![[アップデート] 次世代 Amazon OpenSearch Serverless が一般提供開始、待機コストゼロになったのでベクトル検索を試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-b383cfad7452c18278d4772c71cae640/70681da1d5cfd4b8d3a7edcc29830075/amazon-opensearch-service?w=3840&fm=webp)
[アップデート] 次世代 Amazon OpenSearch Serverless が一般提供開始、待機コストゼロになったのでベクトル検索を試してみた
クラウド事業本部の石川です。次世代(next generation)の Amazon OpenSearch Serverless が一般提供されました。AWS の発表によると、エージェント(agentic AI)ワークロードを念頭にアーキテクチャを刷新し、前世代と比べてオートスケーリングが 20 倍高速になり、ピーク負荷時にプロビジョニングする構成と比較して最大 60% のコスト削減を実現するとされています。Collection Group の scale-to-zero からベクトル検索まで実際に試してみました。
最大の特徴は、コンピューティングが完全に分離された共有ストレージレイヤーを使う構成になったことで、最小 OCU 要件がなくなり「scale-to-zero」(アイドル時にキャパシティをゼロまで縮退)が可能になった点です。AI エージェントが必要なときだけベクトル検索や取得ステップを起動する、といった動的なワークロードに適した設計になっています。
次世代 OpenSearch Serverless とは
Collection Groupの導入
次世代版では、新しく Collection Group という管理単位が導入されました。Collection Group は OCU(OpenSearch Compute Unit)のキャパシティ上限・下限をグループ単位で管理する器で、複数のコレクションがそのキャパシティを共有します。下限(最小キャパシティ)を指定しなければ scale-to-zero となり、10 分間アクティビティがなければ OCU はゼロまで縮退し、約 10 秒で復帰します。
コレクションタイプは、ローンチ時点で全文検索の SEARCH とベクトル検索の VECTORSEARCH の 2 種類がサポートされます(前世代の TIMESERIES はローンチ時点では非対応です)。indexing・search・storage・Vector Index の GPU アクセラレーションは、それぞれ独立してメータリング・課金されます。
ストレージとコンピュートの分離
最大の変更点は、コンピュート(OCU: OpenSearch Compute Unit)とストレージを分離し、分散共有ストレージレイヤーを導入したことです。これにより、コンピュートとストレージをそれぞれ独立してスケールできるようになりました。
| 項目 | Classic(従来) | NextGen(次世代) |
|---|---|---|
| 最小キャパシティ | 2 OCU(常時稼働) | 0 OCU(scale-to-zero 可能) |
| ストレージ | ローカルストレージ | 分散共有ストレージ |
トラフィックが少ない時間帯はコンピュートをゼロまで縮退させ、リクエストが届いたときに秒単位で立ち上げます。なお、ゼロから復帰する初回リクエストではコールドスタートが発生します(詳細は後述の「利用上の注意点」を参照してください)。
アーキテクチャ
アーキテクチャを図にすると以下のようになります。
アップデート内容
主な変更点は以下のとおりです。
- scale-to-zero と従量課金: 使っていない時間帯はコンピュートをゼロまで縮退します。使った分だけ支払う従量課金となり、ピーク容量をプロビジョニングし続ける場合と比べて最大 60% のコスト削減が可能です
- 最大 20 倍高速なオートスケーリング: ゼロから毎秒数千リクエストまで、前世代比で最大 20 倍高速にスケールします
- コレクショングループ(Collection Groups): 複数のコレクションでコンピュート容量を共有できる組織単位です。テナントごとにコレクションを分けつつ容量はまとめて使う、といったマルチテナント環境でリソースを効率化できます
- リソースベースエンドポイント: コレクション単位のエンドポイントに加えて、アカウント(リージョン)単位のエンドポイントが提供されます。1 つの接続からヘッダー指定で複数コレクションへアクセスできるため、マルチ VPC やオンプレミスからの接続が簡素化されます
