
『Amazon Redshift&Tableau パフォーマンスチューニング』に関するホワイトペーパーを読んでみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Amazon RedshiftとTablaeu Softwareの組み合わせは弊社でも取り組んでいるものの1つであり、様々なお客様の案件でこの組み合わせを用いた環境に携わっています。そういった案件の中で重要なポイントとなるのが『パフォーマンスの改善』について。Amazon Redshift然り、Tableau製品然り『こういうケースでこの部分が他のものより遅い、より早くしたい』というケースや課題は割と頻繁に挙がってくものとなります。
Amazon RedshiftとTableau Softwareではそれぞれの技術について最適化する方法が紹介・展開されています。これらの技術について理解していく事でパフォーマンスが向上し、結果として仮説検証の分析サイクルを短くする事が出来ます。当エントリではTableau Software社が公開しているホワイトペーパー『Tuning your Amazon Redshift and Tableau Software Deployment for Better Performance』を読んでみて、そのポイントについて理解を深めて行きたいと思います。

目次
- クエリパフォーマンスのモニタリング
- Tableau Software編(Tableau Softwareのクエリパフォーマンス最適化)
- Amazon Redshift編(Amazon Redshiftのクエリパフォーマンス最適化)
- カーソルを使う際の考慮事項について
- まとめ
クエリパフォーマンスのモニタリング
Tableauを使ってビッグデータ分析を行う際、可能な限り最善のユーザー・エクスペリエンスを提供する為に良い設計とクエリの実践方法に従って作った方が良いのは自然の流れかと思います。レスポンスの改善にはデータベース・テーブル設計、DWH(データウェアハウス)の定期的なメンテナンス実行Tableau可視化の際のベストプラクティスといったもの等も含みます。
Tableauのビルトイン機能である『パフォーマンスの記録』を用いる事で、パフォーマンス的に時間の掛かっているクエリや処理を特定する事が出来ます。指定の操作後に生成されるレポートを見ることで、どの部分がどれ程時間が掛かっているか、またその詳細な内容をグラフを交えて把握する事が可能となります。『パフォーマンスの記録』に関する公式ドキュメントは以下となります。
- Performance(英語)
- パフォーマンス(日本語)
この機能は、Tableau Desktop若しくはTableau Serverで実践が可能です。
また、このテーマについてのブログエントリも以下にありますので宜しければ御参照ください。
Tableau Software編 (Tableau Softwareのクエリパフォーマンス最適化)
レポートやダッシュボードを作成する際、クエリの複雑さ、クエリの数、Amazon Redshiftから返ってくる結果サイズを最小限に留め、応答性を確保する為にTableau Desktopの機能を活用する事が出来ます。
コンテキストフィルタ
もしデータセットのサイズを減らす為にフィルタを使い、またそのフィルタが復数のデータビューで使われている場合、『コンテキストフィルタ』としてそれらのフィルタを設定する事ができます。
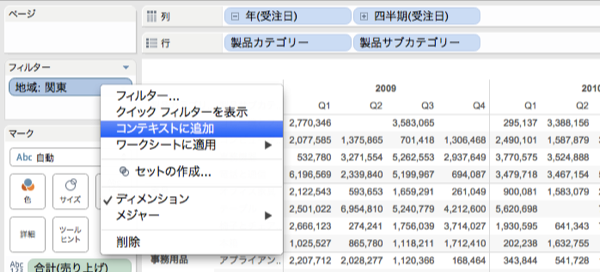
元々のデータサイズが大きい場合、そのビューに於いて表示させる条件が固定されている場合(特定地域のデータ、上位N件のデータ等)等にこのコンテキストフィルタを用いる事で、パフォーマンスの高速化を図る事が出来ます。
- 関連公式ドキュメント:
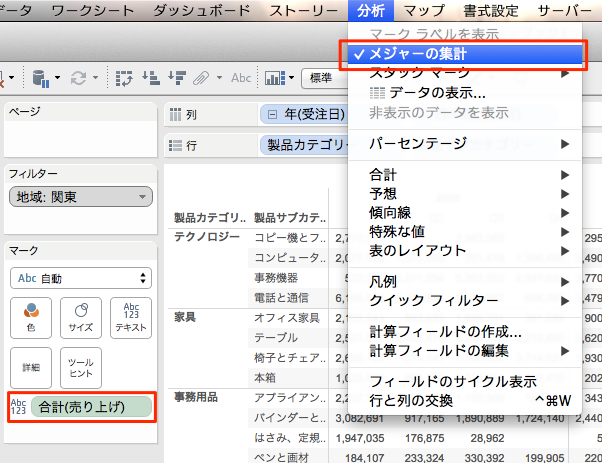
集計メジャー(Aggregate measures)
作成したビューが遅い場合、分散されたままのメジャーを使うのではなく、集計メジャー(aggregated measures)を使う事を検討してみます。 遅いビューは大抵の場合、一度で多くのデータ行を見ようとしているというケースだったりします。予めデータを集約しておく事で、そのデータ行の数を減らす事が出来ます。この操作はメニューで[分析]→[メジャーの集計]を行う事で実現出来ます。
