Google Cloud Translation API で Word を PDF にして、再度 Word にして翻訳してみた
こんにちは、けーまです。
Word で作った資料を翻訳するとき、本文や表は訳せても、テキストボックスや図形の中に入れた文章だけが日本語のまま残ってしまうことがあります。
これは Cloud Translation の Document Translation で DOCX をそのまま翻訳したときの仕様で、公式にも「テキストボックス内の文字列は翻訳されず原文のまま残る」と明記されています。
ポンチ絵やフロー図、吹き出しを多用した資料ほど、この「翻訳されないテキストボックス」が問題になります。
そこで本記事では、いったん Word を PDF にしてから、Cloud Translation の PDF→DOCX 変換(バッチ翻訳の format_conversions)を使って、テキストボックスや図形の中身ごと翻訳した DOCX を取り出せるかを実際に試しました。
PDF を経由するとテキストボックスが翻訳対象になるのではないか、という仮説の検証です。
本記事は、ドキュメント翻訳を形式別に検証してきたシリーズの続きです。
これまで PDF・Word・Excel・PowerPoint を扱ってきましたが、今回はその応用編として、Word のテキストボックスを翻訳するために PDF→DOCX 変換を使う、という 5 本目になります。
仕様や挙動は Google Cloud の公式ドキュメントで確認し、該当箇所を引用しています。
そのうえで、公式の記載どおりになるかを実際に動かして検証しました。
シリーズ記事
| 形式 | 記事 |
|---|---|
| PDF 編 | Google Cloud Translation API で PDF を丸ごと翻訳してみた |
| Word 編 | Google Cloud Translation API で Word を丸ごと翻訳してみた |
| Excel 編 | Google Cloud Translation API で Excel を丸ごと翻訳してみた |
| PowerPoint 編 | Google Cloud Translation API で PowerPoint を丸ごと翻訳してみた |
| PDF→DOCX 変換編(本記事) | - |
対象読者:Word のテキストボックスや図形に入れた文章まで翻訳したい方
1. 結論:公式ドキュメントの記載と実証結果
急いで結論だけ知りたい方向けに、先にまとめます。
Word を DOCX のまま翻訳するとテキストボックスは翻訳されませんが、いったん PDF にして バッチ翻訳の PDF→DOCX 変換を使うと、テキストボックスや図形の中身まで翻訳された DOCX が得られます。
まず、3 つの翻訳方法の違いです。
| 方法 | 入力→出力 | テキストボックス・図形の中身 | 帰属表示 | 処理時間 |
|---|---|---|---|---|
| ① Word を直接翻訳(同期) | DOCX → DOCX | 翻訳されない(原文のまま) | なし | 速い |
| ② PDF を翻訳(同期) | PDF → PDF | 翻訳される | 焼き込まれる | 約 1.4 秒 |
| ③ PDF→DOCX 変換(バッチ・本記事) | PDF → DOCX | 翻訳される | なし | 約 9.6 分 |
そのうえで、③ の PDF→DOCX 変換について、公式の記載と実証結果をまとめます。
| 観点 | 公式ドキュメントの記載 | 実証結果(本記事で確認) |
|---|---|---|
| PDF→DOCX 変換の可否 | バッチ翻訳かつネイティブ PDF のみ対応 | format_conversions で DOCX として出力できた |
| テキストボックス・図形の中身 | DOCX 直接翻訳では「翻訳されない」と明記 | PDF を経由すると翻訳された |
| 用語集(独自用語の固定) | 用語集で訳語を固定できる | 本文・表・図形・テキストボックスに適用された |
| 画像 | (明記なし) | 画像として保持され、中の文字は日本語のまま |
| 表 | 複雑なレイアウトは整形が崩れる場合がある | Word の表ではなく、罫線つきの配置テキストになった |
| レイアウトの忠実度 | ネイティブ形式の方が PDF より保持に優れる | テキストボックスは保たれたが、フォント縮小・表の崩れなど崩れる箇所もあった |
いちばんのポイントは、DOCX のままでは翻訳されないテキストボックス・図形が、PDF を経由すると翻訳されることです。
ただし PDF→DOCX 変換はバッチ翻訳でしか使えず、処理に数分かかり、レイアウトの忠実度も DOCX 直接翻訳より落ちます。
「テキストボックスや図形の中身をどうしても翻訳したい」という目的に絞った方法、という位置づけになります。
2. PDF→DOCX 変換(format_conversions)とは
Cloud Translation の Document Translation は、ファイルをそのまま渡すと書式やレイアウトを保ったまま翻訳して返す機能です。
機能の概要や認証は、これまでの記事で扱いました。
引用元: DevelopersIO: Google Cloud Translation API で PDF を丸ごと翻訳してみた
テキストボックスが翻訳されないという仕様
まず押さえておきたいのが、対応形式の表に書かれた注釈です。
DOC・DOCX には「テキストボックス内の文字列は翻訳されず原文のまま残る」と明記されています。
Content inside text boxes aren't translated and remain in the source language.
