
Supabase Realtime 利用時に遭遇した、再現できない接続不具合を追いかけた記録
はじめに
開発中に不具合が出たら原因を調べて直す。普段はそれで済みますが、「出たり出なかったりする」不具合はそうはいきません。いわゆる間欠障害です。
この記事では、Supabase Realtime を使った開発で間欠障害に遭遇し、原因を追いかけたものの特定には至らなかった経緯を紹介します。きれいに解決する話ではありませんが、間欠障害に対して自分がどう考え、何を試し、何がわかって何がわからなかったか、その記録を残します。
ストレステストの様子
間欠障害とは
タイミング依存の競合状態や、外部サービスの一時的な不安定さ、環境固有の条件など、複数の要因が重なったときにだけ発現する障害です。通常のテストでは検出できず、本番環境で突然現れることが多いため、対処が後手に回りがちです。
対象読者
- Supabase Realtime で接続障害に遭遇して困っている方
- 外部サービス連携で間欠的な不具合を経験したことがある方
- 再現できない不具合にどうアプローチすべきか参考にしたい方
参考
何が起きたか
以前の記事で、Supabase Realtime の Presence を使った対戦ゲームの実装例を紹介しました (記事リンク) 。これを Vercel にデプロイしたところ、チャネルの subscribe が SUBSCRIBED に到達せず CHANNEL_ERROR や TIMED_OUT で止まる症状が出始めました。毎回ではなく、出るときと出ないときがあります。Supabase Console から restart project を実行すると一時的に復旧しますが、しばらくするとまた発生します。デモに支障が出るほど頻発していたため、早急に手を打つ必要がありました。
厄介だったのは、当時の実装で subscribe のエラーをきちんとハンドリングしていなかったことです。
.subscribe(async (status, err) => {
if (status === "SUBSCRIBED") {
await channel.track({});
