OpenAIがリリースした音声認識モデル”Whisper”の使い方をまとめてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部 機械学習チームの中村です。
OpenAIがリリースしたWhisperについて、先日は以下の紹介記事を書きました。
今回はもう少し深堀することで、様々な使い方がわかってきたのでシェアしたいと思います。
Whisperでできること
APIを使ってできるのは以下になります。
- transcribe(書き起こし処理)
- 音声からの文字書き起こし。
- 99言語に対応
- translate(書き起こし + 翻訳)
- 音声からの翻訳処理。
- 入力は多言語に対応していますが、出力は英語のみ。
また内包される機能として、言語判定や有音無音判定(VAD:Voice Activation Detector)があります。
この記事ではそれぞれの使い方を見ていきながら、transcribeの詳細に迫ります。
実行環境
ハードウェアなどの主な情報は以下の通りです。
- GPU: Tesla P100 (GPUメモリ16GB搭載)
- CUDA: 11.1
- メモリ: 26GB(ハイメモリタイプ)
主なライブラリのバージョンは以下となります。
- transformers: 4.22.1
- whisper: 1.0
使用するデータ
前回同様、ソースは社内の勉強会で自身が発話したデータを用います。
そのうち、30秒を切り出した音声データ(audio_sample.wavとする)や、動画全体(video_full.mp4とする)を入力として使用してみます。
切り出し方法については、前回の記事を参照ください。
使い方サンプル
準備
whisperのインストールをします。
!pip install git+https://github.com/openai/whisper.git
インポートします。
import whisper
モデルはlargeをロードしておきます。
model = whisper.load_model("large")
transcribe
音声からの文字書き起こしが可能です。99言語に対応しています。 処理は30秒あたり約8秒で終わります。
- コード
result = model.transcribe("audio_sample.wav")
print(result["text"])
- 出力
初めにがすごい余談なので 少し飛ばしましょうかねいろいろしてますけど 16時間物を食べないっていうのを最近やってますっていう話です 興味あったら見ておいてくださいちょっと木地の方は 前回から日が空いてるので 前回のおさらいの方
途中の処理過程のログを出すにはverbose=Trueを設定します。
- コード
result = model.transcribe("audio_sample.wav", verbose=True)
print(result["text"])
- 出力
Detecting language using up to the first 30 seconds. Use
--languageto specify the language
Detected language: Japanese
[00:00.000 --> 00:09.000] 初めにがすごい余談なので 少し飛ばしましょうかね
[00:09.000 --> 00:15.000] いろいろしてますけど 16時間物を食べないっていうのを
[00:15.000 --> 00:21.000] 最近やってますっていう話です 興味あったら見ておいてください
[00:21.000 --> 00:30.000] ちょっと木地の方は 前回から日が空いてるので 前回のおさらいの方
初めにがすごい余談なので 少し飛ばしましょうかねいろいろしてますけど 16時間物を食べないっていうのを最近やってますっていう話です 興味あったら見ておいてくださいちょっと木地の方は 前回から日が空いてるので 前回のおさらいの方
このように、まず言語判定が表示され、その後セグメント毎の書き起こし結果が出力されます。
また、言語を指定すれば、内部の言語判定がスキップされますのでその分ほんの少しだけ高速となります。(約7秒)
- コード
result = model.transcribe("audio_sample.wav", verbose=True, language="ja")
print(result["text"])
- 出力
[00:00.000 --> 00:09.000] 初めにがすごい余談なので 少し飛ばしましょうかね
[00:09.000 --> 00:15.000] いろいろしてますけど 16時間物を食べないっていうのを
[00:15.000 --> 00:21.000] 最近やってますっていう話です 興味あったら見ておいてください
[00:21.000 --> 00:30.000] ちょっと木地の方は 前回から日が空いてるので 前回のおさらいの方
初めにがすごい余談なので 少し飛ばしましょうかねいろいろしてますけど 16時間物を食べないっていうのを最近やってますっていう話です 興味あったら見ておいてくださいちょっと木地の方は 前回から日が空いてるので 前回のおさらいの方
ログ出力からも言語判定をスキップしていることが分かります。
言語判定を自動で実行する場合は、冒頭30秒区間のみが言語判定に使用されますので、頭に無音がある場合などは正常に言語判定ができなくなります。 そのため、発話言語が決まっているシーンではできるだけ言語を指定した方が良さそうです。(処理時間的にもメリットがあります)
translate
次にtranslateを見ていきます。
translateも書き起こし+翻訳の機能となるので、モデルとしてはtranscribeメソッドで処理し、引数にtask=translateを指定します。
- コード
result = model.transcribe("audio_sample.wav", verbose=True, language="ja", task="translate")
print(result["text"])
- 出力
[00:00.000 --> 00:09.000] I'm going to skip the first part because it's a bit of a foreshadowing.
