
Vercel AI Gateway を OpenRouter ユーザーである私が触ってみた
はじめに
普段の開発で OpenRouter を使って Claude 系のモデルを呼び出していたのですが、 Vercel AI Gateway がどう違うのかを自分の手で確かめてみたくなり、同じプロンプトで両サービスを並べて触ってみました。
本記事は、 OpenRouter は触ったことがあるが Vercel AI Gateway は未経験という読者向けに、 2 つのサービスを並べて検証した結果をまとめます。優劣をつけるのではなく、何がどう違うのかを事実ベースで並べていきます。
Vercel AI Gateway とは
Vercel AI Gateway は、 Vercel が提供する AI モデル統合 API です。 Vercel AI SDK との連携に加え、 OpenAI Chat Completions 互換と Anthropic Messages 互換の両エンドポイントを公開し、 Vercel ダッシュボード上での観測機能を備えます。
OpenRouter とは
OpenRouter は、複数のプロバイダが公開する数百種類の AI モデルを単一の API で扱える統合ゲートウェイサービスです。 OpenAI Chat Completions 互換のエンドポイントを持ち、モデル単位のフォールバックやプロバイダ選択を 1 つのリクエストにまとめて記述できます。
検証環境
- 検証日時: 2026 年 5 月 1 日
- 使用モデル:
anthropic/claude-haiku-4.5(キャッシュ章ではanthropic/claude-sonnet-4.5も併用)
対象読者
- OpenRouter で Claude 系モデルを呼び出した経験があり、 Vercel AI Gateway を初めて触る開発者
- AI モデルゲートウェイの選定にあたって、レスポンス構造や観測機能の違いを把握しておきたい人
- 自社の監視基盤と AI 呼び出しの統合方針を検討している人
参考
- Vercel AI Gateway ドキュメント
- Vercel AI Gateway: Provider Options
- Vercel AI Gateway: Observability
- OpenRouter ドキュメント
- OpenRouter: Model Fallbacks
- OpenRouter: Input/Output Logging
基本的な Chat Completions 呼び出しは baseURL の差し替えだけで試せる
最初に分かったのは、基本的な Chat Completions 呼び出しに限れば、既存の OpenRouter クライアントを Vercel AI Gateway へ向けるのに必要な変更が少ないことです。両サービスとも OpenAI Chat Completions 互換のエンドポイントを公開しており、認証ヘッダはどちらも Authorization: Bearer <token> です。