....と見てみると、例えば表形式のビューを作った際は既にこの選択はされてますね。売り上げの[合計]を利用している時点で恐らくこの機能は選択されるようになるのでしょうか。ケースに応じてこの部分が選択されていなかった場合、選択することで改善を見込めるものもありそうです。
- 関連公式ドキュメント:
セット(Sets)
メジャー値の範囲に基づいてメンバーを削除するためにディメンションをフィルタリングしたい場合、定量的なフィルタを使うよりもセット(Set)を使う方が良いでしょう。例えば、ディメンションに於ける全てのアイテムを返すのでは無く、ディメンションに於けるTop50のアイテムのみを返すようなセットを作成する事が出来ます。
- 関連公式ドキュメント:
- 関連ドキュメント(公式以外)
必要なカラムだけをビューに含める
ソートやグルーピング、セットを用いたグループを作成する際は、必要なカラムのみを含む形にしている事を確認します。セットに余分な列が含まれていると、その分パフォーマンスは低下します。(※ソートなりグルーピングをする際、行そのものを扱う事になるので3列の行と100列の行ではサイズ及びパフォーマンスに差が出る、と言う意味合いなのでしょう。)
- 関連公式ドキュメント:
最初にフィルタを追加する
大きいデータソースを扱っている状態でTableauでの自動更新設定をOFFにしている場合、ビューにフィルタを追加するとそのアクションが非常に負荷の高いクエリを発行する可能性があります。ビュー内容を作成してからフィルタリングをするのでは無く、先ずフィルタを指定してからビューを作り上げていった方が良いでしょう。この場合、自動更新設定をONにした時点でフィルタが先ず評価されます。
Amazon Redshift編 (Amazon Redshiftのクエリパフォーマンス最適化)
クラスタサイズ - 特性とサイズに応じた適切なノードタイプの選択を
Amazon Redshiftクラスタでは、コンピュートノードのタイプと数により、計算量、メモリ、利用可能なストレージ容量の総計が決まります。これらの要素はクエリやクエリに格納出来るデータ量、クラスタ全体で格納出来るデータ量等に影響して来ます。Amazon Redshiftでは以下の2タイプのノードをサポートしています。
- 高密度ストレージノード(DW1):
- 安価なHDDを使った、非常に大規模なDWHを構築する際にお勧めです。
- DWHに1TB以上のデータを持つ(又はシングルノードクラスタで500GBのデータを持つ)お客様にとって最もコスト効率が高く、高パフォーマンスなオプションとなります。パフォーマンスを重要としていないお客様や、コスト削減を再優先とするお客様であれば、このDW1ノードを使い、より大きなペタバイト級のデータを扱う事が出来るようになります。RI(Reserved Instance)と組み合わせる事で更なるコストパフォーマンスの効率化も可能です。
- 高密度計算ノード(DW2):
- 高性能CPU、大量のRAM、SSDを使用した、非常に高いパフォーマンスを備えるDWHを構築する際にお勧めです。最も重要な観点をパフォーマンスに置いているお客様に対し、非常に高いCPU、メモリ、I/O性能を提供します。
- DW2ファミリーでは、1TB以下のDWHに対して費用対効果のある比較的小さめのノードを用意しており、DW2クラスのノードを使うことで、同じDWHに対する同じクエリ実行速度は大幅に改善され、結果としてTableauワークブックのパフォーマンスも改善に繋がります。
各ノードは2つのサイズを持ち、結果として4つのノードタイプが選択可能となっています。ストレージ容量を増やす場合、リサイズ処理を行ってノードの数を増やすか、より大きいノードタイプへの変更を行います。DW1⇔DW2間のリサイズ処理も可能です。リサイズ処理は管理コンソールまたはコマンドラインツールでの実行が可能です。
(※以下は2014年10月時点でのノードタイプ及びノードのスペック表です)
| ノードタイプ | vCPU | ECU | メモリ(GiB) | ストレージ | I/O |
|---|---|---|---|---|---|
| DW1(高密度ストレージノード) | |||||
| dw1.xlarge | 2 | 4.4 | 15 | 2TB HDD | 0.30GB/s |
| dw1.8xlarge | 16 | 35 | 120 | 16TB HDD | 2.40GB/s |
| DW2(高密度計算ノード) | |||||