[00:09.000 --> 00:18.000] I've been doing a lot of things lately, but I've been doing something called eating for 16 hours.
[00:18.000 --> 00:21.000] If you're interested, please take a look.
[00:21.000 --> 00:30.000] The wood is open from the last time, so I'll show you the last review.
I'm going to skip the first part because it's a bit of a foreshadowing. I've been doing a lot of things lately, but I've been doing something called eating for 16 hours. If you're interested, please take a look. The wood is open from the last time, so I'll show you the last review.
内容自体は少し意図と違うニュアンスになっている部分がありそうですが、口語調のため難しい部分があるのかもしれません。
長いデータの処理
次に動画全体の処理をやってみます。
- コード
result = model.transcribe("video_full.mp4", verbose=True, language="ja")
- 出力
[00:05.400 --> 00:06.900] 画面共有
[00:24.400 --> 00:26.300] 画面見えてますでしょうか
[00:27.800 --> 00:28.600] こっちか
[00:28.600 --> 00:30.600] はい、見えてます
[00:30.600 --> 00:32.600] ありがとうございます
[00:36.600 --> 00:40.600] NNアーキテクチャ勉強会ということで
[00:40.600 --> 00:42.600] 物体検出編
[00:42.600 --> 00:47.600] ちょっと前回3月の16日だったかな
[00:47.600 --> 00:50.600] そこでやった続きということで
[00:50.600 --> 00:55.600] 今回は物体検出の方をやっていきます
[00:55.600 --> 00:59.600] スレッドとかあるのかな
[01:01.600 --> 01:02.600] ないかな
[01:04.600 --> 01:05.600] 作ります
[01:05.600 --> 01:07.600] ありがとうございます
[01:13.600 --> 01:16.600] はじめにがすごい余談なので
[01:16.600 --> 01:18.600] ちょっと飛ばしましょうかね
[01:19.600 --> 01:21.600] ちょっといろいろしてますけど
[01:21.600 --> 01:24.600] 16時間ものを食べないっていうのを
[01:24.600 --> 01:28.600] 最近やってますっていう話です
[01:28.600 --> 01:30.600] 興味あったら見ておいてください
[01:34.600 --> 01:37.600] ちょっと目次の方は
[01:37.600 --> 01:38.600] 前回から日が空いてるので
[01:38.600 --> 01:43.600] 前回のおさらいの方をまずやっていきます
[01:43.600 --> 01:47.600] で、物体検出の仕組みを説明して
...
[44:32.600 --> 44:42.600] では他になければ
[44:42.600 --> 44:49.600] 勉強会の方これで終わりたいと思います
[44:49.600 --> 44:55.600] 本日ありがとうございました
[44:55.600 --> 44:58.600] ありがとうございました
[44:58.600 --> 45:02.600] ありがとうございました
実際に試されたい方は是非、ご自分のデータソースを準備してみてください。
処理自体は45分の動画でしたが、処理は13分程度で終わりとても高速に処理されています。
また、実際に流して頂けると分かりますが、約30秒単位でログが出力されていることが分かります。
これは以降で解説しますが、transcribe内部ではWhisperの処理単位が30秒となっているためです。
transcribeの流れ
おおむね以下のフローで実行されます。
- 音響的な特徴量への変換
log_mel_spectrogramで対数メルスペクトログラムを計算します。- 最終的には80次元の特徴量が10msec単位の特徴量となります。
- ファイル全体を一気にバッチ処理します。
- 言語判定の実施(言語指定がない場合)
model.detect_languageで判定します。- 先頭30秒分の特徴量を使います。
- 30秒以下の場合はpaddingされます。
- 特徴量を30秒単位で処理
model.decodeでデコードします。
- デコード結果の有音無音判定