引用元: 公式ドキュメント: Translate documents | Google Cloud
一方、入力と出力の対応表を見ると、PDF の出力には PDF だけでなく DOCX も選べることがわかります。
| 入力 | 出力 |
|---|---|
| DOCX | DOCX |
| PDF, DOCX | |
| PPTX | PPTX |
| XLSX | XLSX |
引用元: 公式ドキュメント: Translate documents | Google Cloud
PDF→DOCX 変換の条件
この PDF→DOCX 変換には、いくつか条件があります。
Support for PDF to DOCX conversions is available for batch document translations on native PDF files only.
引用元: 公式ドキュメント: Translate documents | Google Cloud
- バッチ翻訳(
batchTranslateDocument)でのみ使える。リアルタイムの同期翻訳(translateDocument)では PDF→DOCX 変換はできません。 - ネイティブ PDF 限定。スキャン PDF を混ぜるとリクエスト全体が拒否されます(Word から書き出した PDF はネイティブ PDF なので問題ありません)。
- バッチ翻訳は Cloud Storage 入力・Cloud Storage 出力で、完了まで待つ長時間オペレーション(LRO)です。
- 用語集と同じく
globalロケーションは使えず、us-central1などを指定します。
公式ドキュメントにも、複雑な PDF レイアウトでは整形が崩れる場合があると明記されています。
Complex PDF layouts can also result in some formatting loss, which can include data tables, multi-column layouts, and graphs with labels or legends.
引用元: 公式ドキュメント: Translate documents | Google Cloud
つまり、PDF→DOCX 変換は「テキストボックスを翻訳できる」という利点と引き換えに、レイアウトの崩れというリスクを抱えています。
このトレードオフを、実際に動かして確かめます。
3. 検証の準備
3.1 前提環境
前提環境は Word 編・Excel 編・PowerPoint 編と同じです(macOS、Python 3.12 系の venv、google-cloud-translate 3.26.0、課金を有効化した個人プロジェクト)。
API の有効化、ADC 認証、venv へのライブラリ導入の手順も共通です。
バッチ翻訳では Cloud Storage を使うため、入力ファイルの読み取りと出力先への書き込みができる権限(roles/storage.objectViewer など)が必要です。
3.2 サンプル文書(Word をいったん PDF にする)
検証用に、これまでのシリーズと同じ架空アニメ「星霊物語 ルミナ・クロニクル」の Word 資料を使います。
この Word には、本文や表のほかに、Word 編では翻訳されなかった要素を意図的に入れてあります。
- 「みどころ」やキャラクター紹介を入れたテキストボックス
- 四角・角丸・楕円などの図形に入れた文章
- 世界設定の 2 カラムのメモ(テキストボックス)
- 画像として貼った棒グラフ
- キービジュアル画像
この Word を、まず PDF として書き出します。
Word の「ファイル」→「名前を付けて保存」または「PDF として書き出す」で、ネイティブ PDF を作成します(スキャンではなく、文字情報を持った PDF になります)。
今回 PDF にした元の Word は、全 4 ページの構成です。
翻訳前の全ページを載せておきます。

翻訳前 1 ページ目:タイトル、本文、キービジュアル画像、「みどころ」テキストボックス、2 カラムの世界設定メモ、星霊図鑑の表

翻訳前 2 ページ目:星霊図鑑の表(続き)、用語解説、第一章あらすじ

翻訳前 3 ページ目:人気星霊ランキングの棒グラフ(画像)、制作メモ(テキストボックス)、四角・角丸・楕円の図形、放送情報の表

翻訳前 4 ページ目:放送情報の表(続き)と免責注記
4. 用語集を用意する
今回は、独自用語を決まった訳に固定する用語集を最初から適用して翻訳します。
そのため、先に用語集を用意してから、次の §5 で翻訳を実行します。
用語集の仕組みや TSV の考え方は、これまでの記事でも扱っています。
ここでは、この記事だけで再現できるよう、用語集を作る手順を再掲します(すでに作成済みなら §5 へ進んでください)。
4.1 用語集の TSV を用意する
用語集は、原文(日本語)と訳語(英語)をタブ区切りで並べた TSV として用意します。
今回はシリーズで使ってきた造語 20 語を glossary_ja_en.tsv として用意しました。
星霊 Hoshirei
共鳴進化 Reso-Evolution
輝光石 Lumina Shard
雷狼ボルテ Voltefang
焔狐ココ Pyrofox Coco
水亀アクオ Aquortle
草鹿リーフィ Leafawn
輝竜ルミナ Lumidragon
月読の祠 Moonread Shrine
守護者 Warden
星導士 Starwright
星霊守護協会 Hoshirei Warden Guild
共鳴値 Reso-Value
共鳴の灯 Resonance Flame
絆ゲージ Bond Gauge
星霊酔い Hoshirei-sickness
星霊図鑑 Hoshirei Codex
ルミナ群島 Lumina Archipelago
七つの祠 Seven Shrines
共鳴結界 Reso-Barrier
4.2 用語集リソースを作成する
TSV を Cloud Storage に置き、その GCS URI から用語集リソースを作成します。バケットは用語集と同じ us-central1 にします。
gcloud storage cp glossary_ja_en.tsv \
gs://<YOUR_BUCKET>/glossaries/glossary_ja_en.tsv
用語集リソースの作成は長時間オペレーション(LRO)なので、クライアントライブラリから実行して完了を待ちます。
setup_glossary.py の全文(クリックすると展開します)
from google.cloud import translate_v3 as translate
PROJECT_ID = "<YOUR_PROJECT_ID>"
LOCATION = "us-central1" # 用語集は us-central1 のみ
GLOSSARY_ID = "hoshirei-ja-en"
INPUT_URI = "gs://<YOUR_BUCKET>/glossaries/glossary_ja_en.tsv"
client = translate.TranslationServiceClient()
