![[新機能] Amazon Redshift Federated QueryがGAになったので試してみました](https://devio2023-media.developers.io/wp-content/uploads/2019/05/amazon-redshift.png)
[新機能] Amazon Redshift Federated QueryがGAになったので試してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
昨年のre:Invent2019で発表されたAmazon RedshiftのFederated QueryがGA(Generally Available:正式リリース)になりました!クラスタバージョン1.0.14677から利用可能なので早速試してみました。
Amazon Redshift Federated Querying is Now Available!
1⃣What's New - https://t.co/dbZjTSTX2z
2⃣Use Cases - https://t.co/y8NS5JaMhC
3⃣Getting Started Using CloudFormation - https://t.co/Pz9wmqK29d pic.twitter.com/ghi8O9m6JS
— Jeff Barr ☁️ (@ ? ) (@jeffbarr) April 16, 2020
Amazon Redshift の Federated Queryとは
RDSとAurora PostgreSQLのテーブルにRedshiftから直接アクセスできるようになりました。いわゆる、RedshiftからPostgreSQLに対してデータベースリンクする機能です。
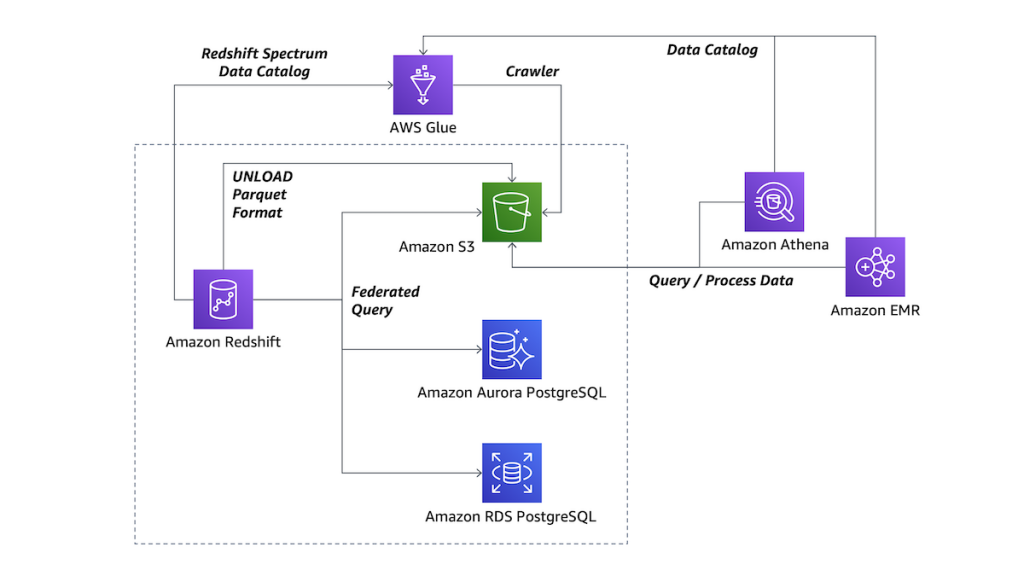
Federated Queryの特長
RedshiftによるPostgreSQLのデータ統合
Federated Queryを用いることで、Amazon RDS for PostgreSQLまたはAmazon Aurora with PostgreSQL compatibilityとデータを連携できます。これまで、Redshift/Redshift SpectrumのデータとPostgreSQL上のデータと組み合わせて分析するには、PostgreSQLのデータをS3経由でRedshiftにロードする必要がありました。これからはRedshiftからPostgreSQL内に保持するデータとRedshift/Redshift Spectrumのデータをクエリで統合できるようになります。
Federated Queryを使用して、OLTPのライブデータをビジネスインテリジェンス(BI)およびレポートアプリケーションの一部として組み込むことができます。例えば、以下のようなユースケースがあります。
- RedshiftからOLTP用途の基幹データベースを直接クエリできる
- RedshiftでOLTP用途のデータの変換をすばやく適用できます
- ETLなしでOLTP用途のデータを直接Redshiftのターゲットテーブルに読み込めます
RDS/Aurora PostgreSQLによる並列分散
Federated Queryは、単純なデータベースリンクではなく、クエリの一部をPostgreSQL上で実行して処理負荷を分散、結果のみを送り返すことネットワーク上のデータ移動を減らしてパフォーマンスを向上させます。
Federated Queryを実行すると、RedshiftのリーダーノードからPostgreSQLのDBインスタンスへのクライアント接続を作成して、テーブルメタデータを取得します。Redshiftのコンピュートノードは、プリディケイトプッシュダウンされたサブクエリを発行し、結果のレコードを取得します。取得した結果のレコードはコンピュートノード間で分散して処理します。
Federated Queryの導入
導入の流れ
RedshiftからRDSまたはAurora PostgreSQLへ接続するための認証情報は、Secrets Managerのシークレットを用います。そのため、シークレットを作成して、Redshiftがシークレットを参照するためのIAMロールをRedshiftに付与します。あとは、RedshiftからRDSまたはAurora PostgreSQLへの外部スキーマを作成して完了です。もちろん、RedshiftからターゲットとなるRDSまたはAurora PostgreSQLへ接続するためのネットワークやセキュリティグループも設定してください。
0.導入環境
今回導入した環境はバージニア(us-east-1)のパブリックサブネットにあるRedshift(クラスタバージョン1.0.14677)とRDS PostgreSQL(エンジンバージョン11.5)間でFederated Queryを試しました。
検証に用いるデータは、AWS Redshift用のサンプルデータベースのデータです。色々と組み合わせを試したかったので、RedshiftとPostgreSQLにtickitスキーマとテーブルを準備しました。

- Redshift
- データベース名:cm-redshiftdb
- スキーマ名:tickit
- 外部スキーマ名:pg
- RDS PostgreSQL
- データベース名:rdspg
- スキーマ名:tickit
1.セキュリティグループの設定(落とし穴)
