![[レポート]「最近のAuroraのアップデート使いこなし術」という発表を行いました – Developers.IO TOKYO 2019 #cmdevio](https://devio2023-media.developers.io/wp-content/uploads/2019/11/img_devio2019_session.jpg)
[レポート]「最近のAuroraのアップデート使いこなし術」という発表を行いました – Developers.IO TOKYO 2019 #cmdevio
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
大栗です。
先日開催したDevelopers.io 2019 Tokyoで最近のAmazon Auroraについてのアップデートをご紹介する発表をさせて頂きましたので、まとめたいと思います。
最近のAuroraのアップデート使いこなし術
セッション概要
Amazon Auroraとは
Amazon Auroraはre:Invent 2014で発表され、AWS史上最も早く成長しているRDBMSのサービスです。OSSのRDBMSをベースにして大量アクセスを捌くためにスループットを向上させる方針で開発しています。そのため御自身のワークロードによってはオリジナルのMySQLやPostgreSQLを使うほうが良い場合もあります。
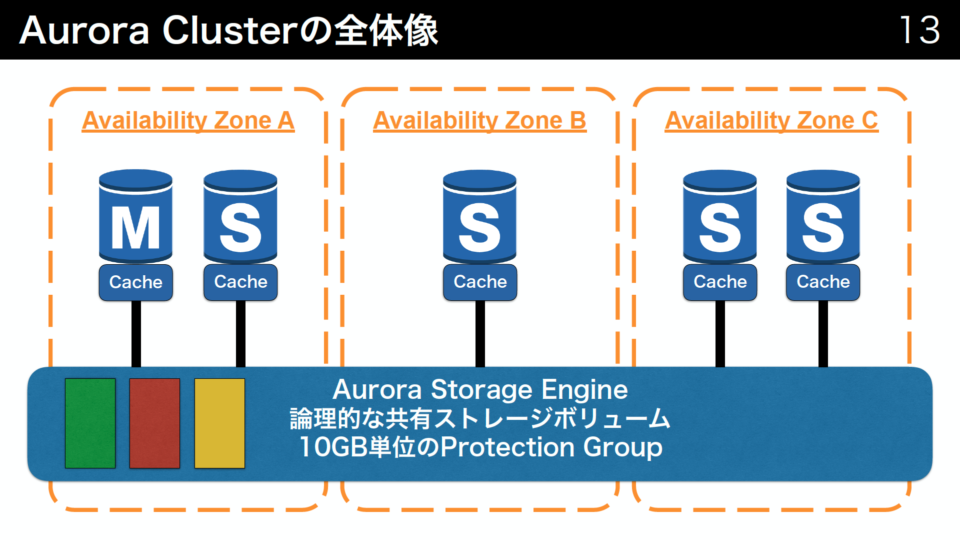
Aurora Storage Engineという3個のAvailability Zoneに跨って構成される論理的な共有ボリュームに対して、マスタやスレーブのインスタンスがアクセスします。Aurora Storage Engineは単一の論理ボリュームなのでマスタとスレーブで同じものを共有します。また、Aurora Storage Engineは10GBごとに別れており、AZごとに2個、合計6個の複製があり耐久性を高めています。