name = client.glossary_path(PROJECT_ID, LOCATION, GLOSSARY_ID)
glossary = translate.Glossary(
name=name,
# 単方向(ja→en)の用語集
language_pair=translate.Glossary.LanguageCodePair(
source_language_code="ja", target_language_code="en"
),
input_config=translate.GlossaryInputConfig(
gcs_source=translate.GcsSource(input_uri=INPUT_URI)
),
)
parent = f"projects/{PROJECT_ID}/locations/{LOCATION}"
operation = client.create_glossary(parent=parent, glossary=glossary)
result = operation.result(180) # 完了を最大180秒待つ
print(f"作成完了: {result.name}(エントリ数: {result.entry_count})")
python setup_glossary.py
5. PDF→DOCX 変換で翻訳する
用語集が用意できたので、PDF→DOCX 変換つきで翻訳します。
5.1 バッチ用のスクリプト
バッチ翻訳は Cloud Storage 入出力なので、同期翻訳のスクリプトとは別に、バッチ用のスクリプトを用意します。
ポイントは、format_conversions で「PDF を DOCX に変換する」と指定するところです。
用語集は、同期翻訳の glossary_config(単数)ではなく、バッチ翻訳では glossaries(ターゲット言語ごとのマップ)で指定します。
batch_translate_convert.py の全文(クリックすると展開します)
from __future__ import annotations
import argparse
import time
from google.cloud import translate_v3 as translate
# バッチ翻訳・用語集・PDF→DOCX変換は us-central1 のみ(global 不可)
DEFAULT_LOCATION = "us-central1"
PDF_MIME = "application/pdf"
DOCX_MIME = "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
def parse_args() -> argparse.Namespace:
p = argparse.ArgumentParser(
description="Cloud Translation バッチ翻訳(ネイティブPDF→DOCX変換つき)"
)
p.add_argument("--project", required=True, help="GCP プロジェクト ID")
p.add_argument("--input-uri", required=True, help="入力ファイルの GCS URI(gs://...)")
p.add_argument(
"--output-uri", required=True, help="出力先 GCS URI プレフィックス(空ディレクトリ)"
)
p.add_argument("--source", default="ja", help="原文言語コード(既定: ja)")
p.add_argument("--target", default="en", help="訳文言語コード(既定: en)")
p.add_argument("--location", default=DEFAULT_LOCATION)
p.add_argument("--glossary-id", default=None, help="用語集 ID(指定時は用語集を適用)")
p.add_argument(
"--convert-to-docx",
action="store_true",
help="ネイティブ PDF を DOCX に変換して出力する",
)
p.add_argument("--timeout", type=int, default=600, help="LRO 完了待ちの秒数")
return p.parse_args()
def build_request(args: argparse.Namespace) -> dict:
parent = f"projects/{args.project}/locations/{args.location}"
request: dict = {
"parent": parent,
"source_language_code": args.source,
"target_language_codes": [args.target],
"input_configs": [{"gcs_source": {"input_uri": args.input_uri}}],
"output_config": {"gcs_destination": {"output_uri_prefix": args.output_uri}},
}
# ネイティブ PDF → DOCX 変換
if args.convert_to_docx:
request["format_conversions"] = {PDF_MIME: DOCX_MIME}
# 用語集(バッチはターゲット言語ごとのマップ。同期の glossary_config とは書式が違う)
if args.glossary_id:
glossary_path = (
f"projects/{args.project}/locations/{args.location}"
f"/glossaries/{args.glossary_id}"
)
request["glossaries"] = {
args.target: translate.TranslateTextGlossaryConfig(glossary=glossary_path)
}
return request
def main() -> None:
args = parse_args()
client = translate.TranslationServiceClient()
request = build_request(args)
print(f"入力 : {args.input_uri}")
print(f"出力先: {args.output_uri}")
print(f"変換 : {'PDF→DOCX' if args.convert_to_docx else 'なし(同形式)'}")
print(f"用語集: {args.glossary_id or 'なし'}")
started = time.perf_counter()
operation = client.batch_translate_document(request=request)
print("バッチ翻訳を開始しました(LRO)。完了を待っています...")