実際に GET /v1/models を叩いて Claude 系モデルの ID を比較すると、 12 種類のモデル ID が両サービスに共通して存在しました。たとえば本記事で採用した anthropic/claude-haiku-4.5 は、 Vercel 側でも OpenRouter 側でも同じ ID で呼び出せます。
OpenAI 互換 SDK で書く場合、 baseURL を入れ替えるだけで切り替えられます。
import OpenAI from 'openai';
// Vercel AI Gateway 向け
const vercelClient = new OpenAI({
apiKey: process.env.AI_GATEWAY_API_KEY,
baseURL: 'https://ai-gateway.vercel.sh/v1',
});
// OpenRouter 向け
const openrouterClient = new OpenAI({
apiKey: process.env.OPENROUTER_API_KEY,
baseURL: 'https://openrouter.ai/api/v1',
});
Vercel AI SDK の場合は、文字列でモデルを指定するだけで AI Gateway が既定のプロバイダになります。 AI_GATEWAY_API_KEY を環境変数に置いておけば、追加のクライアント設定は不要です。
import { generateText } from 'ai';
const { text } = await generateText({
model: 'anthropic/claude-haiku-4.5',
prompt: 'Reply with exactly: ok',
});
レスポンスメタデータの構造差
クライアントの差はほぼないのですが、レスポンスの中身を読むと両サービスの違いがはっきり出てきます。同じプロンプト、同じモデル、同じパラメータで送ったときに目立つ差は以下の 3 点でした。
■ 採用プロバイダの表示
Vercel: choices[0].message.provider_metadata.gateway.routing.resolvedProvider
OpenRouter: トップレベルの provider フィールド
■ choices[0].message の追加フィールド
Vercel: provider_metadata.{anthropic, gateway} を同梱
OpenRouter: refusal, reasoning を持ち choices[0].native_finish_reason も並記
■ usage のキャッシュ系フィールド
Vercel: cache_creation_input_tokens と market_cost が直下に並ぶ