RedshiftからターゲットとなるRDS PostgreSQLへ接続できるようにセキュリティグループの設定が必要です。Redshiftは、ノードIPアドレスのパブリックIPアドレスからRDS PostgreSQLに接続します。そのため、RDS PostgreSQLのセキュリティグループにこれらのIPアドレス全てを指定します。ノードIPアドレスのパブリックIPアドレスは、クラスタの一覧からクラスタ名を選択した後、[プロパティ]タブの「接続状態の詳細」を開くと参照できます。

VPCのCIDRを全て許可したり、Redshiftのセキュリティグループを指定してもダメでした。マニュアルにも記載がなく、私はこれで一日潰しました。
2.PostgreSQLへ接続するシークレット(認証情報)の作成
RedshiftからRDSまたはAurora PostgreSQLへ接続するには、Secrets Managerにシークレット(認証情報)を登録します。(登録方法は、機密管理サービス AWS Secrets Manager で RDS のパスワードローテーションを試すをご覧ください)

3.AWS Secrets Managerを利用できるIAMロールを作成
Secrets Managerを利用するためのRedshiftのIAMロール(Secrets Manager)を作成します。Resourceにシークレットのarnを指定しています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessSecret",
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": "arn:aws:secretsmanager:us-east-1:123456789012:secret:tickit-zLrq7N"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"secretsmanager:GetRandomPassword",
"secretsmanager:ListSecrets"
],
"Resource": "*"
}
]
}
4.IAMロールをRedshiftに付与
上記のIAMロールをRedshiftに適用することで、シークレット(認証情報)を用いて、ターゲットとなるRDSまたはAurora PostgreSQLに接続できるようになります。

5.外部スキーマの作成
RedshiftからRDS PostgreSQLデータベースに接続するには、RedshiftにRDS PostgreSQLのスキーマに対する外部スキーマを作成します。
- 作成する外部スキーマ名:
pg - 接続するサービス:
POSTGRES - 接続先のデータベース:
rdspg - 接続先のスキーマ:
tickit - 接続先のURL:
arn:aws:iam::123456789012:role/redshift-federated-query-role - シークレット(認証情報)のARN:
arn:aws:secretsmanager:us-east-1:123456789012:secret:tickit-zLrq7N
cm-redshiftdb=# CREATE EXTERNAL SCHEMA pg cm-redshiftdb-# FROM POSTGRES cm-redshiftdb-# DATABASE 'rdspg' cm-redshiftdb-# SCHEMA 'tickit' cm-redshiftdb-# URI 'rdspg.ct6wtpooxxxx.us-east-1.rds.amazonaws.com' cm-redshiftdb-# PORT 5432 cm-redshiftdb-# IAM_ROLE 'arn:aws:iam::123456789012:role/redshift-federated-query-role' cm-redshiftdb-# SECRET_ARN 'arn:aws:secretsmanager:us-east-1:123456789012:secret:tickit-zLrq7N'; CREATE SCHEMA cm-redshiftdb=# ALTER SCHEMA pg owner to tickit; ALTER SCHEMA
作成した外部スキーマを確認します。外部スキーマpgのesoptionsに接続情報が設定されていることが確認できます。
cm-redshiftdb=# SELECT * FROM svv_external_schemas WHERE schemaname = 'pg';
-[ RECORD 1 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
esoid | 2320282
eskind | 3
schemaname | pg
esowner | 100
databasename | rdspg
esoptions | {"SCHEMA":"tickit","URI":"rdspg.ct6wtpooxxxx.us-east-1.rds.amazonaws.com","PORT":5432,"IAM_ROLE":"arn:aws:iam::123456789012:role/redshift-federated-query-role","SECRET_ARN":"arn:aws:secretsmanager:us-east-1:123456789012:secret:tickit-zLrq7N"}
また、外部スキーマpgに接続して、参照できる外部テーブルを確認します。PostgreSQL上のテーブルが参照できたら接続完了です。