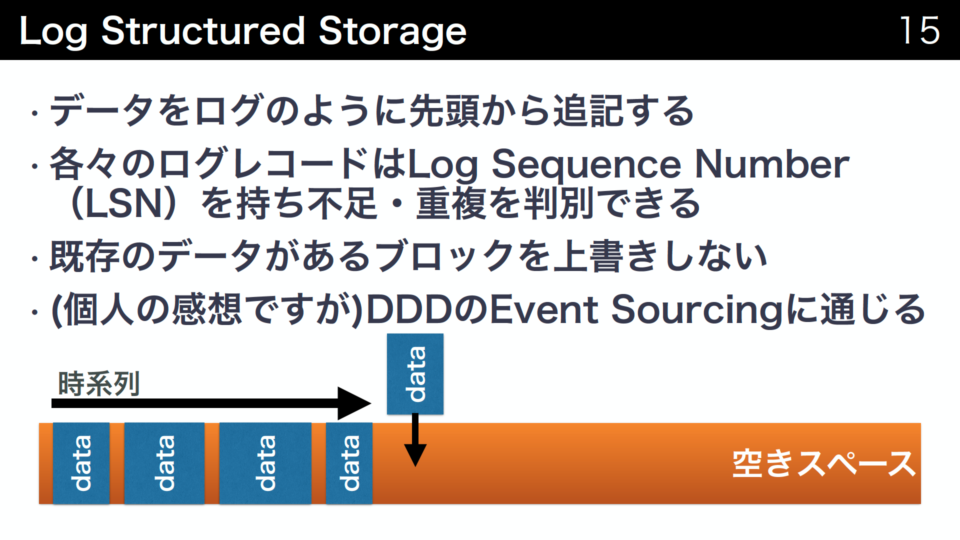
Aurora Storage Engineは論理的にはLog Structured Storageと呼ばれる構成でデータを書き込みます。ログのようにデータを先頭へ追記します。
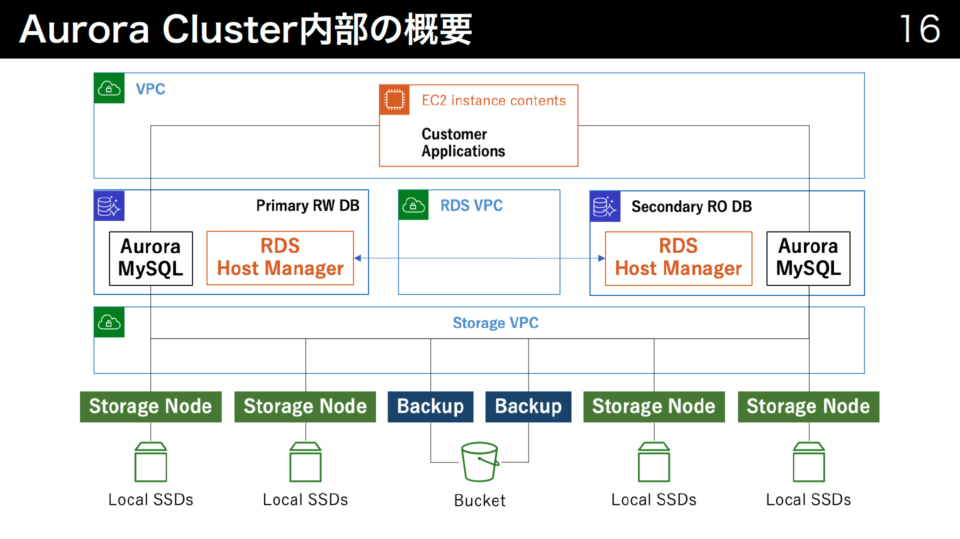
Amazon AuroraはVPCやS3などの既存のAWSのサービスを組み合わせて構成されています。
更に内部アーキテクチャが気になる方は論文を読むことをお勧めします。
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
- Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes
こんなスライドもあります。
最近の大きなアップデート
最近1年間のアップデートについて独断と偏見に基づいてピックアップしてみました。
- 2018年11月8日 Aurora PostgreSQL での IAM 認証サポート
- 2018年11月12日 カスタムエンドポイント
- 2018年11月20日 Aurora PostgreSQL のクエリ計画管理
- 2018年11月28日 Aurora Global Database
- 2019年5月30日 Aurora PostgreSQL のDatabase Activity Streamsのサポート