response = operation.result(args.timeout)
elapsed = time.perf_counter() - started
print(f"処理時間 : {elapsed:.2f} 秒")
print(f"総ページ数: {response.total_pages}")
print(f"翻訳文字数: {response.translated_characters}")
print(f"失敗文字数: {response.failed_characters}")
if __name__ == "__main__":
main()
5.2 入力 PDF を置いて実行する
まず、PDF 化した Word をバケットにアップロードします。
出力先のディレクトリは、公式ドキュメントで「存在し、かつ空である必要がある」と定められています。
The destination of output. The destination directory provided must exist and be empty.
すでに何か入っているディレクトリを出力先に指定しないよう、空のプレフィックスを使います。
# 入力 PDF をアップロード
gcloud storage cp hoshirei_word_ja.pdf \
gs://<YOUR_BUCKET>/batch_in/hoshirei_word_ja.pdf
用語集を指定して、PDF→DOCX 変換つきで実行します。
--convert-to-docx で format_conversions(PDF→DOCX)を、--glossary-id で §4 で作成した用語集を有効にします。
python batch_translate_convert.py \
--project <YOUR_PROJECT_ID> \
--input-uri gs://<YOUR_BUCKET>/batch_in/hoshirei_word_ja.pdf \
--output-uri gs://<YOUR_BUCKET>/batch_out/ \
--glossary-id <YOUR_GLOSSARY_ID> \
--convert-to-docx
# 出力例
入力 : gs://<YOUR_BUCKET>/batch_in/hoshirei_word_ja.pdf
出力先: gs://<YOUR_BUCKET>/batch_out/
変換 : PDF→DOCX
用語集: hoshirei-ja-en
バッチ翻訳を開始しました(LRO)。完了を待っています...
処理時間 : 577.18 秒
総ページ数: 4
翻訳文字数: 3916
失敗文字数: 0
処理時間は約 9.6 分(577 秒)でした。
同期翻訳の約 1.4 秒と比べると桁違いに遅く、これはバッチ翻訳が完了まで待つ長時間オペレーションであるためです。
