
AIエージェントで実現する製造業のスマートデータワークフロー #IND305 #AWSreInvent
「データサイロ化された製造業データの統合、去年のワークショップとはアプローチが違う!」
開催中のre:Invent 2025のチョークトーク「AI Agents in Manufacturing: Building Intelligent Data Workflows」において、AIエージェントを使った製造業データワークフローの構築方法について聞いてきたので、その内容をお届けします。
既に、GitHubにもソースコードが公開されているようで、さらに、チョークトークならではのQ&Aも非常に豊富で参考になったので、皆さんにもその内容をお届けします。
セッション内容

AI Agents in Manufacturing: Building Intelligent Data Workflows
セッション概要
Manufacturing organizations often struggle with data silos and lengthy analysis cycles that delay decision-making. This session introduces Agentic Data Exploration using Amazon Bedrock Agents to automate analysis across various data sources. We'll explore how multi-agent workflows can seamlessly integrate structured databases, analytics exports, unstructured text, multimedia, and APIs for near real-time insights. Learn practical implementation patterns for orchestrating specialized AI agents in distributed problem solving scenarios. We will demonstrate how to reduce analysis timeframes from months to minutes while maintaining governance standards, ultimately accelerating operational decision-making in manufacturing environments.
上記のDeepLによる翻訳。
製造業組織は、意思決定を遅延させるデータサイロや長大な分析サイクルにしばしば直面します。
本セッションでは、Amazon Bedrock Agentsを活用したエージェント型データ探索により、多様なデータソースを横断した分析を自動化する手法を紹介します。マルチエージェントワークフローが、構造化データベース、分析エクスポート、非構造化テキスト、マルチメディア、APIをシームレスに統合し、ほぼリアルタイムの洞察を得る方法を検証します。
分散型問題解決シナリオにおいて専門的なAIエージェントをオーケストレーションする実践的な実装パターンを学びます。ガバナンス基準を維持しながら分析期間を数ヶ月から数分に短縮し、製造環境における業務上の意思決定を加速する方法を実演します。
以下、チョークトークのセッション内容に応じて進めていきます。
冒頭のご挨拶
皆さん、おはようございます。今日の調子はいかがですか?本日はご参加いただきありがとうございます。私はRobe Sableと申します。AWSでシニアソリューションアーキテクトを務めています。AWSには5年以上在籍しており、自動車・製造業のバーティカルでエンタープライズのお客様をサポートしています。
AWS入社前は、主にソフトウェア開発とイノベーションに焦点を当てたITリーダーシップの役割を長く務めていました。私は北米の自動車・製造業のフィールドCPOであり、ソリューションアーキテクトと、この領域のテクニカルアドバイザーを担当しています。
私は長いバックグラウンドを持っています。実際に工場の現場で働いた経験があり、その後18年間法執行機関で働き、そしてテクノロジーと製造業に戻ってきました。皆さんにお越しいただけて嬉しいです。
このセッションは皆さんのためのものです。スライドは少なめにして、対話を重視しています。ワークショップ形式で進め、皆さんと一緒に考えていきたいと思います。
本日のアジェンダ

なぜ今なのか? テクノロジーは新しく進歩していますが、私たちは今、特別な変曲点にいると考えています。製造業のお客様と毎日仕事をしていて、他の業界にはない課題があることを知っています。他の業界にはないデータ量など、様々な課題があります。
本セッションでは、製造業にフォーカスしエージェントを使ってデータへのアクセスをどう再構築するかについてお話しします。いくつかの一般的なデータアクセスパターンについてお話ししますが、Shwanが言ったように、これは本当にインタラクティブなセッションです。皆さんがデータに関して直面している課題を教えていただき、一緒に解決策を考えていきたいと思います。
お客様と一緒に取り組んだ事例と、そのソリューションがもたらしたインパクトについてもお話しします。これはGitHubで公開されています。詳細が知りたい方は、以下のサイトからアクセスしてください。
こちらには、今日お話しする内容の基盤となるオープンソースプロジェクトがアップされています。
変曲点にいるのか?
私たちはこれについてよく議論します。変曲点なのか?創発点なのか?どちらにしても、Agentic AIとそれができることを考えると、本当に驚くべき状況です。
能力と需要が収束する地点にいるのでしょうか?急速に学習し発見しなければならない時点にいて、今このギャップを埋めなければ、ジャンプできないのでしょうか?