- GPU 加速によるベクトルインデックス構築: VECTORSEARCH コレクションの HNSW ベクトルインデックス構築を、GPU で短縮できる場合に AWS 管理の GPU コンピュートへ自動的にオフロードします。GPU インスタンスを別途用意・管理する必要はなく、利用分は OCU として従量課金されます。大規模なベクトルデータの取り込み・更新にかかる時間を、CPU のみの場合と比べて短縮できます(公式ブログでは最大 10 倍高速・インデックス作成コスト約 1/4 と紹介されています)
- エージェント/AI 開発プラットフォームとの統合: 後述します
エージェント/AI 開発との統合
AI エージェントは、数百の並行ベクトルクエリを実行して推論した後にアイドル状態になる、といった動的な負荷を生みます。scale-to-zero と高速なオートスケーリングを備えた次世代版は、こうしたワークロードと相性が良く、生成 AI アプリケーション開発との親和性が大きく高められています。
- Vercel との統合: AWS Marketplace 経由の統合により、数秒でプロダクション対応の検索バックエンドを構築できます
- Kiro との連携: OpenSearch Launchpad(Kiro Powers)を使い、ガイドに沿ってアーキテクチャを計画できます
- OpenSearch Agent Skills: ドメイン知識や多段階の実行ロジックをカプセル化したスキル群を、Claude Code・Cursor・Codex などのコーディングプラットフォームから利用できます
対応コレクションタイプ
次世代版でサポートされるコレクションタイプは、全文検索(SEARCH)とベクトル検索(VECTORSEARCH)の 2 種類です。時系列(TIMESERIES)コレクションは現時点では対象外です。
対応リージョン
Amazon OpenSearch Serverless が現在利用可能な、すべてのコマーシャル AWS リージョンで利用できます。
料金への影響
Amazon OpenSearch Serverless では、インスタンスタイプを選ぶのではなく、コンピュート(OCU: OpenSearch Compute Unit)とストレージの使用量に対して課金されます。NextGen ではコンピュートを 0 までスケールできる(scale-to-zero)ため、使った分だけ支払う従量課金が基本です。
従量課金(pay-per-usage)は、インデックス作成・検索・GPU 加速に使われる OCU と、ストレージ(GB-月)に対して課金されます。インデックス作成・検索・ストレージ・GPU 加速は独立して計量・課金されるため、請求の内訳で GPU 加速分を個別に確認できます。scale-to-zero により、アイドル時のコンピュート課金を抑えられる点が大きな特徴です。
NextGen かつ collection group の最小 OCU = 0 の場合、最後のリクエストから 10 分間のアイドル保持され課金の対象となります。
例えば、検索リクエストで起動するワーカー(= Search 2 OCU 相当、standby 有効時)を前提にすると、断続利用では「利用時間 + 10 分」が積み重なります。
| 実際の利用 | 実効 OCU 稼働(利用+アイドル 10 分) | 概算課金 |
|---|---|---|
| 検索 10 秒 × 1 回 | 約 10 分 | 2 OCU × (10/60)h × $0.334 ≈ $0.11 |
| 検索 3 分 × 1 回 | 約 13 分 | 2 OCU × (13/60)h × $0.334 ≈ $0.14 |
| 全くリクエストなし | 0 分 | $0 |
詳細は料金ページを参照してください。
マネジメントコンソールから作成する
マネジメントコンソールでは、Amazon OpenSearch Service の Serverless メニューから「Create collection」を選択します。次世代版には設定不要の「Express create」が用意されており、デフォルト設定のコレクションを秒単位でプロビジョニングできます。
マネジメントコンソールの Amazon OpenSearch Serverless の画面から [Create collection] ボタンを押します。
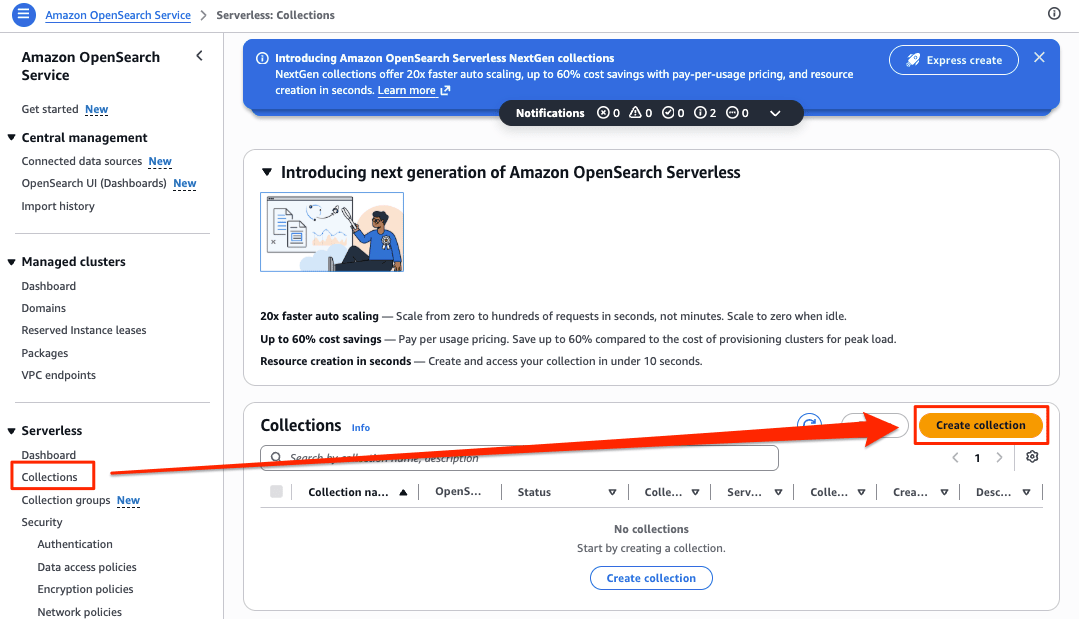
Collection nameを入力し、Serverless Generationはデフォルトのまま、Collection typeは Vector Searchに変更しています。後は、Express create(デフォルト)で作成します。
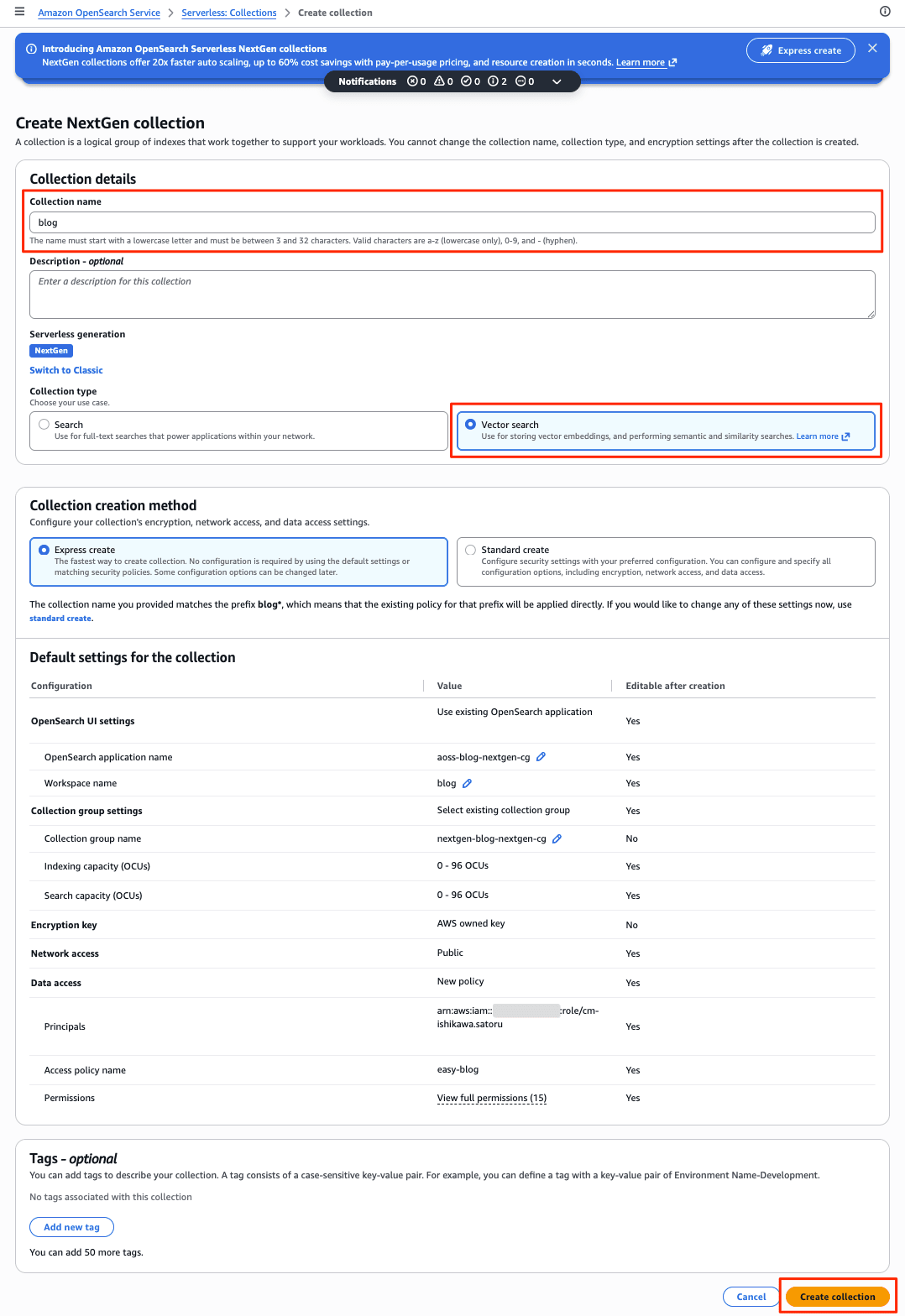
すぐに作成が開始され、1分程度で作成されます。

Collection Group、Collection(Vector Search)など、自動的に作成されます。
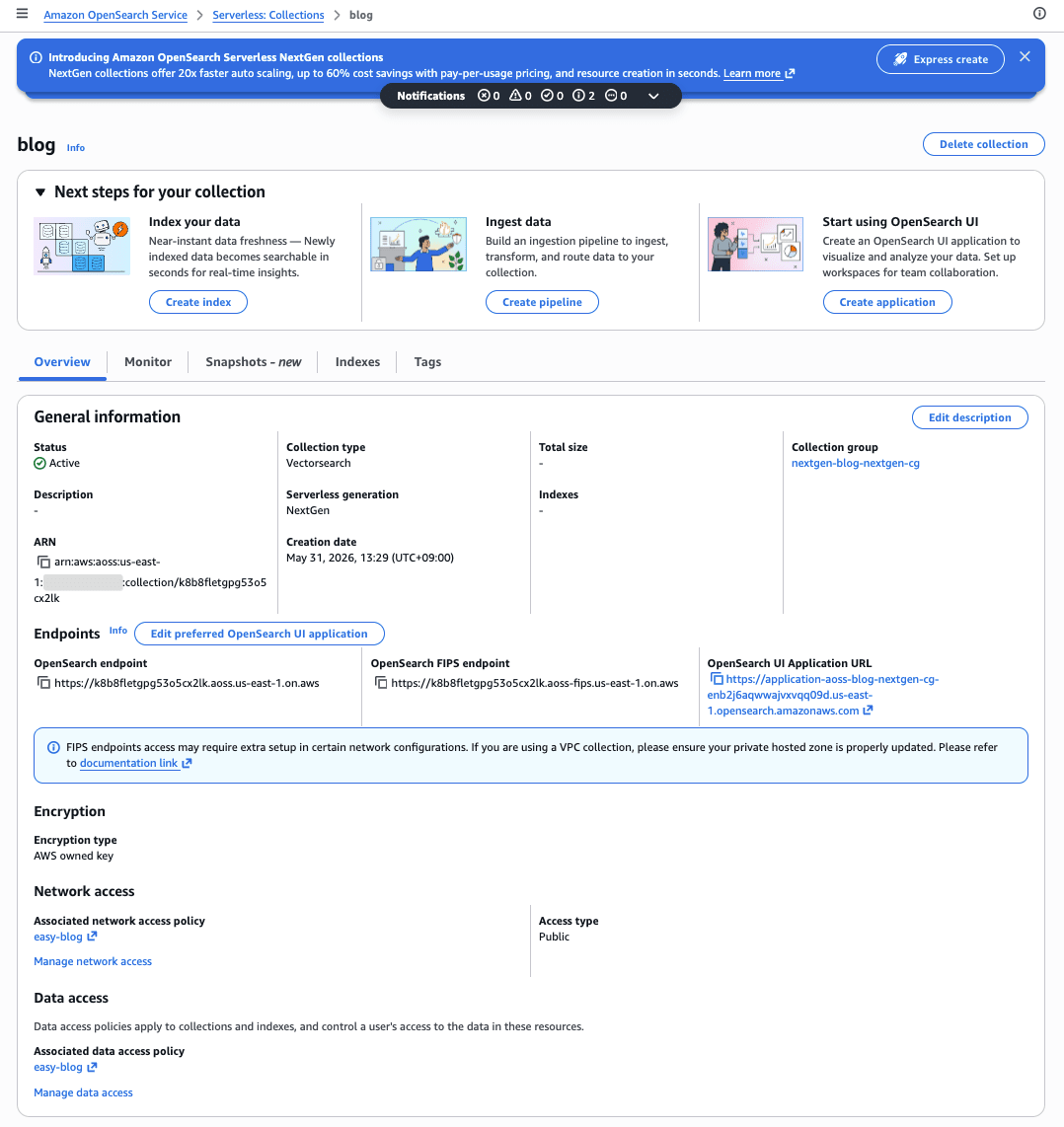