- 2019年5月30日 Aurora MySQL Serverlessの Data APIを一般公開
- 2019年6月11日 Aurora PostgreSQL のクラスターキャッシュ管理で高速なフェイルオーバーを実現
- 2019年7月9日 Aurora PostgreSQLでAurora Serverless をサポート
- 2019年8月8日 Aurora MySQL のMulti-Master Cluster
- 2019年9月23日 Aurora PostgreSQL の Data API
その中で、以下の機能に焦点を当ててご紹介します。
- Custom Endpoint
- Aurora Global Database
- Aurora Serverless Data API
- Multi-Master Cluster
各機能をどのように利用するのか
Custom Endpoint
元々Auroraには以下のエンドポイントが存在しました。
- インスタンスエンドポイント
- クラスタエンドポイント
- リーダーエンドポイント
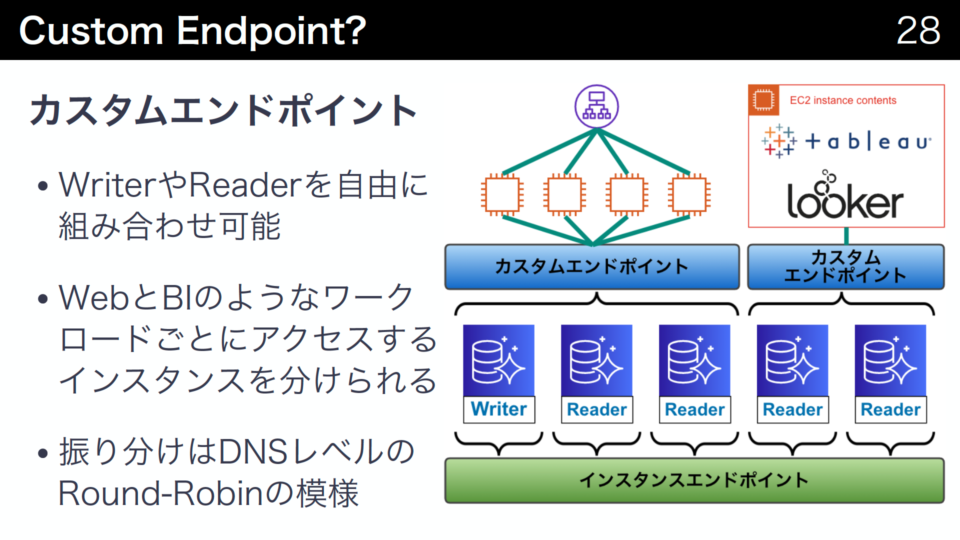
カスタムエンドポイントはWriterやReaderを自由に組み合わせ可能で、WebとBIなどのようにワークロードが異なる場合にアクセスするインスタンスを分離できます。もしWebのように大量で軽いクエリとBIのように少量で重いクエリが同一インスタンスで処理されると、重いクエリに引きずられて大量で軽いクエリがスローダウンすることも考えられます。カスタムエンドポイントでは、そのような問題を解決できます。
フェイルオーバーして、ReaderがWriterへ昇格してもReaderのみ名前解決可能で、Auto Scalingなどの台数増減にも追従できます。
