
Azure AI Search(Foundry IQ)とMicrosoft FoundryでRAGをつくる
これまでのドキュメントを知見として活かしたい!
製造ビジネステクノロジー部・浅野です。
私、実はエンジニアとして働くかたわらで、短歌をつくったり論じたりする歌人としても活動しています。
活動歴として十数年、いろいろな場所で短歌について文章を書かせてもらったのですが、意外と悩むのが発表後の文章の活用です。
発表して誰かに読んでもらったらそれだけでも万々歳なのですが、せっかくがんばって書いた文章、できればもっと有効活用したい!
そこで今回は、Azure AI Search(Foundry IQ)とMicrosoft Foundryを中心としたRetrieval-augmented generation(RAG)を作成し、自分の書いた文章をもとにAIに回答してもらえるようにしてみます。
うまくいけば、自分が忘れているような文章まで、AIに探してもらって活用できるかもしれません!
Azure AI Search(Foundry IQ)とは?
Azure AI Searchとは、データをAIで活用するための検索サービスです。
クラシック検索とエージェント検索の2つのエンジンを備え、フルテキスト・ベクター・ハイブリッド・マルチモーダル検索に対応しています。
一方でFoundry IQは、Azure AI Searchを基盤として構築された、マネージドなナレッジレイヤーです。
AIエージェントが効率的にナレッジを活用するための仕組みを提供します。
Microsoft Foundryとは?
Microsoft Foundryは、AIアプリやエージェントの構築・管理を行うためのAIプラットフォームです。
モデル・エージェントフレームワーク・ナレッジ・ツールなど、AIを活用したアプリ・エージェントを開発・運用するための機能がまとまっています。
旧来、Azure AI Studio / Azure AI Foundry と呼ばれていたサービスが、より統合された形で提供されています。
やってみる
前提・注意事項
- 本記事ではリソースのリージョンとして
(Europe) Sweden Centralを指定しています。筆者が試したタイミングと利用プランの範囲では、Microsoft Foundryで特定のモデルを利用できるリージョンが限られていたのですが、そのなかでできる限り同じリージョンにリソースを置きたかったために、このリージョンを選択しています。- お試しになる方で特定のリージョンでの運用を希望する場合には、事前に各サービスの最新情報をご確認のうえ設定をお願いします。
- AzureおよびMicrosoft FoundryのUIについては変更される場合があります。