| dw2.large | 2 | 7 | 15 | 0.16TB SSD | 0.20GB/s |
| dw2.8xlarge | 32 | 104 | 244 | 2.56TB SSD | 3.70TB/s |
ノードのサイズを大きくする事で可能となるカーソルの数も増やせる様になり、クエリの同時実行についてもより大きなレベルで実行出来るようになります。もしワークブックから直接Redshiftに接続しているのであれば、Redshiftは十分な計算リソースとメモリ容量、更には十分なストレージ容量の結果を備えるようになり、結果としてクエリパフォーマンスの向上ときびきびとしたユーザーエクスペリエンスに繋がります。
クラスタののサイズをどのような内容にするのかについては、求めるワークブックの更新スピードとDWHに対するクエリの接続数を考慮して決定する事になります。もし多くのワークブックを同時に更新し、多くのユーザーが同時にクエリ接続を行える形を望むのであれば、高キャパシティのものを選びましょう。
データの暗号化 - 暗号化は慎重に
機密データを含む環境・ケースの場合、ディスクに格納されているデータの暗号化が必要な局面も出て来ます。
Amazon RedshiftはハードウェアアクセラレーションによるAES-256暗号化とユーザー制御のキーローテーションをサポートするオプションを有しています。Amazon Redshiftはまた、オンプレミスのハードウェアセキュリティモジュール(HSM: Hardware Security Module)と、お客様が暗号化キー生成と管理を直接制御出来るCloudHSMの使用をサポートしています。
暗号化を用いる事で、お客様のセキュリティ要件を満たすための支援を行う事が出来、機密性の高いデータを保護する事が出来るようになります。Redshiftでは、エンドユーザーとデータを格納するノードの間にセキュリティ分離の幾つかのレイヤーを持っています。例えば、エンドユーザーはデータを格納しているAmazon Redshiftクラスタのノードには直接接続は出来ません。
しかし、上記の対策で暗号化がなされたとしても、暗号化はとてもコストの掛かる操作となります。平均で20%、ピーク時では40%程パフォーマンスが低下します。セキュリティ要件がAmazon Redshiftが提供している分離レイヤーの条件を超えて暗号化を必要としている場合、またお客様のニーズが暗号化を必要とする場合のみ、データの暗号化を行うようにしてください。この点については慎重な決定が必要です。
…最後の段落、暗号化は重要な点ではありますがパフォーマンスが20〜40%低下するというのは結構辛いですね...機密データをAWSにアップロードする前に、オンプレ側でデータをマスキングするなり不要な項目を除去しておく等して暗号化を回避する等の対策を考えておく必要はありそうですね。
適切な分散スタイル・分散キーの選択
適切な分散スタイルと分散キーの設定を行う事で、結合のパフォーマンスが大幅に向上します。Amazon Redshiftは復数ノード間を跨って操作を並列処理する事でスケールアウトします。分散スタイル(EVEN, KEY, ALL)は、どのようにテーブルがクラスタ間に分散配置されるかどうかの定義を行います。
分散スタイル指定:KEY
大規模なテーブルに対する一般的な分散スタイル(の指定)はKEYです。
テーブルを作成(CREATE TABLE)する際に、distkey(対象列名)で1つの列を指定します。同じキー値を持つ全ての行は、同じノードに配置されるようになります。分散スタイルをKEY指定している異なるテーブルがある場合、双方のdistkey指定を同じ列名にする事で同じノードにその行が配置されるようになります。
これはつまり、一般的に結合されている2つのテーブルがある場合、結合で使用されている列同士が分散キーとなり、結合された行が同じ物理ノード上に併置(collocated)されるようになるという事です。同じノード上にデータが併置されている事により、ノード間のデータ移動が必要無くなり、結果としてクエリが高速に実行されるようになります。もし、ファクトテーブルのような復数の他のテーブルと結合するようなテーブルの場合、テーブルが結合している最も大きなのディメンションの外部キーを分散キーとします。
分散キーの指定の結果としてテーブルデータが均等に分散されているかどうかを常に確認するようにしてください。