OpenRouter: 上記は持たず prompt_tokens_details.cache_write_tokens を持つ
Vercel は OpenAI 互換の標準的な形を保ちつつ、採用プロバイダや routing の詳細を choices[0].message.provider_metadata.gateway 配下に集約します。一方の OpenRouter は、採用プロバイダをトップレベルの provider フィールドで示します。 usage 直下に cost や cost_details を入れる構造は両サービスで似通っています。移行で取得経路を変えるべき箇所は採用プロバイダ名周りが中心です。
routing メタデータがレスポンスに常時同梱される
Vercel 側で気がついたのは、すべてのレスポンスに routing メタデータが入っている点です。フォールバックを発火させなくても、 provider_metadata.gateway.routing の中に originalModelId, resolvedProvider, fallbacksAvailable, planningReasoning, modelAttempts が毎回含まれて返ってきます。たとえば今回の検証では anthropic/claude-haiku-4.5 の呼び出しに対して、利用可能なフォールバック候補が ["bedrock", "vertexAnthropic"] であること、最終的に anthropic 直接ルートで成功したこと、プロバイダ試行は 1 回で完了したことが、 1 回のレスポンスから読み取れました。
Vercel AI Gateway の provider_metadata.gateway 全文
{
"routing": {
"originalModelId": "anthropic/claude-haiku-4.5",
"resolvedProvider": "anthropic",
"resolvedProviderApiModelId": "claude-haiku-4-5-20251001",
"fallbacksAvailable": ["bedrock", "vertexAnthropic"],
"planningReasoning": "System credentials planned for: anthropic, bedrock, vertexAnthropic. Total execution order: anthropic(system) → bedrock(system) → vertexAnthropic(system)",
"canonicalSlug": "anthropic/claude-haiku-4.5",
"finalProvider": "anthropic",
"modelAttemptCount": 1,
