
HTTP QUERYメソッド(RFC 10008)をPythonで実装して、GET・POSTとの違いを体感してみた
はじめに
2026年6月、新しいHTTPメソッド QUERY が RFC 10008 として正式に標準化されました。GETとPOSTの「いいとこ取り」をするこのメソッド、実際にPythonでサーバーを実装して動かしてみました。
TL;DR
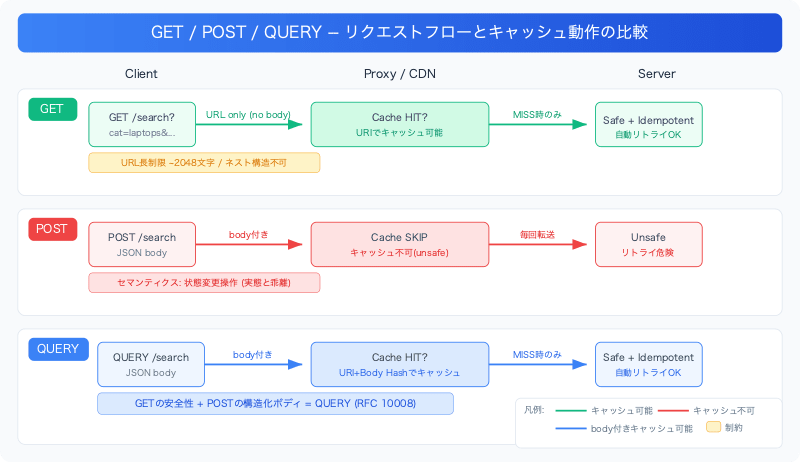
QUERYメソッドとは何か
HTTPでの検索系APIを設計するとき、開発者はずっとこのジレンマを抱えてきました。
| 特性 | GET | POST | QUERY |
|---|---|---|---|
| リクエストボディ | なし | あり | あり |
| 安全(Safe) | Yes | No | Yes |
| 冪等(Idempotent) | Yes | No | Yes |
| キャッシュ可能 | Yes | 制限的 | Yes |
- GET は安全で冪等でキャッシュ可能だが、ボディを持てない。複雑な検索条件はURLクエリ文字列に詰め込む必要があり、URLの長さ制限(実質的に約2048文字)やネスト構造の表現に苦しむ
- POST はボディを持てるが、「状態を変更する操作」というセマンティクスを持つ。プロキシやキャッシュは「副作用がある」と判断するため、キャッシュが効きにくく、自動リトライも安全ではない
QUERYは、GETの安全性・冪等性・キャッシュ可能性を維持しながら、POSTのように構造化されたリクエストボディを送れるメソッドです。
Safe・Idempotent・Cacheableとは何か、なぜ重要か
上の表に登場した3つの特性について、それぞれ具体的に説明します。
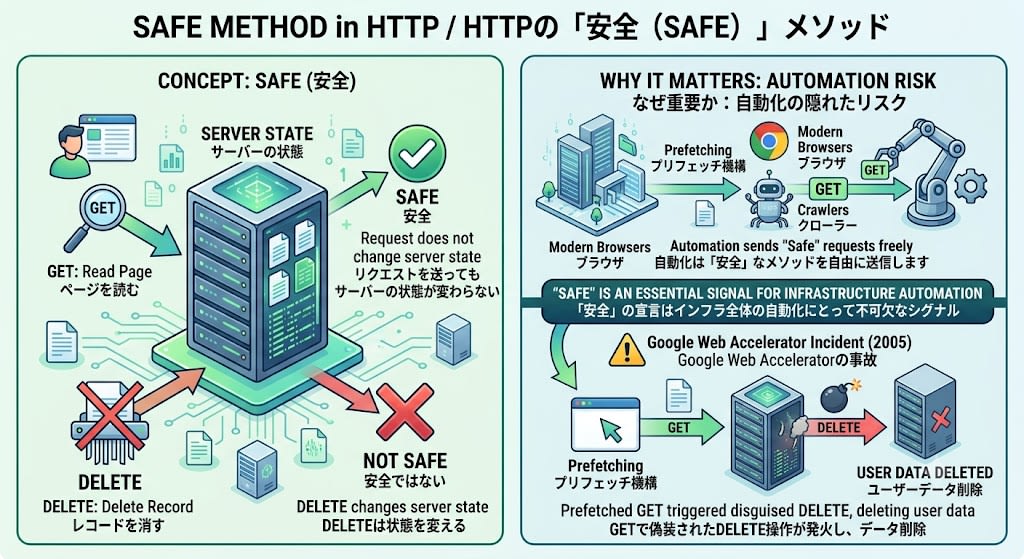
Safe(安全)
リクエストを送ってもサーバーの状態が変わらないことを意味します。GETでページを読むのは安全、DELETEでレコードを消すのは安全ではありません。
なぜ重要か: ブラウザ、クローラー、プリフェッチ機構は「安全なメソッド」であれば自由にリクエストを送信します。2005年にGoogle Web Acceleratorがリンクを先読みした結果、GETで偽装されたDELETE操作が発火し、ユーザーのデータが削除される事故がありました。「安全」の宣言はインフラ全体の自動化にとって不可欠なシグナルです。
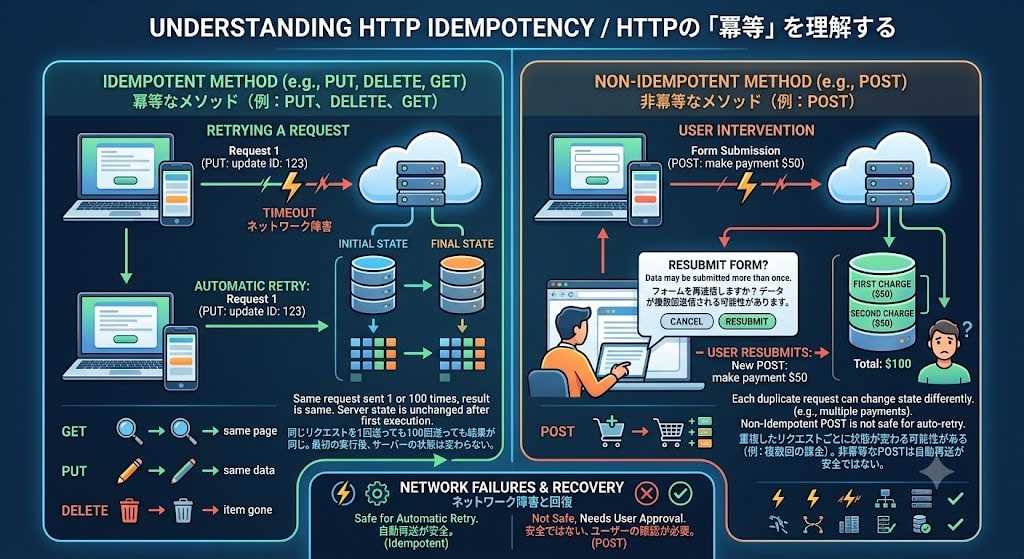
Idempotent(冪等)
同じリクエストを1回送っても100回送っても結果が同じであることを意味します。GET、PUT、DELETEは冪等です。POSTは冪等ではありません(決済を2回送信すれば2回課金される可能性がある)。
なぜ重要か: ネットワーク障害時の自動リトライです。リクエストがタイムアウトした場合、冪等なメソッドであればクライアントやプロキシが自動的に再送できます。POSTの再送は安全ではないため、ブラウザは「フォームを再送信しますか?」と確認ダイアログを出します。
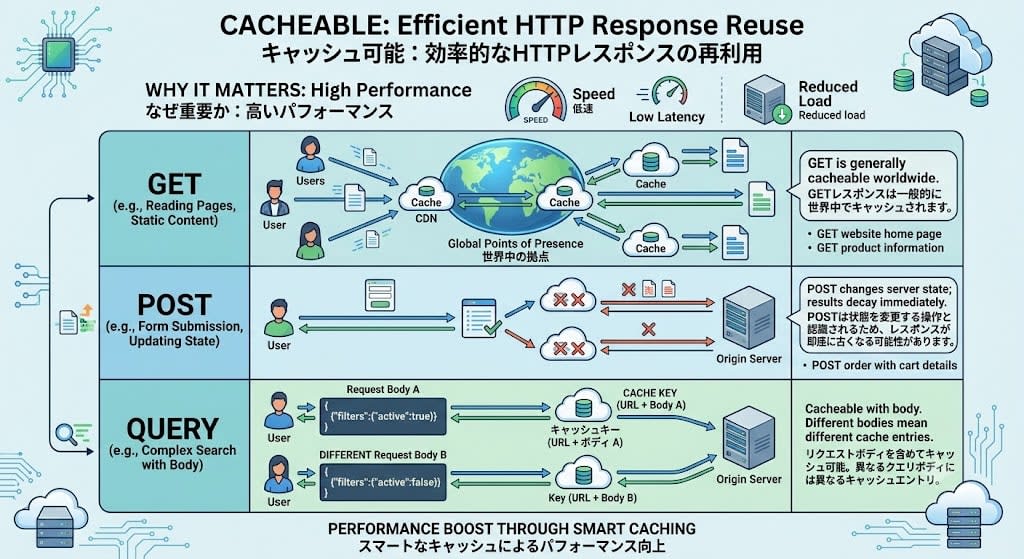
Cacheable(キャッシュ可能)
レスポンスを保存して、同一のリクエストに対して再利用できることを意味します。
なぜ重要か: パフォーマンスです。CDNはGETレスポンスを世界中の拠点にキャッシュします。POSTのレスポンスは一般的にキャッシュされません。なぜなら、キャッシュ機構はPOSTが状態を変更する操作だと認識しているため、レスポンスが即座に古くなる可能性があるからです。QUERYはGETと同様にキャッシュ可能ですが、キャッシュキーにリクエストボディも含めるため、異なるクエリボディには異なるキャッシュエントリが使われます。
QUERYはGETやPOSTの代替ではない
QUERYは既存メソッドの置き換えではなく、これまで適切なメソッドがなかったユースケースを埋めるものです。
| ユースケース | 適切なメソッド | 理由 |
|---|---|---|
| URLでリソースを取得 | GET | シンプル、普遍的、URL自体がリソースの識別子 |
| 少数パラメータの検索 | GET | ?q=shoes&color=red 程度ならURLで十分 |