これは歴史上何度も起きてきました。1997年とその後の10年間を覚えていますか?あれも別の変曲点でした。ギャップを埋めた企業もあれば、そうでない企業もあります。それぞれに異なるストーリーがあります。
今日お話ししたいのは、その能力、私たちがこれについて考えた方法です。本当に重要なのは、特に製造業において、生産が最優先される中で、低い障壁と低いリスクで迅速に展開できる場所にたどり着くことでした。
しかし、どうやって会社の競争力を維持するのか?それが私たちの仕事ですよね?私たちはテクノロジーを推進してきました。これが皆さんに持ち帰っていただき、会社の成長に役立てていただきたいことです。
製造業が直面する課題

製造業者は常にこれに直面してきました。何十年も存在する痛みです:
- データアクセスの問題 - レガシーシステム
- Accessデータベースがまだ稼働している
- スプレッドシートで工場が運営されている
- 非文脈化データ
- リアルタイムデータ - IoTやマシンセンサーからのデータ
- オペレーショナルデータ - 需要予測、生産、BOMなど
しかし、Agentic AIの登場により、5番目のカテゴリーが出現しています:サードパーティまたは外部データです。
以下のケースを想像してみてください。
- 保証ケースでの重大故障に対して、バッテリーが運用範囲内にあったかどうかを即座に確認できる天気データ
- 極端な気象条件での金属の故障
- 関税情報に基づいてサプライヤーを即座に切り替える
- 外部の製品レビュー
- 大手小売店のレビュー
- 組み立て型生産のデータ
これらすべては外部に存在しますが、以前は入手が非常に困難でした。今はそれが変わりました。
実際の事例:重大故障の調査
製造業での従来の調査は、データ量やユースケースによって時間がかかります。皆さんも経験されたことがあるでしょう。調査には30日かかることもあります。変革ミーティングがあり、工場での生産方法を変更するためにすべてを行う必要があります。
約1年前、2つのコンポーネントの重大故障を調査するよう依頼されました。故障の原因は、極端な条件下で2種類の異なる金属が組み合わされ、天気が適切な条件になると、エアライドサスペンションのフィッティングが故障するというものでした。
従来: 調査に30日かかり、その間にさらに25万ユニットが生産されました。25万ユニットをリコール、修正、変更する必要がありました。
Agentic AIを使用後: 1時間半で実行でき、現場での重大故障の根本原因分析が完了。翌日には製造を変更し、再稼働。さらに25万個の故障品を生産せずに済みました。
これがAgentic AIを使用することのインパクトです。
アーキテクチャアプローチ
従来のデータ活用のアプローチには、以下のような多くの変換による対応が必要でした。

現在、私たちは以下ののアプローチを実践できます。

- 固定スキーマなし
- 固定データモデルなし
- すべてを柔軟に保つ
これにより、任意のデータセットを取り込む柔軟性が得られました。エージェントがデータを見て、データについて理解し最初の判断を行います。データセットを追加すればするほど、より多くの関係性を理解できるようになります。
工場が使用していたデータが悪いかどうかも即座に判断できます。エージェントが悪いデータだと教えてくれるからです。
これらを組み合わせて、内部データセット、ERP、サードパーティに接続されたエージェントを作成し、製品のデータ発見を行えるようにしました。接続できる限り、どんな製品でも対応できます。
エージェントとスーパーバイザーが関係性を構築し、グラフデータベースにそのエンタイトルメントを確立できます。