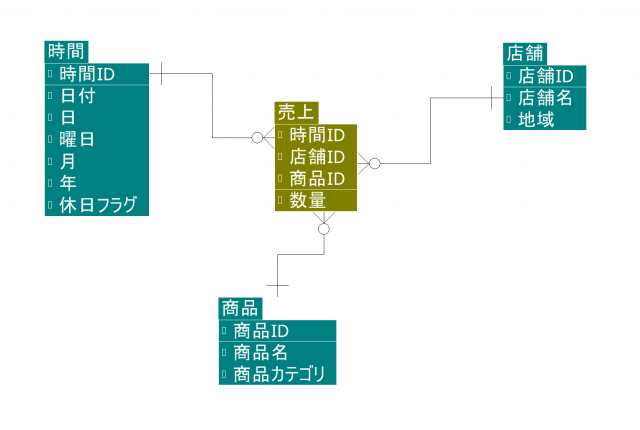
※ちなみに、ここで出て来たファクトテーブルとディメンションテーブルですが、意味合いとしては以下のようなものになります。ファクトテーブル:トランザクションデータ、ディメンションテーブル:マスタ系やその他付加的な情報を備えたテーブル、という位置付けになりますでしょうか。
- ファクトテーブル:
- データウェアハウススキーマ内の中心に位置する、索引と数値カラムで構成される中心的なテーブル。 (※出典 )
- ディメンションテーブル:
- ディメンションテーブルとは、ファクトテーブル内のデータを表すエントリを持つ、属性データで構成されるテーブル。 (※出典 )
以下エントリで紹介されているテーブル構造がイメージし易い物となってますので参考に挙げておきます。
分散スタイル指定:ALL
2つ目の分散スタイル指定はALLです。結合データに関するコロケーションを促進します。
この分散スタイルはクラスタ内の全てのノードにデータを配置します。全てのノードにデータをレプリケート(複製)するため、ストレージのコストが掛かり、ロード時間もその分長くなります。全てのノードに配置されているので結合は全てそのノード間内で行われるようになり、データの移動も無くなるので結果としてパフォーマンスが改善します。
分散スタイル: ALL(diststyle ALL)を指定する際の良い候補としては、ファクトテーブルと同じ分散キーを共有しないスタースキーマ(Star Schema)に於ける、緩やかに変化するディメンションテーブルです。
分散スタイル:EVEN
分散スタイルの指定について、KEY指定(distkey(対象列名))、ALL指定(diststyle ALL)のいずれも指定しない場合(すなわち指定無しの場合)、テーブルデータはクラスタ全体に、均等に分散します。
データ分散の指定方法に関する詳細は、以下ドキュメントなどをご参考ください。
ソートキー
ソートキーはテーブルのデータがどのような順序で格納されるかを定義するものです。この"順序"は、Amazon Redshiftがクエリの条件やWHERE句の内容に応じて効果的にフィルタリングするための重要な要素となります。
ディメンションテーブルの様に頻繁にテーブルを結合する場合、分散キーとソートキーに同じ列を指定します。これによりAmazon Redshiftで多くのケースで最適化された結合で処理を実行するようになります。もし指定の際『効率的な結合を行う事が出来るフィールド』と『フィルタリングに使用するフィールド』を選ぶ場合は、一般的には後者の列を選ぶようにします。
ソートキーは複数列の指定が可能です。例えば、ソートキーに[Color(色)]列、[Product Type(製品タイプ)]列と指定した場合、データはまず[Color(色)]でソートされ、次いで[Product Type(製品タイプ)]でソートされます。色と製品タイプの両方をフィルタ指定してるのであれば、双方の項目をソートキーに指定しておいた方が良いでしょう。
クエリが製品タイプのみでフィルタリングされている場合、ソートキーはあまり効果を発揮しません。なぜなら製品タイプの順序は色の中に収まっているからです。
一方、もしクエリが色のみでフィルタリングされている場合、ソートキーは効果を発揮するでしょう。なぜなら、色がソートキーの先頭列に指定されているからです。
(↑この辺り、読んでて若干意味が取りづらいかな〜と思いましたけど、以下の様なデータの並びであった場合、Tableauでフィルタリングした時の事を考えると、[製品タイプ]でフィルタリングしても第1ソートキーの色でソートされているデータなのでフィルタリングの効果が見込められないのに対し、色は第1ソートキーで既にソートされているので色でフィルタリングするのは効果的、という風に捉えれば良いのでしょうか。共に設定していた場合でも、先ず色フィルタで絞り込んでから製品タイプで絞り込む方が効率は良さそうですね。)
赤:TYPE-A 赤:TYPE-A 赤:TYPE-B 青:TYPE-A 青:TYPE-C 青:TYPE-D 黄:TYPE-B 黄:TYPE-D 黄:TYPE-E
ソートキーに指定された列が"選択度が高い"("カーディナリティが高い"とも言う)ものである時、その列の追加による効果は少なく、メンテナンスコストが掛かるようになります。選択度の低いものであれば追加しましょう。
※さて、また新しい単語『カーディナリティ』が出て来ました。以下サイトに分かり易い例を交えた解説があるので引用します。