PDF→DOCX 変換を使いたい場合は、この処理時間を前提に、まとめて流すバッチ処理として組むのがよさそうです。
5.3 出力をダウンロードする
バッチ翻訳が完了すると、出力先に index ファイルと翻訳結果が書き出されます。
用語集を指定したので、用語集なしの結果(..._translation.docx)と、用語集ありの結果(..._glossary_translation.docx)の両方が出力されます。
gcloud storage ls gs://<YOUR_BUCKET>/batch_out/
# index.csv
# ..._en_translation.docx
# ..._en_glossary_translation.docx
gcloud storage cp "gs://<YOUR_BUCKET>/batch_out/*" ./output/
5.4 翻訳結果を確認する
得られた DOCX を開くと、本文や表に加えて、テキストボックスや図形の中身まで翻訳されていました。
全 4 ページの翻訳前後を並べます。
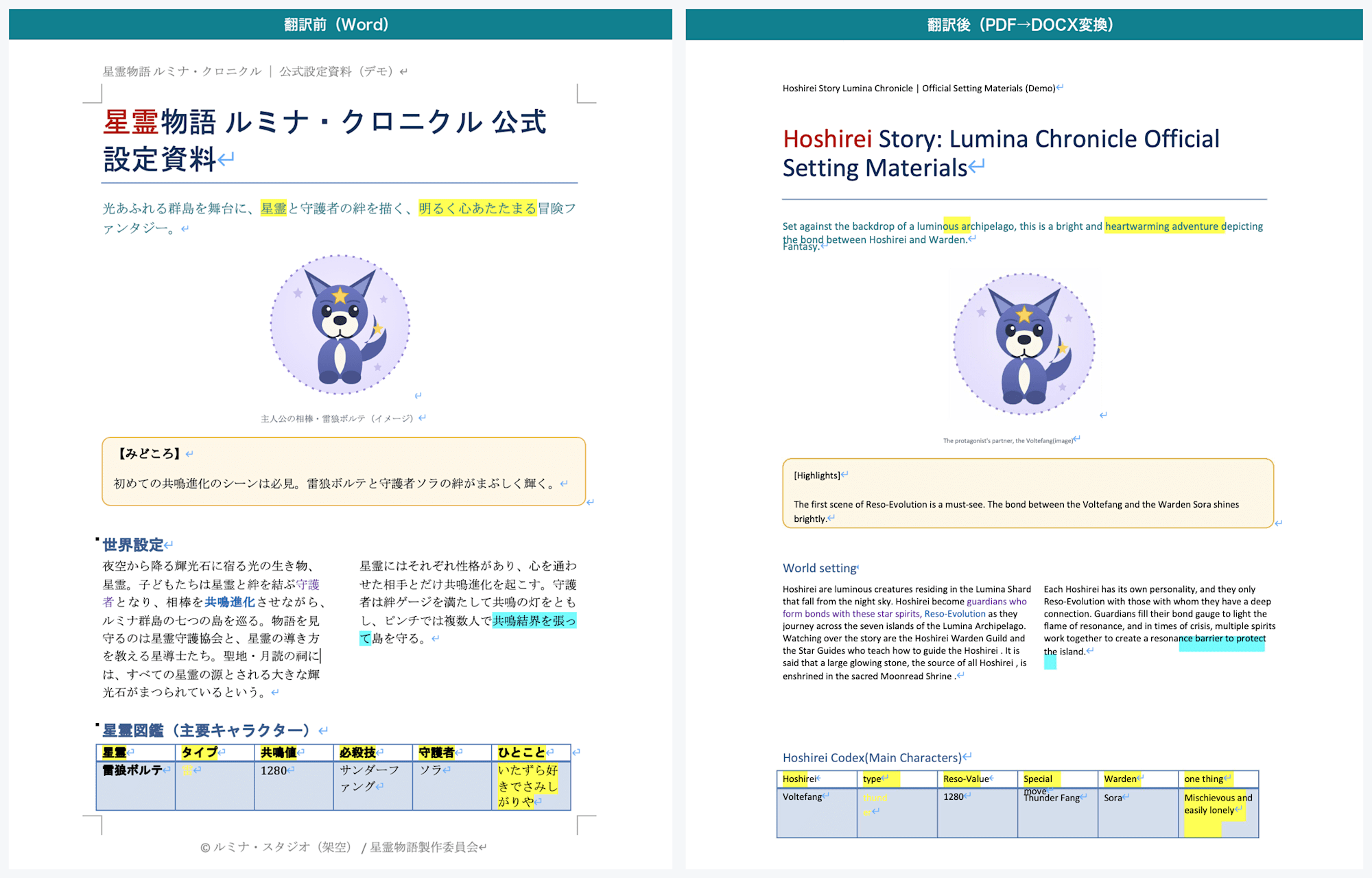
1 ページ目:左が翻訳前(Word)、右が翻訳後(PDF→DOCX 変換)。「みどころ」テキストボックスも、世界設定の 2 カラムメモも翻訳される
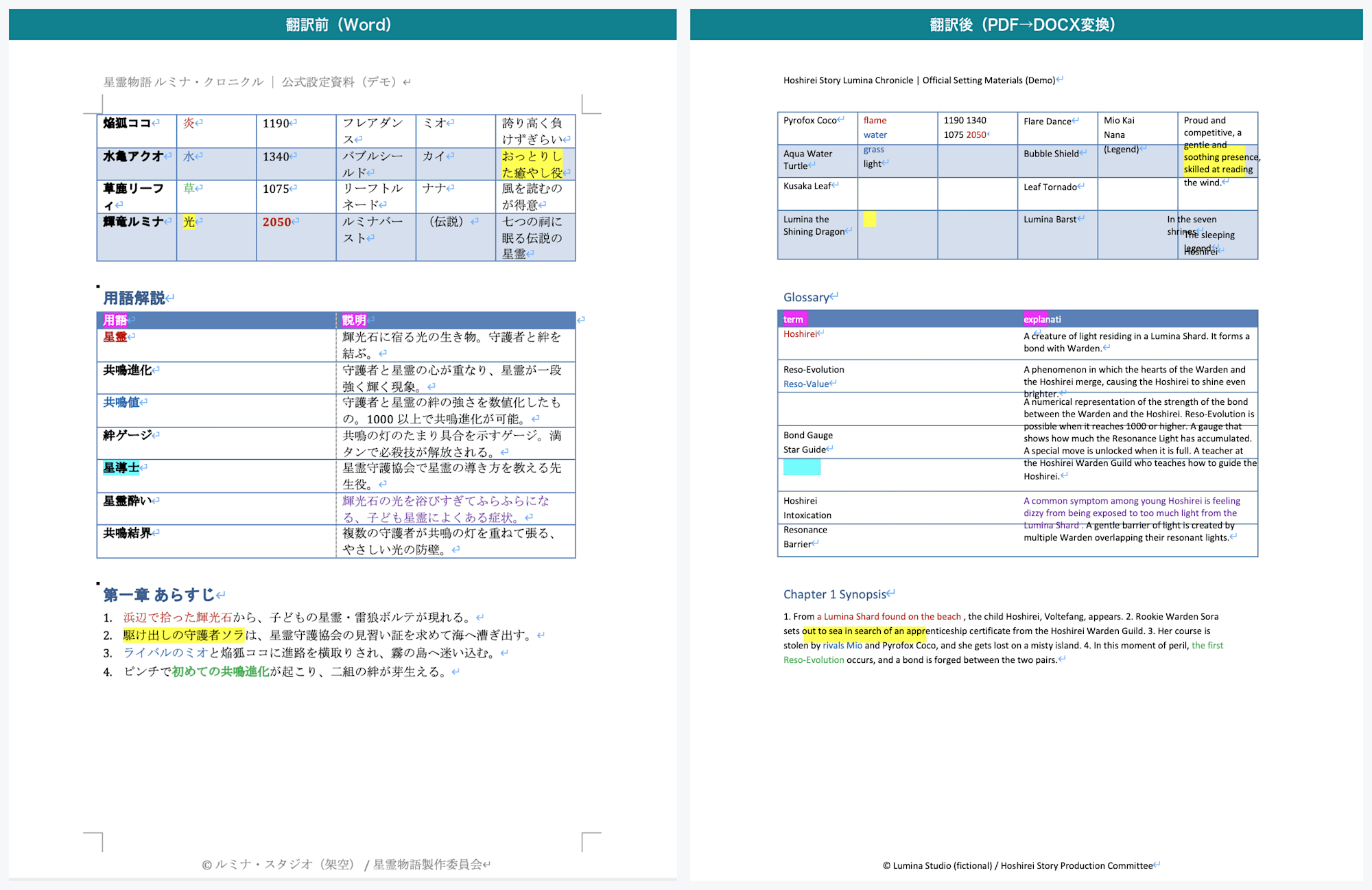
2 ページ目:左が翻訳前、右が翻訳後。星霊図鑑・用語解説・あらすじが翻訳される
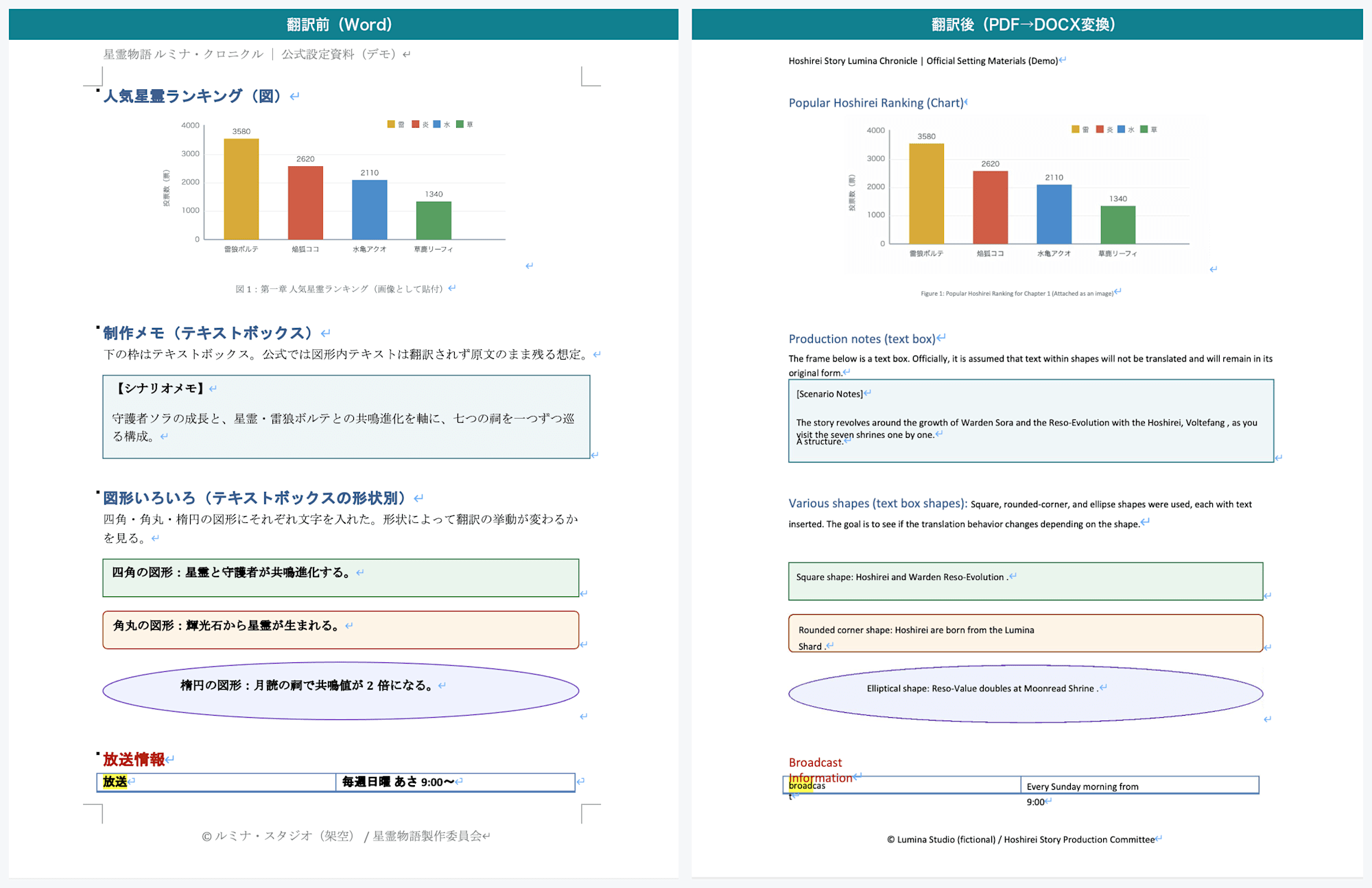
3 ページ目:左が翻訳前、右が翻訳後。四角・角丸・楕円の図形の中身が翻訳される。棒グラフ(画像)の中の文字は日本語のまま
4 ページ目:左が翻訳前、右が翻訳後。放送情報や話数が翻訳される
図形・テキストボックスの中身も翻訳される
Word を DOCX のまま翻訳したときは、テキストボックスや図形の中身は翻訳されず原文のまま残りました。
ところが PDF→DOCX 変換では、これらがすべて翻訳されていました。
- 四角の図形:
Square shape: Hoshirei and Warden Reso-Evolution. - 角丸の図形:
Rounded corner shape: Hoshirei are born from the Lumina Shard. - 楕円の図形:
Elliptical shape: Reso-Value doubles at Moonread Shrine.
世界設定の 2 カラムメモや、「みどころ」「制作メモ」のテキストボックスも翻訳されました。
DOCX をそのまま翻訳すると原文のまま残るこれらの要素が、PDF を経由することで翻訳対象になっています。
ここが今回いちばん効いたポイントです。
画像は翻訳されない