| リソースの作成・更新・削除 | POST/PUT/DELETE | 状態を変更する操作 |
| 複雑な構造化クエリによる検索 | QUERY | GETのURL制限を超える検索条件 |
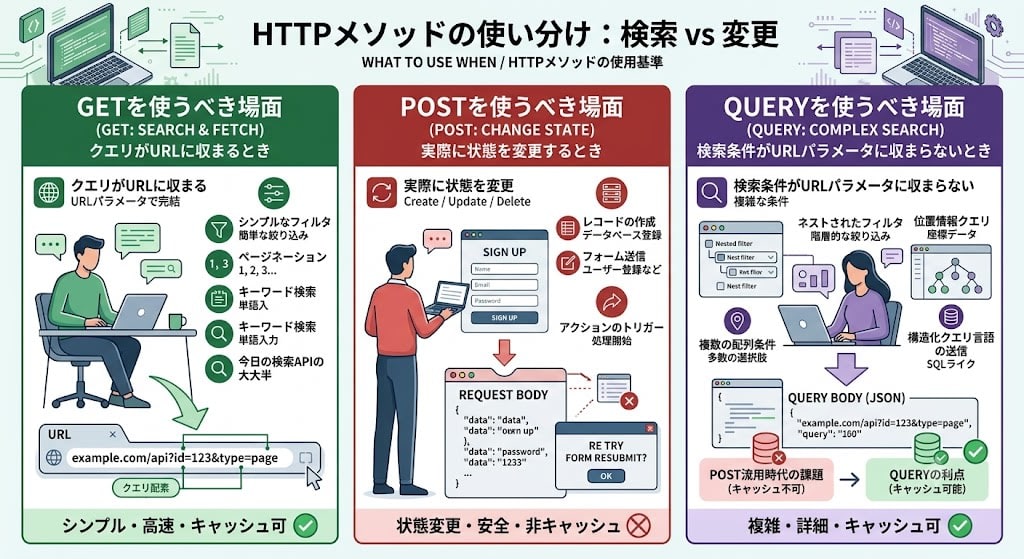
GETを使うべき場面: クエリがURLに収まるとき。シンプルなフィルタ、ページネーション、キーワード検索。今日の検索APIの大半はGETで問題ありません。
POSTを使うべき場面: 実際に状態を変更するとき。レコードの作成、フォーム送信、アクションのトリガー。
QUERYを使うべき場面: 検索条件がURLパラメータに収まらないとき。ネストされたフィルタ、位置情報クエリ、複数の配列条件、構造化クエリ言語の送信。QUERYが存在する以前は、この用途にPOSTを流用し、キャッシュ可能性を犠牲にしていました。
なぜ今まで存在しなかったのか
RFC 10008の共著者は CloudflareのJames Snell氏とAkamaiのMike Bishop氏です。CDN大手2社のエンジニアが仕様を書いたということは、CDNレベルでのQUERYサポートが比較的早く実現する可能性を示唆しています。
長年、検索APIでは「POST /search」というパターンが事実上の標準でしたが、これは意味的には「検索リソースを作成する」という意味になり、実態と乖離していました。QUERYメソッドはこの問題を根本的に解決します。
前提・環境
- Python 3.12+
- Starlette 0.46+(ASGIフレームワーク)
- uvicorn 0.34+
- httpx 0.28+(クライアント)
- uv(パッケージマネージャ)
デモコードは以下のリポジトリにあります:
デモの全体像
商品カタログの検索APIを題材に、同じ検索条件を GET・POST・QUERY の3つのメソッドで実行し、違いを比較します。
検索条件の例:
{
"categories": ["laptops", "phones"],
"price": {"min": 500, "max": 2000},
"tags": ["pro"],
"min_rating": 4.5,
"in_stock": true,
"near": {"lat": 35.68, "lng": 139.76, "radius_deg": 1.0},
"sort": {"field": "price", "order": "desc"}
}
各フィールドの意味:
| フィールド | 型 | 説明 |
|---|---|---|
categories |
string[] | 対象カテゴリ。配列で複数指定(OR条件) |
price |
object | 価格帯。min/maxでネストされた範囲指定 |
tags |
string[] | 商品タグ。配列内すべてに一致(AND条件) |
min_rating |
number | 最低レーティング(0〜5) |
in_stock |
boolean | 在庫ありの商品のみに絞り込み |
near |
object | 位置情報による近傍検索。緯度・経度・半径をネストで指定 |
sort |
object | ソート条件。対象フィールドと昇順/降順をネストで指定 |
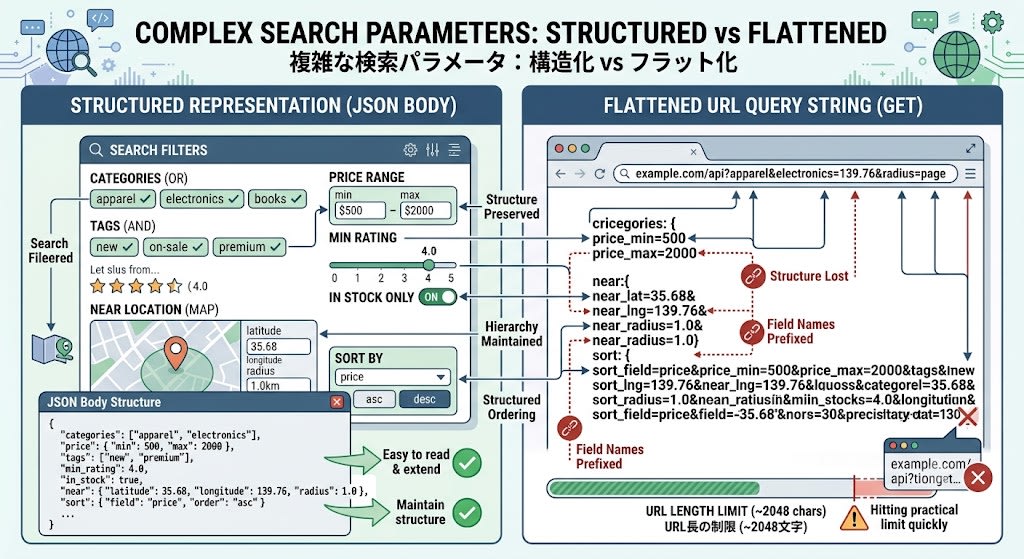
注目すべきは、price、near、sort がネストされたオブジェクトである点です。これらをGETのクエリ文字列で表現しようとすると、price_min=500&price_max=2000&near_lat=35.68&near_lng=139.76&near_radius=1.0 のようにフラットに展開する必要があり、構造が失われます。フィールド数が増えるほどURLは長くなり、実質的な上限(約2048文字)にすぐ到達します。
サーバー実装
プロジェクトセットアップ
# pyproject.toml
[project]
name = "http-query-demo"
version = "0.1.0"
requires-python = ">=3.12"
dependencies = [
"starlette>=0.46",
"uvicorn>=0.34",
"httpx>=0.28",
]
uv sync
