![[アップデート] Amazon Redshift Apache Iceberg テーブルへ ALTER TABLE できるようになったので試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[アップデート] Amazon Redshift Apache Iceberg テーブルへ ALTER TABLE できるようになったので試してみた
クラウド事業本部の石川です。Amazon Redshift から Apache Iceberg テーブルへの ALTER TABLE DDL と、AWS Glue Data Catalog (awsdatacatalog) マウント経由での書き込みがサポートされましたので、実際に試してみました。
Amazon Redshift では 2025 年 11 月の append-only 書き込みサポート、2026 年 4 月の UPDATE/DELETE/MERGE サポートを経て、ついに Iceberg テーブルのスキーマ進化を Redshift から直接管理できるようになりました。
これまで Iceberg テーブルのスキーマ変更には、テーブルとデータを削除して再作成する必要があり、データパイプラインに余計な複雑性と遅延が生じていました。今回のアップデートで、ADD/DROP/ALTER COLUMN、RENAME COLUMN、SET TABLE PROPERTIES、ADD/DROP/REPLACE PARTITION FIELD といった ALTER TABLE 操作が利用可能になり、データ量の増加に応じてパーティション戦略を後から進化させることもできます。
また、auto-mount された awsdatacatalog 経由で Redshift が直接書き込めるようになったため、外部スキーマを作らずに3パート記法 awsdatacatalog.<database>.<table> でデータレイクへ書き出すことが可能になりました。Lake Formation でフェデレーションされた Iceberg テーブルへの書き込みもサポートされています。
※ auto-mount された awsdatacatalog 経由 とは、2023年7月にGAされた automatic mounting of AWS Glue Data Catalog で、AWS Glue Data Catalog をアカウント内のデータベースとして自動的にマウントし、3パート表記でデータレイクのテーブルをクエリできるようにする機能です。
ALTER TABLE for Iceberg とは
Amazon Redshift から発行できる Iceberg テーブル向けの ALTER TABLE は、次の 5 種類です。
ALTER TABLE ADD COLUMN/DROP COLUMNALTER TABLE ALTER COLUMN TYPE(型ワイドニングのみ。int → bigint、float → double、decimal(P,S) → decimal(P2,S)で P2 > P)ALTER TABLE RENAME COLUMNALTER TABLE SET TABLE PROPERTIES(現時点ではcompression_typeのみ。設定可能な値はbrotli/gzip/snappy/uncompressed/zstd)ALTER TABLE ADD / DROP / REPLACE PARTITION FIELD
ALTER 文はすべてメタデータ操作で、既存のデータファイルは書き換わりません。利用にあたっての制約は次のとおりです。
- Iceberg v2 テーブルのみサポート
- 複合型 (complex type) カラムを持つテーブルではサポートされない
RENAME COLUMNは AWS Lake Formation 登録テーブルではサポートされないvoidtransform は ALTER 文では使えない
やってみた
前提条件
- AWS アカウント(東京リージョン)
- Redshift Serverless ワークグループ
devio-wg(patch version 201、workgroup version 1.0.300094) - Redshift Serverless ネームスペース
devio-ns(default IAM Role に Glue/S3 への書き込み権限あり) - 検証用 Glue Database
cm_blog_iceberg - 検証用 S3 バケット
cm-blog-iceberg - 検証日: 2026 年 5 月 19 日
SQL はすべて Amazon Redshift Data API (aws redshift-data execute-statement) 経由で発行しています。
認証
awsdatacatalog 3パート記法での書き込み(CREATE TABLE / INSERT / ALTER 等)は、Redshift エンジンが裏側で Glue Data Catalog と S3 を呼び出すため、その API 呼び出しに使う IAM セッションクレデンシャルが「現在の DB セッション」に紐づいている必要があります。そのため、psql で admin + パスワード認証(Secrets Manager 由来の管理者パスワード)で接続したセッションには IAM 認証情報が一切含まれません。よって書き込み時点で Redshift は使えるクレデンシャルを見つけられず、
ERROR: No session credential found
を返します。
「Redshift のユーザーとパスワードで psql」→「IAM セッションがない」→「awsdatacatalog 書き込み不可エラー」となります。そのため、下記のように IAM 認証情報を含む一時クレデンシャルを取得してクエリを実行しました。
% CREDS=$(aws redshift-serverless get-credentials \
--workgroup-name devio-wg \
--db-name dev \
--duration-seconds 3600 \
--region ap-northeast-1)
export PGUSER=$(echo "$CREDS" | jq -r '.dbUser')
export PGPASSWORD=$(echo "$CREDS" | jq -r '.dbPassword')
export PGHOST=devio-wg.<AWS_ACCOUNT_ID>.ap-northeast-1.redshift-serverless.amazonaws.com
export PGPORT=5439
export PGSSLMODE=require
psql -d dev
psql (14.20 (Homebrew), server 8.0.2)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, bits: 128, compression: off)
Type "help" for help.