- 特にMicrosoft Foundryは発表が2025年11月、2026年3月に新ポータルがGAされるなど、改善による変化の著しいサービスです。利用導線の変化に注意してください。
- 本記事のようなAzureの利用については、わずかですが料金がかかる場合があります。
- ただし、Azureには無料枠が存在します。本記事の内容の範囲ならほとんど支払いは発生しませんが、心配な場合には作業終了後に作成したリソースを削除するなどの対応をお願いします。
リソースグループを用意する
まずは今回作成するリソースをまとめて管理できるように、リソースグループを作成します。
Azureの左ペインなどから「リソースグループ」を開きます。
リソースグループの「作成」から、リソースグループの作成画面へ遷移し、情報を入力します。
ここでは以下のように記載しました。このほかの値はいずれもデフォルト値のまま「レビューと作成」から作成します。
| 項目名 | 設定値 |
|---|---|
| サブスクリプション | ご自身の利用されているサブスクリプション |
| リソースグループ名 | rg-my-rag |
| リージョン | (Europe) Sweden Central |

ストレージアカウントとBlob Storageのコンテナを用意する
次にRAGで探す対象となるドキュメントを格納するため、ストレージアカウントを作成します。
左ペインから「ストレージアカウント」を選択し、開いた「ストレージセンター」の画面で「作成」をクリックします。
作成画面では、以下の設定を行いました。記載のない部分については、デフォルト値のままとしています。
| 項目名 | 設定値 | 備考 |
|---|---|---|
| リソースグループ | rg-my-rag |
|
| ストレージアカウント名 | stamyrag |
|
| リージョン | (Europe) Sweden Central |
|
| プライマリサービス | Azure Blob Storage または Azure Data Lake Storage |
|
| 冗長性 | ローカル冗長ストレージ(LRS) |
単一の物理データセンター内にデータのコピーを3つ複製。ドライブ・サーバー・ラックの障害からは保護されますが、火災・洪水などデータセンター全体の障害ではすべてのレプリカが失われる可能性があります。今回は検証ということで、コストが最も安いことから選択しました。 |
| パブリックネットワークアクセス | 有効にする |
デフォルト値で有効となっており若干心配になりますが、ここで設定されているのはあくまで「アクセスできるかどうか」まで。セキュリティで個々のコンテナーでの匿名アクセスの有効化を許可するをチェックしない限りは、中身を見るためには認証が必要となります。 |
| パブリックネットワークアクセススコープ | すべてのネットワークから有効にする |