uv run uvicorn server:app --reload
QUERYメソッドのルーティング
2026年6月時点では、ほとんどのWebフレームワークがQUERYメソッドをネイティブサポートしていません。Starletteでは Route の methods パラメータにカスタムメソッド名を渡すことで対応できました。
async def search_dispatcher(request: Request) -> JSONResponse:
"""HTTPメソッドに応じてハンドラを振り分け"""
match request.method:
case "GET":
return await search_via_get(request)
case "POST":
return await search_via_post(request)
case "QUERY":
return await search_via_query(request)
case "OPTIONS":
return await product_search_options(request)
case _:
return JSONResponse(
{"error": f"Method {request.method} not allowed"},
status_code=405,
headers={"Allow": "GET, POST, QUERY, OPTIONS"},
)
routes = [
Route(
"/products/search",
search_dispatcher,
methods=["GET", "POST", "QUERY", "OPTIONS"],
),
]
app = Starlette(routes=routes)
ポイントは、Starletteの Route が methods リストに任意の文字列を受け付けてくれることです。フレームワーク側で明示的に「QUERY」をサポートしているわけではなく、未知のメソッド名を受け入れてくれた、という形です。
GETハンドラ: フラットなクエリ文字列の限界
async def search_via_get(request: Request) -> JSONResponse:
params = request.query_params
query: dict[str, Any] = {}
if cats := params.get("categories"):
query["categories"] = cats.split(",")
if price_min := params.get("price_min"):
query.setdefault("price", {})["min"] = int(price_min)
if price_max := params.get("price_max"):
query.setdefault("price", {})["max"] = int(price_max)
# ... near_lat, near_lng, near_radius など個別パラメータが必要
ネストされた構造(price.min, near.lat)を表現するために、フラットなパラメータ名の規約(price_min, near_lat)を自前で定義する必要があります。クライアントとサーバーの間で暗黙の合意が必要になり、OpenAPIスキーマでの表現も煩雑になります。
POSTハンドラ: 動くが、セマンティクスが間違っている
async def search_via_post(request: Request) -> JSONResponse:
body = await request.body()
content_type = request.headers.get("content-type", "")
if "json" not in content_type:
return JSONResponse(
{"error": "Content-Type must be application/json"},
status_code=415,
)
query = json.loads(body)
data = search_products(query)
return JSONResponse(data)
コードはシンプルですが、問題はHTTPのセマンティクスです。