データ変換
必要な変換は最小限です:
- カラムヘッダーの変更
- グラフデータベースに入るエンティティ名を持つフィールドを1つ追加
これにより、データのグラフができ、そのグラフをトラバースすることがはるかに容易になります。
例えば、1年半から2年前に生産された製品の保証クレームについて調べる場合:
- サプライチェーンを遡って簡単に調べられる
- サプライヤーが誰だったか
- その材料は何だったか
- 違いがあったか
- どこで生産されたか
- その時の生産ラインには誰がいたか
これらの質問すべてに、データをグラフ形式にして、エージェントにユーザーの自然言語クエリを変換させることで、より簡単に答えられるようになります。
「オーダー123について教えて」と言えば、エージェントはそれをどう調べるかを理解します。スキーマにグラウンドトゥルースがあり、フィールドはありますが、エンティティだけを知っています。オーダーがあり、製品があります。
スキーマの重要性
エージェントが自動的に関係性を作成する際、存在しないものを作り上げないようにすることが重要です。エージェントにはスキーマを生成する指示があり、これは必要なメインノードまたはエンティティのリストとそれらの間の関係性です。エージェントはこれを使い続け、結果がグラウンドトゥルースに従っていることを確認します。
スキーマは自由に調整できます。速度は人間を排除するためではなく、人間を強化するためです。何かが欠けていれば、スキーマをすぐに変更し、アップロードすれば動作します。固定的にせず、調整可能にしたのはそのためです。
これは人間を強くするために作られました。人間を排除するためではありません。
構造化データと非構造化データ
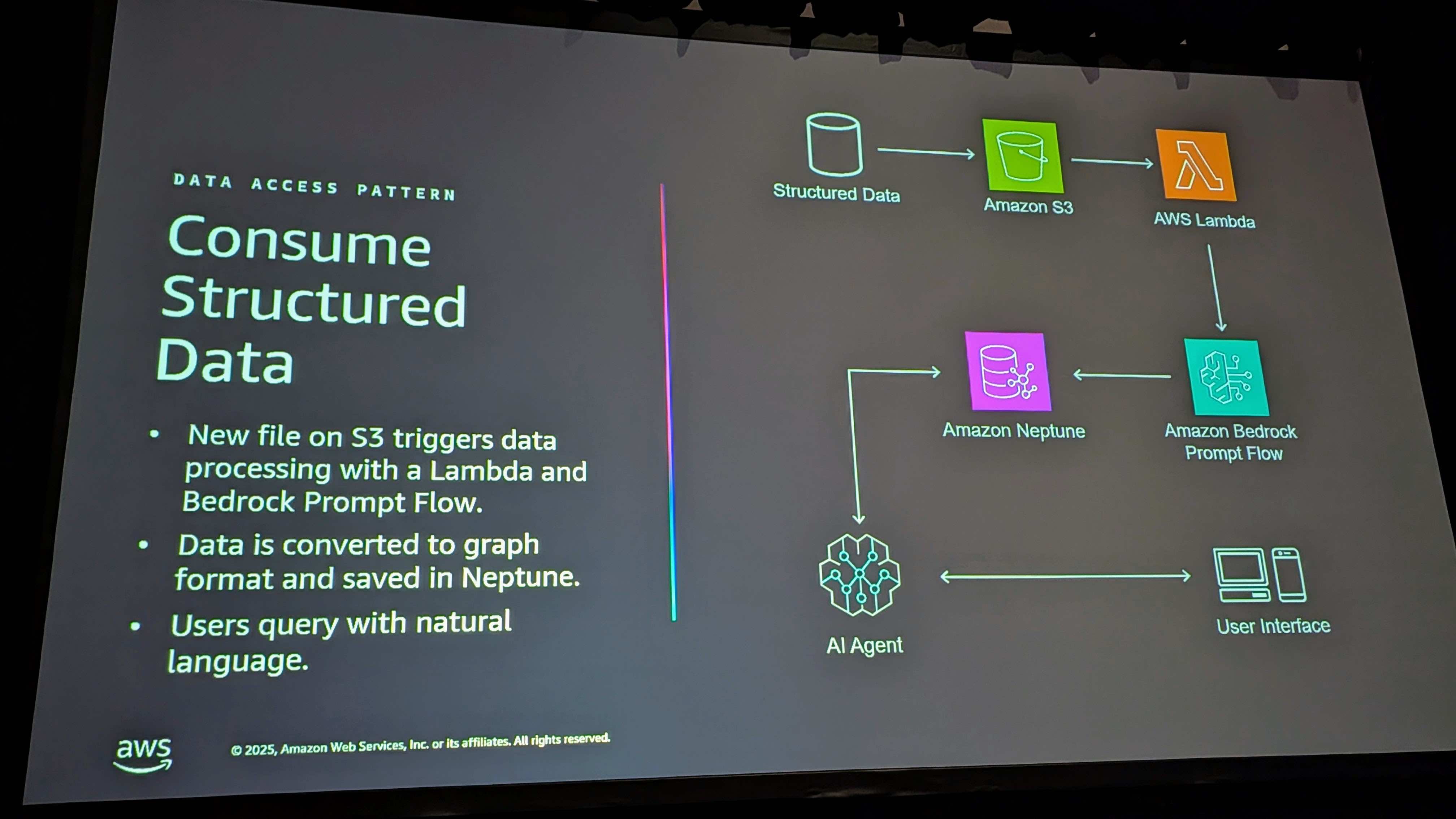
構造化データ(データベース駆動のもの)を活用することには多くの価値があります。しかし、非構造化のデータもあり、それはRAGに適しています。
PDF、テキスト、あらゆるコンテンツ - データベースに入れる必要のないものは、Bedrockのナレッジベースに入れ、エージェントがそのデータセットにアクセスできるようにします。
例えば:
- サードパーティサイトからの製品レビューのデータフィード
- 必ずしもデータベースにロードする必要はない
- 以前は他のものと結合するためだけにデータベースにロードを強制されていた
- 今は非構造化データはナレッジベースに最適
拡張性の面でも、データが変われば素早く調整できます。新しいデータが欲しければ、別のエージェントを追加するだけです。非常にスケーラブルです。
サードパーティAPI

天気の例について話しましたが、この分野には多くの例があります。公開データだけでなく、使用しているパートナーソリューションからも。ERPや他のアプリには独自のAPIがあります。
さらに、ここ数週間で登場したのは、より多くのパートナーが独自のMCPサーバーを立ち上げていることです。MCPサーバーは、独自のAPIを書く代わりにツールとして機能できます。
例えばSAPを使用していて、APIと通信するツールをコーディングしたい場合、それらのプロバイダーは独自のMCPサービスを提供しており、簡単にプラグインでき、エージェントを通じてそのデータにアクセスできます。
ここでの作業は約1時間から1時間半です。
アーキテクチャ概要
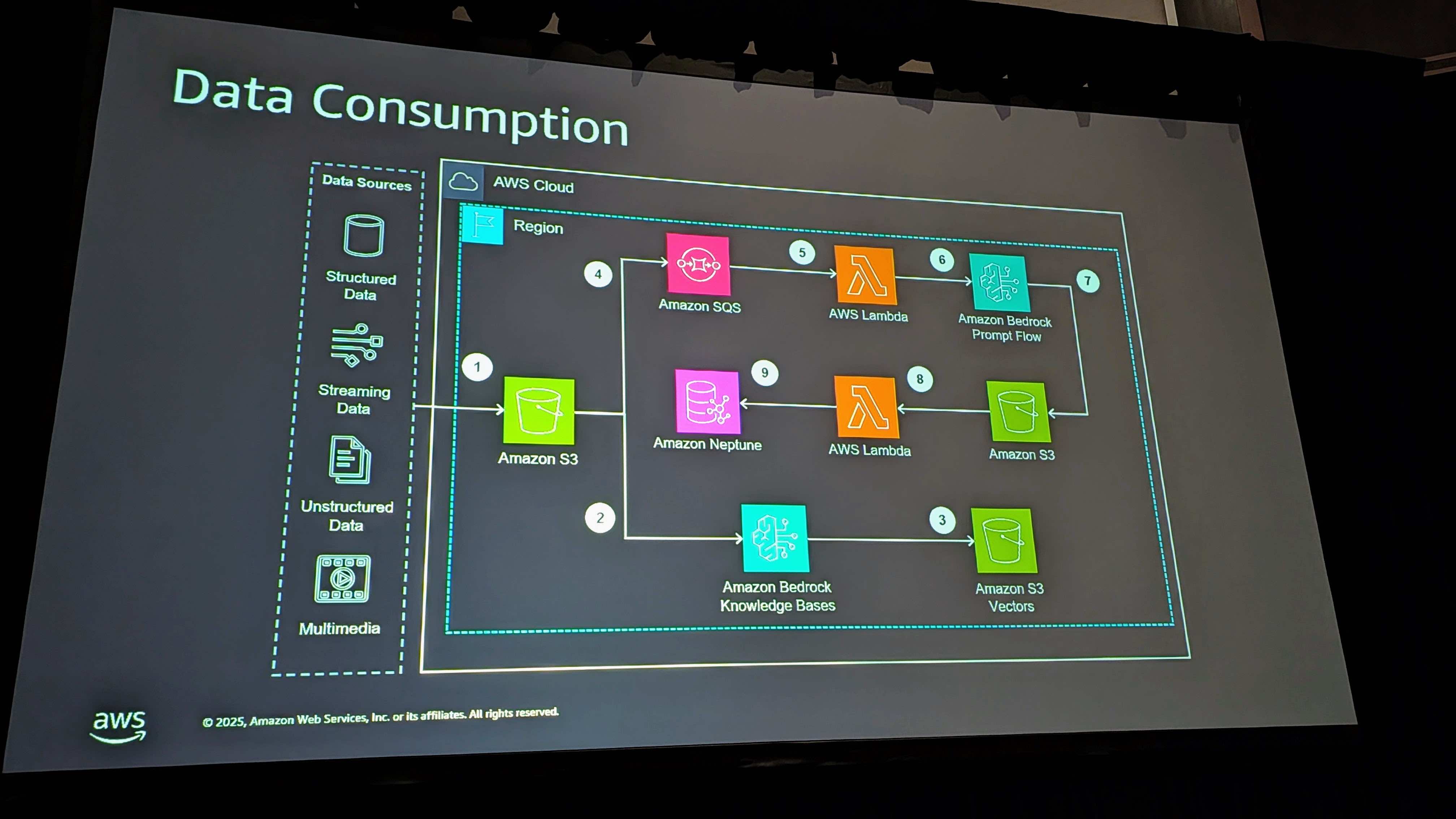
これはソリューションの構成要素の組み合わせです。
番号1、2、3をたどると、非構造化データのパスが見えます。上の4、5、6、7、8、9をたどると、グラフへのパスです。