カーディナリティ度が低いとは、カラムの値の種類がレコード数に比べて少ないことをあらわす。 カーディナリティ度が高いとは、カラムの値の種類がレコード数に比べて多いことをあらわす。 種類の絶対数の多少でなく度合いである。 例えば、子供から大人までの場合、性別や血液型などはカーディナリティ度が低く、 身長や体重はカーディナリティ度が高い。同じ長さでも、靴のサイズなどはカーディナリティ度が低いといえる。
整理すると『カーディナリティの低いもの(カラムの値の種類がレコード数に比べて少ないもの)であれば、ソートキーに指定しておくと効果が高い』となります。復数ソートキー指定候補となり得る項目があった場合は、この辺りの情報を頼りに指定を定めていくと良さそうです。
この例の場合、色のカーディナリティは(製品タイプに比べて)低いので、(色に続けて)製品タイプをソートキーに追加する事はメリットがあると考えられます。
圧縮設定(列圧縮タイプ)
圧縮設定(列圧縮タイプ)はAmazon Redshiftでのクエリパフォーマンスを改善するための効果的な手段の1つです。適切な圧縮設定を行う事で、データI/Oとストレージ容量の削減を図る事が出来、結果的にそれらがパフォーマンス改善へと繋がります。
空のテーブルにデータをCOPYする際、デフォルトでは10万件以上のデータがあれば、オプション指定を行う事でRedshiftオススメの圧縮設定を参考にする事が出来ます。テーブルを作成(列圧縮タイプの指定無し)→COPY処理実施(自動圧縮指定オプションを有効にして実行)→圧縮設定情報の取得→その情報を元にテーブル再作成(列圧縮タイプの指定あり)、と言った流れです。もちろん、一からテーブル作成時の列圧縮タイプの設定を自分で定め、作成していく事も可能です。
(※この辺り、実際の感覚で行くと、データの内容にも拠ってくるのですが必ずしも適切な指定・ベストな指定をAmazon Redshiftが提示してくれるものでは無い感じです。ざっくりAmazon Redshiftの提示された内容を参考にしつつ、データ型や値の範囲等から改めて項目毎の列圧縮タイプを見直して行くほうが良いでしょう。)
『自動圧縮ありのデータロード』及び列圧縮タイプに関する情報については、以下のエントリも参考にしてみてください。
VACUUM処理
データの追加・更新・削除を大量に行った際は、パフォーマンスを最適化させる為にVACUUMコマンドを実効する様にしてください。VACUUM処理を行う事で削除された要素のスペースをクリアし、ディスク上のデータをソートします(※ソートキーが設定されている場合)。結果としてクエリ実行の高速化を図る事が出来ます。COPYコマンドはテーブルへのロード時にデータをソートするので、初期ロード時、またソートファイル内でデータをソートしておく必要はありません。
もしソートキーの順序に並んでいる復数のファイルをテーブルにロードする場合、COPYコマンドは日付ファイルの順番で行いましょう。例えば、以下のようにファイルが異なる日付で存在している場合、ソートキーは日付時刻の項目とし、COPYコマンド実行も日付の古いものから順に実行します。こうする事でVACUUM処理を行う必要無く、データのロードを行う事が出来ます。
- 20140810.csv
- 20140811.csv
- 20140812.csv
VACUUM処理は実行にリソースを喰いますので、より早いVACUUMコマンド処理の為にメモリ量を増やすためにオフピークの時間帯にコマンドを実行するなど検討する必要があるでしょう。詳細は以下を御参照ください。
ANALYZE
大量データのロードを行った後にANALYZEを実行する事で、クエリプランを構築し、最適化する際にクエリプランナーが使用する統計情報を更新するクエリパフォーマンスを向上させる事が出来ます。COPYコマンドを使用してデータをロードする際、STATUPDATE ONオプションを指定する事で、データロード完了後、自動的にANALYZEを行わせる事が出来ます。
VACUUM処理同様に、ANALYZEコマンドは処理にリソースが必要となります。オフピーク時間帯に実行を行う等の対応が好ましいでしょう。
もしVACUUM処理とANALYZE処理を両方行う場合、VACUUM処理を先に行います。ANALYZEによって生成される統計情報の内容がVACUUM処理の結果に影響を受けるからです。その他詳細については以下情報を御参照ください。
関連