デフォルト値です。 |





ストレージアカウントが作成できたら、次はドキュメントの格納場所となるBlob Storageのコンテナを作成します。
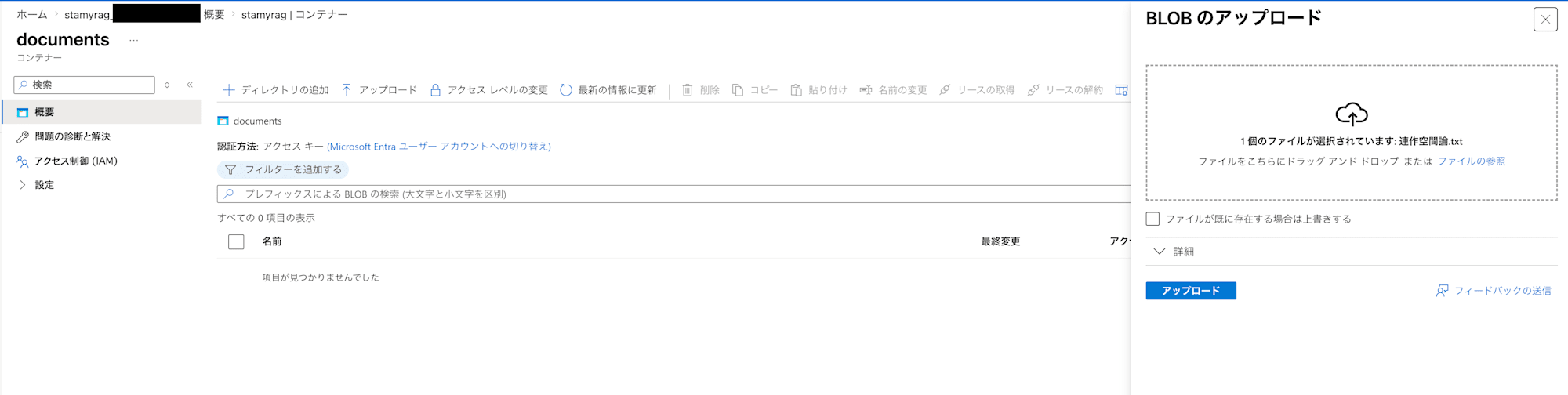
ストレージアカウント内のペインから「データストレージ」>「コンテナー」を開き、「コンテナーの追加」をクリックします。「新しいコンテナー」のUIが表示されるため、documentsとコンテナ名を入力して作成します。
作成したコンテナに、RAGの情報源としたいドキュメントを配置します。
ここでは、私自身が過去に執筆した短歌についての評論文のテキストファイルを配置しました。ファイルサイズとしては100KB程度、文字数としては30,000文字程度あります。短歌を数首並べて1作品とする「連作」という形式があるのですが、それを線形代数的な発想で扱おうという内容の文章となっています。既発表の文章ながらインターネット上では公開していないために単純なWeb検索だけでは情報として見つけられず、かつ同様の主張を行なっている事例も多くはないことから、RAGの検証にちょうど良いと判断しました。
Azure AI Search(Foundry IQ)を用意する
データを検索するため、Azure AI Search(Foundry IQ)を用意しましょう。
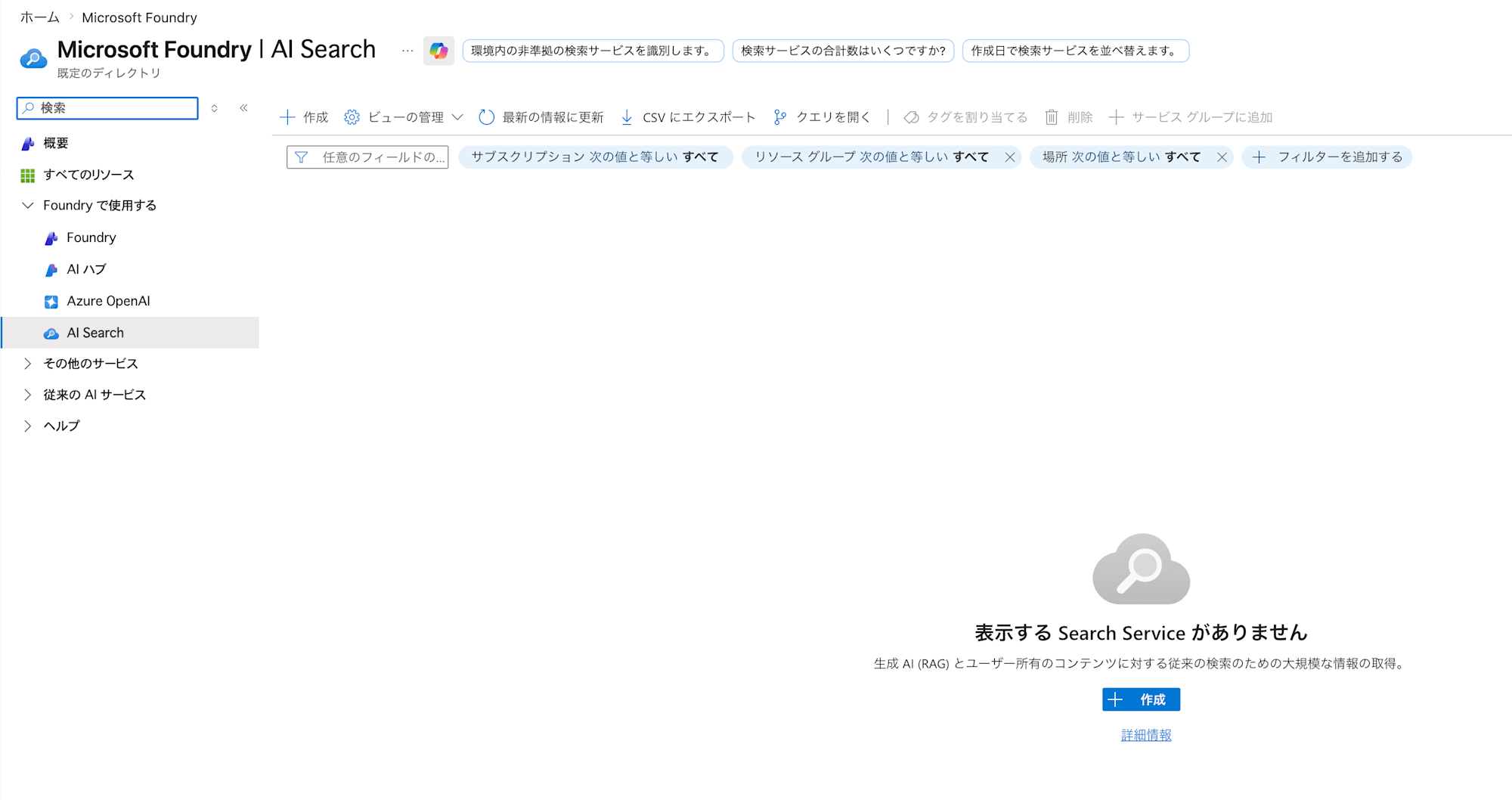
検索バーからAI Searchなどで検索して、AI Search(Foundry IQ)を表示します。AI Searchの画面を開いたら、「作成」からAI Searchを作成します。以下が設定値となります(他はいずれもデフォルト値)。
| 項目名 | 設定値 | 備考 |
|---|---|---|
| リソースグループ | rg-my-rag |
|
| サービス名 | ais-my-rag |
|
| 場所 | (Europe) Sweden Central |
|
| 価格レベル | Free |
検証ということで、コストを抑えるため選択。 |

AI Searchがストレージアカウントにアクセスできる権限を付与する
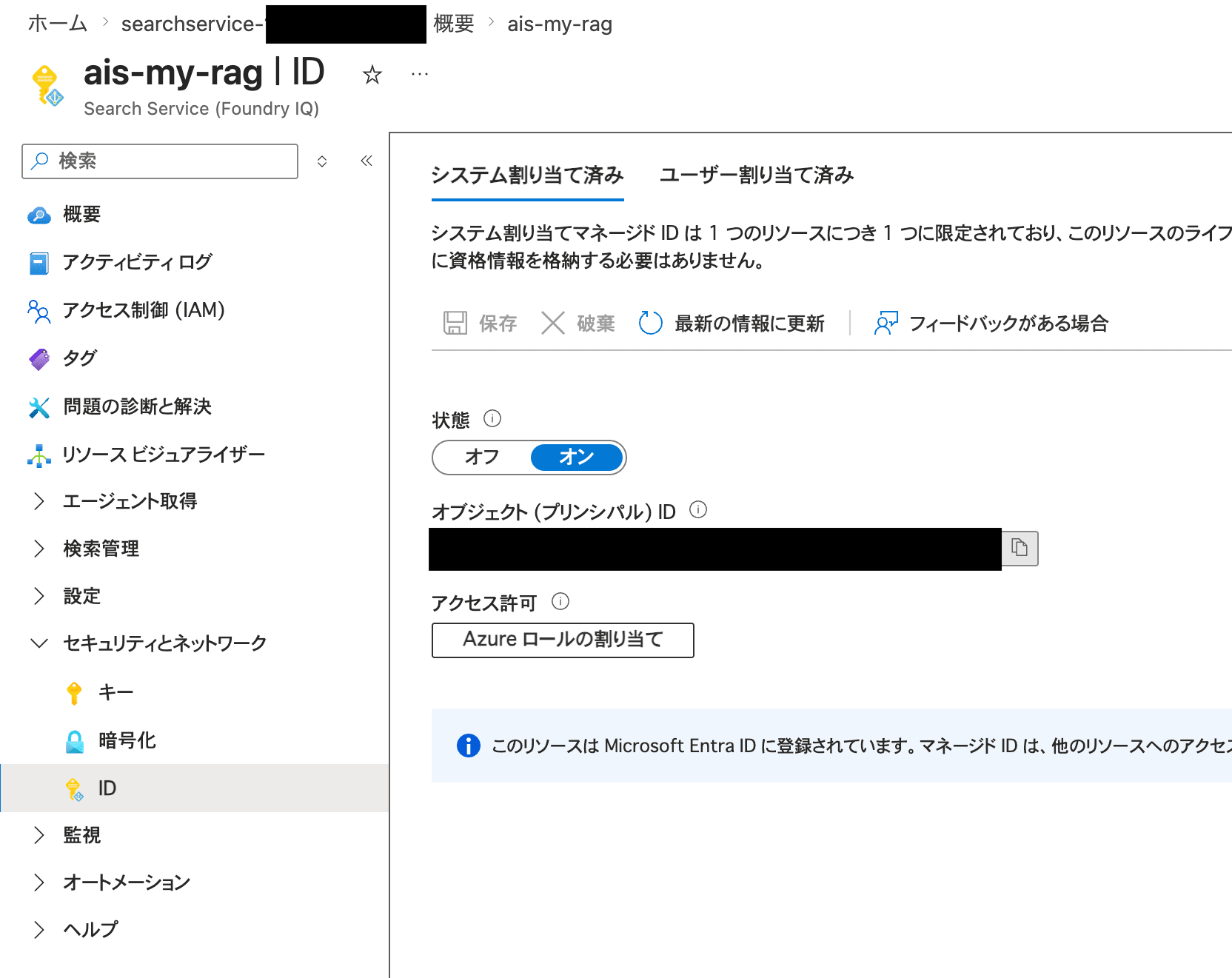
つくったAI Searchが、ストレージアカウント内のデータにアクセスできるようにしてあげましょう。
まず、AI Search側の左ペインから「セキュリティとネットワーク」>「ID」と進みます。「システム割り当て済み」タブで、状態を「オン」に切り替えて保存します。これにより、システム割り当てマネージドIDというAI Search用のIDが用意されます。
用意したマネージドIDに対して、ストレージアカウント側で権限を付与します。
