OCRの読み取りミスを修正する手作業をAIに代わりにやってもらってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
新規事業部 Passregiチームの山本です。
先日、CX事業本部の平内さん(SINさん)が、FAXで受信した紙の帳票をOCRで読み取ってCSVファイルにする方法に関して、ブログを公開されました。
https://dev.classmethod.jp/articles/computer-vision-read-api/
上記のページの最後に、課題としてOCRが読み取りをミスすることがあり、そのミスを手動で修正する必要がありそう、と分析されていました。
このページでは、OCRの読み取りミスを自動で修正するために、AIを使って試してみた内容について記載します。
問題点と解決方法
問題点の整理

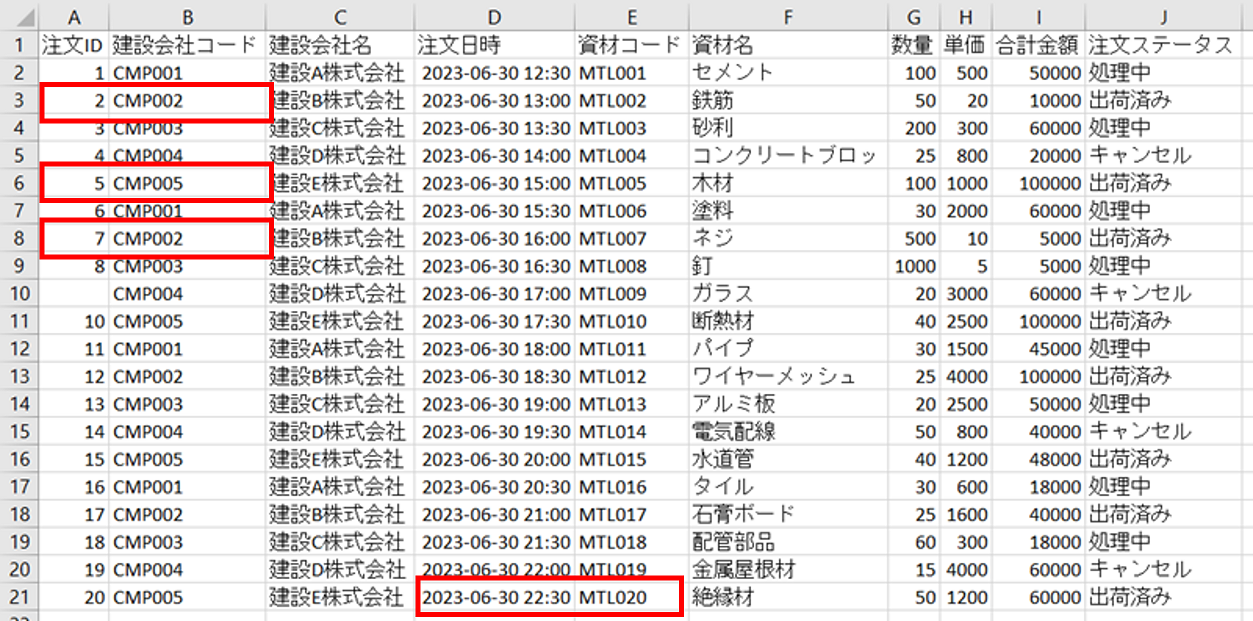
上のページの取り組みで残った問題点は、以下のような状況した。
- 文字の読み取り自体はできていた
- 読み取りを行う範囲(単位)がズレてしまった(複数のセルを1つとして認識してしまっている)。その結果、1つ1つのセルとの突き合わせができず、空白になってしまった
- (前後の行では、正しく読み取りができていた)
(テーブル外の文字は格子の座標より外側なので、単純な判定でフィルタリングすることができそうです)
解決方法の考え方
修正の概要については以下の図のとおりです(赤文字の箇所が追加した処理です)。OCRで認識した結果をもとに、ミスの種類や箇所を特定し、それをもとにプロンプト作成してLLM(Large Language Model)に修正させるという方法です。