- プロキシやCDNはPOSTを「状態変更を伴う操作」と見なし、レスポンスをキャッシュしない
- ネットワーク障害時に自動リトライが安全でない(同じPOSTを2回送ると副作用が2回起きる可能性がある)
- ブラウザの戻るボタンで「フォームを再送信しますか?」と聞かれるのも、POSTが安全でないことの表れ
QUERYハンドラ: RFC 10008準拠の実装
async def search_via_query(request: Request) -> JSONResponse:
body = await request.body()
# RFC 10008 §3: Content-Typeヘッダが必須
content_type = request.headers.get("content-type", "")
if not content_type:
return JSONResponse(
{"error": "QUERY requests MUST include a Content-Type header (RFC 10008 §3)"},
status_code=400,
)
# RFC 10008 §3: 未対応のメディアタイプには415 + Accept-Queryヘッダで対応タイプを通知
if "json" not in content_type:
return JSONResponse(
{"error": f"Unsupported media type: {content_type}"},
status_code=415,
headers={"Accept-Query": '"application/json"'},
)
# RFC 10008 §4: QUERYレスポンスはキャッシュ可能
# キャッシュキーにリクエストボディのハッシュを含める
cache_key = _cache_key("QUERY", request.url.path, body)
if cached := _get_cached(cache_key):
return JSONResponse(cached, headers={"X-Cache": "HIT"})
try:
query = json.loads(body)
except json.JSONDecodeError as e:
# RFC 10008 §3: 構文的に正しいが意味的に処理できない → 422
return JSONResponse(
{"error": f"Unprocessable query content: {e}"},
status_code=422,
)
data = search_products(query)
_set_cache(cache_key, data)
return JSONResponse(
data,
headers={
"X-Cache": "MISS",
"Accept-Query": '"application/json"',
},
)
RFC 10008が定めるエラーハンドリングのポイント:
| 状況 | ステータスコード | 説明 |
|---|---|---|
| Content-Typeヘッダなし | 400 Bad Request | QUERYはContent-Typeが必須 |
| 未対応メディアタイプ | 415 Unsupported Media Type | Accept-Queryヘッダで対応タイプを通知 |
| パース不能なボディ | 422 Unprocessable Content | メディアタイプは正しいが中身が不正 |

キャッシュの実装
QUERYの最大の優位点はキャッシュ可能性です。GETと違い、キャッシュキーにはURIだけでなくリクエストボディも含める必要があります。
def _cache_key(method: str, path: str, body: bytes) -> str:
body_hash = hashlib.sha256(body).hexdigest()[:16]
return f"{method}:{path}:{body_hash}"
RFC 10008 §4では、キャッシュがボディの「意味的に重要でない差異」を正規化してよいとされています。例えばJSONの場合、キーの順序やインデントの違いは無視できます。ただし、クライアントが no-transform キャッシュディレクティブを指定した場合は正規化を行ってはいけません。