再びストレージアカウントを開き、ストレージアカウントの「アクセス制御」から「追加」>「ロールの割り当ての追加」と進みます。
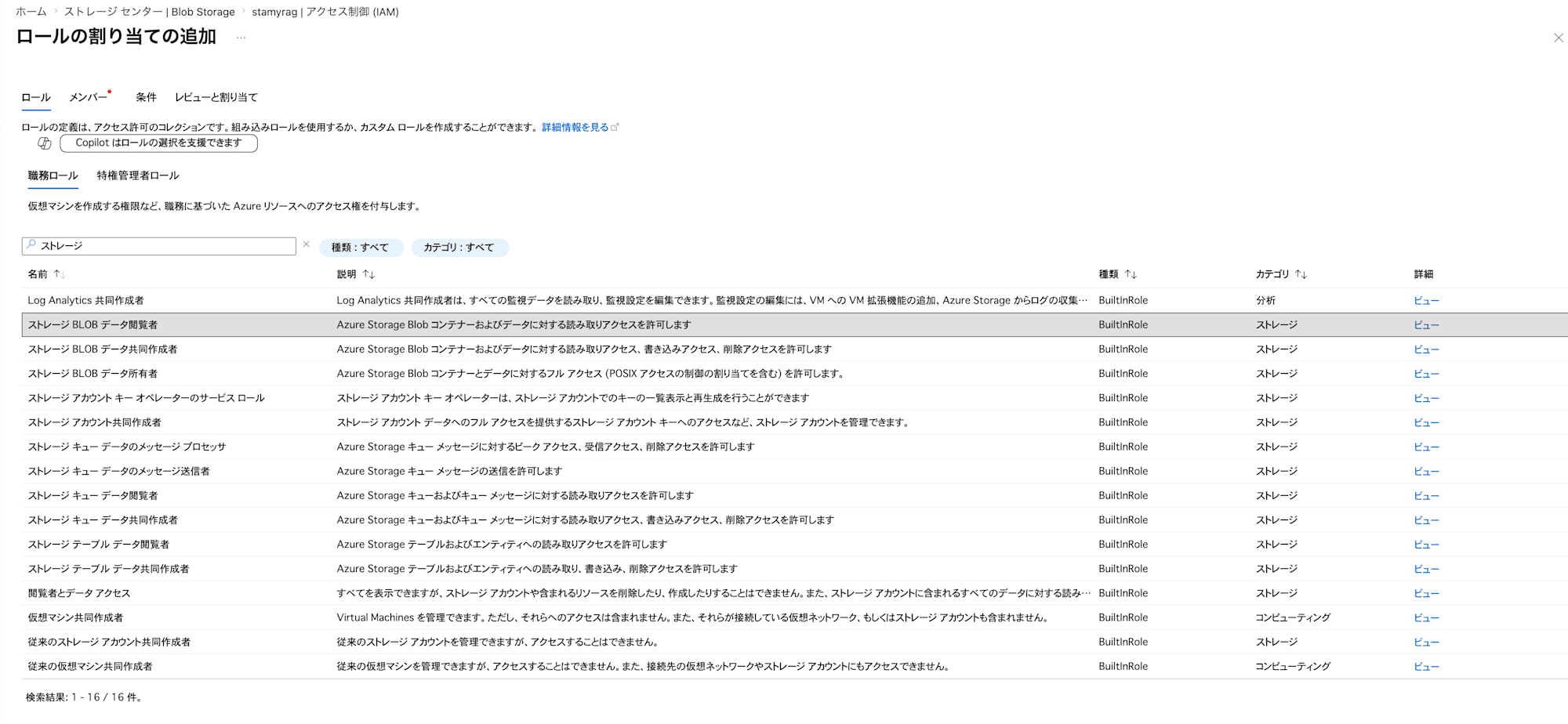
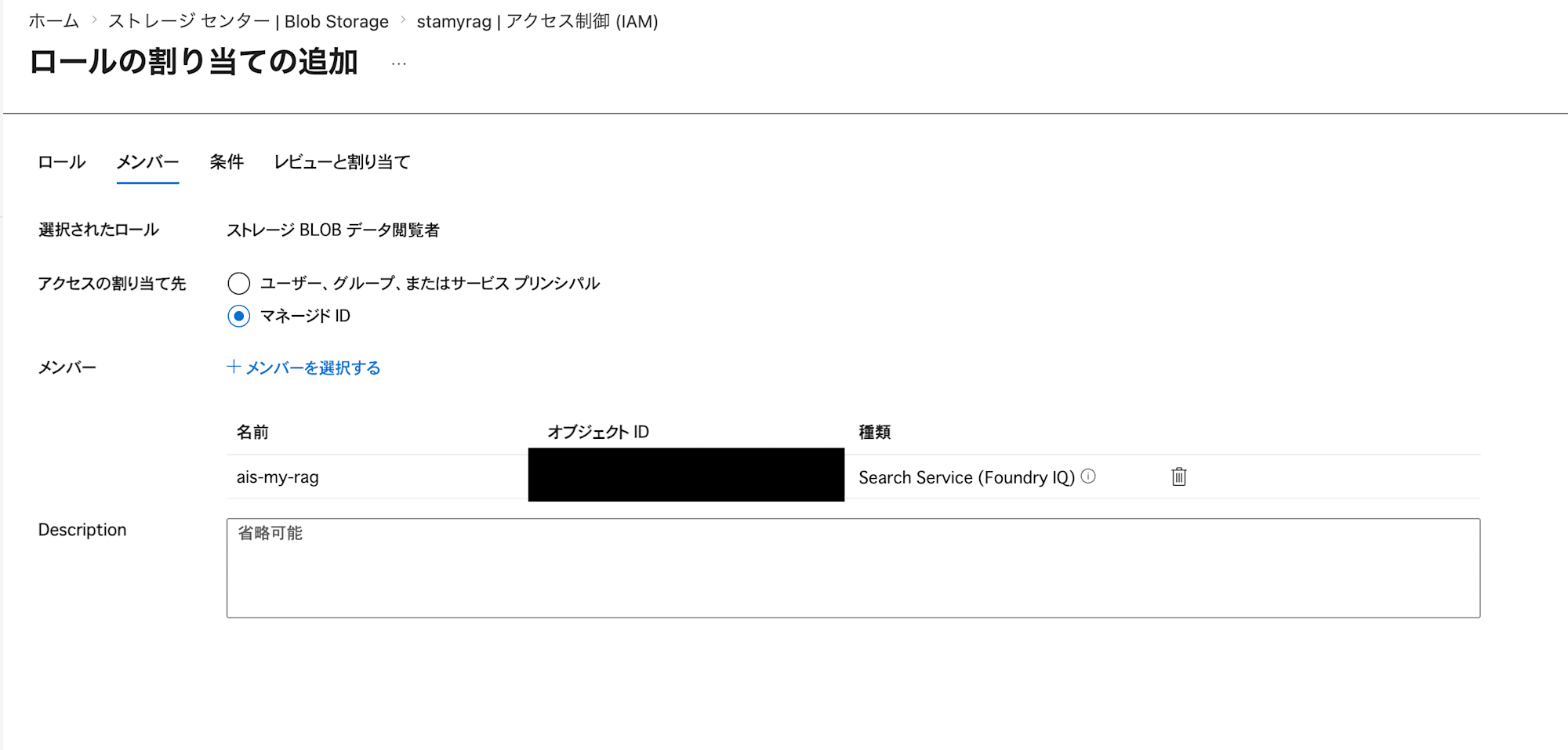
「ロールの割り当ての追加」では、ストレージBLOBデータ閲覧者の権限を、先ほど作成したAI SearchのマネージドIDに付与します。
Microsoft Foundryでプロジェクトを用意する
まだAI Searchで用意したい部分があるのですが、先にMicrosoft Foundryで用意しておくべきリソースがあります。
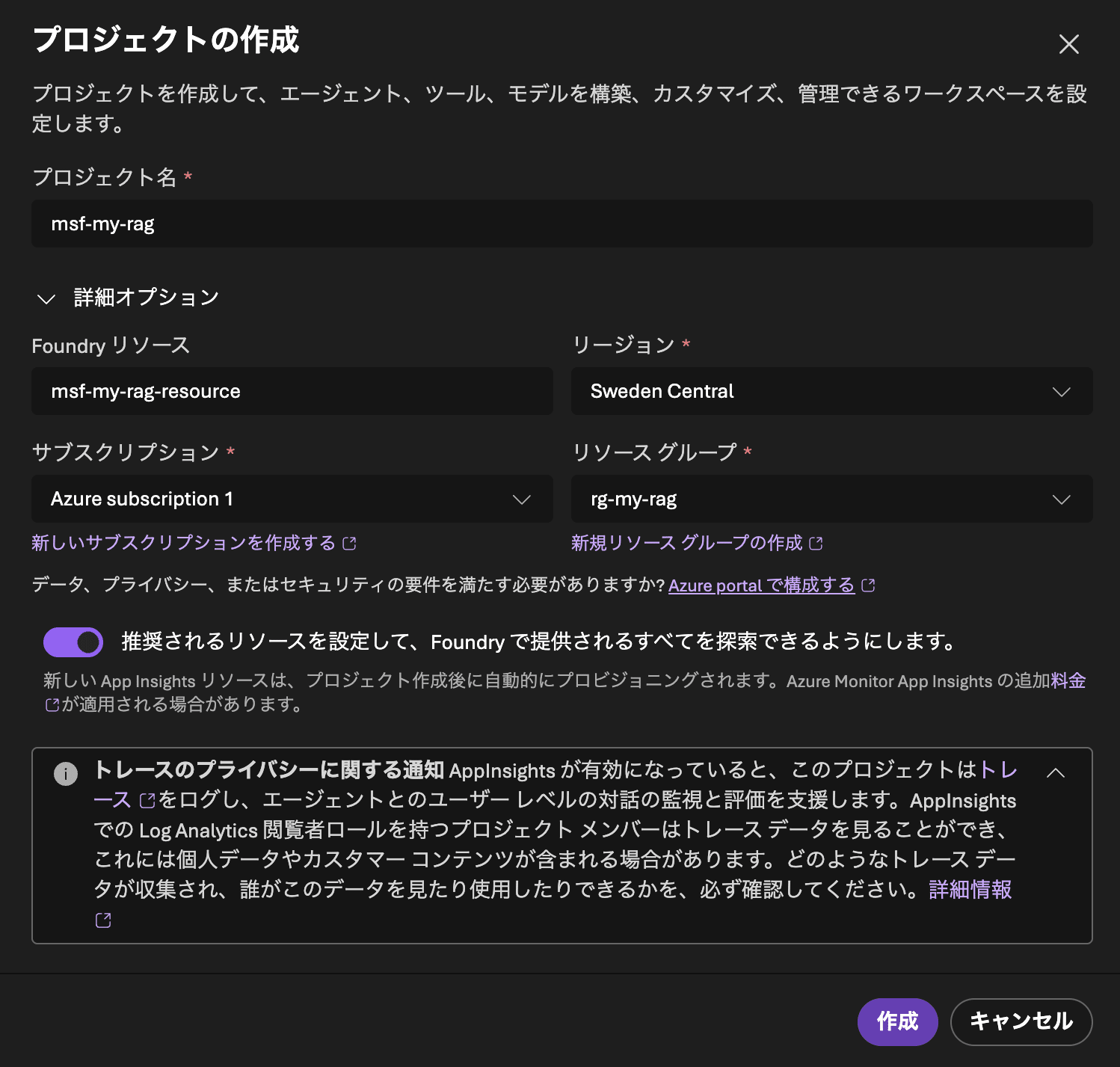
まずMicrosoft Foundryにサインインして、プロジェクトを作成しましょう。設定値は以下となります。
| 項目名 | 設定値 |
|---|---|
| プロジェクト名 | msf-my-rag |
| Foundryリソース | msf-my-rag-resource |
| サブスクリプション | ご自身の利用されているサブスクリプション |
| リージョン | Sweden Central |
| リソースグループ | rg-my-rag |
少し待つとプロジェクトの作成が完了するはずです。

Foundryでモデルを用意する
Foundryでは、まず以下の2つのモデルを用意します。
- Embeddingモデル:
text-embedding-3-small- テキストを埋め込み(ベクトル化)するために利用します。
- 回答生成用のモデル:
gpt-5-mini- RAGとして自然文で回答を生成してもらうために利用します。
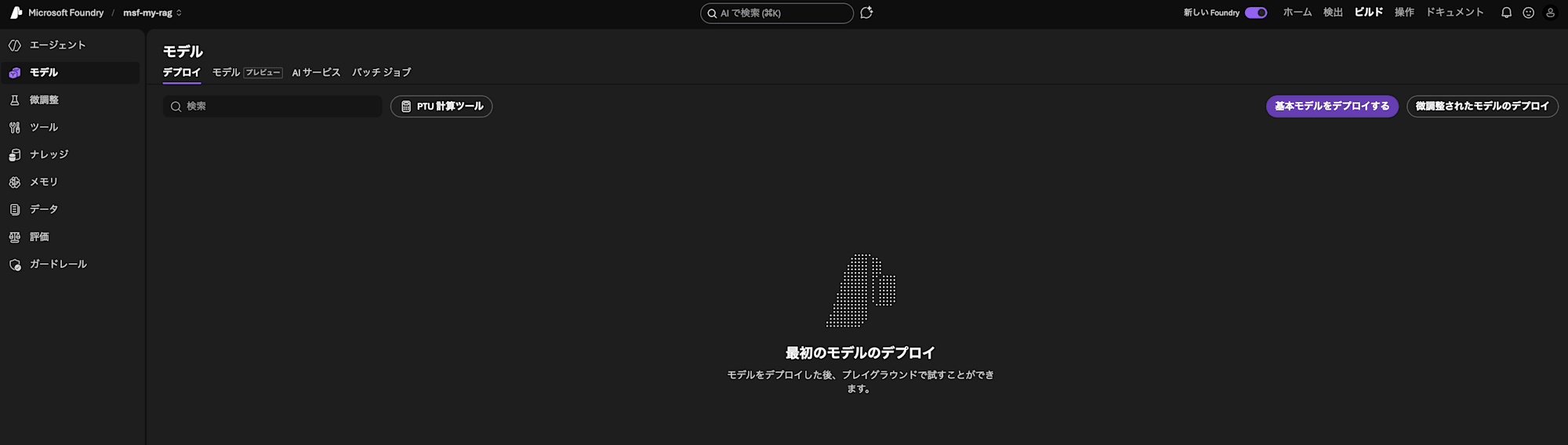
まずEmbeddingモデルから用意してみましょう。プロジェクトの画面から、画面右上部の「ビルド」>「モデル」と進みます。その後、「基本モデルをデプロイする」へと進みます。
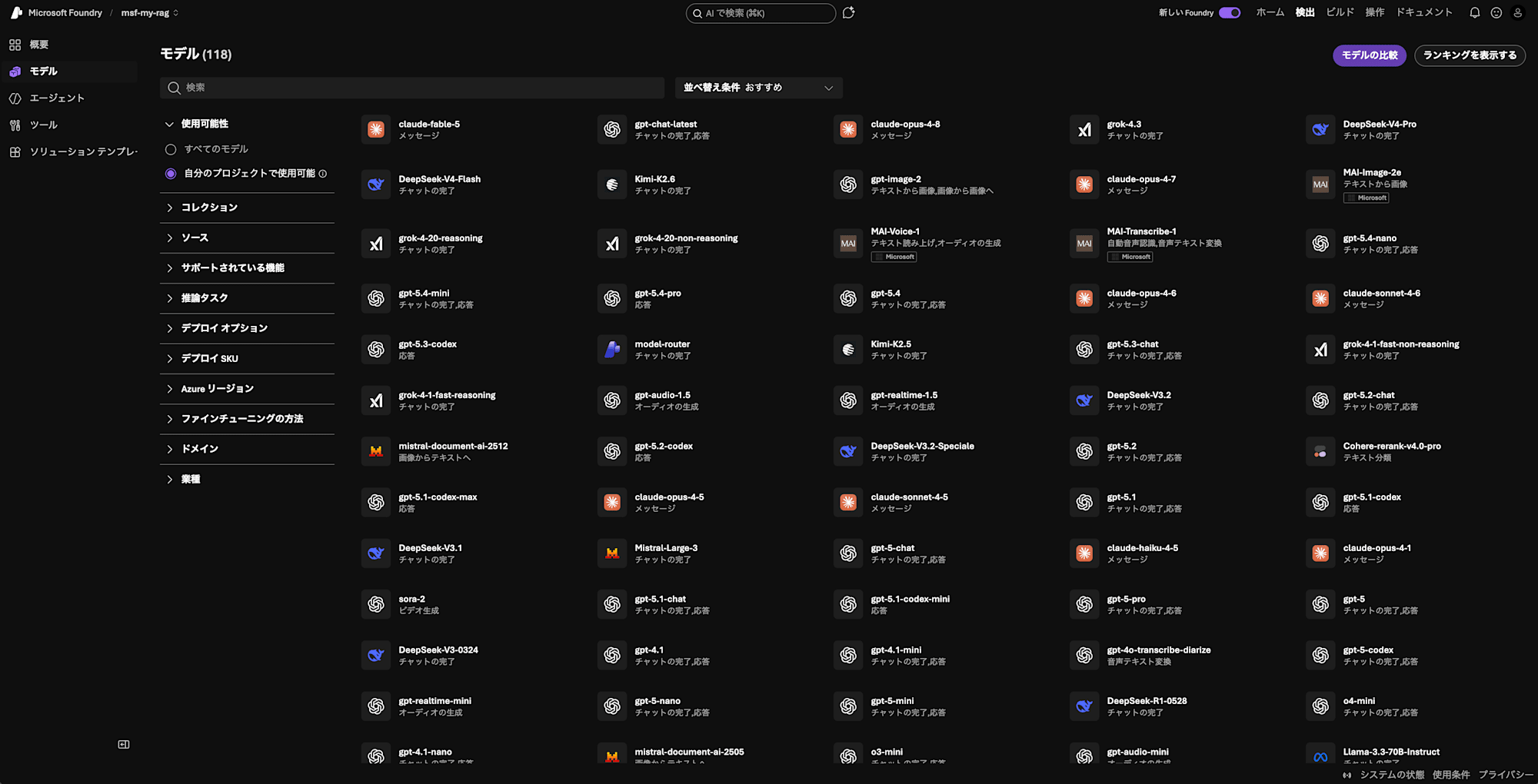
利用可能なモデルが表示されます。非常に多岐にわたるモデルから選択することができます。モデルの検索から目的のtext-embedding-3-smallを探して開きます。
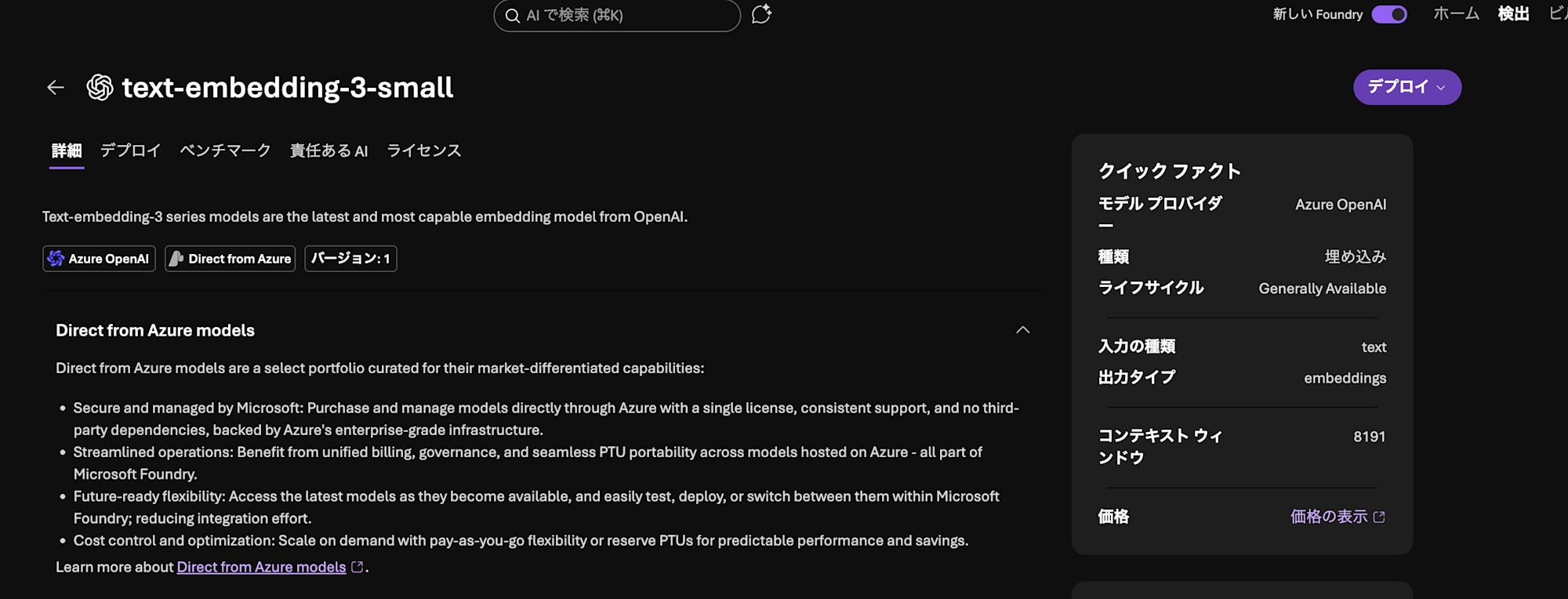
モデルの「デプロイ」から「既定の設定」をクリックしてデプロイします。
同様の手順で、gpt-5-miniもデプロイしてください。
AI Searchでデータをインポートする
再びAI Searchの画面に戻ります。ここでは、Foundryで用意したモデルを活用しながらAI SearchにBlob Storageのデータをインポートします。