人気ランキングの棒グラフは、グラフのように見えますが画像として貼ったものです。
そのため、グラフ内のラベル(雷狼ボルテなどのカテゴリ名や軸ラベル)は日本語のまま残りました。
キービジュアル画像も同様で、画像として配置したものは中の文字も画像の一部なので翻訳されません。
出力 DOCX には元の画像がそのまま保持されていました。
表は「Word の表」ではなくなる
翻訳結果を見ると、星霊図鑑や用語解説の表は、見た目には罫線つきの表に見えます。
ただし DOCX の中身を調べると、これらは Word の表(テーブル)ではなく、罫線つきで配置されたテキストになっていました。
さらに、表のセルの対応が崩れている箇所もありました。
たとえば星霊図鑑では、あるキャラクターのセルに、本来は別の行にある複数の数値がまとめて入ってしまっていました。
公式が「複雑な PDF レイアウトでは表が崩れる場合がある」と書いているとおりで、表として再編集したい場合には注意が必要です。
レイアウトは保たれる箇所と崩れる箇所がある
段落や画像は保持され、ページ構成(今回は全 4 ページ)も元の資料に近い形で再現されました。
元の Word に付けていた蛍光ペンの装飾も、翻訳後におおむね残っていました。
一方で、崩れる箇所もありました。
- フォントサイズ:Word を DOCX のまま翻訳したときはフォントサイズが保たれましたが、PDF→DOCX 変換では、英語の文章を日本語の配置幅に収めるためか、元より小さいフォントで配置される箇所がありました。
- 背景色(セルの塗り):星霊図鑑の見出しなどの背景色は、日本語のセルに対応する形では完全には再現されず、位置がずれて適用されている箇所がありました。
- 表の配置:前述のとおり、セルの対応が崩れて数値が混ざる箇所がありました。
テキストボックスや図形の翻訳という目的はうまく達成できましたが、レイアウトは「保たれる箇所もあれば崩れる箇所もある」というのが実際のところです。
出力先が Word(DOCX)なので、開いてから手で直せる余地はありますが、そのまま完成原稿として使えるレベルではありませんでした。
5.5 用語集の効果
用語集なしの DOCX と、用語集ありの DOCX を比べると、独自用語の訳がどれだけ揃うかがはっきり分かりました(Claude調べ)。
たとえば、原文に 34 回出てくる 星霊 を用語集なしの英訳で数えると、主な訳語の内訳は次のとおりでした。
星霊 の訳(用語集なし) |
出現回数 |
|---|---|
| Star Spirit | 16 |
| star spirits | 5 |
| star spirit | 3 |
| Celestial Spirit | 2 |
| celestial spirits | 1 |
| celestial spirit | 1 |
大文字小文字や単複、さらに Celestial Spirit という別訳まで含めて、表記がばらついています。