- 無音判定では、デコード結果の
no_speech_probとno_speech_thresholdを比較します。 - 有音判定では、デコード結果の
avg_logprobとlogprob_thresholdを比較します。 - 無音でなく、有音であった場合のみ、スキップせず以降を処理します。
- 無音判定では、デコード結果の
- デコード結果をタイムスタンプトークンで分割
- デコード結果にはセグメントの前後にタイムスタンプトークンが入ります。
- セグメントの途中で30秒の切れ目がきている場合は次の処理に回されます。
- セグメント毎にtokenizerでデコード
- 結果を格納し、3.に戻ってループ処理
処理単位については少し分かりにくいので図を起こしました。

このように、30秒単位で切り出してデコードをします。
デコード結果には、タイムスタンプトークンが出力されます。
そして、この区間の最後のタイムスタンプトークンを基準に30秒間が次のデコード対象として切り出されます。
応用編
これらを理解したうえで応用的な使い方を探っていきます。
言語判定のみを動作させる
特徴量計算から必要ですので、以下のようにコードを切り出せば、単体の実行が可能です。
- コード
import torch
from whisper.audio import N_FRAMES, pad_or_trim, log_mel_spectrogram
# 音響特徴量の計算
mel = log_mel_spectrogram("audio_sample.wav")
# 30秒データに整形
segment = pad_or_trim(mel, N_FRAMES).to(model.device).to(torch.float16)
# 判定
_, probs = model.detect_language(segment)
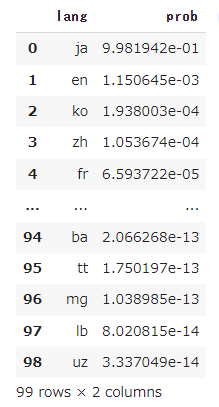
結果は、各言語毎の確率としてprobsが得られます。データフレームにして確認してみます。
- コード
import pandas as pd
pd.DataFrame([{"lang": k, "prob": v} for k, v in probs.items()])\
.sort_values(['prob'], ascending=False)
- 結果
VADの結果確認
VADは単体では行えないのですが、model.decodeにより書き起こし結果とともに得られます。
- コード
import torch
from whisper.audio import N_FRAMES, pad_or_trim, log_mel_spectrogram
# 音響特徴量の計算
mel = log_mel_spectrogram("audio_sample.wav")
# 30秒データに整形
segment = pad_or_trim(mel, N_FRAMES).to(model.device).to(torch.float16)
# デコード
result = model.decode(segment)
resultの中身は、以下のようになっています。
DecodingResult(audio_features=tensor([[-3.9990e-01, -1.1309e+00, -3.9453e-01, ..., 1.2617e+00,
3.4497e-01, -1.0088e+00],
[ 4.5142e-01, -1.1318e+00, -8.5596e-01, ..., 1.0674e+00,
1.6016e+00, -1.1191e+00],
[ 9.3750e-01, -1.8936e+00, -5.4834e-01, ..., 8.7280e-02,
1.2803e+00, -9.2090e-01],
...,
[-1.4541e+00, -8.4229e-01, 7.1289e-01, ..., -3.7744e-01,
4.7192e-01, 4.3579e-01],
[-1.6963e+00, -5.6201e-01, -1.7725e+00, ..., 5.4092e-03,
6.8408e-01, 3.8428e-01],
[-9.5312e-01, 2.1708e-04, -1.8643e+00, ..., 1.0469e+00,
5.2490e-01, 1.0684e+00]], device='cuda:0', dtype=torch.float16), language='ja', language_probs=None, tokens=[50364, 28727, 11429, 4108, 5142, 34161, 1593, 247, 48022, 47275, 220, 15686, 2849, 34629, 13349, 2849, 26513, 3703, 5555, 50814, 50814, 1764, 12488, 1764, 12488, 8822, 5368, 21891, 3165, 20788, 23516, 5998, 50067, 9311, 46896, 2972, 5998, 51114, 51114, 46777, 31497, 5368, 46896, 11103, 4767, 220, 44089, 17268, 3590, 10102, 5154, 33363, 6117, 18549, 25079, 51414, 51614], text='初めにがすごい余談なので 少し飛ばしましょうかねいろいろしてますけど 16時間物を食べないっていうのを最近やってますっていう話です 興味あったら見ておいてください', avg_logprob=-0.34457703294425174, no_speech_prob=0.041390493512153625, temperature=0.0, compression_ratio=0.48502994011976047)