複数インスタンスへの振り分けはDNSレベルのRound-Robinのようなので厳密な負荷分散が必要な場合は別途ロードバランスが必要になります。
Custom Endpointは異なるワークロードが共存しているときにDB側の負荷を分離させるために利用するのが良いと思われます。
Aurora Global Database
Aurora Global Databaseは別リージョンへのレプリケーション機能です。以前からCross-Region Read Replicaがありましたが仕組みが異なっています。論理レプリケーションではなく、Log Structured Storageのログレコードをストレージ層で送信する物理レプリケーションになっており、高速で性能影響が少ないレプリケーションが可能になります。
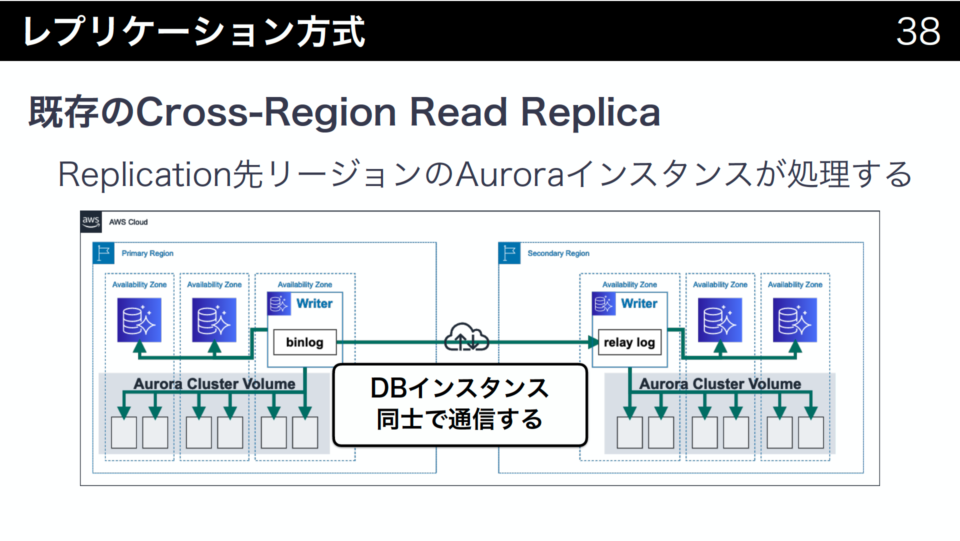
既存のCross-Region Read Replicaは、Auroraには本来不要なbinlogを出力してMySQLの既存機能で論理レプリケーションを行います。
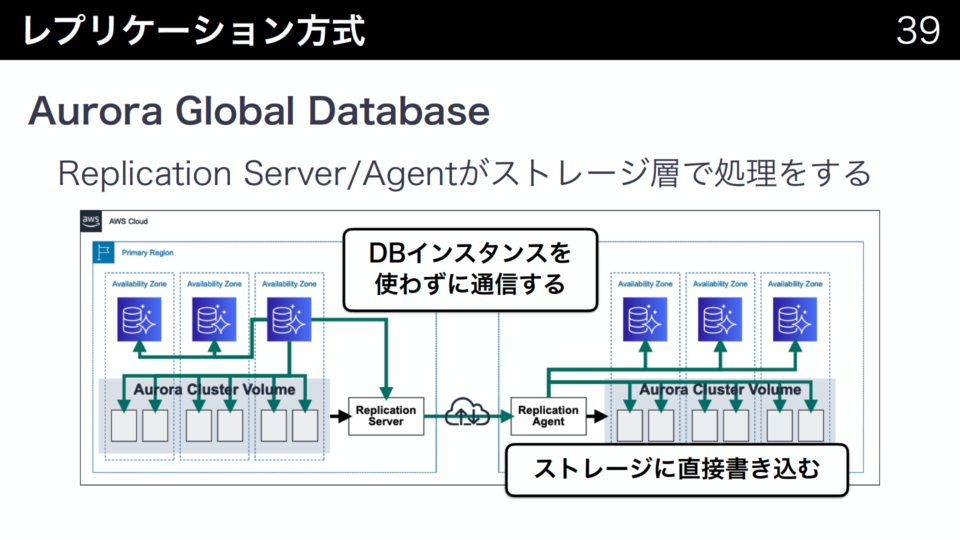
Aurora Global Databaseの場合は、ストレージへのログ書き込みのようにReplication Serverへ出力して、別リージョンへ送信します。送信先のリージョンではReplication Agentが受け取り、ストレージに書き込みを行います。送信先のリージョンでストレージに書き込むため、レプリケーションのためにはDBインスタンスは必ずしも必要ないので、待機コストを削減できます。
Aurora Global Databaseは、RPO(目標復旧時間)が短く低価格なDRサイトを構築するときにRDBMSのリージョン間の冗長化に役に立ちます。