cm-redshiftdb=# SELECT * FROM svv_tables where table_type = 'EXTERNAL TABLE' AND table_schema = 'pg'; table_catalog | table_schema | table_name | table_type | remarks ---------------+--------------+------------+----------------+--------- cm-redshiftdb | pg | category | EXTERNAL TABLE | cm-redshiftdb | pg | date | EXTERNAL TABLE | cm-redshiftdb | pg | event | EXTERNAL TABLE | cm-redshiftdb | pg | listing | EXTERNAL TABLE | cm-redshiftdb | pg | sales | EXTERNAL TABLE | cm-redshiftdb | pg | users | EXTERNAL TABLE | cm-redshiftdb | pg | venue | EXTERNAL TABLE | (7 rows)
Federated Queryの実行
RedshiftからRDS PostgreSQLのテーブルに対してクエリを実行します。以下のようにネストした分析クエリが実行できます。
cm-redshiftdb=> -- Find total sales on a given calendar date. cm-redshiftdb=> SELECT sum(qtysold) cm-redshiftdb-> FROM pg.sales, pg.date cm-redshiftdb-> WHERE sales.dateid = date.dateid cm-redshiftdb-> AND caldate = '2008-01-05'; sum ----- 210 (1 row) cm-redshiftdb=> -- Find top 10 buyers by quantity. cm-redshiftdb=> SELECT firstname, lastname, total_quantity cm-redshiftdb-> FROM (SELECT buyerid, sum(qtysold) total_quantity cm-redshiftdb(> FROM pg.sales cm-redshiftdb(> GROUP BY buyerid cm-redshiftdb(> ORDER BY total_quantity desc limit 10) Q, pg.users cm-redshiftdb-> WHERE Q.buyerid = userid cm-redshiftdb-> ORDER BY Q.total_quantity desc; firstname | lastname | total_quantity -----------+----------+---------------- Jerry | Nichols | 67 Kameko | Bowman | 64 Armando | Lopez | 64 Kellie | Savage | 63 Penelope | Merritt | 60 Rhona | Sweet | 60 Herrod | Sparks | 60 Deborah | Barber | 60 Belle | Foreman | 60 Kadeem | Blair | 60 (10 rows) cm-redshiftdb=> -- Find events in the 99.9 percentile in terms of all time gross sales. cm-redshiftdb=> SELECT eventname, total_price cm-redshiftdb-> FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile cm-redshiftdb(> FROM (SELECT eventid, sum(pricepaid) total_price cm-redshiftdb(> FROM pg.sales cm-redshiftdb(> GROUP BY eventid)) Q, pg.event E cm-redshiftdb-> WHERE Q.eventid = E.eventid cm-redshiftdb-> AND percentile = 1 cm-redshiftdb-> ORDER BY total_price desc; eventname | total_price ----------------------+------------- Adriana Lecouvreur | 51846.00 Janet Jackson | 51049.00 Phantom of the Opera | 50301.00 The Little Mermaid | 49956.00 Citizen Cope | 49823.00 Sevendust | 48020.00 Electra | 47883.00 Mary Poppins | 46780.00 Live | 46661.00 (9 rows)
もちろん、RedshiftのテーブルとPostgreSQLのテーブルを結合したクエリも実行できます。次のクエリでは、レコード数の多いRedshift上のsalesテーブルと、レコード数の少ないPostgreSQL上のpg.dateテーブルとpg.usersテーブルを結合して集計するクエリを実行します。