なお、Query Editor v2(マネコン)やRedshift Data APIから実行した場合は、上記のような対策は不要です。
Iceberg テーブルの作成(awsdatacatalog 経由)
外部スキーマを作らずに、3パート記法 awsdatacatalog.<database>.<table> で直接テーブルを作成します。year(order_date) と bucket(8, customer_id) の 2 段パーティションにしてみました。
dev=# CREATE TABLE awsdatacatalog.cm_blog_iceberg.customer_orders (
customer_id INT,
order_date DATE,
order_amount DECIMAL(10, 2),
region VARCHAR
)
USING ICEBERG
LOCATION 's3://cm-blog-iceberg/customer_orders/'
PARTITIONED BY (year(order_date), bucket(8, customer_id));
CREATE TABLE
なお、最初は region VARCHAR(50) と書いて実行したところ、以下のエラーが返ってきました。
ERROR: VARCHAR(N) specifiying length is not supported for column "region" in Iceberg table.
Hint: Use VARCHAR for strings in Iceberg tables.
Iceberg テーブルでは VARCHAR の長さ指定はサポートされないため、VARCHAR のままにする必要があります。長さ指定を外して再実行したところ、CREATE TABLE は約 10 秒で成功しました。
INSERT INTO で書き込み
awsdatacatalog 経由の INSERT も問題なく動きます。
dev=# INSERT INTO awsdatacatalog.cm_blog_iceberg.customer_orders
(customer_id, order_date, order_amount, region) VALUES
(1001, DATE '2025-01-15', 100.50, 'us-east-1'),
(1002, DATE '2025-06-20', 250.75, 'us-west-2'),
(1003, DATE '2026-01-10', 80.00, 'eu-west-1'),
(1004, DATE '2026-03-05', 500.00, 'ap-northeast-1'),
(1005, DATE '2026-05-18', 175.25, 'ap-northeast-1');
INSERT 0 5
5 行の INSERT が約 4 秒で完了しました。これで ALTER TABLE 検証の準備が整いました。
ALTER TABLE ADD COLUMN
まずはカラムの追加です。後付けで discount_rate DECIMAL(5, 2) を増やしてみます。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
ADD COLUMN discount_rate DECIMAL(5, 2);
ALTER TABLE
メタデータ操作のみのため、行数が増えても所要時間は変わりません。既存行の追加カラムは NULL になります。
ALTER TABLE ALTER COLUMN TYPE(型ワイドニング)
続けて、追加した discount_rate の precision を 5 から 8 に拡張してみます。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
ALTER COLUMN discount_rate TYPE DECIMAL(8, 2);
ALTER TABLE
DECIMAL の precision 拡張は scale を変更しない範囲で許可されています。int → bigint や float → double も同様に動作します。
ALTER TABLE RENAME COLUMN
カラム名を region から sales_region に変更してみます。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
RENAME COLUMN region TO sales_region;
ALTER TABLE
公式ドキュメントによると、Lake Formation 登録テーブルでは RENAME COLUMN はサポートされない点に注意が必要です。本検証は Lake Formation 未登録のテーブルのため、問題なく成功しました。
ALTER TABLE SET TABLE PROPERTIES(圧縮タイプの変更)
データファイルの圧縮タイプを snappy(デフォルト)から zstd に切り替えます。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
SET TABLE PROPERTIES ('compression_type' = 'zstd');
ALTER TABLE
SET TABLE PROPERTIES で設定変更後に INSERT したデータには新しい圧縮タイプが適用されます。既存のデータファイルは書き換わりません。
ALTER TABLE ADD PARTITION FIELD(パーティション進化)
ここからはパーティション進化を試します。まずは sales_region カラムへ truncate(3, ...) 変換を追加してみます。これにより、us-east-1 と us-west-2 は同じ us- というパーティションプレフィックスにまとまります。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
ADD PARTITION FIELD truncate(3, sales_region);