Aurora Serverless Data API
Aurora Serverless Data APIは、AWS API経由でAurora Serverlessにインターネットからアクセスできる機能です。認証はIAMで、httpアクセスが可能で、トランザクションも実現できます。またAurora Serverlessがベースである他、アプリ影響無しで自動的なスケーリングができます。
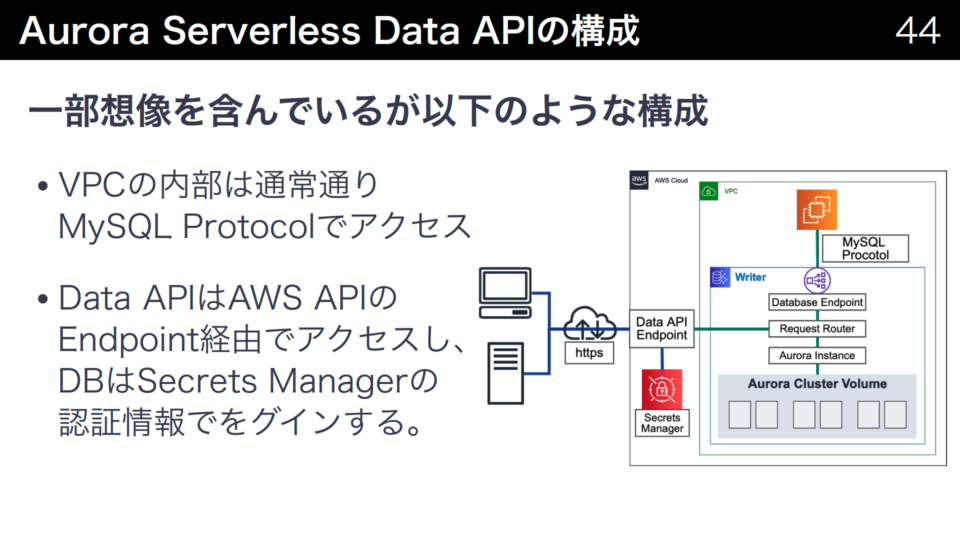
通常はMySQL Protocolでアクセスしますが、Data APIではAWS APIのEndpoint経由でアクセスします。DBの認証情報はSecrets Managerに保存し、それを利用してアクセスします。
トランザクションが不要な場合は、ExecuteStatement APIかBatchExecuteStatement APIを実行すると、そのままコミットされます。
トランザクションが必要な場合は、最初にBeginTransaction APIを実行してTransaction IDを取得します。Transaction IDを使用してExecuteStatement APIやBatchExecuteStatement APIを実行し、最終的にCommitTransaction API経由でDBにCOMMITを行います。
VPCの外側から自由にアクセスできるため、AppSync経由でLambdaを挟まずにAuroraへアクセスできます。また以前はVPC Lambdaのコールドスタートが遅かったため、それを避けるためににAurora Serverlessでアクセスしましたが、現在ではVPC Lambdaのコールドスタートが高速になったため考慮不要になりました。