setIsConnected(true);
} else if (status === "CHANNEL_ERROR" || status === "TIMED_OUT") {
console.error("[Realtime] connection failed:", status, err);
// ← リトライも UI 通知もなし
}
});
コンソールにエラーは出していましたが、画面には何も表示されません。ユーザーから見ると、アプリが無言で固まるだけです。 この設計が問題の切り分けをさらに難しくしていました。
当時は「切断処理が甘くてサーバーにゴミが溜まっているのだろう」と考え、beforeunload / pagehide による切断処理の追加、removeAllChannels への変更、ハートビート間隔の短縮を同日中に立て続けに投入しました。なお、beforeunload / pagehide はブラウザやモバイル環境によって必ず発火するとは限らないため、これだけに依存した cleanup は堅牢とは言えません。途中で一度「直った」と判断してコミットしましたが再発し、さらに対策を重ねています。最終的に症状は収まりました。しかしどの対策が効いたのか、そもそも対策が効いたのかはわからないままでした。
仮説と検証
後日、改めて原因を調べることにしました。3 つの仮説を順に検証しています。
仮説 1: Presence セッションの残留
当時の自分が最も疑っていたシナリオです。切断処理の不備でサーバーに Presence セッションが残留し、チャネルの状態が壊れているのではないか。cleanup を強化した理由もここにあります。
Presence のみを使う最小構成の再現アプリを作り、対策前の実装 (beforeunload のみ、removeChannel) でタブの開閉を繰り返しました。
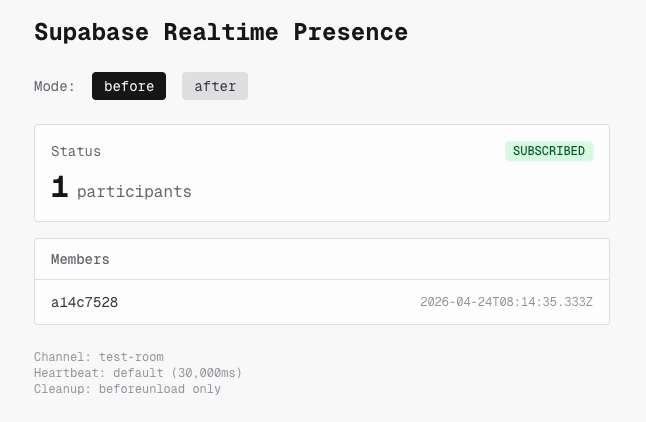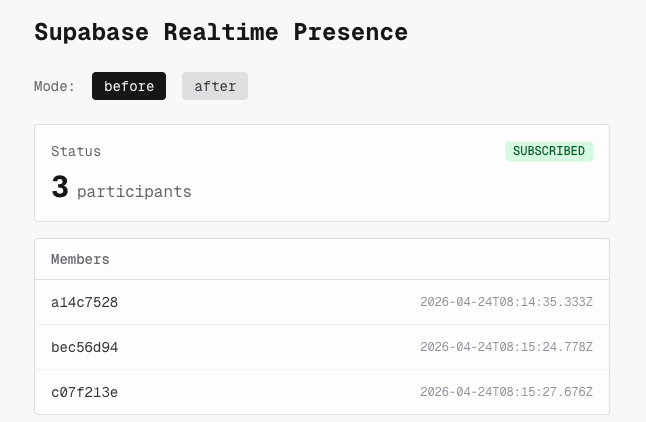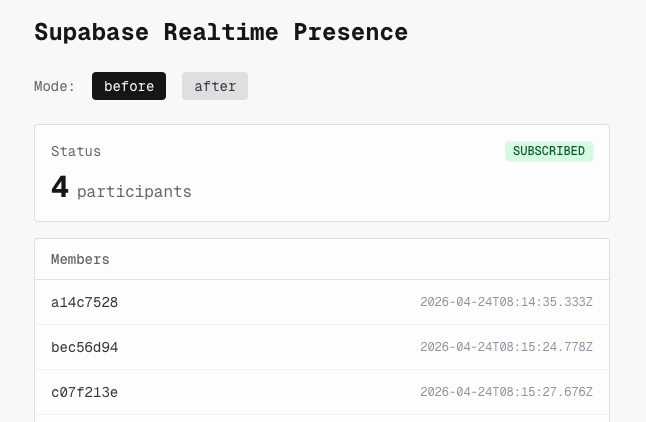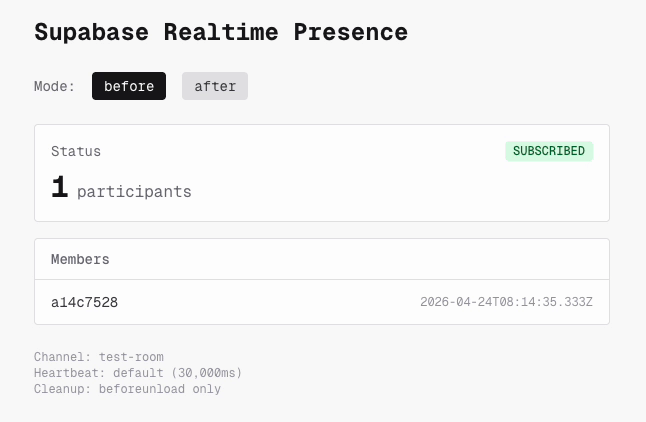