今回の場合で言うと、以下のような処理を追加します。(少しわかりにくいと思うので、詳しくは次節以降をご覧ください)
- 格子の座標とOCRの認識結果をもとに、空欄箇所に該当する認識結果を特定する
- 空欄箇所の認識結果(失敗した箇所)と前後の行の認識結果(成功した箇所)をもとにプロンプトを作成し、LLMに認識した文字列分割させる
特に今回のミスの場合は、以下の観点からLLMでの処理に向いてそうです。
- 比較的簡単なタスクである
- 文字列の変換のみであり、計算や思考が必要なさそう
- 情報がプロンプト内で完結していて、検索が必要ない
- (今まで筆者が見聞きした中で、成功していたタスクに似ている・ほぼ同じ)
- 前後の行に同じ形式のデータがあり、Few-Shotのようなプロンプトの与え方ができる
補足
もちろん、こうした条件以外にも読み取りミスが発生することがありそうです(実際に上の画像でも起きています、後述)。ただ、今回は上記の問題に絞って解決方法を検討しました。実際の取り組みでは、いくつかのサンプル画像で試して問題点を抽出・整理し、発生する条件に合わせてLLMに修正させる処理を追加する、というプロセスにすると良さそうです。
検討:まずはChatGPT(Web)で試してみる
誤った認識結果とその前後の行を手動でコピペし、下のようなプロンプトで修正させたところ、GPT-3.5とGPT-4の両方で同じく意図した回答を得られました。

この結果から、修正作業をAIに実行させられそうなことがわかりました。
(使用したプロンプト)
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように分割してください。分割した結果のみ出力してください。 # 前後の行 1,CMP001 3,CMP003 4,CMP004 # 分割したい文字列 2 CMP002 # 分割結果
解決:OpenAI API(コード)で自動処理する
上記の検討をもとに、プログラムを作成しました。処理の内容は以下の通りです。(追加した処理についてのみ記載しています。既存の部分に関してはSINさんの記事をご覧ください)
1.空欄の座標を特定する
出力結果(CSV)が空欄になっているセルと探索し、それに該当する画像上の座標(下図右の水色の四角)を計算します

2-1.空欄に該当するOCRの認識結果を特定する
空欄の座標に対して、OCRの認識結果のbboxが含まれるかを判定します。これにより、空欄に対応する認識結果(赤太の四角)のテキストを得ます

(OCRの認識位置と空欄セルの位置が一致しているかどうかは、IoU(より正確には、OCRのbboxが空欄の四角形に含まれている面積の割合)を計算して閾値以上かどうかを判定する方が良いかもしれません)
2-2.該当箇所と同じ項目(列)を前の行から取り出す
認識結果の表から、空欄のセルと同じ列で、認識に成功した結果(下図の緑を取り出します)