ただし、AppSync経由でAuroraを利用する場合にはVTL(Velocity Template Language)でResolverを定義する必要があります。トランザクションを利用するのであれば、クライアント側でBeginTransaction APIやCommitTransaction APIを意識して制御するかPipeline ResolverでResolverをまとめて自動化することになります。しかしPipeline Resolverの場合はトランザクション中に問題があってもRollbackできないなど問題があります。そのためLambdaを挟んで、Lambdaの中でトランザクションを制御したほうが良いです。
そのためAurora Serverless Data APIは、トランザクションが不要な場合にAppSyncで利用するのが良いと思われます。
Multi-Master Cluster
Multi-Master Clusterは書込み可能なDBインスタンスを複数作成できて、極めて高い可用性を実現できる機能です。
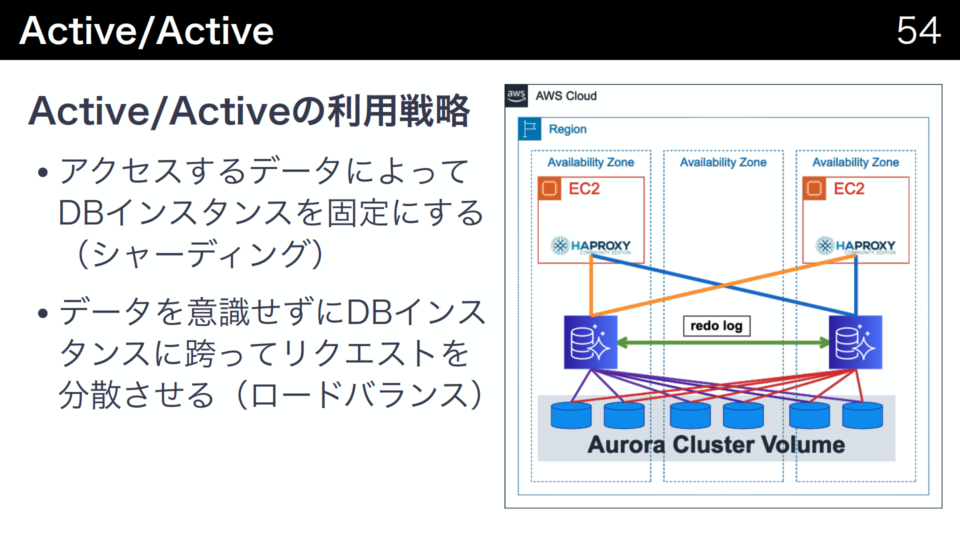
Multi-Masterでは同時実行制御が楽観的な同時実行制御が推奨されて、おり、異なるDBインスタンス間で同じデータを更新すると書き込み競合が発生します。また、常に最新のデータを表示できるように同期を行う設定であるグローバルな書き込み後読み取り(GRAW)もサポートされています。
2台のDBインスタンスの使い方として、両方を併用するActive/Activeと片方のみを使用するActive/Passiveが考えられます。