動作確認
curlでQUERYリクエストを送信
curl -s -D - -X QUERY "http://localhost:8000/products/search" \
-H "Content-Type: application/json" \
-d '{
"categories": ["laptops", "phones"],
"price": {"min": 500, "max": 2000},
"tags": ["pro"],
"min_rating": 4.5,
"in_stock": true,
"near": {"lat": 35.68, "lng": 139.76, "radius_deg": 1.0},
"sort": {"field": "price", "order": "desc"}
}'
curlは -X QUERY で任意のHTTPメソッドを指定できるため、そのまま動作します。
1回目のレスポンス(キャッシュ MISS)
HTTP/1.1 200 OK
x-search-method: QUERY
x-cache: MISS
x-cache-key: QUERY:/products/search:7f73fb16e7395e7d
accept-query: "application/json"
x-note: Safe + idempotent + cacheable + structured body (RFC 10008)
{"total":1,"offset":0,"limit":10,"results":[{"id":4,"name":"iPhone 16 Pro",...}]}
2回目のレスポンス(キャッシュ HIT)
同じリクエストを再送すると:
HTTP/1.1 200 OK
x-search-method: QUERY
x-cache: HIT
x-cache-key: QUERY:/products/search:7f73fb16e7395e7d
同じキャッシュキーでヒットしています。POSTではこのキャッシュ動作は仕様上実現できません。
Pythonクライアント(httpx)
import httpx
import json
SEARCH_QUERY = {
"categories": ["laptops", "phones"],
"price": {"min": 500, "max": 2000},
"tags": ["pro"],
}
with httpx.Client(base_url="http://localhost:8000") as client:
# httpxはrequest()メソッドでカスタムHTTPメソッドをサポート
resp = client.request(
"QUERY",
"/products/search",
content=json.dumps(SEARCH_QUERY),
headers={"Content-Type": "application/json"},
)
print(resp.json())
httpxの client.request() は第1引数に任意のHTTPメソッド名を受け付けるため、特別な対応なしでQUERYリクエストを送信できます。
GETのURL長問題を可視化
Pythonクライアントの実行結果から、GETでのURL長を確認:
GET /products/search?... (flat query string)
→ URL length: 212 chars
今回のシンプルな検索条件でも212文字。実務では検索条件が20-30項目になることもあり、URLの実質的な上限(約2048文字)にすぐ到達します。
エラーハンドリングの確認
No Content-Type → 400: QUERY requests MUST include a Content-Type header (RFC 10008 §3)
Wrong Content-Type → 415: Unsupported media type: text/plain
Accept-Query header: "application/json"
Malformed JSON → 422: Unprocessable query content: ...