データモデルと同様、プライマリキーと外部キーを定義する事が出来ます。Amazon Redshiftではこれらのリレーションを、クエリプランを最適化する方法として、クエリプランを作成する際のヒントとして利用出来ます。
Tableauはプライマリキーと外部キーを、重複クエリを検出・除去する為に使います。 データ元のシステムがリレーションを強制している場合には、リレーションは定義した方が良いでしょう。(ちなみに Amazon Redshiftはこれらのリレーション制約を強制しません。ですので、リレーションを定義したものの整合性が適用されなかった場合は、クエリが予期しない結果を返す事があります。この辺りの詳細については以下を御参照ください。
その他Redshiftパフォーマンスに関するTips
Amazon Redshift DB管理者ガイド(英語/日本語)では上記情報の他にも参考となる情報が色々と展開されています。以下に英語版・日本語版の公式ドキュメントをご紹介。
- テーブル設計:
- クエリパフォーマンスのチューニング:
- テーブルへのロード処理:
- 利用可能なメモリを増やす:
- データロードのベストプラクティス:
- WLM(ワークロード管理):
カーソルを使う際の考慮事項について
Amazon Redshiftからクエリに対するデータを返す際、Tableauではカーソルを使っています。
カーソルを利用する事で(一度に全てでは無く、一定量のデータを取得するようになり)Tableauが大量のデータを効率的に取得出来、消費されるメモリの量を減らせるようになります。データセットのサイズはカーソルを使わずに取得出来るものよりも大きかったりします。
最大結果サイズはクラスタノードタイプ、及びクラスタ構成(シングルノードorマルチノード)に依存します。カーソル毎の最大結果サイズを変更する事で、カーソル毎の最大結果サイズと実行可能な同時カーソル数を調整して行く事が出来ます。
例えば、デフォルトでdw2.largeクラスタの復数ノードではクラスタあたり384GBの最大結果サイズ、カーソルは2つ、カーソル毎の最大結果サイズが192GBとなります。もし最大結果サイズを32GBと定めた場合、max_cursor_result_set_sizeを32000(MB)と設定する事で利用可能なカーソルの数を増やす事が出来ます。(384000MB/32000MB=12個) なお、同時実行カーソル数は同時実行クエリ数の上限を超える事は出来ません。
- 同時実行カーソル数:当項で解説している要素。[クラスタ毎に割り当てられている容量の総量(MB)]÷[カーソル1つで利用出来る容量(MB)]で割り出される個数。
- 同時実行クエリ数:クラスタ自体が扱えるクエリの同時アクセス数。WLM(Workload Management:ワークロード管理)で管理制御が可能。
カーソルに関する詳細については以下を御参照ください。
また、過去カーソルについてブログエントリを書いております。こちらも併せて御参照ください。
TableauとAmazon Redshiftを併せて使用する際にメリットを最大限得るにはライブ接続をお勧めしますが、抽出を利用する選択もあります。 Tableauで大きな抽出ファイルを扱う際にカーソル利用数の上限に達してしまうのを避けるために、同時並行でリフレッシュする事を避けてスケジュールしておくのが良いでしょう。詳細については以下を御参照ください。
まとめ
以上、Tableau社から出されているAmazon RedshiftとTableauに於けるパフォーマンス改善のホワイトペーパーを読んでみたエントリでした。
今回ご紹介した様に、Tableauサイド、Redshiftサイド共に見るべきポイントは多いです。着手出来る部分から少しずつでも改善を重ねて、より良いデータ分析環境を構築して行きたいものですね。
なお、Tableau公式ドキュメントでは以下のページで『パフォーマンス』に関する解説を行っています。上記の内容で言及されているものもありますが、宜しければご参照ください。こちらからは以上です。
<!--
- カタログクエリの例 - Amazon Redshift
- 分散の例 - Amazon Redshift
- Optimizing for Star Schemas on Amazon Redshift : Articles & Tutorials : Amazon Web Services
- スタースキーマ - Wikipedia
--!>