Active/Activeの場合はシャーディングとロードバランスがあります。
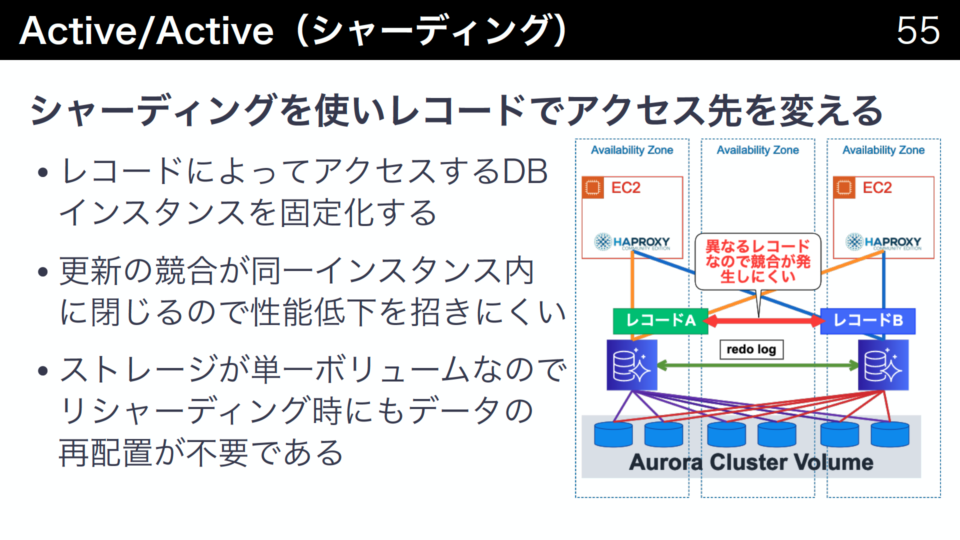
シャーディングではアクセスするレコードを特定のDBインスタンスに固定化します。するとレコードによってアクセス先のDBインスタンスが異なり、更新の競合が発生しにくくなるので各クエリの実行性能が低下しにくくなります。
通常のMySQLをシャーディングする場合はデータはシェアードナッシングになるので、ホットデータなどの影響を是正するために理シャーディングする場合データの再配置が必要なので手間がかかります。しかしAuroraの場合は単一のボリュームを共有しているためデータの再配置が不要となります。
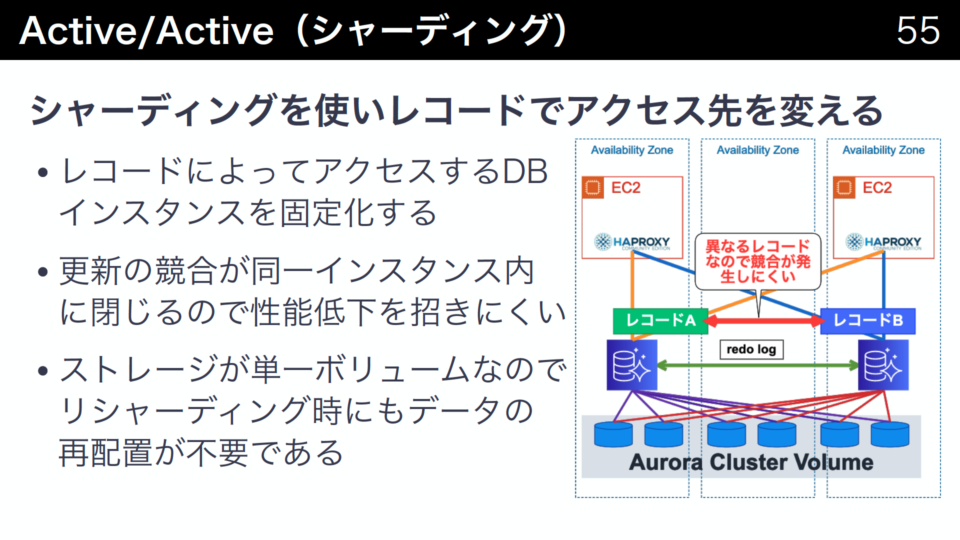
アクセス先をランダムに負荷分散させる場合、同一データを異なるDBインスタンス感で更新する可能性があり、性能低下を招く可能性があります。そのため、アクセス先をランダムにすることは推奨されません。
Active/Passiveの場合を考えてみます。
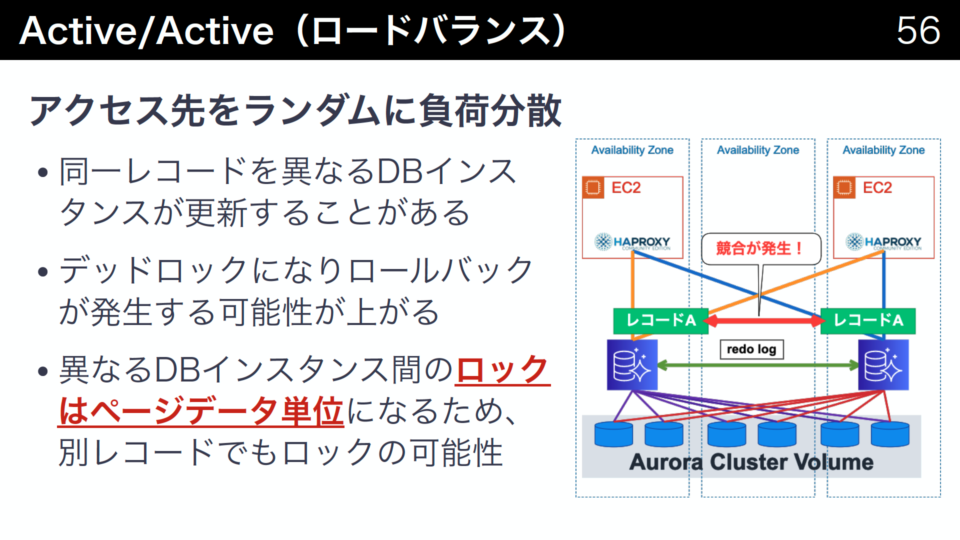
ここではActive/PassiveをHAProxyで実装する例を考えます。HAProxyがDBインスタンスのヘルスチェックを行っていると、片方のDBインスタンスが停止したときに数秒で別インスタンスへアクセスに振り返られます。障害の発生から数秒で切り替えが可能になります。
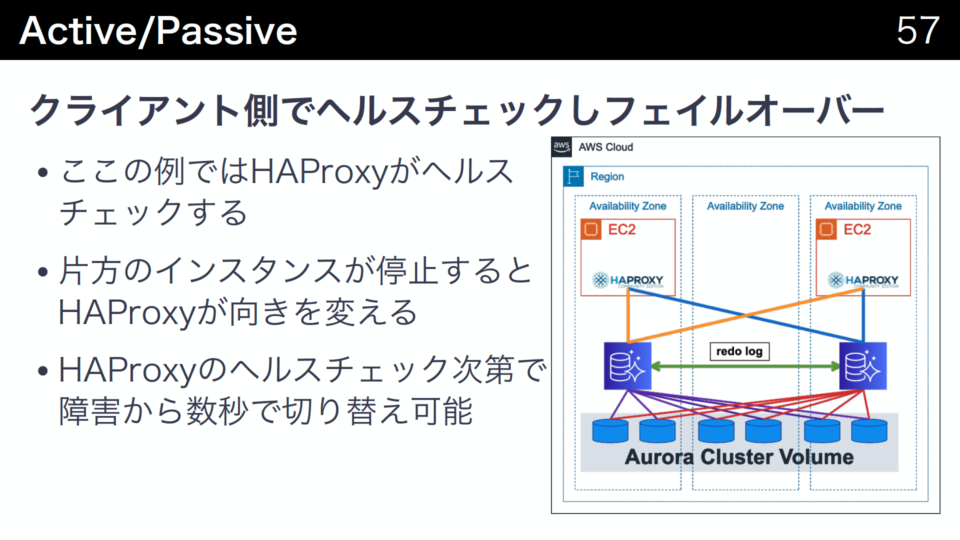
しかし、通常のAuroraであってもFast Failoverを使って高速に切り替えられます。Fast Failoverの場合は障害発生からAWSで検知するまでに概ね20秒以内となり、そこから切り替えを数秒で行います。そのため障害発生から概ね30秒以内での切り替えが可能になります。