結果として、不具合は再現しませんでした。 タブを閉じると Presence の参加者数は速やかに減少し、セッションの残留は起きませんでした。
仮説 2: WebSocket 接続数の上限到達
Supabase のドキュメントには、Free プランの Realtime 同時接続上限が 200 と記載されています。開発中のリロードやタブ開閉で接続が蓄積し、上限に達しているのではないかという仮説を立てました。
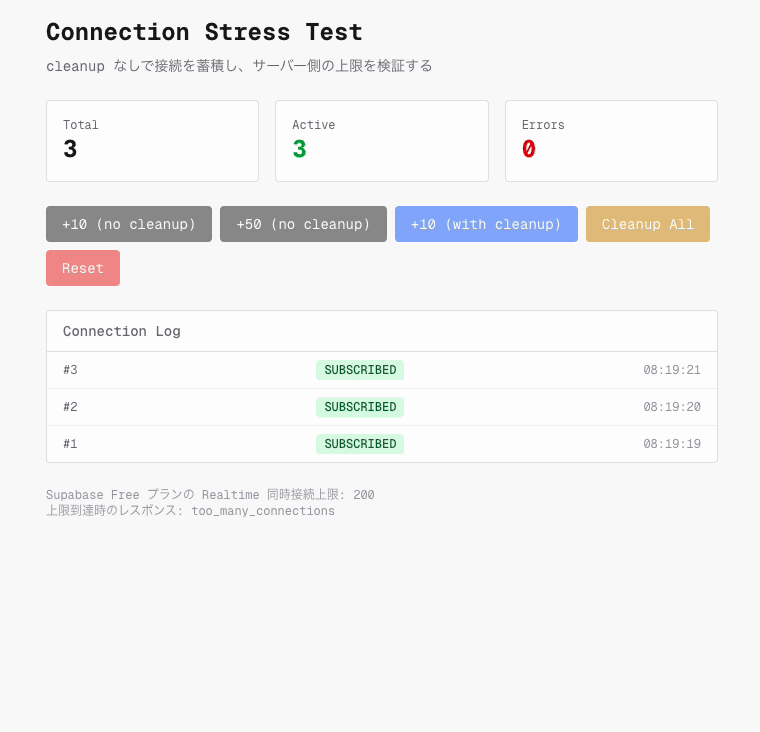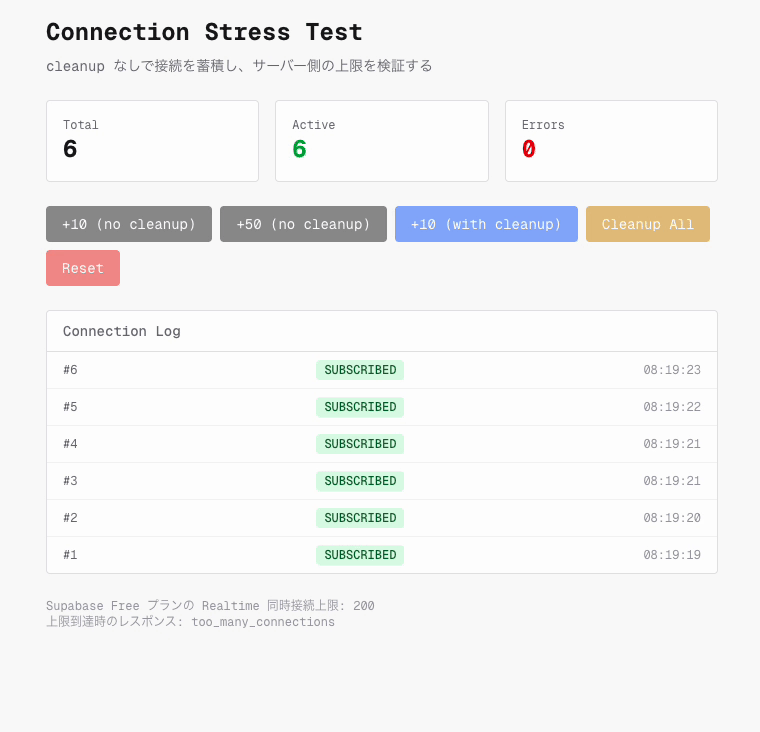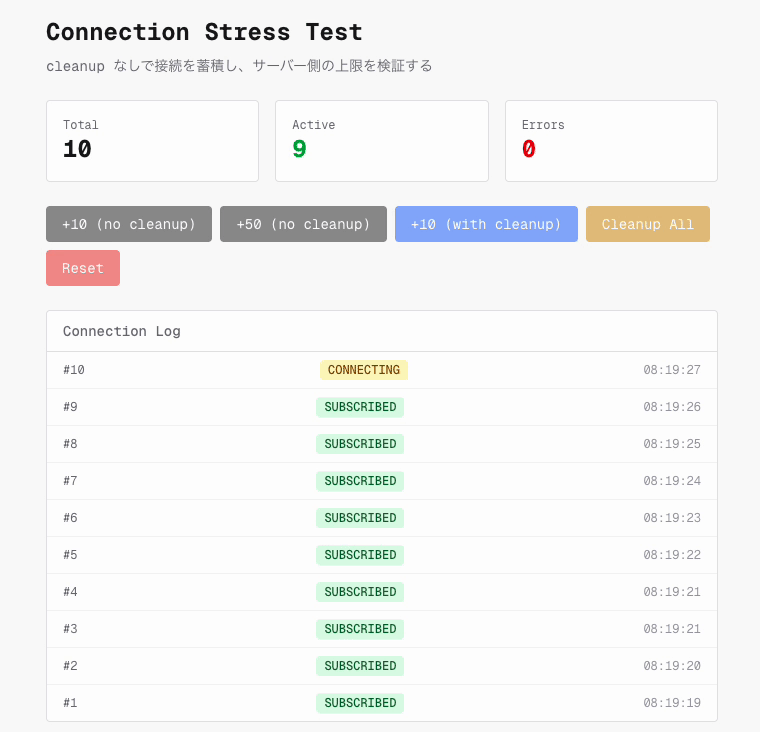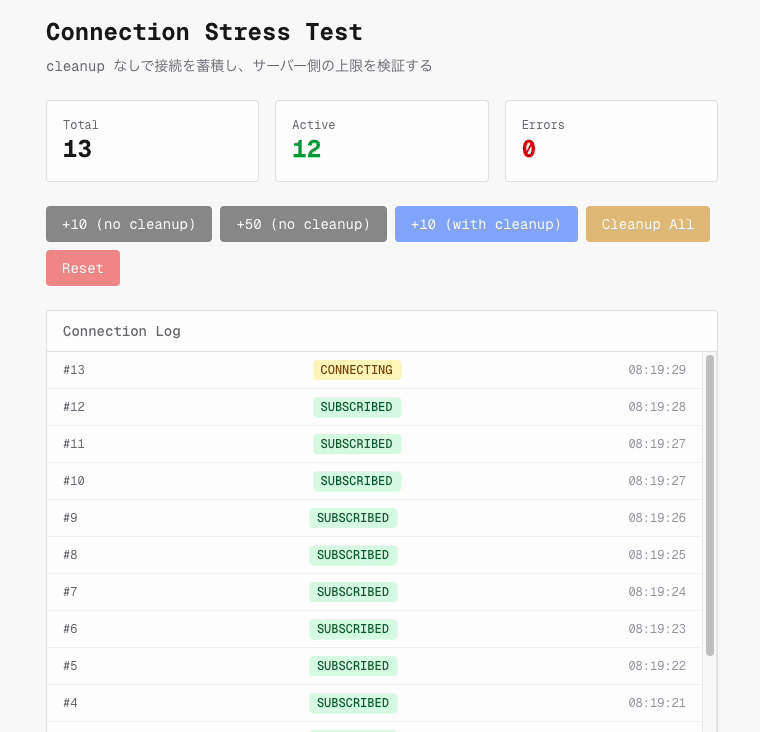
そこで cleanup なしで WebSocket 接続を連続生成するストレステストを実施しました。
少なくとも今回の検証条件では、接続数を 250 に増やしても too_many_connections は観測されませんでした。 Network タブで確認すると、250 本すべてが status 101 で接続に成功しています。そのため、当時の障害を単純な同時接続数上限だけで説明するのは難しいと判断しました。
仮説 3: 元のコードに再現性のある問題がある
最後の手段として、元プロジェクトを clone し、対策前のコミットまで戻してログを仕込み、同じ Supabase プロジェクトに対してローカルと Vercel の両方で動かしました。
ところが 両方で正常に動作しました。 subscribe は毎回 SUBSCRIBED を返し、問題は再現しません。
消去法で残ったもの
今回検証した 3 つの仮説では、当時の症状を再現できませんでした。
手がかりとして残ったのは 2 つです。1 つは、Supabase Realtime のログに MigrationsFailedToRun や ErrorOnRpcCall: timeout が記録されていたこと。もう 1 つは、restart project を実行すると一時的に復旧していたことです。