ポイントは、これらすべてのサイドを期待していることです。ゴールはデータをエージェントがアクセスできる形式にすることです。必要なだけ多くの異なる受信データフローを追加できます。
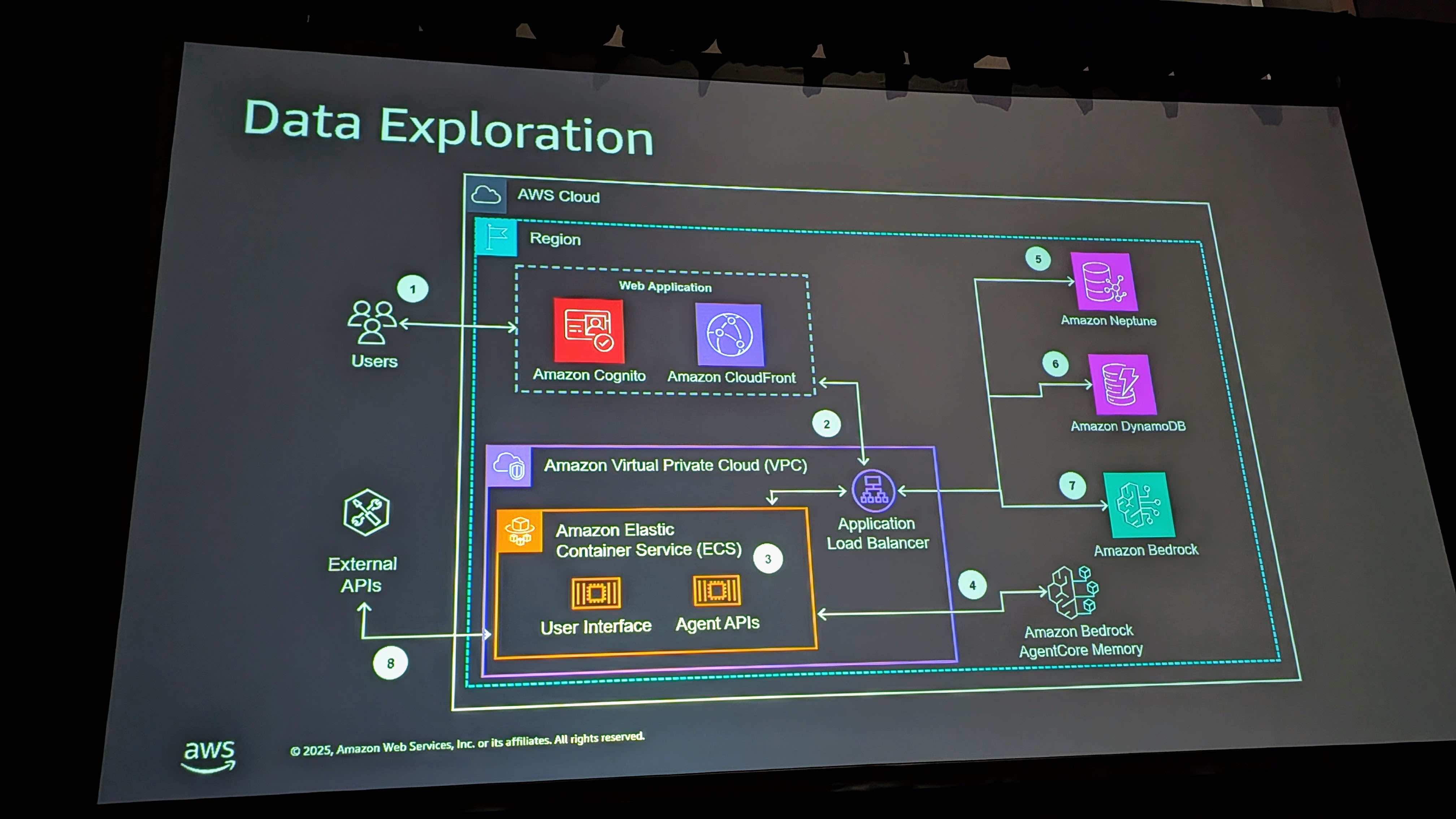
結果として、構築されたアプリケーションを実行します。プロジェクトの動作方法として、エージェントへの直接アクセスを提供するAPIがあります。インターフェースだけが必要で、独自のUIを構築したい場合は、その柔軟性があります。
アプリにはUIも含まれています。現在Fargateで実行されていますが、今年のre:Inventの前に新しいエージェントコアランタイムに移行する予定です。これは自然な進化です。
エージェントコアメモリ
エージェントコアメモリを使用しています。チャットの良いところは、あなたのことを知るようになることです。あなたの好みを理解し、短期・長期メモリを活用します。
これらのデータポイントを定期的に扱う人にとって重要です。明日システムに入って「昨日やっていた調査に戻ろう」と言えば、「では中断したところから続けましょう」と言ってくれます。
メモリが重要なのは、慣れているやり方に近いからです。宿題をするとき、中断したところから再開しますよね?ゼロから始めてすべてをクリアする必要はありません。メモリがそのカギです。
DynamoDBの役割
まだ話していない最後の部分はDynamoDBとその役割です。
DynamoDBはエージェントによってレポート履歴に使用されます。会話履歴を保持するためにBedrockのメモリを使用できますが、データのライブイングと変換については、エージェントがそれを行う際にDynamoDBにログを取ります。
UIでシステムへのデータフローを確認でき、エラーが発生した場合もそこにログされます。そのアクセスも得られます。
ユーザーペルソナ非依存
ユーザーの側面についてダブルクリックすると、これを意図的にペルソナ非依存にしました。誰が入って作業する必要があるか、会社でどんな役割を持っているかは関係ありません。
財務コントローラーでも、品質担当でも、工場長でも、HRでも。役割非依存にしました。
ただし、これを行った場合、独自のコントロールを設置する必要があります。特定のデータを特定の人から制限したい場合は、適切に接続する必要があります。トレードオフはあります。
非常に重要だと考えたのは、誰でもできるように非依存にすることでした。特に今、エージェントが誰がいて、誰が質問していて、なぜ質問しているかを理解するようになったからです。
同じ質問を同じ方法で聞いても、工場の3人の異なる人に3つの異なる方法で重要です:
- マーケティングはレビューを気にする
- 調達は価格を気にする
「最も人気のあるSKUは?」と聞いて実行すると、ペルソナに基づいて適切な回答が得られます。その力と柔軟性をプラットフォームに与えるために非依存にしました。
Q&A セッション

ここまで、アーキテクチャの内容を詳しく説明してきました。新しい概念なので、様々な質問があると思います。せっかくのチョークトークです。さぁ、遠慮なく質問を挙げてみてください。
Q: データへのアクセス制御について
A: データがどこに保存されているかによります。テーブルを分離するのは少し重くなります。データベースを分離して、必要なものへのアクセスだけを与えるのが簡単です。
エージェントとツールを通じてこれを行えます。ユーザーロールを持ち、特定のユーザーには特定のツールだけが利用可能になるようにできます。