用語集ありに切り替えると、原文 34 回の 星霊 がすべて Hoshirei に統一されました(あり版での Hoshirei の出現回数も 34 回で、原文と一致)。
ほかの造語も、守護者 → Warden、共鳴進化 → Reso-Evolution、輝光石 → Lumina Shard と、登録どおりの訳に揃いました。
ただし、完全に 100% ではありませんでした。
星導士(用語集では Starwright)は、用語集ありでも Star Guide という字義訳のままで固定されませんでした。
原文で「星導士たち」のように後ろに語が続いていたり、PDF のレイアウト上で文が改行・段組みで分割されたりすると、用語集の語境界マッチが外れて取りこぼすことがあるようです。
6. 料金
ドキュメント翻訳の料金は、標準の NMT モデルでページ単位です。
| 項目 | 単価 |
|---|---|
| NMT ドキュメント翻訳 | 0.08 ドル / ページ |
引用元: 料金ページ: Pricing | Google Cloud
料金ページで確認できる範囲では、同期・バッチの区別や、PDF→DOCX 変換に対する追加料金の記載はありませんでした(課金はページ単位で、バッチ処理のメタデータにもページ数のフィールドがあります)。
今回のサンプル(4 ページ)は、用語集あり/なしを合わせても 1 ドルに満たない規模です。
7. 帰属表示(Machine Translated by Google)について
PDF 編では、翻訳後の PDF の左上に「Machine Translated by Google」という帰属表示が焼き込まれました。
一方、今回の PDF→DOCX 変換で得た DOCX には、この表示は入っていませんでした。
確認したところ、帰属表示が入るかどうかは「PDF を経由したかどうか」ではなく、出力ファイルの形式で決まっていました。
同じ PDF を入力にしても、出力が PDF なら帰属表示が焼き込まれ、出力が DOCX なら焼き込まれません。
PDF は訳文をページ上に重ねて再構成する形式なので帰属表示を載せやすく、編集可能な DOCX とは出力の作られ方が違うため、と推測されますが、公式の記載で裏づけられたものではありません。
帰属表示の文言自体は、API のリクエストで customizedAttribution として指定でき、指定しない場合のデフォルトが「Machine Translated by Google」です。
これは translateDocument・batchTranslateDocument に共通のフィールドです。
customizedAttribution
stringOptional. This flag is to support user customized attribution. If not provided, the default is Machine Translated by Google.