"modelAttempts": [
{
"modelId": "anthropic:claude-haiku-4-5-20251001",
"canonicalSlug": "anthropic/claude-haiku-4.5",
"success": true,
"providerAttemptCount": 1,
"providerAttempts": [
{
"provider": "anthropic",
"providerApiModelId": "claude-haiku-4-5-20251001",
"credentialType": "system",
"success": true,
"startTime": 3274894.19934,
"endTime": 3275274.606483,
"providerRequestId": "req_011XXXXXXXXXXXXXXXXXXXXX",
"statusCode": 200,
"providerResponseId": "msg_01XXXXXXXXXXXXXXXXXXXXX"
}
]
}
],
"totalProviderAttemptCount": 1
},
"cost": "0.000087",
"marketCost": "0.000087",
"inferenceCost": "0.000087",
"inputInferenceCost": "0.000022",
"outputInferenceCost": "0.000065",
"generationId": "gen_01XXXXXXXXXXXXXXXXXXXXXXXX"
}
ストリーミングで受信した場合も、最終チャンクの delta.provider_metadata に同じ構造が入って届きます。 routing 情報を取り出すために別エンドポイントへ問い合わせる必要はありません。
一方、OpenRouter のレスポンスでは、採用プロバイダ自体は provider フィールドで確認できますが、フォールバック候補や試行履歴はレスポンスから見えません。フォールバックが発火した場合に限り、レスポンスの model フィールドが実際に採用されたモデル名に変わる動きです。
キャッシュは層が違う
両サービスとも 「キャッシュ機能」 を持っていますが、実体は異なります。
Vercel AI Gateway には、現時点の公式ドキュメントの範囲ではゲートウェイ層でレスポンスを丸ごと保持するキャッシュは見当たりません。代わりに、 Anthropic などプロバイダが提供するプロンプトキャッシュを透過利用する設計です。 providerOptions.gateway.caching: 'auto' を指定すると、 Anthropic や MiniMax のように明示的なキャッシュマーカーが必要なプロバイダに対して、 AI Gateway が静的コンテンツの末尾に cache_control を自動で挿入します。