特定の顧客セットへのアクセスのようなものは、典型的なセキュリティが必要になります。エージェントレベルで指示を書いて「顧客名を出さない」「これらのフィールドだけを出す」といった粒度まで書くこともできます。
ただし、ラビットホールに深く入りすぎると、自分自身にオーバーヘッドを作ることになります。パラダイムに挑戦することをお勧めします。
複数のユーザーインターフェースと複数のエージェントで異なるアクセスを構築できます。すべてのユースケースに対応する1つではなく、特定のユースケース用に複数回インストールできます。エージェントコアランタイムでは、複数回実行してもコストへの影響はほとんどありません。
Q: 不整合な構造化データへの対処
35種類の異なるファイルが一度に来て、異なる形式や変数がある場合。
A: データストアの前に変換を行うことをお勧めします。エージェントがその一部を行うことができます。すでに日付のようなものに対するロジックが組み込まれています。これはおそらく最も一般的な問題で、異なる形式があります。
エージェントの指示に、すべての日付をどの形式にするかを追加します。プロファイルにはいくつかの基本的なものが組み込まれていますが、カスタマイズできます。
例えば、住所。35種類の異なる形式があり、「住所」という単語がスペルミスされていても、エージェントはそれが住所であると推測します。
スキーマで調整が必要な場合もありますが、25種類の異なるものを渡すと、グラフで住所のバブルを見ると、住所フィールドを見たすべてのデータセットが表示されます。
ただ「ad」とだけ書かれているかもしれないフィールドは認識されないかもしれません。そのデータセットを追加して、そのフィールドが何かを正確に伝える必要があります。
現在のユースケースでは、農業ビジネスで今年の干ばつに強い完璧な種子を見つけるために1000万のゲノムを処理するようなことはしていません。そのレベルだと正直問題が起きると思います。
しかし、製造現場での現在のユースケースでは、そのような問題には遭遇していません。
Q: 構造化データと非構造化データの統合
構造化データはNeptuneに、非構造化データはナレッジベースにあります。
A: これは本当にデータサイロを排除し、ソース間でデータを組み合わせたり関連付けたりできるようにすることに戻ります。
一般的な例:製品があり、保証クレームがあり、どこかのサイトからの公開カスタマーレビューがあり、ERPデータがあり、製造ラインデータがあります。これらはすべて異なる形式と異なるシステムにあります。
保証クレームの徹底的な根本原因分析を行うには、これらすべてにアクセスする必要があります。カスタマーレビューは非構造化データです。製品データはデータベースから来ます。
構造化データと症状を、カスタマーレビューや製造している製品の技術仕様PDFのようなものと組み合わせる必要があります。
すべてのデータがエージェントにアクセス可能になります。異なるタイプのデータが混在していても処理できます。
これはスーパーバイザーエージェントレベルで処理されます。接続は切り離されています。スーパーバイザーは物事がどこにあり、どの質問に対してどこに行くべきかを理解し、他のエージェントに仕事をするよう指示します。
すべてをNeptuneに持ってくることもできます。それが適切な価値提案かもしれません。柔軟性を残しました。すべてを持ってきたければ100%可能です。会社にとって最適な場所にプッシュとプルができる柔軟性を与えただけです。
特定のシナリオでは、すべての関係性を理解したい場合、それは可能です。同時に低コストを維持する柔軟性を与えているだけです。
Q: ビデオや写真の処理
