, 408 reasoning)
google:gemini-3.5-flash: 354 (0 requests; cached, 281 reasoning)
Results:
✓ 2 passed (100%)
0 failed (0%)
0 errors (0%)
Duration: 6s (concurrency: 4)
Web UI で見ると、モデルが列で横並びになり、どのケースで差が出たかが一目で分かります。
(今回のケースだと単純なテストだったため、結果に大きな違いはありませんでした。)
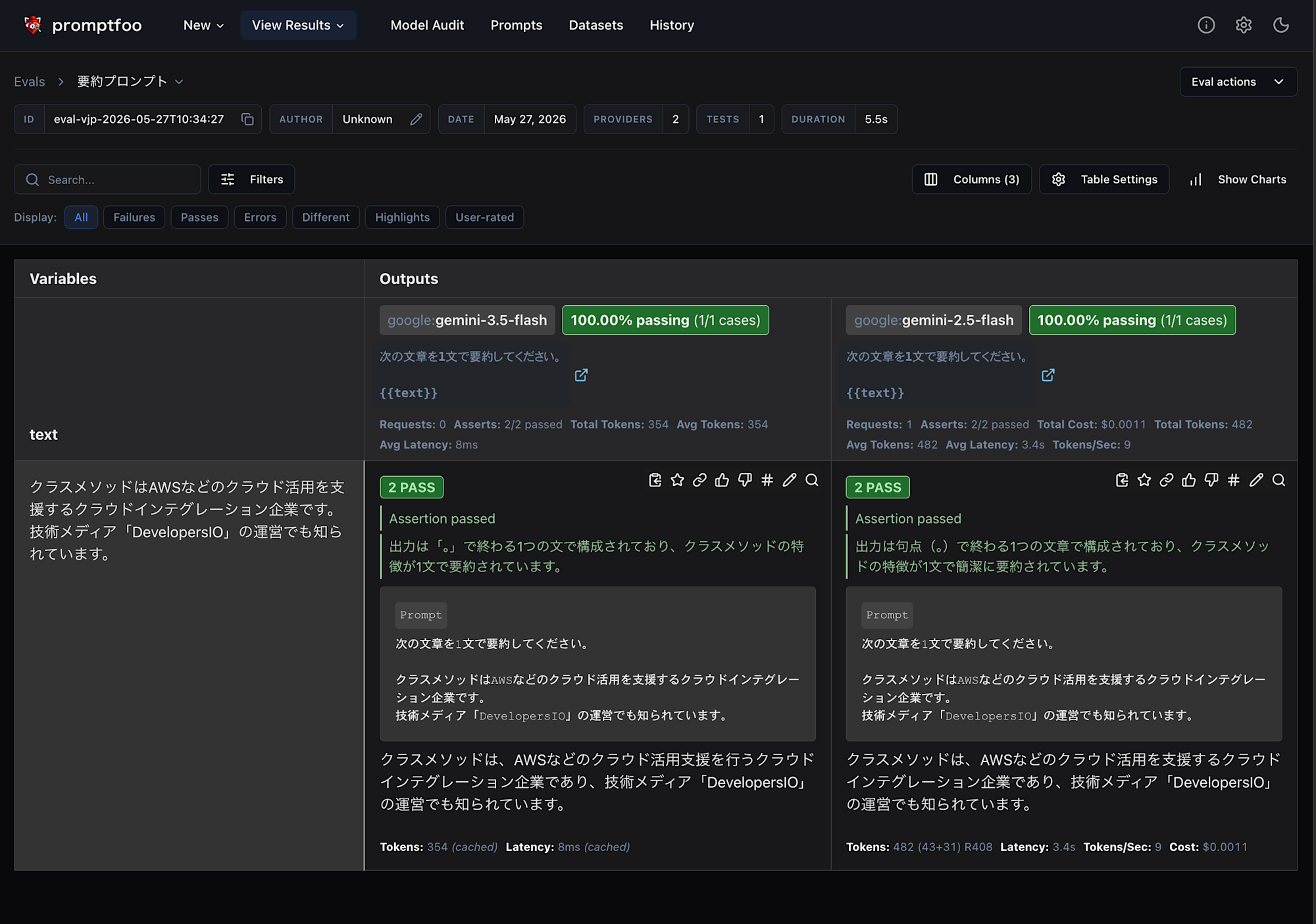
このように同一のプロンプトで別々のモデルを比較し、最適なモデルを選ぶためのデータを収集することができます。
まとめ
- promptfoo を使うと、YAMLでプロンプトテストを宣言的に書ける
- わかりやすいWEB UIで結果を参照できて便利!!
providersを並べるだけでモデルの横並び比較ができ、CI連携で回帰テストも現実的になる
簡単にローカルでプロンプトの検証を始められるのでぜひお試しください!