実際に Anthropic Messages 互換エンドポイントに system: [{ type: 'text', text: <長文>, cache_control: { type: 'ephemeral' } }] を送ったところ、 claude-sonnet-4.5 では 1 回目のレスポンスに cache_creation_input_tokens: 3,202 が返り、 Anthropic 側でキャッシュ書き込みが行われたことを確認できました。一方、続けて同じプロンプトを送った 2 回目でも cache_creation_input_tokens: 3,202 のままで cache_read_input_tokens は 0、つまり読み出しは観測できませんでした。今回の検証だけでは原因を特定できていませんが、 cache_control の指定箇所、リクエスト内容の差分、プロバイダ側のキャッシュ条件、 AI Gateway のルーティング経路などが影響している可能性があります。
一方で、OpenRouter は X-OpenRouter-Cache: true ヘッダで有効化できるゲートウェイ層のレスポンスキャッシュを備えています。キャッシュキーは API キー、モデル、エンドポイント種別、ストリーミングの有無、リクエストボディの SHA-256 ハッシュから組み立てられ、既定 5 分 (X-OpenRouter-Cache-TTL で 1 秒から 86,400 秒まで調整可能) の間は同じリクエストに対して応答を即時に返します。
検証では claude-haiku-4.5 への同一リクエストで、 1 回目が 1,127 ms、 2 回目が 33 ms に短縮されました。キャッシュヒット時はトークン消費 0、課金 0 で記録されます。
検証から見えてきたのは、 Vercel AI Gateway はプロバイダのキャッシュを通す役割を担っているのに対し、 OpenRouter には 「同じリクエストが繰り返し届くケース」 でゲートウェイがそのままキャッシュを返す経路があるという違いです。アプリ側でレスポンスを丸ごとキャッシュしたい場合は、 Vercel ではキャッシュ層を別に用意することになります。
ダッシュボードでわかること
両サービスではダッシュボードで観測できる情報も異なります。
| 情報 | Vercel | OpenRouter |
|---|---|---|
| 時系列グラフ | Usage (Spend by Model、 P50 TTFT by Model、 Requests by Model、 All Tokens) | Activity (Spend、 Requests、 Tokens) |
| API キー別の集計 | Requests の API キー別ビュー | Logs ページのフィルタで対応 |
| プロジェクト別の集計 | Requests のプロジェクト別ビュー | 非対応 |