ビデオや写真をエージェントが理解できる関連ポイントにどう持ち込むかについて。
A: 受信マルチメディアについては、その画像をパースします。Novaがビデオとオーディオをパースします。画像から抽出された情報(タグ、説明など)はカタログ化されて保存されます。
意味のある形式で保存できます。追加データを取得したい場合は、フローの最初に適切な処理を設定します。
既知のETLがあって特定のものを抜き出す場合も、システムで設定でき、カスタマイズ可能です。
スーパーバイザーエージェントはすべてのリクエストを受け入れ、アクセスできる他のすべてのエージェントとツールを知っています。指示に、異なるデータフローを説明し、クエリや使用方法を書きます。
これらの指示が、構造化データ対ナレッジベースの質問に役立ちます。エージェントはどこからデータを取得すべきか、スーパーバイザーの指示で知ることができます。
消費側で画像をパースするものと、アクセス側でメタデータを構築するためのツールや方法が必要です。
メタデータを持つことができ、データセットに構築できます。ユニークな能力が必要な場合は、レンズを書いて「毎回これをあれに追加」と指定できます。少し高度ですが、シンプルに保つなら、ファイルを置くだけです。
工場のノイズや、ラインの命名法、そのカメラのハブを書いて、時系列に追加できます。
Q: 大量の構造化データのパフォーマンス
パフォーマンスの期待について - 大量の構造化データがある場合。
A: 質問は、エージェントにどのように検索させるかについてです。指示やツールで、検索を広げるオプションを与えないように注意する必要があります。
伝統的なパフォーマンス最適化が必要になります。もっと頻繁に出てくるのはLLMに関するもので、異なるモデルは異なるパフォーマンスを発揮します。
好きなモデルを使用できますが、Anthropic Claudeを使用するか、Amazon Novaを使用するかで、異なるレスポンス時間があります。
特定のケースに適したモデルは何かに焦点を当てることが重要です。そこが変化する部分です。最新のベストプラクティスに従うことをお勧めします。
モデルによって異なる利点があるので、柔軟性に焦点を当てて最新のものを使用しています。どのモデルが最良の結果を与えるかを理解することに時間をかけることが重要です。
Q: エージェントとNeptuneの関係
エージェントはNeptuneにどう書き込むのか。
A: エージェントには、自然言語の質問をグラフクエリに変換し、クエリを実行し、結果を返すツールがあります。
特定のグラフQAチェーンツールを使用しています。これは非常に便利で、他のAWSプロジェクトでも使用しています。グラフに接続するだけで、データベースをクエリしてスキーマを理解します。
データベースへのアクセスを与えれば、すべての関係を把握し、そこから処理を進めます。これが最も強力な部分の1つです。
Q: AIエージェントの設計原則
異なるデータセットに対してAIエージェントをどのように設計するかについて。
A: ユースケースから始めて逆算します。それがエージェントが何にアクセスする必要があるか、どの境界線にアクセスする必要があるかを定式化するのに役立ちました。
例えば、世界が私のドリルについてどう思っているか知りたい場合:
- 1つのエージェントを書いて大手小売店に行かせる
- 別のエージェントを書いてTikTokを監視して開封動画を見る
そのように逆算して考えます。ストーリーの終わりに到達したときに、適切なエージェントができるように。常に逆算して設計します。
Q: エージェントの数の制限
数の制限について。