Accept-Query ヘッダにより、クライアントは「このエンドポイントがどのメディアタイプのQUERYを受け付けるか」を自動的に知ることができます。
QUERYメソッドの重要な仕様ポイント
Accept-Queryヘッダ
サーバーはレスポンスヘッダで Accept-Query を返し、QUERYでサポートするメディアタイプを通知できます。
Accept-Query: "application/json", application/sql;charset="UTF-8"
将来的にJSON以外のクエリ言語(SQLライク、JSONPath等)をサポートする際のコンテンツネゴシエーション基盤になります。
リダイレクトの挙動
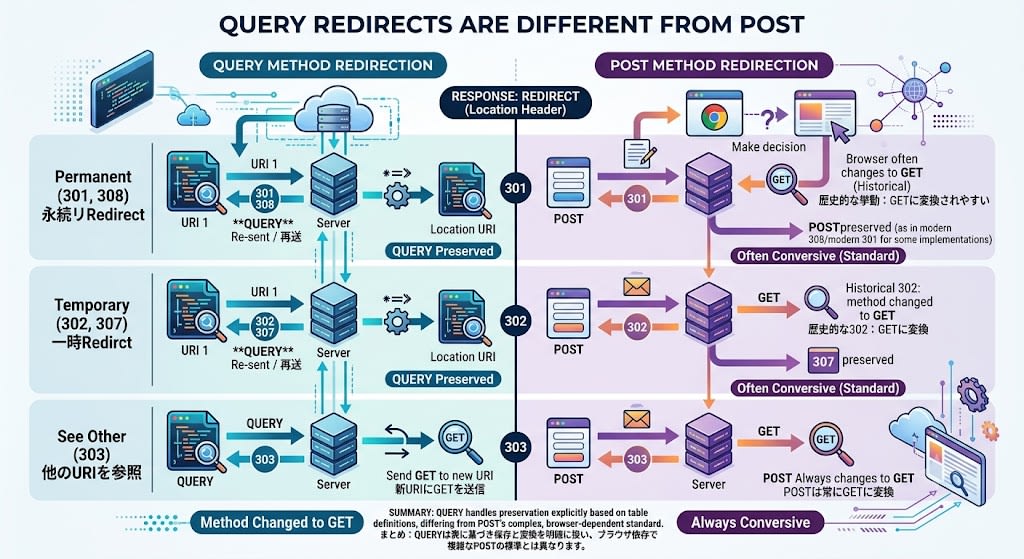
QUERYのリダイレクトはPOSTとは異なります:
| ステータス | 動作 |
|---|---|
| 301/308 (永続) | 新しいURIにQUERYを再送 |
| 302/307 (一時) | 新しいURIにQUERYを再送 |
| 303 (See Other) | 新しいURIにGETを送信 |
POSTの場合、301/302でメソッドがGETに変わる曖昧な挙動がありましたが、QUERYでは明確に定義されています。
CORSの影響
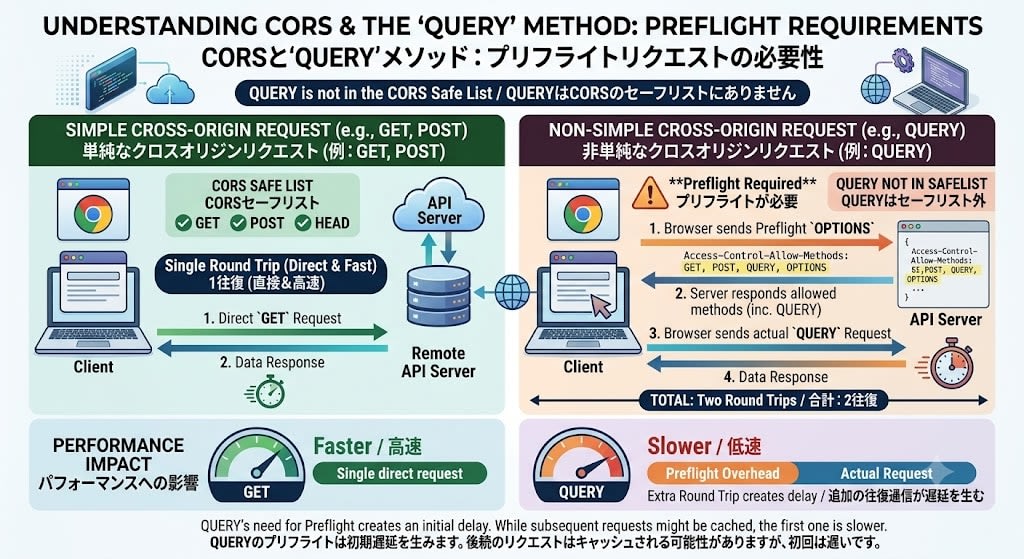
QUERYはCORSのセーフリストに含まれていないため、ブラウザからの送信時はプリフライトリクエスト(OPTIONS)が必要になります。
Access-Control-Allow-Methods: GET, POST, QUERY, OPTIONS
これはブラウザクライアントでのパフォーマンスに影響する可能性があります(追加の往復通信が発生)。
GraphQLとの関係: 競合ではなく補完
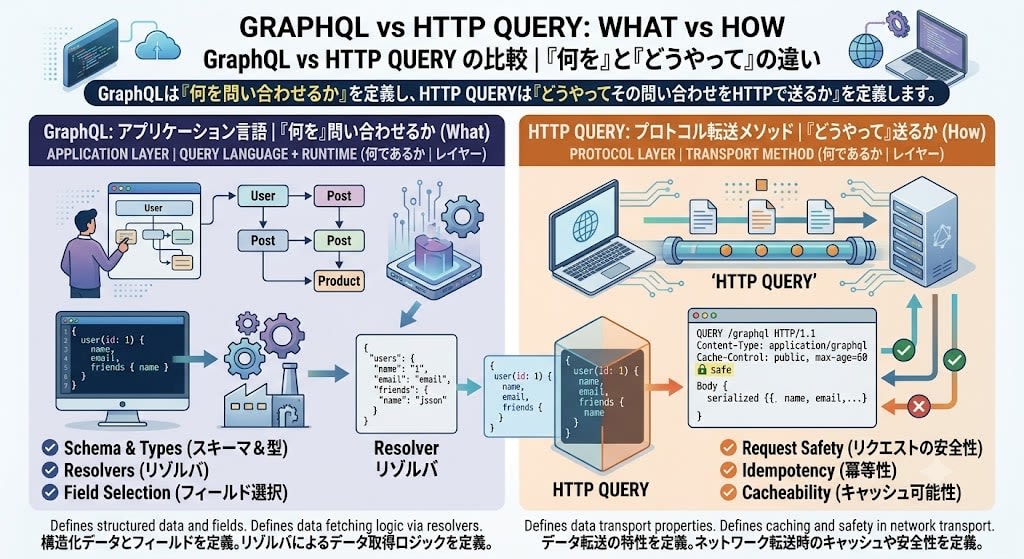
「QUERYメソッドはGraphQLと同じ問題を解こうとしているのか?」という疑問が浮かぶかもしれません。結論から言えば、競合ではなく補完関係です。両者は異なるレイヤーで動作します。
| GraphQL | HTTP QUERY | |
|---|---|---|
| 何であるか | クエリ言語 + ランタイム | トランスポートメソッド |
| レイヤー | アプリケーション層(クエリの表現方法) | プロトコル層(クエリの送信方法) |