| 個別ログとリクエスト詳細 | Requests の個別ログ | Logs ページと詳細ビュー (プロンプトと補完の中身は Observability で入出力ロギングを ON にすると表示) |
Vercel AI Gateway のダッシュボード
Vercel ダッシュボードの AI Gateway タブには Usage と Requests の 2 つのビューがあります。 Usage には Spend by Model、 P50 TTFT by Model、 Requests by Model、 All Tokens の 4 種のグラフが並びます。
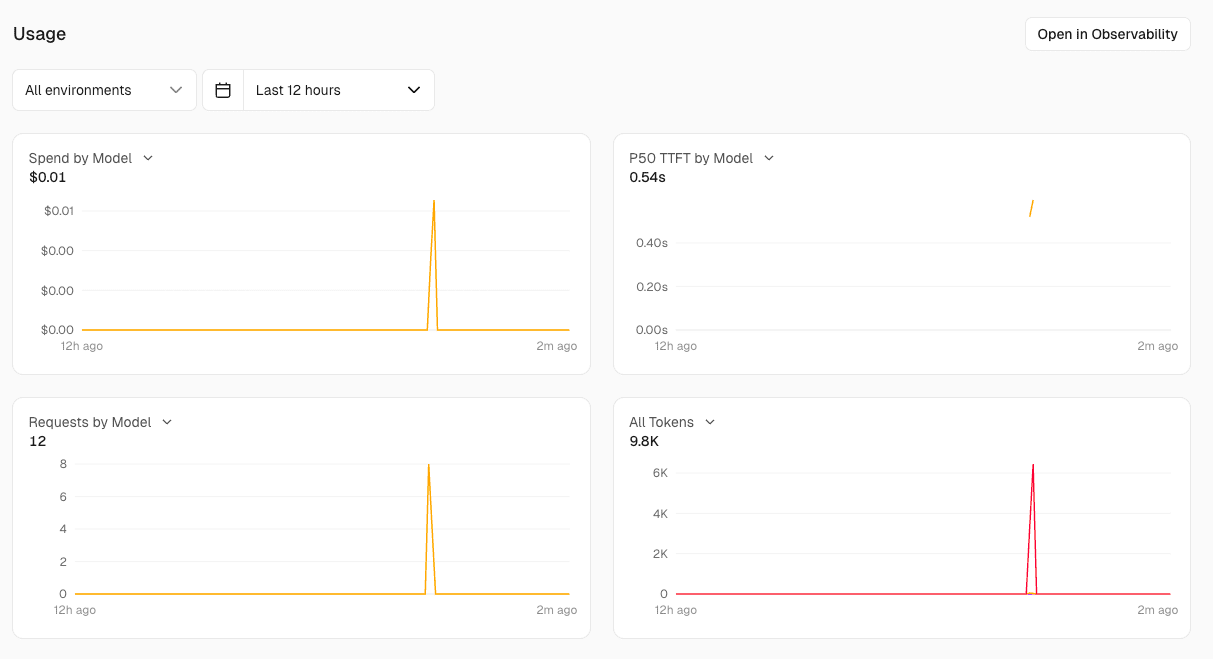
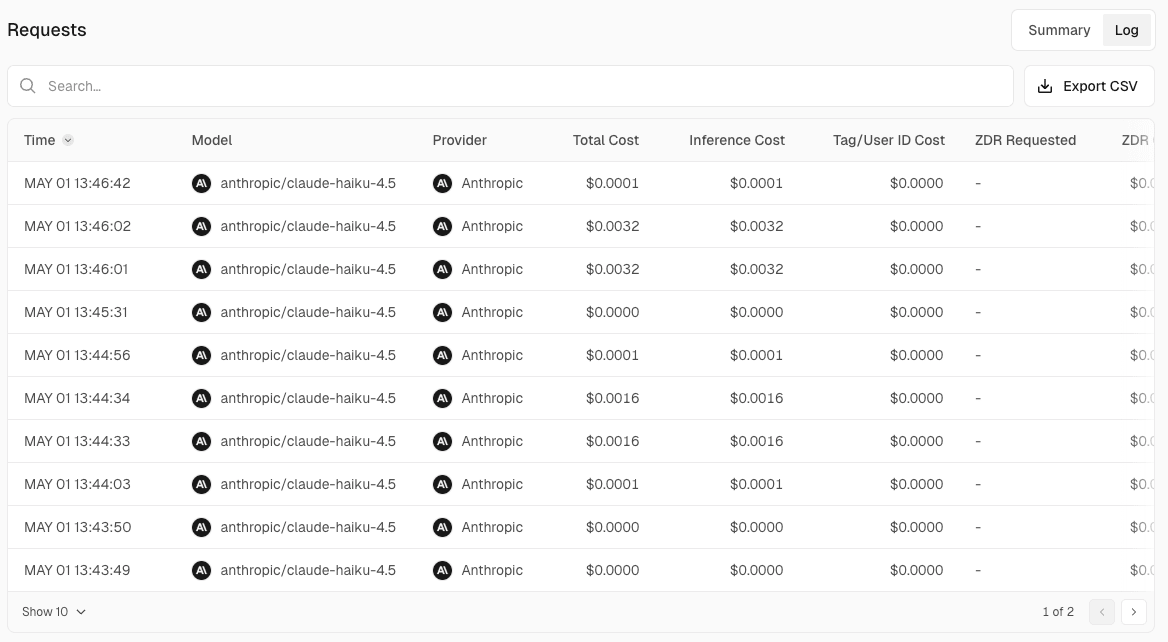
Requests ビューでは、プロジェクト別、 API キー別、個別ログの 3 種の切り口でリクエストを掘り下げられます。
■ プロジェクト別
■ API キー別
■ 個別ログ
OpenRouter のダッシュボード
OpenRouter の Activity ページでは、 Spend、 Requests、 Tokens の 3 種のグラフが並びます。
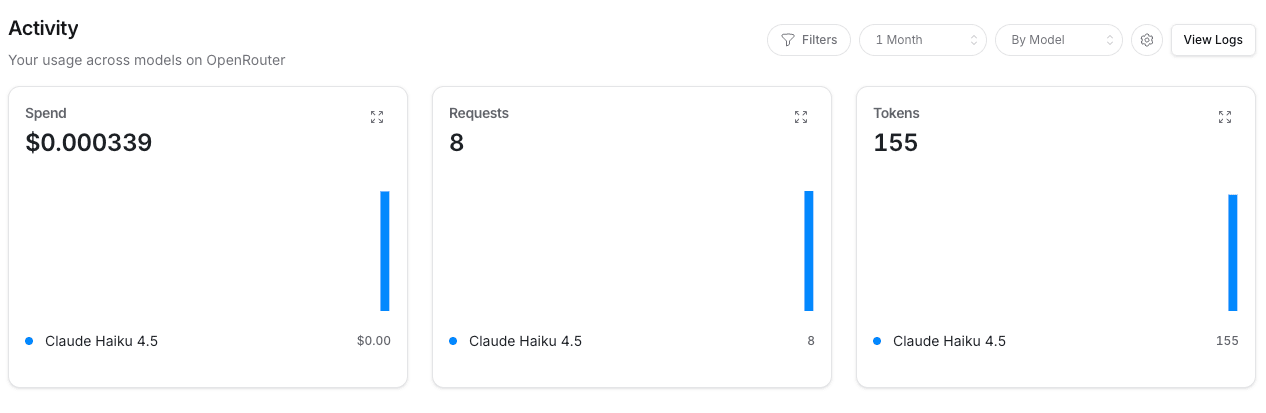
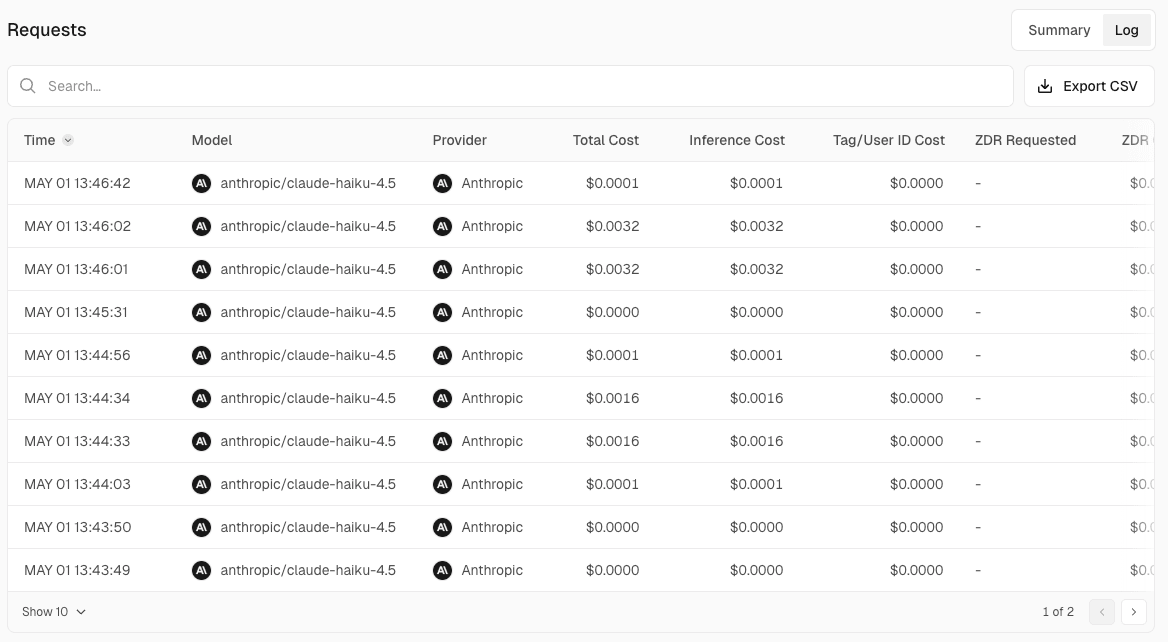
Logs ページではリクエスト一覧を確認できます。モデル、プロバイダ、トークン数、コストなどが行単位で並びます。
各リクエストをクリックするとプロンプトと補完の中身を確認できます。
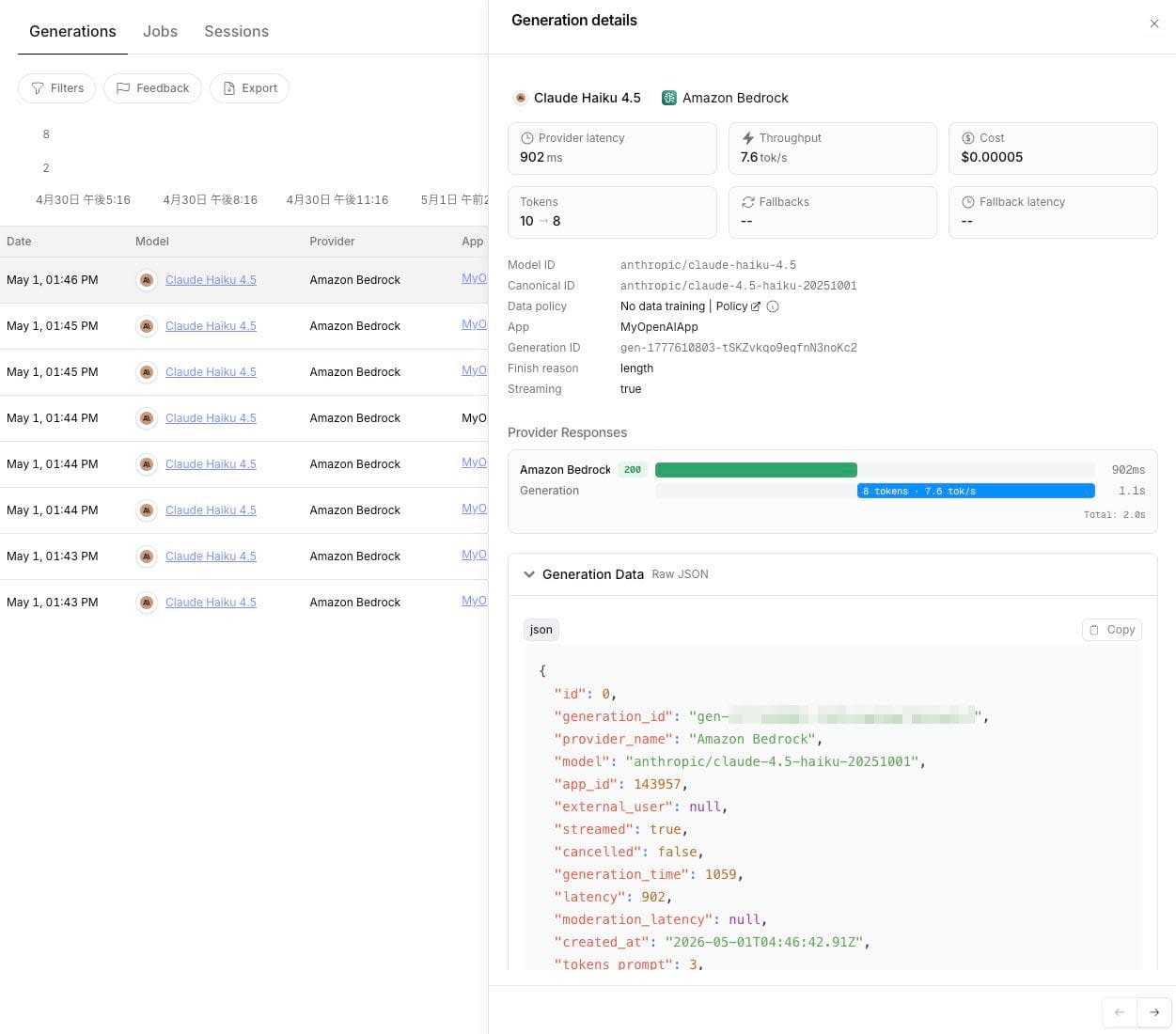
ただし入出力ロギングは既定で無効化されており、 Observability から明示的にトグルする必要があります。

おわりに
OpenRouter を使ってきた立場で Vercel AI Gateway を触ってみると、観測情報の置き場所とキャッシュの担当層が両サービスではっきり違うことが見えました。 Vercel は routing メタデータをレスポンスに常時同梱しダッシュボードを Vercel プロジェクト体系に統合する一方、 OpenRouter は usage.cost や cost_details.upstream_inference_* をトップレベルに展開し、ゲートウェイ層のレスポンスキャッシュや外部観測ツールへの broadcast を備えています。
どちらが良いかではなく、観測情報をどこから取りたいか、キャッシュをどの層で持ちたいか、どの監視基盤と統合したいかで選び分けるのが現実的だと感じます。手元のコードを Vercel AI Gateway へ向け直す手間は baseURL の差し替えだけで済むため、まず触って違いを確認するのがおすすめです。