まず、AI Searchの画面から「データのインポート」をクリックします。その後、データソースとしてAzure Blob Storageを選び、RAGを選択します。


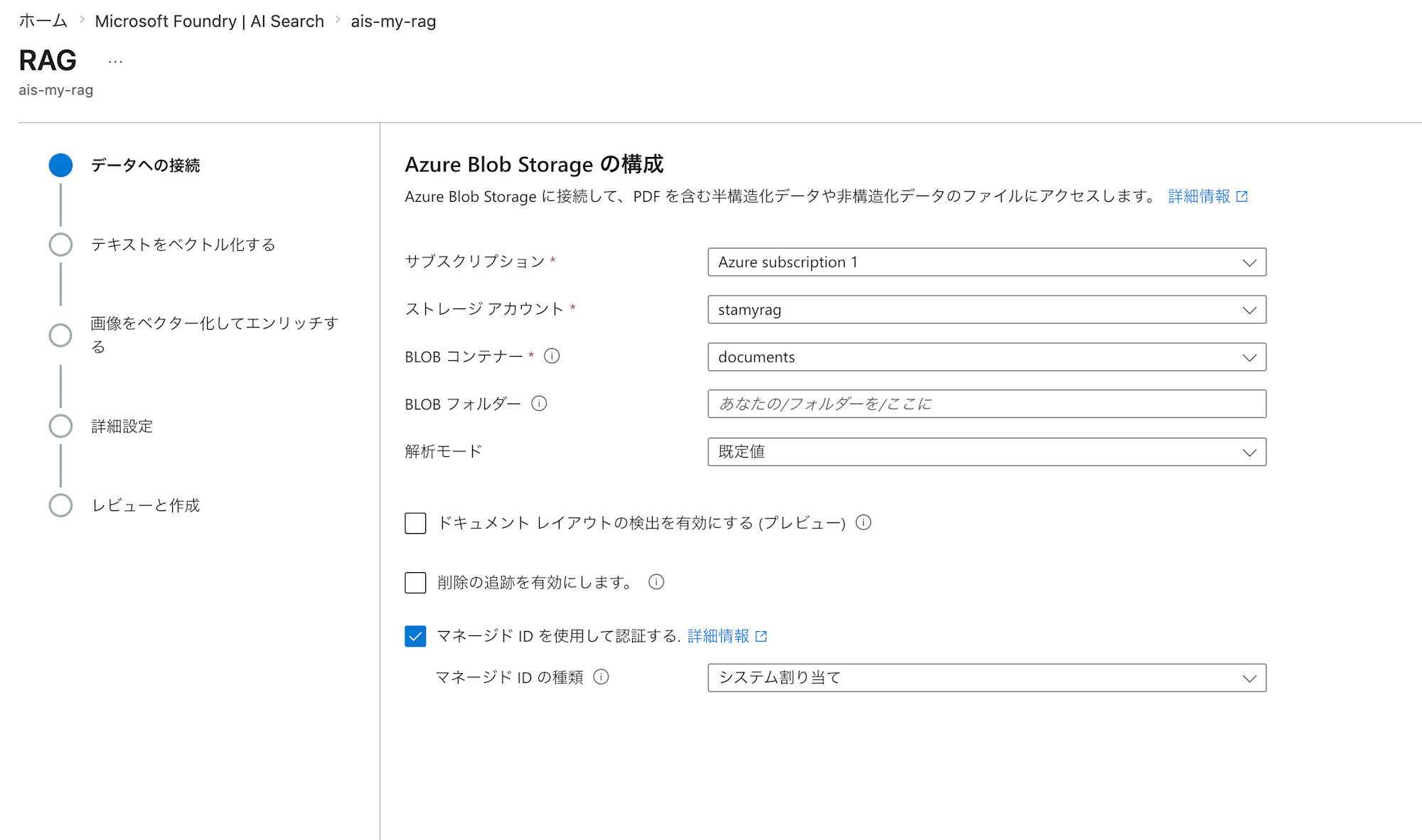
まずはインポート元となるAzure Blob Storageを指定します。
| 項目名 | 設定値 | 備考 |
|---|---|---|
| サブスクリプション名 | ご自身の利用されているサブスクリプション | |
| ストレージアカウント | stamyrag |
|
| BLOBコンテナー | documents |
|
| 削除の追跡を有効にします。 | チェックなし(デフォルト値) | チェックすることで、Blob Storageからのデータ削除に合わせて検索インデックスからデータを削除するように設定可能です。 |
| マネージドIDを使用して認証する。 | チェック | |
| マネージドIDの種類 | システム割り当て |
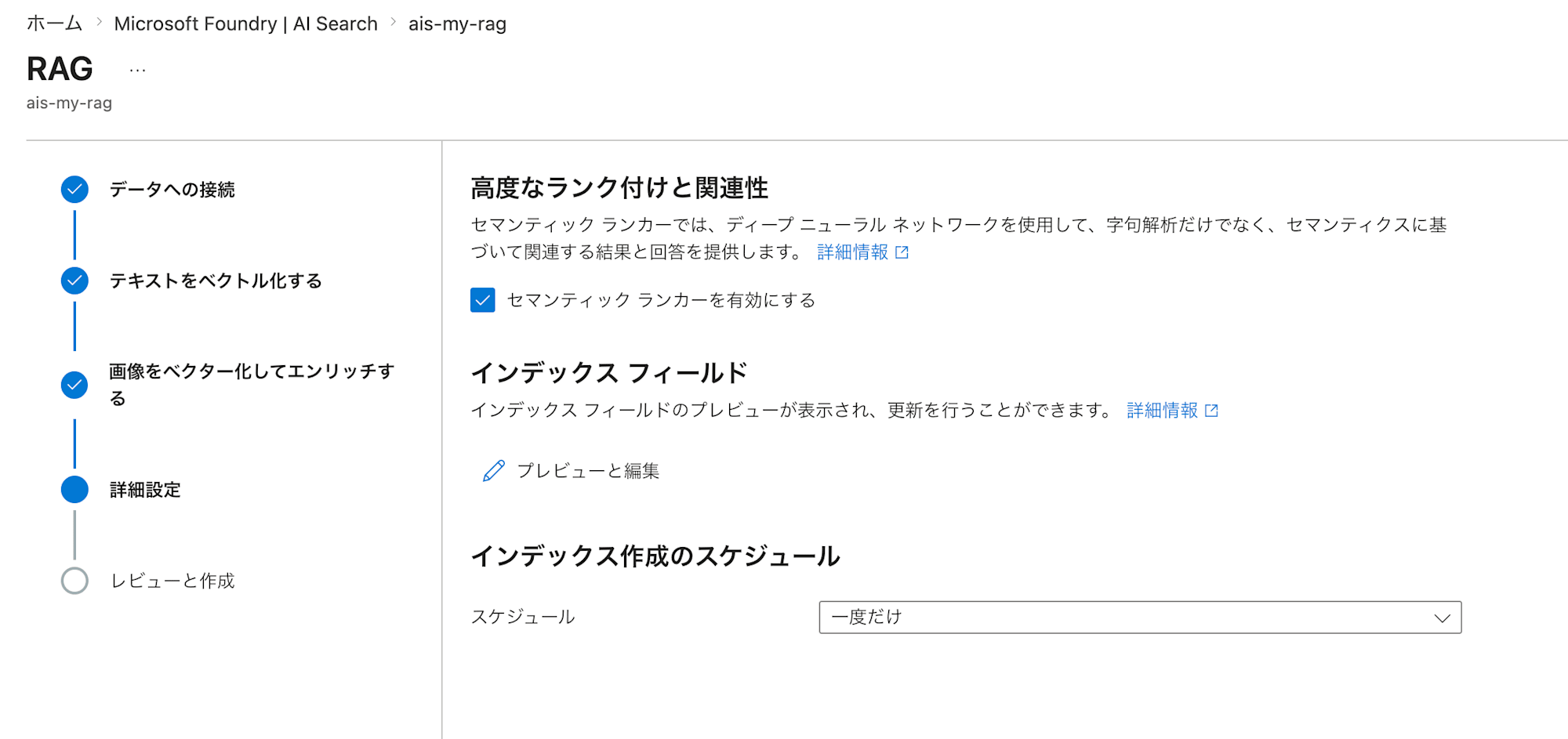
続けて、テキストをベクトル化するための設定を行います。ここで先ほどまでに作成したFoundryのEmbeddingモデルを活用します。
| 項目名 | 設定値 |
|---|---|
| Kind | Microsoft Foundry |
| サブスクリプション | ご自身の利用されているサブスクリプション |
| Microsoft Foundryプロジェクト | msf-my-rag |
| モデルデプロイ | text-embedding-3-small |
| 認証の種類 | APIキー |
| 追加料金が発生する旨の確認 | チェックする |

さらに画像のベクトル化、詳細設定と続きますが、今回はテキストデータのみのためデフォルトのまま進みます。詳細画面の「スケジュール」は「一度だけ」としていますが、お好みで変更することで自動でインデックスを更新するようにも設定可能です。

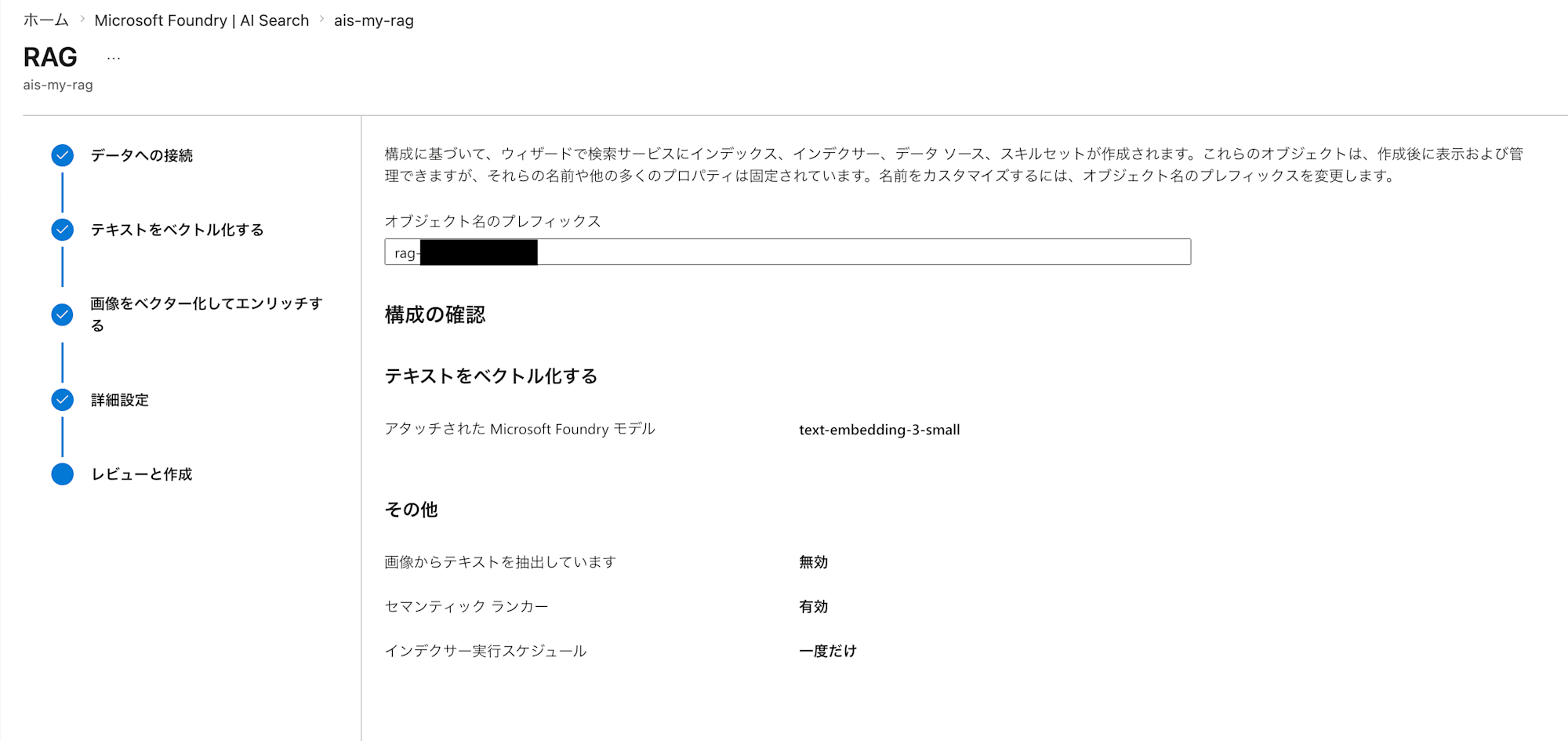
レビューと作成後、完了するといくつかのリソースが出来上がっています。それぞれのリソースの役割は以下の通りです。
- データソース:どこのデータを読み込むかの指定
- インデックス:検索用のデータベース
- インデクサー:データを読み込んで加工するジョブの指定
- スキルセット:AIによる前処理の指定
ここまでくると、用意したドキュメントを検索できるようになっています。検索エクスプローラーに移動してテストしてみましょう。
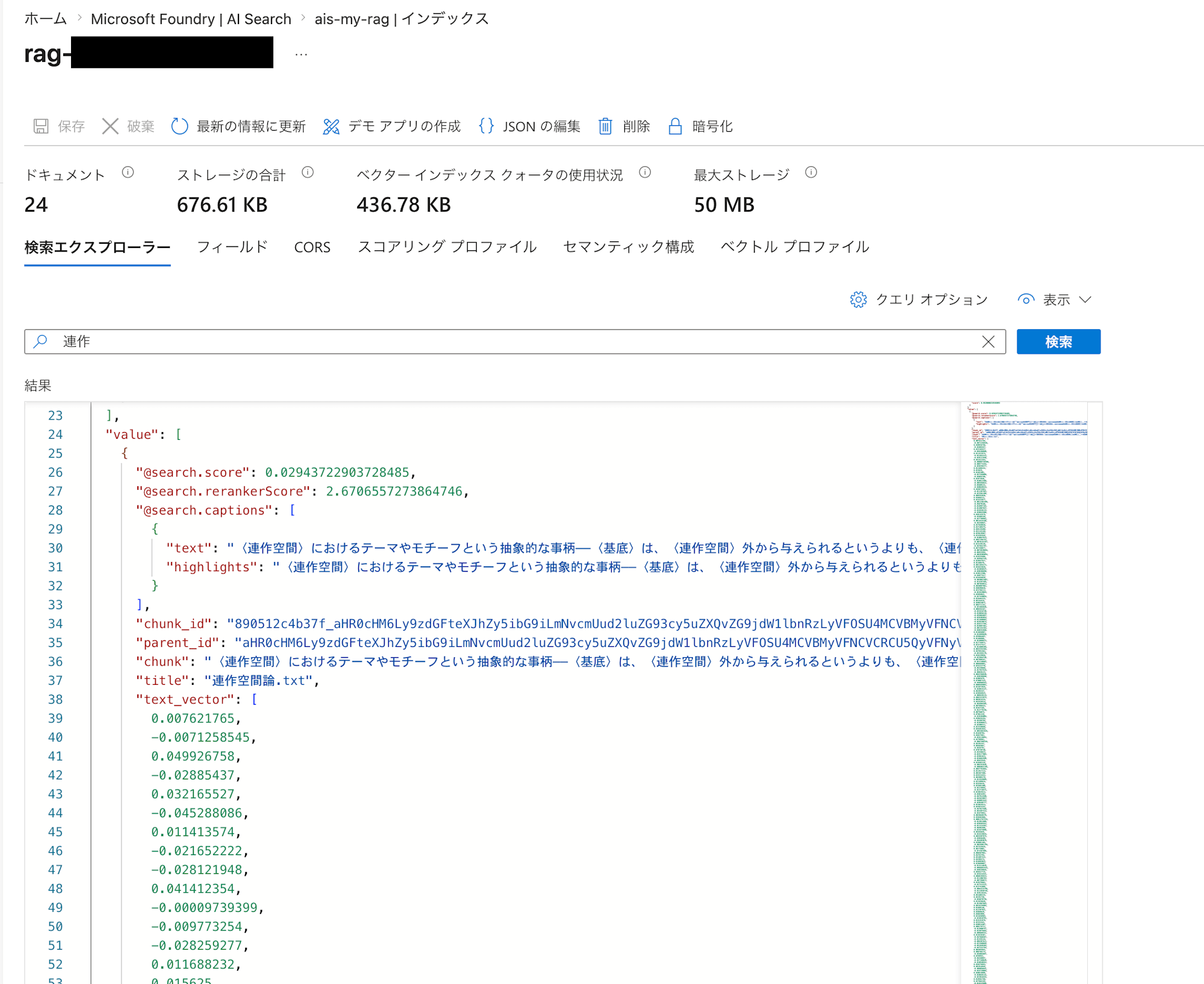
ちゃんとテキストの内容がベクトルとして取り込まれていそうです!