| 定義するもの | スキーマ、型、リゾルバ、フィールド選択 | リクエストの安全性、冪等性、キャッシュ可能性 |
GraphQLは「何を問い合わせるか」を定義し、HTTP QUERYは「どうやってその問い合わせをHTTPで送るか」を定義します。
GraphQLの現在のトランスポート問題
今日のGraphQLは主にPOSTでクエリを送信しています:
# 現在のGraphQLの一般的な送信方法
curl -X POST https://api.example.com/graphql \
-H "Content-Type: application/json" \
-d '{"query": "{ products(category: \"laptops\") { name price } }"}'
このため、GraphQLはPOSTの問題をそのまま引き継いでいます:
- CDNがレスポンスをキャッシュしない(POSTは状態変更と見なされる)
- ネットワーク障害時に自動リトライできない
- HTTP層での安全性保証がない
一部のGraphQL実装はGETも使いますが(クエリをURLに入れる)、複雑なGraphQLクエリはすぐにURL長の制限に達します。
QUERYはGraphQLのトランスポートを改善できる
GraphQLの読み取りクエリをQUERYメソッドで送信すれば、両方の利点を得られます:
# GraphQL over HTTP QUERY — 理想的な組み合わせ
curl -X QUERY https://api.example.com/graphql \
-H "Content-Type: application/graphql+json" \
-d '{"query": "{ products(category: \"laptops\") { name price } }"}'
CDNは「これは安全で冪等でキャッシュ可能」と判断できます。GraphQLのmutation(データ変更)はPOSTのまま — mutationは実際に状態を変更するので、POSTのセマンティクスが正しいです。
本当の競合軸
市場がGraphQLかQUERYかを選ぶ必要はありません。競合するのはAPI設計哲学のレベルです:
| 比較 | 競合? |
|---|---|
| GraphQL vs REST | Yes — API設計アプローチの違い |
| HTTP QUERY vs 検索にPOST流用 | Yes — QUERYがPOSTワークアラウンドを置き換える |