3.プロンプトと作成してLLMに実行させる
「検討」の節で使用したように、プロンプトに「前後の行(2-2の緑四角)と」「認識結果(2-1の赤太四角)」を加えて、LLMに渡して分割を推定させます
使用したテンプレートは以下のものを使用しました。SPLITTERは”,”で、OPENAI_MODELは"gpt-3.5-turbo-0613”で実行しました。
- 使用したテンプレート
prompt_template = """
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように"{splitter}"で分割してください。分割した結果のみ出力してください。
# 前後の行
{near_rows}
# 分割したい文字列
{target_row}
# 分割結果
"""
- 実行する処理
prompt = prompt_template.format(
splitter=SPLITTER,
near_rows="\n".join([SPLITTER.join(line) for line in near_cells_list]),
target_row=ocr_text,
)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=OPENAI_MODEL,
temperature=0.0,
messages=messages,
)
content: str = response["choices"][0]["message"]["content"]
- 実行時の例
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように","で分割してください。分割した結果のみ出力してください。 # 前後の行 1,CMP001 3,CMP003 4,CMP004 # 分割したい文字列 2 CMP002 # 分割結果
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように","で分割してください。分割した結果のみ出力してください。 # 前後の行 2023-06-30 12:30,MTL001 2023-06-30 13:00,MTL002 2023-06-30 13:30,MTL003 # 分割したい文字列 2023-06-30 22:30 MTL020 # 分割結果
4.元のCSVを更新する
LLMの実行結果をもとに、認識結果の空欄だった箇所(CSV)を更新します
使用したコード
クリックすると開きます
import codecs
import csv
import json
import os
import time
from typing import Dict, List
import cv2
import numpy as np
import openai
import requests
WIDTH_CONSOLIDATE = 3
SPLITTER = ","
# OPENAI_MODEL = "gpt-4-0613"
OPENAI_MODEL = "gpt-3.5-turbo-0613"
prompt_template = """
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように"{splitter}"で分割してください。分割した結果のみ出力してください。
# 前後の行
{near_rows}
# 分割したい文字列
{target_row}
# 分割結果
"""
# 矩形描画
def disp_rects(rects, img, thickness):
image = img.copy()
for i, rect in enumerate(rects):
color = np.random.randint(0, 255, 3).tolist()
cv2.drawContours(image, rects, i, color, thickness)
return image
# 近似座標の集約
def consolidation(list: List[int]):
result: List[int] = []
min = 0
counter = 0
for val in list:
if min == 0:
min = val
keep = val
else:
if val > keep + WIDTH_CONSOLIDATE: # 3ドット以内をまとめる
if counter > 2: # 得意な検出は排除する
result.append(int(min + (keep - min) / 2))
min = val
counter = 0
counter += 1
keep = val
if counter > 2: # 特異な検出は排除する
result.append(int(min + (keep - min) / 2))
return result
# 座標検出
def detect_point(rects: List[np.ndarray]):
# 全X,Y検出
x_list = []
y_list = []
for rect in rects:
for i in range(4):
x, y = rect[i]
if not x in x_list:
x_list.append(x)
if not y in y_list:
y_list.append(y)
x_list.sort()
y_list.sort()
# 近似値の集約
x_list = consolidation(x_list)
y_list = consolidation(y_list)
return x_list, y_list
# LINE描画
def disp_line(x_list, y_list, img):
image = img.copy()
x_min = min(x_list)
x_max = max(x_list)
y_min = min(y_list)
y_max = max(y_list)
for x in x_list:
cv2.line(
image,
pt1=(x, y_min),
pt2=(x, y_max),
color=(0, 0, 255),
thickness=1,
lineType=cv2.LINE_4,
shift=0,
)
for y in y_list:
cv2.line(
image,
pt1=(x_min, y),
pt2=(x_max, y),
color=(0, 0, 255),
thickness=1,
lineType=cv2.LINE_4,
shift=0,
)
return image
def estimate_table_coords(org_img: np.ndarray):
# グレースケール変換
gray_image = cv2.cvtColor(org_img, cv2.COLOR_BGR2GRAY)
# エッジ抽出
edges_image = cv2.Canny(gray_image, 1, 100, apertureSize=3)
# 膨張処理
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dilate_image = cv2.dilate(edges_image, kernel)
# 輪郭抽出
contours, hierarchy = cv2.findContours(dilate_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 面積でフィルタリング
rects: List[np.ndarray] = []
for cnt, hrchy in zip(contours, hierarchy[0]):
if cv2.contourArea(cnt) < 3000:
continue # 面積が一定の大きさを満たさないものを除く
if cv2.contourArea(cnt) > 20000:
continue # 面積が一定の大きさを超えるものを除く
if hrchy[3] == -1:
continue # ルートノードは除く
# 輪郭を囲む長方形を計算する。
rect = cv2.minAreaRect(cnt)
rect_points = cv2.boxPoints(rect).astype(int)
rects.append(rect_points)
# 座標検出
x_list, y_list = detect_point(rects)
return x_list, y_list
def detect_empty_cell_sets(line: List[str]):
index_sets_empty_cell: List[List[int]] = []
index_set = []
for i, cell in enumerate(line):
if cell == "":
index_set.append(i)
if i == (len(line) - 1) or line[i + 1] != "":