作成されたCollectionは一覧から確認できます。
やってみた
手早く試すならマネジメントコンソール、再現性を確保したいなら AWSCLI、といった使い分けがおすすめです。
今回はAWSCLIを用いて VECTORSEARCH コレクションを作成し、コントロールプレーンの新しい create-index API でベクトルインデックスを定義したうえで、商品データを投入して knn ベクトル検索が動作するところまで確認します。
前提条件
- AWS アカウント(検証は sandbox アカウントを使用)
- AWS CLI v2.34.57(次世代版の作成に必須。v2.34.42 では
create-collection-groupに--generationオプションが無く、Classic コレクションになってしまうため、--generation NEXTGENに対応した版へ更新が必要) - Python 3 + boto3 1.43.14 + opensearch-py 3.2.0(データプレーンの SigV4 署名アクセス用)
- 検証リージョン:
us-east-1(東京リージョンでも可能)
なお、AWSCLI v2.34.42 の時点で、次世代版に対応した以下のコマンドが追加されています。create-collection-group / list-collection-groups / batch-get-collection-group / update-collection-group / delete-collection-group、および create-index / get-index / update-index / delete-index です。
アカウントのキャパシティ上限を確認する
まず、アカウントの OCU キャパシティ上限を確認します。
% aws opensearchserverless get-account-settings --region us-east-1
{
"accountSettingsDetail": {
"capacityLimits": {
"maxIndexingCapacityInOCU": 10,
"maxSearchCapacityInOCU": 10
}
}
}
indexing・search ともに上限 10 OCU でした。Collection Group のキャパシティ上限はこの範囲内で設定します。(東京リージョンでも同様でした。)
暗号化・ネットワーク・データアクセスの 3 ポリシーを作成する
次世代版でも、コレクションを作成する前に暗号化ポリシー(必須)・ネットワークポリシー・データアクセスポリシーが必要です。まず暗号化ポリシー(AWS 所有キー)を作成します。
% aws opensearchserverless create-security-policy --name blog-nextgen-enc --type encryption \
--policy '{"Rules":[{"ResourceType":"collection","Resource":["collection/blog-nextgen-vec"]}],"AWSOwnedKey":true}' \
--region us-east-1
{
"securityPolicyDetail": {
"type": "encryption",
"name": "blog-nextgen-enc",
"policyVersion": "MTc4MDIyMzk4NTE3NF8x",
"policy": {
"Rules": [
{
"Resource": [
"collection/blog-nextgen-vec"
],
"ResourceType": "collection"
}
],
"AWSOwnedKey": true
},
"createdDate": 1780223985174,
"lastModifiedDate": 1780223985174
}
}
続いてネットワークポリシー(パブリックアクセス)を作成します。
% aws opensearchserverless create-security-policy --name blog-nextgen-net --type network \
--policy '[{"Rules":[{"ResourceType":"collection","Resource":["collection/blog-nextgen-vec"]},{"ResourceType":"dashboard","Resource":["collection/blog-nextgen-vec"]}],"AllowFromPublic":true}]' \
--region us-east-1
{
"securityPolicyDetail": {
"type": "network",
"name": "blog-nextgen-net",