| GraphQL vs HTTP QUERY | No — レイヤーが異なり、組み合わせ可能 |
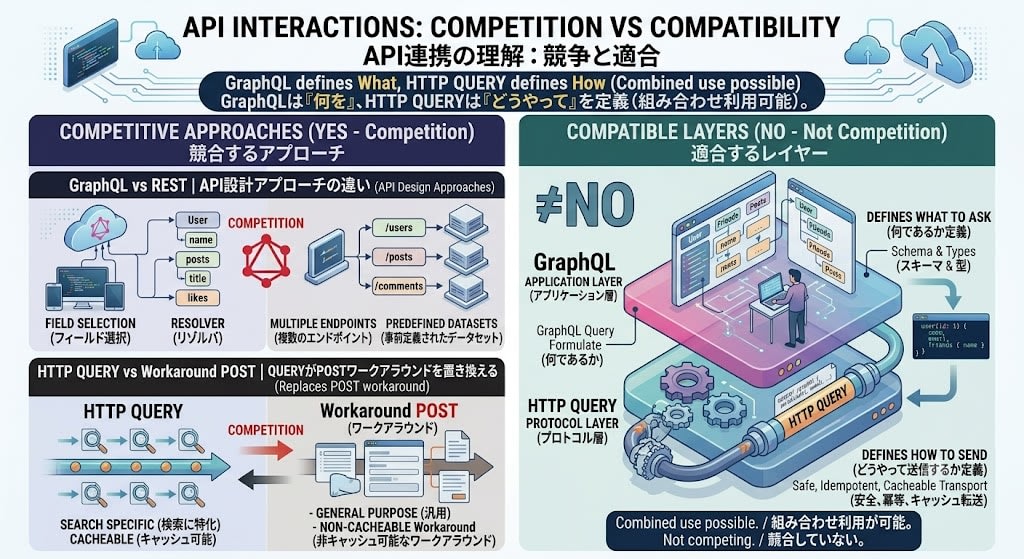
むしろGraphQLチームにとってQUERYは朗報です。GraphQL自体を何も変えずに、HTTPトランスポート層のキャッシュ問題が解決する可能性があるからです。
フレームワーク対応状況(2026年6月時点)
| フレームワーク | QUERYサポート | 備考 |
|---|---|---|
| Starlette | カスタムメソッドとして可 | methods=["QUERY"] で動作 |
| Express.js | app.query() は未実装 |
app.all() + 手動判定で対応可能 |
| FastAPI | Starlette経由で可 | ネイティブデコレータは未対応 |
| Spring Boot | カスタムアノテーション要 | @RequestMapping(method="QUERY") |
| Ruby on Rails | 議論中 | 提案がフォーラムに出ている |
フレームワーク、リバースプロキシ、APIゲートウェイ、CDN、WAFのすべてが対応しないと、本番環境での利用は難しい状況です。ただし、仕様の共著者がCloudflareとAkamaiのエンジニアである点は、CDNレベルのサポートが早期に実現する可能性を示唆しています。
まとめ
RFC 10008のHTTP QUERYメソッドは、長年の「検索APIにはPOSTを使うしかない」というワークアラウンドに対する正式な解答です。
QUERYが解決すること:
- GETでは不可能だった構造化されたリクエストボディの送信
- POSTで失われていた安全性・冪等性・キャッシュ可能性の回復
Accept-Queryヘッダによる明示的なコンテンツネゴシエーション
現時点での制約:
- フレームワークのネイティブサポートはほぼない(カスタムメソッドとして対応可能なものは多い)
- CDN・プロキシ・WAFのサポートはこれから
- CORSプリフライトが必要(ブラウザクライアント向けAPI)
今すぐ本番投入するフェーズではありませんが、仕様を理解して備えておく価値はあります。特に、複雑な検索条件を持つAPIを設計する際は「将来QUERYに移行しやすい設計」を意識しておくとよいでしょう。