Multi-Master Clusterは、シャーディングによるパフォーマンス向上か、Active/Passiveによるダウンタイムの極小化を狙って利用すべきだと思われます。
ただし、競合の制約(GRAWの有無など)や読み込みのスケーリングが出来ないなど考慮が必要です。可用性の向上が目的の場合は通常のAuroraクラスタのFast Failoverも選択肢として考えるべきです。
まとめ
- Custom Endpoint
BIのような少量の重いクエリとWebのような大量の軽いクエリが混在するような場合に、読み込みのワークロードを 分離して負荷の影響を抑えられます - Aurora Global Database
RPO(目標復旧時間)が短く低価格なDRサイト構築を構築できます - Aurora Serverless Data API
トランザクションが不要な場合のAppSync利用に良いが、VPC Lambdaのコールドスタートが高速化したため出番が減っている状況です - Multi-Master Cluster
シャーディングによりパフォーマンスの向上を図るか、Active/Passiveで極めて高い可用性を求める場合に利用しましょう。GRAWや読み込みスケーリングが出来ないなどの問題があるため、利用はどうしても必要な場合に限った方が良いです。
さいごに
最近Auroraの注目機能が色々出てきているのですが、試すことが難しいことが多いと思います。本セッションを聞いてAuroraのアップデートの活用方法が分かり、新たな施策に取り組んだり運用負荷を図って頂ければ幸いです。