"policyVersion": "MTc4MDIyNDAzMDE3NF8x",
"policy": [
{
"Rules": [
{
"Resource": [
"collection/blog-nextgen-vec"
],
"ResourceType": "collection"
},
{
"Resource": [
"collection/blog-nextgen-vec"
],
"ResourceType": "dashboard"
}
],
"AllowFromPublic": true
}
],
"createdDate": 1780224030174,
"lastModifiedDate": 1780224030174
}
}
最後に、実行ロールにコレクションとインデックスへのフルアクセスを与えるデータアクセスポリシーを作成します。
% aws opensearchserverless create-access-policy --name blog-nextgen-data --type data \
--policy '[{"Rules":[{"ResourceType":"index","Resource":["index/blog-nextgen-vec/*"],"Permission":["aoss:*"]},{"ResourceType":"collection","Resource":["collection/blog-nextgen-vec"],"Permission":["aoss:*"]}],"Principal":["arn:aws:iam::<aws_account_id>:role/cm-ishikawa.satoru"]}]' \
--region us-east-1
{
"accessPolicyDetail": {
"type": "data",
"name": "blog-nextgen-data",
"policyVersion": "MTc4MDIyNDIwMzUzNF8x",
"policy": [
{
"Rules": [
{
"Resource": [
"index/blog-nextgen-vec/*"
],
"Permission": [
"aoss:*"
],
"ResourceType": "index"
},
{
"Resource": [
"collection/blog-nextgen-vec"
],
"Permission": [
"aoss:*"
],
"ResourceType": "collection"
}
],
"Principal": [
"arn:aws:iam::<aws_account_id>:role/cm-ishikawa.satoru"
]
}
],
"createdDate": 1780224203534,
"lastModifiedDate": 1780224203534
}
}
3 つとも正常に作成できました。
Collection Group を作成する(scale-to-zero)
ここが次世代版の肝です。次世代版にするには --generation NEXTGEN を指定します(省略すると Classic になります)。さらに、NextGen の Collection Group は --standby-replicas ENABLED が必須で、DISABLED を指定すると StandbyReplicas cannot be set to DISABLED for NEXTGEN collection groups. という ValidationException になります(Classic では DISABLED も選べました)。--capacity-limits は最大キャパシティのみを指定し、最小キャパシティを省略することで scale-to-zero になります。今回は最大 2 OCU としました。
% aws opensearchserverless create-collection-group --name blog-nextgen-cg \
--generation NEXTGEN \
--standby-replicas ENABLED \
--capacity-limits "maxIndexingCapacityInOCU=2,maxSearchCapacityInOCU=2" \
--region us-east-1
{
"createCollectionGroupDetail": {
"id": "9drrer2c1r5zlgg61d3i",
"arn": "arn:aws:aoss:us-east-1:<aws_account_id>:collection-group/9drrer2c1r5zlgg61d3i",
"name": "blog-nextgen-cg",
"standbyReplicas": "ENABLED",
"createdDate": 1780224231731,
"capacityLimits": {