index_sets_empty_cell.append(index_set)
index_set = []
return index_sets_empty_cell
def search_bbox(
x_list: List[int],
y_list: List[int],
i_line: int,
read_results: Dict,
index_set: List[int],
):
# coordinate from image
left = x_list[index_set[0]]
right = x_list[index_set[-1] + 1]
top = y_list[i_line]
bottom = y_list[i_line + 1]
for line in read_results["lines"]:
# coordinate from OCR
boundingBox = line["boundingBox"]
x0 = boundingBox[0]
x1 = boundingBox[4]
y0 = boundingBox[1]
y1 = boundingBox[5]
# if bbox in empty cell
if left <= x0 and x1 <= right and top <= y0 and y1 <= bottom:
return line
return None
def extract_near_cell_values(
content: List[List[str]],
i_line: int,
index_set: List[int],
n_get_near_rows: int = 3,
):
near_cells_list: List[List[str]] = []
n_get_line = 0
for line in content[1:]: # 先頭行はヘッダーなので除く
near_cells = line[index_set[0] : index_set[-1] + 1]
if all([cell != "" for cell in near_cells]):
near_cells_list.append(near_cells)
n_get_line += 1
if n_get_line >= n_get_near_rows:
break
return near_cells_list
def estimate_split_with_AI(
ocr_text: str,
near_cells_list: List[List[str]],
):
prompt = prompt_template.format(
splitter=SPLITTER,
near_rows="\n".join([SPLITTER.join(line) for line in near_cells_list]),
target_row=ocr_text,
)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=OPENAI_MODEL,
temperature=0.0,
messages=messages,
)
content: str = response["choices"][0]["message"]["content"] # type: ignore
estimated_result = content.split(SPLITTER)
print(content)
print(estimated_result)
return estimated_result
def revise_table(
x_list: List[int],
y_list: List[int],
response: Dict,
content: List[List[str]],
):
content_ = content.copy()
read_results = response["analyzeResult"]["readResults"][0]
# detect empty cell
for i_line, content_line in enumerate(content):
index_sets_empty_cell = detect_empty_cell_sets(content_line)
index_sets_empty_cell_filtered = [
index_set for index_set in index_sets_empty_cell if all([index < len(x_list) for index in index_set])
]
for index_set_empty in index_sets_empty_cell_filtered:
if len(index_set_empty) == 1: # 1つのセルが空の場合、今回の推定の対象外なので何もしない
print(f"WARNING: {i_line} {index_set_empty} cannot be estimated")
pass
else: # 2つ以上のセルが連続で空の場合、その座標に該当するOCRの認識結果をあてはめる
# 該当するOCRの認識結果を探す
line_ocr = search_bbox(x_list, y_list, i_line, read_results, index_set_empty)
if line_ocr is None: # その箇所をOCRが認識していなければ処理しない(できない)
continue
near_cells_list = extract_near_cell_values(content, i_line, index_set_empty)
ocr_text = line_ocr["text"]
estimated_cells = estimate_split_with_AI(ocr_text, near_cells_list)
if len(index_set_empty) != len(estimated_cells):
print(f"WARNING: {i_line} {index_set_empty} ignored")
for index, cell in zip(index_set_empty, estimated_cells):
content_[i_line][index] = cell
return content_
def main(
filepath_img: str,
filepath_ocr_json: str,
filepath_csv_input: str,
filepath_csv_output: str,
):
# 入力
img_fax_warped = cv2.imread(filepath_img)
with codecs.open(filepath_ocr_json, "r", encoding="utf8") as f:
response = json.load(f)
with open(filepath_csv_input, "r", encoding="utf8") as f:
reader = csv.reader(f)
content = [row for row in reader]
# 画像に写っている表の格子の座標を推定する
x_list, y_list = estimate_table_coords(img_fax_warped)
# 空のセルを推定する
content_revised = revise_table(x_list, y_list, response, content)
# 出力
with open(filepath_csv_output, mode="w", encoding="utf_8_sig") as f:
for line in content_revised:
f.write(",".join(line))
f.write("\n")
if __name__ == "__main__":
filepath_img = os.path.join(os.path.dirname(__file__), "fax.png")
filepath_ocr_json = os.path.join(os.path.dirname(__file__), "..", "output_read3.2.json")
filepath_csv_input = os.path.join(os.path.dirname(__file__), "..", "output.csv")
filepath_csv_output = os.path.join(os.path.dirname(__file__), "..", "output_rev.csv")
main(
filepath_img=filepath_img,
filepath_ocr_json=filepath_ocr_json,
filepath_csv_input=filepath_csv_input,
filepath_csv_output=filepath_csv_output,
)
結果
以下の空欄だった箇所を正しく埋めることができました。