引用元: API リファレンス: Method: projects.locations.translateDocument | Google Cloud
なお、出力ファイルに帰属表示が焼き込まれるかどうかとは別に、ブランドガイドライン上の明示義務があります。
翻訳結果を利用者に見せる場面では、形式にかかわらず機械翻訳であることを明示する責任が利用者側にあります。
Whenever you display translation results from Google Translate directly to users, you must make it clear to users that they are viewing automatic translations from Google Translate using the appropriate text or brand elements.
引用元: ブランドガイドライン: Attribution requirements | Google Cloud
8. まとめ
Word を DOCX のまま翻訳するとテキストボックスや図形の中身は翻訳されませんが、いったん PDF にして バッチ翻訳の PDF→DOCX 変換を使うと、テキストボックスや図形の中身まで翻訳された DOCX が得られました。
用語集も併用でき、原文 34 回の 星霊 がすべて Hoshirei に揃うなど、独自用語をしっかり固定できました(一部に取りこぼしあり)。
一方で、代償もはっきりしています。
- 表が Word のテーブルではなく、罫線つきの配置テキストになる(セルの対応が崩れる箇所もある)
- フォントサイズや背景色など、レイアウトが崩れる箇所がある
- 画像の中の文字は翻訳されない(画像として保持される)
- 処理に数分かかる(バッチ翻訳のため)
公式も「ネイティブ形式(DOCX・PPTX)の翻訳は、PDF よりレイアウトの保持に優れる」と明記しています。
レイアウトをきれいに保ちたいなら、本来は元の形式のまま翻訳するのが王道です。
PDF→DOCX 変換は、それでは翻訳されないテキストボックスや図形の中身を、どうしても翻訳したいときの選択肢、という位置づけになります。
これまでのシリーズと合わせると、Word を翻訳する場合は、次のように使い分けるのがよさそうです。
- レイアウトを保ちたい・テキストボックスをそこまで使っていない場合:DOCX をそのまま翻訳する
- テキストボックスや図形が多く、その中身も翻訳したい場合:いったん PDF にして PDF→DOCX 変換を使う(レイアウトの崩れは許容する)
本シリーズが、Word 文書の翻訳自動化を考えている方の参考になればうれしいです。