"maxIndexingCapacityInOCU": 2.0,
"maxSearchCapacityInOCU": 2.0,
"minIndexingCapacityInOCU": 0.0,
"minSearchCapacityInOCU": 0.0
},
"generation": "NEXTGEN"
}
}
レスポンスに "generation": "NEXTGEN" が含まれており、次世代版として作成されたことを CLI レベルで確認できます。capacityLimits の min... が 0.0(最小キャパシティなし= scale-to-zero)になっている点も次世代版の特徴です。
VECTORSEARCH コレクションを作成する
作成した Collection Group に所属させる形で、VECTORSEARCH コレクションを作成します。--collection-group-name で所属先を指定する点が次世代版ならではです。コレクションも Collection Group に合わせて --standby-replicas ENABLED にします。世代は Collection Group から継承されるため、create-collection 側に --generation はありません。
% aws opensearchserverless create-collection --name blog-nextgen-vec \
--type VECTORSEARCH \
--collection-group-name blog-nextgen-cg \
--standby-replicas ENABLED \
--region us-east-1
{
"createCollectionDetail": {
"id": "8kz9vpajkj4gvm8um9he",
"name": "blog-nextgen-vec",
"status": "CREATING",
"type": "VECTORSEARCH",
"arn": "arn:aws:aoss:us-east-1:<aws_account_id>:collection/8kz9vpajkj4gvm8um9he",
"kmsKeyArn": "auto",
"standbyReplicas": "ENABLED",
"deletionProtection": "DISABLED",
"vectorOptions": {
"ServerlessVectorAcceleration": "ENABLED"
},
"createdDate": 1780224282589,
"lastModifiedDate": 1780224282589,
"collectionGroupName": "blog-nextgen-cg"
}
}
レスポンスの vectorOptions.ServerlessVectorAcceleration が自動で ENABLED になっています。次世代版では GPU 加速(ベクトルインデックス構築の高速化)がデフォルトで有効になることを示しています。
status が CREATING になりました。batch-get-collection でステータスをポーリングして待機します。
% aws opensearchserverless batch-get-collection --ids 8kz9vpajkj4gvm8um9he --region us-east-1
{
"collectionDetails": [
{
"id": "8kz9vpajkj4gvm8um9he",
"name": "blog-nextgen-vec",
"status": "ACTIVE",
"type": "VECTORSEARCH",
"arn": "arn:aws:aoss:us-east-1:<aws_account_id>:collection/8kz9vpajkj4gvm8um9he",
"kmsKeyArn": "auto",
"standbyReplicas": "ENABLED",
"deletionProtection": "DISABLED",
"vectorOptions": {
"ServerlessVectorAcceleration": "ENABLED"
},
"createdDate": 1780224282589,
"lastModifiedDate": 1780224287330,
"collectionEndpoint": "https://8kz9vpajkj4gvm8um9he.aoss.us-east-1.on.aws",
"fipsEndpoints": {
"collectionEndpoint": "https://8kz9vpajkj4gvm8um9he.aoss-fips.us-east-1.on.aws"
},
"collectionGroupName": "blog-nextgen-cg"