ALTER TABLE
ALTER TABLE REPLACE PARTITION FIELD
既存の year(order_date) を month(order_date) に変更してみます。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
REPLACE PARTITION FIELD year(order_date) WITH month(order_date);
ALTER TABLE
REPLACE では、置き換え元のフィールドが「最後のレベル」である必要はありません。任意のレベルのフィールドを別の変換に差し替えできます。
ALTER TABLE DROP PARTITION FIELD
最初に設定した bucket(8, customer_id) を削除します。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
DROP PARTITION FIELD bucket(8, customer_id);
ALTER TABLE
DROP PARTITION FIELD も任意のレベルのフィールドを指定できます。ALTER 後に挿入されたデータは新しいパーティション仕様に従い、既存データはそのままです。
ALTER TABLE DROP COLUMN
最後に、追加していた discount_rate カラムを削除します。
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
DROP COLUMN discount_rate;
ALTER TABLE
パーティション仕様に含まれるカラムは DROP COLUMN できないので、先に DROP PARTITION FIELD でパーティションから外す必要があります。
SHOW TABLE で最終スキーマを確認
ここまでの変更がどう反映されたかを SHOW TABLE で確認します。
dev=# SHOW TABLE awsdatacatalog.cm_blog_iceberg.customer_orders;
Show Table DDL statement
--------------------------------------------------------------------------------------
CREATE TABLE awsdatacatalog.cm_blog_iceberg.customer_orders (customer_id int, +
order_date date, +
order_amount decimal(10, 2), +
sales_region varchar) +
USING ICEBERG +
LOCATION 's3://cm-blog-iceberg/customer_orders'+
PARTITIONED BY (MONTH(order_date), TRUNCATE(3, sales_region)) +
TABLE PROPERTIES ('compression_type'='zstd');
(1 row)
(END)
region は sales_region にリネームされ、discount_rate は消えています。パーティションは (MONTH(order_date), TRUNCATE(3, sales_region)) に進化し、圧縮タイプも zstd に切り替わっています。
SELECT で既存データが残っていることを確認
ALTER TABLE はメタデータ操作のみなので、既存データはそのまま読めるはずです。
dev=# SELECT customer_id, order_date, order_amount, sales_region
FROM awsdatacatalog.cm_blog_iceberg.customer_orders
ORDER BY customer_id;
customer_id | order_date | order_amount | sales_region
-------------+------------+--------------+----------------
1001 | 2025-01-15 | 100.50 | us-east-1
1002 | 2025-06-20 | 250.75 | us-west-2
1003 | 2026-01-10 | 80.00 | eu-west-1
1004 | 2026-03-05 | 500.00 | ap-northeast-1
1005 | 2026-05-18 | 175.25 | ap-northeast-1
(5 rows)
INSERT した 5 行がそのまま参照できました。リネーム後のカラム名で問題なくクエリできています。
Athena からのクロスエンジン互換性を確認
Redshift 経由で行ったスキーマ変更が、他の Iceberg 互換エンジンからも見えるかを確認します。Athena から同じテーブルをクエリしてみました。
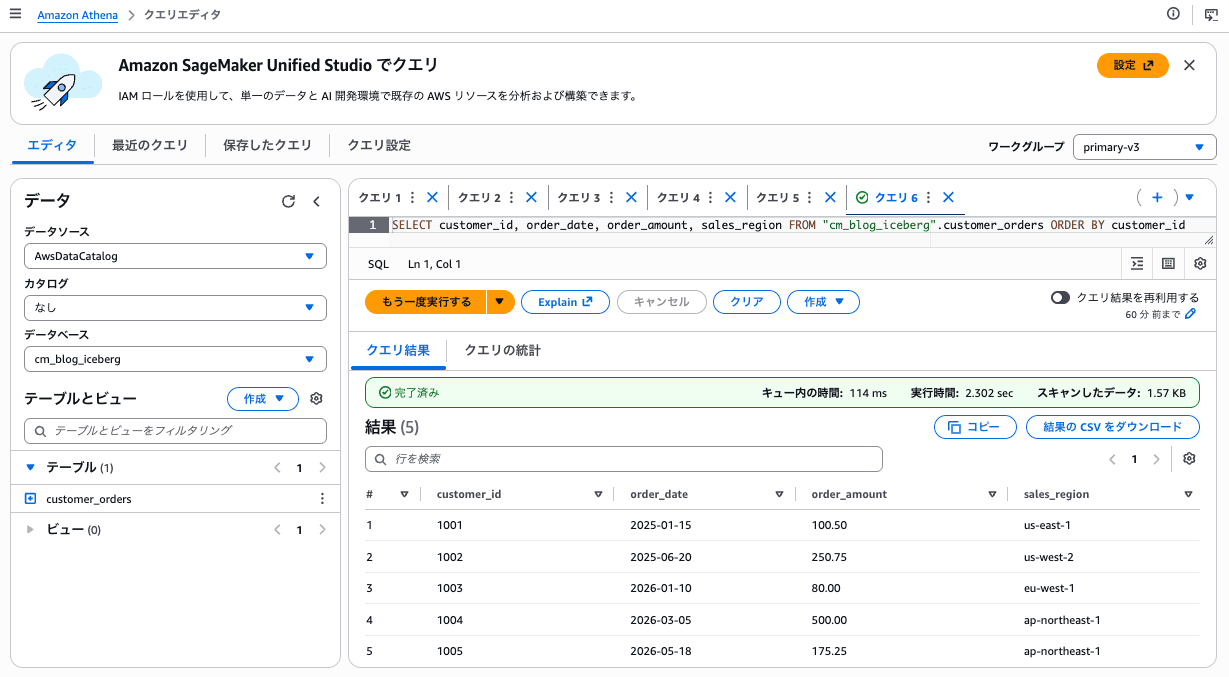
Redshift で行ったリネームや DROP COLUMN が Athena からもそのまま反映されており、クロスエンジン互換性が維持されていることが確認できました。
失敗ケースを確認しておく
ドキュメントに記載されている制約が実際にどんなエラーで返ってくるかも見ておきます。
1. 型 narrowing は拒否される
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
ALTER COLUMN order_amount TYPE DECIMAL(8, 2);
ERROR: Cannot change column "order_amount" from type "numeric(10, 2)" to "numeric(8, 2)"
DETAIL: Only type widening is supported for Iceberg tables.