Foundryでナレッジとナレッジベースを用意する
そろそろRAG構築も佳境です。
再びFoundryに戻り、ナレッジとナレッジベースを作成します。
まずナレッジから作成します。どちらも似たような名前がついていて紛らわしいのですが、「ナレッジ」は基盤となるAI Searchの指定となっています。
ナレッジを作成すると、その基盤の上にナレッジベースを作成できるようになります。これは複数のナレッジソースをまとめてエージェントから利用できるようにしたリソースです。
「ナレッジベースの作成」から進みます。

ナレッジベースを構成するため、含めるソースを選択します。ここではAzure AI Search インデックスを選択しましょう。ソースの作成も同時に行われます。
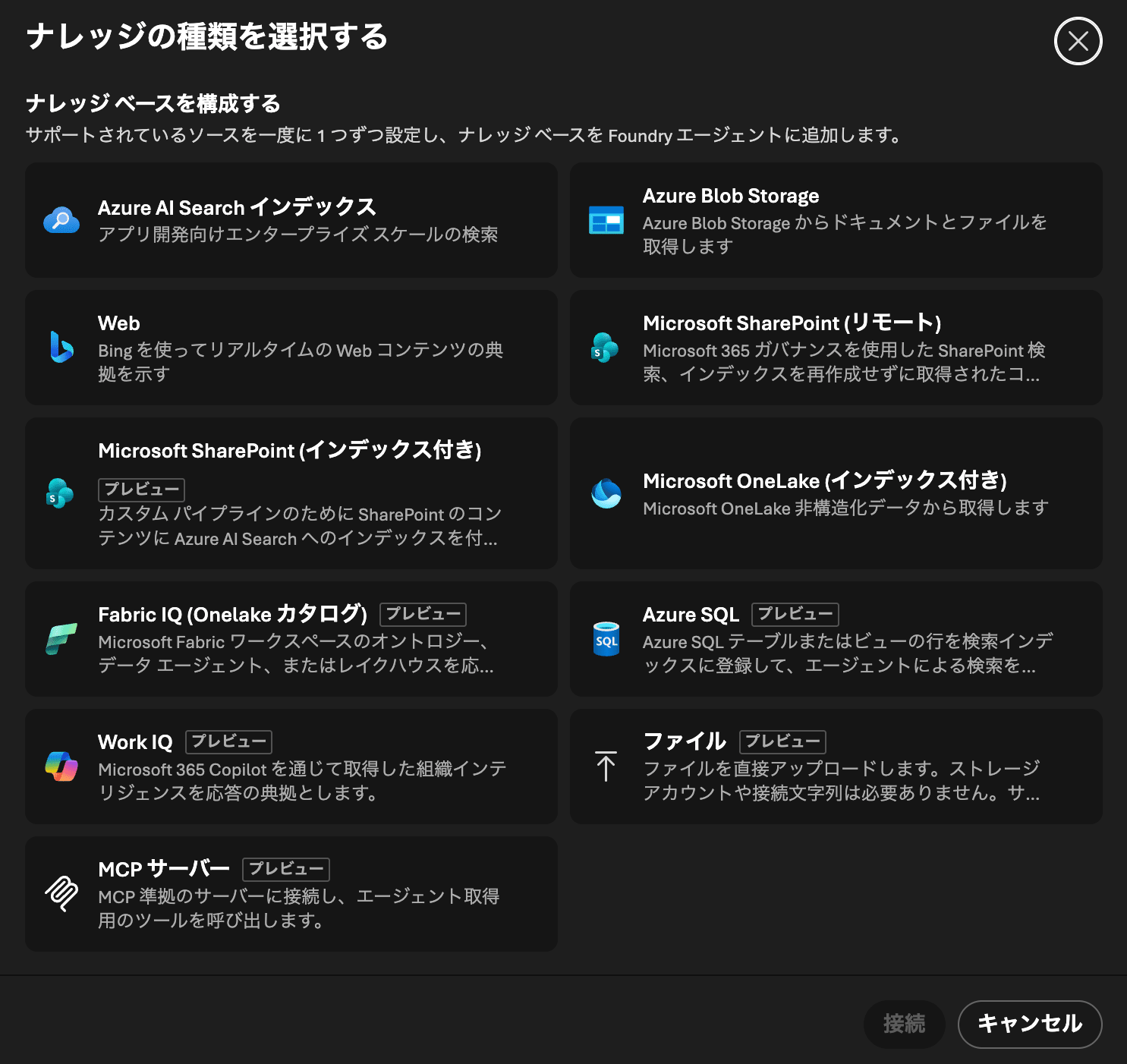
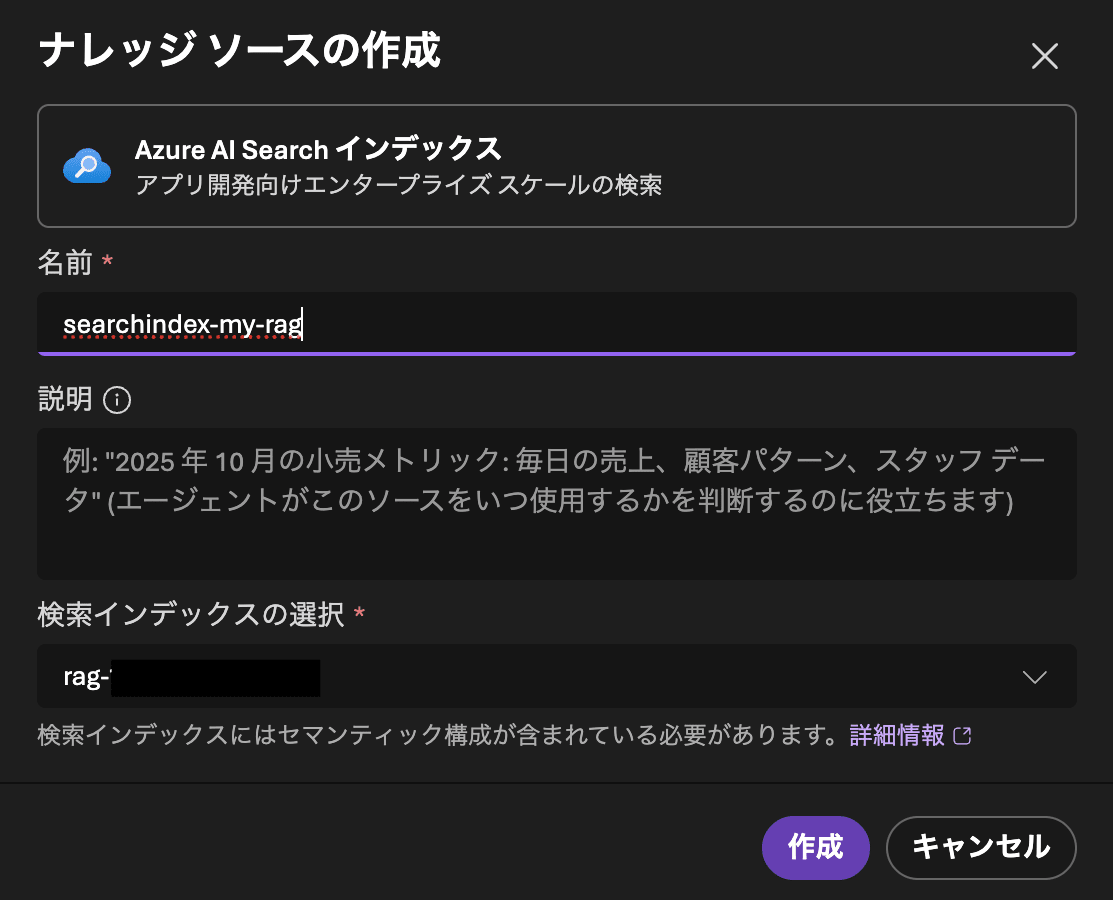
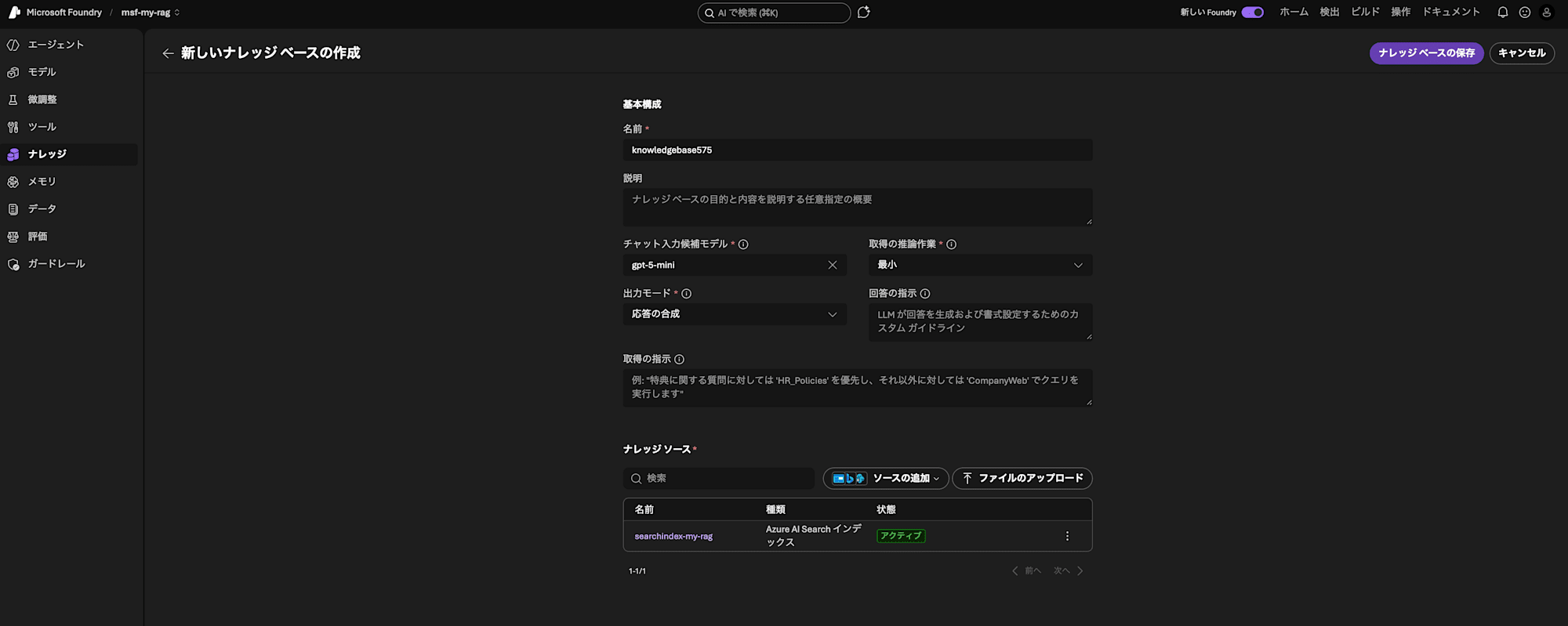
「新しいナレッジベースの作成」画面が開いているので、以下の設定を変更して「ナレッジベースの保存」をクリックします。
| 項目名 | 設定値 |
|---|---|
| チャット入力候補モデル | gpt-5-mini |
| 出力モード | 応答の合成 |
Foundryでエージェントを作成してナレッジを追加する
ラストです!エージェントを作成して、ナレッジを利用できるようにしましょう。
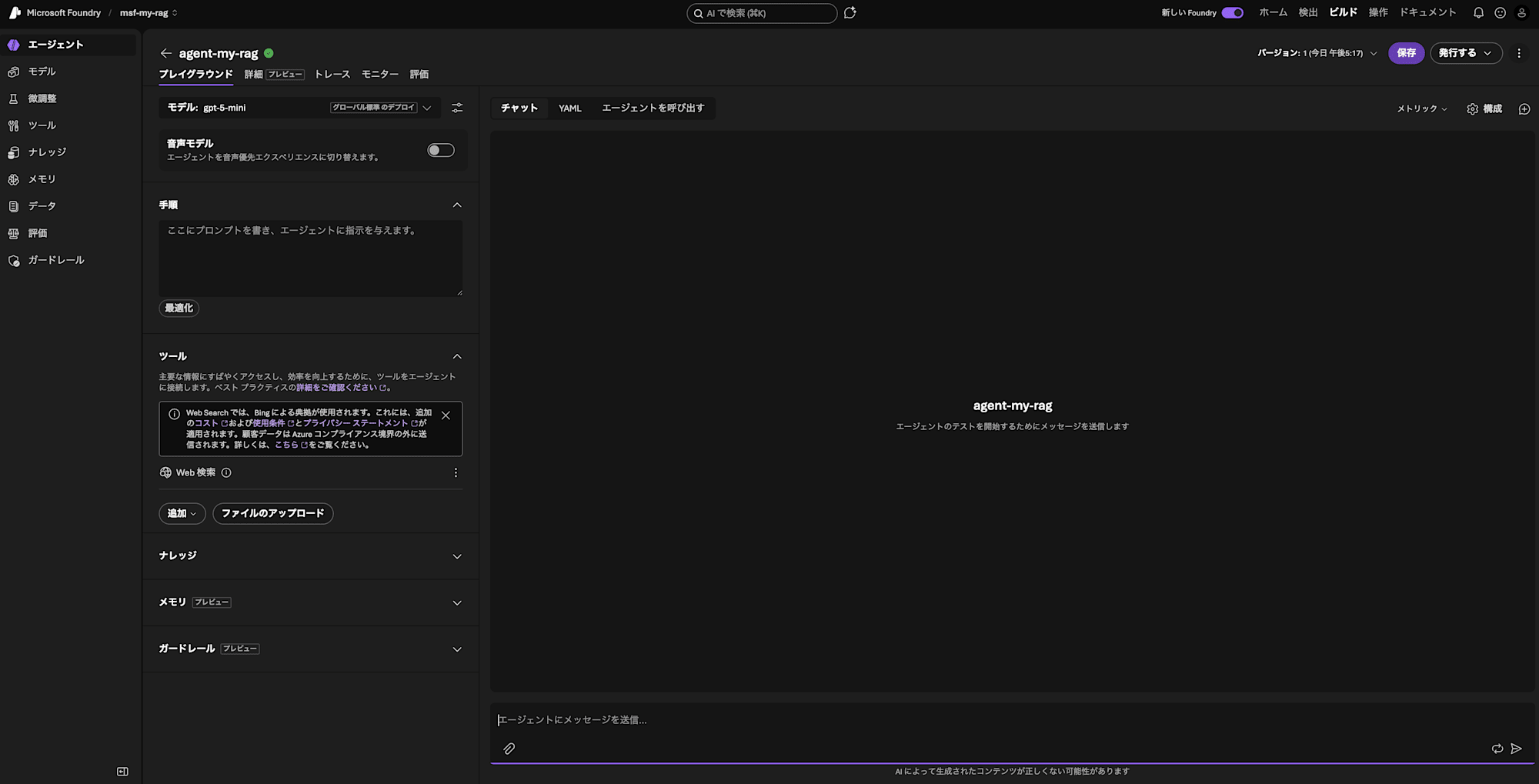
「ビルド」>「エージェント」から、エージェントの作成に進みます。わかりやすい名称をつけて「プレイグラウンドを作成して開く」をクリックします。
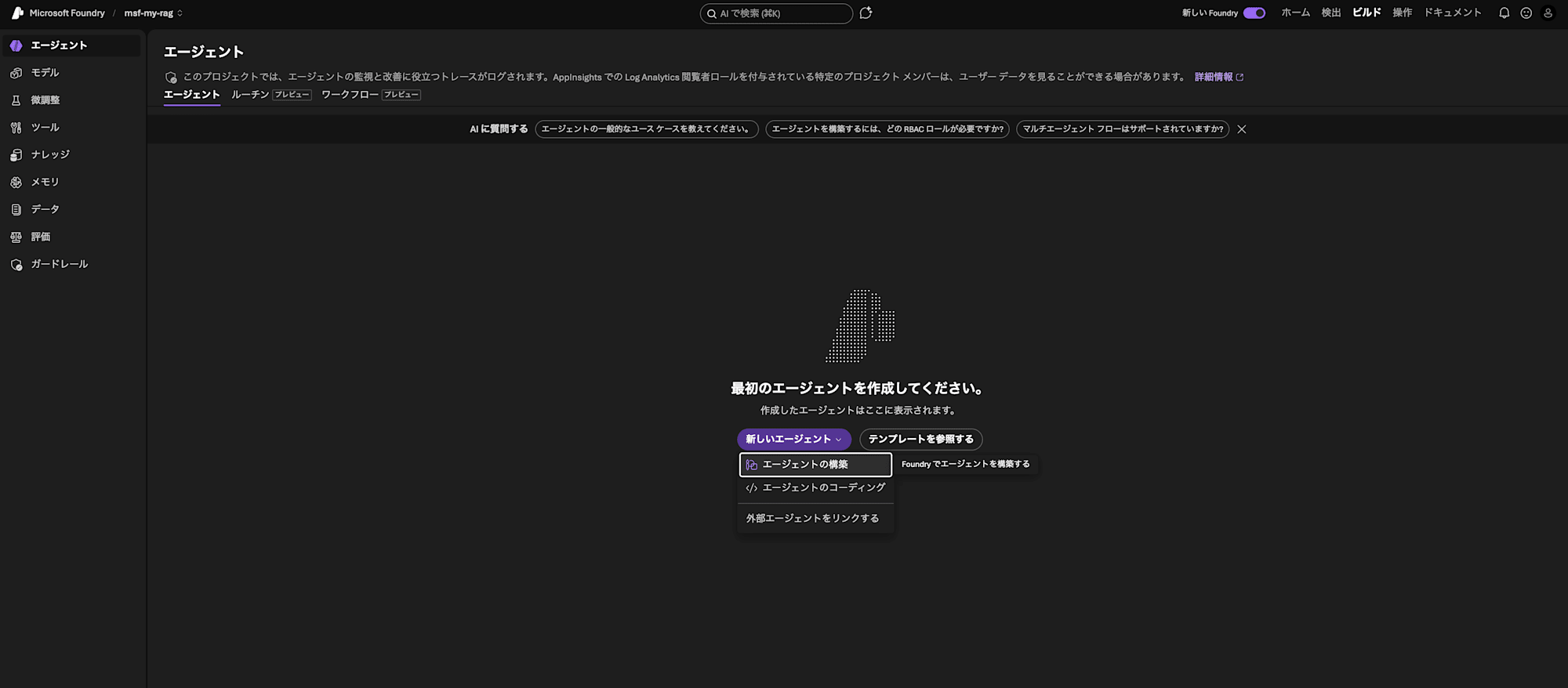