}
],
"collectionErrorDetails": []
}
今回は 約 15 秒で ACTIVE になりました(前世代 Classic での同等検証は約 4 分だったため、次世代版はプロビジョニングが大幅に高速化されています)。払い出された collectionEndpoint の形式は <collection-id>.aoss.<region>.on.aws で、Classic の <collection-id>.<region>.aoss.amazonaws.com とは異なります。また、次世代版ではコレクション単位の dashboardEndpoint は払い出されません(OpenSearch UI 経由でアクセスします)。
コントロールプレーンの create-index でベクトルインデックスを定義する
次世代版では、コントロールプレーンの create-index API でインデックスを定義できます。データプレーンエンドポイントへ SigV4 署名リクエストを送らずに、CLI からインデックスのマッピングを定義できるのが便利な点です。3 次元の knn_vector フィールドを持つインデックスを作成します。
% aws opensearchserverless create-index --id 8kz9vpajkj4gvm8um9he --index-name products \
--index-schema '{"settings":{"index":{"knn":true}},"mappings":{"properties":{"description":{"type":"text"},"category":{"type":"keyword"},"embedding":{"type":"knn_vector","dimension":3}}}}' \
--region us-east-1
コマンドは正常終了しました。get-index で定義内容を確認します。
% aws opensearchserverless get-index --id 8kz9vpajkj4gvm8um9he --index-name products --region us-east-1
{
"indexSchema": {
"products": {
"settings": {
"index": {
"knn.remote_index_build": {
"enabled": "true"
},
"number_of_shards": "2",
"provided_name": "products",
"knn": "true",
"creation_date": "1780224440004",
"custom_doc_id_enabled": "true",
"number_of_replicas": "0",
"uuid": "kdylfZ4B-lPmRp_CNsUL",
"version": {
"created": "137247827"
}
}
},
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"description": {
"type": "text"
},
"embedding": {
"mode": "on_disk",
"type": "knn_vector",
"dimension": 3,
"compression_level": "32x"
}
}
},
"aliases": {}
}
}
}
knn が有効化され、embedding が knn_vector(次元数 3)として定義されていることを確認できました。指定していない設定が自動付与されている点が次世代版ならではです。custom_doc_id_enabled: true(カスタムドキュメント ID 対応)、knn.remote_index_build.enabled: true(GPU 加速=リモートインデックスビルド)、embedding の mode: on_disk と compression_level: 32x(32 倍圧縮がデフォルト)が付いています。engine / method は指定していません(次世代版では自動最適化されるため設定不可)。
データを投入してベクトル検索する
ドキュメントの投入(_bulk / _doc)とベクトル検索(_search)は、引き続きデータプレーンエンドポイントへの SigV4 署名リクエストが必要です。AWS 推奨のクライアントである opensearch-py の AWSV4SignerAuth を使い、署名サービス名 aoss でアクセスします。
検証コード:dataplane_vector_search.py (クリックで展開)
#!/usr/bin/env python3
"""次世代 OpenSearch Serverless (VECTORSEARCH, NextGen) のデータプレーン検証.