これらの状況から、当時の問題はアプリケーションコード単体では説明しづらく、Supabase プロジェクト側の状態、Realtime サーバー、PostgreSQL との連携、あるいは一時的な外部環境の不安定さなど、複数の要因が関係していた可能性があると考えています。
ただし、これはあくまで当時観測できたログと挙動からの推測です。問題発生時の詳細なサーバーログは当時利用していたプランでは 24 時間しか保持されておらず、既に失われています。Supabase 側の不具合だったと断定するものではありません。
当時の対策は、問題の原因に対する修正ではなかった可能性があります。対策を試行錯誤する過程で何度も restart project を実行しており、それがプロジェクトの状態をリセットして復旧に至っていたのでしょう。
振り返り
原因は特定できませんでした。この調査を通じていくつかの学びがあります。
まず、間欠障害に対して思い込みで対策を重ねることの危うさ です。当時の自分は「切断処理を見直せば解消するはず」と決めつけて対策を投入し、症状が収まったことで満足してしまいました。原因がわからないまま「直ったからよし」とするのは、次に同じことが起きたとき同じ手探りを繰り返すことを意味します。
次に、エラーハンドリングの不備が間欠障害を致命的にする こと。subscribe の CHANNEL_ERROR / TIMED_OUT を握りつぶしていたために、障害が発生してもアプリは黙って止まるだけでした。ログを見なければ何が起きたかすらわかりません。間欠障害に限らず、外部サービスとの接続には適切なエラーハンドリングとリトライが不可欠です。
まとめ
3 つの仮説を検証し、すべて否定された結果、消去法で「実行環境側の一時的な問題だった」という推測に至りました。原因を特定できなかったのは悔しいですが、仮説を潰すプロセスを踏んだことで得られた知見はありました。間欠障害に遭遇した際の考え方として、同じようなケースに遭遇された方の参考になれば幸いです。