avg_logprobが有音らしさ、no_speech_probが無音らしさを表現しています。
デフォルトの閾値はそれぞれlogprob_threshold=-1.0、no_speech_threshold=0.6となっており、これらの判断により30秒毎の有音・無音判定が行えます。
transcribeのメソッドでは以下のような条件で使われています。
if no_speech_threshold is not None:
# no voice activity check
should_skip = result.no_speech_prob > no_speech_threshold
if logprob_threshold is not None and result.avg_logprob > logprob_threshold:
# don't skip if the logprob is high enough, despite the no_speech_prob
should_skip = False
if should_skip:
seek += segment.shape[-1] # fast-forward to the next segment boundary
continue
トークナイザでデコードしてみる
model.decodeの処理結果のresult.tokensにトークンが入っているため、トークナイザでデコードしてみます。
- コード
import torch
from whisper.audio import N_FRAMES, pad_or_trim, log_mel_spectrogram
from whisper.tokenizer import get_tokenizer
# 音響特徴量の計算
mel = log_mel_spectrogram("audio_sample.wav")
# 30秒データに整形
segment = pad_or_trim(mel, N_FRAMES).to(model.device).to(torch.float16)
# デコード
result = model.decode(segment)
# トークナイザ取得
tokenizer = get_tokenizer(multilingual=True, language="ja", task="transcribe")
# トークナイザのデコード
tokenizer.decode(result.tokens)
- 出力
初めにがすごい余談なので 少し飛ばしましょうかねいろいろしてますけど 16時間物を食べないっていうのを最近やってますっていう話です 興味あったら見ておいてください
また、タイムスタンプトークンを表示したい場合は、以下で得ることができます。
- コード
# トークナイザのデコード(タイムスタンプトークン付き) tokenizer.decode_with_timestamps(result.tokens)
- 出力
<|0.00|>初めにがすごい余談なので 少し飛ばしましょうかね<|9.00|><|9.00|>いろいろしてますけど 16時間物を食べないっていうのを<|15.00|><|15.00|>最近やってますっていう話です 興味あったら見ておいてください<|21.00|><|25.00|>"
一つ一つのトークンをデコードすることももちろん可能です。データフレームにしてそのデコード結果を可視化してみます。
- コード
pd.DataFrame([
result.tokens,
[tokenizer.decode_with_timestamps([t]) for t in result.tokens]
], index=["tokens", "decode"]).T
- 出力
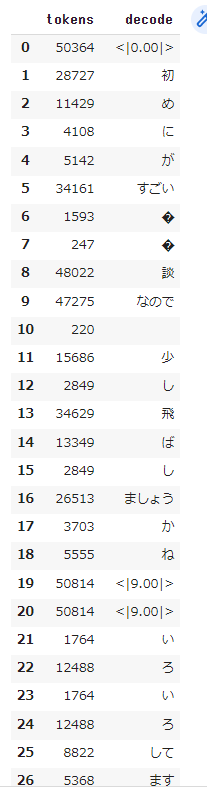
一部そのまま日本語に戻せないトークンがありますが、おおむねどの単位でトークンが出力されているか確認できます。
<|0.00|>などで表記されているのがタイムスタンプトークンになります。
これらのタイムスタンプトークンは、セグメントの開始と終了を表しており、発話が無い区間も分かるようになっています。
無音が多い区間の結果をサンプルで記載しておきます。
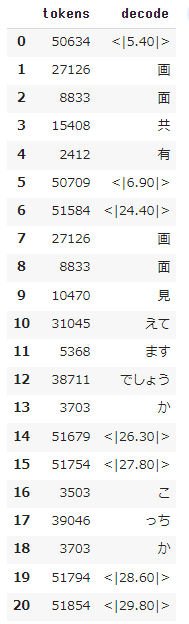
実際これらの発話区間の情報は、model.transcribeでも取得することができ、戻り値に入っているstart、endに格納されているものと同じものです。
まとめ
いかがでしたでしょうか。
様々なサービスと組み合わせる場合は、transcribeの中身をある程度理解しておいた方が応用先が広がると考えて今回調査してみました。
本記事がwhisperを活用してみようと思われる方の参考になれば幸いです。