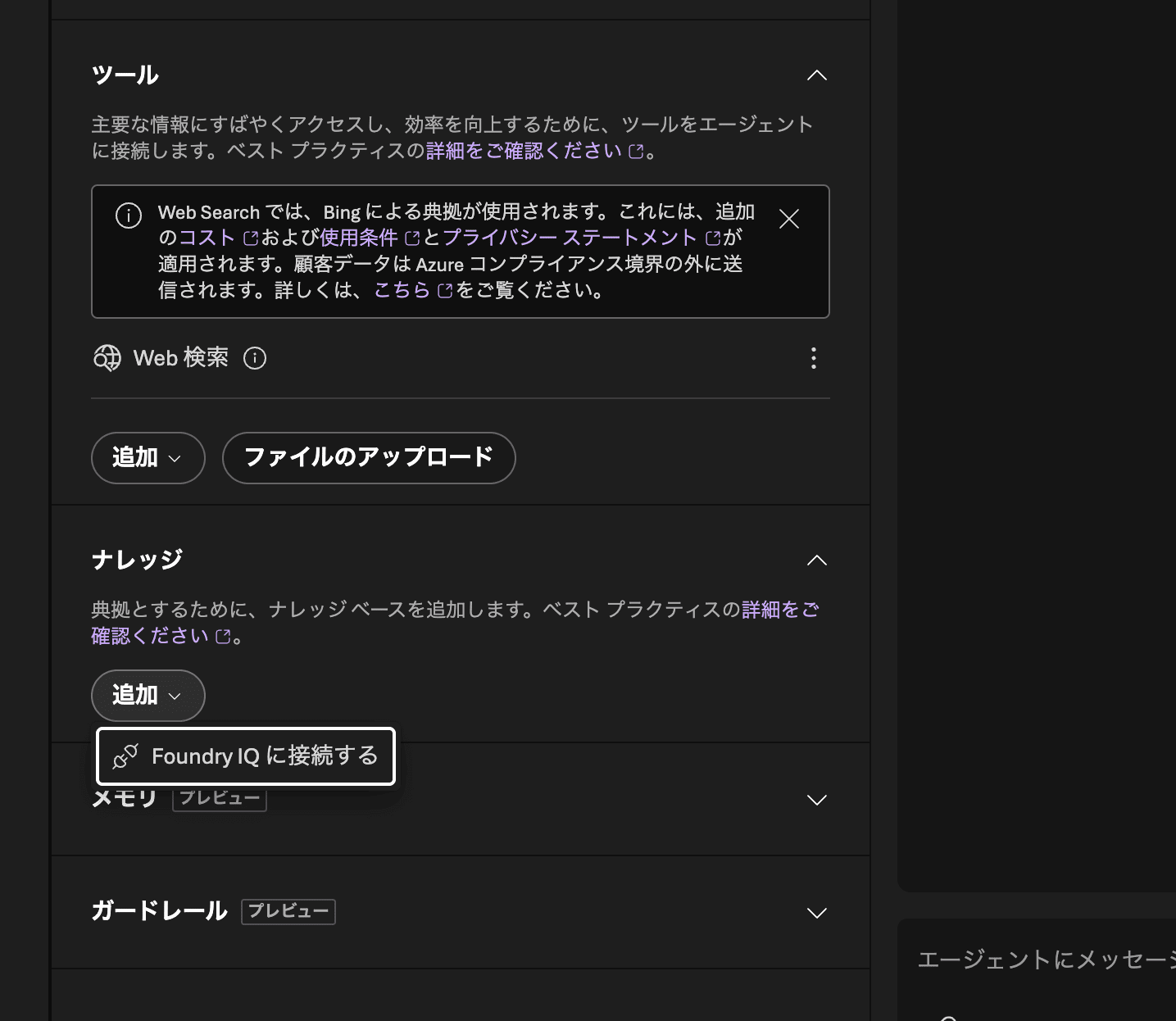
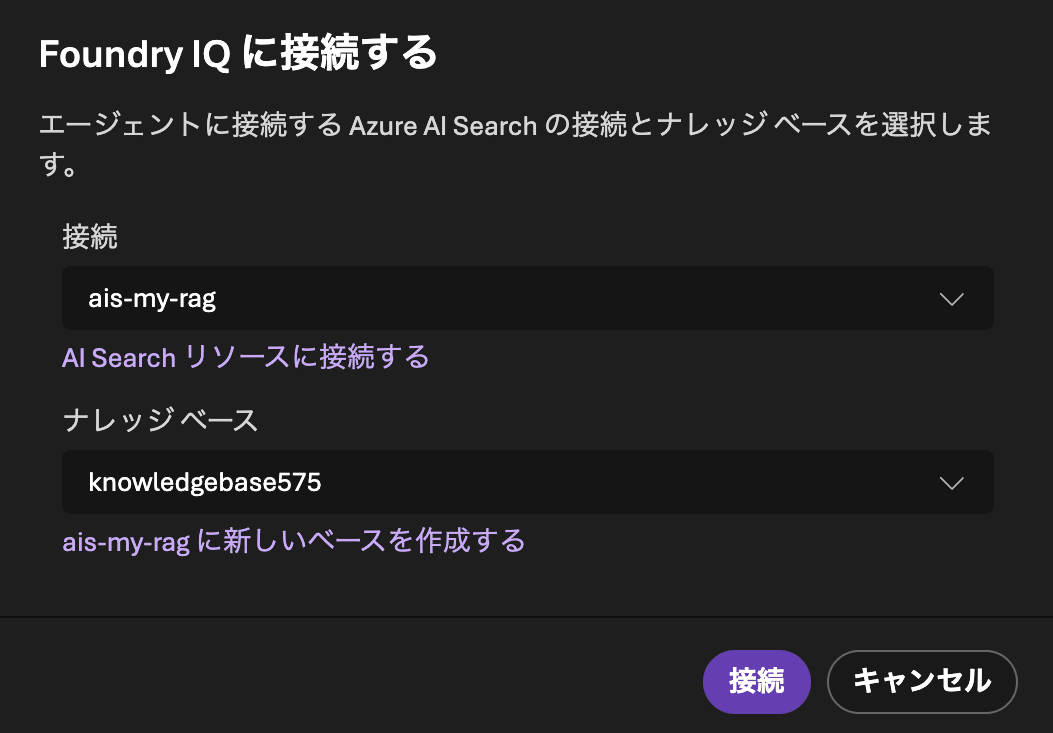
ナレッジを追加します。「接続」に用意していたAI Search(ais-my-rag)を、「ナレッジベース」に先ほど作ったナレッジベースを指定します。
おつかれさまでした!ここまででRAGの構築は完了です!
テスト
いよいよRAGを動作させてみましょう。ちゃんとナレッジから情報を取ってくるように念押ししつつ、質問を投げかけます。
浅野が短歌の連作について話していることをナレッジから探して
結果は……?
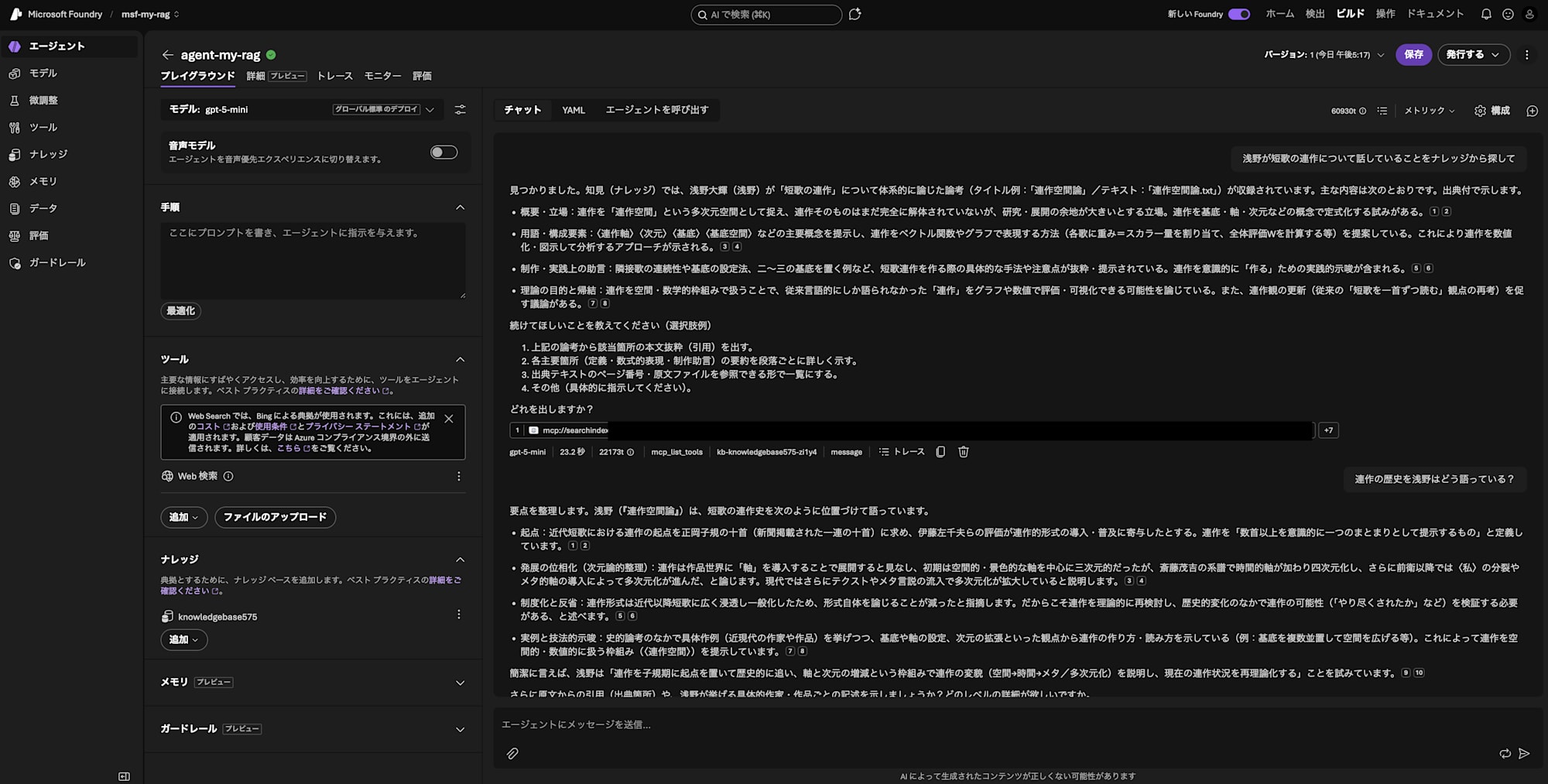
見つかりました。知見(ナレッジ)では、浅野大輝(浅野)が「短歌の連作」について体系的に論じた論考(タイトル例:「連作空間論」/テキスト:「連作空間論.txt」)が収録されています。主な内容は次のとおりです。出典付で示します。
- 概要・立場:連作を「連作空間」という多次元空間として捉え、連作そのものはまだ完全に解体されていないが、研究・展開の余地が大きいとする立場。連作を基底・軸・次元などの概念で定式化する試みがある。12
- 用語・構成要素:〈連作軸〉〈次元〉〈基底〉〈基底空間〉などの主要概念を提示し、連作をベクトル関数やグラフで表現する方法(各歌に重み=スカラー量を割り当て、全体評価Wを計算する等)を提案している。これにより連作を数値化・図示して分析するアプローチが示される。34
- 制作・実践上の助言:隣接歌の連続性や基底の設定法、二〜三の基底を置く例など、短歌連作を作る際の具体的な手法や注意点が抜粋・提示されている。連作を意識的に「作る」ための実践的示唆が含まれる。56