AWS 推奨の公式クライアント opensearch-py の AWSV4SignerAuth で SigV4 署名し、
control-plane の create-index で定義済みの products インデックスへ
ドキュメントを投入し、knn ベクトル検索を実行する。署名サービス名は 'aoss'。
次世代版はカスタムドキュメント ID に対応するため、id を明示指定する。
"""
import argparse
import time
import boto3
from opensearchpy import OpenSearch, RequestsHttpConnection
try:
from opensearchpy import AWSV4SignerAuth
except ImportError: # 古いバージョン互換
from opensearchpy.helpers.signer import AWSV4SignerAuth
REGION = "us-east-1"
SERVICE = "aoss"
# 次世代版のエンドポイント形式は <collection-id>.aoss.<region>.on.aws
HOST = "8kz9vpajkj4gvm8um9he.aoss.us-east-1.on.aws"
INDEX = "products"
credentials = boto3.Session().get_credentials()
auth = AWSV4SignerAuth(credentials, REGION, SERVICE)
client = OpenSearch(
hosts=[{"host": HOST, "port": 443}],
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
pool_maxsize=20,
timeout=30, # scale-to-zero からのコールドスタート(約10秒)を吸収
max_retries=3,
retry_on_timeout=True,
)
# 次世代版はカスタムドキュメント ID に対応するため id を指定する
# 実際の埋め込みモデルで生成したものではなく、解説用に手で決めた「ダミーの 3 次元ベクトル」
# 第1次元 ≈ audio らしさ/第2次元 ≈ furniture らしさ/第3次元 ≈ accessories
DOCS = [
{"id": "p001", "description": "Wireless noise-cancelling headphones", "category": "audio", "embedding": [0.92, 0.10, 0.08]},
{"id": "p002", "description": "Bluetooth portable speaker", "category": "audio", "embedding": [0.85, 0.20, 0.12]},
{"id": "p003", "description": "Ergonomic mesh office chair", "category": "furniture", "embedding": [0.10, 0.90, 0.20]},
{"id": "p004", "description": "Electric standing desk", "category": "furniture", "embedding": [0.12, 0.82, 0.30]},
{"id": "p005", "description": "Mechanical RGB keyboard", "category": "accessories", "embedding": [0.20, 0.25, 0.90]},
]
def index_docs():
print("=== STEP 10-a: ドキュメント投入 (custom doc ID / AWSV4SignerAuth, service=aoss) ===")
for d in DOCS:
body = {k: v for k, v in d.items() if k != "id"}
resp = client.index(index=INDEX, id=d["id"], body=body) # 次世代版は custom doc ID 対応
print(f" id={d['id']} result={resp.get('result')} _id={resp.get('_id')}")
print(f"投入完了: {len(DOCS)} 件")
def search():
print("\n=== STEP 10-b: knn ベクトル検索 (AOSS 非同期リフレッシュのためリトライ) ===")
knn_query = {
"size": 3,
"query": {"knn": {"embedding": {"vector": [0.88, 0.15, 0.10], "k": 3}}},
"_source": ["description", "category"],
}
print("クエリベクトル: [0.88, 0.15, 0.10] (audio 系に近い), k=3")
start = time.time()
hits = []
for attempt in range(1, 25):
res = client.search(index=INDEX, body=knn_query)
hits = res.get("hits", {}).get("hits", [])
elapsed = int(time.time() - start)
print(f"[試行{attempt}/{elapsed}s] took={res.get('took')}ms hits={len(hits)}")
if len(hits) >= 3: # k=3 の全件が揃うまで待つ(部分反映で止まらないように)
print("\n--- 検索結果 (knn 類似度スコア順) ---")
for h in hits:
src = h["_source"]
print(f" _id={h['_id']} score={h['_score']:.5f} [{src.get('category')}] {src.get('description')}")
break
time.sleep(6)
if not hits:
print("\n(注意: 反映待ちタイムアウト)")
raise SystemExit(2)
def main():
parser = argparse.ArgumentParser(
description="次世代 OpenSearch Serverless (VECTORSEARCH) のデータプレーン検証"
)
parser.add_argument(
"-s",
"--search-only",
action="store_true",
help="ドキュメント投入をスキップし knn ベクトル検索のみ実行する(重複投入の回避・順位の揺らぎ確認に便利)",
)
args = parser.parse_args()
if args.search_only:
print("=== STEP 10-a: ドキュメント投入をスキップ (--search-only) ===")
else:
index_docs()
search()
if __name__ == "__main__":
main()
カスタムドキュメント ID(p001〜p005)を指定して投入しています。次世代版は custom doc ID に対応しているため、client.index(id=...)(PUT /products/_doc/<id> 相当)で任意の ID を指定できます(Classic では非対応でシステム採番のみでした)。投入直後は非同期リフレッシュのため検索結果が段階的に揃い、今回は約 18 秒で全 5 件が反映されました。
=== STEP 10-a: ドキュメント投入 (custom doc ID / AWSV4SignerAuth, service=aoss) ===