A: シンプルな制限があります。通常1〜8、1〜12です。1つのスーパーバイザーに対して約8つのエージェント。
特定のワークフローについては、スーパーバイザーが処理したいだけ多くのエージェントを処理できるという無制限のルールがあります。ユースケースに適したコンテキストと回答が得られます。
これを製造施設のどの部門でも調査を行うことを想定して書きました。それぞれに非常に一般的なデータセットがあり、いくつかはユニークです。そのユニークなデータセット内の質問を処理するために、ユニークなパラメータを持つユニークなエージェントを書きます。
すべてがマルチエージェントである必要はありません。探索側とデータ消費側で非常に異なる部分があるからです。
私が言いたいのは、任意の数のツールを持つ1つのエージェントから始めることです。すべてのツールの使い方を知っているエージェント。マルチエージェントを追加すると、リクエストの複雑さが増します。
エージェントは任意の数のツールを持てるので、5つの異なるデータソースに到達する1つのツールを持てます。そのために5つの異なるエージェントは必要ありません。
より一般的には、ビジネスプロセスをマッピングします。RPAや何らかの自動化プロジェクトを行う場合と非常に似ています。ワークフローに深く入り込み、人々の隣に座る必要があります。
多くのことが非常に根付いています。それらの細かいディテールを見逃すと、このようなソリューション全体が崩れる可能性があります。これは本当にビジネスプロセスを自動化する別の方法であり、ビジネスプロセスに従う必要があります。
Q: データ分類について
データ分類に関して。
A: 堅牢な分類があれば、エージェントの指示に入れることができます。堅牢な分類を持つ企業もあれば、2つの分類しかないような企業もあります。
複数の方法でできます。組織で既に何が整っているかによって、最も意味のある方法を選びます。
Q: 強化学習の使用
エージェントで強化学習を使用しているか。
A: まだ行っていません。よく聞くのは、自己学習エージェントで、自分自身をチェックし続け、構築している指示を更新するようなものです。
まだ行っていませんが、多くの人が「どうやってシステムを完全に自己維持・更新できるようにするか」を考えています。非常に理にかなっています。
Q: なぜリレーショナルデータベースではなくNeptuneか
構造化データにリレーショナルデータベースを使わないのはなぜか。
A: リレーショナルデータベースも使用できます。Neptuneに接続できます。
これは、グラフのスキーマを取得し、自然言語変換を行うツールを使用するためでした。製造データから顧客の手に届くまでを接続するような関係をトラバースする能力に役立ちます。
グラフは、すべての結合クエリを書かずにそれらの関係をトラバースする能力に役立ちます。
特に孤児データで役立ちました。エージェントが独自のシンプルなETLプロセスを実行する際に、孤児データセットが表示されました。会社はまだすべてのデータを使用してビジネスを運営していますが、処理すると、ビジネスプロセス全体で関係のない孤児データのポッド全体があることがわかりました。
これは追加の利点でした。求めていたものではなく、結果として得られた利点です。
Q: 本番環境への準備の判断
エージェントが本番環境の準備ができているかどうかをどう判断するか。スピードと評価について。
A: これには評価フレームワークが組み込まれています。準備ができたかどうかは、閾値と結果次第です。
評価を実行し、一貫性を見つけたとき - 70%、80%、90%と言う人もいます - その部分はあなた次第です。テストが必要です。評価フレームワークを使用すると、ユーザーテストだけでなくスケールで行うことができます。