cm-redshiftdb=> -- Finds the top five sellers in San Diego, based on the number of tickets sold in 2008 cm-redshiftdb=> select sellerid, username, (firstname ||' '|| lastname) as name, cm-redshiftdb-> city, sum(qtysold) cm-redshiftdb-> from sales, pg.date, pg.users cm-redshiftdb-> where sales.sellerid = users.userid cm-redshiftdb-> and sales.dateid = date.dateid cm-redshiftdb-> and year = 2008 cm-redshiftdb-> and city = 'San Diego' cm-redshiftdb-> group by sellerid, username, name, city cm-redshiftdb-> order by 5 desc cm-redshiftdb-> limit 5; sellerid | username | name | city | sum ----------+----------+-------------------+-----------+----- 49977 | JJK84WTE | Julie Hanson | San Diego | 22 19750 | AAS23BDR | Charity Zimmerman | San Diego | 21 29069 | SVL81MEQ | Axel Grant | San Diego | 17 43632 | VAG08HKW | Griffin Dodson | San Diego | 16 18888 | KMQ52NVN | Joan Wright | San Diego | 14 (5 rows)
データ型の対応と相違点
Amazon Redshiftデータ型からAmazon RDS PostgreSQLおよびAurora PostgreSQLに対応するデータ型は以下のとおりです。
| Amazon Redshift のデータ型 | RDS PostgreSQL または Aurora PostgreSQL のデータ型 | 説明 |
|---|---|---|
| SMALLINT | SMALLINT | 符号付き2バイト整数 |
| INTEGER | INTEGER | 符号付き4バイト整数 |
| BIGINT | BIGINT | 符号付き8バイト整数 |
| DECIMAL | DECIMAL | 精度の選択が可能な真数 |
| REAL | REAL | 単精度浮動小数点数 |
| DOUBLE PRECISION | DOUBLE PRECISION | 倍精度浮動小数点数 |
| BOOLEAN | BOOLEAN | 論理ブール演算型 (true/false) |
| CHAR | CHAR | 固定長文字列 |
| VARCHAR | VARCHAR | 制限付き可変長文字列 |
| DATE | DATE | Calendar date (year, month, day) |
| TIMESTAMP | TIMESTAMP | 日時(タイムゾーンなし) |
| TIMESTAMPTZ | TIMESTAMPTZ | 日時(タイムゾーンあり) |
| GEOMETRY | PostGIS GEOMETRY | 空間データ |
以下のRDS PostgreSQLおよびAurora PostgreSQLデータ型は、Amazon RedshiftでVARCHAR(64K)に変換されます。
- JSON, JSONB
- Arrays
- BIT, BIT VARYING
- BYTEA
- Composite types
- Date and time types INTERVAL and TIME
- Enumerated types
- Monetary types
- Network address types
- Numeric types SERIAL, BIGSERIAL, SMALLSERIAL, and MONEY
- Object identifier types
- pg_lsn type
- Pseudo-types
- Range types
- Text search types
- TXID_SNAPSHOT
- UUID
- XML type
最後に
これまでは、RDS/Aurora PostgreSQLからデータを取得するためにS3を介してRedshiftやRedshift Spectrumと連携する必要がありましたので、ジョブフローが複雑になりがちでした。しかし、今後は何も考えずにRDS/Auroraの PostgreSQLのデータをRedshiftで組み合わせて分析できるようになります。「DWH」とは、サイロ化されたデータを誰もがいつでも利用できるように一元的に統合・管理することが主目的です。Redshiftは、単に大規模データを低価格・高性能・伸縮自在に扱えるだけではなく、S3上のデータ(データレイク)や他のデータベースをアドホックに統合できる分析プラットフォームに正常進化したと言えるでしょう。さらにRDS/Aurora MySQLなどのサポートを期待しています。