HINT: Supported type changes: integer to bigint, real to double precision, or numeric with increased precision (same scale).
エラーメッセージで許可される型変更がそのまま示されるので、対応が分かりやすいです。
2. 既にパーティションに含まれるカラムは別の変換で再パーティション化できない
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
ADD PARTITION FIELD year(order_date);
ERROR: Column "order_date" is already part of an existing partition field in table "customer_orders"
order_date は直前のステップで month(order_date) で使われているので、year(order_date) を追加することはできません。
3. void transform は使えない
dev=# ALTER TABLE awsdatacatalog.cm_blog_iceberg.customer_orders
ADD PARTITION FIELD void(customer_id);
ERROR: Unknown Iceberg transform function: "void".
void は Iceberg 仕様では非互換のパーティションを表現するためのものですが、Redshift ではそもそも transform 関数として認識されません。
考察
実際に試してみて感じたポイントを整理します。
- すべてのALTER 操作が数秒で完了する: メタデータ操作のため、テーブルサイズに関係なく短時間で完了します。dev 用テーブルでも本番テーブルでも、ダウンタイムを気にせずスキーマ進化を進められそうです。
- awsdatacatalog 経由の3パート記法が便利: 外部スキーマを作らずにそのまま
awsdatacatalog.<database>.<table>で書き込めるので、シンプルな ELT パイプラインを Redshift だけで完結できます。Lake Formation 連携も視野に入ります。 - クロスエンジン互換性が維持される: Redshift 側で変更したスキーマが Athena(あるいは EMR/Spark など)からそのまま見えるのは、データレイクのオープン性という観点で重要です。
- VARCHAR(N) の落とし穴: 普段の Redshift CREATE TABLE 感覚で
VARCHAR(50)と書いてしまうとエラーになります。Iceberg テーブルではVARCHARのみと割り切りが必要です。 - 型ワイドニングの制約:
int → bigintのように1方向のみ。decimal は precision を増やす方向のみで、scale は変えられません。本番運用では拡張のタイミングで型を広く取っておく方針が現実的です。 RENAME COLUMNの Lake Formation 制約: Lake Formation 登録テーブルではリネームができない点はワークロード設計時に意識する必要があります。- パーティション進化は強力だが既存データは再分散されない: ADD/REPLACE/DROP PARTITION FIELD いずれもメタデータのみで、過去データのファイル配置は変わりません。新しいパーティションが効くのは ALTER 後に挿入したデータのみという点に注意です。
今後は SET TABLE PROPERTIES で扱える property の拡充や、複合型カラムを持つテーブルでの ALTER TABLE サポートにも期待したいところです。
最後に
Amazon Redshift の Iceberg 書き込みは、append-only から UPDATE/DELETE/MERGE 、 ALTER TABLE と着実に強化されてきました。今回のアップデートで、Redshift をデータレイクへの書き込みハブとして使う場合に、テーブル削除して作り直すという回避策がついに不要になりました。
awsdatacatalog の auto-mount を使えば外部スキーマすら作らずに ELT パイプラインを組めるので、Redshift で集計した結果をデータレイクに書き戻し、Athena や EMR から共有するという構成がよりシンプルになります。Iceberg テーブルを使ったレイクハウス構成を採用中の方や、これから本格的に Iceberg に乗せていく予定の方にはぜひ試していただきたい機能です。この記事がどなたかのお役に立てば幸いです。
合わせて読みたい