評価はStrandsに組み込まれているものです。
これはデータ探索用であり、本番ワークロード用ではありませんでした。そのためコンセプトが異なります。
平均的な人間について考えてみてください。釘を打つとき、約74%の精度で打てます。人生を通じて研究されています。
会社は異なるパラメータ、異なるレベルで自分自身を想定できます。例えば私の水泳とマイケル・フェルプスを比べるようなものです。マイケル・フェルプスのストロークはおそらく毎回98-99%正確です。私はそれに近くもありません。
しかし、これらのビジネスプロセスを座って行い、歩んでいる誰かには特定のレベルの効率があります。会社は自分自身を測定して「80%に達すれば、これを毎日行っている労働者よりおそらく良い」と判断する必要があります。
ただし、これをワークロードとして書いたのではなく、人間の助けとして書きました。そこが少しトリッキーです。これを変換できますか?はい。私たちはそうしませんでした。ビジネスのすべての従業員をより良くするために作りました。
Q: Neptuneへのデータロードの問題
Neptuneとデータのロード、問題について。
A: おそらく最も秘密なコンポーネントは、自然言語からグラフクエリへの変換を行う部分だと思います。
ガードレールは探索側で使用されているので、ユーザーチャットにガードレールがあります。しかし、データ消費側では、グラフをクエリしているコンポーネントがあります。それがスキーマを検索し、グラフの実際のエンティティと関係を知るためのグラウンドトゥルースになります。
そこから逸脱すべきではありません。もう1つは、保存しているスキーマがあり、形式は:エンティティ、関係、そして関連する他のエンティティです。例えば、製品は保証を持つ、のように。
そのグラウンドトゥルースを持つことが、データ消費側でエージェントが使用するものです。「この製品の関係を推測しよう」と言ったとき、製品の有効な関係は1、2、3、4で、それらを見つけようとします。
これがないと、関係を作り上げたり、エンティティを追加したり、テーブルを取って複数のエンティティに分割しようとしたりします。
本当に指示にあります。ライブラリを使用しています。終わったらGitHubで調べて名前をお教えします。
そのコンポーネントが、データベースの詳細に入らずに済むようにしてくれていると思います。クエリに役立ち、存在しないものに対してクエリしようとしないと分かりました。
最も難しい部分は、データがクリーンでない場合です。
そして、密接に名前が付けられているものがあり、指示が明確でない場合、いくつかのおかしな結果が出ることがあります。その遷移にあると思います。
セッション聴講後の感想
チョークトークは時間が1時間ということもあり、またこのセッション自体が技術的に非常に多岐にわたる内容を扱っているため、この時間で技術的な詳細を把握することはかなり難しいなと感じたのが正直なところです。ただ、サンプルのソースはセッション中で触れられていた通り、下記に既に公開されているとのことです。
また、チョークトークならではの多様なQAが聞けたのは非常に収穫でした。特にデータの権限に関しては非常によく質問される事項だと思うので、今後似たような機能を構築していくうえで参考にしておくべき内容だったと思います。
今後の理解を深めるため、改めてソースコードをデプロイしつつ、各コンポーネントの動作を実際に確認していく予定です。そちらの解説も楽しみにしていてください。
それでは今日はこのへんで。濱田孝治(ハマコー)でした。