残っている問題点と解決方法案
セルF5
画像の段階でセルの幅に収まらずに隠れてしまい、途中までしか認識できなかったケースのようです。「コンクリートブロッ」はおそらく「コンクリートブロック」が正しそうです。

このケースでは、文字がセルのいっぱいまで埋まっていると予想できるので、認識結果のbboxの幅とセルの幅とを比較し、割合が高ければ該当箇所と判定できそうです。

修正方法としては、以下のように「途切れてるようなので推定してください」とプロンプトを与えれば良さそうです。

仮に、もともと正しく認識できていた場合(「コンクリートブロッ”ク”」だった場合)はそのまま回答され、余計な単語をつけることがありませんでした。人間でも同様の回答をすると思われるので、これが良さそうです(逆にこれ以上の推測は人間でも難しそうです)。

セルA10
OCRで文字を認識できなかった(ので空欄になってしまった)ケースです。この場合は、そもそも文字を認識できていないので、手動で修正をする方がよさそうです。(OCRの設定や前処理を見直しもするべきでしょう。)
もし数が多い場合は、前後から文字列の推定だけしておいて、修正するユーザには候補として見せてあげることで、手打ちする必要が無いようにしてあげる(時間を短縮する)のが良いように思われます。
まとめ
OCRの認識ミスがあるという問題に対して、座標をもとに種類と箇所を特定し、LLMにプロンプトを実行させることで、手動で修正する箇所を減らすことができました。今回は1つの種類のミス(OCRが複数のセルをまとめて読み込んでしまう誤り)を修正する方法を考えましたが、他のミスも同様にAIに修正させる(推定させる)ことができそうです。
Appendix
今回は比較的簡単なミス(2つのマスのみ)だったのですが、これよりも難しいミスを想定して、いくつか試してみました。
一行まるごとミスした場合
仮にOCRが1行すべてをミスした場合を仮定して、AIで修正できるか試してみました。下のように、半角・全角スペースが入ってしまうミス、スペースがなくなってしまうミスが起きたような文字列を入力しました。
GPT-4での結果は下のとおりで、良い感じに推定してくれました。

- 「CMP 012」→「CMP012」
- 「建設あいうえお 株式会社」→「建設あいうえお株式会社」
- 時刻内の半角スペースは分割しない(正しい動作)
- 「5020」→「50,20」
(GPT-3.5では余計な出力が含まれてしまいました。GPT-3.5はコストを抑えられるのでできれば使用したいところですが、プロンプトを試行錯誤する必要がありそうです)

- 入力プロンプト
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように分割してください。各列の内容に合わせて分割してください。分割した結果のみ出力してください。 # 前後の行 1,CMP001,建設A株式会社,2023-06-30 12:30,MTL001,セメント,100,500,50000,処理中,, 3,CMP003,建設C株式会社,2023-06-30 13:30,MTL003,砂利,200,300,60000,処理中,, 4,CMP004,建設D株式会社,2023-06-30 14:00,MTL004,コンクリートブロッ,25,800,20000,キャンセル,, # 分割したい文字列 2 CMP 012 建設あいうえお 株式会社 2023-06-30 13:00 MTL002 鉄筋 5020 10000 出荷済み # 分割結果
改善方法
より複雑なケースやOCRの精度が出ない場合、各列の説明を別途用意しておき、プロンプトに加えると対応できることが予想されます。
- 入力プロンプトの例
OCRで複数のセルを文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように分割してください。各列の内容に合わせて分割してください。分割した結果のみ出力してください。 # 前後の行 1,CMP001 3,CMP003 4,CMP004 # 各列の内容 1列目:注文ID。形式は数値。 2列目:建設会社コード。形式はアルファベット3文字と数字3文字 # 分割したい文字列 2 CMP002 # 分割結果
これをChatGPT(Web)で実行したところ、GPT-4では意図通りの出力が得られました。

ただ、GPT-3.5では意図通りではない出力が得られてしまいました。モデルによっては情報を与えすぎると上手く動かすのが難しいかもしれません。このあたりは、実際のデータをもとに調整が必要そうです。