- 理論の目的と帰結:連作を空間・数学的枠組みで扱うことで、従来言語的にしか語られなかった「連作」をグラフや数値で評価・可視化できる可能性を論じている。また、連作観の更新(従来の「短歌を一首ずつ読む」観点の再考)を促す議論がある。78
続けてほしいことを教えてください(選択肢例)
1. 上記の論考から該当箇所の本文抜粋(引用)を出す。
2. 各主要箇所(定義・数式的表現・制作助言)の要約を段落ごとに詳しく示す。
3. 出典テキストのページ番号・原文ファイルを参照できる形で一覧にする。
4. その他(具体的に指示してください)。
成功です!Blob Storageに投入したテキストの情報をもとに回答してくれています!
後片付け
もしもリソースが不要なら、削除しておく方が不要な料金などが発生しないため安心です。
その場合には各リソースを削除するようにしましょう。本記事の内容に沿っている場合、リソースが1つのリソースグループにまとまっているはずですので、リソースグループを削除すればすべて削除できます。
まとめ
Azure AI Search(Foundry IQ)とMicrosoft Foundryを中心としたRetrieval-augmented generation(RAG)を作成し、自分の書いた文章をもとにAIに回答してもらえるようにしました。
設定項目こそ多く見えますが、一度手を動かしてみると、思っている以上にさくさくとつくれるようになるかと思います。
また、今回は実施していませんが、Blob Storageにさらに別のファイルを投入した上でインデックスを更新することで、より多くの情報をRAGの仕組みの上で活用できるようにもなります。
ご自身のまわりにも、眠ったままになっているドキュメントはないでしょうか?
もしよければ、本記事を参考にRAGの構築にチャレンジしてみていただければ幸いです!