id=p001 result=created _id=p001
id=p002 result=created _id=p002
id=p003 result=created _id=p003
id=p004 result=created _id=p004
id=p005 result=created _id=p005
投入完了: 5 件
=== STEP 10-b: knn ベクトル検索 (AOSS 非同期リフレッシュのためリトライ) ===
クエリベクトル: [0.88, 0.15, 0.10] (audio 系に近い), k=3
[試行1/18s] took=18117ms hits=3
--- 検索結果 (knn 類似度スコア順) ---
_id=p002 score=0.99621 [audio] Bluetooth portable speaker
_id=p001 score=0.99552 [audio] Wireless noise-cancelling headphones
_id=p004 score=0.48391 [furniture] Electric standing desk
audio 系のクエリベクトルに対して、audio カテゴリの商品(speaker・headphones)が高いスコアで上位に来ました。投入時に指定した _id(p001とp002)がそのまま返っている点にも注目してください。手元で L2 距離(ユークリッド距離)の二乗 d² を計算したスコア 1/(1+d²) とも一致しており(speaker は d²=0.0038 → 0.99621)、ベクトル検索が正しく機能していることを確認できました。
| 順位 | 商品 (_id) |
embedding | クエリとの距離² d² |
スコア 1/(1+d²) |
|---|---|---|---|---|
| 1 | speaker (p002) |
[0.85,0.20,0.12] |
0.0038 | 0.99621 |
| 2 | headphones (p001) |
[0.92,0.10,0.08] |
0.0045 | 0.99552 |
| 3 | standing desk (p004) |
[0.12,0.82,0.30] |
1.0665 | 0.48391 |
なお _source を指定しない場合、次世代版では検索レスポンスから embedding が除外されます。レイテンシとペイロード削減のためと考えられます。
考察
実際に試してみて得られた知見と注意点を整理します。
- scale-to-zero とコスト: Collection Group の最小キャパシティを省略することで、アイドル時に OCU がゼロまで縮退します。今回の検証では待機中の課金は発生せず、実際に OCU が稼働したのはインデックス作成・データ投入・検索のごく短時間のみでした。前世代の「最小 2 OCU(レプリカ有効時 4 OCU)常時課金」と比べると、検証用途や間欠的なワークロードでのコストメリットは大きいと考えられます。
- 世代は
--generation NEXTGENで指定する(重要): 次世代版にするにはcreate-collection-groupに--generation NEXTGENを指定します(省略すると Classic)。v2.34.57 に更新すると--generation(CLASSIC/NEXTGEN)が使えるようになり、create-collection-groupのレスポンスに"generation": "NEXTGEN"が返ることで世代を確認できます。コレクションは Collection Group の世代を継承するため、create-collection側に--generationはありません。 - NextGen 特有の制約・挙動: 実機で確認できた Classic との主な違いは次のとおりです。
- StandbyReplicas は
ENABLED必須(DISABLEDはValidationException。Classic はDISABLED可) - カスタムドキュメント ID に対応(
PUT /_doc/<id>で任意の ID を指定可能。Classic は非対応でシステム採番のみ) - 検索レスポンスはデフォルトで元ベクトルを除外(
_sourceにembeddingが含まれない。必要なら_source: true) - コレクションエンドポイントが
<id>.aoss.<region>.on.aws形式(Classic は<id>.<region>.aoss.amazonaws.com)。dashboardEndpointは払い出されない - プロビジョニングが高速(コレクション ACTIVE まで約 15 秒。Classic は約 4 分)
- GPU 加速(
ServerlessVectorAcceleration)がデフォルト有効
- StandbyReplicas は
- コントロールプレーンの create-index: インデックスのマッピングを CLI から定義できるため、IaC やセットアップスクリプトに組み込みやすくなりました。一方で、ドキュメントの投入や検索は引き続きデータプレーンエンドポイントへの SigV4 署名リクエストが必要です。
- データプレーンの SigV4 署名は opensearch-py が確実: 当初 botocore の
SigV4Authで手動署名したところ、ボディなしのリクエスト(GET 系やPUT /<index>)は成功するのに、ボディありのリクエスト(POST /_doc・_bulk・POST /_search)が一律 403 Forbidden になりました。同じ読み取り権限・同じリソースでもGET /_searchは成功しPOST /_searchは失敗したことから、権限ではなくペイロードハッシュ(x-amz-content-sha256)の整合の問題だと切り分けられました。opensearch-py のAWSV4SignerAuth(署名サービス名aoss)に切り替えることで解消できたため、データプレーンへのアクセスは公式クライアントの利用をおすすめします。 - 非同期リフレッシュ: 投入直後の検索は反映待ちで結果が安定しないことがあります。数秒から十数秒のリフレッシュを見込んで、リトライする実装にしておくと安全です。
- CLI の細かな差異:
delete-collection-groupは--nameではなく--idを要求します(--name指定では ParamValidation エラーになりました)。 - 対応状況: コレクションタイプはローンチ時点で SEARCH と VECTORSEARCH のみで、TIMESERIES は非対応です。また VECTORSEARCH の
engineプロパティは次世代版では設定できません(GPU アクセラレーションは自動適用され、課金は独立計上されます)。
最後に
次世代 Amazon OpenSearch Serverless を、Collection Group の作成から VECTORSEARCH コレクション・コントロールプレーンの create-index・ベクトル検索まで一通り試しました。
scale-to-zero により「使うときだけ課金」が実現され、コントロールプレーンからインデックス定義まで行えるようになったことで、AI エージェントが必要に応じてベクトル検索を起動するようなワークロードに組み込みやすくなっています。一方で、ドキュメント投入・検索のデータプレーンアクセスは従来どおり SigV4 署名が必要で、公式クライアント opensearch-py の利用が確実です。
前世代から移行する場合は、新しい Collection Group とコレクションを作成し、Amazon OpenSearch Ingestion などでデータを再インデックスする流れが案内されています。ベクトル検索基盤を検討されている方は、まず小さなコレクションで scale-to-zero とベクトル検索の挙動を確かめてみると、コスト感と使い勝手がつかめると思います。












